基于支持向量机的脂肪酶耐热序列与嗜热序列分类研究
赵伟,许尤厚,郑甲,王玉光,周洪波
(中南大学 资源加工与生物工程学院,湖南 长沙,410083)
摘要:从GenBank数据库中获取了微生物来源的嗜热脂肪酶序列77条,耐热脂肪酶序列65条,分别统计分析序列中20种氨基酸出现的频次,二肽片段、三肽片段出现的差异以及非相邻二元组合的偏爱性。在此基础上,利用支持向量机(SVM)进行序列分类研究。研究结果表明:在统计学意义上,20种天然氨基酸残基中,亮氨酸、脯氨酸、蛋氨酸、苯丙氨酸、色氨酸和酪氨酸在嗜热蛋白序列中出现的频率高于其在耐热蛋白中出现的频率;二肽片段KC,EE,KE,RE, VE, YI, EK, VK, EV, YV, EY, KY, VY 和 YY的出现频率在嗜热蛋白中显著高于其在耐热蛋白中出现的频率。三肽片段的出现频率和非相邻二元组合的序列偏爱性也显示与蛋白耐热性显著相关。训练集的分类准确率达99.65%,真实数据集的分类准确率达到98.41%。
关键词:氨基酸组成;多肽片段;非相邻二元组合;蛋白质热稳定性;支持向量机
中图分类号:Q816 文献标志码:A 文章编号:1672-7207(2011)09-2543-08
Classification of thermostable and thermophilic lipases using support vector machines
ZHAO Wei, XU You-hou, ZHENG Jia, WANG Yu-gang, ZHOU Hong-bo
(School of Minerals Processing and Bioengineering, Central South University, Changsha 410083, China)
Abstract: The amino acid compositions, the distributions of N(N=2, 3) neighboring amino acids and the non-adjacent di-residue coupling patterns in the sequences of 65 thermostable and 77 thermophilic lipases getting from GenBank were systematically analyzed. Based on the information, a statistical method based on support vector machines (SVMs) for discriminating thermophilic and thermostable lipases was developed. The results show that hydrophobic residues Leu, Pro, Met, Phe, Trp, as well as the polar residue Tyr have higher occurrences in thermophilic lipases than thermostable ones. The occurrences of KC, EE, KE, RE, VE, YI, EK, VK, EV, YV, EY, KY, VY and YY in thermophilic proteins are significantly more frequent. The composition of dipeptide, tripeptide and non-adjacent