DOI: 10.11817/j.issn.1672-7207.2019.07.014
多核微处理器体系结构级功耗模型分析
陈卓1,刘畅2,侯申3,郭阳4
(1. 陆军研究院 作战保障研究所,无锡 江苏,214000;
2. 湖南大学 信息科学与工程学院,湖南 长沙,410083;
3. 信息工程大学 基础系,河南 洛阳,471003;
4. 国防科技大学 计算机学院,湖南 长沙,410083)
摘要:利用FT-SHSim模拟工具平台,对主流的微处理器核心模型SMT(同步多线程,simultaneous multithreading)和MSS(适度超标量,moderate superscalar)进行建模。采用先进CMOS工艺,在体系结构级进行功耗评估的模拟实验,得到不同微处理器结构的工艺需求和不同工艺下同微处理器结构可以实现的性能及所需的规模,为微处理器设计的早期阶段提供工艺需求与实现方法的参考价值,从而实现提高设计质量、缩短设计周期、加快设计收敛的目的。研究结果表明:在最小线宽为22 nm的工艺下,128核SMT处理器模型峰值功耗为116 W,64核MSS处理器峰值功耗为161 W。
关键词:多核处理器;体系结构级;峰值功耗;工艺模拟器
中图分类号:TP332 文献标识码:A 文章编号:1672-7207(2019)07-1611-08
Analysis of power model of multi-core microprocessor architecture
CHEN Zhuo1, LIU Chang2, HOU Shen3, GUO Yang4
(1. Institute of Combat Support, Army Academe, Wuxi 214000, China;
2. College of Computer Science and Electronic Engineering, Hunan University, Changsha 410083, China;
3. Department of Basic Courses, Information Engineering University, Luoyang 471003, China;
4. School of Computer, National University of Defense Technology, Changsha 410083, China)
Abstract: The FT-SHSim simulation tool platform was used to model the mainstream microprocessor core models SMT and MSS. Using advanced CMOS technology, the simulation experiment of power consumption evaluation at the architecture level obtained the process requirements of different microprocessor structures and the performance and scale required by the same microprocessor structure during different processes. This provided a reference value for process requirements and implementation methods for the early stages of design, improving quality, shortening cycles, and accelerating design convergence. The results show that in the 22 nm process of the minimum line width, the 128-core SMT processor model has a peak power of 116 W and 64-core MSS processor model has a peak power of 161 W.
