一种基于危险理论的恶意代码检测方法
黄聪会,陈靖,龚水清,罗樵,朱清超
(空军工程大学 信息与导航学院,陕西 西安,710077)
摘要:针对当前基于多维特征检测恶意代码过程中缺乏有效的特征综合手段及检测方法问题,提出一种基于危险理论的恶意代码特征提取、融合及检测方法。该方法采用n-gram算法提取恶意代码运行时API调用序列特征,再将多个特征融合成危险信号和安全信号,最后利用确定性树突状细胞算法检测恶意代码。实验结果表明:与其他4种检测算法(朴素贝叶斯算法、决策树算法、支持向量机算法、基于实例的学习算法)相比,该方法具有更低的漏报率和误报率。
关键词:危险理论;确定性树突状细胞算法;恶意代码检测;API调用序列;检测率
中图分类号:TP309 文献标志码:A 文章编号:1672-7207(2014)09-3055-06
A malicious code detection method based on danger theory
HUANG Conghui, CHEN Jing, GONG Shuiqing, LUO Qiao, ZHU Qingchao
(School of Information and Navigation, Air Force Engineering University, Xi'an 710077, China)
Abstract: Aiming at the problem that there was no effective means to synthesize features and detection method during the process of detecting malware with multi-level features, a method based on the danger theory was proposed to extract malware characteristics, synthesize them, and detect malware. This method used the n-gram algorithm to extract the runtime API call sequence features of malware, and then integrated the features into danger signal and safety signal, lastly used the deterministic dendritic cell algorithm to detect malware. The experimental results show that compared with the other four detection algorithms (Naive Bayes algorithm, decision tree algorithm, support vector machine algorithm and instance-based learning algorithm), the proposed method has lower false negative rate and false positive rate.
Key words: danger theory; deterministic dendritic cell algorithm; malicious code detection; API call sequence; detection rate
信息化技术推动企业业务信息化和网络化的同时,也使其面临各种安全威胁。其中最显著的威胁来自恶意代码。恶意代码是一类威胁计算机系统机密性、完整性、可用性的代码序列,如病毒、木马、蠕虫等[1]。恶意代码的严重危害使其检测问题一直是信息安全研究的重点。根据特征使用方式的不同,恶意代码的检测方法可分为基于唯一特征、基于多种特征和基于综合特征3类。基于唯一特征检测方法通过提取样本的唯一特征来识别一种或一类恶意代码。根据唯一特征抽象程度的不同,此类检测方法分为基于代码特征方式[2]、基于行为特征方式[3-5]和基于语义特征方 式[6]。随着抽象程度的加深,其对抗恶意代码迷惑技术的能力不断增强,但实现难度和代价也不断提高。基于多种特征检测方法通过提取样本的多种不同特征以识别恶意代码。此类检测方法通常提取样本中抽象程度较低的多个特征,如字节码序列、输入参数特征、API调用序列等[7-8]。