J. Cent. South Univ. (2012) 19: 504-510
DOI: 10.1007/s11771-012-1032-3
A robust feature extraction approach based on an auditory model for classification of speech and expressiveness
SUN Ying(孙颖)1, 2, V. Werner2, ZHANG Xue-ying(张雪英)1
1. College of Information Engineering, Taiyuan University of Technology, Taiyuan 030024, China;
2. Department Electronic and Informatics, Laboratory for Digital Speech and Audio Processing,
Vrije Universiteit Brussel, B-1050 Brussels, Belgium
? Central South University Press and Springer-Verlag Berlin Heidelberg 2012
Abstract: Based on an auditory model, the zero-crossings with maximal Teager energy operator (ZCMT) feature extraction approach was described, and then applied to speech and emotion recognition. Three kinds of experiments were carried out. The first kind consists of isolated word recognition experiments in neutral (non-emotional) speech. The results show that the ZCMT approach effectively improves the recognition accuracy by 3.47% in average compared with the Teager energy operator (TEO). Thus, ZCMT feature can be considered as a noise-robust feature for speech recognition. The second kind consists of mono-lingual emotion recognition experiments by using the Taiyuan University of Technology (TYUT) and the Berlin databases. As the average recognition rate of ZCMT approach is 82.19%, the results indicate that the ZCMT features can characterize speech emotions in an effective way. The third kind consists of cross-lingual experiments with three languages. As the accuracy of ZCMT approach only reduced by 1.45%, the results indicate that the ZCMT features can characterize emotions in a language independent way.
Key words: speech recognition; emotion recognition; zero-crossings; Teager energy operator; speech database
1 Introduction
Speech is one of the most effective human communication ways. Emotion refers to the maintenance and change of some relations between human beings and external environment [1]. All kind of speeches produced by humans include information about the speaker, and the emotional and physical conditions of the speaker [2]. The automatic detection of the human emotional and physical states from a speaker’s speech is one of the most recent challenges in speech technology, and becomes important for many application areas, such as safety, human-machine interaction and public health.
The studies of emotional speech in recent years can be classified into three groups: 1) Building for more natural, real-life and multi-languages data; 2) Taking into account not only emotional speech model for one emotion state but also cross emotion states; 3) The trend towards a thorough exploitation of the feature space used for classification. Relatively few studies were conducted using more than one database, for example, BATLINER et al [3] discussed similar or different characteristics of different databases. In order to detect human emotional states reliably, statistical measures of speech pitch and intensity contours and the change rate of the short-time spectra were used as typical features of the expression of emotion in speech [3-5].
Taiyuan University of Technology (TYUT) emotional speech database is designed for emotional recognition experiments. This database contains two languages (Mandarin and English). A new method of feature extraction called zero-crossings with maximal Teager energy operator (ZCMT) was proposed in this work. The ZCMT feature extraction is based on a model for human auditory perception using zero-crossing intervals in the sub-band domain to represent the rate of change of the frequency information of signal [6] and the Teager energy to represent intensity information [7].
2 Feature extraction approaches
2.1 ZCMT approach
Figure 1 shows the block diagram of ZCMT, which is composed of a band-pass filter bank (BPF), detection blocks for variational rate of frequency in each sub-band channels, Teager energy detection blocks and the frequency receiver block.

Fig. 1 Basic structure of ZCMT feature extraction approach
1) Band-pass filter bank
The filter-bank consists of 16 FIR band-pass filters which are designed to emulate the basilar membrane of cochlea [8]. The basilar membrane of the cochlea functions is treated as a mechanical resonator. The air pressure variations due to the speech signal are transmitted through the inner ear and the oval window at the base of the cochlea in which they are converted into traveling waves along the basilar membrane. The places of the maximum excitation of the basilar membrane by the traveling wave depend on the frequency contents of the signal. Frequencies higher than 800 Hz are distributed logarithmically along the basilar membrane [9]. The relationship of frequency and position can be approximated as
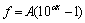 (1)
(1)
where f is the frequency, x is the normalized distance along the basilar membrane (x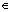 [0, …, 1]); A=165.4 and α=2.1.
[0, …, 1]); A=165.4 and α=2.1.
