Self-adaptive learning based immune algorithm
��Դ�ڿ������ϴ�ѧѧ��(Ӣ�İ�)2012���4��
�������ߣ����� ׯ�� Ѧ�� ����
����ҳ�룺1021 - 1031
Key words��immune algorithm; multi-modal optimization; evolutionary computation; immune secondary response; self-adaptive learning
Abstract:
A self-adaptive learning based immune algorithm (SALIA) is proposed to tackle diverse optimization problems, such as complex multi-modal and ill-conditioned problems with the high robustness. The SALIA algorithm adopted a mutation strategy pool which consists of four effective mutation strategies to generate new antibodies. A self-adaptive learning framework is implemented to select the mutation strategies by learning from their previous performances in generating promising solutions. Twenty-six state-of-the-art optimization problems with different characteristics, such as uni-modality, multi-modality, rotation, ill-condition, mis-scale and noise, are used to verify the validity of SALIA. Experimental results show that the novel algorithm SALIA achieves a higher universality and robustness than clonal selection algorithms (CLONALG), and the mean error index of each test function in SALIA decreases by a factor of at least 1.0��107 in average.
J. Cent. South Univ. (2012) 19: 1021-1031
DOI: 10.1007/s11771-012-1105-3![]()
XU Bin(����)1, ZHUANG Yi(ׯ��)1, XUE Yu(Ѧ��)1, WANG Zhou(����)2
1. Department of Computer Engineering & Science, Nanjing University of Aeronautics & Astronautics,Nanjing 210016, China;
2. Science and Technology on Electron-optic Control Laboratory, Luoyang 471000, China
? Central South University Press and Springer-Verlag Berlin Heidelberg 2012
Abstract: A self-adaptive learning based immune algorithm (SALIA) is proposed to tackle diverse optimization problems, such as complex multi-modal and ill-conditioned problems with the high robustness. The SALIA algorithm adopted a mutation strategy pool which consists of four effective mutation strategies to generate new antibodies. A self-adaptive learning framework is implemented to select the mutation strategies by learning from their previous performances in generating promising solutions. Twenty-six state-of-the-art optimization problems with different characteristics, such as uni-modality, multi-modality, rotation, ill-condition, mis-scale and noise, are used to verify the validity of SALIA. Experimental results show that the novel algorithm SALIA achieves a higher universality and robustness than clonal selection algorithms (CLONALG), and the mean error index of each test function in SALIA decreases by a factor of at least 1.0��107 in average.
Key words: immune algorithm; multi-modal optimization; evolutionary computation; immune secondary response; self-adaptive learning
1 Introduction
The fundamental of artificial immune system (AIS) is inspired by some aspects of the theoretical immune system and the observed immune functions, principles, and models. The main purpose of modeling the natural immune system is to have better understandings of immune functions and then to solve practical problems in engineering, science, computing, and other research areas. Some early works in applying immune system paradigms were undertaken in the area of fault diagnosis [1]. Later work applied immune system paradigms to the field of computer security [2], anomaly detection [3], pattern recognition [4] and optimization [5-11].
As one of the most important applications of AIS, numerical optimization has attracted wide interests of researchers. Recently, amounts of immune based algorithms (IBAs) were proposed to deal with optimization problems. For examples, the clonal selection algorithm (CLONALG) takes advantages of clone operator to increase local search ability [5]; the artificial immune network called opt-aiNet determines whether the individual will preserve not depending on the interaction established by immune network [6]; the B-cell algorithm (BCA) which is the first immune algorithm theoretically proved to be convergent with probability according to Marcov chain model [7-8]; the opt-IA used three immune operators, cloning, hypermutation, and aging for multi-modal optimization problems [9]; the secondary response clonal programming algorithm (SRCPA) utilized the mechanism of immune secondary response to accelerate the searching speed [10].
Although many variants of IBA have been proposed, the effectiveness of the algorithm in tackling diverse problems especially complex multi-modal and ill- conditioned problems is still unsatisfied. Generally speaking, the success of IBA in solving one specific problem crucially depends on the choice of suitable immune strategies, foremost the selection of the mutation method. Since the natural immune mutation method is semi-blind to some extent [12], the introduction of other mutation mechanisms, such as Baldwin based learning mutation strategy, greatly improves the solution quality of the original immune algorithm when dealing with multi-modal problems. However, the convergence speed of these immune algorithms on uni-modal problems and relatively simple multi-modal problems is much lower than that of the other variants. On the other hand, the IBA variants with high convergence speed always suffer from premature in a few generations. Therefore, it is desirable to make a trade off between exploration and exploitation of searching space to cope with diverse problems with different characteristics.
