Decision tree and deep learning based probabilistic model for character recognition
��Դ�ڿ������ϴ�ѧѧ��(Ӣ�İ�)2017���12��
�������ߣ�A. K. Sampath Dr. N. Gomathi
����ҳ�룺2862 - 2876
Key words��grey level co-occurrence matrix feature; histogram oriented gabor gradient feature; hybrid classifier; holoentropy enabled decision tree classifier
Abstract: One of the most important methods that finds usefulness in various applications, such as searching historical manuscripts, forensic search, bank check reading, mail sorting, book and handwritten notes transcription, is handwritten character recognition. The common issues in the character recognition are often due to different writing styles, orientation angle, size variation (regarding length and height), etc. This study presents a classification model using a hybrid classifier for the character recognition by combining holoentropy enabled decision tree (HDT) and deep neural network (DNN). In feature extraction, the local gradient features that include histogram oriented gabor feature and grid level feature, and grey level co-occurrence matrix (GLCM) features are extracted. Then, the extracted features are concatenated to encode shape, color, texture, local and statistical information, for the recognition of characters in the image by applying the extracted features to the hybrid classifier. In the experimental analysis, recognition accuracy of 96% is achieved. Thus, it can be suggested that the proposed model intends to provide more accurate character recognition rate compared to that of character recognition techniques used in the literature.
Cite this article as: A.K.Sampath, Dr.N.Gomathi. Decision tree and deep learning based probabilistic model for character recognition [J]. Journal of Central South University, 2017, 24(11): 2862�C2876. DOI: https://doi.org/10.1007/ s11771-017-3701-8.
J. Cent. South Univ. (2017) 24: 2862-2876
DOI: https://doi.org/10.1007/s11771-017-3701-8

A. K. Sampath1, Dr. N. Gomathi2
1. Rizvi College of Engineering, Mumbai, Maharashtra 400050, India;
2. Veltech Dr.R.R&Dr.S.R. Technical University, Avadi Chennai-600 062, India
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2017
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2017
Abstract: One of the most important methods that finds usefulness in various applications, such as searching historical manuscripts, forensic search, bank check reading, mail sorting, book and handwritten notes transcription, is handwritten character recognition. The common issues in the character recognition are often due to different writing styles, orientation angle, size variation (regarding length and height), etc. This study presents a classification model using a hybrid classifier for the character recognition by combining holoentropy enabled decision tree (HDT) and deep neural network (DNN). In feature extraction, the local gradient features that include histogram oriented gabor feature and grid level feature, and grey level co-occurrence matrix (GLCM) features are extracted. Then, the extracted features are concatenated to encode shape, color, texture, local and statistical information, for the recognition of characters in the image by applying the extracted features to the hybrid classifier. In the experimental analysis, recognition accuracy of 96% is achieved. Thus, it can be suggested that the proposed model intends to provide more accurate character recognition rate compared to that of character recognition techniques used in the literature.
Key words: grey level co-occurrence matrix feature; histogram oriented gabor gradient feature; hybrid classifier; holoentropy enabled decision tree classifier
1 Introduction
Character recognition [1] is an emerging research used widely in pattern recognition, artificial intelligence, machine vision, and image processing [2]. Moreover, in the modern world, adaptation of tablets and mobile phones also utilize character recognition [3]. Due to the increased requirement of images in the processing field, the challenges concerning character recognition ascends day by day. The methods of character recognition can provide a symbolic identity to the printed input image. The technique reads the input as a sequence of characters using the existing set of characters. It is reliable and is an alternative for the manual typing [4]. As character recognition depends on optically generated characters instead of magnetically generated characters, it is also named as optical character recognition (OCR). The challenges in OCR like lighting variation, distortion, blurring of the printed character image and difference in font size, increased the demand for OCR in the research. The important drawback observed in OCR is that the infraclass variations are large due to the large quantity of image availability for the processing.
Since the numbers of reports, contracts, letters, and so on, are being increasing nowadays, the requirement for retrieval, archival, distribution and replication of such printed documents is rising. These procedures can be executed automatically using OCR [2]. The steps involved in the character recognition based on OCR are as follows: pre-processing, feature extraction [5] and classification/recognition [6]. In pre-processing, the images that are subjected for character recognition are filtered and resized. The low level features of the image like shape, color corner, and texture, which represent the perceptual images are extracted in the feature extraction, based on which, the similarity and the dissimilarity between the images are evaluated for the recognition [7]. This utilizes both the semantic and non-semantic information of the image. The things to be considered during the feature extraction are 1) unrelated noisy features must not be selected; 2) features having less feature space are to be selected; 3) the cost of computation for the feature extraction must be low [2]. Once the features are extracted, they are classified and recognised by the classifier. The classifiers that can be used for the recognition are support vector machines (SVM) [8], neural network (NN) [9] classifier, etc. The accuracy of character recognition varies due to lighting resolution, font size variation, blurring, and so on,whereas, the efficiency depends on the classifier algorithm used for the recognition.
There are various techniques developed for recognizing printed characters on definite databases [10] like binary weighed scheme (BWS), moment-based pattern classifier (MPC), multilayer back propagation (MLP) and frequency weighed scheme (FWS). Back propagation (BP) network can be used to extract the arithmetical and the structural features from the written characters [11] to solve the problems related to distorted hand written recognition. The unpredictability in the handwritten character recognition is mainly due to a writer��s dissimilar writing styles [12]. Inappropriate selection of features is also an issue that affects the recognition technique. The feature selected must contain the entire information associated with the digital image, such as color, texture, background, structure, contour information, foreground, and shadow feature [13]. Most of the classification algorithms designed for the optical recognition are limited due to the accuracy that reduces due to varying writing styles.
This research paper intends to design a new hybrid classifier model for the optical character recognition. The proposed probabilistic model develops a classifier comprised of holoentropy based decision tree and DNN to enhance the performance of recognition. The GLCM and local gradient gabor features are extracted for the character recognition that utilizes both the statistical and the local information of the images to improve the efficiency of character recognition. The training process of the proposed probabilistic model is based on DNN classifier.
A hybrid classification model comprised of HDT and DNN is proposed. The classifier trains DNN and HDT separately in the training process for the generation of new class labels. The probabilistic model is designed based on the mean and the variance of the feature vectors from the classes generated, for the character recognition. The organization of the paper is as follows. Section 2 presents the study on character recognition techniques used in the existing systems. The motivation for the proposal recognition approach is described in section 3. In section 4, the proposed probabilistic model for character recognition is explained. The results and discussion of the proposed system is demonstrated in section 5. Section 6 provides the conclusions of the paper.
2 Literature review
Handwritten OCR, which defines the mechanical translation of images by providing machine-editable text, is a research area employed in pattern recognition, machine vision and artificial intelligence.
The literature review made on the classification approaches used for the character recognition is explained in this section. Therefore, ten research papers that used different types of classification algorithm for the recognition of the optical character are reviewed. SURINTA et al developed a classifier using k-neighbor and SVM classification algorithms [14]. For the character recognition, SVM is used along with the local gradient features of the optical image. But, the accuracy of the SVM classifier in character recognition is poor. Hence, FUKUSHIMA [15] designed NN classifiers to improve the accuracy. A hierarchical model, neocognitron, that can deform the invariant recognition, was developed for the connected character recognition. Later, training algorithms were developed by CHOUDHARY et al [16] to learn the network. The authors adopted binarization technique to overcome the limitations of feature extraction.
In Ref. [4], a feed forward network classifier was presented. To solve the descendant problem that occurred in the error minimization and to attain high accuracy, BP training algorithm was used in the neural network. A recognition approach was developed by AVI-ITZHAK et al [17] using centroid dithering in the training algorithm that has several advantages like, low sensitivity normalization and character recognition over multi-size and multi-fonts. A similar approach was developed by YANG et al [11], they used statistical and structural feature information for the character recognition. The slow convergence issue in the BP network provided a way for multi networks for the recognition.
Dual Cellular Network architecture was developed by SZIRANYI [18] for the character recognition, where the recognition rate attained was 95 %. As a solution to the issues related to the generation of feature space, an image zoning method based on voronoi was designed by PIRLO et al [12]. A membership function was created by the combined action of the image zoning method that could be used in any zoning classifiers irrespective of the feature type. Two stage foreground sub-sampling approach was designed by VAMVAKAS et al [2] for the character recognition. The prediction was made with the utilization of sub sampling method that provided granularity level based classification of the feature space. In Ref. [19], a decision tree based classifier was presented using a multi stage classifier similar to the quad trees. The best feature formed at each stage of the tree was considered as the optimal feature, for which the recognition was performed.
3 Motivation
In this section, the motivation behind the development of the proposed probabilistic model based classifier for the character recognition is explained.
3.1 Problem definition
The character image that is to be recognized is the input to the OCR, in a pattern recognition system. From the input images, the important features are then extracted and are used for the recognition in the classifiers. Consider S as the input image, represented as S=[S]u��n, where u and v are the number of image pixels in the row and the column, subjected for the character recognition. The size of the feature vectors that are extracted from the character image of size 1��i��m is in the range 1��j��n. The generated feature vectors can be expressed as, F=[F]m��n. The feature vectors extracted are applied to the classifier that consists of HDT and DNN, where the classes generated, i.e. (m��1) are converted into a probabilistic model in the proposed OCR system for the character recognition.
3.2 Challenges
Following are the challenges that should be considered while developing the OCR system of high accuracy:
1) The important challenge in character recognition is in attaining high accuracies with the handwritten character data sets, as they vary with varying data styles of the same characters, writing persons (with differences in the age, gender and education), writing devices or the difficulties that arise due to background noise that appears from the printer, in case of a printed document [20].
2) Another challenge in character recognition is the low quality image that gets affected due to noise, illumination variance, complex and degraded backgrounds, and so on, making OCR a difficult task [21].
3) The rate of recognition of the training and the testing sets to be feasible is also a challenge for the OCR systems of high accuracy [22].
4) For prediction learning, the feature space considered must be comprised of both the structural and the local information of the character image [23].
5) In Ref. [14], local gradient feature descriptors were used with SVM classifier for handwritten character recognition to preserve the texture property. However, structural description is more concerned than texture description, as it gains robustness against the light variation and small deformation in the character image [24]. It is also used for the measurement of smoothness of the image. Hence, to improve the performance of the classifier, the gradient and the structural descriptor features can be used with the model based class labelling results for accurate recognition.
4 Proposed system: Probabilistic model based hybrid classifier
The proposed hybrid classifier that uses probabilistic model for the optical character recognition is explained in this section. The block diagram of the proposed hybrid classifier for the recognition is depicted in Fig. 1.
The input to the classifier is the character image to be recognized. The most fundamental step in classification is pre-processing of the image. The pixel intensity that resembles the image is extracted in pre-processing, as it contributes to the region of interest boundary. After the detection of interest boundary, the size of the image is reduced by eliminating the pixels without much lose of information. Then, the feature vectors of the image that constitutes color, shape, local, texture, structural and positional information, are extracted. To extract the gradient features, histogram oriented gabor gradient (HOGG) and grid format level procedures are used, whereas, the texture features are extracted adopting GLCM. The extracted features are fed to the classifiers by concatenating them into a single feature vector. The proposed classifier used for the handwritten character recognition is the hybrid classifier that combines DNN classifier and HDT. Moreover, a probabilistic model is designed by combining both the classifiers in the proposed OCR approach so that the accuracy in character recognition is improved. The probabilistic model utilizes the mean and the variance of the classes obtained using both the classifiers.
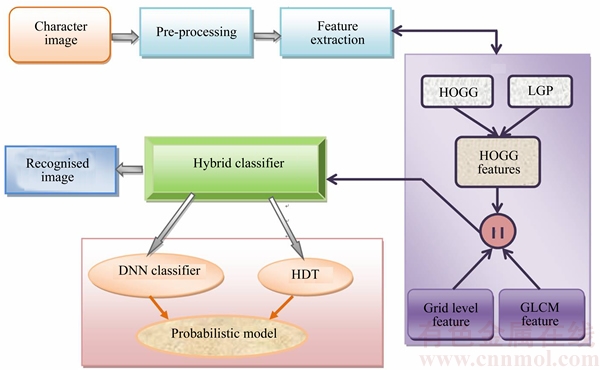
Fig. 1 Block diagram of proposed hybrid classification model
The feature vectors applied into the classifier is split into classes. In the classifier, the training set is labelled into 62 classes that consist of 26 alphabets (upper case and lower case letters), and (0�C9) numeric numbers. The recognition procedure is carried out in two sessions, training and testing sessions. The features are labelled into classes in the training session, whereas in the testing session, the character images having similar sequence with the labelled classes are recognized precisely and accurately.
4.1 Pre-processing
The proposed classification system for character recognition begins with pre-processing. In pre- processing, region of interest (ROI) extraction is done in the input character image covering the pixel intensities, which indicates the presence of the letter sequence in the image [25]. After ROI extraction, the image is resized to distinguish the character image from the unnecessary background of the image. Here, the size of the input character image is not entirely minimized in pre-processing, whereas, the pixel size is reduced.
Assume the input image S having u��v number of image pixels. The pre-processed image, which is resized into the image with high pixel intensity representing the presence of the image, is defined as
Sp=[Ss] (1)
where Ss is the pre-processed image.
4.2 Generation of feature space
The performance of OCR system relies on the feature extraction technique, which in turn, depends on the output of the pre-processor. The feature extracted from the character image must be capable of matching the requirements of the classifier adopted for both the classification and the recognition. The proposed hybrid model generates three feature spaces, namely, HOGG feature; grid level feature and GLCM feature. The features extracted include the texture, structural, statistical and positional information of the input character image. The detailed explanation of the feature spaces generated is given in the following subsections.
