���ں����۾�������ģ��֧����������
ģ���·��Ϸ���
�ƾ�1 ������1 ��ʷ�Ϳ�2 ��Ф֧�� 2
(1. �������չ���ѧԺ �о���������ӣ�ɽ�� ��̨��264001��
2. �������չ���ѧԺ ���ƹ���ϵ��ɽ�� ��̨��264001)
ժҪ���˷���ͨ��������ӳ�佫ԭʼ����Ƕ�뵽��ά�����ռ䣬Ȼ��������Է����ʹ�����Ϊ����֪ʶ�����ݷ��������µķ�����ģʽ��������Դ�ͳ��K-��ֵ����������������������ά���ߡ��ڹ���������������ʱ��������ܽϲ�����⡣�ڵ�·������������Ԥ�����Σ������һ��������K-��ֵ�����о��࣬�����˷��˴�ͳ�����з��䲻����©�����⣬���ҽ������������ά���ߴ��������������⣬����Ч����˹�����������ʱ�Ķ����������ܣ������һ�ֺ��ܶȺ�������ģ��֧��������ʵ�ֶ���ϵķ��࣬���������Ŵ�������ⷽ�������÷���Ӧ���ڹ��ʱ���·�е�CTSV�˲�����·��������У�����������÷�����ͻ����ͬ���ϵ����ԣ����кܸߵĹ���ʶ���ʣ����й����Ĺ���Ӧ��ǰ����
�ؼ��ʣ��˺�����K-��ֵ���ࣻģ���·��������ϣ�ģ��֧��������
��ͼ����ţ�TP391 ���ױ�־�룺A ���±�ţ�1672-7207(2011)S1-0108-06
An analog circuit fault diagnosis method based on kernel K-means cluster method and FSVM
TANG Jing 1 , QIN Liang1 , SHI Xian-jun2 , XIAO Zhi-cai2
(1. Graduate Students�� Brigade, Naval Aeronautical and Astronautical University, Yantai 264001, China;
2. Department of Control Engineering, Naval Aeronautical and Astronautical University, Yantai 264001, China)
Abstract: A new methods and models for knowledge-based data analysis is brought by kernel method. It uses nonlinear mapping, the original data is embedded into a high dimensional feature space and linear analysis of the data and processing. Based on the fact that the traditional K-means clustering methods cannot solve the fault characteristics of the problem of high data dimension, and overlap in a serious fault samples, the method of classification performance is poor, in the circuit fault characteristic data pre-processing stage, the cross-equalization of nuclear cluster K-means method is presented, which not only overcomes the uneven distribution of the traditional method or the issue of data leakage points, but also solves the high dimensionality of feature data to bring the singularity, also effectively improves the fault samples overlapping clustering performance for the multi-classification. A kernel density function for fuzzy support vector machine is designed to achieve a classification of multiple faults. At the same time, the optimal method is given to solve the bandwidth. The method is applied in the circuit CTSV international standard filter circuit fault diagnosis, the results show that this method has higher recognition rate of failure, and has a good application prospect.
Key words: kernel function; K-means clustering method; analog circuit; fault diagnosis; fuzzy support vector machine