di-residue patterns contain more information than amino acid composition, and this information indicates the possible thermostable mechanism of microbial lipases. The accuracy of this method for the training dataset is 99.65%, and its accuracy for testing datasets is 98.41%.
Key words: amino acid composition; n-peptide composition; di-residue coupling; protein stability; support vector machines
脂肪酶(lipase,E.C.3.1.1.3)即三酰基甘油水解酶(triacylglycerol acylhydrolase)是一类能在油水界面上水解甘油三酯的酶,它的底物三脂酰甘油的醇部分是丙三醇,酸部分则为水不溶的十二碳以上的长链饱和或不饱和脂肪酸。水解反应发生在三脂酰甘油的酯键上。在丝氨酸水解酶家族中,脂肪酶与酯酶、胆碱酯酶属于进化相关的同一家族成员,这一家族涉及真核、原核和古细菌三大领域。由于脂肪酶来源广泛,其蛋白序列总体的同源性不高,序列平均相似度低于30%,但它们在底物结合催化部位的氨基酸序列均含有一小段保守序列,即以丝氨酸残基为中心,周围有组氨酸和精氨酸/谷氨酸组成电子传递链的催化系统[1]。微生物脂肪酶最适pH多数在中性范围内,最适pH范围与微生物种属间的关联并不明显。与真菌脂肪酶的理化性质相比,细菌脂肪酶的耐热性较高,而嗜热脂肪酶序列几乎都集中于古细菌脂肪酶中[2-3]。在水溶液中,大多数脂肪酶的最适作用温度为25~35 ℃,而在有机相中,脂肪酶作用温度可拓宽至0~100 ℃。脂肪酶是一种目前在工业生产中应用最为广泛的微生物酶之一,应用领域涉及食品工业、化妆品行业、医药行业、造纸工业和生物能源行业。由于工业应用范围的拓展,极端工业条件下(如高温,极端酸碱)酶的稳定性研究得到了高度重视。而获得这些酶的途径大多局限于极端微生物的分离培养,当前,人们对Thermus,Clostridium,Bacillus, Pyrococcus, Pyrodictium,Methanopyrus,Thermococcu等嗜热菌研究较多[4-5],在它们中间已经成功分离获得了一系列具有广阔工业应用前景的耐高温酶,如超嗜热脂肪酶、pfu DNA聚合酶。但由于多数嗜热菌的培养条件严格、生长缓慢、酶产量低,直接培养野生菌分离获得嗜热酶相当困难,制约了性质优良工业用酶的大规模开发与应用。随着基因工程技术的进步,基因组重组和蛋白质改造又为嗜热酶的获得提供了一条新的途径[6],特别在面对目前尚不可培养的极端微生物情况下,这种不依赖宿主生理生化特性的手段,显示了强大的应用潜力。本文作者从脂肪酶蛋白序列角度出发,分析了多种序列组合特征及其与蛋白性质的联系,从中发现了脂肪酶序列中与耐热性相关的序列结构特征。并在此基础上建立了统计学分类筛选器,能够有效地识别筛选具有不同耐热性质的微生物脂肪酶序列,为新型脂肪酶的构建提供了有意义的信息参考,指明了可能的改造方向,提供了有效的序列识别筛分工具。
1 材料和方法
1.1 数据集
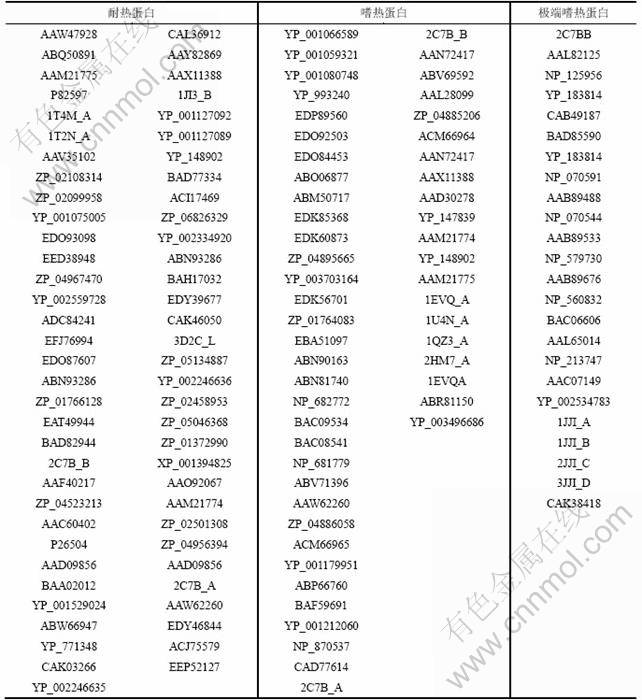