4.2.1 Histogram oriented gabor gradient feature
The reason to use HOGG feature for the feature extraction is that HOGG characterizes the appearance of local objects using local intensity gradients, without requiring any prior information about the gradient position or direction [26]. Oriented histograms are employed by combining histogram and normalization methods and the feature space is extracted using a fusion approach [27]. The histogram feature is extracted using local Gabor pattern (LGP) and Haar wavelet transform. Haar wavelet transform is one of the wavelet transforms that are being used for the compression of image suppressing the noisy pixels in the image. Bior4.4 wavelet consists of decomposition and reconstruction processes, where the image is decomposed using two filters, low pass filter and high pass filter. The reconstruction is usually based on a reverse process that burdens the computation. Hence, Haar wavelet transform is used in this work to resolve this issue, due to its simplicity, memory efficiency and robustness against the edge effects. Figure 2 depicts the proposed histogram oriented feature extraction approach.
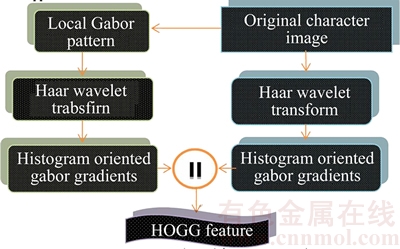
Fig. 2 HOGG-based feature extraction
In Fig. 2, the symbol ��||�� indicates the concatenation operation of feature obtained from the LGP pattern and HOGG feature from the input character image. These features are used for making the decision module.
First, the character image is applied to the LGP, which encodes the color and the texture information of the character image. By comparing the centre pixel of the grey scale image with that of the neighboring pixels, LGP approach extracts the texture information. The Haar wavelet transform converts the images of LGP and the original character image into wavelet transformed images [28]. The reason to choose Haar wavelet transform is due to its ability of encoding the shape and the texture information and less computational complexity. Moreover, the approach can improve the edges of the images more accurately. The Haar wavelet basis function is generated by combining the Haar scaling function and the wavelet function. The basis function with these two combined functions is represented as
Haar basis function=Haar scaling function��Haar wavlet function
The Haar scaling function is given by
 (2)
(2)
The wavelet function using Haar wavelet transform is defined as follows:
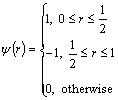 (3)
(3)
For the converted wavelet transformed images, the histograms are formed depending on the gradients computed in every possible direction. In HOGG, the histograms obtained are collected over the detection window in the image. The wavelet transformed image is then normalized and the gradients are computed in HOGG. Depending on the gradients computed over the input image, the histogram is generated by performing weighted voting over the spatial and orientation cells [27]. The image is partitioned into cells after applying the Haar wavelet transform and the histograms are generated for the pixels in each individual cell using HOGG. HOGG obtained from the wavelet transformed image of LGP and the original images are concatenated to obtain the histogram oriented gabor features.
The feature extraction procedure using the histogram oriented gabor feature can be represented mathematically as follows.
For the input character image [Ss], the HOGG feature is extracted using the local gabor pattern and the Haar wavelet transform.
Based on the application of LGP and Haar wavelet transform, the feature extracted can be expressed as
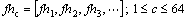 (4)
(4)
4.2.2 Grid level feature
This section explains the generation of feature vector using the grid level feature process. The grid level feature is the second feature extracted. Here, more precise image information that covers the local gradients is extracted [14]. In the grid level feature set, the input image is given to the grid format. In Fig. 3, the feature evaluation using the grid format is depicted. The feature extracted using grid level feature gives the positional information regarding the character image. The grid format used for the generation of feature vector is comprised of M��M grid cells. Once the character image is accepted, it is concurred with the grid cells. The image with the grid cells and the grid cells that do not contain the character image is assumed to be binary. After assigning the binary value, the grid format is scanned depending on the presence of the image over the cells, to create the binary sequence for the input image. Using the binary sequences generated, the feature vector based on the grid level is obtained. For the generation of binary sequence from the grid, the values taken are organized from the left to the right and from the top to the bottom of the grid.
The grid format representation for the input image S, over the grid format that contains M��M grid cells is given by
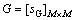 (5)
(5)
where the function [SG]M��M is defined as
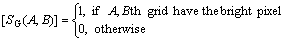 (6)
(6)
The feature vector based on the binary sequence generated is represented by
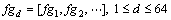 (7)
(7)
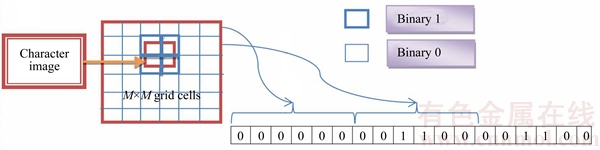
Fig. 3 Process of extracting grid level feature
4.2.3 GLCM feature
The procedure for extracting GLCM feature is illustrated in this part. The GLCM feature of the character image is extracted to get the statistical texture information of the image. GLCM [25] is equivalent to that of the histogram that has the co-occurrence grey scale values of the character image. GLCM feature extraction process is performed based on the GLCM matrix. The texture feature of the character image is extracted utilizing the statistical distribution of the pixel intensities located at a specific position in accordance with the neighbor pixel. The GLCM matrix consists of rows and columns equivalent to the number of grey levels of the image. The elements in the matrix are formed according to the relative variation in the frequency value of the pixels with difference intensities. The matrix element of GLCM indicates the second order statistical values and the formation of GLCM is depicted in Fig. 4. The co-occurrence matrix consists of five different grey levels and the values are filed in the matrix depending upon the combination of the cells.
The features are generated from the GLCM matrix. The features that are obtained from the GLCM matrix in the proposed OCR system have the following properties: autocorrelation, correlation, cluster prominence, contrast, dissimilarity, cluster shade, energy, homogeneity, entropy and maximum probability. The representation of feature extracted by adapting the above criteria over the co-occurrence matrix is given by
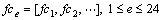 (8)
(8)
4.2.4 Concatenation of feature space
Finally, the feature spaces that are generated using HOGG, grid format level and GLCM are concatenated to create a single feature vector. The resulting concatenated feature vector contains the information regarding position, structure, texture, statistical and local. This information contained in the feature vector improves the recognition procedure by reducing the complexity in computation. This tends to increase the accuracy in the recognition rate obtained using the proposed OCR system. The concatenated feature vector obtained using the features fhc, fgd and fhe is given below:
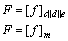 (9)
(9)
where the value of m, which is the total number of features obtained for a single character image is determined as, m=152, i.e. 128 histogram and grid level features and 24 GLCM features. The total features vectors extracted for n input images for the character recognition is given by
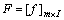 (10)
(10)
where I is the total number of images accepted for the character recognition.
