DOI: 10.11817/j.issn.1672-7207.2015.03.018
实数GA基因层次种群多样性数学模型
赵红1,朱杰1, 2,朱洁1,李雯睿1, 3
(1. 南京晓庄学院 数学与信息技术学院,江苏 南京,211171;
2. 东南大学 自动化学院,江苏 南京,210096;
3. 河海大学 计算机及信息工程学院,江苏 南京,210098)
摘要:针对现有GA种群多样性定义往往针对二进制编码且存在计算量大、适用性差等问题,建立实数编码基因层次种群多样性数学模型。将实数编码中每一维决策变量的取值范围划分为若干等长度的区间段,并借鉴二进制编码中基因位的含义,定义区间段基因位变量的概念,将其看作随机变量并设计图形化方法,描述每一维变量所有编码值在各等长度取值区间的分布情况,以此刻画种群多样性,通过2个测试函数的优化分析,验证模型的有效性;分析区间段基因位的特性,指出其可以作为复杂非线性优化问题中产生初始群体的先验知识使用,从而可以显著提高寻得最优解的概率及收敛速度;指出今后进一步的研究思路和方向。
关键词:遗传算法;实数编码;种群多样性;基因层次;区间段基因位;随机变量
中图分类号:TP181 文献标志码:A 文章编号:1672-7207(2015)03-0894-07
Gene-level population diversity mathematical model of real-coded GA
ZHAO Hong1, ZHU Jie1, 2, ZHU Jie1, LI Wenrui1, 3
(1. School of Mathematics and Information Technology, Nanjing Xiaozhuang University, Nanjing 211171, China;
2. School of Automation, Southeast University, Nanjing 210096, China;
3. College of Computer and Information Engineering, Hohai University, Nanjing 210098, China)
Abstract: The calculation and applicability of existing definitions of GA population diversity are not only complicated and poor, but also always applied to binary coded GA, so a Gene-level population diversity mathematical model of real-coded GA was established to overcome the problems. The value range of each dimension decision variable of real-coded GA was divided into several equal length intervals. Interval gene variable that refers to definition of gene in binary coded GA was defined. The interval gene variable was treated as random variable. And its graph method was designed. The interval gene variable indicates the distribution of all coed values of each dimension variable within each equal interval, and the result of the distribution