基于统计的句法分析方法
袁里驰
(江西财经大学 信息管理学院,数据与知识工程江西省高校重点实验室,江西 南昌,330013)
摘要:句法分析是自然语言处理的一个基本问题,随着大规模标注树库的建立,基于树库的统计句法分析逐渐成为现代句法分析的主流技术。在介绍句法分析树库及句法分析性能评测方法的基础上,对主要句法分析统计模型和中文句法分析的研究现状进行简要综述和分析,并探讨和总结了基于统计的句法分析模型的不足之处和发展趋势,指出现有的汉语句法分析方法不适合汉语的特点,没有有效刻画出汉语的本质特性,导致目前汉语句法分析性能与英语相比相差较大;将语义信息融入句法分析,并在此基础上建立句法分析与语义角色标注联合学习统计模型,将是句法分析的一个重要研究方向。
关键词:句法分析;统计模型;语义分析;自然语言处理
中图分类号:TP391.1 文献标志码:A 文章编号:1672-7207(2014)08-2669-07
Statistical syntactic parsing methods
YUAN Lichi
(Jiangxi Key Laboratory of Data and Knowledge Engineering, School of Information Technology,
Jiangxi University of Finance and Economics, Nanchang 330013, China)
Abstract: Syntactic parsing is a fundamental problem of natural language processing, and statistical syntactic parsing based on treebank gradually becomes the mainstream techniques of modern syntactic parsing following the building of large scale annotated treebanks. Firstly, the main treebanks and the main methods to measure syntactic parsing system performances were described. Secondly, the main statistical syntactic parsing models and the current researches on the Chinese syntactic parsing were presented and analyzed. Finally, the problems and the future study trends of statistical syntactic parsing were discussed and summarized. Is is pointed that Chinese syntax analysis methods are not suitable for the features of Chinese, and they do not effectively characterize the essential features of Chinese, thus the performances of syntactic parsing of Chinese are far below the performances of English. To integrate semantic information in syntactic parsing and to establish a joint syntactic and semantic statistical parsing model based on. semantic analysis will be a important study direction of syntactic parsing.
Key words: syntactic parsing; statistical model; semantic parsing; natural language processing