4.3 Hybrid classifier
The proposed hybrid classifier approach is illustrated in this section. The features that are extracted using the extraction procedures described in section 4.2 are applied into the hybrid classifier. The hybrid classifier involves three classification modules, namely, DNN classifier, HDT classifier and probabilistic model based classifier. The classes generated from the DNN and the HDT classifiers are used for probabilistic modelling that computes the maximum posterior probability value resembling the character image sequence and thus, the optical character in the image is recognized.
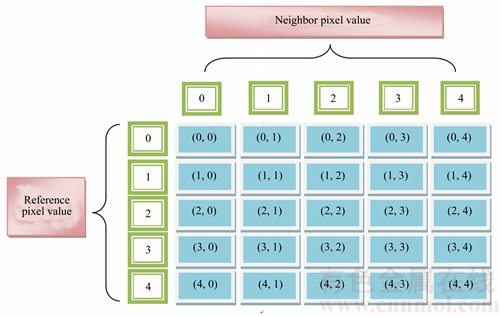
Fig. 4 Formation of GLCM matrix
4.3.1 Deep neural network classifier
This section presents the classifier used for the recognition in the proposed hybrid classifier, which is DNN. The concatenated feature vectors are applied as input to the DNN classifier. The concatenated feature vector consists of three extracted features, histogram, grid and GLCM features. DNN classifies the input depending on the training and the testing phases into separate classes. The classes considered here for the proposed system are 26 upper case letters (A�CZ), 26 lower case letters (a�Cz) and 10 numbers (0�C9). Totally, 62 classes are to be formed for the incoming image features.
The DNN [29, 30] is a feed-forward network comprised of input layer, output layer and more than one hidden layer between the input and the output layer. In the beginning, the input and the output requirements of the network are initialized in random. F is the input feature vector that consists of positional, structural, local, and statistical information of the character image, which is applied to the input layer of the DNN classifier. The network neurons accept the input, and the weights that are randomly generated. Based on the input accepted by the neurons in the network and the weight, it generates a new weight. The neurons with the updated weight and the feature vector perform the classification. In the neural network, the weight update is the critical task as it is used for the further iterations. The algorithm that is used for learning in DNN is restricted Boltzmann machine (RBM) [31] that does the selection of weight coefficients and update in the network at all the layers at a time. The DNN architecture using RBM algorithm is shown in Fig. 5.
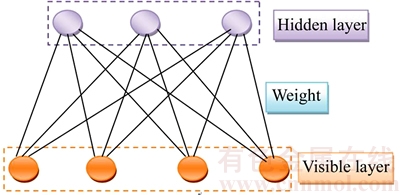
Fig. 5 Architecture of RBM learning algorithm
The steps involved in DNN classifier using RBM learning algorithm for the weight update are given below.
1) For each hidden layer, a logistic function is used to map the input layer to the scalar states and then to the other layers;
2) The learning procedure computes an energy function between the visible layer and the hidden layer;
3) Based on the energy formulated, the network assigns a probability value to all the visible and the hidden layer pairs;
4) The log probability derivative of a training set generates the weight update equation, based on which the states of both the visible and the hidden layers are updated;
5) The states of both the layers are set to 1 based on a probability, during the absence of direct connections between the hidden layers and between the visible units;
6) The weight update is then done based on the reconstructed units formed in step 5.
The process is repeated until multiple trained RBM layers are produced. Using DNN classifier, the feature vectors in the input character image are classified into one of the 62 classes.
For the input feature vector F=[F]m��I, the classification output obtained using DNN classifier is given by
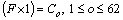 (11)
(11)
where Co is the class formed by the DNN classifier. Each feature vector of the image that arrives at the network input layer is comprised of the matrix having the vector space values and are classified into the classes according to the characteristics of the feature space. Thus, it forms the mutually exclusive class labels.
4.3.2 Holoentropy based decision tree classifier
HDT classifier adopted in the proposed hybrid classifier for the recognition is explained in this section. The feature vectors comprised of the attribute vectors are to be mapped into the classes according to known and unknown instances. The decision tree classifier is one of the mapping techniques with tree structure used for the classification [32]. The four main steps involved in the classifier are: feature selection, splitting, stopping and labeling. For feature selection, holoentropy, which is a method combining entropy and total correlation, is used. In HDT, the root node is generated first and the branch is formed by including the attributes that are selected using holoentropy. After selecting the best feature, using holoentropy information gain, the feasible solution is found.
The holoentropy for each feature attribute is evaluated as
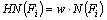 (12)
(12)
where Fi represents the ith attribute; w is the weight function; and N(Fi) is the entropy. The weight function is then given by
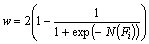 (13)
(13)
The entropy function is given regarding the probability based on the unique values in attributes as
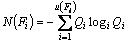 (14)
(14)
where Qi is the probability and u(Fi) is the total number of unique values in the attribute vector.
The input data are then split into two samples using a splitting rule that uses the information obtained u(Fi) to compute the information gain as
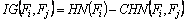 (15)
(15)
where CHN(Fi, Fj) is the conditional holoentropy, which is given by
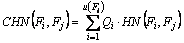 (16)
(16)
Holoentropy for two feature attributes is then calculated using the following equation:
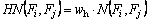 (17)
(17)
where the weight function and the entropy are given by
 (18)
(18)
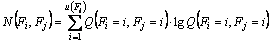 (19)
(19)
Based on this rule, the node is plotted repeating the splitting process until it reaches a stopping rule, which is given by a condition to stop when the label distribution for a node contains most of the information. The label is then determined by identifying the class that has maximum data satisfied.
For the feature vector F=[F]m��I that arrives to the network, HDT classifier classifies the input feature space of the character image into 62 classes as
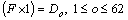 (20)
(20)
where Do is the class generated by the HDT classifier. Thus, the input images given are collected to form 62 classes based on the attribute vector values of the feature.
The pseudocode of the HDT classifier is presented as
HDT classifier
Input: Feature vector and label
Output: HDT
Start
Initialize the root node
If (sample_no=1 or samples from same class)
Stop branch formation
Else
Find HN(Fi) for each attribute Fi
End
Find the best feature and split the vector to find the best feature
Split the samples into two subsets based on the class C
Evaluate IG(Fi, Fj)
Select the best feature and the splitting point
Stop when the stopping condition is reached
Terminate
4.3.3 Probabilistic model based classifier
This section illustrates the probabilistic model classifier constructed based on the labelled class of DNN and HDT classifier.
The proposed hybrid classifier uses the probabilistic model for the character recognition. The classes generated are concatenated into a single image. The probabilistic model is computed based on the mean and the variance of the classes generated. The mean and the variance for all the 124 classes, i.e. 62 classes of DNN and 62 classes of HDT, are computed. Using the mean and the variance computed, the exterior probability value of the input image is obtained. The exterior probabilities of the classes related to the DNN and the HDT classifiers are found separately. The probabilities of DNN and HDT computed are multiplied to compute a new probability value. The character recognition of the image is done accurately depending on the maximum value of the new posterior probability.
For the character recognition, the probabilistic model derived is given as follows.