本文的研究对象是微生物脂肪酶,相关的脂肪酶蛋白一级序列来源于美国国立生物技术信息中心(NCBI)的蛋白质序列数据库(Protein Database),三级结构数据来源于PDB数据库。获取的蛋白序列数据分为普通耐热性脂肪酶蛋白、嗜热性脂肪酶蛋白和超级嗜热性脂肪酶蛋白3类。所获取的序列信息如表1所示。
1.2 氨基酸残基出现频率的计算
序列中20种氨基酸残基的出现频率计算公式[7]如下:
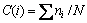 (1)
(1)
式中:i 代表 20种氨基酸残基序号;ni为相对应残基出现的次数;N为20种残基出现的总数。
1.3 二肽片段出现频率的计算
序列中400种二肽片段的出现频率计算公式[8-10]如下:
 , n=1, 2, …, 400 (2)
, n=1, 2, …, 400 (2)
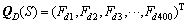 (3)
(3)
式中:i和j分别代表在A位点和A+1位点的20种氨基酸残基中的序号;Nij为i残基后紧接着出现j残基的次数;L-1为在长度为L的序列中可能会出现的二肽片段总数。
1.4 三肽片段出现频率的计算
序列中8 000种三肽片段的出现频率计算公式如下:
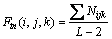 ; n=1, 2, …, 8 000 (4)
; n=1, 2, …, 8 000 (4)
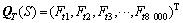 (5)
(5)
式中:i,j与k分别代表在A位点,A+1位点和A+2位点的20种氨基酸残基中的序号;Nijk是i残基后紧接着出现j残基和k残基的次数;L-2则是在长度为L的序列中可能会出现的三肽片段总数。
1.5 非相邻二元组合出现频率的计算
序列中400×Interval(IN)种二肽片段的出现频率计算公式如下:
 ; IN=1, 2, …, 100 (6)
; IN=1, 2, …, 100 (6)
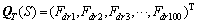 (7)
(7)
式中:i和j分别代表在A位点和A+IN位点的20种氨基酸残基中的序号;Nijint是i残基后插入IN个残基再出现j残基的次数;400×IN则是可能出现的非相邻二元组合总数。
1.6 模型建立与筛分器构建
研究所用支持向量机软件是libSVM,可通过http://www.csie.ntu.edu.tw/~cjlin/libsvm/免费获取使 用[11]。测试过程中进行了20轮交互验证(cross-validation),并分别计算了分类准确度、灵敏度和特异性3个参数。此3个参数的计算公式如下:
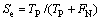 (8)
(8)
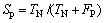 (9)
(9)
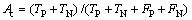 (10)
(10)
式中:Se为灵敏度;Sp为特异性;Ac为准确度;TP为正确判断嗜热脂肪酶序列的个数;TN为将耐热脂肪酶序列错误判断为嗜热脂肪酶序列的个数;FP为正确判断耐热脂肪酶序列的个数;FN为将嗜热脂肪酶序列错误判断为耐热脂肪酶序列的个数。
表1 微生物脂肪酶序列信息
Table 1 Accession number of microbial lipase sequences
2 结果与分析
2.1 氨基酸残基个数与耐热性的关系