句法分析又称文法分析,是指根据给定的语法,自动地识别出句子所包含的句法单位和这些句法单位之间的关系。句法分析在自然语言处理领域中具有十分重要的地位。汉语的理解一般分为以下步骤:原文输入、句子词语切分及词语属性特征标注、语法及句法分析、语义及语用和语境分析、生成目标形式表示、句群及篇章理解等。句子分析上接篇章理解,下联词汇分析,起着承上启下的作用。词汇分析是基础,句子分析是中心,篇章理解是最终目的。那么,一旦得到了句子成分的计算机表示,无论是应用于句群划分、篇章理解,还是机器翻译、机器释义、人机对话或情报检索等方面,都有着实际意义。句法分析同时也是公认的一个研究难题。自20世纪50年代初机器翻译课题被提出以来,自然语言处理研究已经有60年历史,句法分析一直是阻碍自然语言处理发展的主要障碍。困扰句法分析的2个难点[1-2]在于:
(1) 歧义。给定一个合理的语法,即使对于一个非常简单的句子,也可以有多种句法分析结果。
(2) 搜索空间巨大。句法分析是一个极为复杂的任务,候选树个数随句子长度呈指数级增长,搜索空间巨大。
因此,在设计句法分析模型时,必须控制好模型的复杂度,以保证句法分析器能够在可接受的时间内搜索到最优的句法分析树。句法分析的研究大体分为2种途径:基于规则的方法和基于统计的方法[3-11]。基于规则的方法是以知识为主体的理性主义(rationalism)方法,以语言学理论为基础,强调语言学家对语言现象的认识,采用非歧义的规则形式描述或解释歧义行为或歧义特性。基于规则的方法在处理大规模真实文本时,会存在语法规则覆盖度有限、系统可迁移性差等缺陷。20世纪90年代初,自然语言处理的任务开始从小规模受限语言处理走向大规模真实文本处理。随着大规模标注树库的建立,基于树库的统计句法分析逐渐成为现代句法分析的主流技术[12]。构建统计句法分析模型的目的是以概率的形式评价若干个可能的句法分析结果(通常表示为语法树形式)并在这若干个可能的分析结果中直接选择一个最可能的结果。基于统计的句法分析模型[3]其实质是一个评价句法分析结果的概率评价函数,即对于任意一个输入句子s和它的句法分析结果t,给出一个条件概率P(t|s),并由此找出该句法分析模型认为概率最大的句法分析结果,即找到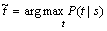 ,句法分析问题的样本空间为S×T(其中S为所有句子的集合,T为所有句法分析结果的集合)。本文作者讨论句法分析树库及句法分析性能评测方法,对现有的主要句法分析统计模型和方法进行简要介绍和评述,对中文句法分析的研究现状进行综述,并探讨基于统计的句法分析模型的不足之处和发展趋势。
,句法分析问题的样本空间为S×T(其中S为所有句子的集合,T为所有句法分析结果的集合)。本文作者讨论句法分析树库及句法分析性能评测方法,对现有的主要句法分析统计模型和方法进行简要介绍和评述,对中文句法分析的研究现状进行综述,并探讨基于统计的句法分析模型的不足之处和发展趋势。
1 句法分析树库及性能评测
1.1 句法分析语料库
统计句法分析模型的训练[4]可以采用有指导学习方式,也可以采用无指导学习方式。无指导学习方式一般只需要给定一套文法和若干个没有任何句法标记的句子就可以自动地估计出模型的所有参数。有指导学习方式通常需要从一个树库中获取句法分析模型的各种参数和句法知识。所谓树库是指对句子中的句法成分进行了划分和标注的语料,从中可以提取出大量有用的句法分布信息。不管是有指导的方法还是无指导的方法它都需要树库去测试其句法分析的精度, 因此,树库的建设对于统计句法分析器的开发与研究有着基础性的支撑作用[1]。
1961年,世界上第一个大规模电子语料库―布朗语料库出现,标志着语料库语言学诞生[5]。英语的树库研究起步较早,发展也很快。其中2个比较大的工程项目是:英国的Lancaster-LeedS树库项目和美国宾夕法尼亚大学的PennTreebank项目[1, 4]。1984―1988年的5年间,英国Lancaster大学的UCREL研究小组总共加工产生了200多万词的树库语料。Penn TreeBank是宾夕法尼亚大学在新闻语料上标注的英文句法分析树库。其前身为ATIS和华尔街日报(Wall Street Journal)树库,它的第1版本出现于1991年,第2版本即Penn TreeBank出现于1994年。Penn TreeBank除文法标注外,还标注了部分语义信息。从第1版本到现在,整个过程一直都在不断地维护和修正,标注规模已接近5万个句子,100万个单词。Penn treebank具有较高的一致性和标注准确性,是目前研究英文句法分析所公认的标注语料库。此外,比较著名的英语树库还有IBM研究院树库,其句子取自计算机手册;在树库建设技术上,Charniak等[13]介绍了使用自动句法分析器和文法理论辅助标注树库的算法。