The class label from the DNN classifier is Co and Do is that obtained from the HDT classifier. In the probabilistic model, this is represented as
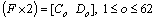 (21)
(21)
Then, the mean and the variance associated with both the classifiers in the probabilistic modelling is computed as
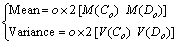 (22)
(22)
where M() represents the mean and V() represents the variance. o��2 indicates the 124 mean values computed, 62 of which refer to the mean values of the DNN classifier labels and the other 62 are those of the HDT classifier labels. In a similar way, the variance associated with label values of the classifiers is calculated.
The exterior posterior probability of the DNN classifier is given by
 (23)
(23)
where M(Co) represents the mean of the DNN class label and V(Co) represents the variance of the DNN class label. Similarly, for HDT, the posterior probability is
 (24)
(24)
where M(Do) and V(Do) represent the mean and the variance of the HDT class label. Then, the maximum posterior probability is computed based on the product of the posterior probability of DNN and HDT classifiers as

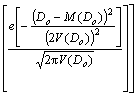 (25)
(25)
where M(Co) and V(Co) represent the mean and the variance of DNN and HDT class labels, while, M(Do) and V(Do) represent those of DNN and HDT class labels. The input character image with the maximum value is recognized using the probability model given by
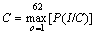 (26)
(26)
According to the maximum value of the posterior probability, the character recognition is performed over the character image. The probabilistic model based posterior probability value is measured for the input character image. The character image having the maximum probability value in the class will be recognized. In each class, the feature space of the image containing the maximum probability is recognized, which leads to more accurate recognition of the optical characters in the OCR systems.
4.4 Character recognition procedure using probabilistic model
The character recognition method based on the probabilistic model involved in the proposed hybrid classifier is explained in this section with a suitable pictorial representation in Fig. 6. First, the class labels from the HDT classifier and the DNN classifier are generated for the feature vectors of the input image. The probability model is then formulated from the estimated class labels for the character recognition. Then, the mean and the variance of the class labels regarding the DNN and the HDT classifiers are calculated. The total number of the mean and the variance estimated depends on the total number of classes formed. In the proposed OCR approach, 62 mean and variance values are calculated in both DNN and HDT classifiers separately. The posterior probability is then computed based on the mean and the variance of the classes. The posterior probability values of DNN and HDT obtained are concatenated into a single probability value and the maximum probability value decides the characters to be recognized from the input character image.
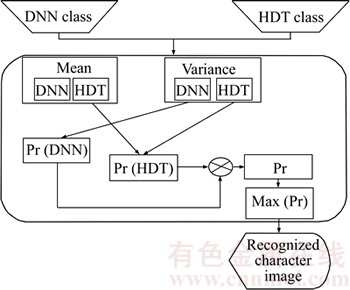
Fig. 6 Character recognition based on probability model classifier (Pr stands for posterior probability)
5 Results and discussion
In this section, the results of the proposed hybrid classifier that combines DNN and HDT classifiers for the character recognition are demonstrated.
The performance of the proposed probabilistic model based hybrid classifier is analyzed using the FAR, FRR and accuracy metrics and compared with the existing techniques.
5.1 Dataset description
The experimentation of the proposed OCR system is performed using the dataset Chars74K dataset [33]. The dataset consists of more than 74000 images. Chars74K datasets contain the symbols in the English and the Kannada language.The datasets considered for the experimentation and the analysis consist of the following.
1) 62 classes are comprised of 26 upper case letters, 26 lower case letters and 0�C9 numeric numbers.
2) Char74K having 7705 characters is taken from the natural images, 3410 handwritten characters and 62992 characters are obtained from computer fonts.
5.2 Experimental setup
The experimental setup for the implementation of the proposed optical recognition system includes a personal computer having the specifications as follows:
1) Intel i-3 core processor;
2) 2 GB RAM installed memory;
3) Windows 8 operating system.
The simulation software used for the experimentation of OCR is MATLAB (R2014a).
5.3 Evaluation metrics
The metrics considered for the validation of the performance of the proposed probabilistic model based hybrid classifier for the character recognition are defined in this section. Three evaluation metrics are used, namely, false acceptance rate (FAR), false rejection rate (FRR) and accuracy.
5.3.1 False acceptance rate
The total number of recognitions identified indelicately is known as FAR and given by
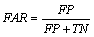 (27)
(27)
where FP represents incorrectly recognized character, i.e. false positive, and TN represents the characters that are correctly rejected.
5.3.2 False rejection rate
FRR refers to the number recognition of the characters that are indelicately rejected as
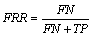 (28)
(28)
where FN is the incorrectly rejected recognition, i.e. false negative and TP is true positive that represents the correctly identified recognition.
5.3.3 Accuracy
Accuracy is the third evaluation metric used, which is comprised of FRR and FAR parameter and is defined as
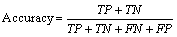 (29)
(29)
where TP represents true positive; TN represents true negative; FP represents false positive and FN represents false negative.
5.4 Sample database
The sample database considered for the proposed model for character recognition experimentation is depicted in this section. Figure 7 shows the sample database used for the proposed method of character recognition. As given in Fig. 7, upper case letter A is written in the first row. The structure of the individual A��s in the row is different, as it is written in different writing styles. During the training of the neural network with the upper case letter A, the testing of the sample data base letter A is recognized precisely using the proposed probabilistic model based classifier despite of the dissimilarities in the structure of the data given as input. Similarly, in the other rows, the upper case letters A, D, K, Y and Z, which are thought-ought to be as the sample data base are given in different writing styles for the recognition.
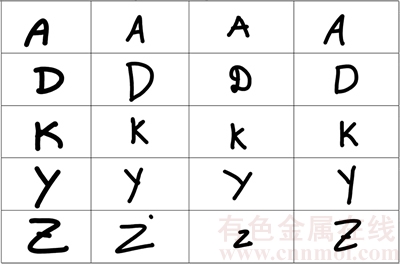
Fig. 7 Sample database
5.5 Comparative analysis
This section presents the comparative analysis of the proposed probabilistic model with the existing classifier system for the character recognition to evaluate the performance. The evaluation metrics used for the comparative analysis are FAR, FRR and accuracy. The existing systems used for the performance comparative analysis are hdes+lmnn, gdes+lmnn, hybrid+lmnn, hdes+flmn,gdes+flmn, and hybrid+flmn. hdes+lmnn is the classifier with HOG oriented feature and levenberg- macquardt (LM) training algorithm, gdes+lmnn is the classifier that uses grid level feature and LM training algorithm, hybrid +lmnn is the classifier with the hybrid features i.e. HOG, grid level and GLCM energy level features and LM algorithm, hdes+flmn is the classifier with HOG feature and firefly [34] LM (FLM) training algorithm, gdes+flmn is the classifier using FLM training algorithm with grid level feature and hybrid+flmnn represents the classifier that uses hybrid feature and FLM algorithm.