结果显示,按照耐热性质分组统计,耐热脂肪酶、嗜热脂肪酶和超级嗜热脂肪酶的序列长度分布各有所不同。耐热脂肪酶在序列长度大于400残基区段的比例最大,嗜热脂肪酶在序列长度为300至400残基区段的比例最大,而超级嗜热脂肪酶则在200至400的区段平衡分布,如图1所示。统计结果显示从耐热酶到嗜热酶,明显的序列长度减小,而比较嗜热酶和超级嗜热酶的序列长度情况却不存在显著差异。但序列长度数据的标准差显示3种不同耐热性质脂肪酶序列的长短分散度不同,嗜热脂肪酶序列长度最集中,而耐热脂肪酶序列长度最分散。

图1 脂肪酶序列长度分布
Fig.1 Sequence length distribution and composition statistical analysis of lipases
为了消除天然背景中不同氨基酸使用频率差异带来的影响,需要建立天然蛋白序列氨基酸残基使用频率本底库。从Swiss-port数据库中统计获得了天然状态下原核生物蛋白质氨基酸残基的出现频数(图2),作为背景参考。
统计分析显示存在着和耐热性正相关或负相关的氨基酸。其中,对于酸性和碱性氨基酸,组氨酸、精氨酸、赖氨酸、天冬氨酸和谷氨酸的含量都呈现出与蛋白耐热性正相关的关系;半胱氨酸也存在着正相关的联系。丝氨酸、异亮氨酸和亮氨酸的含量也与耐热性正相关。而呈现负相关关系的氨基酸主要有疏水性氨基酸丙氨酸、脯氨酸、苯丙氨酸、色氨酸以及不带电荷的极性氨基酸天冬酰胺、谷氨酰胺、酪氨酸和甘氨酸。在这些氨基酸残基中天冬酰胺残基的出现频率显得较为特殊,一方面,耐热蛋白和嗜热蛋白序列中天冬酰胺出现频率明显高于Swiss-Port数据库中可获得的所有蛋白序列平均天冬酰胺残基出现频率,表明天冬酰胺残基具有一定的耐热性质偏爱;另一方面,天冬酰胺残基出现频率在嗜热蛋白与耐热蛋白中的差异趋势不统一,耐热脂肪酶和嗜热脂肪酶都有含天冬酰胺残基较多的序列,天冬酰胺残基对脂肪酶耐热性提高的作用又显得不明确。其实,这样的结果在Yamamoto等[12-13]的研究中也曾有报道,Yamamoto等[12]发现在磷酸化酶序列中用天冬酰胺替换天冬氨酸,可使得该酶的热稳定温度由60.0 ℃提升至67.5 ℃;而Rollence等[14]则发现某一嗜热蛋白与其常温对应蛋白相比,仅置换了1个氨基酸残基,即天冬酰胺残基被异亮氨酸替换,就大幅度提高了该蛋白的热稳定性。Rollence等[14]认为是天冬酰胺残基在高温下易于发生脱氨基反应,使得蛋白质结构失稳。
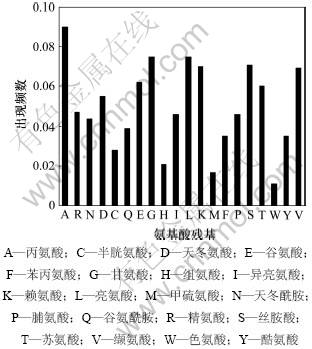
图2 Swiss-Port数据库中原核生物蛋白质20种氨基酸分布频率
Fig.2 Distribution of prokaryotic amino acid composition in Swiss-port database
2.2 寡肽片段组成与耐热性的关系
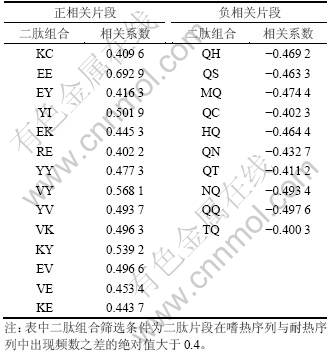
嗜热蛋白序列中共有19个与其蛋白性质可能存在正相关性的二肽片段,有6个与其蛋白性质可能存在负相关性的二肽片段;耐热蛋白序列中共有31个与其蛋白性质可能存在正相关性的二肽片段,有16个与其蛋白性质可能存在负相关性的二肽片段。
呈现序列特征与蛋白耐热性特征正相关的二肽片段有KC,EE,KE,RE,VE,YI,EK,VK,EV,YV,EY,KY,VY和YY;而呈现负相关关系的二肽片段有QC,QH,QN,HQ,MQ,NQ,QQ,TQ,QS和QT(表2)。从二肽片段组成情况可以推断出赖氨酸、谷氨酸、酪氨酸、缬氨酸和精氨酸含量与蛋白质耐热性呈正相关关系,而谷氨酰胺、组氨酸、天冬酰胺、蛋氨酸、苏氨酸的含量与蛋白质耐热性呈负相关关系,这一结论和氨基酸组成分析结果一致。Chapelle等[15]认为Cation-π效应可以稳定蛋白质,其主要原因是KY与YK的作用,同时研究发现KY,EI和VY在耐热蛋白质中具有显著的残基内相互作用。这部分结果与本研究结果相符合。