中文树库[2, 4]建设较晚,比较著名的有中文宾州树库(Chinese Treebank)、清华大学中文树库(Tsinghua Chinese Treebank)、台湾中研院树库(Sinica Treebank)北京大学计算语言所的《人民日报》语料、哈尔滨工业大学机器翻译研究室树库等。Chinese TreeBank (CTB)是宾夕法尼亚大学从1998年开始标注的汉语句法树库。语料来源于中国大陆、香港、台湾等媒体新闻信息。自2000年发布CTB1.0以来,已多次对语料进行了更正和添加,目前的最新版本为CTB6.0。该版本包含了2 306篇新闻文章,由28 295个句子构成,共781 351个词。CTB的标注方法沿用了英文树库的标注体系,共包括33种词性标记和19种短语类别标记。目前,绝大多数的中文句法分析研究均以CTB为基准语料库。Tsinghua Chinese TreeBank(TCT)是清华大学计算机系智能技术与系统国家重点实验室人员从汉语平衡语料库中提取出100万汉字规模的语料文本,经过自动句法分析和人工校对,形成高质量的标注有完整的句法结构树的中文句法树库语料。Sinica TreeBank是台湾中研院词库小组从中研院平衡语料库(Sinica Corpus)中抽取句子,经由电脑自动分析成句法结构树,并加以人工修改、检验后所得的成果。
1.2 句法分析模型性能评测
句法分析模型性能评测是句法分析研究的重要内容,它决定句法分析模型的选择和优化。语料库语言学出现以后,对句法分析模型的评价通常都是基于某一语料库进行[14]。其方法是:从语料库中选取一部分句子,将语料库标注的结果与句法分析系统标注的结果进行对比。基于语料库的方法其优点是语料库的建设是在统一的标注体系下进行,标注的句子具有较高的一致性,在此基础上的评价具有较好的一致性。若语料库规模较大,则可以进行较大规模的评价,且评价具有较强的客观性和可比性。
目前使用比较广泛的句法分析性能评测方法是PARSEVAL 评测体系[6-7],它是一种粒度比较适中、较为理想的评价方法,主要指标有准确率(P)、召回率(R)、交叉括号数(C)和综合指标F。其定义如下。
精确率P用来衡量句法分析系统所分析的所有成分中正确成分的比例。
召回率R用来衡量句法分析系统分析出的所有正确成份在实际成分中的比例。
综合指标F: 。
。
交叉括号数C:给出了1棵树中与其他树的成分边界交叉的成分数目的平均数。
2 句法分析统计模型的研究现状
自20世纪90 年代以来,随着语料资源的获取变得容易,基于统计的方法开始在自然语言处理领域成为主流。这种方法采用统计学的处理技术从大规模语料库中获取语言分析所需要的知识,放弃人工干预,减少对语言学家的依赖。它的基本思想是:(1) 使用语料库作为唯一的信息源,所有的知识(除了统计模型的构造方法)都是从语料库中获得;(2) 语言知识在统计意义上被解释,所有参数都是通过统计处理从语料库中自动获得的[8]。
基于统计的方法具有效率高、鲁棒性强的优点,大量的实验已经证明了该方法的优越性。目前,统计方法已经被句法分析的研究者普遍采用。为进行统计句法分析,首先要遵循某一语法体系,根据该体系的语法确定语法树的表示形式。目前,在句法分析中使用比较广泛的有短语结构语法和依存语法[9]。
2.1 短语结构语法
当前短语结构句法分析普遍基于概率上下文无关文法(probabilistic context free grammar,PCFG)。大规模的基于上下文无关文法的树库(比如宾州树库库)的出现极大地促进了这一方向的研究。
2.1.1 基于词汇化PCFG的句法分析模型
在早期研究工作中,基于上下文无关文法的短语结构句法分析方法直接从人工标注的树库中读取文法规则,并以相对频率作为规则的概率[10]。这类方法实现简单,但是,先前的研究工作表明这种方法的性能并不理想。其主要原因在于上下文无关文法中的独立性假设,而这些独立性假设在实际情况中往往并不成立。为了突破PCFG所进行的独立性假设条件,很多研究者转向研究基于词汇化PCFG的句法分析模型。词汇化PCFG指在文法规则中引入词汇的信息,即在句法树的每个非终结符节点上标注词汇信息,利用词汇信息放宽上下文无关文法的独立性假设。Magerman[11]最先开展了这个方向的研究工作,论证了词汇信息的有效性。Charniak等[12-14]随后推进了这一方向的研究。
2.1.2 基于改进PCFG的句法分析模型
Petrov等[14]设计实现了基于生成模型的句法分析器。生成模型从句法树和相应句子的联合概率出发,根据合理的独立性假设对从句法树到句子的语言生成过程进行建模,在英文Penn树库上得到的召回率和准确率分别为89.6%和89.8%,性能高于大多数基于词汇化PCFG的句法分析模型。Finkel等[15]指出传统的PCFG模型在计算产生式概率时,采用的是生成模型,利用的信息只限于产生式本身的信息,而没有放眼于整个句子。因此,本文提出在计算产生式概率时,采取判别式模型,利用的信息包括覆盖整个句子的产生式信息、词汇/词性标注信息[13]。虽然基于判别模型的句法分析的研究历史相对较短,但是,基于判别模型的句法分析器已经获得与基于生成模型的句法分析器可比较的性能[16-17]。