Key words: multi-core processor; architecture level; peak power consumption; process simulator
随着集成电路发展到深亚微米及纳米工艺后,单片芯片上集成的晶体管数目可达几十亿个,使得高性能微处理器进入超大存储容量、众多高速IO接口的多核心时代,新型体系结构不断出现,处理能力大大提升[1-3]。高性能微处理器的性能与集成度在按照摩尔定律高速发展时,“功耗墙”成为棘手的问题[4-7]。现代的通用处理器功耗峰值已经高达上百瓦,例如,Alpha 21364功耗为100 W,AMD Opteron功耗为90 W,Intel Itanium 2功耗超过100 W,能效比成为微处理器的重要设计指标[8-10]。低功耗设计已成为微处理器设计的关键,而精确的功耗评估是进行低功耗设计的基础[11-12]。一方面,由于微处理器主频和规模的大幅提升以及集成电路工艺向纳米级发展,微处理器的设计复杂度大大提升,设计周期大大增加[13-14],所以,迫切需要在设计的各个阶段就能精确评估功耗,尽早确定能满足目标体系结构、性能指标要求的工艺,从而达到缩短设计周期的目的。另一方面,微处理器的功耗与芯片的体系结构、主频、规模、工艺等因素密切相关[15],在设计的各个阶段(特别是设计的早期阶段)进行较为精确的功耗评估变得十分困难,因此,如何根据功耗评估结果来确定工艺需求是CPU(中央处理器,central processing unit)工程实现的重要前提,在设计的开始阶段就能确定工艺需求,对CPU的成功研制将起到事半功倍的效果。许多学者对高性能微处理器在体系结构、低功耗设计与评估、新工艺等方面展开了大量的分析与研究,取得了许多研究成果。LIU等[13]通过参数化RTL(寄存器转换级电路,register transfer level)和物理反标的方法对处理器的基本单元进行建模分析,针对门级网表对处理器进行模拟功耗研究。HUANG等[16]则是将电路级参数封装在模型内部,通过体系结构属性和特征尺寸来估算电容,从而进行功耗分析建模。以往的这些研究主要注重低功耗设计在RTL和电路级的功耗评估,缺少对多核心处理器、体系结构层次性能、功耗、工艺等进行综合模拟的研究[17-20]。本文作者采用FT-SHSim模拟工具对主流的微处理器核心模型SMT和MSS建模,在体系结构级对功耗和工艺进行综合评估的模拟实验,得到不同微处理器结构的工艺需求和不同工艺下可以实现的处理器性能及规模,使得微处理器设计的早期阶段就能够考虑工艺需求,从而实现提高设计质量、缩短设计周期、加快设计收敛的目的。
1 体系结构级工艺模拟器FT-SHSim
1.1 FT-SHSim结构与工作原理
FT-SHSim工艺模拟器的结构如图1所示。该模拟器通过XML(可扩展标记语言,extensible markup language)的接口与性能模拟器交互,使用XML解释器解释处理XML接口文件。接口文件中可以指定静态的微体系结构参数,也可以传递由性能模拟器产生的动态行为统计结果的参数。模拟器还可以基于XML的接口实时返回运行功耗结果给性能模拟器,使得性能模拟器可以获得功耗甚至温度,并且该模拟器提供体系结构和工艺级的完整层次化模型。XML接口还可以包含电路实现风格以及工艺参数。
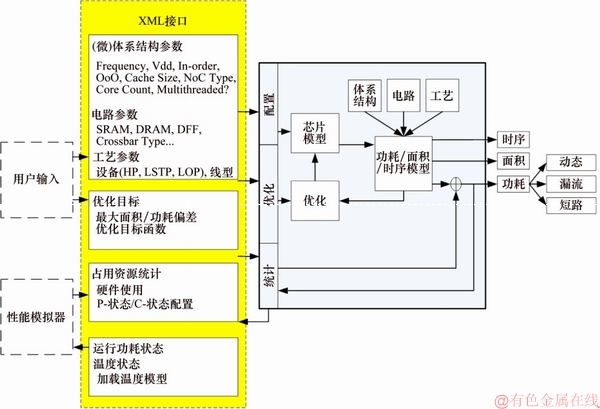
图1 FT-SHSim体系结构级工艺模拟器结构图
Fig. 1 Simulator structure of FT-SHSim architecture level process