5.5.1 Analysis based on accuracy
The comparative analysis result based on accuracy to prove the efficiency of the proposed probabilistic model based hybrid classifier is given in Fig. 8.Figure 8(a) shows the accuracy analysis curve based on the number of hidden neurons varied from 20 to 60. Considering the number of hidden neurons, the maximum accuracy obtained by the proposed hybrid classifier is greater than 0.95038.But the existing systems cannot attain the accuracy greater than 0.95. For 50 hidden neurons, the accuracy achieved by the proposed approach is 0.95038, whereas the hdes+lmnn, gdes+lmnn, hybrid +lmnn, hdes+flmn, gdes+flmn, and hybrid+flmn, have the accuracy value of 0.95. In Fig. 8(b), the accuracy analysis curve is plotted based on the number of the hidden layers. When the number of hidden layer is 2, the accuracy attained by the proposed hybrid classifier is 0.9499, whereas the hdes+lmnn, gdes+lmnn, hybrid+lmnn, hdes+flmn and gdes+flmn, have the accuracy of 0.9244, 0.9404, 0.9293, 0.9143 and 0.9396, respectively. The accuracy when the number of hidden layer 5 for the proposed system is 0.95038, while all the comparative approaches have attained a value 0.95. For the hidden layers 4 and 5, the accuracy attained by the existing systems is 0.95 due to the concatenation of the hybrid feature used for the recognition. From the accuracy analysis curve, it is clear that the proposed system can provide the maximum accuracy of 95.038% for the character recognition.
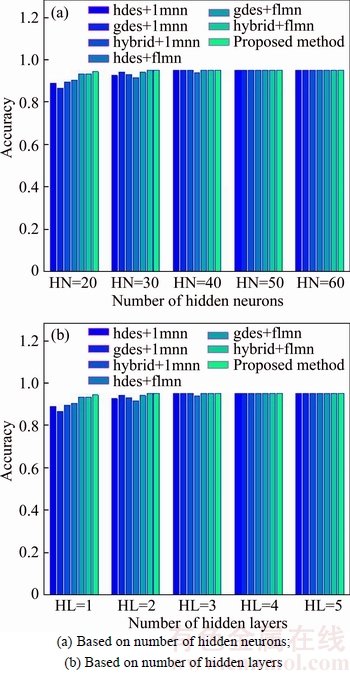
Fig. 8 Accuracy analysis curve:
5.5.2 Analysis based on false rejection rate
The analysis result obtained in all the comparative approaches based on FRR is demonstrated in Fig. 9. Usually, an effective classifier used for the character recognition must have minimal FRR for the optimal performance. The FRR analysis curves obtained based on the varying number of hidden neurons and the hidden layers are given in Figs. 9(a) and (b), respectively. In FRR analysis based on varied hidden neurons, the FRR attained by the existing techniques hdes+lmnn, gdes+lmnn, hybrid +lmnn, hdes+flmn, gdes+flmn and hybrid+flmn, for 20 hidden neurons are 0.1958, 0.2089, 0.1919, 0.1874, 0.1711 and 0.1711, respectively. The proposed hybrid system has the FRR of 0.16514, which shows that the proposed approach has comparatively lower FRR than the other comparative techniques. As the number of the hidden neurons increases, the value of the FRR decreases for the systems considered for the experimentation. However, among the techniques considered for the analysis by varying number of hidden neurons, the proposed system has shown the minimum FRR of 0.1342. The FRR analysis curve based varying number of hidden layers is pictured out in Fig. 9(b). The figure shows the accuracy obtained in the proposed as well as the existing techniques by varying the number of the hidden layers from 1 to 5. For the training done with 1 hidden layer, the FRR produced by the proposed system is 0.17954, while, the exiting hdes+lmnn, gdes+lmnn, hybrid +lmnn, hdes+flmn, gdes+flmn and hybrid+flmn, have the FRR value of 0.238, 0.2848, 0.2206, 0.255, 0.2541 and 0.1855, respectively. The minimum value of FRR obtained in the proposed approach is or the various hidden layer training, the minimal FRR of 0.13756 is achieved by the proposed system which is more effective for the significant performance of the proposed system. From the FRR analysis curve, it is clear that the proposed hybrid+hybrid classifier system results in the recognition with the reduced false rejection ratio.
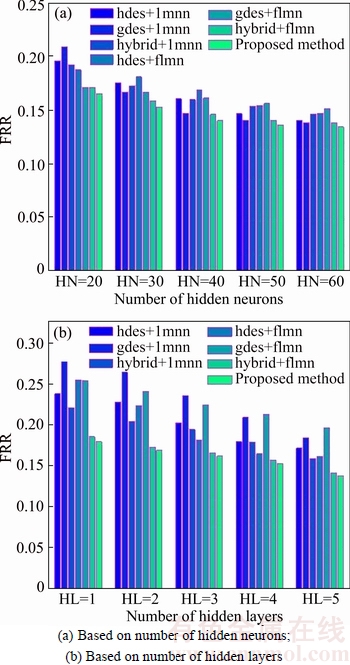
Fig. 9 FRR analysis curves:
5.5.3 Analysis based on false acceptance rate
The comparative analysis based on FAR in all the comparative techniques is shown in Fig. 10. The FAR analysis curve for varying number of the hidden neurons is presented in Fig. 10(a) and that for varying number of hidden layers is given in Fig. 10(b). The FAR of the reliable recognition system must be minimal to offer an improved performance. From Fig. 10(a), it is seen that the FAR of the proposed system is minimal compared to that of the existing techniques used for the recognition. For the training with 20 hidden neurons, the proposed method can attain the FAR of 0.16514. The existing systems had the FAR value that ranges from 0.1711 to 0.2089. The increase in the number of the neurons also has considerable effects on the FAR value. If the number of hidden neurons in the network increases, the FAR value is minimal. The FAR analysis curve based on varying number of hidden layers is presented in Fig. 10(b). For the network with 1 hidden layer, the proposed system reached the FAR value of 0.1795, whereas, hdes+lmnn, gdes+lmnn, hybrid+lmnn, hdes+ flmn, gdes+flmn and hybrid+flmn had attained the value 0.238, 0.2848, 0.2206, 0.255, 0.2541 and 0.1855, respectively. The FAR values are further reduced to 0.1715, 0.1842, 0.1589, 0.1613, 0.196 and 0.1416, in hdes+lmnn, gdes+lmnn, hybrid+lmnn, hdes+flmn, gdes+flmn and hybrid+flmn, for the number of hidden layers 5. However, the proposed approach has the minimal value of 0.13756, which shows that the proposed hybrid classifier has better performance than the existing techniques. From the FAR analysis curve, it is suggested that the proposed system provides the reliable recognition procedure for the recognition of optical character with minimal FAR value.