2.2 依存语法
近年来,基于依存关系的句法分析受到了越来越多的重视。依存语法由法国语言学家Tesniere提出[4]。依存语法是天然词汇化的,直接按照词语之间的依存关系工作。由于依存语法中词汇的依存本质是语义的,而不同语言间的语义层面是相通的,因此,依存语法是一种跨越语言界限、客观揭示人类语言内在规律的句法理论[6]。不同于短语文法,依存文法理论认为每个句子中存在1个唯一的中心词,支配着句子中其他所有的词,其他词直接或间接依赖于中心词;同时,句子中除了中心词外每个词都只被1个词支配。依存文法可以使用依存句法树表示,依存分析的结构没有非终结点,词与词之间直接发生依存关系,构成1个依存对,其中一个是核心词,也叫支配词,另一个叫修饰词,也叫从属词。依存关系用1个有向弧表示,叫依存弧。
Melchuk[17]对英语的依存语法理论进行了全面系统的研究,Eisner[18]最先将Penn Treebank转化为依存表示形式,然后进行依存句法分析的实验。在数据转换时,Eisner[18]排除了包含连词的句子,对其余的句子使用规则进行自动转换。实验中,Eisner[18]使用面向说话者的生成模型,得到了90.0%的依存准确率。Yamada等[19]将Penn Treebank 中的句子完全转换为依存结构,然后使用确定性的分析算法,获得90.3%的准确率,为英文依存分析工作奠定了坚实的基础。
2.3 多句法分析器的组合
近年来,针对单一模型的局限性,另一个研究重点是多个句法分析器的组合。这种方法是利用多个高精度的基准句法分析器输出多个高概率结果,并结合丰富句法结构特征对它们进行合成处理。目前,合成方式主要有子树重组合[20-21]和候选树重排序[22]。子树重组合是对候选树中的子树进行重组,形成一个新的最优句法树。候选树重排序是对候选树分值进行重新估算,选出分值最高的候选树作为最后的分析结果。文献[22]在实验中采用5个高精度的句法分析器,最优性能如下:召回率为90.6%,准确率为91.3%;子树重组合后实验结果如下:召回率为91.0%,准确率为93.2%。文献[22]进行了候选树重排序,采用Charniak[12]和Petrov等[14]提出的基准句法分析器,并且让这2个句法分析器系统分别输出最优的50个结果,实验的F1为92.6%。
3 中文句法分析研究现状
与英文句法分析相比,中文句法分析研究起步较晚。
在基于非词汇化PCFG的句法分析模型方面,林颖等[23]利用内向―外向算法,从已有小规模中文宾州树库中提取规则,利用大规模已做好分词标注的语料库对规则进行训练,并针对汉语的特点(特别是汉语虚词的特点),引入句法结构共现的概念来减弱PCFG的独立性假设。实验结果表明,引入句法结构共现概率能够提高句法分析器的准确率和召回率。在基于词汇化PCFG的句法分析模型方面,曹海龙[1]将中心词驱动模型应用于哈尔滨工业大学机器翻译研究室树库,基于正确分词,句法分析取得的召回率和准确率分别为80.9%和79.3%。何亮等[24]基于中心词驱动的汉语统计句法分析模型,在词性处理和基本名词短语识别上对Bikel基于Collins中心词驱动概率句法分析模型进行了改进。在基于改进PCFG的句法分析模型方面,Petrov等[14]将自动发现隐藏的组块子类算法应用于中文树库,基于正确分词,在CTB5.0取得的召回率和准确率分别为85.7%和86.9%,是当时已报告的基于正确分词的单模型中文句法分析的最高值。
在汉语方面,依存句法分析的工作在近年来开始受到重视。Zhou[25]是最早从事这方面的研究者之一,他采用分块的思想,应用一些制定的语法规则,先对句子进行分块处理,找出关系固定的语块,然后对整个句子进行依存分析。Lai 等[26]使用基于 span的思想以及Gao 等[27]利用无指导的方法在汉语依存分析方面进行了研究。鉴萍等[28]提出了一种全新的分层式依存句法分析方法。该方法以依存深度不大于1的依存层作为分析单位,自底向上构建句子的依存结构。在层内,通过穷尽搜索得到层最优子结构;在层与层之间,分析状态确定性地转移。车万翔等[29]将主动学习应用到中文依存句法分析,优先选择句法模型预测不准的实例交由人工标注,提出并比较了多种衡量依存句法模型预测可信度的准则。