Recently, some works were focused on applying multiple strategies or methods in one algorithm to obtain good performance on different kinds of problems. It has been testified that this scheme is very effective for a single algorithm to cope with diverse problems with different characteristics [13-14]. From this perspective, a new immune secondary response based mutation operator and three modified differential evolution (DE) mutation operators are firstly proposed compose to a mutation strategy pool to generate promising individuals. Then, a self-adaptive learning framework is used to probabilistically steer four mutation strategies with different features in parallel to optimize problems with different fitness landscapes. The purpose of using self-adaptive learning framework is to adaptively give preference to appropriate strategies on different problems and at different stages of the optimization process according to the feedback of the quality of solutions generated by them. The fundamental idea of tuning the contribution of strategies proportionally to their previous performance is similar to those is Refs. [13-14]. Instead of directly assigning choice of strategies to population according to their effectiveness [13] or using execution probabilities to stochastically determine strategies according to their fitness scores [14], self-adaptive learning based immune algorithm (SALIA) combines these two schemes to gradually update the selection probabilities of strategies based on the direct effectiveness and fitness scores of the strategies. The main purpose of this framework is to self-adaptively select mutation strategies with specific control parameter settings at each generation for each antibody to create new promising antibodies. Twenty-six numerical optimization problems with different characteristics, such as uni-modality, multi-modality, rotation, ill-condition, mis-scale and noise, were tested to comprehensively evaluate the performance of SALIA. In addition, the performance of SALIA was compared with three IBA variants and four representative population based algorithms.
2 Proposed self-adaptive learning based immune algorithm
2.1 Four mutation strategies
1) Modified DE/rand/1 mutation strategy (Mr1)
DE/rand/1/bin is the prevailing mutation strategy employed in most DE variants. Since all vectors for mutation are randomly selected from the population in this strategy, it bears strong exploration capability when solving multi-modal problems [13].
A modified DE/rand/1 mutation strategy is proposed to enhance its dynamics and thus to be more suitable to the self-adaptive learning framework. Different from DE/rand/1/bin, Mr1 strategy discards the crossover rate by a scheme that at least one dimension of original vector is randomly selected for crossover. Besides, the scaling factor F is not a constant but a random number generated from normal distribution with mean of 0.5 and variance of 0.2. In the Mr1 strategy, the following mutation equations are used:
F=N(0.5, 0.2) (1)
![]() (2)
(2)
 (3)
(3)
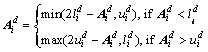 (4)
(4)
where N(0.5, 0.2) means a random number generated from normal distribution with mean of 0.5 and variance of 0.2; ![]()
![]() and
and ![]() are three antibodies selected randomly from current population;
are three antibodies selected randomly from current population; ![]() is the generated antibody by Eq. (2);
is the generated antibody by Eq. (2); ![]() denotes the d-th variable of i-th antibody; R(D) is a function which generates a subset of {1, 2, ��, D}, with at least one element;
denotes the d-th variable of i-th antibody; R(D) is a function which generates a subset of {1, 2, ��, D}, with at least one element; ![]() and
and ![]() are the lower bound and upper bound of the d-th variable of the i-th antibody, respectively. Instead of using binomial crossover determined by the crossover rate, Eq. (3) is used to generate the new antibody with a random binomial crossover. Equation (4) prevents this antibody vector moving out of the search bound.
are the lower bound and upper bound of the d-th variable of the i-th antibody, respectively. Instead of using binomial crossover determined by the crossover rate, Eq. (3) is used to generate the new antibody with a random binomial crossover. Equation (4) prevents this antibody vector moving out of the search bound.
