J. Cent. South Univ. (2012) 19: 1921-1926
DOI: 10.1007/s11771-012-1226-8
Relevance-based content extraction of HTML documents
WU Qi(吴麒), CHEN Xing-shu(陈兴蜀), ZHU Kai(朱锴), WANG Chun-hui(王春晖)
Network and Trusted Computing Institute, College of Computer Science, Sichuan University, Chengdu 610065, China
? Central South University Press and Springer-Verlag Berlin Heidelberg 2012
Abstract: Content extraction of HTML pages is the basis of the web page clustering and information retrieval, so it is necessary to eliminate cluttered information and very important to extract content of pages accurately. A novel and accurate solution for extracting content of HTML pages was proposed. First of all, the HTML page is parsed into DOM object and the IDs of all leaf nodes are generated. Secondly, the score of each leaf node is calculated and the score is adjusted according to the relationship with neighbors. Finally, the information blocks are found according to the definition, and a universal classification algorithm is used to identify the content blocks. The experimental results show that the algorithm can extract content effectively and accurately, and the recall rate and precision are 96.5% and 93.8%, respectively.
Key words: content extraction; DOM; node; relevance; information block
1 Introduction
With the rapid development of the Internet, the amount of information being gathered and stored on the Internet continues to increase. Therefore, it is an important task to discover valuable information. Web pages, as the carrier of the information, are mostly written by HTML language currently. Because the language is semi-structure language and does not have the strict definition similar to XML, it is very difficult to extract content from HTML pages. Moreover, the amount of redundant advertisements is so huge that the contents are hidden in a large amount of unrelated information. Because of the reasons mentioned above, extracting content from the pages accurately and efficiently becomes a particularly challenging job.
Many works have been done to tackle the difficulty. After analyzing the page structure and constructing template library, OU et al [1] use machine learning method to extract information from HTML pages. However, it is only intended to HTML pages corresponding to the template pages. On the basis of DOM tree, SANDIP et al [2] propose a method. In this method, the content is extracted by link text to non-link text ratio. MOHSEN et al [3] use layout structure to build the visual structure of a Web page and fulfill the partitioning task in terms of the visual structure. After a Web page is partitioned into some blocks, algorithms based on block features can be performed to extract content. However, few features can be used in these methods, so the accuracy of these methods is limited. Besides using information inside a Web page, YI et al [4] use a method called Site Style Tree to denote Web pages into content blocks and noisy blocks. Other similar methods are included in Refs. [5-6]. GOTTRON [7-8] allows to define combinations of CE algorithm with the aim to yield more reliable, more robust or even better result. However, it is difficult to optimize the parameters.
JAVIER et al [9] transform HTML page into text string sequence and extract content by the text length. Although the speed of extraction is fast, the accuracy of this method is low. TIM and WILLIAM et al [10] calculate the score by text-to-tag ratio in each line. Then, they adjust the score by Gaussian smoothing and extract contents. Because the relation between lines is neglected, some cluttered information will be mistaken for useful information. THOMAS [11] thinks that the text content is typically a long, homogeneously formatted region in a web document and the aim is to identify exactly these regions in an iterative process. This method may miss some texts. BING et al [12] use mountain model to extract content. This algorithm extracts text between the symbol “>” and “<”. Then, the score is calculated and the information ridges are obtained. Finally, the algorithm uses SVM classifier to identify the primary content blocks. Similar to the algorithm proposed by WENINGER, some advertisements will be mistaken for primary content because the relationship among the neighbors is ignored all the same.
In order to overcome the above obstacles and eliminate the limitations, a novel algorithm is proposed. At first, the HTML page is transformed into DOM tree and the IDs of leaf nodes are generated. Secondly, the score which is relevant to the text length of node is calculated. Then, taking the relation with neighbors into consideration, the score is adjusted. At last, the information blocks in HTML page are found and the content blocks are identified by classifier.
2 Basis of algorithm
DOM [13] is the document object model which is the standard interface specification developed by W3C. DOM transforms a document into a tree and provides access to the document. Each node in DOM tree represents a tag or a text inside the tag. Figure 1 shows that DOM parses a HTML page into a DOM tree.


