������۽ṹ�Ĵʻ㻯�䷨����ģ��
Ԭ���
(�����ƾ���ѧ ��ϢѧԺ��������֪ʶ���̽���ʡ�ص�ʵ���ң����� �ϲ���330013)
ժҪ�����ڡ���ۡ��Ǻ�������һ���Ƚϱ��ʵ��ص㣬һ��1���������۽ṹȷ����������Ӧ�ú������Ĵʽ��д���ͱȽ�������Ӷ�Ҳ���ԱȽ�ֱ�ӵص������ӵĽṹ��Ϊ�ˣ�������Ĵ������䷨����ģ�ͣ����������۽ṹ�Ĵʻ㻯�䷨����ģ�ͣ�����ḻ��������Ϣ������������Ϣ����۽ṹ�����������Ϣ�����øĽ��ľ䷨����ģ�ͽ��о䷨����ʵ�顣ʵ����������ģ�͵ľ�ȷ�ʺ��ٻ��ʷֱ�Ϊ88.65%��87.26%���ۺ�ָ��F��Collins�����Ĵ������䷨����ģ�͵�������6.51%��
�ؼ��ʣ���۽ṹ�����������ϵ�����Ĵ��������䷨����ģ��
��ͼ����ţ�TP391.1 ���ױ�־�룺A ���±�ţ�1672-7207(2012)05-1808-06
A lexicalized syntactic parsing model based on valence structure
YUAN Li-chi
(Jiangxi Key Laboratory of Date & Knowledge Engineering,
School of Information Technology, Jiangxi University of Finance & Economics, Nanchang 330013, China)
Abstract: Based on the fact that ��valency�� is an essential semantic feature of Chinese words, once the valency of word is determined, the collocation of the word is clear, and the sentence structure can be directly derived, a syntactic parsing model combining valence structure with head-driven statistical syntactic parsing models was purposed, which incorporates rich semantic information including semantic dependency and semantic collocation. Experiments were conducted for the refined statistical parser. The results show that using refined statistical parser can achieve 88.65% precision and 87.26% recall, comprehensive index F is improved by 6.51% compared with the head-driven parsing model introduced by Collins.
Key words: valence structure; semantic dependency; head-driven; syntactic parsing model
�䷨����[1]�ֳ��ķ�������ͨ������䷨����ȷ�����ӵĽṹ�Լ�����ɳɷ�֮��Ĺ�ϵ���䷨��������Ȼ���������һ���ؼ���ɲ��֣��Ƕ���Ȼ���Խ��н�һ����������Ļ���������Ȼ���������У�ȷ��ʵ��ʶ���¼�ʶ�����Ϣ��ȡ����������ɫ��ע�����������������Ȼ���Դ�����������ڿɿ��ľ䷨����������䷨�������о������Ϊ2��;�������ڹ���ķ����ͻ���ͳ�Ƶķ���[2-9]�����ڹ���ķ�������֪ʶΪ�������������(Rationalism)������������ѧ����Ϊ������ǿ������ѧ�Ҷ������������ʶ�����÷�����Ĺ�����ʽ���������������Ϊ���������ԡ�����ͳ�Ƶľ䷨����������ij�ַ�ʽ�����Ե���ʽ�����������������������������������ͨ������֪�䷨���������ѵ����ã�����Ǿ䷨����ģ�͡��������������ķ�(PCFG)�ǽ�ͳ�Ʒ������뵽�������������ϵͳ���γɵ������ϵͳ��Ȼ���������PCFGʵ�����ǽ�����һЩ�dz����뻯�Ķ����Լ������֮�ϣ�����Щ���貢������ʵ�ʣ����ǣ����PCFG��ʵ��Ч�������롣Ŀǰ�ĸ�������������о���Ҫ���������ͻ����Щ�����Լ����ϡ�ͨ���ſ���Щ������������������ȷ�ʵõ��ܴ���ߡ��ʻ㻯�ľ䷨������Ŀǰ��Ȼ���Դ����о������ƺ��ȵ㣬��PCFG������ʻ���Ϣ�������˴ʻ㻯��PCFG���ֲ��˴ʻ���Ϣ�IJ��㡣�䷨�ṹ�Ǿ䷨��ʽ���������ݵ�ͳһ�塣�Ծ䷨�ṹ����Ҫ������ʽ��������䷨��η������䷨��ϵ�����Լ����ͷ����ȣ�����Ҫ������������������Ծ䷨�ṹ���������Խȫ�桢Խ��̣���Խ�п��ܶԾ䷨��ʽ�ϵĸ��������Կ�ѧ�����Ľ��͡�Ŀǰ�Ĵʻ㻯�䷨���������Ĵ������䷨����ģ�͡�������������Ǵ���֮������������ϵ[10-13]��û���������ķ�ӳ���������ص����Ϣ����������[14-16]����������������Ϣ������Щ������Ϣ�Ծ䷨���������������������Ҫ�ġ����������ľ䷨�������۲�û����Ч�̻�������ı������ԣ�����Ŀǰ����䷨��������������Ч����Ӣ��������ϴ��ں����У���۽ṹ���ԽϺõؿ̻�������ӵľ䷨�ṹ�����幹�ɹ�ϵ����ˣ��б�Ҫ��ϵͳ���㷺���о���ʽ������ۣ����������������ڴ˻����Ͻ����䷨����ģ�͡�
1 ����
������ɷ�������ѧ��Tesniere��1959������ģ����������Ȼ�ʻ㻯�ģ�ֱ�Ӱ��մ���֮��������ϵ����ģ�͡�����������дʻ�����汾��������ģ�����ͬ���Լ�������������ͨ�ģ���ˣ��������һ�ֿ�Խ���Խ��ޡ��۽�ʾ�����������ڹ��ɵľ䷨���ۡ�������ķ���ͬ�������ķ�������Ϊÿ�������д���1��Ψһ���Ĵʣ�֧���ž������������еĴʣ�������ֱ�ӻ������������Ĵʣ�ͬʱ�������г������Ĵ���ÿ���ʶ�ֻ��1����֧�䡣�����ķ�����ʹ������䷨����ʾ����������Ľṹû�з��ս�㣬�����֮��ֱ�ӷ��������ϵ������1������ԣ�����һ���Ǻ��Ĵʣ�Ҳ��֧��ʣ���һ�������δʣ�Ҳ�д����ʡ������ϵ��1������ʾ�������满���ڱ����У��涨���满�ķ������ɴ�����ָ��֧��ʡ�
Collins��������Ĵ������䷨����ģ��[17]���ʻ������ϵ���뵽�ķ��У�ͬ���������ֱ�Ӱ��մ���֮��������ϵ����ģ�͡�����˵��Ŀǰ�Ĵʻ㻯�䷨�����������Ǵ���֮������������ϵ����û���������ķ�ӳ���������ص����Ϣ���������ࡢ ��������������Ϣ�����ھ��ӡ�Astronomers saw stars with telescopes���дʡ�telescopes������������ϼ�����ֱ�ӵĺ��Ĵʡ�with���йأ�Ҳ���������ӵĺ��Ĵʡ�saw���йأ��������������������������������������Լ����telescopes���͡�saw��֮�������������ϵ��ͬ�����ں�����ӡ���������ʱ���˸��ס��У�������������������������������������Լ�������ᡱ�͡����ס�֮�������������ϵ�������ֹ�ϵ�Ծ䷨������������Ҫ�ġ�
�����������һ����ͬ������Ϊ����Դ�ڷ�������ѧ����˹��Ү��������ѧ˼�롣����½�����ġ��ִ����������о��������е�˵��[19]�����ۡ�(valency/valenz����ơ���ۡ�/����)��һ����Դ�Ի�ѧ����ѧ�С��ۡ��ĸ�������˵���ڷ��ӽṹ�и�Ԫ��ԭ����Ŀ֮��ı�����ϵ������˹��Ү�����ѧ���������ۡ��ĸ����Ϊ��˵��1��������֧����ٸ����ʴ��顣�硰�ԡ���1�����۶��ʣ���Ҫ֧��2�����ʴ��飬�ֱ�˵����˭�ԡ��͡���ʲô��������������1�����۶��ʣ���Ҫ֧��3�����ʴ��飬�ֱ�˵����˭����������˭��������ʲô�������ѿ����������;��Ӽ����������(�ر��������ɫ��ע)���Ž��ܵ���ϵ�����ڣ���۵��о��Ѿ������������ڶ��ʣ����ݴʺ����ʵ����Ҳ�кܶ������о��������ݴʡ����ᡱ�����ʡ���㡱����һ�ۣ��ֱ���Ҫ֧��1�����ʴ��飬����˵����˭���ᡱ�͡�˭�Ľ�㡱��
���������о�������������ˡ��ִ����������о���[17, 19]���⣬��Ҫ����Ԭع�ֵġ����ﶯ�ʵ�����о�����[19]������������Ŀǰ��Ҫ����ͣ��������ѧ�IJ��棬��û�п����������������㷨ģ�͵��о���
2 ��۽ṹ����ʽ��
��������[19-20]���о��༯�����о����������ص㣬��û�п����������ӵ���۽ṹ��ϣ������1�־��ӵ���۽ṹ���ܷ�ӳ���������д���֮�����۹�ϵ����ϣ����ע����۹�ϵ�����漰���������ʶ���ֱ�ӵĹ�ϵ��Ҳ�漰���������ʶ�����ݴ������ʶ������������붯�����ݴʶ���֮��Ĺ�ϵ��Ҳ����˵����۽ṹӦ����һ�������ľ䷨�ṹ��Ӧ�ðѾ��������еĴ��ﶼ�����������������еĶ���ṹ��������ṹ��һ�ֲ��䡣
�������У�����������ָ����������ʱ���˸��ס����־��ӣ���һ��ľ�ʽ��ȣ��ɿ������־�ʽ�������ص㣺(1) ���е����������ﶯ��û��ֱ�ӵ������ϵ���������ﶯ�ʵı�������ɷ֣�����Ϊ�������͵ķǵ����ԣ�(2) ���б����Ϊ���ﶯ�ʵ�ʩ�£�����Ϊ�������͵ķǵ����ԣ�(3) ������������ϵ���ǿ����ʶ��ǿ�2���ɷ�֮���ڴʻ������ϵġ�����-��������ϵ����������ص�������ﶯ��(�����ݴ�)Ϊһ��(��һ��)��
�ԡ������ʮ�����˶��ӡ�������������ʱ���˸��ס�Ϊ���������������������е���۽ṹ����ͼ1~4��ʾ������ͼ2��ͼ4��ʾΪ�������һ�ֿ��ܵ���۽ṹ��ʽ��������ʽ�������о������л��ᷢ���仯�Ľ������Կ�����2�����Ӿ�����ʽ��ͬ����������ȴ���в�ͬ����۽ṹ���ɼ��봫ͳ�Ķ���ṹ������������ȣ���۽ṹ��ӳ�˸���������ص㡣ͬʱ������������Ϣ�Ƚ��ȶ��������۽ṹ����ʽ�ϲ���1����������1������ͼ����ˣ���۽ṹ���бȶ�������������ǿ�ı�����������DZ����ø��ߵľ䷨����������ܡ���Ϊ�ھ��ӡ���������ʱ���˸��ס��У������ᡱ����۵ģ������ˡ��͡����ס�����һ�۵ģ���������ʱ����1�����۵�ʱ�丱��(2����۳ɷֱַ�˵����˭���ꡱ�������귢����ʲô���顱)�����ھ��ӡ������ʮ�����˶��ӡ��У�����骡�����۵ģ������ӡ���һ�۵ģ������ˡ��͡���ʮ�ꡱ�������۵ġ�������Щ����������Ϣ���Ϳ��ԱȽ�ȷ�ػ��������۽ṹ��
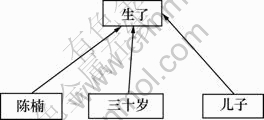
ͼ1 ���ӡ������ʮ�����˶��ӡ�������
Fig.1 Dependent tree of sentence �������ʮ�����˶��ӡ�
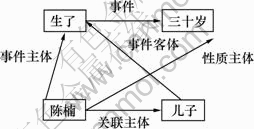
ͼ2 ���ӡ������ʮ�����˶��ӡ���һ�ֿ�����۽ṹ
Fig.2 Possible valence structure of sentence �������ʮ�����˶��ӡ�
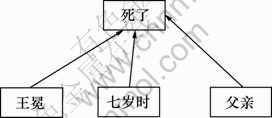
ͼ3 ���ӡ���������ʱ���˸��ס�������
Fig.3 Dependent tree of sentence ����������ʱ���˸��ס�
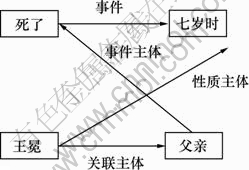
ͼ4 ���ӡ���������ʱ���˸��ס���һ�ֿ�����۽ṹ
Fig.4 Possible valence structure of sentence ����������ʱ���˸��ס�
�䷨�ṹ�Ǿ䷨��ʽ���������ݵ�ͳһ�塣�Ծ䷨�ṹ����Ҫ������ʽ����������䷨��η������䷨��ϵ�����Լ����ͷ����ȣ�����Ҫ������������������Ծ䷨�ṹ���������Խȫ�桢Խ��̣���Խ�п��ܶԾ䷨��ʽ�ϵĸ���������п�ѧ�������Ľ��͡��ھ䷨����������������Ϣ��������Ϣ���������ࡢ������䡢����������Ϣ�ȡ����ĵĻ���˼���ǣ��ھ��Ӷ���ṹ������ṹ�Ļ����ϣ����û���������ۿ���������ʵ�����õ�������۽ṹ�������������þ�����۽ṹ�Ծ��������ϵ���б�Ҫ���������ھ䷨����ģ��������ḻ��������Ϣ���Ȱ����ɾ䷨����������ȷ��������������Ϣ��Ҳ�����ɾ��ӷ�������Ӧ��۽ṹͼȷ�������������Ϣ��
3 ������۽ṹ�Ĵʻ㻯�䷨����ģ��
3.1 ���Ĵ������䷨����ģ�͵Ļ���ԭ��
���Ĵ������䷨����ģ��������д����ԵĴʻ㻯ģ�͡�Ϊ�˷��Ӵʻ���Ϣ�����ã����Ĵ�����ģ��Ϊ�ķ������е�ÿһ�����ս��(none terminal)��������Ĵ�/������Ϣ����������ʻ���Ϣ�����ɱ��⽫�������ص�ϡ�����⡣Ϊ�˻���������⣬���Ĵ�����ģ�Ͱ�ÿһ���ķ���������ֲ�ֽ�Ϊ���֣��ֱ�Ϊ��1�����ijɷ֣����ɸ���������ߵ����γɷ֣����ɸ��������ұߵ����γɷ֡�����д������ ��ʽ��
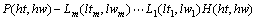
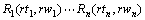 (1)
(1)
���У�PΪ���ս����H��ʾ���ijɷ֣�L1��ʾ������γɷ֣�R1��ʾ�ұ����γɷ֣�hw��lw��rw���dzɷֵĺ��Ĵʣ�ht��lt��rt�ֱ������ǵĴ��ԡ���һ�����裬������P�������ijɷ�H��Ȼ����HΪ���ķֱ�����ز����������ߵ��������γɷ֡�����������(1)ʽ���ķ�����ĸ���Ϊ��

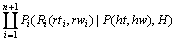 (2)
(2)
����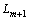 ��
��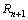 �ֱ�Ϊ�������ߵ�ֹͣ���š�
�ֱ�Ϊ�������ߵ�ֹͣ���š�
3.2 ������۽ṹ��������Ĵ�����ģ�͵Ĵʻ㻯�䷨����ģ��
��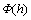 ��ʾ�䷨�����Ѿ����ɵĴ����뵱ǰ���Ĵ�h�����������ϵ(�ɾ䷨��ȷ��)����������ϵ(�ɾ��ӷ�������Ӧ����۽ṹͼȷ��)�Ĵʺ������ϵ���������ŵı�ʾͬ����һ�¡��ڱ��ĵľ䷨����ģ���У�ÿһ���ķ�����д��������ʽ��
��ʾ�䷨�����Ѿ����ɵĴ����뵱ǰ���Ĵ�h�����������ϵ(�ɾ䷨��ȷ��)����������ϵ(�ɾ��ӷ�������Ӧ����۽ṹͼȷ��)�Ĵʺ������ϵ���������ŵı�ʾͬ����һ�¡��ڱ��ĵľ䷨����ģ���У�ÿһ���ķ�����д��������ʽ��
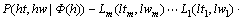
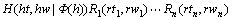 (3)
(3)
����(3)ʽ���ķ�����ĸ���Ϊ:

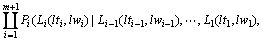
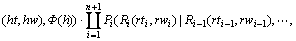
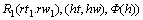 (4)
(4)
���У����ֱ�Ϊ�������ߵ�ֹͣ���š�ʽ(4)�еĸ���
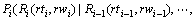
�ɷֽ�Ϊ2�����ʣ�
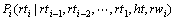 (5)
(5)
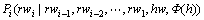 (6)
(6)
�ij˻�����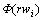 ��ʾ
��ʾ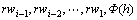 �����뵱ǰ��
�����뵱ǰ��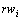 ����������ϵ�Ĵʣ�����:
����������ϵ�Ĵʣ�����:
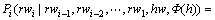
 (7)
(7)
�ټٶ�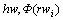 �����������������У�
������������������
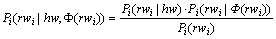 (8)
(8)
ʽ(8)�и��� ����Ϊ
����Ϊ ��Ļ���Ϣ�������ʽ(8)�ĸ�������ʮ����ȷ��������������
��Ļ���Ϣ�������ʽ(8)�ĸ�������ʮ����ȷ��������������
�䷨�������йش��Ա�ע�ĸ���Ϊʽ(5)���ټٶ� ��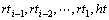 ����
����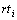 ��������������:
��������������:

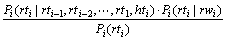 (9)
(9)
(9)ʽ�и���
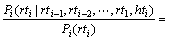
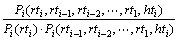 (10)
(10)
��Ϊ��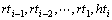 ��Ļ���Ϣ�����ʽ(9)�ĸ�������ʮ����ȷ��Ҳ������������ʽ(9)�еĸ���
��Ļ���Ϣ�����ʽ(9)�ĸ�������ʮ����ȷ��Ҳ������������ʽ(9)�еĸ���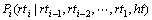 ���Կ�������������ڴʴ��Դ����ϵ�Ĵ��Ա�עģ���������
���Կ�������������ڴʴ��Դ����ϵ�Ĵ��Ա�עģ���������
����˵��Ŀǰ�ʻ㻯�����������ķ������еĶ����Լ�����������������ϣ��Ȳ��ʺ���Ӣ�ģ����Ӳ��ʺ������ġ��ڱ��ĵľ䷨����ģ���У������������Լ���ȡ�������Ĵ������䷨����ģ���еĶ����Լ��衣��ͳ��ѧ�ĽǶ���˵��������������Լ��裬�����Լ����ǹ�ǿ���裬����������Ҳ������ �ϡ�������þ䷨����ģ���������Ե�ʵ���������̡�ͨ����Collinsģ�͵Ĺ�����зֽ���ģ�������۽ṹ��������Ĵ�����ģ�͵Ĵʻ㻯�䷨����ģ���ܹ����õ���������(�Ȱ����ɾ䷨��ȷ��������������Ϣ��Ҳ�����ɾ��ӷ�������Ӧ����۽ṹͼȷ�������������Ϣ)�����Է���֪ʶ����߾䷨������ȷ�ʡ�
4 ʵ����
��������ȡ�Ա�����������(CHTB)5.0�汾����ȡ�����»������š�Sinorama������־�Լ�������š�CTB����������������(LDC)����������1�����Ͽ⣬Ϊ����䷨�����о��ṩ��һ��������ѵ��������ƽ̨�������������507 222���ʣ�824 983�����֣�18 782�����ӣ���890�������ļ���Ϊ����ѵ�������������Ͳ��Լ���ƽ�����������Դ�������Ϸָ����£����ļ�301~320��611~630��Ϊ���Լ������ļ�271~300��631~660��Ϊ���Լ��������ļ���Ϊѵ�������ڱ��ĵ�����ʵ���У�ģ�͵IJ������Ǵ�ѵ�����в��ü�����Ȼ�����Ƴ����ġ�
���Խ��Ϊ���õ�4������ָ�꣬��ȷ��P���ٻ���R���ۺ�ָ��F�ͽ�������CB���䶨�����¡�
��ȷ��(Precision)���������䷨����ϵͳ�����������гɷ�����ȷ�ɷֵı�����
�ٻ���(Recall)���������䷨����ϵͳ��������������ȷ�ɷ���ʵ�ʳɷ��еı�����
�ۺ�ָ�꣺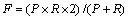 ��
��
��������CB����������1���������������ijɷֱ߽罻��ijɷ���Ŀ��ƽ������
ʵ���в��õľ䷨����Baselineϵͳ��Daniel M.Bikel����Collinsģ��ʵ�ֵ�DBParser����1��ʾΪbaselineϵͳ�Ľ�ģ�͵ľ䷨����ʵ������
��1 �䷨����ʵ����
Table 1 Experimental results of language parsing

�ӱ�1���Կ����������ڹ���ķֽ⼰���ʼ����У����������ɾ䷨����������ȷ��������������Ϣ�����������ɾ��ӷ�������Ӧ��۽ṹͼȷ�������������Ϣ���Ľ�ģ�͵�ȷ��P���ٻ���R���ۺ�ָ��F����������CB��Collins�����Ĵ������䷨����ģ�͵���Ⱦ�����������ߡ�
5 ����
(1) Ŀǰ�Ĵʻ㻯�䷨���������Ĵ������䷨����ģ�͡�������������Ǵ���֮������������ϵ��������۽ṹ��������Ĵ�����ģ�͵Ĵʻ㻯�䷨����ģ���ڹ���ķֽ⼰���ʼ����У����������ɾ䷨����������ȷ��������������Ϣ��Ҳ�������ɾ��ӷ�������Ӧ��۽ṹͼȷ�������������Ϣ����������������ߡ�
(2) ģ�͵ľ�ȷ�ʺ��ٻ��ʷֱ�Ϊ88.65%��87.26%���ۺ�ָ��F���ollins�����Ĵ������䷨����ģ�͵�������6.51%��
(3) �����о��ؿ�������ѧ���о������������ѧ�ı����о�������ͳ������ѧ�о��ṩ��һ��ȫ�µ��ӽǣ����������Ӧ�õ����ô�ͳ������������ѵ����⣬���Դ���һЩ���㣬�磺���������о��������ۻ���ȱ��ʵ�������ԣ����������о�ʱ�䲻�Ǻܳ����������۹۵��﷽ѧ���д�ͳһ������һ���̶�����Լ�˸�ѧ�Ƶķ�չ���й����������ۺ�Ӧ���д���һ���о���
�ο����ף�
[1] Manning C D, Schutze H. Foundations of statistical natural language processing[M]. London: MIT Press, 1999: 184-197.
[2] Seo K J, Nam K C, Choi K S. A probalistic model of the dependency parse of the variable-word-order languages by using ascending dependency[J]. Computer Processing of Oriental Languages, 2000, 12(3): 309-322.
[3] XUE Nian-wen, XIA Fei, Chiou F D, et al. The Penn Chinese treebank: Phrase structure annotation of a large corpus[J]. Natural language engineering, 2005, 11(2): 207-238.
[4] Fung P, Ngai G, Yang Y S, et al. A maximum-entropy Chinese parser augmented by transformation-based learning[J]. ACM Trans on Asian language Processing, 2004, 3(2):159-168.
[5] Vilares J, Alonso M A,Vilares M. Extraction of complex index terms in non-English IR: A shallow parsing based approach[J]. Information Processing and Management, 2008, 44(4): 1517-1537.
[6] �Ծ�, �Ʋ���. ����������ʶ���ṹ����ģ��[J]. �����ѧ��, 1999, 22(2): 141-146.
ZHAO Jun, HUANG Chang-ning. The model for Chinese BaseNP structure analysis[J]. Chinese Journal of Computers, 1999, 22(2): 141-146.
[7] ��ӡ��, �����, ��ʤ��, ��. �㼶������ʾ䷨����[J]. ����ѧ��, 2011, 22(2): 245-257.
DAI Yin-tang, WU Cheng-rong, MA Sheng-xiang, et al. Hierarchically classified probabilistic grammar parsing[J]. Journal of Software, 2011, 22(2): 245-257.