2) Modified DE/rand/2 mutation strategy (Mr2)
Many works [15-16] demonstrated that the DE/ rand/2/bin strategy has better exploration capability than one-difference-vector-based strategies, such as the DE/rand/1/bin strategy. In DE/rand/2/bin, two difference vectors are added to base vector to perform the Gaussian-like perturbation, which may result in a better perturbation. The updating equation of modified DE/ rand/2 mutation strategy is defined as
![]() (5)
(5)
where ![]()
![]()
![]()
![]() and
and ![]() are the antibodies selected randomly in current population; rand(j) denotes a random number uniformly distributed between 0 and 1, and the scaling factor F is computed using Eq. (1). It is observed from Eq. (5) that the searching ability is extended by varying the scaling factor of first difference vector from zero to one. After the generation of new antibody by Eq. (5), Eqs. (3) and (4) are used to perform crossover operation and validation, respectively.
are the antibodies selected randomly in current population; rand(j) denotes a random number uniformly distributed between 0 and 1, and the scaling factor F is computed using Eq. (1). It is observed from Eq. (5) that the searching ability is extended by varying the scaling factor of first difference vector from zero to one. After the generation of new antibody by Eq. (5), Eqs. (3) and (4) are used to perform crossover operation and validation, respectively.
3) Modified DE/current-to-rand/1 mutation strategy (Mcr1)
It has been testified in Ref. [13] that the strategy DE/current-to-rand/1 without crossover is effective for rotated problems. In order to improve the performance of IBA on rotated problems, an updating equation of modified DE/current-to-rand/1 mutation strategy is defined as
F=U(0.6, 1) (6)
![]() (7)
(7)
where ![]()
![]()
![]() and
and ![]() are the antibodies selected randomly from current population; rand(j) denotes a random number uniformly distributed between zero and one, and the scaling factor F is computed by Eq. (6), in which U(0.6, 1) means a uniformly distributed random number between 0.6 and 1. It is considered that the large value of F can increase the population diversity while the small one makes the search focus on neighborhoods of the current solutions. From Eq. (7), it can be observed that the first and the second difference scaling factors F are randomly sampled from a uniform distribution, represented by rand(j) and U(0.6,1), respectively. Therefore, Mcr1 strategy is suitable for self-adaptive learning framework of SALIA because the search ability of this strategy is enhanced while the population diversity is also maintained, that is, the feature of preventing premature of Mcr1 gives the chance of SALIA to gradually learn to adopt to the optimal mutation strategy for each antibody during the process of algorithm. After the generation of new antibody by Eq. (7), Eq. (4) is used to perform validation checking.
are the antibodies selected randomly from current population; rand(j) denotes a random number uniformly distributed between zero and one, and the scaling factor F is computed by Eq. (6), in which U(0.6, 1) means a uniformly distributed random number between 0.6 and 1. It is considered that the large value of F can increase the population diversity while the small one makes the search focus on neighborhoods of the current solutions. From Eq. (7), it can be observed that the first and the second difference scaling factors F are randomly sampled from a uniform distribution, represented by rand(j) and U(0.6,1), respectively. Therefore, Mcr1 strategy is suitable for self-adaptive learning framework of SALIA because the search ability of this strategy is enhanced while the population diversity is also maintained, that is, the feature of preventing premature of Mcr1 gives the chance of SALIA to gradually learn to adopt to the optimal mutation strategy for each antibody during the process of algorithm. After the generation of new antibody by Eq. (7), Eq. (4) is used to perform validation checking.
4) Immune secondary response based mutation strategy (ISR)
As pointed out in Ref. [10], human bodies will response rapidly when infected by an antigen similar as the one recognized before, which is called the immune secondary response. In the process of immune secondary response, the gene of the antibody that best matches the antigen is reused to generate a gene structure to match the new coming antigen similar as the one recognized before.
Motivated by the human immune secondary response, an immune secondary response based mutation strategy is proposed for accelerating the convergence speed and extending the potential search range of SALIA. The main idea of ISR is using the beneficial information of the genes of antibodies in current population to recombine a gene structure towards the optimal solution regions. In ISR, the mutation strategy equation is defined as
c=U(0, 2) (8)
![]() (9)
(9)
where ![]() denotes the d-th variable of i-th antibody;
denotes the d-th variable of i-th antibody; ![]() is the d-th variable of an antibody randomly selected from the current population; c is the learning strength which is sampled from a uniform distribution U(0, 2) by Eq. (8). Since the mutated clone with better fitness value than that of the original antibody of the clone will participate in the evolving of next generation, the historical beneficial information of genes and gene structures of antibodies is maintained during the process of immune response. It is implied from Eq. (9) that the beneficial information is recombined randomly to make a wild search in the promising search region. In addition, the magnitude of learning of the beneficial information is controlled by Eq. (8) to balance the exploration and exploitation of SALIA to some extent. After the generation of new antibody by Eq. (9), Eq. (4) is used to perform validation checking.
is the d-th variable of an antibody randomly selected from the current population; c is the learning strength which is sampled from a uniform distribution U(0, 2) by Eq. (8). Since the mutated clone with better fitness value than that of the original antibody of the clone will participate in the evolving of next generation, the historical beneficial information of genes and gene structures of antibodies is maintained during the process of immune response. It is implied from Eq. (9) that the beneficial information is recombined randomly to make a wild search in the promising search region. In addition, the magnitude of learning of the beneficial information is controlled by Eq. (8) to balance the exploration and exploitation of SALIA to some extent. After the generation of new antibody by Eq. (9), Eq. (4) is used to perform validation checking.