模拟器的核心组件包括:1) 层次化功耗、面积和时序模型;2) 决定电路级实现的优化器;3) 用于分析功耗、面积和时序的内部芯片的表示。大部分内部芯片表示的参数(如高速缓冲存储器(Cache)容量、核发射宽度)是直接通过输入参数设定的。模拟器的层次化结构能够完成基于器件工艺在低层次建模,而体系结构设计师只需要关注高层次体系结构配置。电路级优化器关注2种主要的规则结构:互连和阵列。例如,通过指定片上互连的频率、等分带宽或者Cache块的容量、相联度、数量,工具自动确定实现细节,如金属层的选择、互连信号线的间距或者Cache块字线、位线的长度。
模拟器的工作流程分为2个阶段:初始化阶段和计算阶段。在初始化阶段,需要指定静态配置,包括体系结构、电路以及工艺所有3个层次的参数。体系结构参数包括核的数量、路由器的数量、共享末级Cache的参数、核发射宽度、乱序(OoO,out of order)重命名策略、OoO调度策略、硬件线程数量等。电路级参数指定电路实现技术,如执行某一个阵列用基于触发器的单元实现还是基于SRAM(静态随机存取存储器,static random-access memory)的单元实现、片上路由器是否使用双泵(double-pumped)交叉开关等。工艺级参数包括器件类型和互连,器件类型包括高性能(HP,high performance)、低standby电源(LSTP,low standby power)、低操作电源(LOP,low operation power)。静态配置还包括一些优化选项,例如最大面积偏差、最大功耗偏差和优化函数。所有的静态配置设置完毕后,模拟器开始进行初始化阶段。
初始化阶段完成后得到按照用户配置要求的微处理器芯片的一个描述,然后模拟器开始功耗计算阶段。模拟器在精确的功耗和面积建模基础上,对每一个处理器部件优化电路级结构以满足时序约束,然后判断该部件的功耗和面积是否在最佳值允许的偏差范围内。在所有满足功耗和面积最佳范围的配置中,模拟器采用1个优化函数报告最终的功耗和面积。
1.2 模拟器功耗模型分析
CMOS电路的功耗主要由3个部分组成:动态功耗、短路电流功耗和漏流功耗,即
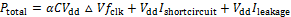 (1)
(1)
式(1)中右边第1项为动态功耗,表征消耗在电路切换状态时对负载电容充电和放电,其中C为总的负载电容,Vdd为电源电压,ΔV为电源切换时的摆幅,fclk为时钟频率;Ishortcircuit为短路电流,Ileakage为漏流。C取决于每一个IC组件的电路设计和版图,模拟器对于规则结构(如存储阵列和连线)采用分析模型计算负载电容,对于随即逻辑结构(如ALU(算术逻辑部件运算器,arithmetic logical unit))采用经验模型计算负载电容。活动性因子α表示在1个时钟周期内被充电的电容占总电容的比例。模拟器从体系结构模拟以及电路属性得到的访问统计信息来计算活动性因子α。
式(1)中右边第2项为短路电流功耗,为CMOS电路中上拉器件和下拉器件在短时间内导通的消耗,它通常占总动态功耗的10%左右。电路在切换时,产生动态功耗和短路电流功耗。电路的固有属性决定了短路电流功耗在动态功耗中所占的比例,该比例是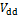 与
与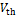 比例的强函数。
比例的强函数。
式(1)中右边第3项为静态功耗,为电路中晶体管上的漏流所消耗。漏流取决于晶体管的宽度和器件的局部状态。存在2种漏流:亚阈漏流和栅漏流。亚阈漏流是关断状态下的晶体管存在从源到漏极的小电流。栅漏流是通过晶体管栅级泄露的电流,随器件状态的变化而变化。为了对电路模块中的多个晶体管进行建模,需要考虑每一个晶体管的逻辑状态,再把每一个静态管的漏流相加。假设1个电路处于一种逻辑状态s,所有消耗亚阈漏流的晶体管有效宽度表示为Wsub(s);类似地,打开和关断的晶体管栅漏流有效宽度表示为Wgon(s)和Wgoff(s)。设电路处于状态s的概率为 ,所有可能状态下的总漏流可以用下式表示:
,所有可能状态下的总漏流可以用下式表示:
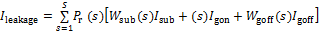 (2)
(2)
在模拟器中,计算每一个基本电路块不同状态下的漏流。即使在同一个状态同一个电路块中,亚阈漏流和栅漏流也具有不同的漏流路径。器件打开时的栅漏流也与关断时的栅漏流有很大不同。由于关断状态栅漏流远小于打开状态下的栅漏流,因此,模拟器忽略关断状态下的栅漏流。
2 模拟模型的建立
2.1 SMT和MSS模型的建立
SMT允许1个时钟周期内发射多个线程的多条指令执行,能够同时利用程序的TLP(线程级并行,thread level parallelism)和ILP(指令层并行,instruction level parallelism),提高处理器发射槽以及功能部件的利用率。而MSS对通用处理器的指令数目和寻址方式都进行了精简,使其实现更容易,指令并行执行程度更好,编译器的效率更高,它只要求硬件执行有限且常用的指令,大部分复杂的操作则使用成熟的编译技术,由简单指令合成,对提高核心数量和处理器性能有很大的帮助。这2种处理器核心的多核处理器体系结构参数配置如表1所示。
表1 处理器体系结构参数配置
Table 1 Processor architecture parameter configuration
处理器核心数目范围为16~1 024个,频率分别设置为1.0,1.5,2.0,2.5和4.0 GHz。每一个处理器核包含1个32 kB的一级指令Cache(L1I Cache)和1个32 kB的一级数据Cache(L1D Cache)。对于片上L2 Cache,分别模拟2种配置:配置1为不同核心数量下,L2 Cache等比配置,256 kB/bank,bank数等于核心数;配置2类似于GPU,L2 Cache不随核心数变化,全芯片配置768 kB L2 Cache。片上互连网络采用2D Mesh结构。片上存储控制器(MC)数量随核心数增加而增加,具体对应关系如下:16和32核处理器配置MC数为4个;64和128核处理器配置MC数为8个;256和512核处理器配置MC数为16个;1 024核处理器配置MC数为32个。网络接口(NIU)数量配置为2个,PCIe接口数量配置为1个。
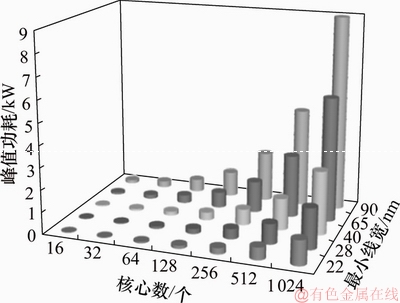
图2 L2 Cache等比配置SMT峰值功耗
Fig. 2 L2 Cache equal ratio configuration SMT peak power consumption
处理器核心的主要参数配置如表2所示。在处理器核心配置中,每一个核包含2个ALU单元和1个FPU单元,每一个核有2条整数流水线和1条浮点流水线,流水线深度为8级。
2.2 工艺参数配置
工艺相关的特性参数配置包括工艺节点(Core_Tech_Node)、互连类型(Interconnect_ Projection_Type)、器件类型(Tevice_Type)以及是否使用长沟器件类型(Longer_Channel_Device)。在模型中,选取5种工艺节点即最小线宽为90,65,40,28和22 nm,覆盖了国内成熟以及国际主流、先进工艺节点。对于互连类型,模拟器可以提供2种:激进互连类型( aggressive wire technology)和保守互连类型(conservative wire technology),考虑高性能多核微处理器的高性能要求,在模型中选取激进互连类型。对于器件类型,模型中将包括3种类型:HP,LSTP以及LOP的功耗建模,分别对这3种器件类型进行模拟对比,比较不同器件类型实现下处理器的面积与功耗。
图3 L2 Cache固定配置SMT峰值功耗
Fig. 3 L2 Cache fixed configuration SMT peak power consumption
3 模拟实验与结果分析
3.1 SMT建模分析
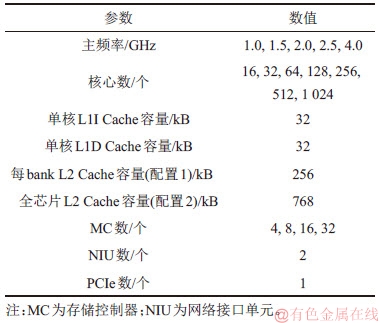
