代价敏感核主元分析及其在故障诊断中的应用
唐勇波1, 2,桂卫华1,彭涛1
(1. 中南大学 信息科学与工程学院,湖南 长沙,410083;
2. 宜春学院 物理科学与工程技术学院,江西 宜春,336000)
摘要:针对传统核主元分析没有考虑误分类代价的差别、对故障工况不敏感等问题,提出代价敏感核主元分析方法。该方法将代价敏感机制引入核主元分析,以误分类代价最小化为目标,设计最佳阈值调整方法获取最佳阈值,并采用混沌粒子群算法对核参数进行优化,最后利用SPE(squared prediction error)统计量诊断新样本类别。研究结果表明:该方法能有效地降低误分类代价,具有故障敏感性和诊断准确率高以及泛化能力强等特点。
关键词:核主元分析;代价敏感;混沌粒子群算法;阈值调整;故障诊断
中图分类号:TP277 文献标志码:A 文章编号:1672-7207(2013)06-2324-07
Cost-sensitive kernel principal component analysis with its application in fault diagnosis
TANG Yongbo1, 2, GUI Weihua1, PENG Tao1
(1. School of Information Science and Engineering, Central South University, Changsha 410083, China;
2. School of Physical Science and Engineering, Yichun University, Yichun 336000, China)
Abstract: Cost-sensitive kernel principal component analysis(CS-KPCA) was proposed. Cost-sensitive mechanism was firstly introduced into kernel principal component analysis aiming at the problems that traditional kernel principal component analysis doesn’t consider the misclassification cost, and is insensitive to fault condition. CS-KPCA aimed to minimize misclassification cost. The best threshold adjusting method was designed to get the best threshold and the chaos particle swarm optimization(CPSO) algorithm was adopted to optimize the kernel parameters of kernel principal component analysis. At last, class labels of new instances were diagnosed by using squared prediction error(SPE) statistic. The results show that the proposed method can reduce misclassification cost effectively with high fault sensitivity, diagnosis accuracy and strong ability of generalization.
Key words: kernel principal component analysis; cost-sensitive; chaos particle swarm optimization; threshold adjusting; fault diagnosis