Sixteen equidistance points along with the basilar membrane are chosen. Each point corresponds to a finite impulse response (FIR) filter of the filter bank. The center frequencies fi of the filter bank are determined by Eq. (1) and are chosen in the range of 200-4 000 Hz. The bandwidths are proportional to the equivalent rectangular bandwidth (ERB) as approximated by Eq. (2) [9-10]:
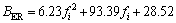 (2)
(2)
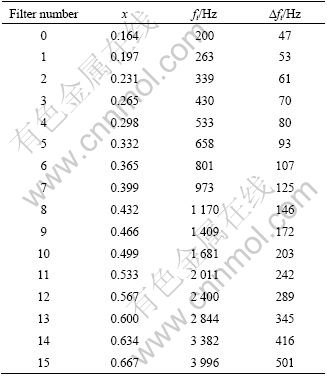
where fi is the center frequency of each filter. Table 1 gives the relationship of the normalized distance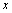 , the center frequencies fi and the bandwidths ?fi of each FIR filter.
, the center frequencies fi and the bandwidths ?fi of each FIR filter.
2) Detection for variational rate of frequency in each sub-band channels
A positive zero crossing is detected when the current sample value is smaller than zero and the next sample value is larger than zero. The number of positive zero-crossings per second is the zero-crossing rate. The zero-crossing numbers of speech signals with different frequency contents are different. For example, the number of zero-crossing is much higher in high- frequencies than in low frequencies. So, the variational rate of signal can be reflected by the zero-crossing rate. In this work, the frequency information is represented by the interval of positive zero-crossing.
Table 1 Relationship of normalized distance, center frequencies and bandwidths of FIR filters
The exact location of each zero-crossing point is approximated by
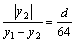 (3)
(3)
where y1 and y2 are the amplitude values of the adjacent samples with different signs. To find out the precise position of the zero-crossing, the distance between adjacent samples are divided into 64 units. Figure 2 shows the sketch map of the location of zero-crossing point.
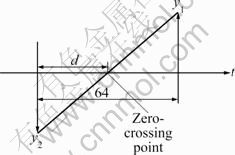
Fig. 2 Location of zero-crossing point
Actually, the number of samples between adjacent zero-crossings represents information in the time domain. In order to convert it into frequency domain information, 16 frequency bins are used [11]. Each frequency bin covers a frequency band. The number of samples between zero-crossing is mapped into the right frequency fr of the frequency bins by using Eq. (4):
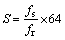 (4)
(4)
where S is 64 times of the number of samples between successive zero crossings and fs is the sampling frequency. The relationship between the frequency bins S and the right frequency of frequency bins is listed in Table 2. According to Table 2, the frequency range of the signal can be determined.
Table 2 Relationship between frequency bins, number of samples and right frequency of frequency bins (fs=11.025 kHz)

3) Teager energy detector
The Teager energy operator (TEO) was first proposed by KAISER [12]. Since then, many applications have been developed by using TEO. One of the most important uses of the operator is as a signal feature. The TEO is defined in the discrete time domain [12-13]:
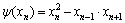 (5)
(5)
where xn, xn+1 and xn-1 are the current sample value, the next sample value and the previous sample value of speech signal, respectively. The maximum absolute value sample between successive upward-going zero-crossings is found by the Teager energy detector block. Then, the TEO value which is the output of the Teager energy detector block is computed by Eq. (5).
4) Frequency receiver
The frequency information and the output of the Teager energy detector are combined by the frequency receiver [14]. Denote xk(t) as the output of the k-th filter, Zk as the number of upward-going zero-crossings in xk(t), and Pk,l as the maximum sample between the l-th and (l+1)-th zero-crossings of xk(t). The output of the frequency receiver at time m is defined as
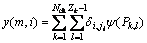 1≤i≤N, 0≤j≤15 (6)
1≤i≤N, 0≤j≤15 (6)
where N is the number of filters, Nch is the number of frequency bins, 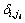 is the Kronecker operator. For each filter channel, jl is reserved as the index of frequency bin. So, the frequency receiver can get the frequency information and Teager energy information at certain time interval. At last, the whole features are combined by the 16 frequency receivers [15].
is the Kronecker operator. For each filter channel, jl is reserved as the index of frequency bin. So, the frequency receiver can get the frequency information and Teager energy information at certain time interval. At last, the whole features are combined by the 16 frequency receivers [15].