5.6 Comparative analysis by percentage of training data
In Fig. 11, the comparative performance analysis based on varying percentage of training data, denoted as k, is illustrated. The FAR performance analysis plot is given in Fig. 11(a) by varying the percentage of data from 50 to 90. For the percentage of training data 60, the existing hdes+lmnn achieves FAR of 0.2178, the gdes+lmnn obtains 0.2243, hybrid+lmnn has a value 0.2318, and a FAR value of 0.2342, 0.2353 and 0.2158 is produced by hdes+flmn, gdes+flmn and hybrid+flmn. Meanwhile, the proposed hybrid system attained FAR of 0.20984. When k=90, FAR value obtained in the proposed method is 0.13786, whereas the minimal FAR observed among the existing systems is in hybrid+flmn with value 0.1419. Compared to the existing algorithm, the proposed approach with hybrid feature can achieve a reduced FAR of 0.13786.
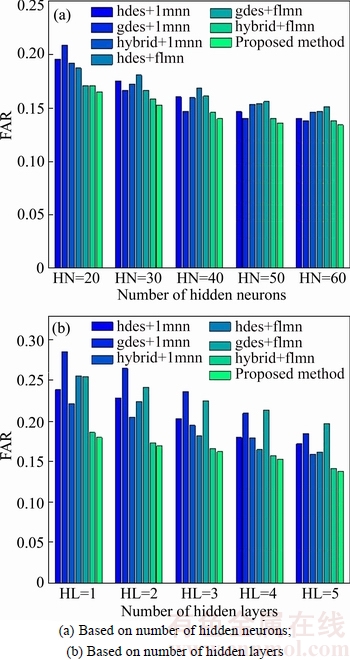
Fig. 10 FAR analysis curves:
Figure 11(b) demonstrates the FRR performance analysis in the techniques taken for the comparison. For 50% of training data, the existing technique hybrid+flmn has an FRR value of 0.2589, while the proposed classifier achieves FRR of 0.2529, which is then reduced gradually to 0.13786 for the percentage of training data samples 90. Consequently, Fig. 11(c) demonstrates the accuracy analysis chart by comparing the accuracy with the existing systems. The existing method hdes+lmnn acquires 0.7457 accuracy for 50% training data, whereas, gdes+lmnn, hybrid+lmnn and hybrid+flmn have 0.7597, 0.7668 and 0.774. With 90% training data, the proposed method attains the maximum accuracy of 0.96, while in the existing algorithms, the maximum accuracy obtained is 0.95. Hence, from the comparative analysis made with varied percentages of training data, the proposed method seems to have better character recognition performance.
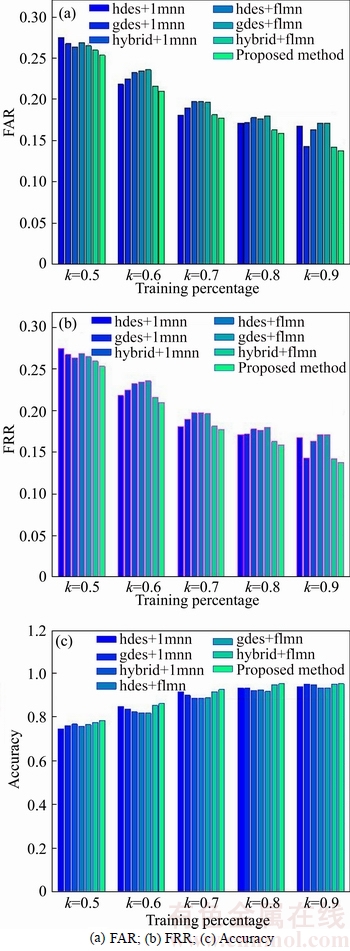
Fig. 11 Comparative analysis by percentage of training data:
5.6.1 Significance of features for classifier
In the character image, the feature represents the meaningful information that makes the classifier to be recognized easily. In this method, the features from the HOGG, grid level and GLCM, are extracted. The set of feature representation offers robustness against the computational complexity, as it has less training time of the data samples and improves the generalization by reducing the variance of the feature. The extracted features reduce the storage requirements, time required for training and utilization in the decision making module. Therefore, the classifier can perform the classification of character feature that provides better character recognition performance. From Fig. 11, it is seen that the hybrid features provide better performance than the individual features like, HOG, grid level and GLCM. Thus, it is proved that the hybrid features make the classifier in the training phase to provide faster convergence.
5.6.2 Hybrid classifier
The hybrid classifier is comprised of DNN and HDT classifiers. The deep neural network has the ability to determine all the possible interactions for the recognition of the characters in the character image. Thus, DNN detects the non-linear complexity so that it can attain better recognition performance. Then, the features that are recognized by the input database character images are classified. The feature in the HDT classifier is used to provide induction learning with improved performance. The major significance of HDT classifier is to achieve the interpretability. Moreover, it can detect the non-linear relationship or interactions and robustness against the outlier. The construction of the decision tree based on holoentropy helps in handling the high dimensional data. HDT can lessen the ambiguity that occurs during the process of decision making. Hence, the proposed hybrid classifier, with the advantageous HDT, achieves higher accuracy and thereby, better performance in recognizing characters. Therefore, from the comparative analysis, it can be concluded that the proposed hybrid classifier outperforms the existing classifiers.
6 Conclusions
This paper proposes a probabilistic model based hybrid classifier for the recognition of optical characters in the image. The proposed classifier model can successfully recognize the 62 characters, i.e. 26 upper case letters, 26 lower case letters and 0�C9 numeric numbers. Due to the inclusion of GLCM feature in addition to the local gradient features like HOGG and grid level feature, more statistical information about the input character image can be attained. Then, a probabilistic model is developed from the labelled classes of DNN and HDT classifiers. The probabilistic model formulation is based on the posterior probability value, for which the character with the maximum value is recognized among the input character images. The performance of the proposed approach is evaluated in a comparative analysis with existing recognition system like hdes+lmnn, gdes+lmnn, hybrid+lmnn, hdes+flmn, gdes+flmn, and hybrid+flmn, using three evaluation metrics, accuracy, FAR and FRR. The proposed optical character recognition system gives excellent result with accuracy of 95% for the numeric digits and letters recognition system.
References
[1] PRADEEP J, SRINIVASAN E, HIMAVATHI S. Neural network based handwritten character recognition system without feature extraction [C]// Proceedings of International Conference on Computer, Communication, and Electrical Technology. 2011: 40�C44.
[2] VAMVAKAS G, GATOS B, PERANTONIS S J. Handwritten character recognition through two-stage foreground sub-sampling [J]. Pattern Recognition, 2010, 43: 2807�C2816.
[3] PAUPLIN O, JIANG Jian-min. DBN-based structural learning and optimisation for automated handwritten character recognition [J]. Pattern Recognition Letters, 2012, 33: 685�C692.
[4] KADER M, DEB K. Neural-network based english alphanumeric character recognition [J]. Computer Science, Engineering and Applications, 2012, 2(4): 1�C10.