袁里驰[6]结合中心词驱动句法分析模型,提出了基于配价结构和语义依存关系的句法分析模型。模型在规则的分解及概率计算中引入丰富的语义信息,既包括语义依存信息,也包括配价结构等语义搭配信息, 在CTB5.0取得的召回率和准确率分别为87.43%和88.76%。除了使用单一的句法分析模型外,也有研究者结合多种模型的输出结果,从中选择最优的句法树作为输出,例如,Zhang等[22]以Charniak[12]句法分析器产生的候选句法树为输入,通过系统合成的方案从中选择最优的句法树作为输出。
4 探讨
基于树库的统计句法分析逐渐成为现代句法分析的主流技术,与早期的方法相比,现在的句法分析方法更强调从真实的树库中获取文法知识,使得训练出来的模型更加符合实际情况,因而促进了句法分析性能的提高[2]。百万词次规模树库Penn Treebank 的建立极大地推动了英语句法分析的研究。Penn Treebank 的规模大,标注质量高。更为重要的是,它已经成为英语句法分析事实上的标准,几乎所有的研究工作都基于该树库进行,这就使得研究者的研究成果可以比较、可以继承。汉语自身灵活的特点[30]使得语料库在标注体系的标准化、系统化和加工深度等方面存在困难,这是制约汉语进行统计句法分析的一个很大的瓶颈。
Collins提出的中心词驱动的句法分析模型[7]是当前句法分析的主流模型,其基本思想就是在上下文无关文法规则中引入词汇化信息和短语的中心词信息,这2种信息的引入增强了句法分析模型的消歧能力,然而,不可避免地带来了严重的数据稀疏问题。基于词类的统计语言模型是解决统计模型数据稀疏问题,提高句法分析系统性能的重要方法。聚类算法有很多种,但可归结为2种基本类型:层次聚类与非层次聚类。非层次聚类只是简单地包括了每类的数量,类与类之间的关系不确定。层次聚类的每一个节点是其父节点的1个子类,叶节点对应的是类别中每个单独的对象,常用算法有自下向上与自上向下(凝聚与分裂)。传统的统计聚类方法通常基于贪婪原则,以语料的似然函数或困惑度作为判别函数。这种传统方法的主要缺点是聚类速度慢,初值对结果影响大,易陷入局部最优。袁里驰[31]利用互信息给出了基于邻接关系、语义依存关系的2种词相似度定义,在词相似度的基础上提出了一种自下而上的分层聚类算法,较成功地解决了中心词驱动句法分析模型数据稀疏问题,大幅度提高了句法分析的系统性能。
汉语的句法分析过程是一个语法知识、语义知识共用的过程。如何在语料中表示句子中蕴涵的复杂知识,并使用统计学习的方法获取这些复杂的不同层次的知识,并把它应用于汉语句法分析将是一个热点问题[30]。语义分析是自然语言处理的一个关键问题。作为目前的热点研究课题之一,语义角色标注(semantic role labeling, SRL)是浅层语义分析(shallow semantic parsing)的一种,其实质是在句子级别进行浅层的语义分析,即对于给定句子,对句中的每个谓词标注出句中相应的语义成分,并确定其相应的语义标记,包括核心语义角色(如施事者、受事者等)和附属语义角色(如地点、时间、方式、原因等)。根据谓词类别的不同,可以将现有的SRL分为动词性谓词SRL和名词性谓词SRL语义。语义角色标注已广泛应用于信息抽取、自动问答、机器翻译、信息检索、自动文摘等领域,具有广阔的前景。目前,大多数语义角色标注系统采用统计学习的方法。随着统计自然语言处理技术的发展,一个长期困扰该领域的关键问题是多任务的联合学习问题。传统的自然语言处理任务通常是按顺序一个接一个执行的,例如,一个比较典型的中文信息处理次序分别是分词、词性标注,然后是组块识别、句法分析,最后是语义信息标注等。建立句法分析与语义角色标注联合学习模型(在句法分析的过程中,进行语义信息标注及分析,同时将标注的语义信息融入产生式的概率计算)是一个有意义的研究方向。
5 结论
(1) 目前对汉语句法分析的研究通常都局限在一个较小的熟语料规模下进行;同时,在汉语方面,树库建设工作还有差距,既缺少统一的依存标注体系,又缺少大规模的依存树库,缺乏一个像英语Penn Treebank那样的标准语料,这也为各种汉语基于统计的句法分析方法的性能比较带来困难。
(2) 统计句法分析面临的另一个主要问题是如何发现和利用具有强消歧能力的语言特征知识,同时保证语言知识的应用不会使模型的参数急剧膨胀而导致严重的数据稀疏问题。
(3) 句法结构是句法形式和语义内容的统一体。对句法结构不仅要进行形式分析,例如句法层次分析、句法关系分析以及句型分析等,而且要进行种种语义分析。对句法结构的语义分析越全面、越深刻,就越有可能对句法形式上的各种现象进行科学、合理的解释。
参考文献:
[1] 曹海龙. 基于词汇化统计模型的汉语句法分析研究[D]. 哈尔滨: 哈尔滨工业大学计算机学院, 2006: 15-83.