The four strategies detailed above compose the mutation strategy pool where the mutation strategy will be selected adaptively by self-adaptive learning framework during the whole process of the algorithm.
2.2 Self-adaptive learning based immune algorithm
The self-adaptive learning framework of SALIA is proposed to improve the universality and robustness on diverse problems with specific characteristics. The main idea is to adaptively select the suitable mutation strategy from the mutation strategy pool at different stages of optimization process for different problems.
In essence, the hybridizing of multiple strategies in one algorithm implies that different kinds of philosophies of different species and/or agents could be combined to observe one thing sophisticatedly. Thus, one of the most important factors which determine the performance of that design on complex problems is the selection scheme of the strategies at the different stages of algorithm when dealing with the problem. As a promising research direction, self-adaptively learning scheme has been testified to be effective on different kinds of optimization problems [13-14]. In SALIA, the fundamental idea of tuning the contribution of strategies proportionally to their previous performance is similar to that of Refs. [13-14]. Instead of directly assigning choice of strategies to the population according to their effectiveness [13] or using execution probabilities to stochastically determine strategies according to their fitness scores [14], SALIA combines these two schemes to gradually update the selection probabilities of strategies based on the direct effectiveness to individual with strategy and the corresponding fitness value of that individual after executing that strategy in whole population.
In SALIA, the i-th antibody has a selection probability vector si, si=[si1, si2, ��, siM], where sij, j=1, 2, ��, M, denotes the probability that the j-th strategy in all M (M equals four in our experiment) strategies in the mutation strategy pool adopted by the i-th antibody clone. In addition to selection probability vector, it also assigned a flag vector fi, fi=[fi1, fi2, ��, fiM], where fij, j=1, 2, ��, M, equals one if the j-th strategy is selected to execute on the i-th antibody; otherwise, it equals 0. Initially, we assign equal probabilities for all strategies, sij=0.25, and set fij=0, for i=1, 2, ��, N; i=1, 2, ��, M.
At each generation, the temporary selection probability accumulator of the i-th antibody with the j-th strategy, tij, is computed as
![]() (10)
(10)
 (11)
(11)
where mi is the improving flag, that is, mi=1, if the fitness value of the mutated antibody is better than that of the original one; otherwise, mi=0.1. Parameter wi denotes
weight value of fitness sorting, i.e.,  for
for
the si-th best antibody, where si is the sequence number of the i-th antibody based on sorting fitness values of all antibodies in whole population, i=1, 2, ��, N. It can be observed from Eqs. (10) and (11) that tij is updated not only by direct effectiveness to individual with strategy and but also the corresponding fitness value of that individual after executing that strategy. Besides, tij is initiated by tij=0.25.
During a fixed learning period (LP), each antibody evolves according to si, and the si is updated by
![]() (12)
(12)
where mi, wi and fij have the same meanings as those above. The value of LP depends on the applied area. The smaller the value of LP, the faster the learning frequency, and vice versa.
Finally, after a fixed learning period LP, the following equation is used to update the selection probability of the j-th mutation strategy of the i-th antibody.
![]() (13)
(13)
where tij and sij have the same meanings as those above.
Parameter sij is then normalized by ![]()
Equation (13) shows that the learning of selection probability is based on the whole population, which implies the ability of learning in SALIA is enhanced to accelerate the learning speed. At last, tij is assigned by tij=sij. The details of SALIA are listed in Algorithm 1.
Step 1: Algorithm initialization
Randomly initialize an antibody population A=(A1, A2, ��, AN) of size N (number of function evaluation NFE); Set each sij to be 0.25, j=1, 2, 3, 4, tij=sij, and set generation k=0 and the learning period as Lp.