由于多种不同特征共同判定未知恶意代码,因此此类方法具有较强的抵御代码迷惑技术的能力。但孤立的特征并不能作为判断代码行为恶意性的充分依据,因此具有较高的误检率。基于综合特征的检测方法将多种特征融合成一个或多个综合特征以识别恶意代码。例如,刘巍伟等[9]采用改进的攻击树模型将多种代码特征综合,以识别未知恶意代码。此类检测方法兼顾多种不同特征,并考虑了特征间的内聚性,去除了冗余特征,因此具有较高的检测率和较低的误检率,从而成为当前的研究热点。目前基于综合特征的检测方法还处于发展阶段,缺乏有效的特征综合方法及检测算法,为此本文作者提出一种基于危险理论的恶意代码特征提取、融合及检测的方法。该方法首先采用n-gram算法提取多个恶意代码运行时的API调用序列特征,然后采用危险理论的思想将多个API调用序列特征进行融合,最后基于融合后的特征,采用确定性树突状细胞算法(deterministic dendritic cell algorithm, dDCA)检测恶意代码。该方法具有以下优点:不再关注代码的单个特征,而是将各种特征进行融合,有利于给出代码恶意性的准确判定。本方法关键在于各种特征的融合,增加或减少部分代码特征对检测性能的影响不大,因此具有较强的开放性和鲁棒性。
1 危险理论与树突状细胞算法
危险理论是一种备受争议的著名免疫理论,由免疫学家Matzinger于1994年提出[10]。她对自我与非自我辨析是引起免疫应答的原因提出质疑,并认为引起免疫应答的原因不是所有的非自我物质,而是对机体有害的非自我物质。此类物质将引起受损细胞产生有害信号,且在触及到抗原提呈细胞(antigen presenting cell, APC)后,免疫系统将产生应答。
基于危险理论,Greensmith等[11]在研究自然树突状细胞(dendritic cell, DC)功能的基础上,提出树突状细胞算法(dendritic cell algorithm, DCA)。树突状细胞是一类对组织环境中危险信号变化特别敏感的专职抗原提呈细胞。它具有3种状态,分别为未成熟状态、半成熟状态和成熟状态。初始时DC为未成熟状态,而随着时间的推移,DC在协同刺激信号(costimulatory molecules, CSM)的刺激下达到一定阈值时,DC的状态将进行迁移。其中当协同刺激信号中的半成熟输出信号大于成熟输出信号,DC进入半成熟状态;反之,DC进入成熟状态。树突状细胞算法即是对自然树突状细胞工作原理的抽象,其工作原理如图1所示。

图1 DCA基本原理
Fig. 1 Basic principle of DCA
2 恶意代码检测方法
在研究危险理论和树突状细胞算法的基础上,提出一种以树突状细胞算法为核心的恶意代码检测方法,并设计如图2所示的恶意代码检测系统架构。整个系统分为恶意代码特征提取融合流程和未知恶意代码检测流程。其中:恶意代码特征提取融合流程用于提取和融合恶意代码特征,并构建分类器,主要由动态分析、特征选择和融合、分类器构建3个模块组成。未知恶意代码检测流程用于恶意代码的判定,主要由动态分析、特征融合、分类器检测3个模块构成。
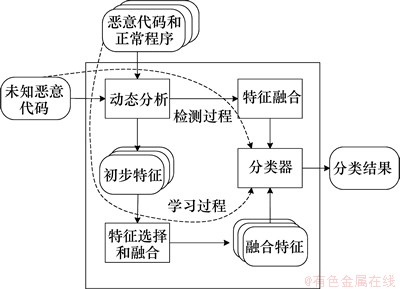
图2 恶意代码检测系统架构
Fig. 2 Architecture for malware detection
2.1 特征提取
随着多态技术、变形技术等代码迷惑技术的流行,静态分析技术已经无法满足当前恶意代码检测的需 要[12]。因此,系统采用动态分析技术提取恶意代码特征。本文选择运行时API调用序列作为恶意代码特征,并使用API Monitor[13]方法进行捕捉。
获取API调用序列后,将采用n-gram算法提取特征[14]。n-gram算法最早用于文本分类和信息检索中,核心思想是统计连续n个词出现的频率。在本系统中,将用于统计n个连续的API调用序列是否在恶意代码或正常代码中出现。在n-gram算法中,n越小,那么对应特征包含的信息将越不充分;n越大,特征越多,将增加计算的复杂度。根据文献[15]中实验效果,选择n=4。
2.2 特征选择和融合
采用4-gram算法将提取非常多的特征,但不是每个特征都具有较强的分类效果,因此需要筛选出具有较强分类效果的特征。本文采用信息增益衡量每个特征的分类效果[16]。设Y为分类结果的随机变量,Xi为特征i对应的随机变量,则特征i的信息增益由下式确定:
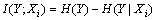 (1)
(1)