CAO Hailong. Research on Chinese syntactic parsing based on lexicalized statistical model[D]. Harbin: Harbin University of Technology. School of Computer Science and Technology, 2006: 64-83.
[2] 吴伟成, 周俊生, 曲维光. 基于统计学习模型的句法分析方法综述[J]. 中文信息学报, 2013, 27(3): 9-19.
WU Weicheng, ZHOU Junsheng, QU Weiguan. A survey of syntactic parsing based on statistical learning[J]. Journal of Chinese Information Processing, 2013, 27(3): 9-19.
[3] 袁里驰. 基于依存关系的句法分析统计模型[J]. 中南大学学报(自然科学版), 2009, 40(6): 1630-1635.
YUAN Lichi. Statistical language paring model based on dependency[J]. Journal of Central South University(Science and Technology), 2009, 40(6): 1630-1635.
[4] 李军辉. 中文句法语义分析及其联合学习机制研究[D]. 苏州: 苏州大学计算机科学与技术学院, 2010: 64-103.
LI Junhui. Research on joint syntactic and semantic parsing for Chinese[D]. Suzhou: Soochow University. School of Computer Science and Technology, 2010: 64-103.
[5] 孟遥, 李生, 赵铁军, 等. 基于统计的句法分析技术综述[J]. 计算机科学, 2003, 30(9): 54-58.
MENG Yao, LI Sheng, ZHAO Tijun, et al. The overview of statistical natural language parsing technology[J]. Computer Science, 2003, 30(9): 54-58.
[6] 袁里驰. 基于配价结构和语义依存关系的句法分析统计模型[J]. 电子学报, 2013, 41(10): 2029-2034.
YUAN Lichi. A statistical parsing model based on valence Structure and semantic dependency[J]. Acta Electronica Sinica, 2013, 41(10): 2029-2034.
[7] Collins M. Head-driven statistical models for natural language parsing[J]. Computational Linguistics, 2003, 29(4): 589-637.
[8] 周强. 基于语料库和面向统计学的自然语言处理技术介绍[J]. 计算机科学, 1995, 22(4): 36-40.
ZHOU Jiang. Corpus-based and statistics-oriented natural language processing techniques[J]. Computer Science, 1995, 22(4): 36-40.
[9] 马金山. 基于统计方法的汉语依存句法分析研究[D]. 哈尔滨:哈尔滨工业大学计算机科学与技术学院, 2007: 5-30.
MA Jinshan. Research on Chinese dependency parsing based on statistical methods[D]. Harbin: Harbin University of Technology. School of Computer Science and Technology, 2007: 5-30.
[10] Jurafsky D, Martin J H. Speech and language processing[M]. Upper Saddle River: Prentice Hall, 2009: 14-108.
[11] Magerman D M. Statistical decision-tree models for parsing[C]//Proceedings of the 33th Annual Meeting of the Association of Computational Linguistics. Boston, MA, 1995: 276-283.
[12] Charniak E. A maximum-entropy-inspired parser[C]// Proceedings of the First Conference of the North American Chapter of the Association for Computational Linguistics. Seattle, Washington, 2000: 132-139.
[13] Charniak E. Top-down nearly-context-sensitive parsing[C]// Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, MIT, Massachusetts, USA, 2010: 674-683.
[14] Petrov S, Barrett L, Thibaux R, et al. Learning accurate, compact, and interpretable tree annotation[C]//Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics. Sydney, Australia, 2006: 433-440.
[15] Finkel J, Kleeman A, Christopher D. Manning. efficient, feature-based,conditional random field parsing[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics. Columbus, Ohio, USA, 2008: 959-967.
[16] Carreras X, Collins M, Koo T. Dynamic programming, and the perceptron for efficient, feature-rich parsing[C]//Proceedings of the 12th Conference on Computational Natural Language Learning. Manchester, UK, 2008: 9-16.