Step 2: Immune cloning and mutation
As for each Ai of A , select the j-th mutation strategy from mutation strategy pool by roulette wheel selection based on si for the each clone of Ai to create a new mutated antibody ![]() Secondly, Evaluate the fitness value of
Secondly, Evaluate the fitness value of ![]() and update the value of NFE. At last, set fij=1, if
and update the value of NFE. At last, set fij=1, if ![]() is better than Ai or
is better than Ai or ![]() is the mutated antibody of the last clone of Ai.
is the mutated antibody of the last clone of Ai.
Step 3: Immune selection
As for each ![]() if
if ![]() is better than Ai, then replace Ai with
is better than Ai, then replace Ai with ![]() otherwise set improving flag mi=0.1. At last, sort the fitness value in descending order to get si of each Ai.
otherwise set improving flag mi=0.1. At last, sort the fitness value in descending order to get si of each Ai.
Step 4: Self-adaptive learning
Using Eqs. (10) and (11), update each tij; using Eq. (12), update sij. If the learning generations satisfy the Lp, then update each sij using Eq. (13), normalize sij, and set each tij by tij=sij.
Step 5: End
If a certain criterion is satisfied, otherwise set k=k+1 and go to Step 2.
3 Experimental study
As discussed in Refs. [13, 17], two major problems of the classical test functions, i.e., the global optimum lies at the center of the search space, the distribution of local optima is regular, and the variables are separable and limit the practical significance of using these functions. In order to make up the above demerits and better approximate real-world problem behavior, the classical test functions are shifted and rotated with a certain scale [13-14]. The global optima of all functions are shifted to different numerical values for different dimensions (z=x-o), where o is the location of the new global optimum. Besides, the classical test functions are rotated by z=M(x-o), where M is an orthogonal rotation matrix, to avoid local optima lying along the coordinate axes while retaining the properties of the test functions. A detailed description of these test optimization problems can be found in Ref. [14]. These 26 optimization problems are divided into four groups:
Group 1: Classical test functions that are non-linear, separable, scalable (z=x-o), Fun1-Fun11;
Group 2: Test functions that are mis-scaled (z=x-o), Fun12-Fun14;
Group 3: Test function with noise (z=x-o), Fun15;
Group 4: Rotated test functions that are non-linear, non-separable, scalable (z=M(x-o)), Fun16-Fun26.
The dimension size of all test functions was set to be 30 for all the 26 test functions. For each algorithm and each test function, 24 independent runs were conducted with 300 000 function evaluations (NFE) as the termination criterion. In SALIA, the population size N and the learning period LP were set to be 50 and 30, respectively; the clone size of the antibody with the highest fitness value in the population of each generation was set to be 5 while that of the others was set to be 1.
In the experimental studies, the average and standard deviation of the function error value (E=f(x)- f(x*)) as well as the success rates were recorded for measuring the performance of each algorithm, where x is the best solution found by the algorithm in a run and x* is the global optimum of the test function. The success of an algorithm means that this algorithm can result in a function value not worse than the prespeci?ed optimal value, i.e., (f(x*)+10-5), for all problems with the number of FEs less than the pre-speci?ed maximum number, i.e., 300 000. The success rate is calculated as the number of successful runs divided by the total number of runs. Moreover, when all 24 runs are successful, the average number of function evaluations (NFE) required to find the global optima are also recorded. The SALIA algorithm was compared with three IBAs and four representative population based algorithms. In order to have statistically sound conclusions, Wilcoxon��s rank sum test at a significance level of 0.05 was conducted on the experimental results.
3.1 Comparison between SALIA and three IBAs
SALIA was compared with three other representative IBAs, CLONALG [5], opt-IA [9], and BCSA [12]. The parameter settings of these algorithms are listed in Table 1.
The maximum number of function evaluations (Fes) in all these methods was set to be 300 000, as a stop criterion. The experimental results are given in Table 2. The last three rows of Table 2 summarize the experimental results.
The success rate was zero of CLONALG, opt-IA and BCSA on all test functions except that CLONALG had at least one success run on Funs 1 and 11, and BCSA on Funs 1, 10, 11, 16 and 19. Thus, it is unnecessary to list the detailed information about SR and NFE of these three algorithms. However, the corresponding results of SALIA were significantly better than CLONALG, opt-IA and BCSA, as listed in Table 3.
Figure 1 depicts the convergence characteristics in terms of the best error value of the median run of each algorithm, where label Y is the logarithm of error value, E=f(x)-f(x*).