[5] MOHANAIAH P, SATHYANARAYANA P, GURUKUMAR L. Image texture feature extraction using GLCM approach [J]. Scientific and Research Publications, 2013, 3(5): 1�C5.
[6] PRASAD K, AGRAWAL S. Character recognition using neural networks [C]// International Conference on Research and development in Computer Science and Applications, 2015: 90�C92.
[7] PILLAI C S. A survey of shape descriptors for digital image processing [J]. Computer Science and Information technology & Security. 2013, 3(1): 44�C45.
[8] ZHANG Yu-dong, WANG Shui-hua, DONG Zheng-chao. Classification of alzheimer disease based on structural magnetic resonance imaging by kernel support vector machine decision tree [J]. Progress in Electromagnetics Research, 2014, 144: 171�C184.
[9] van GRINSVEN M J J P, van GINNEKEN B, HOYNG C B, THEELEN T, S NCHEZ C I. Fast convolutional neural network training using selective data sampling: Application to hemorrhage detection in color fundus images [J]. IEEE Transactions on Medical Imaging, 2016, 35(5): 1273�C1284.
NCHEZ C I. Fast convolutional neural network training using selective data sampling: Application to hemorrhage detection in color fundus images [J]. IEEE Transactions on Medical Imaging, 2016, 35(5): 1273�C1284.
[10] SAMADIANI N, HASSANPOUR H. A neural network-based approach for recognizing multi-font printed English characters [J]. Electrical Science and Information Technology, 2015, 2: 207�C218.
[11] YANG Yang, XU Li-jia, CHENG Chen. English character recognition based on feature combination [C]// Advances in Engineering, 2011: 159�C164.
[12] PIRLO G. Adaptive membership functions for handwritten character recognition by voronoi-based image zoning [J]. Image Processing, 2012, 21(9): 3827�C3837.
[13] JAMEEL A, KOUTSOUGERAS C. On features used for handwritten character recognition in a neural network environment [C]// International Conference on Tools with Artificail Intelligence, 1993: 280�C284.
[14] SURINTA O, KARAABA M, SCHOMAKER L B, MARCO A W. Recognition of handwritten characters using local gradient feature descriptors [J]. Engineering Applications of Artificial intelligence, 2015, 45: 405�C414.
[15] FUKUSHIMA K. Character recognition with neural networks [J]. Neuro Computing, 1992, 4(5): 221�C233.
[16] CHOUDHARYA A, RISHI R, AHLAWAT S. Off-line handwritten character recognition using features extracted from binarization technique [C]// International Conference on Intelligent Systems and Control, 2013: 306�C312.
[17] AVI-ITZHAK H I, THANH A. Diep, and harry garland, high accuracy optical character recognition using neural networks with centroid dithering [J]. Pattern Analysis and Machine Intelligence, 1995, 17(2): 218�C224.
[18] SZIRHNYI T, CSICSVARI J. High-speed character recognition using a dual cellular neural network architecture (CNN) [J]. Circuits and Systems-II: Analog and Digital Signal Processing, 1993, 40(3): 223�C231.
[19] GU Y X, WANG Q R, SUEN C Y. Application of a multilayer decision tree in computer recognition of Chinese characters [J]. Pattern Analysis and Machine Intelligence, 1983, 5(1): 83�C89.
[20] SURINTA O, SCHOMAKER L R B, WIERING M A. Handwritten character classification using the hotspot feature extraction technique [C]// Proceedings of First International Conference on Pattern Recognition Applications and Methods (ICPRAM). 2012: 261�C264.
[21] SU B, DING X. Linear sequence discriminant analysis: A modelbased dimensionality reduction method for vector sequences [C]// Proceedings of IEEE International Conference on Computer Vision (ICCV). 2013: 889�C896.
[22] KAMBLE P M, HEGADI R S. Handwritten marathi character recognition using R-HOG feature [J]. Computer Science, 2015, 45: 266�C274.
[23] NIBARAN D, RAM S, SUBHADIP B, SAHA P, MAHANTAPAS K, MITA N. Handwritten bangla character recognition using a soft computing paradigm embedded in two pass approach [J]. Pattern Recognition, 2015, 48(6): 2054�C2071.
[24] ZAHID H M, ASHRAFUL A M, YAN Hong. Rapid feature extraction for optical character recognition [J]. Computer Vision and Pattern Recognition. 2012: 1�C5.
[25] ZHANG B, ZHANG S, ZHANG J, JING X. A method region of interest extraction based on orientation entropy [C]// Proceedings of International Conference on Broadband Network and Multimedia Technology. 2011: 664�C669.
[26] DALAI N, TRIGGS B. Histograms of oriented gradients for human detection [C]// Proceedings of International Conference on Computer Vision and Pattern Recognition. 2005: 886�C893.
[27] BANERJI S, SINHA A, LIU Cheng-jun. New image descriptors based on color, texture, shape and wavelets for object and scene image classification [J]. NeuroComputing, 2013, 117: 173�C185.
[28] TIAN Shang-xuan, BHATTACHARYA U, LU Shi-jian, SU Bo-lan, WANG Qing-qing, WEI Xiao-hua, LU Yue, CHEW Lim-tan. Multilingual scene character recognition with co-occurrence of histogram of oriented gradients [J]. Pattern Recognition, 2016, 51: 125�C134.
[29] CHEN Y, LIN Z, ZHAO X, WANG G, GU Y. Deep learning-based classification of hyperspectral data [J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2014, 7(6): 2094�C2107.
[30] HINTON G, LIDeng,DONGYu,DAHL G E, MOHAMED A R, JAITLY N,SENIOR A, VANHOUCKE V,NGUYEN P, SAINATH T N,KINGSBURY B. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups [J]. IEEE Signal Processing Magazine, 2012, 29(6): 82�C97.
[31] PALM R B. Prediction as a candidate for learning deep hierarchical models of data [D]. Technical University of Denmark, 2012.
[32] MANE V M, JADHAV D V. Holoentropy enabled-decision tree for automatic classification of diabetic retinopathy using retinal fundus images [J]. Biomedical Engineering/Biomedizinische Technik, 2016, 62: 321�C332.
[33] de Campos T E. The Chars74K dataset: Character recognition in natural images[EB/OL]. [2012]. http://www.ee.surrey.ac.uk/CVSSP/ demos/chars74k/.
[34] SENTHILNATH J, OMKAR S N, MANI V. Clustering using firefly algorithm: Performance study [J]. Swarm and Evolutionary Computation, 2011, 1: 164�C171.
(Edited by FANG Jing-hua)
Cite this article as: A.K.Sampath, Dr.N.Gomathi. Decision tree and deep learning based probabilistic model for character recognition [J]. Journal of Central South University, 2017, 24(11): 2862�C2876. DOI: https://doi.org/10.1007/ s11771-017-3701-8.
Received date: 2016-05-30; Accepted date: 2017-03-13
Corresponding author: A. K. Sampath, Assistant Professor; E-mail: sampath.ak127@gmail.com