֧��������������[1-2]���ٷ�չ�����ں˵ķ��������ѱ��ɹ������ڽ��������ʵ��������⡣�˷����ṩ��ͨ��ij�ַ�����ӳ�佫ԭʼ����Ƕ�뵽��ά�����ռ䣬Ȼ����������ѧϰ����������¿ռ��з����ʹ�������ģʽ���㷺Ӧ����ģʽʶ���е�������ȡ���ɷַ�����֧������������������ڵ�·������Ϸ��棬���ں����۵ķ����ѳ�Ϊ�о����ȵ㡣���ܺ˷����ܹ���ʾĿ��临�ӵķ����Թ�ϵ�����˺�����˲�����ѡȡ�Է�������������Ҫ��Ӱ�졣����������£������������������������֪ʶѡ��˺���������ѡ�˺���������������ռ��н�����ѧϰ����Ϊij�־����ģʽ������ѡ��[3-4]����ʵ���У�Ԥ��֪����ȷ�ĺ˺�����ʽ��ʮ�����ѵģ�ͬʱ���������κ����ݵ��ձ���ڵĺ˺���Ҳ�Dz����ڵģ���ˣ���Ҫ�ҵ�һ�����������е�Ŀ�꺯�������ƺ˺��������ܡ�����[5]�����һ�ֻ��ھֲ���Ȩ��Fisher����Ż��������������ú�K-��ֵ���������ݽ�������֣�Ȼ���ݸ��������ݶ�֮������Ͼ�����ȡ���������M���������ݣ�������ü�Ȩ�ĺ��Ż��о����M���������ݽ����Ż�����ȡ���յ��Ż��������÷����ܹ���Ч��߿ɷ��Խϲ����������Լ�ľ��룬��ˣ��Զ��������ݳ������õķ������ܡ����÷����ڼ�������Լ�ľ���ʱ�������Ͼ���[6]����������������ά����ʱ����������������Ͼ�������ȡ�����Ҹ÷��������ڹ��Ϸ���ʱ�����ݲ�ģ���·���µĹ�������������������������ʱ���ܽϲ�����Щ���⣬�����������һ�ֻ��ں����۵ľ�������֧����������ϵ��ݲ�ģ���·������Ϸ���������˼·Ϊ���ڵ�·������������Ԥ�����Σ������һ��������K-��ֵ��(Mutual cluster balanced K-means�����MCBKM)���о��࣬�����˷��˴�ͳ��K-��ֵ����������׳��ַ��䲻����©�����⣬���ҽ��������[5]�о�������������⣻Ȼ�����MCBKM�������ֵĸ����࣬���ú�Fisher�����Ż������������ݶ��½���ʵ�ֺ˺����������Ż�����������һ�ֺ��ܶȺ�������ģ��֧��������ʵ�ֶ���ϵķ��ࡣ���÷���Ӧ����ITC��97���ʱ���·�е�CTSV�˲�����·��������У�����������÷�����ͻ����ͬ���ϵ����Բ���Ч��������Ұ������������������кܸߵĹ���ʶ���ʡ�
1 ���㷨����
�˺��� �Ǽ���2�����ݵ��ڷ����Ա任
�Ǽ���2�����ݵ��ڷ����Ա任 ��ӳ����ڻ�����
��ӳ����ڻ����� �����У�
�����У�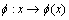 Ϊ�˺��������������任��XΪ����ռ䣻
Ϊ�˺��������������任��XΪ����ռ䣻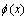 Ϊ�����ռ䣻����Ϊij��Hilbert�ռ���ڻ���������Ӧ���ǶԳƵģ���λ�Ҫ����һЩ������������Mercer������
Ϊ�����ռ䣻����Ϊij��Hilbert�ռ���ڻ���������Ӧ���ǶԳƵģ���λ�Ҫ����һЩ������������Mercer������
���㷨�Ļ���˼���ǽ�nά�����ռ��е��������x���÷����Ժ���ӳ�䵽��ά�����ռ�H��Ȼ���������ά�����ռ���������Ե�ѧϰ�㷨��������и���������������ý������ڻ���������֪���ľ�����ʽ��ֻҪ��������Mercer�����ĺ˺����滻�����㷨�е��ڻ����Ϳ�ʵ��ԭ�ռ��ж�Ӧ�ķ������㷨��
2 ������K-��ֵ�����
��ͳ��K-��ֵ����ͨ����С����ԭ�����������ۼ�����ͬ������[7]������K-��ֵ������һ�ַǼලѧϰ��������ˣ�����֤�����ڸ���������Ŀ��ƽ�⣬�Ӷ����¾������׳����������ʧ������⡣Ϊ�˽��������⣬����[8-11]�����һ�ִ��ල�ľ���ѧϰ�����D�D���ھ���K-��ֵ��(Intra-cluster balanced K-means�����ICBKM)��ICBKM������������״���������ݣ������ڷ���״�����ݣ�ICBKM�ķ������ܴ�͡�Ϊ����߾������ͨ���Ժ���Ч�ԣ�ͬʱΪ������˺����Ż�����Ҫ�����������һ���µľ�����D�D������K-��ֵ��(Mutual cluster balanced K-means�����MCBKM)����ͨ��������ӳ�䣬������ӳ�䵽��ά�����Կռ䣬�ڷ����Կռ������������K-��ֵ���࣬ͬʱ���Դﵽ�������ڸ��������ľ��⣬��������������ľ��⡣