Table 3 represents that the SALIA performs best on all test functions except for Funs 7, 21 and 23, which means that the multiple mutation strategies of SALIA are more suitable for most of the test problems than CLONALG, opt-IA and BCSA. In addition, it should be noted that only SALIA approaches the true global optima on Funs 1, 8, 10 and 11 with 100% success rate, as given in Table 4.
1) Experimental results on Group 1
For uni-modal Funs 1-5, SALIA performs best on these test functions. Algorithms CLONALG, opt-IA and BCSA have great difficulty in obtaining the global optima on all problems except Fun 1, which is easily optimized by CLONALG, BCSA and SALIA with at least one successful run.
For the separate multi-modal Funs 6�C11, where the number of local minima increases exponentially as the dimension of the function increases, the performance of CLONALG is better than others on Fun 7 in terms of the solution quality, and this may be due to the exploration ability of continuously random mutation. For the remaining test functions, CLONALG, opt-IA and BCSA totally fail in finding the global optima, while SALIA reaches the true global optima on three functions out of six functions.
2) Experimental results on Groups 2 and 3
Three mis-scaled test problems are generalized from Rastrigin and Rosenbrock functions, which are considered as two typical hard tasks, to extend the difficulty of the optimization problems. As pointed out in Ref. [14], the mis-scaling between the longest and shortest axis is 10 for Rastrigin10 and 100 for Rastrigin100 and Rosenbrock100. For the 30 dimensional problems, the factor between ��adjacent�� axes are 1.08 and 1.17, respectively. Function 15 is the only function in Group 3, which is the generalized form Fun 2 (Schwefel 1.2). It is difficult to accurately locate the global optimum on Fun 5 because of its systematical Gaussian noise.
For Funs 12-15, SALIA yields the best results than others in terms of solution quality, success rate and the convergence speed. It is implied that the robustness of SALIA is remarkably better than three other IBAs.
Table 1 Parameter settings of CLONALG, opt-IA and BCSA

Table 2 Optimization results of CLONALG, opt-IA, BCSA and SALIA on 26 test functions of 30 variables

3) Experimental results on Group 4
Group 4 is designed to test the capability of handling non-separability and ill-condition. In Group 4, three mis-scaled Funs 17-19, which are convex- quadratic and can be transformed into the Sphere problem, have the axes scaling of 1 000, 20 and 10. Functions 20 and 21 are two more typical uni-modal test problems. Functions 22-24 are derived from the original Ackley, Griewank and Rastrigin functions. The last two functions are rotated noisy functions with systematical or white noise.
It can be seen from Table 2 that SALIA provides the best results for almost all problems except Fun 21. For Fun 21, CLONALG performs slightly better than other algorithms in terms of solution quality, followed by SALIA. The reason for this behavior is likely that SALIA is capable of selecting most appropriate mutation strategy at different stages for different problems. That is to say, the self-adaptive learning mechanism of SALIA makes it possible to use stratgies Mr1, Mr2, Mcr1 and ISR to cooperatively handle the complex fitness landscapes of hard tasks.
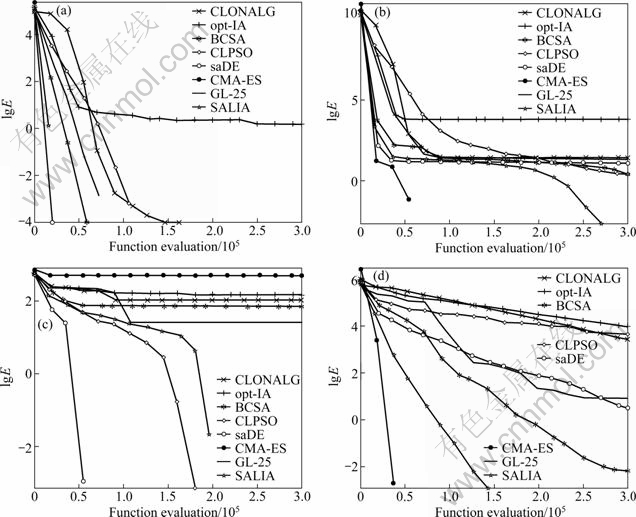
Fig. 1 Median convergence characteristics of CLONALG, opt-IA, BCSA, CLPSO, saDE, CMA-ES, GL-25 and SALIA on Fun1 (a), Fun 5 (b), Fun 8 (c) and Fun 17 (d)
In summary, SALIA is the best among the four IBAs on 24 functions out of 26 test functions. According to the results of the last three rows in Table 2 and the convergence maps in Fig. 1, it is concluded that SALIA shows an remarkably better solution quality and convergence speed than CLONALG, opt-IA and BCSA.