2.2 TEO approach
The TEO approach proposed by HE et al [16] is as follows:
1) Segment the speech signal. The frame length is 110 samples. And there is 50% overlap between frames.
2) Calculate the TEO within 16 frequency bands determined by ERB, as listed in Table 1.
3) The output of each filter is used as the features denoted as TEO.
3 Classifier
A radial basis function (RBF) neural network classifier was used in the isolated word recognition experiments on neutral (non-emotional) speech and a support vector machine (SVM) classifier was used for emotional speech recognition.
Radial basis function is a kind of novel, effective forward-feedback neural network [17]. In this work, the number of nodes of RBF input layer was 1 024. Because the number of frequency bins was 16 and each pair of successive samples was divided into 64 parts, the ZCMT system normalized the time and the amplitude to 64×16= 1 024 dimensions at its output. The number of nodes of the latent layer and the output layer were according to the number of words for training and testing.
A SVM algorithm was used for classifying features in the emotional speech recognition experiment. Support vector machine was proven to be a powerful technique for pattern classification. The SVM maps inputs into a high-dimensional space and then separates classes with a hyperplane [18-19]. Because SVM is a discriminative classifier, the application of SVM to speech emotion recognition was considered. In this work, the different sets of emotional features were used in turn as the input for SVM. The input features which were used for training, built each emotion state model. Then, testing features could be classified to each emotional state. Figure 3 shows the whole recognition system.
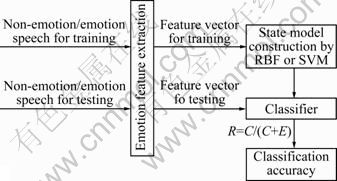
Fig. 3 Block of whole recognition system
4 Speech database
4.1 Isolated words database
The isolated words database was used for speaker-independent, isolated word recognition of neutral (non-emotional) speech. The vocabulary sizes used in the experiments were 10 words, 20 words, 30 words, 40 words and 50 words (including ten digits and 40 command words), respectively. Sixteen speakers uttered each of the words three times. Nine persons utterances were used as the training set and the remaining seven persons utterances as the test set. Additive white Gaussian noise was added with four levels to evaluate the robustness of the features.
4.2 TYUT database
The TYUT database was recorded at January, 2010 in Taiyuan University of Technology to study speech emotion recognition and synthesis [20-21]. Followed principles were considered when the sentences were chosen.
1) The chosen sentences are emotion free. It is easy to add different emotion states to sentences for actors.
2) The chosen sentences are declarative sentences and can be applied suitably for both male and female.
3) The chosen sentences are short ones. If the sentences are too long, the parameters of emotional speech could be weakened.
4) The chosen sentences cannot be any emotional state tendencies.
At last six Mandarin sentences and five English sentences were chosen. Each sentence was spoken nine times for each emotional class by each of 14 male actors and 13 female actresses. Three emotional classes were included in the database, namely Happiness, Anger and Neutral. Therefore, the total number of Mandarin sentences is 6×9×(14+13)×3=4 374 and the number of English sentences is 5×9×(14+13)×3=3 645. The recoding was performed in a quiet environment with 16-bit per sample and 11.025 kHz sampling frequency. To assess the emotional quality and naturalness of the utterances, a perception test was carried out. Eleven listeners were sitting in front of a stereo playback system in a quite room. Each emotional sentence was played in isolation. Listeners were not told the emotional state when they were listening. After the emotional sentence was played, the listeners estimated the emotional state. At last, 890 sentences for both languages together were chosen by eleven listeners.
4.3 Berlin database
B.The Berlin database is a German database that was recorded in an anechoic chamber in the Technical University of Berlin. Ten actors (five female and five male) simulated seven emotions (Neutral, Anger, Fear, Happiness, Sadness, Disgust and Boredom). Each emotion category contains ten German sentences. The recordings were made with a sampling frequency of 48 kHz and later down-sampled to 16 kHz with high- quality recording equipment. A perception test was carried out after the recording and 493 sentences were included in the database [22].