�������һ����������{(x1, z1), (x2, z2), ��, (xN, zN)}������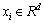 (i=1, ��, N)�����ݿռ��е�i��������zi(i=1, ��, N)�ǵ�i��������Ӧ�������Ϣ����
(i=1, ��, N)�����ݿռ��е�i��������zi(i=1, ��, N)�ǵ�i��������Ӧ�������Ϣ���� ��cΪ��������������i������ӳ�䵽�����ռ�FΪ
��cΪ��������������i������ӳ�䵽�����ռ�FΪ ����MCBKM�������ռ�F��Ŀ�꺯������Ϊʽ(1)��
����MCBKM�������ռ�F��Ŀ�꺯������Ϊʽ(1)��

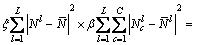

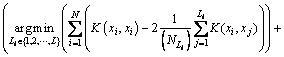

 (1)
(1)
ʽ(1)�еĵ�1���������ڴ�ͳ�ĺ�K-��ֵ��������С�����Ա�֤�����������¡�����L��ʾ���������Li��ʾF�ռ��е�i�����������ľ�����ꣻ ��ʾF�ռ��������ڵ�Li�������������ľ�ֵ��
��ʾF�ռ��������ڵ�Li�������������ľ�ֵ�� ��ʾ��
��ʾ�� �������е�����������
�������е����������� ��ʾ�˺�����
��ʾ�˺�����
ʽ(1)�еĵ�2�ӳ���������������ƽ��̶Ⱥ;����ڸ�����������ƽ��̶ȡ����� ��ʾ��l�������е�����������
��ʾ��l�������е����������� ��ʾ��������ֵ��
��ʾ��������ֵ�� ��ʾ��l��������������c�����������
��ʾ��l��������������c����������� ��ʾ��l�������ڸ�����������ƽ��ֵ��
��ʾ��l�������ڸ�����������ƽ��ֵ�� ��
��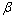 Ϊ��Ȩϵ�����ɴ˿�֪��ֻҪ����D��С��ÿ������
Ϊ��Ȩϵ�����ɴ˿�֪��ֻҪ����D��С��ÿ������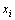 ��Ӧ�ľ��༴Ϊ���������ࡣ
��Ӧ�ľ��༴Ϊ���������ࡣ
��MCBKM�У���2������ؼ���һ����Ϊ�˱�֤�����ڡ�����������ƽ�⣬�������������·���ʱ��Ҫ�ȼ�������������������������������Ϣ�������������������Ϣ������2�࣬������µľ������ĺ;���ԭ���������䵽L���е�ijһ�࣬���������ľ�����겻�䡣ֵ��ע���һ���ǣ��������������������о������ʱ��ʽ(1)�е�1��ı䶯��ǣ�Ƶ�2��ı仯����ˣ���С��D�����ǽ���Ҫ�������1����С��������һ��ȫ�ֶ�̬������̣�����б��ڴ�ͳ�ĺ�K-��ֵ������
����MCBKM���������ݸ����������������ռ��еķֲ�����ͬ����������������ۼ���һ�������ڣ���������Զ���������䵽��ͬ�ľ��࣬�ܶ��������������ľ����������Ч�ĸĽ�������ʽ(1)�����ã������˸������������ݳ��ֽϴ�IJ��죬ͬʱҲ�����˾����ڲ�ij���������ݹ��ࡢ�������ݹ�������ķ�����
MCBKM�㷨�ı��ʾ���Ϊ�˻�ȡ�ɷ��Խϲ����������ԣ����Խ��ɷ��Բ�����������ֱ�Ӿۼ���һ��������Եĸ�������������ͬ�����踽�Ӷ���������жϡ�
3 �˺����Ż������Ľ���
�˺������Ż���Ҫ������һ�����Ż���֮�ϡ����������ռ��е�����-��������������һ�ֿ��еķ������������ݾ�MCBKM�������ֳɶ����������ԣ���ˣ�Ϊ�˽���ͳһ���Ż�Ŀ�꺯�������Ƚ����ֲ��Ż�Ŀ�꺯�������ݾֲ��Ż�Ŀ�꺯����ȷ���˺������Ż�������
�辭MCBKM������Li�������е���������Ϊ �����У�
�����У�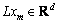 (m=1, 2, ��, MLi����MLi��N)Ϊ�����е�m��������������Ӧ�����Ϊ
(m=1, 2, ��, MLi����MLi��N)Ϊ�����е�m��������������Ӧ�����Ϊ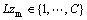 (m=1, 2, ��, MLi)���������ݵĺ˺�������Ϊ��
(m=1, 2, ��, MLi)���������ݵĺ˺�������Ϊ��
 (2)
(2)
���� ��
�� Ϊ�����˺�����һ��ѡ�ó��õĸ�˹�˺�����Poly�˺����ȡ�
Ϊ�����˺�����һ��ѡ�ó��õĸ�˹�˺�����Poly�˺����ȡ�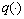 ����Ϊ��
������
 (3)
(3)
 Ϊ����ϵ����
Ϊ����ϵ���� ��
�� ����
���� ������Խ��߾���Q����Խ����ϵ�Ԫ��Ϊ
������Խ��߾���Q����Խ����ϵ�Ԫ��Ϊ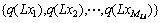 ������
������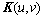 ��
��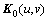 Ϊ
Ϊ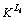 ��
�� ����
����
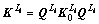 (4)
(4)
���� ��
��
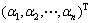 ����
����
 (5)
(5)
���������ռ��к˺����Ŀɷ��Բ�������ڣ��������������������ڿɷ��Բ�Ⱦ������Ե����ԣ��Ҹ��ݾ��������ռ�Ķ��壬��ֲ��Ż�Ŀ�꺯���ɱ�ʾΪ��
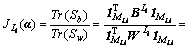
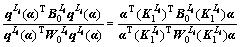 (6)
(6)
�ɴˣ������ ��Ӧ��
��Ӧ��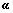 ����˺���(2)�У��õ��ĺ˺������ܽϺ�����ӳ���������ռ������ݵķֲ��ṹ��
����˺���(2)�У��õ��ĺ˺������ܽϺ�����ӳ���������ռ������ݵķֲ��ṹ��
4 ģ��֧���������������
����ģ��֧����������Ԥ�����Ĺ����������ݽ��з��࣬��Գ���֧����������ѵ������������������������������ʶ�⣬ģ��֧��������ѵ����ÿ��������������ģ�������ȣ�����������Ч�����������Ұ���Ӱ�졣
��ģ��֧������������ϵ�ѵ��������Ϊ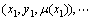 ,
,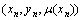 ��
�� ��
�� , 0��
, 0�� ��1������
��1������ Ϊ��ѵ��������ԭʼ�ռ�RNӳ�䵽��ά�����ռ�Z֮���ӳ���ϵ��ģ����������ʾ������������ij��Ŀɿ��̶ȣ�
Ϊ��ѵ��������ԭʼ�ռ�RNӳ�䵽��ά�����ռ�Z֮���ӳ���ϵ��ģ����������ʾ������������ij��Ŀɿ��̶ȣ�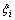 ��֧��������Ŀ�꺯���еķ���������
��֧��������Ŀ�꺯���еķ��������� Ϊ��Ȩ�����õ������ŷ���ƽ��Ϊ��ʽĿ�꺯�������Ž⡣
Ϊ��Ȩ�����õ������ŷ���ƽ��Ϊ��ʽĿ�꺯�������Ž⡣
 (7)
(7)
ʽ�У��ͷ�����CΪ������w��ʾ���Է��ຯ��yi��Ȩϵ������ʽ(7)���Կ���������Сʱ��Ҳ��С����ʽ(7)�е�Ӱ�죬��ɽ�xi��������Ҫ��������
��Ӧ�����ŷ�������б���Ϊ��
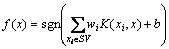 (8)
(8)
ʽ�У�K(xi, x)Ϊ�˺��������IJ��ø�˹�ˡ�
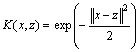 (9)
(9)
Ӧ��һ�ֻ��ں��ܶȹ��Ʒ�������Ч�������Ⱥ�����
 (10)
(10)
 (11)
(11)
���Ŵ���Ϊ
 (12)
(12)
��˵������Ĵ���Ϊ ��Ȼ�����������������������������ȡ�õġ�ʵ���ϣ�����Ӧ�ø������ݺ��ܶȹ��Ƶ������һ����Χ�ڲ��ϵ�����
��Ȼ�����������������������������ȡ�õġ�ʵ���ϣ�����Ӧ�ø������ݺ��ܶȹ��Ƶ������һ����Χ�ڲ��ϵ�����
5 ���ݲ�ģ���·�Ķ�������ʵ��
����ѡ��ITC��97���ʱ���·�е�CTSV�˲���Ϊ�����з���ͷ�����CTSV�˲�����·��ͼ1��ʾ����·�е���͵��ݵ���Դ�������ݲ���Ϊ10%����Դ�����ı��ֵΪR1= R2= R3= R4= R5=10 k?��R6=3 k?�� R7=7 k?��C1= C2=20 nF��

ͼ1 CTSV�˲�������·
Fig.1 Standard circuit CTSV filters