其中:H(Y)为随机变量Y的熵,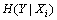 为在随机变量Xi的前提下,随机变量Y的条件熵。信息增益
为在随机变量Xi的前提下,随机变量Y的条件熵。信息增益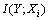 越大,说明随机变量Xi对应的特征i的分类效果越好。
越大,说明随机变量Xi对应的特征i的分类效果越好。
选取信息增益值最大的前500个特征,构成特征集合S。在树突状细胞算法中,其输入是抗原和各种信号。对应本系统,抗原即是待检测的恶意代码,而各种信号则由特征集合S融合后产生。下面给出特征融合的形式化描述。
设U表示已知分类的程序集合,对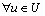 ,u满足
,u满足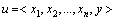 ,其中
,其中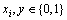 , i=1, 2, …, n,xi=0表示u中不存在特征xi,反之亦然;y=0表示u为正常代码,y=1表示u为恶意代码。M表示U中的恶意代码集合,则
, i=1, 2, …, n,xi=0表示u中不存在特征xi,反之亦然;y=0表示u为正常代码,y=1表示u为恶意代码。M表示U中的恶意代码集合,则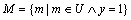 。N表示U中的正常代码集合,则
。N表示U中的正常代码集合,则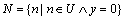 。设V表示待检测的未知恶意代码集合,对
。设V表示待检测的未知恶意代码集合,对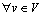 ,v满足
,v满足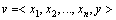 ,其中y=2表示v未分类。
,其中y=2表示v未分类。
v表示抗原,特征x1, x2, …, xn将融合成危险信号和安全信号。融合方法如下:
1) 将特征集合S分成3个子集,即危险特征集合DS、安全特征集合SS和普通特征集合PS,其中

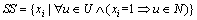
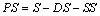
2) 设nmi和nbi分别为集合M和N中特征xi=1的元素个数。下面计算每个特征形成的信号分量的权重。
a. 当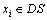 时,
时,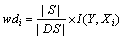 ,
,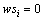 。
。
b. 当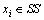 时,
时,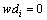 ,
,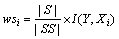 。
。
c. 当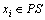 时,
时, 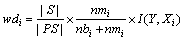 ,
,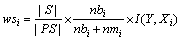 。
。
3) 计算融合后的危险信号vd和安全信号vs。对,设vi为特征xi的值,其计算公式分别为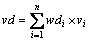 ,
,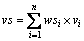 。
。
2.3 检测算法
由于经典DCA存在大量的随机参数,导致难以对算法进行分析,因此本系统采用确定性树突状细胞算法[17]。dDCA的输入信号简化为2类,即安全信号vd和危险信号vs,DC群体的生命周期值均匀分布,每个DC暴露在相同的输入信号中,以相同的方式处理信号,并对处理过程进行了优化。DC输出减少为2个,即CSM和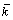 。dDCA信号处理公式如下:
。dDCA信号处理公式如下:
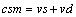 (2)
(2)