Since the Berlin database contains four extra emotional classes that are not available in the TYUT database, those four classes of emotions for carrying out emotional speech recognition experiments were removed. And considering the accuracy and the generalization of the experiments, 91 sentences of TYUT-database and 71 sentences of Berlin-database were chosen randomly.
5 Classification experiments
In particular, in emotional speech recognition experiments, two kinds of experiments were carried out: the first kind was performed on each of the two databases individually and the second kind was performed on the merged databases of all three languages. The ZCMT and TEO approaches were used to compare their performances on both non-emotional and emotional speech. For the experiments on emotional speech, about two thirds of the sentences were used for training and the rest was used for testing, as listed in Table 3.
Table 3 Number of sentences of three emotion states in each database

The classification accuracy can be calculated as
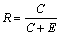 (7)
(7)
where R is the classification accuracy; C is the number of the sentences which are classified correctly; E is the number of the sentences which are classified in error.
5.1 Isolated word recognition of non-emotional speech
The recognition results in different signal-to-noise ratios (SNR) are given in Table 4. Table 4 indicates that ZCMT performs much better than TEO. The average recognition of ZCMT is 92.04%. In the condition of clean speech and ten words, the recognition rate reaches 97.62%. Even in the lowest SNR, the average recognition rate of ZCMT is 89.54%. This kind of experiments show that ZCMT can be used in isolated word recognition of non-emotional speech more effectively than TEO. This is because the ZCMT approach contains not only the Teager energy information between zero-crossing points but also frequency information. This means there is more speech information in ZCMT than in TEO. The ZCMT approach also has better robustness characteristics than TEO.
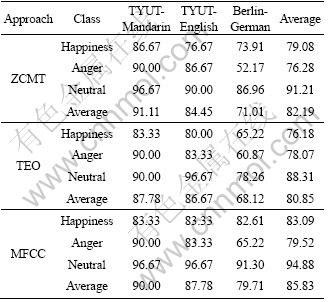
5.2 Single language experiments on emotional speech
This kind of experiment is performed on one language database at a time. For example, when class Happiness emotion of Mandarin is tested, the sentences for testing are all from class Happiness sentences in TYUT-Mandarin. The sentences for training are from all the emotion states of TYUT-Mandarin.
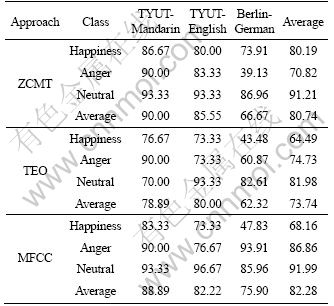
Table 5 gives the recognition rate of each language by using ZCMT, TEO and MFCC, respectively. According to Table 5, the average recognition rate of ZCMT is 82.19%, that of the TEO approach is 80.85%, and that of the MFCC approach is 85.83%. The results show that these three methods can characterize speech emotions effectively. However, the MFCC approach gives the best performance.
In terms of emotion class, the recognition rate of the Neutral emotion is the highest. This is in line with the fact that the recognition by human listeners was also the highest for the neutral class. And the Neutral emotion is the most common emotion in daily life and it could be performed easily by actors when the database is recorded. In terms of language class, the results of TYUT-Mandarin are the best of the three languages. The probable reason is that TYUT database is recorded by actors whose native language is Mandarin. It is much easier to perform better emotional characteristics in Mandarin than in English for these actors. And in addition, all recognition rates on Berlin are not very good. It can be speculated that the emotion performance in the Berlin database is inherently worse than in the TYUT database or these three methods are less suitable for German.
Considering each method only, MFCC performs best in all emotion classes of German and classes in Happiness and Neutral of TYUT-English. The ZCMT has the highest recognition rate in class Happiness of TYUT- Mandarin and class Anger of TYUT-English. So, MFCC is the best method.
The results indicate that the change rate of the frequency information and the intensity information of the signal are typical features for emotional speech classification. The ZCMT method is not just a simple link between these two features. It is an optimized combination of them. And the combination is based on a model for human auditory perception. So, the ZCMT approach is an effective feature for emotional speech classification.