���Ǵ����·�ĵ�һ�����ϣ�F1(R1+50%)��F2(R1-50%)��F3(C1+50%)��F4(C1-50%)��F5(C2+50%)��F6(C2-50%)��F7(R5+50%)��F8(R5-50%)���������������Ϊ��F9(R1+50% & C 1+50%)��F10(R 1-50% & C1-50%)��F11(R5+50% & C2+50%)�����з��š�+����-����ʾ����ֵ��ƫ����ƫ��Ԫ���ı��ֵ�����ϵ�·��������״̬NF������12��״̬ģʽ����NI-Multisim10��·���������ж�CTSV��·���з��棬���еĹ���ģʽ��������̬���ؿ���(Monte Carlo)�������Ե�·ÿ�ֹ���ģʽ����150��Monte Carlo���档��Vin�ڵ����뼤���źţ������źŲ�������Ϊ10 ��s������Ϊ5V�ĵ������ź���Ϊ��·�ļ����źţ��ڽڵ�6(Output)���ɼ�����״̬�µ�·����Ӧ��ѹ�źš��Ե�·ÿ����Ӧ�źŵ�ǰ100 ��s�źŽ��в�����1 000�����ݵ㣬����5��HaarС���任������С���任�����н���ϵ����ϸ��ϵ���ֱ������˹����źŵĵ�Ƶ��Ƶ��Ϣ��������С������ϵ����ϸ��ϵ������ģ���·��2�ֹ�����������ÿ�����ϵ���ĵ�1����ֵ���ɵ�Ƶ��������ÿ��ϸ��ϵ���ľ���ֵ֮���ɸ�Ƶ�������ֱ���ά��Ƶ��Ƶ������������������й�һ����������������·ÿ��״̬ģʽ��������150����Ƶ������150����Ƶ����������ɣ�����50����������ѵ����100���������ڲ��ԡ�
6 ������ϲ���
(1) ���ȸ��ݵ�·����������ȡ�����ķ������й���������ȡ��ÿ�ֹ��Ͼ�����������ɵõ�50������������������ѵ�����γ�һ��50��10�ľ���
(2) ������������и��Ե�����c����С����뾶r��
(3) ��������������ÿ��ģʽ�ڵ�6�ĺ��ܶȺ��������ݺ��ܶȺ������ó�����������ݵ������� ��
��
(4) ����һ�Զ�Ķ������Խ�FSVM�ƹ㵽�����FSVM����ģ���·�Ĺ�����ϡ��������K�������������Ҫѵ��k��ģ��֧�����������Ե�k��ģ��֧�����������Ե�k���������Ϊ���������������Ϊ��������������z��ģ��������ȡֵΪ��
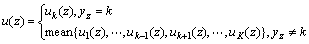 (13)
(13)
ʽ�У�yz��ʾ����z����������ꡣ
(5) ����ʽ(7)����Ż����⣬��õ�k�����ߺ�����
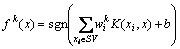 (14)
(14)
(6) ���ϲ��������Ĺ�����𡣽�����������x����ǰ����õľ��ߺ������з��ࣻ
(7) �������ܶȺ����Ĵ���hn�ʹ��ֳͷ�����C���õ���������Ĺ�����Ͻ����
���õ�·�Ĺ����������ݶԺ��Ż���������Ч�Խ�����֤��MCBKM����L=2����=0.001��T=100��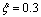 ��
�� ���˺���ѡΪ��˹�˺�������������ѡȡ�ú��ܶȺ����Ĵ���hn=5�����ֳͷ�����C=12����1������ͬ�����µ������ȷ�ʡ�����K&SVM��ʾ���ô�ͳ�ġ�δ���Ż���K��ֵ�������֧�����������������ϣ�K&FSVM��ʾ���ô�ͳ�ġ�δ���Ż���K��ֵ�������ģ��֧�����������������ϣ�Ours��ʾ�����Ż���MCBKM������ģ��֧�����������������ϡ�
���˺���ѡΪ��˹�˺�������������ѡȡ�ú��ܶȺ����Ĵ���hn=5�����ֳͷ�����C=12����1������ͬ�����µ������ȷ�ʡ�����K&SVM��ʾ���ô�ͳ�ġ�δ���Ż���K��ֵ�������֧�����������������ϣ�K&FSVM��ʾ���ô�ͳ�ġ�δ���Ż���K��ֵ�������ģ��֧�����������������ϣ�Ours��ʾ�����Ż���MCBKM������ģ��֧�����������������ϡ�
��1 ��ͬ������Ӧ�������ȷ��
Table 1 Diagnosis results of different methods %

7 ����
��������ķ������������Ϸ�����һ�ֿ��еķ���������������ϣ�������������Ż������Ϸ����ϴ�ͳ��K&SVM��K&FSVM���������ݲ�ģ���·�Ĺ����������ݡ����Ҷ�������ϵ���ϣ�����������ķ����������ţ��ڱ��־��ȵ�ͬʱ��Ч�����˹����������ݵ�ά�������кܸߵĹ���ʶ���ʡ��Ը��ݲ�ģ���·�Ķ���������ȷ�ʴﵽ94.49%�����кܺõ�������ܺ����Ĺ���Ӧ��ǰ����
�ο����ף�
[1] Vapnik V N. Statistical learning theory[M]. New York: Springer, 1995: 86.