Fig. 1 Simple HTML page parsed into DOM tree
As we all know, the valid information in HTML page is text. In other words, the aim of content extraction is to select valid information from the leaf nodes of the DOM tree. Therefore, it can be intuitively believed that the valid information can be obtained if the leaf nodes which have a longer text length from the page are extracted successfully. The text length of all leaf nodes is shown in Fig. 2.
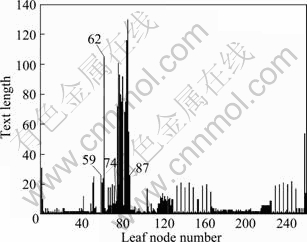
Fig. 2 Text length of leaf nodes
Definition 1: Content node
In a DOM tree, the content node is leaf node whose text is the most important and useful part in terms of semantic meaning.
The texts of content nodes located in [59, 62] and [74, 87] are contents. From Fig. 2, the text length of these leaf nodes is longer than that of other leaf nodes. Therefore, it is possible to extract content by using text length of the leaf nodes. But it also should be noted that there are also small amounts of other leaf nodes having a longer text length.
In web pages, the advertisement contains many texts. If the text length of leaf node is calculated only, the result will not be perfect. In order to estimate whether a leaf node is content node more accurately, the score of content node is defined as follows:
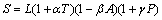 (1)
(1)
where the text length of leaf node is denoted by L; T is a Boolean value which indicates whether the text is fully stopped; Symbol A indicates whether it is anchor text; P is also a Boolean value which indicates whether the text includes a comma or a full stop at least; α, β and γ are predefined constants. Generally, the predefined constants are set as follows: α=2, β=0.5 and γ=1.
If the text is fully stopped, the score will increase by two times. If the text is anchor, the score of leaf node is upgraded by 50%. If the text includes punctuation at least, the score will increase by one time. The method (Eq. (1)) makes use of heuristic rules: The text of content node contains punctuation generally and anchor text is unlikely to be content of the page usually. Therefore, it is more accurate to extract content by the method mentioned above.
The score of all leaf nodes is shown in Fig. 3. From Fig. 3, almost all the scores of the leaf nodes located in [59, 62] and [75, 87] are larger than those of other nodes obviously. When extracting content from pages, the text of the nodes which have a higher score than the average score is outputted. Although this algorithm can select the majority of content nodes, few content nodes may still be missed. Consequently, the content node can not be selected completely. For example, the score of the 81st node is 3 and the score is lower than the average score, and even lower than some non-content nodes, so the 81st node which is content node will be mistaken for non-content node with the method mentioned above. In summary, using the formula mentioned above to extract content will lead to imperfect result that some content nodes will be missed.
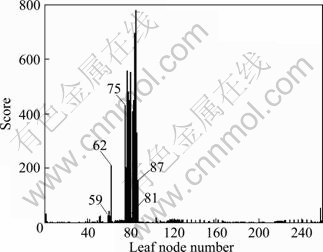
Fig. 3 Score of leaf nodes
In HTML pages, the content nodes are clustered into blocks. Generally, a leaf node is probably a content node when its neighbors are content nodes. Thereby, the score of nodes should be influenced by their surrosundings. In a word, high score nodes upgrade their neighbors, whereas the low ones degrade their neighbors.
3 Model of content extraction
3.1 Node ID
When the DOM tree is constructed, the IDs of leaf nodes are generated. The generation rules of IDs are as follows:
1) The root node is set to current node. From the root node, the tree is visited according to the order of breadth-first.
2) If the current node has N child nodes, the path ID from parent to child will be denoted by 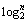 bits binary string. The string is started from “000…” and increases gradually. Then, the child is set to current node and this process is repeated until the entire DOM tree is visited.
bits binary string. The string is started from “000…” and increases gradually. Then, the child is set to current node and this process is repeated until the entire DOM tree is visited.
3) When the whole DOM tree is visited, the path ID from root to leaf node will be combined as the leaf node ID.
Figure 4 shows the generation process of the node IDs. From Fig. 4, the ID of topmost node is the whole 0, whereas the downmost node may not be the whole 1. The reason is that the child node count of some nodes cannot divide 2 exactly. In the DOM tree, the ID length equals the number of node layer. In other words, if the node is in deeper layer, the length of its ID is longer. For example, the node “000” is located in the 3rd layer, then the length of ID equals 3; the node “11010” is located in the 5th layer, then the length of ID equals 5. It is tempting to summarize the following characteristics:
1) The ID length of each leaf node may be different.