can be used to measure population diversity. The mathematical model presented is effective through analysis to optimization process of two GA test functions. The characteristic of interval gene was analyzed, and the analysis result can be used as experimental knowledge when producing the initial population in complicated nonlinear optimization problem for improving global convergence probability and speed. Finally, further research ideas and direction were pointed out.
Key words: genetic algorithm (GA); real-coded; population diversity; gene level; interval gene; random variable
遗传算法(GA)计算过程简单,对搜索空间具有广泛的适应性,尤其适用于处理传统搜索方法难以解决的复杂和非线性问题,是21世纪有关智能计算的关键技术之一。目前,早熟收敛仍是GA中最亟待研究和解决的问题之一,现有研究表明GA进化过程中种群多样性的变化对其是否会早熟收敛具有本质影响。因此,关于种群多样性在GA进化过程中的特性分析问题具有重要意义。在现有研究中关于GA种群多样性的定义方式,刘胜等[1]提出可以从微观(基因层次)和宏观(个体层次)2个角度统一。从微观角度定义的多样性主要包括种群方差[2]、信息熵[3]、多样性测度和Hamming距离[4]等,从宏观角度定义的多样性主要有欧式距离[5]、种群熵[2]、基因座权重[6]和种群多样度等。种群多样性是以基因和个体2个层次为全面描述的,以基因为基本单元定义的多样性,其本质为:描述N (N为群体规模) 个个体在L (L为决策变量个数,即编码长度) 维空间的每一维上的值不同程度的总和,以实数编码为例,也就是当所有个体在每一维的编码值是对该维空间的均匀覆盖时,种群多样性最好,是从遗传操作的角度衡量种群的进化能力,这正是本文研究的重点;个体层次上多样性描述的是个体在解空间分散程度的总和,是衡量种群中所有个体对整个搜索空间覆盖范围的重要标志。虽然它们分别是从结构和空间2个角度衡量种群多样性,但在多数情况下,二者是具有一致性的。但是以上种群多样性定义或往往用于计算种群中2个个体的差异性,如Hamming距离、欧式距离、基因座权重等,并通常在设计交叉算子时使用,而非整个群体的多样性度量[4-5],对于整个种群多样性在进化的不同阶段、在3个遗传算子不断作用下的变化规律及其对收敛状态的影响却无法体现和分析;或仅适用于二进制编码,如信息熵、多样性测度等,但是对于一些多维、高精度要求的优化问题采用实数编码较二进制编码有更大的优势;或计算量大,不便于使用,如种群熵等,大大限制了其适用性;另外有些文献并没有研究GA进化过程中整体种群多样性的变化规律[7-13],只关心子代种群适应度值是否大于父代种群适应度。而种群多样性是GA进化过程中最重要的性能指标,其如何变化将直接影响GA的收敛状态和收敛速度,因此,建立一个简单、通用的GA种群多样性的数学模型,以便于分析其随GA进化代数的变化过程以及遗传算子和遗传控制参数等对其的影响将对研究GA收敛性能有重大意义。
1 种群多样性本质分析
1.1 实数编码基因层次种群多样性的数学模型