3.2 Comparison between SALIA and four representative population based algorithms
Algorithm SALIA was compared with four representative population based algorithms, i.e., CLPSO [18], saDE [13], CMA-ES [19] and GL-25 [20]. Algorithm CLPSO is a particle swarm optimization (PSO) variant, in which two strategies were employed alternatively to perform a particle��s behavior; saDE is a DE variant, which used a self-adaptive framework to adaptively adjust its trial vector generation strategies and control parameters simultaneously based on their previous performance; CMA-ES is a variant of evolution strategy (ES), in which two concepts, namely derandomization and cumulation, were put forward for self adaptation of the mutation distribution; GL-25 is a variant of genetic algorithm (GA), which hybridizes three processes before crossover operating to enhance the global and local search.
In our experiments, the same parameter settings were used for these four methods as their original work. The maximum number of FEs in all these methods was set to be 300 000, as the same in SALIA. Tables 3 and 4 summarize the experimental results. All the results are obtained from 24 independent runs.
1) Experimental results on Group 1
As shown in Tables 3 and 4, SALIA yields the best results on 7 functions out of 11 functions of Group 1 among the five algorithms. Especially, it should be noted that only SALIA approaches to the true global optimum on Funs 8, 10 and 11 with 100% success rate. Therefore, it is evident that SALIA shows the best universality on these problems. It can be observed that on Funs 2-4, SALIA is worse than CMA-ES or saDE. This is because the strategies employed by CMA-ES and saDE make a greedy search based on the best information of the population, such as DE/rand-to-best/2/bin strategy in saDE. However, SALIA performs significantly better on Fun 5 (a well-known hard test problem named Rosenbrock function) than others with the highest success rate and lowest error value.
Table 3 Optimization results of CLPSO, saDE, CMA-ES, GL-25 and SALIA on 26 test functions of 30 variables

2) Experimental results on Groups 2 and 3
For functions 12-15 in Groups 2 and 3, it is shown that CLPSO outperforms other algorithms on Fun 13. Except this function, the performance of SALIA is the best. In addition, it is worth noting that only SALIA can locate the true global optima on Fun 14 in every run.
3) Experimental results on Group 4
For Funs 16-26 in Group 4, SALIA and CMA-ES perform much better than CLPSO, saDE and GL-25 on most problems. The detail in Tables 4 and 5 indicates that CMA-ES finds the best results on Funs 17-19 and 21 with a fast convergence speed, followed by SALIA. For Funs 23 and 26, SALIA performs second better than CLPSO and GL-25 in solution quality, respectively.
Table 4 Optimization results of CLPSO, saDE, CMA-ES, GL-25 and SALIA on 26 test functions of 30 variables

In summary, it is concluded from the last three rows in Table 4 that the overall performance of SALIA is better than CLPSO, saDE, CMA-ES and GL-25. Furthermore, the convergence maps of SALIA, CLPSO, saDE, CMA-ES and GL-25 in Fig. 1 illustrate that SALIA converge second or third faster among all algorithms on Funs 1, 5, 8, 17. In fact, the convergence speed of SALIA is the fastest of all algorithms on Funs 6, 12, 15, 22 and 25, while the second on most of the remaining problems. This may be because SALIA gradually improves the performance by a period time of learning. That is, SALIA could balance exploration and exploitation on these test functions by combining different mutation strategies in a self-adaptive learning framework to some extent.
According to the ��no free lunch�� theorem [21], ��any elevated performance over one class of problems is offset by performance over another of the no-free lunch (NFL) theorem class��, there is a cost for tuning the SALIA to obtain better performance, and the cost has the slightly slow convergence on some of the problems.