2) The leaf node IDs may not contain all values from all 0 to all 1, so the distribution of IDs may be discontiguous.
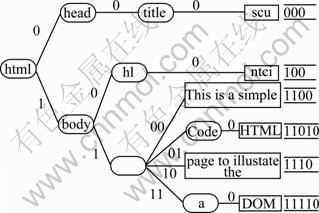
Fig. 4 Generation of IDs
3.2 Node relevance and smoothing score
In HTML pages, the content nodes are clustered into blocks. As shown in Fig. 4, the leaf nodes under the tag ‘p’ are content nodes and there is a high correlation among them. Therefore, the distance among the content nodes should be shorter, whereas the distance between content and non-content should be farther. According to this feature, the count of common prefixes between the IDs could indicate the node relevance.
Definition 2: Node relevance
Assume A and B are leaf nodes in a DOM tree. The IDs of node A and node B are denoted by DA and DB, respectively. Then, the node relevance between A and B is calculated as follows:
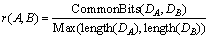 (2)
(2)
where the count of common prefixes between DA and DB is denoted by CommonBits(DA, DB). For example,
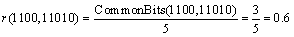
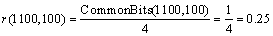
From the example mentioned above, the node relevance between the nodes under different tags is lower, whereas the node relevance between the nodes under the same tag is higher. Consequently, the node relevance can manifest the cluster degree among the content nodes.
As mentioned in Section 2, the score of some content nodes may be lower, but the score of their neighbors may be higher relatively. Therefore, the score of leaf nodes is depended on not only their own score, but also the score of their neighbors.
Definition 3: Smoothing score
Assume that the score of node i is denoted by Si, and the size of smoothing window is denoted by w. The symbol V indicates the average score of all nodes inside the smoothing window. Then, the smoothing score of the node is calculated as follows:
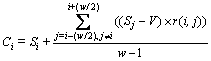 (3)
(3)
Figure 5 shows the smoothing score of all leaf nodes in the HTML page. Compared to Fig. 3, the scores of node 74 and 81 are “pulled” up a lot. Although the left neighbor of the 88th node has a high score, the score of the 88th node is still low. The reason is that the relevance between the 88th node and its left neighbor is so low that its score is “pulled” up a little. Although the surroundings of node 74 and node 88 are similar, because of their different relevance with neighbors, the 74th node will be recognized as content node and the 88th node will be identified as non-content node. From difference between Fig. 5 and Fig. 3, the 74th node and 81st node which are mistaken for non-content node in Fig. 3 will be recognized as content node, so the ID mechanism can adjust the score of content node effectively. However, the 88th node will be identified as non-content node all the time, so it can only slightly affect the score of non-content node in a degree. In a word, the smoothing score implements the idea that the score of node is depended not only on its score, but also on the score of its surroundings perfectly.

Fig. 5 Smoothing score
3.3 Identification of content blocks
In the HTML pages, there are some noises, such as copyright information, related readings and copyright notices. Since the score of the cluttered information may be very high, few cluttered information will be mistaken for content. Therefore, in order to improve the precision of content extraction, the HTML pages should be partitioned into blocks.
Definition 4: Information block
The information block is the leaf node set which satisfies the conditions as follows:
1) The set contains two or more adjacent nodes whose smoothing score is larger than average score of all nodes.
2) The minimal relevance among the sets must be greater than the relevance threshold or the score of all nodes in this set must be larger than average score of all nodes.
The relevance represents the cluster degree among the nodes in information block. The high relevance threshold implies the large cluster degree among the nodes. And the low relevance threshold implies the small cluster degree. When the information block is generated, it should be ensured that the nodes which belong to the same block are under the same tag as much as possible. In addition, although the score of some content nodes is lower than average score, these nodes will be added into information blocks. If so, the phenomenon that some nodes which are located in the edge of the block and have low score are recognized as non-content nodes is avoided.