若严格按照该描述来定义实数编码基因层次种群多样性的模型,则给出的模型不但复杂,而且实用性很差,不便于操作。因此,本文进行了如下简化设计:将每一维变量的取值范围划分为若干个取值区间,用该维变量所有(N个)编码值在各个取值区间的分布情况来描述其对该维空间的覆盖程度,从而既能体现其种群多样性的本质,又便于操作。具体方法如下。
设种群U={uij(t)(其中,j=1, 2, …, L; i=1, 2, …, N; t为进化代数},其一决策变量x的取值范围为[lmin, lmax],被均匀的划分为m个区间,若种群在该维空间的N个编码值落入各个取值区间的个数相等,则
种群多样性最好。且限定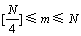 (其中[・]表示取整),则区间长度为
(其中[・]表示取整),则区间长度为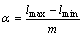 ,落入每个区间的编
,落入每个区间的编
码值个数最多不超过4个,最少为1个。这里给出区间段基因位变量的概念来描述编码值在各个取值区间的分布情况,如下所示。
定义1 区间段基因位变量。区间段基因位变量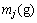 描述的是决策变量x的N个编码中取值范围在第j个区间的个数(以下涉及到变量j时,其取值范围均为j=1, 2, …, m,为了简化,省略表示)为
描述的是决策变量x的N个编码中取值范围在第j个区间的个数(以下涉及到变量j时,其取值范围均为j=1, 2, …, m,为了简化,省略表示)为
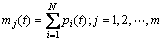 (1)
(1)
其中: 。
。
根据GA基因层次种群多样性的本质含义可知:当t取定某值,变量mj(g)取值N/m时,种群多样性最好,无论以正负何种形式偏离该值相同的程度时种群多样性以相同程度变差。因此,对于mj(g)而言可以用1个期望值和对该期望值的偏离程度来刻画其特性,而这种刻画方式与随机过程中以期望值和方差来刻画随机变量的过程类似,因此,本文提出将变量mj(g)以类似随机变量来看待,并定义mj(g)的数学期望、偏离度或方差等概念作为进一步分析其特性的工具。具体定义如下。
定义2 区间段基因位变量期望值。由上所述可知,随机变量mj(g)的数学期望为m,即分布于每个取值区间的编码数量都相等时,种群多样性最好。因此,
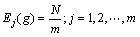 (2)
(2)
定义3 区间段基因位变量偏离度。即随机变量mj(g)对Ej(g)的偏离程度:
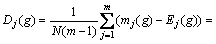
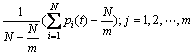 (3)
(3)
为第g代的基因位偏离度。
对于Dj(g),当j=1, 2, …, m时,有一个值等于1,其他值都等于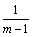 时,表明决策变量x的N个编码值都集中于某一取值区间范围内,此时种群多样性最差;当Dj(g)=0, j=1, 2, …, m时,表明决策变量x的N个编码值平均分布于各个取值区间,此时种群多样性最好。
时,表明决策变量x的N个编码值都集中于某一取值区间范围内,此时种群多样性最差;当Dj(g)=0, j=1, 2, …, m时,表明决策变量x的N个编码值平均分布于各个取值区间,此时种群多样性最好。
图1所示为编码值落入某一取值区间的个数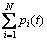 与其对应的区间段基因位变量偏离度取值
与其对应的区间段基因位变量偏离度取值
Dj(g)的曲线。图1中标注了几个关键的坐标点,如表1所示(对应图1(a))。由图1和表1可见:当种群规模不同,取值区间划分个数不同时,对应的区间段基因位变量偏离度曲线也略有不同,但是都满足落入某取值区间的编码数等于其期望值N/m时,偏离度值为0,落入某取值区间的编码个数等于N时,偏离度等于1。只是由于2条曲线斜率不同,图1(a)中直线的斜率为0.030 3,图1(b)直线的斜率为0.027 8,因此,在取其他相同值时对应的偏离度略有不同,但这对算法本身的分析不会产生影响。