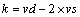 (3)
(3)
其中:csm为CSM信号的中间值,累加得到CSM;k为的中间值,累加得到。为负值时表示安全环境,为正值时表示危险环境。dDCA算法的伪代码如图3所示。

图3 dDCA算法伪代码
Fig. 3 Pseudocode of the deterministic DCA
dDCA的异常指标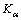 则用下式表示:
则用下式表示:
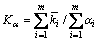 (4)
(4)
其中: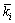 为第i个DC的,
为第i个DC的,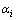 为第i个DC提呈的
为第i个DC提呈的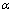 类抗原的数量,m为DC的数量。
类抗原的数量,m为DC的数量。
dDCA的异常阈值TK的计算公式如下。
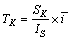 (5)
(5)
 (6)
(6)
其中:SK为所有输入信号的加权和;IS为信号实例对的数量;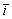 为每个细胞的平均循环数。
为每个细胞的平均循环数。
比较与TK:如果>TK,该类抗原归为异常;如果<TK,该类抗原归类为正常。
2.4 算法分析
dDCA作为对自然树突状细胞工作原理的模拟,具有众多的优点。首先,dDCA的训练阶段仅需要对训练数据集进行数据预处理,如分析各种特征的权重,并将各种特征融合成安全信号和危险信号,因此其训练时间非常短。其次,dDCA的复杂度比较低,效率较高。从图3中dDCA算法伪代码分析可知,其时间复杂度为O(N2)。再次,dDCA具有突出的特征数据融合的能力,尤其擅长将各种时间相关信号融合成安全信号和危险信号。这也是在基于多维特征的恶意代码检测过程中采用dDCA作为的检测算法的重要依据。最后,dDCA对一定范围内的系统参数变化(如特征数据融合时权重的变化、抗原存储空间的变化等)的敏感度不高,这表明dDCA具有较强的鲁棒性。
同时,dDCA也存在一些限制和不利因素。例如,当算法输入数据的排列顺序严重随机化时,将导致dDCA产生较差的分类结果。此外,dDCA对数据集中抗原和信号的数量比较敏感。当抗原和信号数量较少时,dDCA分类效果将变差。
3 实验及分析
3.1 实验数据及特征分析
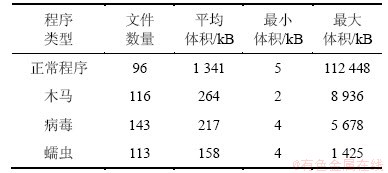
实验平台选取为Pentium E5200,2.5 GHz处理器,2 G内存,Windows XP SP3操作系统。收集的实验样本分为正常代码和恶意代码2个部分,其中正常代码共96个,收集于Windows XP Professional平台(如winword,notepad,visio,winrar等用户常用的合法程序),恶意代码共372个,均来源于VirusShare (http://virusshare.com),其中木马116个、病毒143个、蠕虫113个。所有程序均为Win32 PE格式。表1给出了数据集的基本统计信息。
表1 数据集基本信息统计
Table 1 Basic information statistic of dataset
在一台新安装的Windows XP SP3的VMware虚拟机中,运行实验样本,并使用API Monitor方法记录其API调用序列。每次执行完正常代码或恶意代码后,将使用VMware虚拟机中的快照功能将Windows XP SP3还原到新安装的状态。采用4-gram算法从API调用序列中提取特征,并选取信息增益值最大的前500个API调用序列特征。将这500个特征分成危险特征集合DS、安全特征集合SS和普通特征集合PS。图4给出3个子集合元素个数的统计特征。从图4可知:500个特征中不能直接标明程序身份的普通特征占大多数。这些特征通常是造成检测算法分类准确率降低的主要来源。然而通过文中提出的特征融合方法,可减少这些普通特征对安全信号或危险信号的影响,以增强dDCA检测算法的分类准确率。
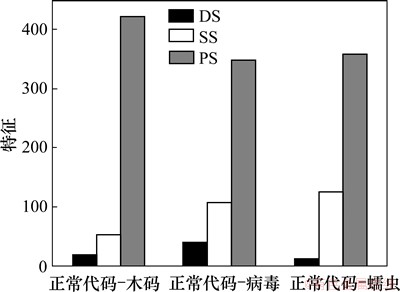
图4 元素个数特征统计
Fig. 4 Feature statistic of element number