[17] Melchuk I A. Dependency syntax: Theory and practice[M]. Albany: State University Press of New York, 1988: 20-76.
[18] Eisner J. Bilexical grammars and a cubic-time probabilistic parser. [C]//Proceedings of the Fifth International Workshop on Parsing Technologies. Boston, Mass, 1997: 54-65.
[19] Yamada H, Matsumoto Y. Statistical dependency analysis with support vector machines[C]//Proceedings of the 8th International Workshop on Parsing Technologies. Nancy, 2003: 195-206.
[20] Henderson H, Brill E. Exploiting diversity in natural language processing: Combining parsers[C]//Proceedings of the Joint Sigdat Conference on Empirical Methods in Natural Language Processing and Very Large Corpora. College Park, MD, USA, 1999: 187-194.
[21] Sagae K, Lavie A. Parser combination by reparsing[C]// Proceedings of the Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics. New York, 2006: 129-132.
[22] ZHANG Hui, ZHANG Min, Tan C L, et al. K-best combination of syntactic parsers[C]//Proceedings of the Joint Sigdat Conference on Empirical Methods in Natural Language Processing and Very Large Corpora. Singapore, 2009: 1552-1560.
[23] 林颖, 史晓东, 郭锋. 一种基于概率上下文无关文法的汉语句法分析[J]. 中文信息学报, 2006, 20(2): 1-7.
LIN Ying, SHI Xiaodong, GUO Feng. A Chinese parser based on probabilistic context free grammar[J]. Journal of Chinese Information Processing, 2006, 20(2): 1-7.
[24] 何亮, 戴新宇, 周俊生, 等. 中心词驱动的汉语统计句法分析模型的改进[J]. 中文信息学报, 2008, 22(4): 3-9.
HE Liang, DAI Xinyu, ZHOU Junsheng, et al. Improvements on head-driven probabilistic parsing for Chinese[J]. Journal of Chinese Information Processing, 2008, 22(4): 3-9.
[25] Zhou M. A block-based dependency parser for unrestricted Chinese text[C]//Proceedings of the 2nd Chinese Language Processing Workshop. Hong Kong, 2000: 78-84.
[26] Lai T B Y, Huang C N, Zhou M, et al. Span-based statistical dependency parsing of Chinese[C]//Proceedings of the 6th Natural Language Processing Pacific Rim Symposium (NLPRS2001). Tokyo, Japan, 2001: 677-684.
[27] Gao G F, Suzuki H. Unsupervised learning of dependency structure for language modeling[C]//Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics. Sapporo, Japan, 2003: 521-528.
[28] 鉴萍, 宗成庆. 基于序列标注模型的分层式依存句法分析方法[J]. 中文信息学报, 2010, 24(6): 14-22.
JIAN Ping, ZONG Chengqing. Layer based dependency parsing by sequence labeling models[J]. Journal of Chinese Information Processing, 2010, 24(6): 14-22.
[29] 车万翔, 张梅山, 刘挺. 基于主动学习的中文依存句法分析[J]. 中文信息学报, 2012, 26(2): 18-22.
CHE Wanxiang, ZHANG Meishan, LIU Ting. Active learning for Chinese dependency parsing[J]. Journal of Chinese Information Processing, 2012, 26(2): 18-22.
[30] 王继曾, 任浩征, 罗恒, 等. 基于统计的句法分析方法研究[J]. 计算机工程与设计, 2006, 27(12):2207-2210.
WANG Jizeng, REN Haozheng, LUO Heng, et al. Research on method of syntax parsing based on statistical approach[J]. Computer Engineering and Design, 2006, 27(12): 2207-2210.
[31] 袁里驰. 基于词聚类的依存句法分析[J]. 中南大学学报(自然科学版), 2011, 42(7): 2023-2027.
YUAN Lichi. Dependency language paring model based on Word Clustering[J]. Journal of Central South University(Natural Science), 2011, 42(7): 2023-2027.
(编辑 陈灿华)
收稿日期:2013-05-25;修回日期:2013-09-10
基金项目:国家自然科学基金资助项目(61262035);江西省自然科学基金资助项目(20142BAB207028,20122BAB201033);江西省教育厅科技项目(GJJ14335,GJJ12742)
通信作者:袁里驰(1973-),男,湖南邵阳人,博士,副教授,从事自然语言处理研究;电话:0791-83983891;E-mail:yuanlichi@sohu.com