1.2 图形化表示方法
为了更直观的体现GA进化过程中区间段基因位变量mj(g)的变化规律,下面给出mj(g)的图形化表示方法。
定义4 区间段基因位直方图如图2所示。 ,j=1, 2, …, m,将由(j, mj(g))绘成的直方图称为区间段基因位直方图,它可以用来衡量某一维变量的N个编码值在各个取值区间的分布情况。
,j=1, 2, …, m,将由(j, mj(g))绘成的直方图称为区间段基因位直方图,它可以用来衡量某一维变量的N个编码值在各个取值区间的分布情况。
图2(a)和(b)所示为Shubert函数:
初始群体二维变量编码的区间段基因位直方图。
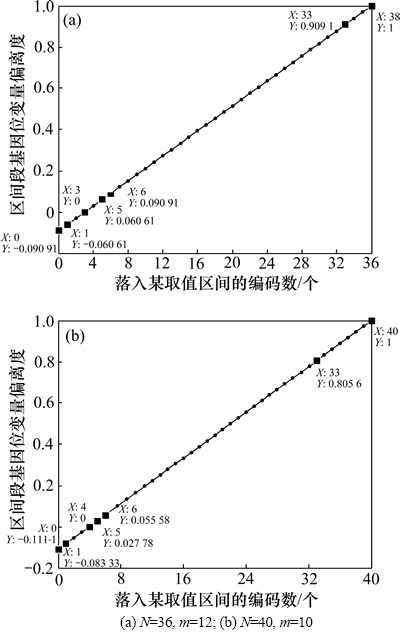
图1 区间段基因位变量偏离度随落入某一取值区间编码数的变化
Fig. 1 Variations of deviation degree of interval gene variable with code numbers within some interval
表1 图1标注的坐标点
Table 1 Coordinates in Fig. 1

其中,变量取值范围限定在[-3, 3],N=36,g=0。 平均划分为12个取值区间,满足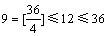 。 1~12分别对应的取值区间为{[-3, -.25], (-2.5, -2.0], (-2.0, -1.5], (-1.5, -1.0], (-1.0, -0.5], (-0.5, 0], (0, 0.5], (0.5, 1.0], (1.0, 1.5], (1.5, 2.0], (2.0, 2.5], (2.5, 3.0])},从图2中可以体现二维变量初始编码值在各取值区间的分布。由图2可见:初始的N个编码在各取值区间的分布是比较均匀的,即种群多样性较好。为了获得进化过程的不同阶段的种群多样性分析图形,可以绘出g取不同值时对应的区间段基因位变量图。
。 1~12分别对应的取值区间为{[-3, -.25], (-2.5, -2.0], (-2.0, -1.5], (-1.5, -1.0], (-1.0, -0.5], (-0.5, 0], (0, 0.5], (0.5, 1.0], (1.0, 1.5], (1.5, 2.0], (2.0, 2.5], (2.5, 3.0])},从图2中可以体现二维变量初始编码值在各取值区间的分布。由图2可见:初始的N个编码在各取值区间的分布是比较均匀的,即种群多样性较好。为了获得进化过程的不同阶段的种群多样性分析图形,可以绘出g取不同值时对应的区间段基因位变量图。
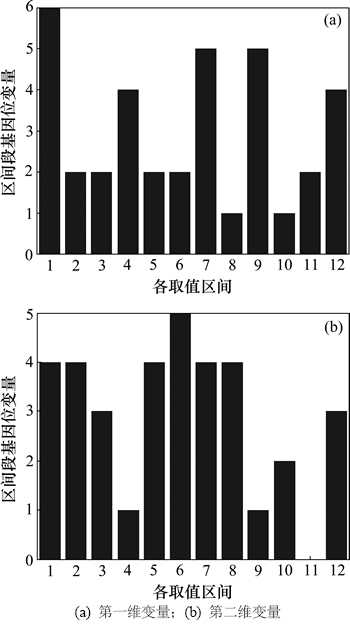
图2 区间段基因位直方图
Fig. 2 Interval gene histograms
当g不同时为了对mj(g)进行对比分析以获得种群多样性随进化过程的变化规律,需要把它们绘在同一个图中。但若把多个直方图绘在1个图中,既混乱又不直观,因此,将区间段基因位直方图绘成区间段基因位曲线图的形式。
以Shubert函数为例,遗传优化50代,函数全局收敛于其最优解-186.73,此时对应的变量为(-1.425 2,-0.800 3)。函数2个变量的取值范围及其取值区间划分与前面的相同。