The content block is the information block of which the text completely belongs to the content. Our main purpose is to identify the content blocks from the information blocks which contain advertisement and other noise blocks. Therefore, in order to identify the content blocks, the features of information blocks should be defined and the content blocks should be identified according to the features.
The features of the information blocks (BFV) are defined as follows: height (Eq. (4)), width (Eq. (5)), position (Eq. (6)), and cluster degree (Eq. (7)):
h=Vi/Vmax (4)
d=Li/Lmax (5)
N=Fi/O (6)
D=min(r(m, n)) (7)
where h indicates the height of the block, Vi indicates the average score of all nodes in this information block and Vmax indicates the maximal one in the average score of all information blocks; d indicates the width of the block, Li indicates the count of nodes in block and Lmax indicates the maximal one in all information blocks; N is the position of the information block, Fi is the number of the first leaf node in the block and O is the total number of nodes in the HTML pages; D which is denoted by the minimal relevance among the nodes in block represents the cluster degree of the block. If the D value of the block is higher, the nodes in block are ‘closer’.
According to the definition of BFV, the identification process of content block is as follows:
1) At first, the information blocks should be found according to the definition of information block.
2) The BFV of all information block is calculated.
3) The K-means algorithm [14] is used to determine whether the information block is the content block.
4) Output the text of all content blocks.
The pseudo-code of identification algorithm for content block is as follows:
Algorithm 1: Content extraction
Input: Text Nodes of The HTML
Output: Content
Data: temporary information block set BSet
begin
get the information blocks and add them into BSet;
for each B in BSet do
calculate the B.BFV;
isContent=KMeans_Classify(B.BFV);
if isContent then
Content=Content∪B.Text
endif
endfor
return Content;
end
4 Performance evaluation
Our experimental test data were from CWT70th [15] which were collected for testing the performance of information retrieval by Peking University. This data consisted of more than 70 000 HTML pages. In our experiment, 1 300 pages were selected randomly and the contents were marked manually. 300 pages of them were selected as training data set. 500 pages were selected as test data set T1 to determine the smoothing window size and relevance threshold. The remaining 500 pages were selected as test data set T2 to test the performance of the algorithm.
Assume that the content found from HTML page by our method is denoted by H1 and the real content is denoted by H2, and the intersection of H1 and H2 is denoted by H0. And then, the precision (p), recall (e) and F score (F) are defined as follows:
p=H0/H1 (8)
e=H0/H2 (9)
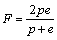 (10)
(10)
In the process of parameter optimization, the test data set T1 was used. Figure 6 illustrates the effects of smoothing window size and relevance threshold. When the relevance threshold equals 0.8, some un-content nodes are mistaken for content nodes because of the larger range of the relevance threshold. Therefore, the maximal F will only reach 91%. At this time, the recall rate is up to 98.7% and the precision is only 84.8%. When the relevance threshold is 1, the highest recall rate is 74.2% (F=81.9%). However, when the relevance threshold is less than 1, the lowest recall rate is 82.6% (F=88.7%). Thus, the recall rate of our algorithm is effectively improved by applying the node relevance. On the whole, the size of smoothing window is not the bigger the better and the relevance threshold is not the smaller the better. When the size of smoothing window equals 5 and the relevance threshold equals 0.9, the algorithm has the best performance. The recall rate is 96.7%, the precision is 94.1% and the F value is 95.4%. Hence, in our experiment, the size of smoothing window equals 5 and the relevance threshold T2 is used to evaluate the performance of our algorithm. The performances of our relevance-based algorithm, MM [12] and Text-to-Tag [11] are studied and depicted in Fig. 7. From the figure, the F value of our algorithm (relevance-based algorithm) is larger than other algorithms. The text-to-tag algorithm [11] has the highest recall rate, but its precision is the lowest. The text-to-tag algorithm [11] extracts content from pages according to the text-to-tag ratio in a line, so many anchor texts will be mistaken for the content. Therefore, the precision of this algorithm is low. The MM algorithm [12] neglects the relationship among the texts, so the performance of MM is worse than our algorithm. However, its performance is still better than text-to-tag. Our algorithm has the excellent performance on test data set and the precision and recall rate are up to 93.8% and 96.5% respectively.