呈现正相关的二肽片段组合体现出带电氨基酸残基组合的特点,同时芳香族氨基酸也占有一定优势;呈现负相关的二肽片段组合则全部为谷氨酰胺与其他酰胺残基或组氨酸残基的组合,从总体上看,呈现出酰胺残基与耐热性负相关强烈相关,这点与酰胺残基高温下易脱氨而变得不稳定密切相关。
表2 脂肪酶序列中与蛋白耐热性显著相关的二肽片段
Table 2 Positive and negative correlative characteristic dipeptides of thermostable character from mesophilic to thermophilic proteins
2.3 三肽片段组成与耐热性的关系
为了进一步挖掘蛋白序列编码信息与耐热特性之间的关联性,在二肽片段组成分析的基础上进一步开展了三肽片段组成研究。三肽组成由于片段长度的增加而导致了位点残基确定性的增加,进而使得序列编码信息的含量增加。在蛋白质性质功能由编码复杂度和编码量共同决定的假设前提下,三肽组成研究将能够比二肽组成研究更精确的揭示系列特征和性质特征之间的关联。与二肽片段分析类似,分析计算了标准化的8 000个三肽片段组合频率,显著性三肽片段和耐热相关特征三肽片段。这里仅列出了与耐热相关的统计显著特征三肽片段,如表3所示。
与蛋白耐热性正相关的三肽片段主要以正相关二肽片段的组成残基为基本组合单元,但在最显著的片段中新出现了脯氨酸(P)残基、半胱氨酸(C)残基,含有脯氨酸残基或半胱氨酸残基的片段占正相关片段18.5%,且这2种残基总是同时出现在相同组合中,除此以外,还有精氨酸(R)残基也是首次出现在显著性片段中,含有精氨酸的片段占正相关片段11.1%。结果表明除了K,E,V和Y的残基组合外,C-P组合在三肽片段中也是一种与蛋白耐热性正相关的典型组合形式。
表3 脂肪酶序列中与蛋白耐热性显著相关的三肽片段
Table 3 Most significant positive correlated and negative correlated tripeptides in thermophilic proteins
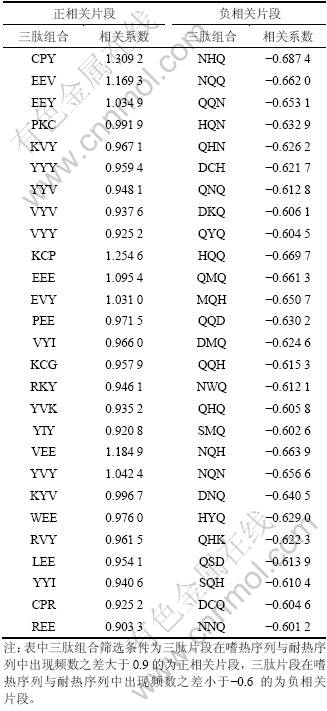
而与蛋白耐热性呈负相关的高显著性三肽片段依旧全部都是谷氨酰胺(Q)残基组合,但与二肽片段有所不同的是:Q片段三肽组合的方向性明显增强,同时与谷氨酰胺残基配对的残基也发生了微小变化,例如苏氨酸(T)残基不再出现于三肽片段中,而天冬氨酸(D)残基则出现在三肽片段中,含有天冬氨酸残基的三肽片段占最显著负相关三肽片段 22.2%。
表3的结果显示了序列编码的偏好性对蛋白序列性质的影响。在高维片段组合中,偏爱性即代表了序列编码随机性的降低和信息含量的增加,显示了三肽片段组成分析对蛋白序列信息提取的有效性。蛋白质序列相邻残基组合的研究结果显示:无论是二肽片段组合还是三肽片段组合,带电性残基组合为耐热性序列优势特征,而谷氨酰胺(Q) 残基的存在是蛋白质热稳定性减弱的最主要原因。但其也显示出带电氨基酸残基在一级序列中所处位置对序列耐热性的重要影响,如二肽片段EV和VE(表2)具有不同不同程度的正相关性,K 在三肽片段 KCP,KYV,KVY等中显示了显著的热稳定正相关性,而在QHK和DKQ中则显示了显著的热稳定负相关性(表3)。
2.4 非相邻二元组合与耐热性的关系