3.2 各种检测方法的比较
通常分类器将产生4种可能的结果[18]:1) 真阳性(TP),被确认为异常的恶意代码数目;2) 假阳性(FP),被确认为异常的正常代码数目。3) 真阴性(TN),被确认为正常的正常代码数目。4) 假阴性(FN),被确认为正常的恶意代码数目。在本文中将采用检测率(TPR)、误检率(FPR)和分类准确率(Accuracy)评价检测算法。
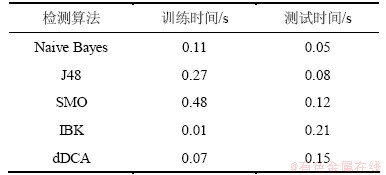
在WEKA平台[19]上实现dDCA算法,并与WEKA平台上的数据挖掘算法―朴素贝叶斯算法(Naive Bayes)、决策树算法(J48)、支持向量机算法(SMO)、基于实例的学习算法(IBK)进行比较。在10折交叉验证下,检测结果如表2所示。从表2可知:dDCA检测算法在3种测试集中的恶意代码检测率、误检率和分类准确率均优于其他4种检测算法。尤其在恶意代码检测率方面,达到100%。表3给出不同检测算法效率的比较,即比较样本的训练时间和测试时间。
3.3 分析与不足
分析实验中dDCA检测算法产生误报的样本是由于正常代码存在一些与恶意代码类似的敏感操作,导致其特征融合后的危险信号值大于安全信号值,从而被误报为恶意代码。这同样也是导致其余检测算法产生误报的原因。当改变dDCA检测算法的内部参数或测试数据集后,同样将产生漏报样本。而漏报样本产生的原因是因为恶意代码行为与正常代码样本间存在较多的相似性,导致其特征融合后的危险信号值小于安全信号值,从而被漏报为正常代码。此外,将漏报样本的安全信号值和危险信号值相加,发现绝大多数漏报样本信号值相加之和小于1。其原因在于提取的前500个API调用序列特征中,漏报样本仅存在少数几个特征,这意味着标识漏报样本的信息很少。通过对其余检测算法中漏报样本分析,同样可发现其漏报样本存在与dDCA中漏报样本一致的特征,即API调用序列特征很少。从表3可知:dDCA的训练时间比较短,仅次于IBK算法,这是因为dDCA在训练阶段仅需要对训练数据集进行数据预处理,消耗时间少,但这也导致其在测试阶段将消耗较长时间。
不足之处是dDCA检测算法对测试样本输入的顺序比较敏感,完全随机化的输入顺序将导致dDCA分类性能急剧下降,而且抗原和信号的数量对dDCA影响很大,较多的抗原和信号才能保证dDCA的分类效果。此外,dDCA检测算法的特长在于特征融合,然而在此次试验中仅考虑了API调用序列特征的融合,因此需要跟进一步提取其他类型特征进行融合,以增强dDCA的分类效果。
表2 各种方法的检测结果
Table 2 Detection result of all kinds of method
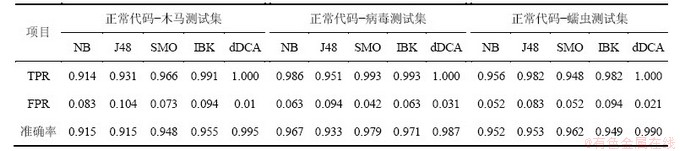
表3 不同检测算法效率比较
Table 3 Efficiency comparison of different detection algorithms
4 结论
1) 提出了一种基于危险理论的恶意代码特征提取、融合及检测的方法。该方法可将多种不同性质的恶意代码特征进行融合,以给出代码恶意性的准确判定。
2) 下一步的工作将研究恶意代码特征的增减以及信息冗余特征对本文检测方法的影响。
参考文献:
[1] Manuel E, Theodoor S, Engin K, et al. A Survey on automated dynamic malware-analysis techniques and tools[J]. ACM Computing Surveys, 2012, 4(2): 1-49.
[2] Ilsun Y, Kangbin Y. Malware obfuscation techniques: A brief survey[C]// Proceedings of the 2010 International Conference on Broadband, Wireless Computing, Communication and Applications. Washington, DC, USA: IEEE, 2010: 297-300.
[3] Jacob G, Debar H, Fillol E. Behavioral detection of Malware: From a survey towards all established taxonomy[J]. Computer Virology, 2008, 4(3): 251-266.