SMT建模完成后,分别对L2 Cache等比配置和固定配置进行分析,选取5种工艺节点即最小线宽为90,65,40,28和22 nm,查看SMT处理器在5种工艺下峰值功耗随核心数增加的变化趋势。从图2和图3可以看出:随着工艺节点向前推进,处理器消耗的总功耗会降低;而随着核心数增加,总体功耗会随之上涨。即使采用模拟器中最先进的22 nm工艺,实现128核SMT处理器峰值功耗也分别达到143 W和116 W。
表2 处理器核心主要参数配置
Table 2 Main parameters of processor core configuration

图4所示为L2 Cache等比配置下SMT处理器在5种工艺的不同器件类型实现下的峰值功耗对比。从图4可见:在最小线宽为90 nm工艺下,采用LSTP器件实现峰值功耗最高,采用HP器件实现次之,采用LOP器件实现最低;在最小线宽为65,40和28 nm工艺下,采用HP器件实现峰值功耗最高,采用LSTP器件实现次之,采用LOP器件实现最低;在最小线宽为22 nm工艺下,采用LOP器件实现峰值功耗最高,采用HP器件实现次之,采用LSTP器件实现最低。从图4可知:HP和LOP器件在每个工艺节点向前推进时功耗有明显幅度下降,但LSTP器件在只前期工艺有明显下降,而到了28 nm以后,功耗不仅没有下降,反而有微小上升,也就是说,低功耗技术的实现不能依赖于工艺节点。
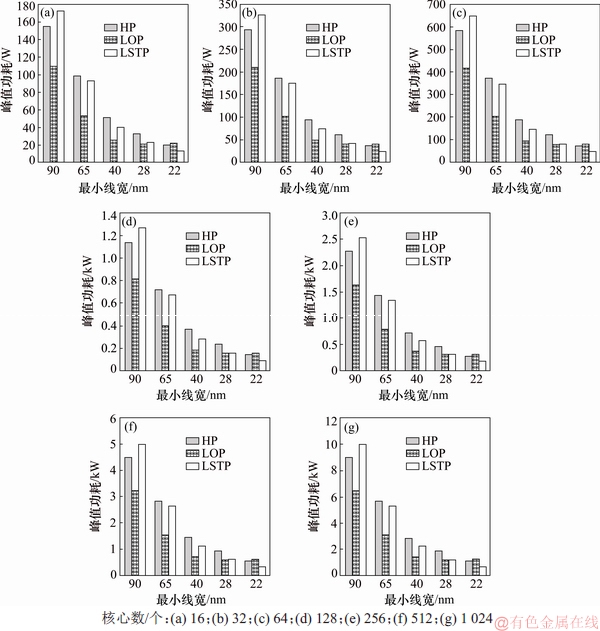
图4 L2 Cache等比配置时不同工艺器件类型的峰值功耗对比
Fig. 4 Peak power comparison for different process device types with L2 cache equal ratio configuration
图5所示为L2 Cache固定配置下SMT,MSS以及CSS处理器在5种工艺的不同器件类型实现下的峰值功耗对比。数据趋势与L2 Cache等比配置相同,但峰值功耗低于L2 Cache等比配置的峰值功耗。
模拟结果表明:随着核心数增加,峰值功耗急剧增加,对封装及散热的实现提出严峻挑战。如要求峰值功耗控制在100 W左右,对于40 nm工艺,可以实现32核规模的SMT处理器,峰值功耗约为95 W;对于28 nm工艺,可以实现64核规模的SMT处理器,峰值功耗约为120 W;对于22 nm工艺,可以实现128核规模的SMT处理器,峰值功耗约为150 W。
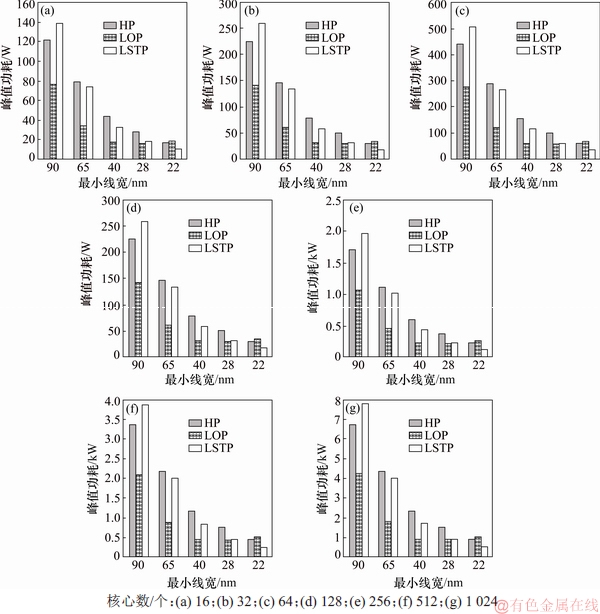
图5 L2 Cache固定配置时不同工艺器件类型的峰值功耗对比
Fig. 5 Peak power comparison for different process device types with L2 cache fixed configuration
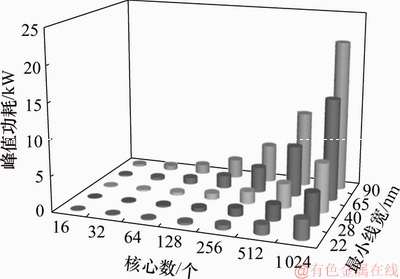
图6 L2 Cache等比配置MSS峰值功耗
Fig. 6 L2 Cache equal ratio configuration MSS peak power consumption
3.2 MSS建模分析
MSS建模完成后,分别对L2 Cache等比配置和固定配置进行分析,选取5种工艺节点即最小线宽为90,65,40,28和22 nm,查看MSS处理器在5种工艺下峰值功耗随核心数增加的变化趋势,结果如图6和图7所示。从图6和图7可以看出:随着工艺节点向前推进,处理器消耗的总功耗降低;而随着核心数增加,总体功耗会随之上涨。采用最先进的22 nm工艺,实现64核MSS处理器峰值功耗分别达到176 W和161 W。
图8和图9所示分别为L2 Cache等比配置和固定配置下MSS处理器在5种工艺下漏流功耗数据以及随核心数增加的变化趋势。从图8可知:随着工艺节点向前推进,MSS漏流功耗呈开口向下的抛物线变化趋势,而且漏流功耗占总体功耗比重较大,即使采用22 nm工艺实现的64核MSS处理器,其漏流功耗也分别达到96 W和85 W,分别占全芯片功耗的55%和53%。