寡肽片段揭示了相邻氨基酸残基片段组合的偏爱性,显示了序列中局部区域的特性。寡肽片段的偏爱增加了序列编码信息量,增加了蛋白质性质、功能扩展的潜能。但若将蛋白质一级序列简化为20个字符的编码字符串,则容易看出:对于增加字符串信息载 量[16-17],最容易的方式是确定位点中字符类型或缩小字符变化范围,这样的形式能够以相邻或相间2种情况存在。既然寡肽片段所代表的相邻情况已显示序列编码偏爱性与性质存在关联关系,则可推断:相间模式或者相邻-相间混合模式也存在着类似关系[18-19]。以下即是从此推断研究相间情况的结果。由于相间情况变化复杂而导致计算量大幅增加,如进行一次二肽片段(相邻)组合分析的计算量为20(即20种氨基酸残基个数)×20(即20种氨基酸残基个数)×N(即样本中序列数目),进行1次二元模式(相间)组合分析所需的计算量为20(即20种氨基酸残基个数)×20(即20种氨基酸残基个数)×Step(即相间步长,本研究中步长变化范围为1~100个氨基酸残基)×N(即样本中序列数目,本研究中N=20 000)。可见:进行一次二元模式分析在同样计算能力下所需的时间是进行一次二肽片段组合分析的Step(本研究中即为100)倍。所以,在目前可以获得的计算能力下,只进行了二元模式组成的分析。
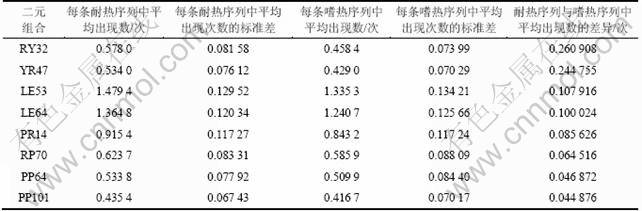
为了提取显著性高的序列特征,减少后续分类工作的难度,在分析了氨基酸组成、二肽片段、三肽片段和二元模式之间的关系后发现它们之间存在互相关联或者部分包含的关系。因此,为提取序列分类特征筛选了8个差异性最显著的二元模式,分别为PR14,RY32,YR47,LE53,LE64,PP64,RP70和PP101。以上8个差异性最显著的二元模式组成在嗜热蛋白和耐热蛋白序列(各10组,每组20 000条,共200 000条)中的统计数据显示8种模式在嗜热蛋白中比在常温蛋白中出现频率要高,且分布更趋均匀(表 4)。非相邻的二元模式组合不仅仅揭示了氨基酸残基在一级序列中位置对蛋白性质影响的重要性,还反映出残基间间隔残基数目对蛋白性质影响的重要性,表明蛋白质一级序列中的残基是一种包含了长度和方向的矢量信息点,而非以往认为的标量点。
非相邻二元组合表示方法为:氨基酸残基符号×氨基酸残基符号×Step(相间步长,本研究中步长变化范围为1~100个氨基酸残基),如PR14代表序列中由Pro与Arg 相间14个残基所形成的二元组合。
表4 脂肪酶序列中8个与蛋白耐热性显著相关的非相邻二元组合
Table 4 Analysis of eight most significant di-residue patterns in thermophilic and mesophilic protein sequences
二元组合在序列中平均出现次数的差异的计算方法为
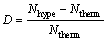
式中:D为差异值;Ntherm为特定二元组合在每条耐热序列中平均出现次数;Nhype为特定二元组合在每条嗜热序列中平均出现次数。
2.5 非相邻二元组合与耐热性的关系
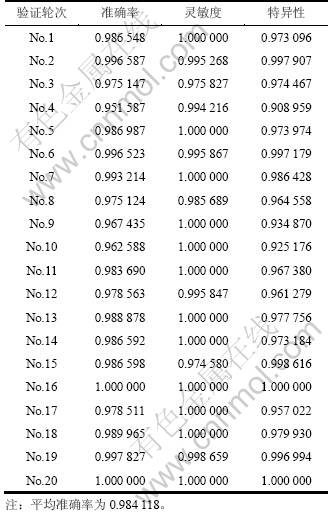
在单因子分析的基础上,根据特征对序列分类正确分辨率的贡献不同和特征向量所反映序列信息的差异,进一步研究单因子序列特征组合对蛋白耐热性的分类正确率的影响,采用三肽组成(TPC)和二元模式(DRPC)组合的模式。实验的结果显示,三肽组成和二元模式组合模式在20组独立随机测试中都获得了很高的分辨正确率(甄别阈为0.5),足以满足后续研究构建性质筛分器的需求,结果如表5所示。
表5 基于三肽组成(TPC)和二元模式(DRPC)组合特征对脂肪酶耐热和嗜热序列分类结果