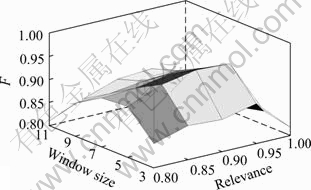
Fig. 6 Effects of window size and relevance threshold
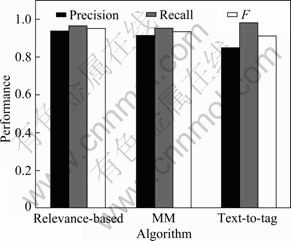
Fig. 7 Comparison of performance
5 Conclusions
1) A novel algorithm for content extraction is designed. In this algorithm, the text length is used. In the meantime, the feature of the anchor text and the punctuation is considered, so that the score is more accurate.
2) The ID mechanism is introduced. The ID can show the relationship among the neighbors correctly, so the score can be adjusted effectively.
3) The information block is proposed. On the basis of node relevance, the information blocks are found and the content blocks are identified.
4) According to the experimental results, the algorithm has the excellent performance on test data set and can provide good support for information retrieval.
References
[1] OU J W, DONG X B, CAI B. Topic information extraction from template web pages [J]. Journal of Tsinghua University: Science and Technology, 2005, 45(S1): 1743-1747.
[2] SANDIP D, PRASENJIT M, C LEE G. Identifying content blocks from web documents [C]// 2005 International Symposium on Methodologies for Intelligent Systems (ISMIS 2005). New York: LNAI, 2005: 285-293.
[3] MOHSEN A, MIR M P, AMIR M R. Main content extraction from detailed web pages [J]. International Journal of Computer Applications, 2010, 4(11): 18-21.
[4] YI L, LIU B, LI X L. Eliminating noisy information in web pages for data mining [C]// The Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Washington: ACM Press, 2003: 296-305.
[5] SUHIT G, HILA B, GAIL K, SALVATORE S. Verifying genre-based clustering approach to content extraction [C]// The 15th International World Wide Web Conference. Budapest: ACM Press, 2006: 875-876.
[6] DEBNATH S, Automatic identification of informative sections of web pages [J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 17(9): 1233-1246.
[7] GOTTRON T. Combining content extraction heuristics: the combined system [C]// The 10th International Conference on Information Integration and Web-based Application & Services. New York: ACM Press, 2008: 591-594.
[8] GOTTRON T. An evolutionary approach to automatically optimize web content extraction [C]// The Joint Venture of the 17th International Conference Intelligent Information System (IIS) and the 24th International Conference on Artificial Intelligence (AI). Krakow: The IEEE Computational Intelligence Society, 2009: 331-341.
[9] JAVIER A M, KOEN D, MARIE F M. Language independent content extraction from web pages [C]// The 9th Dutch-Belgian Information Retrieval Workshop. Netherland: University of Twente, 2009: 50-55.
[10] TIM W, WILLIAM H H. Web content extraction through histogram clustering [C]// The 18th International Conference on Artificial Neural Networks in Engineering (ANNIE 2008). St. Louis: Lecture Notes in Computer Science, 2008: 124-132.
[11] THOMAS G. Content code blurring: A new approach to content extraction [C]// The 2008 19th International Conference on Database and Expert Systems Application. Washington: IEEE Computer Society, 2008: 29-33.
[12] BING L D, WANG Y X, ZHANG Y. Primary content extraction with mountain model [C]// The 8th IEEE International Conference on Computer and Information Technology. Sydney: IEEE Press, 2008: 479-484.
[13] W3C. Document object model [EB/OL]. [2011-3-5]. http://www.w3. org/DOM/.
[14] MACQUEEN J. Some methods for classification and analysis of multivariate observations [C]// The 5th Berkeley Symposium on Mathematical Statistics and Probability. Berkeley: Berkeley Press, 1967: 281-297.
[15] Computer Networks and Distributed System Laboratory, Peking University. CWIRF [EB/OL]. [2011-3-8]. http://www.cwirf. org/.
(Edited by YANG Bing)
Foundation item: Project(2012BAH18B05) supported by the Supporting Program of Ministry of Science and Technology of China
Received date: 2011-05-13; Accepted date: 2011-07-13
Corresponding author: CHEN Xing-shu, Professor, PhD; +86-13981857689; E-mail: chenxs@scu.edu.cn