[8] Aviran S, Siegel P H, Wolf J K. Optimal parsing trees for run-length coding of biased data[J]. IEEE Transaction on Information Theory, 2008, 54(2): 841-849.
[9] ZHOU De-yu, HE Yu-lan. Discriminative training of the hidden vectors state model for semantic parsing[J]. IEEE Transaction on Knowledge and Data Engineering, 2009, 21(1): 66-77.
[10] Seo K J, Nam K C, Choi K S. A probalistic model of the dependency parse of the variable-word-order languages by using ascending dependency[J]. Computer Processing of Oriental Languages, 2000, 12(3): 309-322.
[11] Ԭ���. ���������ϵ�ľ䷨����ͳ��ģ��[J]. ���ϴ�ѧѧ��: ��Ȼ��ѧ��, 2009, 40(6): 1630-1635.
YUAN Li-chi. Statistical language paring model based on dependency[J]. Journal of Central South University: Science and Technology, 2009, 40(6): 1630-1635.
[12] ������, ������, Ԭ����, ��. ��������䷨���������������ɫ��ע[J]. ������Ϣѧ��, 2010, 24(1): 25-30.
WANG Bu-kang, WANG Hong-ling, YUAN Xiao-hong, et al. Chinese dependency parse based semantic role labeling[J]. Journal of Chinese Information Processing, 2010, 24(1): 25-30.
[13] ��Ƽ, �ڳ���. �������б�עģ�͵ķֲ�ʽ����䷨��������[J]. ������Ϣѧ��, 2010, 24(6): 14-22.
JIAN Ping, ZONG Cheng-qing. Layer based dependency parsing by sequence labeling models[J]. Journal of Chinese Information Processing, 2010, 24(6): 14-22.
[14] GAO Jian-feng, Goodman J, MIAO Jiang-bo. The use of clustering techniques for language model�Capplication to Asian language[J]. Computational Linguistics and Chinese Language Processing, 2001, 6(1): 27-60.
[15] Lee L. Similarity-Based approaches to natural language processing[D]. Cambridge, MA: Harvard University, 1997: 35-56.
[16] Ԭ���. �������ƶȵĴʾ����㷨�Ϳɱ䳤����ģ��[J]. С���ͼ����ϵͳ, 2009, 30(5): 912-915.
YUAN Li-chi. Word clustering based on similarity and vari-gram language model[J]. Journal of Chinese Computer��Systems, 2009, 30(5): 912-915.
[17] �ܹ���. �ִ����������о�[M]. ����: �ߵȽ���������, 2011: 21-82.
ZHOU Guo-guang. The study of modern Chinese valence grammars[M]. Beijing: Higher Education Press, 2011: 21-82.
[18] Collins M. Head-driven statistical models for natural language parsing[D]. Pennsylvania: The University of Pennsylvania, 1999: 65-78.
[19] Ԭع��. ���������о�[M]. ����: ����ӡ���, 2010: 55-170.
YUAN Yu-lin. The study of Chinese valence grammars[M]. Beijing: Commercial Press, 2010: 55-170.
[20] �����. ��ʽ�����[J]. �й�����, 2000(4): 291-297.
SHEN Jia-xuan, Vaiency and sentence patterns[J]. Zhongguo Yuwen, 2000(4): 291-297.
[21] ����Ӣ. �����ۡ���о�����[J]. �ӱߴ�ѧѧ��: ����ѧ��, 2011, 44(2): 39-42.
NIE Hong-ying. Review of ��coordination valence�� in Chinese grammar[J]. Journal of Yanbian University: Social Science, 2011, 44(2): 39-42.
(�༭ �²ӻ�)
�ո����ڣ�2011-09-11�������ڣ�2011-11-23
������Ŀ��������Ȼ��ѧ����������Ŀ(60763001)������ʡ��Ȼ��ѧ����������Ŀ(2010GZS0072)������ʡ�������Ƽ���Ŀ(GJJ12271)
ͨ�����ߣ�Ԭ���(1973-)���У����������ˣ���ʿ�����ڣ���������ʶ������Ȼ���Դ����о����绰��0791-3983891��E-mail: yuanlichi@sohu.com