Table 5 Results of classification using TPC combined DRPC
3 结论
(1) 嗜热脂肪酶序列中亮氨酸、脯氨酸、蛋氨酸、苯丙氨酸、Trp和Tyr残基的增加与蛋白耐热性提高正相关。
(2) 二肽片段KC,EE,KE,RE,VE,YI,EK,VK,EV,YV,EY,KY,VY和YY的含量在嗜热脂肪酶序列中显著比耐热脂肪酶序列的高。
(3) CYP,KCP,VEE,EEY,EVY,KVY等三肽片段的含量与脂肪酶耐热性质密切相关。
(4) 嗜热脂肪酶序列和耐热脂肪酶序列中PR14,RY32,YR47,LE53,LE64,PP64,RP70和PP101等非相邻二元组合的偏爱性。
(5) 利用这些组合特征,发展了基于支持向量机的脂肪酶耐热性高效筛分方法,其应用于真实数据集的分类准确率达到了98.41%。
参考文献:
[1] Pernas M, Lo`z C, Prada A, et al. Structural basis for the kinetics of Candida rugosa Lip1 and Lip3 isoenzymes[J]. Colloids Surf B Biointerfaces, 2002, 26(1/2): 67-74.
[2] Jaeger K E, Ransac S. Bacterial lipases[J]. FEMS Microbiology Reviews, 1994, 15(1): 29-63.
[3] Sharma R, Soni S K, Vohra R M, et al. Purification and characterization of a thermostable alkaline lipase from a new thermophilic Bacillus sp. RSJ-1[J]. Proc Biochem, 2002, 37(10): 1075-1084.
[4] Hiol A, Jonzo M D, Rugani N, et al. Purification and characterization of an extracellular lipase from a thermophilic Rhizopus oryzae strain isolated from palm fruit[J]. Enzyme and Microbial Technology, 2000, 26(5/6): 421-430.
[5] Kim H K, Park S Y, Lee J K, et al. Gene cloning and characterization of thermostable lipase from Bacillus stearothermophilus L1 Biosci[J]. Biotechnol. Biochem, 1998, 62(1): 66-71.
[6] 丁彦蕊. 嗜热菌耐热性与蛋白质序列结构和功能关系的生物信息学研究[D]. 无锡: 江南大学生物工程学院, 2005: 155-161.
DING Yan-rui. Studies on the relationship between extremophile thermostability and protein sequence, structure and function by bioinformatics method[D]. Wuxi: Jiangnan University. School of Biotechnology, 2005: 155-161.