Table 4 Recognition results two features in different SNR (%)
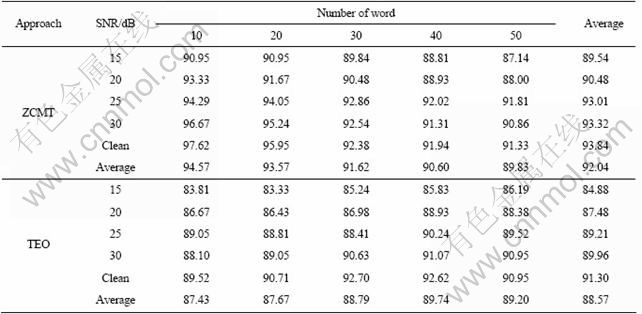
Table 5 Percentage of classification accuracy of each language (%)
5.3 Merged-database of three languages experiments in emotional speech
This kind of experiment is performed using a merged-database paradigm. For example, when class Happiness in Mandarin is tested, the sentences for training are all the emotion training sentences in all three databases. This means the number of sentences for training is 61+61+48=170. And the sentences for testing are only from class Happiness in TYUT-Mandarin. This means the number of sentences for testing is 30.
Table 6 gives the results of merged-database of three languages by using ZCMT, TEO and MFCC. From Table 6, the recognition rates of different classes with different languages are changed. In totally, the recognition rates are all reduced. The ZCMT approach is reduced by 1.45%, the TEO approach is reduced by 7.11% and the MFCC approach is reduced by 3.55%. In terms of emotion class, the performance of MFCC is changed. Class Neutral has the highest recognition rate. In terms of language class, the performance of TEO is changed. TYUT-English database has the highest recognition rate. Furthermore, in terms of each method, MFCC performs best in class Neutral of TYUT-English and class Anger of German. The ZCMT approach has the highest recognition rate in class Happiness of TYUT-Mandarin, classes Happiness and Anger of TYUT-English and classes Happiness and Neutral of German.
Although, in the two kinds of experiments of this work, the MFCC approach performs best in emotion state classification and the ZCMT feature declines to the least of the three method, ZCMT is the most robust feature of the three. This is because the ZCMT approach is an optimized combination of two typical emotional speech features. There are more emotional features in ZCMT than in MFCC. And this approach is based on a model for human auditory perception. This is the main advantage in ZCMT compared with TEO. The merged-database of three languages experiments in this work shows that ZCMT has better database adaptability.
Table 6 Percentage classification accuracy of merged-database (%)
6 Conclusions
1) The ZCMT approach is better than TEO for isolated words recognition of non-emotional speech and can also better represent the characteristic of different emotional states. And it can be used in different languages and different databases. Merged-databases experiments show that ZCMT, MFCC and TEO are all database dependent. But the database has little influence with ZCMT. It is more robust than TEO and MFCC when a merged-database paradigm is used.
2) As the particularity of emotion database, only two kinds of three languages database were used. Future works include a kind of study an the ZCMT feature in experiments with increased number of databases and increased number of languages, and an evaluation of the ZCMT feature with more realistic non-acted emotional speech.
References
[1] MENG Qing-mei, WU Wei-guo. Artificial emotional model based on finite state machine [J]. Journal of Central South University of Technology, 2008, 15(5): 694-699.
[2] DEVILLERS L, VAUDABLE C, CHASTAGNOL C. Real-life emotion-related states detection in call centers: A cross-corpora study [C]// Proceedings of 11th Annual Conference of the International Speech Communication Association. Chiba Japan: ISCA, 2010: 2350-2353.
[3] Batliner A, Steidl S, Schuller B, Seppi D, Vogt T, Wagner J, Devillers L, Vidrascu L, Aharonson V, Kessous L, Amir N. Whodunnit-Searching for the most important feature types signalling emotion-related user states in speech [J]. Computer Speech and Language, 2011, 25(1): 4-28.
[4] Ververidis D, Kotropoulos C. Emotional speech recognition: Resources, features, and methods [J]. Speech Communication, 2006, 48(9): 1162-1181.
[5] Yang B, Lugger M. Emotion recognition from speech signals using new harmony features [J]. Signal Processing, 2010, 90(5): 1415-1423.