[2] ���], ��־��, �ܰ�Ӣ. ����ѧϰ����Ӧ��[M]. ����: �廪��ѧ������, 2006: 315.
WANG Yu, ZHOU Zhi-hua, ZHOU Ao-ying. Machine learning and its application[M]. Beijing: Tsinghua University Press, 2006: 315.
[3] John S T, Cristianini N. ģʽ�����ĺ˷���[M]. ������, ����. ����: ��е��ҵ������, 2006: 246.
John S T, Cristianini N. Kernel methods of pattern analysis[M]. ZHOU Ling-ling, et al, transl. Beijing: China Machine Press, 2006: 246.
[4] �²�, ����ΰ, ���P, ��. һ������״�߷ֱ��������ںϺ��Ż��㷨[J]. ����ѧ��, 2006: 34(6): 1146-1151.
CHEN Bo, LIU Hong-wei, BAO Zheng, et al. Algorithm based on fusion kernel for high-resolution range profiles recognition[J]. Acta Electronic Sinica, 2006: 34(6): 1146-1151.
[5] Chen B, Liu H W, Bao Z. A kernel optimization method based on the localized kernel Fisher criterion[J]. Patterns Recognition, 2007: 41(3): 1098-1109.
[6] ZHANG Dao-qiang, CHEN Song-can, ZHOU Zhi-hua. Learning the kernel parameters in kernel minimum distance classifier[J]. Pattern Recognition, 2006, 39(1): 133-135.
[7] Xiong H L, Swamy M N S, Omair Ahmad M. Optimizing the kernel in the empirical feature space[J]. IEEE Trans Neural Networks, 2005, 16(2): 460-472.
[8] Sap M, Noor M. Weighted kernel K-means algorithm for clustering spatial data[J]. Journal Teknologi Maklumat, 2007: 16(2): 137-156.
[9] �, ���, ����Ⱥ, ��. һ�����������ȡ���·���[J]. �����ѧ��, 2002, 25(6): 570-575.
YANG Jian, YANG Jing-yu, WANG Zheng-qun, et al. A novel feature extraction method based on feature integration[J]. Chinese Journal of Computers, 2002, 25(6): 570-575.
[10] ��ҹü, �����. ������������ͳ��[M]. ����: ���ӹ�ҵ������, 2006: 167.
JI Ye-mei, WU Da-xian. Probability and mathematical statistics[M]. Beijing: Electronic Industry Press, 2006: 167.
[11] �ű���, ������, ɽ����, ��. ����֧��������Kernel�б����[J]. �����ѧ��, 2006, 29(12): 2143-2150.
ZHANG Bao-chang, CHEN Xi-lin, SHAN Shi-guang, et al. Kernel discriminant analysis based on support vectors[J]. Chinese Journal of Computers, 2006, 29(12): 2143-2150.
(�༭ �²ӻ�)
�ո����ڣ�2011-04-15�������ڣ�2011-06-15
������Ŀ��������Ȼ��ѧ����������Ŀ(61004002)
ͨ�����ߣ��ƾ�(1978-)���У������人�ˣ���ʿ�о���������ʦ���������ܵ�·������ϺͲ��Լ������绰��0535-6635491��E-mail: tangj105@163.com