传统的分类算法通常以全局分类误分率最小化为目标,并假设各类的错分代价相等以及数据集是平衡的。在工业生产监控过程中,这2种假设不成立。由于危害程度不同,设备的误诊断代价不对等,将故障状态误诊断为正常状态所需要承担的安全隐患和经济损失等代价往往大于相反情况时的代价。另外,由于故障样本的获取是以设备某种程度的损坏为代价,所以,相对于正常样本,故障样本的数量会少得多,这种样本不均衡性导致以分类准确率为性能指标的故障诊断方法的结论更倾向于正常状态的判定,不能有效地避免故障带来的损失。因此,以误分率最小化为目标已不能满足实际的故障诊断要求,而以诊断代价最小化为故障诊断目标的代价敏感故障诊断是未来故障诊断的重要研究方向之一[1-2]。在机器学习和数据挖掘领域,已提出许多代价敏感学习算法,如:Ting[3]在决策树学习过程中考虑了分类代价,构造代价敏感决策树学习算法;Maciej等[4-5]提出了代价敏感神经网络,该算法易陷入局部最优,有时欠采样或过采样;Tang等[6-7]提出了代价敏感支持向量,该算法分类正确率较高,但在解决多分类问题时存在困难,且在处理非平衡类问题上过于复杂;Ling等[8]提出了一种简单、通用、有效的元学习算法,是经验阈值调整算法。该算法误分类代价低,且对误分类代价率不敏感。到目前为止,尚未见代价敏感学习机制在核主元分析中的应用研究。主元分析方法(principal component analysis,PCA)是一种线性降维方法,即假设过程变量之间满足线性关系,通过降维和提取独立变量来实现监控和故障诊断。然而,在实际工业过程中往往是非线性的, Cho等[9-12]提出核主元分析法(kernel principal component analysis,KPCA),能有效地提取非线性特征。KPCA通过建立SPE(squared prediction error,也叫Q统计量)或T2统计量实现故障检测和诊断,取得许多成果。然而,Q和T2统计量控制限的确定都是通过正常样本的统计抽样分布特性得到的,没有考虑故障样本的分布特性,因而,KPCA对故障工况不敏感。受文献[8]的启发,本文提出类似经验阈值调整的一种阈值调整方法即最佳阈值调整方法。通过训练样本的Q统计量进行代价敏感学习,得到最佳阈值,诊断新样本类别。本文将代价敏感机制引入核主元分析,以误分类代价最小化为目标,提出代价敏感核主元分析算法(cost-sensitive kernel principal component analysis,CS-KPCA),并利用混沌粒子群算法对核参数进行优化。变压器油中溶解气体分析(dissolved gas analysis,DGA)实验结果表明:代价敏感核主元分析与核主元分析相比, 能有效地降低误诊断代价,具有更强的泛化能力和较高的故障敏感性。
1 代价敏感核主元分析
1.1 代价敏感学习
代价敏感学习是近年来机器学习和数据挖掘领域的一个新的研究热点。代价敏感学习通常分为两大类:(1) 将任何非代价敏感学习分类算法转换成代价敏感学习算法,称之为代价敏感元学习方法,如代价敏感BP神经网络。元学习方法又分为阈值和抽样2类;(2)直接构造代价敏感分类算法,称为直接法,如代价敏感支持向量机。
在代价敏感学习中,假设有c类样本,代价矩阵定义为C(i,j),表示将第j类的样本误分到第i类。当正确分类时代价为0,即C(i,i)=0时,第j类的期望代价为
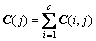 (1)
(1)
以2类分类情况为例,误分类代价所用的代价矩阵如表1所示,其中:C(i,j)表示将j预测为i类时的代价;TP为正例分类为正例的代价;FP为反例分类为正例的代价;FN为正例分类为反例的代价;TN为反例分类为反例的代价。通常认为正确分类代价为TP=TN=0。
表1 2类问题代价矩阵
Table 1 Cost matrix for binary classification

代价敏感评价指标有全局误分代价(β)、全局的平均误分代价(ρ)等。
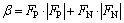 (2)
(2)
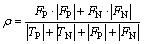 (3)
(3)
式中:|・|表示分类样本个数,如|FP|表示反例分类为正例的个数。
1.2 核主元分析