图3和图4所示分别为Shubert函数的2个变量在不同进化数的区间段基因位变量曲线和偏离度曲线。由于每个变量的编码个数为36(N=36),取值区间被均匀的划分为12个(m=12),因此,由定义1可知区间段基因位变量期望值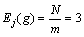 (其中,j=1, 2, …, 12),由图3可见:初始群体的N个编码落入各个取值区间的个数在其期望值(3)上下浮动,自从第10代开始,第一维变量的编码落入第4个取值区间的个数增多,约为21个左右,而落入其他取值区间的编码个数均减少,甚至为0个。第二维变量的编码落入第5个取值区间的个数增多,约为33个,而落入其他取值区间的编码个数均减少,甚至为0个。而进化到第30代以及50代算法已经收敛时,第一维变量的编码落入第4个取值区间的编码个数达到33个以上,落入其他9个取值区间的编码个数为3个左右,第二维变量较之前差异不大。而第4和第5个取值区间的范围分别为(-1.5, -1.0]和(-1.0, -0.5],正是算法最优解对应的编码所在的区间。
(其中,j=1, 2, …, 12),由图3可见:初始群体的N个编码落入各个取值区间的个数在其期望值(3)上下浮动,自从第10代开始,第一维变量的编码落入第4个取值区间的个数增多,约为21个左右,而落入其他取值区间的编码个数均减少,甚至为0个。第二维变量的编码落入第5个取值区间的个数增多,约为33个,而落入其他取值区间的编码个数均减少,甚至为0个。而进化到第30代以及50代算法已经收敛时,第一维变量的编码落入第4个取值区间的编码个数达到33个以上,落入其他9个取值区间的编码个数为3个左右,第二维变量较之前差异不大。而第4和第5个取值区间的范围分别为(-1.5, -1.0]和(-1.0, -0.5],正是算法最优解对应的编码所在的区间。
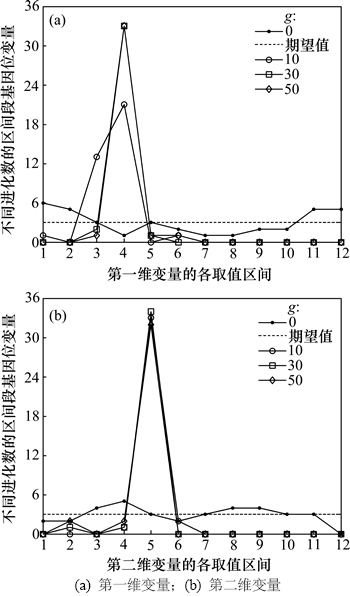
图3 2个变量在不同进化数的区间段基因位变量
Fig. 3 Interval gene variables of two variables for different generations
图4所示为2个变量在不同进化数的区间段基因位变量偏离度曲线。由图4(a)和表1可知:对于第一维变量,初始种群的所有编码落入各取值区间的个数在1~6个之间,算法进化到第30代时所有编码落入第1~2、6~12个之间取值区间的个数为0个,落入第4个取值区间的个数为33个左右。第二维变量情况与第一维变量情况类似,只是算法进化到第10代以及最后收敛时的情况差异较第一维变量更小。
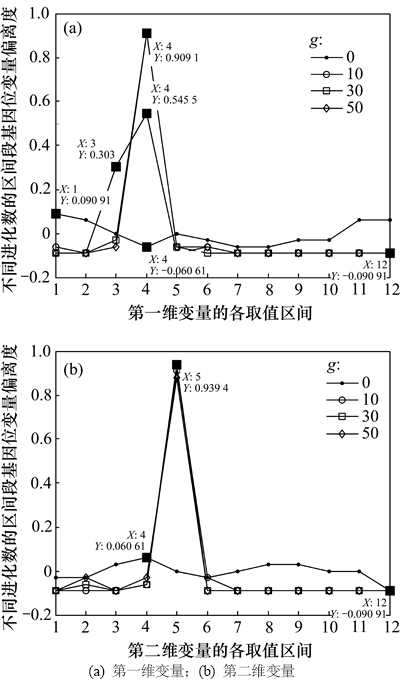
图4 2个变量在不同进化数的区间段基因位变量偏离度
Fig. 4 Deviation degrees of interval gene variables of two variables for different generations
另外,对一元测试函数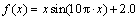 ,
,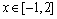 ,多元单峰函数
,多元单峰函数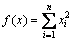 ,
, 等GA测试函数进行了类似分析,获得了相似的结果。根据所得结果可以总结出以下结论。
等GA测试函数进行了类似分析,获得了相似的结果。根据所得结果可以总结出以下结论。
1) 所建立的实数编码基因层次种群多样性数学模型及其图形化表示方法适用于不同优化函数或问题进化过程的分析,可以直观地体现每一维变量的收敛过程以及收敛区间。
2) 初始区间段基因位曲线图较其他进化曲线以其期望值为基准上下较均匀地浮动最小的范围,区间段基因位偏离度曲线较其他进化曲线更接近0,这说明通过随机方式产生的初始群体每个变量的N个编码落入各个取值区间的个数与其期望值最接近,是最平均分布的,其种群多样性在整个GA进化过程中是最好的。
3) 从遗传进化的某代开始,每维变量的N个编码的绝大多数均落入其最优解所在的取值区间,而落入其他取值区间的个数多数为0个。因此可见,每一维变量的所有编码在进化过程中逐步向其最优解所在的取值区间聚集,种群多样性也随之变差。