[7] Shen J W, Zhang J, Luo X M., et al. Prediction protein-protein interactions based only on sequences information[J]. PNAS, 2007, 104(11): 4337-4341.
[8] 朱蔚, 郑佐华, 袁有忠, 等. 编码序列的(G+C)%与蛋白质的耐热性相关性分析[J]. 遗传学报, 1999, 26(4): 418-427.
ZHU Wei, ZHENG Zuo-hua, YUAN You-Zhong, et al. Correlation analysis of (G+C)% of coding sequence and thermostability of xylose isomerase of thermophiles[J]. Acta Genetica Sinica, 1999, 26(4): 418-427.
[9] 丁彦蕊, 蔡宇杰, 须文波. 蛋白质空间结构属性与全基因组微生物耐热性的关系[J]. 中国生物化学与分子生物学报, 2007, 23(4): 323-330.
DING Yan-rui, CAI Yu-jie, XU Wen-bo. Relationship between protein structural attributes and complete genome microorganisms thermostability[J]. Chinese Journal of Biochemistry and Molecular Biology, 2007, 23(4): 323-330.
[10] 张振慧, 王正华, 王勇献. 基于氨基酸和二肽组成的蛋白质四级结构分类研究[J]. 生物信息学, 2006, 5(2): 49-52.
ZHANG Zhen-hui, WANG Zheng-hua, WANG Yong-xian. Classification of protein quaternary structure using amino acid and dipeptide composition[J]. China Journal of Bioinformatics, 2006, 5(2): 49-52.
[11] ZHANG Shao-wu, PAN Quan, ZHANG Hong-cai, et al. Classification of protein quaternary structure with support vector machine[J]. Bioinformatics, 2003, 19(18): 239-2396.
[12] Yamamoto T, Mukai K, Yamashita H, et al. Enhancement of thermostability of kojibiose phosphorylase from Thermoanaerobacter brockii ATCC35047 by random mutagenesis[J]. J Biosci Bioeng, 2005, 100(2): 212-215.
[13] Gromiha M M, Suresh M X. Discrimination of mesophilic and thermophilic proteins using machine learning algorithms[J]. Proteins: Struct Funct Bioinf, 2008, 70(4): 1274-1279.
[14] Rollence M L, Filpula D, Pantoliano M W, et al. Engineering thermostability in subtilisin BPN’ by in vitro mutagenesis[J]. Crit Rev Biotechnol, 1988, 8(3): 217-224.
[15] Chapelle O, Vapnik V, Bacsquest O, et al. Choosing multiple parameters for support vector machines[J]. Machine Leaning, 2002, 46(1/2/3): 131-159.
[16] Krebel U H. Pairwise classification and support vector machines[M]. Cambridge: MIT Press, 1999: 255-268.
[17] ZHANG Hao-helen, Jeongyoun A, LIN Xiao-dong, et al. Gene selection using support vector machines with non-convex penalty[J]. Bioinformatics, 2006, 22(1): 88-95.
[18] Scholkopf B, Burges J C, Smola A J. Advances in Kernel methods: Support vector learning[M]. Cambridge: MIT Press, 1999: 185-208.
[19] 张光亚, 方柏山. 嗜热和常温蛋白模式识别的研究[J]. 生物工程学报, 2005, 21(6): 960-964.
ZHANG Guang-ya, FANG Bai-shan. A study on the pattern recognition of thermophilic and mesophilic proteins[J]. Chinese Journal of Biotechnology, 2005, 21(6): 960-964.
(编辑 杨幼平)
收稿日期:2010-09-02;修回日期:2010-12-10
基金项目:国家自然科学基金资助项目(31000350)
通信作者:赵伟(1980-),男,江苏扬州人,博士,讲师,从事生物工程研究;电话:0731-88836943;E-mail: wei.zhao.csu@gmail.com