核主元分析的主要思想是通过引入非线性映射Φ将输入空间XN×M映射到1个高维特征空间F,然后,在高维特征空间计算主元成分,在高维特征空间中得到的线性主元实质就是原始输入空间的非线性主元。映射数据Φ(xi)的协方差矩阵可以表示为
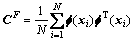 (4)
(4)
解决在特征空间的特征值问题:
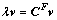 (5)
(5)
CF的特征矢量v可表示为
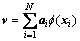 (6)
(6)
其中:ai为系数向量。通过计算映射数据在特征矢量vk上的投影来计算主元,即
 (7)
(7)
式中:表示x与y的点积。为避免直接计算非线性映射,在特征空间定义核函数矩阵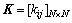 ,
,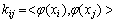 。核函数主元分析的详细求解过程见文献[12]。
。核函数主元分析的详细求解过程见文献[12]。
对于核函数的选择,选取高斯径向基函数:
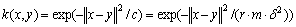 (8)
(8)
式中:r为核参数;m为原始输入空间维数;δ2为方差。Q统计量定义为
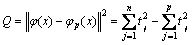 (9)
(9)
Q的控制限Qa可根据其近似分布计算:
 (10)
(10)
式中:g=b/(2a);h=2a2/b;a和b分别为Q的估计均值和方差;p为主元个数;n为非零特征值的个数。
1.3 混沌粒子群算法(chaos particle swarm optimization,CPSO)
粒子群优化算法(particle swarm optimization, PSO)是基于群体的进化计算技术,最早是由美国的Kennedy和Eberhart提出[13],是受启于鸟群觅食行为而提出的一种生物进化算法,原理简单且易于实现、全局收敛。PSO采用速度-位置搜索模型。设粒子群由m个粒子构成,第i个粒子在D维解空间的位置为zi=(zi1,zi2,…,ziD),速度vi=(vi1,vi2,…,viD)。每个粒子都有1个适应值函数f(zi)来计算zi当前的适应值,衡量粒子位置的优劣。zi所经历的最优位置称为个体极值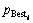 ,而群体所经历的最优位置称为全局极值gBest。在每次迭代中,粒子跟踪个体极值、全局极值和自己前一时刻的状态来调整当前时刻的位置和速度,迭代公式如下:
,而群体所经历的最优位置称为全局极值gBest。在每次迭代中,粒子跟踪个体极值、全局极值和自己前一时刻的状态来调整当前时刻的位置和速度,迭代公式如下:

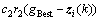 (11)
(11)
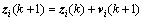 (12)
(12)
式中:w为惯性权重;k为迭代次数;r1和r2为[0,1]之间的随机数;c1和c2为学习因子,通常取为2。
鉴于PSO算法本身不具备遍历特性,且存在由于某些粒子在迭代中出现停滞而导致的算法早熟现象,引入具有遍历特性的混沌机制[14-16]。产生混沌的规则很多,式(13)为混沌变量 的一种演变算式:
的一种演变算式:
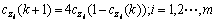 (13)
(13)
变量zi∈(ai,bi)可由式(14)和(15)与混沌变量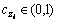 进行往返映射。
进行往返映射。
 (14)
(14)
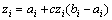 (15)
(15)
1.4 代价敏感核主元分析(CS-KPCA)
为了提高故障敏感性,引入代价敏感机制,提出的CS-KPCA算法描述如下。
算法1:CS-KPCA算法。