从以上的分析过程和获得结论可见,利用所建立的实数编码基因层次种群多样性数学模型及其图形化表示方法能有效的体现和分析GA进化过程种群多样性的变化规律,该模型和方法操作简单,适用性强。
进一步地可以研究基本遗传算子、遗传控制参数或现有文献中涉及的改进遗传算子等对种群多样性性变化的影响,从而对通过改进遗传算子或遗传控制参数等克服GA早熟收敛或提高收敛速度的方法的性能进行评价,并研究通过改进遗传算子或其他方法来克服GA早熟收敛的可行性方法。
2 区间段基因位特性分析
从区间段基因位变量曲线及其偏离度曲线可知,算法运行到一定代数时,每个变量的N个编码将向最优解所在的取值区间聚集,到算法收敛时几乎全部聚集到该区间内,即使在优化开始时不知道算法的最优解,仍然可以从这2个图中方便地分析出最优解所在的取值区间为哪一个,因此,可以利用该性质定义特性区间的概念。
定义5特性区间。将算法进化过程中区间段基因位变量曲线及其偏离度曲线所确定的变量编码聚集最多的取值区间为特性区间。
该特性区间的作用在于可以作为算法初始群体产生的先验知识来用,这样可以缩小算法的搜索范围,加快算法收敛速度。仍以Shubert函数为例,特性区间定义为(-1.0, -0.5]。图5(a)和(b)所示分别为第一维变量利用特性区间产生初始群体情况下算法优化的区间段基因位变量曲线图及其偏离度曲线。
由图5可见,初始群体均位于所定义的特性区间范围内。
表2所示为分别利用特性区间产生初始群体(A)和随机产生初始群体(B)对算法优化10次的收敛数对比。
由表2可见:利用特性区间产生初始群体较随机产生初始群体可以加快算法的收敛速度,平均优化代数可以减少10代左右。
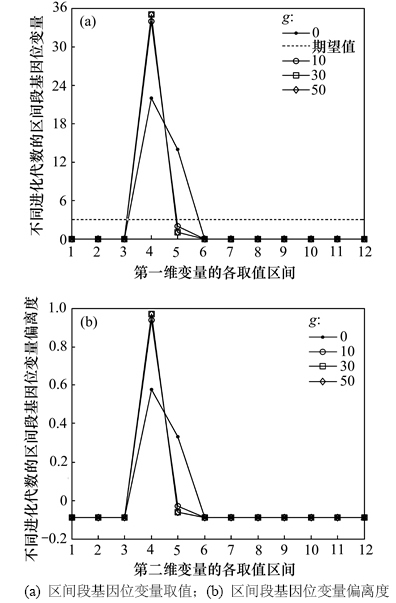
图5 利用特性区间产生初始群体的区间段基因位变量曲线及其偏离度曲线
Fig. 5 Curves of interval gene variable and deviation degree of initial population produced by using characteristic interval
表2 利用特性区间产生初始群体和随机产生初始群体的对比结果
Table 2 Optimization results of two initial population produced by using characteristic interval and random method respectively.

利用该特性区间更重要的意义在于对于某些复杂的非线性优化问题,可能不知道其最优解的情况,且通过几次优化也未必能收敛于其全局最优解,但可以利用几次优化过程中的区间段基因位变量曲线图及其偏离度曲线确定问题的特性区间,从而利用其特性区间作为先验知识产生初始群体,这样可以大大提高寻得最优解的几率,且加快算法的收敛速度,减少优化时间。
3 结论
1) 建立实数编码基因层次种群多样性数学模型。从实数编码基因层次种群多样性的本质出发,考虑了模型的准确性、适用性以及计算量等方面的因素,在作了适当的简化处理后建立现有模型。
2) 仿真结果验证所建立模型在研究GA进化过程中种群多样性的变化规律方面的有效性和适用性,以及用于处理复杂非线性优化问题的意义。
参考文献:
[1] 刘胜, 赵红. 遗传交叉和变异对种群多样性的影响[J]. 控制与决策, 2009, 24(10): 1525-1539.
LIU Sheng, ZHAO Hong. Effect of genetic crossover and mutation on population diversity[J]. Control and Decision, 2009, 24(10): 1525-1539.
[2] 张晓绩, 戴冠中, 徐乃平. 遗传算法种群多样性的分析研究[J]. 控制理论与应用, 1998, 15(1): 17-22.