[4] Engin K, Christopher K. Behavior-based spyware detection[C]// Proceedings of the 15th conference on USENIX Security Symposium. Berkeley, CA, USA: USENIX Association, 2006: 1-16.
[5] Mihai C, Somesh J, Christopher K. Mining specifications of malicious behavior[C]// Proceedings of the 6th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on The Foundations of Software Engineering. New York, USA: ACM, 2007: 5-14.
[6] Mila P, Mihai C, Somesh J, et al. A semantics-based approach to Malware detection[C]// Proceedings of the 34th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages. New York, USA: ACM, 2007: 377-388.
[7] Faraz A, Haider H, M. Zubair S, et al. Using spatio-temporal information in API calls with machine learning algorithms for Malware detection[C]// Proceedings of the 2nd ACM Workshop on Security and Artificial Intelligence. NY, USA: ACM, 2009: 55-62.
[8] 孔德光, 谭小彬, 奚宏生, 等. 提升多维特征检测迷惑恶意代码[J]. 软件学报, 2011, 22(3): 522-533.
KONG Deguang, TAN Xiaobin, XI Hongsheng, et al. Obfuscated Malware detection based on boosting multilevel features[J]. Journal of Software, 2011, 22(3): 522-533.
[9] 刘巍伟, 石勇, 郭煜, 等. 一种基于综合行为特征的恶意代码识别方法[J]. 电子学报, 2009, 37(4): 696-700.
LIU Weiwei, SHI Yong, GUO Yu, et al. A malicious code detection method based on integrated behavior characterization[J]. Acta Electronica Sinica, 2009, 37(4): 696-700.
[10] Matzinger P. Tolerance, danger and the extended family[J]. Annual Review on Immunology, 1994, 12(4): 991-1045.
[11] Julie G. The dendritic cell algorithm[D]. Nottingham, UK: the University of Nottingham, 2007: 90-100.
[12] Jean-Marie B, Eric F, Ludovic M. Are current antivirus programs able to detect complex metamorphic malware? An empirical evaluation[C]// Proceedings of the 18th EICAR Annual Conference. France, 2009: 1-19.
[13] SUN Hungmin, LIN Yuehsun Lin, WU Mingfung. API monitoring system for defeating worms and exploits in MS-windows system[C]// Proceedings of the 11th Australasian Conference on Information Security and Privacy. Berlin: Springer, 2006: 159-170.
[14] Tony A, Nick C, Vlado K, et al. N-gram-based detection of new malicious code[C]// Proceedings of the 28th Annual International Computer Software and Applications Conference. Washington, DC, USA: IEEE Computer Society, 2004: 41-42.
[15] Abdurrahman P, Mehmet E, Tankut A. Proposal of n-gram based algorithm for Malware classification[C]// Proceedings of The Fifth International Conference on Emerging Security Information, Systems and Technologies. 2011: 14-18.
[16] Jeremy K, Marcus A. Maloof. Learning to detect malicious executables in the wild[C]// Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data mining. New York, USA: ACM, 2004: 470-478.
[17] Julie G, Uwe A. The deterministic dendritic cell algorithm[C]// Proceedings of the 7th International Conference on Artificial Immune Systems. Berlin, Germany: Springer, 2008: 291-302.
[18] Salman M, Faraz A, Haider H. A sense of ‘danger’ for windows processes[C]// Proceedings of the 8th International Conference on Artificial Immune Systems. Berlin, Germany: Springer, 2009: 220-233.
[19] Weka. Weka wiki[EB/OL]. [2013-03-21]. http://www.cs. waikato.ac.nz/ml/weka/.
(编辑 陈爱华)
收稿日期:2013-11-03;修回日期:2014-02-22
基金项目:国家自然科学基金资助项目(61172083)
通信作者:黄聪会(1985-),男,湖南衡阳人,博士,从事虚拟化技术与网络安全研究;电话:13720724314;E-mail: huangdoubleten@126.com