输入: 建模数据集XM={xM1,xM2,…,xMi,…,xMn},样本xMi=(x1,x2,…,xd)(d为样本维数);训练样本集XTR;训练样本集类别集CTR;测试样本集XTE;核参数r;代价矩阵C。
输出:测试样本集XTE的类别。
Step 1:将建模数据集进行标准化。
Step 2:按式(8)计算建模数据集核矩阵K,并对核矩阵K作均值化处理,得到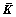 :
:
 (16)
(16)
式中:ln为元素为1/n的n×n常数方阵。
Step 3:解决nλa=Ka的特征值问题,并标准化ak,使 。
。
Step 4:输入训练样本集XTR和类别集CTR,计算训练样本的Q统计量并进行代价敏感学习,得到最佳阈值Qbest。该步骤称为最佳阈值调整算法。
Step 5:输入测试样本集XTE,按照正常状态下模型的均值和方差进行标准化。
Step 6:对标准化后的1个测试样本xte∈Rd,计算其内核向量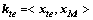 ,并进行均值中心化处理
,并进行均值中心化处理 。
。
 (17)
(17)
式中:In为元素为1/n的n维行向量。
Step 7:按式(7)提取测试样本的非线性主元,并按式(9)计算测试样本的Q统计量。
Step 8:将测试样本的Q统计量与Qbest进行比较,若Q>Qbest,则归为故障类;否则,归为正常类。
算法2:最佳阈值调整算法。
输入:训练样本集XTR和类别集CTR;代价矩阵。
输出:最佳阈值Qbest。
Step 1:输入训练样本集XTR,按照正常状态下模型的均值和方差进行标准化;
Step 2:对标准化后的1个训练样本xtr∈Rd,计算其内核向量 ,按式(17)进行均值中心化处理
,按式(17)进行均值中心化处理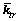 ,只是将式(17)中的kte改为ktr。
,只是将式(17)中的kte改为ktr。
Step 3:按式(7)提取训练样本的非线性主元,并按式(9)计算训练样本集的Q统计量,设为Q1。
Step 4:将Q1升序排成1列, 设为Q2。
Step 5:选取Q2中的第1个元素作为控制限。
Step 6:将Q1中元素与控制限比较,得到Q1在此控制限下的诊断类别C;将C与CTR进行比较,得到正常样本误判为故障样本,以及故障样本误判为正常样本的个数。
Step 7:按式(2)计算全局误分代价。
Step 8:依次选取Q2中的各元素作为控制限,重复Step 6和Step 7至Q2中的最后元素,计算得到不同控制限的全局误分代价。
Step 9:最小全局误分代价所对应的控制限即为Qbest。
鉴于核参数的选择对分类性能有较大影响,针对KPCA的核参数的选择问题构造适应度函数。通过优化核参数提高KPCA的分类性能。对于未知样本,预测误差要尽可能地小。用预测误差作为适应度函数,对每个粒子进行判断,选出预测误差最小时所对应的粒子即为最优解。
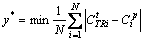 (18)
(18)
式中: 和
和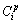 分别表示第i个样本真实的类别值(正常类取值为0,异常类取值为1)和预测的类别值;N为训练集样本数;y*为适应度函数的最小值即最优值。
分别表示第i个样本真实的类别值(正常类取值为0,异常类取值为1)和预测的类别值;N为训练集样本数;y*为适应度函数的最小值即最优值。
算法3:核参数的CPSO算法[15]。
输入:建模数据集XM;训练样本集XTR和类别集CTR。
输出:最优核参数r。
Step 1:确定算法参数,初始化种群:给定群体规模m,随机产生每个粒子的初始位置和速度分别为zi和vi,计算各粒子的适应值f(zi), 有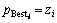 ,经比较得出gBest。
,经比较得出gBest。
Step 2:将zi通过式(14)变换,映射为混沌变量。
Step 3:各粒子将通过式(11)和(12),计算速度vi,并调整至新位置zi,进而计算适应值f(zi)。