ZHANG Xiaoji, DAI Guanzhong, XU Naiping. Study on diversity of population in genetic algorithms[J]. Control Theory and Application, 1998, 15(1): 17-22.
[3] Liao G C, Tsao T P. Application embedded chaos search immunegenetic algorithm for short-term unit commitment[J]. Electric Power Systems Research, 2004, 71(2): 135-144.
[4] 刘全, 王晓燕, 傅启明, 等. 双精英协同进化遗传算法[J]. 软件学报, 2012, 23(4): 765-775.
LIU Quan, WANG Xiaoyan, FU Qiming, et al. Double elite coevolutionary genetic algorithm[J]. Journal of Software, 2012, 23(4): 765-775.
[5] 江中央, 蔡自兴, 王勇. 求解全局优化问题的混合自适应正交遗传算法[J]. 软件学报, 2010, 21(6): 1296-1307.
JIANG Zhongyang, CAI Zixing, WANG Yong. Hybrid self-adaptive orthogonal genetic algorithm for solving global optimization problems[J]. Journal of Software, 2010, 21(6): 1296-1307.
[6] 祝希路, 王柏. 一种基于社团划分的小生境遗传算法[J]. 控制与决策, 2010, 25(7): 1113-1116.
ZHU Xilu, WANG Bo. Niche genetic algorithm based on cluster division[J]. Control and Decision, 2010, 25(7): 1113-1116.
[7] Ruiz R, Maroto C, Alcaraz J. Two new robust genetic algorithms for the flow-shop scheduling problem[J]. OMEGA, 2006, 34(5): 461-476.
[8] Leung Y W, Wang Y P. An orthogonal genetic algorithm with quantization for global numerical optimization[J]. IEEE Trans on Evolutionary Computation, 2001, 5(1): 41-53.
[9] Zeng S Y, Wei W, Kang L S, et al. A multi-objective evolutionary algorithm based on orthogonal design[J]. Chinese Journal of Computers, 2005, 28(7): 1153-1162.
[10] Wang Y, Liu H, Cai Z, Zhou Y. An orthogonal design based constrained evolutionary optimization algorithm[J]. Engineering Optimization, 2007, 39(6): 715-736.
[11] 庄健, 杨清宇, 杜海峰, 等. 一种高效的复杂系统遗传算法[J]. 软件学报, 2010, 21(11): 2790-2801.
ZHUANG Jian, YANG Qingyu, DU Haifeng, et al. High efficient complex system genetic algorithm[J]. Journal of Software, 2010, 21(11): 2790-2801.
[12] 周昌乐, 游维, 丁晓君. 一种宋词自动生成的遗传算法及其机器实现[J]. 软件学报, 2010, 21(3): 427-437.
ZHOU Changle, YOU Wei, DING Xiaojun. Genetic algorithm and its implementation of automatic generation of Chinese Songci[J]. Journal of Software, 2010, 21(3): 427-437.
[13] 应勤伟, 李元香, Shen Phillip C Y, 等. 演化多目标优化中的几何热力学选择[J]. 计算机学报, 2010, 33(4): 754-767.
YING Qinwei, LI Yuanxiang, Shen Phillip C Y, et al. Geometric thermo dynamical selection for evolutionary multi-objective optimization[J]. Chinese Journal of Computers, 2010, 33(4): 754-767.
(编辑 陈爱华)
收稿日期:2014-04-02;修回日期:2014-06-26
基金项目(Foundation item):国家自然科学基金资助项目(61202136);江苏省高校自然科学研究项目(13KJD520007);南京晓庄学院校级科研项目(2012NXY14) (Project(61202136) supported by the National Natural Science Foundation of China; Project(13KJD520007) supported by the University Natural Science Research Project of Jiangsu Province; Project(2012NXY14) supported by the Scientific Research Project of Nanjing XiaoZhuang University)
通信作者:赵红,博士,讲师,从事人工智能和计算机网络研究;E-mail: zhaohong4977@163.com