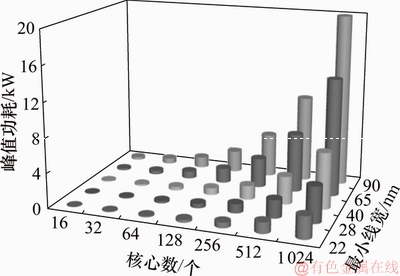
图7 L2 Cache固定配置MSS峰值功耗
Fig. 7 L2 Cache fixed configuration MSS peak power consumption
模拟结果表明:随着核心数增加,峰值功耗急剧增加,对封装及散热的实现提出严峻挑战。如要求峰值功耗控制在150 W左右,对于40 nm工艺,可以实现16核规模的MSS处理器,峰值功耗约为110 W;对于28 nm工艺,可以实现32核规模的MSS处理器,峰值功耗约为140 W;对于22 nm工艺,可以实现64核规模的处理器,峰值功耗约为170 W。在纳米级工艺下,漏流功耗占总功耗的比重越来越大,甚至成为主导部分。因此,在高性能多核处理器设计中,在以往重点注重降低动态功耗的设计流程中,必须考虑降低静态功耗的设计和选择新工艺,如高K金属栅、SOI(绝缘衬底上硅,silicon-on-insulator)等新技术和新工艺的运用。
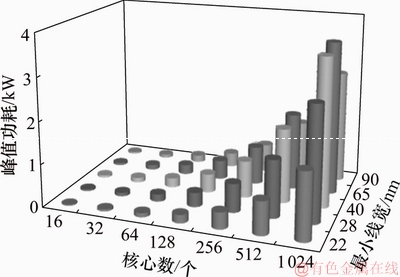
图8 L2 Cache等比配置MSS漏流功耗
Fig. 8 L2 Cache equal ratio configuration MSS leakage consumption
4 结论
1) 采用体系结构级工艺模拟器FT-SHSim对典型CPU架构SMT和MSS进行大量模拟实验,给出不同工艺、不同器件类型下实现不同规模处理器的峰值功耗和静态功耗。随着核心数的增大,峰值功耗将达到数千瓦,单位面积的功耗将远超过目前的散热能力。按照目前100 W左右的峰值功耗要求,对于40,28和22 nm工艺,分别可以实现32核、64核和128核规模的SMT处理器,可以实现16核、32核和64核规模的MSS处理器。此外,在纳米级工艺条件下处理器的静态功耗所占比重达到50%以上,在高性能处理器的设计时,必须大量采用降低静态功耗的新技术和新工艺。
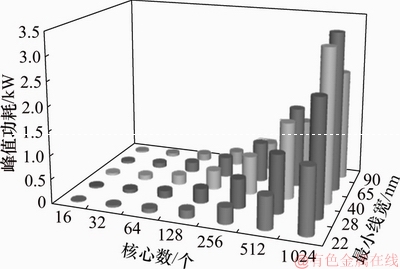
图9 L2 Cache固定配置MSS漏流功耗
Fig. 9 L2 Cache fixed configuration MSS leakage consumption
2) 随着集成电路工艺进入纳米时代,片上集成度不断提高,功耗和面积成为制约高性能微处理器设计的重要因素,在体系结构设计阶段应考虑工艺需求与可实现性。
参考文献:
[1] AFACAN E, BERKE YELTEN M, DUNDAR G. Review: analog design methodologies for reliability in nanoscale CMOS circuits[C]// 2017 14th International Conference on Synthesis, Modeling, Analysis and Simulation Methods and Applications to Circuit Design (SMACD). Giardini Naxos, Italy, 2017: 1-4.
[2] WANG Yang, JIN Xiangliang, ZHOU Acheng. Novel LDNMOS embedded SCR with strong ESD robustness based on 0.5 μm 18 V CDMOS technology[J]. Journal of Central South University, 2015, 22(2): 552-559.
[3] SALAH K. More than Moore and beyond CMOS: New interconnects schemes and new circuits architectures[C]// 2017 IEEE 19th Electronics Packaging Technology Conference (EPTC). Singapore, 2017: 1-6.