Step 4:混沌变量经式(13)作混沌运动,并变换为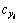 。
。
Step 5:将通过式(15)变换,映射为普通变量yi, 并计算f(yi)。
Step 6:比较f(zi),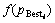 与f(yi),以其间的最优值更新
与f(yi),以其间的最优值更新 ;比较各与f(gBest), 若优,则更新gBest;否则,保留原值。
;比较各与f(gBest), 若优,则更新gBest;否则,保留原值。
Step 7:判断是否已满足终止条件(预设的运算精度或迭代次数),若满足,则终止算法运行,输出结果;否则,返回到Step 2,继续运行。
算法2和算法3是算法1的重要组成部分,由算法3获得最优核参数,由算法2得到最佳阈值。整个算法的基本结构框图如图1所示。
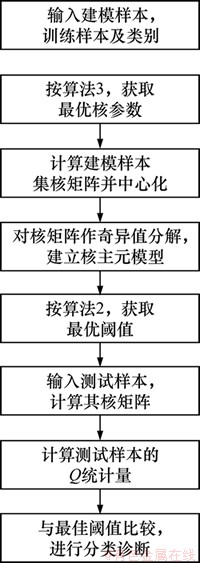
图1 算法的结构框图
Fig. 1 Fundamental structure of algorithm
2 实验与结果分析
电力变压器是电力系统的枢纽设备之一。变压器运行在非常复杂的强电磁场环境中,具有多变量、非线性、强耦合、不确定性等特点。油中溶解气体分析(dissolved gas analysis, DGA)是电力系统诊断充油电气设备早期潜伏性故障的重要方法,变压器在运行过程中积累了大量的油中溶解气体体积分数,包含了丰富的反映变压器运行状态信息,对变压器的故障诊断具有重要价值。本文基于DGA体积分数验证代价敏感核主元分析的有效性。
选取798个样本作为实验数据集,其中正常工况样本523个(反例),故障工况样本275个(正例),每个特征气体样本包括氢气(H2)、甲烷(CH4)、乙烷(C2H6)、乙烯(C2H4)、乙炔(C2H2)共5个属性。实验采用10折交叉验证法。每次进行实验时,先从正常工况523个样本中随机选择100个样本作为建模样本集,然后,从剩余423个正常工况样本中随机选择42个样本并275个故障工况样本中随机选择27个样本作为测试集,其余629个样本作为训练集。代价矩阵设定如下:正确分类的代价TP=TN=0,误分类反例的代价FP=1,误分类正例的代价FN从1按步长1递增到10。评价指标如下。
故障敏感性也叫正例的分类正确率,为
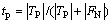 (19)
(19)
反例的分类正确率为
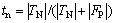 (20)
(20)
全局的分类正确率为
 (21)
(21)
全局的平均误分代价(ρ)见式(3)。
图2所示为r=1,FN=1时,按最佳阈值调整算法对变压器DGA训练样本集(正常样本(反例)381组,故障样本(正例)248组),以全局误分代价最小化为目标,进行代价敏感学习获得最佳阈值的示意图,其中,横坐标为按最大值归一化输入的Q统计量,即以Q统计量除以Q统计量的最大值。由图2可见,全局误分代价随阈值的增大而急剧降低,到达最小值后,随阈值的增大而缓慢升高,在归一化Q统计量为0.8左右急剧升高后缓慢上升。图2中,当虚线所对应的Q统计量作为控制限时,训练样本集的全局误分代价最小,即为最佳阈值Qbest=0.055 5, 而按式(10)计算的控制限Qa=0.056 8, Qbest略小于Qa。图3所示为Qbest与代价FN之间的关系图。由图3可见:Qbest随代价FN的增大而逐步减小,也就是说,随代价FN的增大,训练后得到的分类边界就会逐步倾向于正常样本一边,使得故障样本的漏检率减小,故障敏感性提高。
图4所示为该数据集应用到CS-KPCA,KPCA和PCA的10折交叉验证的平均结果,其中核参数r=1。由图4(a)可见:CS-KPCA的故障敏感性随代价FN的增大而逐渐上升,表明CS-KPCA具有较好的故障敏感性;而KPCA和PCA不随代价的变化而变化,说明KPCA和PCA是非代价敏感学习分类算法;KPCA在r=1时的故障敏感性比PCA时的强。从图4(b)可见:CS-KPCA的全局的分类正确率先随代价FN的增大而逐渐上升,在FN=3时达到最大值,而后随代价FN的增大而下降。这是由于引入代价敏感机制,最佳阈值随代价的增大而减小,分类边界逐步倾向于正常样本一边,导致正常样本的误分个数越来越多,全局分类正确率先增大后减小;KPCA全局分类正确率在r=1时比PCA的高。由图4(c)可见:CS-KPCA的平均误分代价随代价FN的增大而缓慢上升,CS-KPCA的平均误分代价始终比KPCA和PCA的小,KPCA的平均误分代价在r=1时比PCA的小。由图4可见:当FN=1时,CS-KPCA和KPCA的分类性能基本相同,此时,CS-KPCA退化为KPCA。