[6] LUGGER M, YANG B. On the relevant of high-level features for speaker independent emotion recognition of spontaneous speech [C]// Proceedings of 10th Annual Conference of the International Speech Communication Association. Brighton, United Kingdom: ISCA, 2009: 1995-1998.
[7] Boudraa A, Benramdane S, Cexus J, Chonavel T. Some useful properties of cross-ψB-energy operator [J]. AEU-International Journal of Electronics and Communications, 2009, 63(9): 728-735.
[8] KIM D, LEE S, KIL R. Auditory processing of speech signal for robust speech recognition in real-world noisy environments [J]. IEEE Transactions Speech and Audio Processing, 1999, 7(1): 55-58.
[9] Ramachandran R P, Mammone R J. Modern methods of speech processing [M]. Dordrecht: Kluwer Academic Publishers, 1994.
[10] FILLON T, PRADO J. Evaluation of an ERB frequency scale noise reduction for hearing aids: A comparative study [J]. Speech Communication, 2003, 39(1/2): 23-32.
[11] JIAO Zhi-ping. Research on improved ZCPA speech recognition feature extraction algorithm [D]. Taiyuan: College of Information Engineering, Taiyuan University of Technology, 2005. (in Chinese)
[12] KAISER J F. On a simple algorithm to calculate the ‘energy’ of a signal [C]// 1990 International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Albuquerque: IEEE, 1990: 381-384.
[13] SALZENSTEIN F, BOUDRAA A O. Multi-dimensional higher order differential operators derived from the Teager-Kaiser energy-tracking function [J]. Signal Processing, 2009, 89(4): 623-640.
[14] HAQUE S, TOGNERI R, ZAKNICH A. Perceptual features for automatic speech recognition in noisy environments [J]. Speech Communication, 2009, 51(1): 58-75.
[15] Kim D S, Lee S Y, Kil R M. Auditory processing of speech signal for robust speech recognition in real-world noisy environments [J]. IEEE Transactions Speech and Audio Processing, 1999, 7(1): 55-58.
[16] HE L, LECH M, MADDAGE N, ALLEN N. Emotion recognition in speech of parents of depressed adolescents [C]// ZHOU H. Proceedings of 3rd International Conference on Bioinformation and Biomedical Engineering. Redhook: IEEE, 2009: 1-4.
[17] CHEN S. Orthogonal least squares learning algorithm for radial basis function networks [J]. IEEE Transcations on Neutral Network, 1991, 2(2): 302-309.
[18] Campbell W M, Campbell J P, Reynolds D A, Singer E, Torres-Carrasquillo P A. Support vector machines for speaker and language recognition [J]. Computer Speech and Language, 2006, 20(2/3): 210-229.
[19] ZHANG Hong-liang, ZOU Zhong, LI Jie, CHEN Xiao-tao. Flame image recognition of alumina rotary kiln by artificial neural network and support vector machine methods [J]. Journal of Central South University of Technology, 2008, 15(1): 39-43.
[20] SUN Ying, ZHANG Xue-ying. Realization of improved HMM-based speech synthesis system [C]// 2010 International Symposium on Computer, Communication, Control and Automation. Tainan: IEEE, 2010: 354-357.
[13][21] SUN Ying, ZHANG Xue-ying. A study of zero-crossings with peak-amplitudes in speech emotion classification [C]// PAN Jeng-shyang, SUN Sheng-he, SHIECH C S. The First International Conference on Pervasive Computing, Signal Processing and Applications. Harbin: IEEE, 2010: 328-331.
[22] Burkhardt F, Paeschke A, Rolfes M, Sendlmeier W, Weiss B. A database of German emotional speech [C]// Proceedings of 6th Annual Conference of the International Speech Communication Association, Lisben Portngal: ISCA, 2005: 1517- 1520.
(Edited by DENG Lü-xiang)
Foundation item: Project(61072087) supported by the National Natural Science Foundation of China; Project(2010011020-1) supported by the Natural Scientific Foundation of Shanxi Province, China; Project(20093010) supported by Graduate Innovation Foundation of Shanxi Province, China
Received date: 2011-04-15; Accepted date: 2011-05-25
Corresponding author: ZHANG Xue-ying, Professor; Tel: +86-351-6014942; E-mail: tyzhangxy@163.com