[4] BHONGE S, BOPPANA V. Low power chips: a fabless asic perspective[C]// Proceeding of the 13th International Symposium on Low Power Electronics and Design (ISLPED'08). Bangalore, 2008: 347-348.
[5] MELIKYAN V, MARTIROSYAN M, BABAYAN D, et al. Multi-voltage and multi-threshold low power design techniques for ORCA processor based on 14 nm technology[C]// 2018 IEEE 38th International Conference on Electronics and Nanotechnology (ELNANO). Kiev, Ukraine, 2018: 116-120.
[6] WANG Leiou, WANG Donghui. Way prediction set-associative data cache for low power digital signal processors[C]// 2016 IEEE 13th International Conference on Signal Processing (ICSP). Chengdu, China, 2016: 508-512.
[7] LAKSHMINARAYANA N B, KIM H. Block-precise processors: low-power processors with reduced operand store accesses and result broadcasts[J]. IEEE Transactions on Computers, 2015, 64(11): 3102-3114.
[8] REIMANN T, SZE C C N, REIS R. Gate sizing and threshold voltage assignment for high performance microprocessor designs[C]// The 20th Asia and South Pacific Design Automation Conference. Chiba, Japan, 2015: 214-219.
[9] CAMPBELL S A. Fabrication engineering at the micro- and nanoscale[M]. 4 ed. New York: Oxford University Press, 2012: 599-612.
[10] HUANG Ping, XING Zuocheng. Impacts of NBTI/PBTI on power gated SRAM[J]. Journal of Central South University, 2013, 20(5): 1298-1306.
[11] LEE K, JEONG I, RO W W. Parallel in-order execution architecture for low-power processor[C]//2017 International SoC Design Conference (ISOCC). Seoul, Korea, 2017: 65-66.
[12] HUARD V, CACHO F, FEDERSPIEL X, et al. Technology scaling and reliability: challenges and opportunities[C]// 2015 IEEE International Electron Devices Meeting(IEDM). Washington, USA, 2015: 20.5.1-20.5.6.
[13] LIU Xin, SHEN Li, QIAN Cheng, et al. Dynamic power estimation with hardware performance counters support on multi-core platform[C]// Communications in Computer Information Science. Berlin Heidelberg, 2014: 177-189.
[14] WANG Bin, ZHANG Heming, HU Huiyong, et al. Physically based analytical model for plateau in gate C-V characteristics of strained silicon pMOSFET[J]. Journal of Central South University, 2013, 20(9): 2366-2371.
[15] 张骏, 樊晓桠, 刘松鹤. 多核、多线程处理器的低功耗设计技术研究[J]. 计算机科学, 2007, 34(10): 301-305.
ZHANG Jun, FAN Xiaoyu, LIU Songhe. Research of low power design techniques for multi-core and multithreading microprocessor[J]. Computer Science, 2007, 34(10): 301-305.
[16] HUANG Wei, ZHANG Ge, WANG Jun. High-performance processor power consumption modeling and evaluation method based on physical anti-standard[J] Journal of Computer-Aided Design & Computer Graphics, 2007, 19(11): 1471-1475.
[17] Shanghai IC R&D Center. Nano-scale CMOS process research and development technical data[R]. Shanghai: Shanghai IC R&D Center, 2012: 1-3.
[18] OKANO H, KAWABE Y, KAN R, et al. Fine grained power analysis and low-power techniques of a 128GFLOPS/58W SPARC64TMVIIIfx processor for peta-scale computing[C]// 2010 Symposium on VLSI Circuits. Honolulu, USA, 2010: 167-168.
[19] MOSHOVOS A. Checkpointing alternatives for high-performance, power-aware processors[C]// Proceedings of the 2003 International Symposium on Low Power Electronics and Design. Seoul, Korea, 2003: 318-321.
[20] ZENG Xiangyun, ZHAO Lianfeng, BIAN Dong. Research on the Low Power Design Method for the Embedded Multi-core Processor[C]// 2013 Fourth International Conference on Digital Manufacturing & Automation. Qingdao, China, 2013: 1141-1144.
(编辑 杨幼平)
收稿日期: 2019 -01 -08; 修回日期: 2019 -03 -10
基金项目(Foundation item):国家自然科学基金资助项目(61832018) (Project(61832018) supported by the National Natural Science Foundation of China)
通信作者:郭阳,博士,研究员,从事微处理器设计研究;E-mail: guoyang@nudt.edu.cn