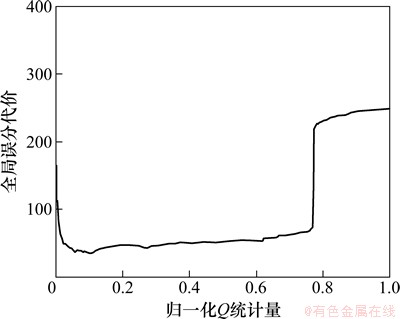
图2 最佳阈值调整算法示意图
Fig.2 Diagram of the best threshold adjusting

图3 最佳阈值Qbest与代价FN的关系
Fig. 3 Relationship between the best threshold and cost
为了验证核参数CPSO算法的有效性,图5给出不同核参数时CS-KPCA的分类性能,其中r=0.470 3为CPSO算法优化的最优核参数值。由图5可见:CS-KPCA在不同核参数时,故障敏感性均随代价FN的增大而逐渐上升,表明CS-KPCA具有较好的故障敏感性;若核参数选择不当,如r=0.1或10, KPCA故障敏感性会大大降低(见表2),导致全局分类正确率下降,甚至低于PCA全局分类正确率;若核参数选择
表2 不同核参数下KPCA分类性能
Table 2 KPCA classification performance of different kernel parameters
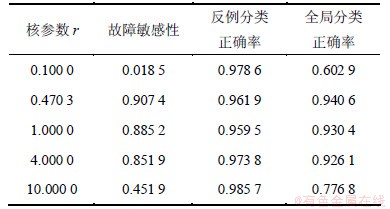
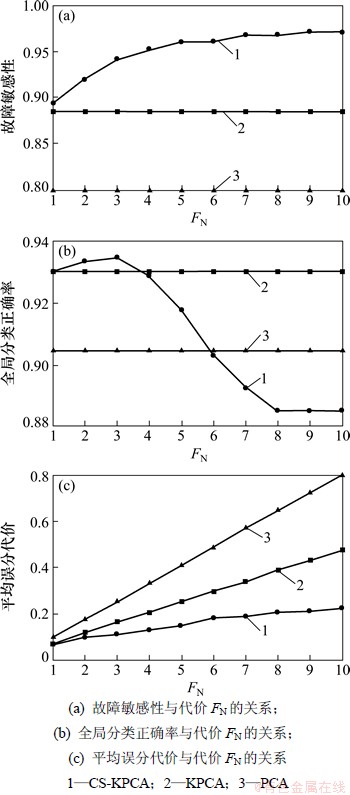
图4 CS-KPCA,KPCA和PCA分类性能比较
Fig. 4 Comparison of classification performance among CS-KPCA, KPCA and PCA

图5 不同核参数下CS-KPCA分类性能比较
Fig. 5 Comparison of CS-KPCA classification performance of different kernel parameters
比较恰当,则CS-KPCA的全局分类正确率相差不大,整体上,r=0.470 3时的全局分类正确率较高, 而且CS-KPCA的平均误分代价始终最小。而对于KPCA,反例的分类正确率随核参数的变化不大,而若核参数的选择不当,则故障敏感性显著降低,导致全局分类正确率显著降低。
3 结论
(1) 针对传统核主元分析没有考虑各类不同误分代价、对故障工况不敏感等问题,提出了代价敏感核主元分析方法。
(2) 代价敏感核主元分析考虑了各类误分代价的不同,以全局误分代价最小化为目标,通过最佳阈值调整方法获得最佳阈值进行诊断,有效地提高了对故障工况的敏感性,改善了数据集不平衡问题造成的影响,KPCA是CS-KPCA的特例,表明CS-KPCA的泛化能力更强。
(3) 由于模型的核参数选择非常关键,利用混沌粒子群算法优化代价敏感核主元分析的核参数,可以提高代价敏感核主元分析的全局分类正确率,降低全局误分代价。与KPCA和PCA相比,CS-KPCA在全局分类正确率随代价的增大稍微上升而后略下降的情况下,能显著提高故障敏感性,始终保持全局的平均误分代价最优。
参考文献:
[1] Saitta L. Machine learning: A technological roadmap[R]. Netherlands: University of Amsterdam, 2000: 1-20.
[2] 吴薇, 胡静涛. 基于代价敏感直推式学习的故障诊断方法[J]. 仪器仪表学报, 2010, 31(5): 1023-1028.
WU Wei, HU Jingtao. Fault diagnosis based on cost-sensitive transduction inference[J]. Chinese Journal of Scientific Instrument, 2010, 31(5): 1023-1028.
[3] Ting K M. An instance-weighting method to induce cost-sensitive trees[J]. IEEE Transactions on Knowledge and Data Engineering, 2002, 14(3): 659-665.
[4] Maciej A M, Piotr A H, Jacek M Z, et al. Training neural network classifiers for medical decision making: The effects of imbalanced datasets on classification performance[J]. Neural Networks, 2008, 21(2): 427-436.
[5] ZHOU Zhihua, LIU Xuying. Training cost-sensitive neural networks with methods addressing class imbalance problem[J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(1): 63-77.
[6] Tang Y C, Zhang Y Q, Chawla N V, et al. SVMs modeling for highly imbalanced classification[J]. IEEE Trans on Systems, Man and Cybernetics, Part B: Cybernetics, 2009, 39(1): 281-288.
[7] 郑恩辉, 李平, 宋执环. 代价敏感支持向量机[J]. 控制与决策, 2006, 21(4): 473-476.
ZHENG Enhui, LI Ping, SONG Zhihuan. Cost sensitive support vector machines[J]. Control and Decision, 2006, 21(4): 473-476.
[8] Ling C X, Sheng V S. A comparative study of cost-sensitive classifiers[J]. Chinese Journal of Computers, 2007, 30(8): 1203-1211.
[9] Cho J H, Lee J M, Choi S W, et al. Fault identification for process monitoring using kernel principal component analysis[J]. Chemical Engineering Science, 2005, 60(1): 279-288.
[10] Choi S W, Lee C K, Lee J M, et al. Fault detection and identification of nonlinear processes based on kernel PCA[J]. Chemometrics and Intelligent Laboratory Systems, 2005, 75(1): 55-67.
[11] 许洁, 胡寿松. 基于KPCA和MKL-SVM的非线性过程监控与故障诊断[J]. 仪器仪表学报, 2010, 31(11): 2428-2433.
XU Jie, HU Shouson. Nonlinear process monitoring and fault diagnosis based on KPCA and MKL-SVM[J]. Chinese Journal of Scientific Instrument, 2010, 31(11): 2428-2433.
[12] Lee J M, Yoo C, Choi S W, et al. Non-linear process monitoring using kernel principal component analysis[J]. Chemical Engineering Science, 2004, 59(1): 223-234.
[13] Kennedy J, Eberhart R. Particle swarm optimization[C]//Proceedings of IEEE International Conference on Neural Network. Perth, Australia: IEEE Piscataway, 1995: 1942-1948.
[14] YANG Dixiong, LI Gang, CHENG Gengdong. On the efficiency of chaos optimization algorithms for global optimization[J]. Chaos, Solitons and Fractals, 2007, 34(4): 1366-1375.
[15] 莫愿斌, 陈德钊, 胡上序. 混沌粒子群算法及其在生化过程动态优化中的应用[J]. 化工学报, 2006, 57(9): 2123-2127.
MO Yuanbin, CHEN Dezhao, HU Shangxu. Chaos particle swarm optimization algorithm and its application in biochemical process dynamic optimization[J]. Journal of Chemical Industry and Engineering, 2006, 57(9): 2123-2127.
[16] 程跃, 程文明, 郑严, 等. 基于混沌粒子群算法的结构可靠性优化设计[J]. 中南大学学报: 自然科学版, 2011, 42(3): 671-676.
CHENG Yue, CHENG Wenming, ZHENG Yan, et al. Structural reliability optimal design based on chaos particle swarm optimization[J]. Journal of Central South University: Science and Technology, 2011, 42(3): 671-676.
(编辑 陈灿华)
收稿日期:2012-06-13;修回日期:2012-08-22
基金项目:国家自然科学基金重点项目(61134006);国家科技支撑计划项目(2012BAK09B04)
通信作者:唐勇波(1975-),男,湖南永州人,博士研究生,从事智能控制和故障诊断技术等研究;电话:13237955569;E-mail:tybcsu@163.com