3.3 Analysis of self-adaptive learning mechanism
Figure 2 depicts the selection probabilities of all four mutation strategies on four typical problems from 24 independent runs whose statistical results have been listed in Table 5. It is observed that the selection probability of Mr1 and Mcr1 is slightly higher than Mr2 and ISR for these four test problems, which means that the Mr1 and Mcr1 are more suitable than Mr2 and ISR for the four typical problems. For Fun 8, in the multi- modal Shifted Rastrigin problem, the probability of Mr1 is always higher than that of Mcr1, Mr2 and ISR. The similar behavior is also observed on the Fun 1, the uni-modal Shifted Sphere problem, which indicates that Mr1 is capable of dealing with not only uni-modal problems but also multi-modal problems. The two peaks in Figs. 2(a) and (c) are caused by the scenario when the solution located in the near optimal region is mutated towards the global optimum by Mr1 with less broad search ability than other strategies. For Fun 5, Mr1 and Mcr1 alternatively occupy the more proportion than others, which implies that the combination of Mr1 and Mcr1 has a better performance on ill-conditioned problems. For Fun 17, Mcr1 plays a more important role than others during the whole optimization process, which is remarkably longer than that on Funcs 1 and 8. This means that Mcr1 has superior performance on ill- conditioned problems. Overall, the following conclusions can be observed from Fig. 2.

Fig. 2 Self-adaptive learning characteristics of probabilities of using different strategies on four typical functions: (a) Fun 1; (b) Fun 5; (c) Fun 8; (d) Fun 17
1) The selection of mutation strategies is different at different stages of SALIA when coping with different problems. In any phase of SALIA, the mutation strategy which fits the problem better will occupy the more proportion than others.
2) It is the cooperation of all four mutation strategies in self-adaptive learning framework improves the performance of SALIA on uni-modal problems, multi-modal problems and ill-conditioned problems, rather than the combination of mutation strategies with specific ability for corresponding kind of problems.
4 Conclusions
1) The self-adaptive learning based inmune algorithm is a new algorithm based on multiple experienced mutation strategies and self-adaptive learning mechanisms. The multiple experienced mutation strategies are composed of Modified DE/rand/1 mutation strategy, Modified DE/rand/2 mutation strategy, Modified DE/current-to-rand/1 mutation strategy and Immune secondary response based mutation strategy.
2) The self-adaptive learning based inmune algorithm is more effective than CLONALG, opt-IA and BCSA when dealing with the most of the 26 optimization problems, especially the large scaled complex multi-modal and ill-conditioned problems.
3) The self-adaptive learning based inmune algorithm is universal and robust. It outperforms on 76%-100% of all test problems compared to CLONALG, opt-IA, BCSA, CLPSO, saDE, CMA-ES and GL-25.
References
[1] ISHIDA Y. Fully distributed diagnosis by PDP learning algorithm: Towards immune network PDP model [C]// International Joint Conference on Neural Networks. San Diego, CA: IEEE, 1990: 777-782.
[2] FORREST S, PERELSON A, ALLEN L, CHERUKURI R. Self-nonself discrimination in a computer [C]// Proceedings of the IEEE Computer Society Symposium on Research in Security and Privacy. Oakland, CA, USA: IEEE, 1994: 202-212.
[3] AICKELIN U, BENTLEY P, CAYZER S, KIM J, MCLEOD J. Danger theory: The link between AIS and IDS? [C]// Proceedings of the 2nd International Conference on Artificial Immune Systems, Edinburgh, Scotland: Springer Verlag, 2003: 147-155.
[4] BERETA M, BURCZYNSKI T. Immune K-means and negative selection algorithms for data analysis [J]. Information Sciences, 2009, 179(10): 1407-1425.
[5] CASTRO L N D, ZUBEN F J V. Learning and optimization using the clonal selection principle [J]. IEEE Transactions on Evolutionary Computation, 2002, 6(3): 239-251.
[6] CASTRO L N D, TIMMIS J. An artificial immune network for multimodal function optimization [C]// Proceedings of 2002 World Congress on Computational Intelligence (WCCI'02). Piscataway, NJ, USA: IEEE, 2002: 699-704.
[7] KELSEY J, TIMMIS J. Immune inspired somatic contiguous hypermutation for function optimisation [C]// Proceedings of the genetic and evolutionary computation conference. Chicago, Illinois USA: Springer Verlag, 2003: 207-218.
[8] CLARK E, HONE A, TIMMIS J. A Markov chain model of the B-cell algorithm [C]// Proceedings of the 4th International Conference on Artificial Immune Systems. Banff, Canada: Springer Verlag, 2005: 318-330.
[9] CUTELLO V, NARZISI G, NICOSIA G, PAVONE M. An immunological algorithm for global numerical optimization [C]// Proceedings of the 7th International Conference on Evolution Artificielle (EA 2005). Lille, France: Springer Verlag, 2006: 284-295.
[10] GONG Mao-guo, JIAO Li-cheng, ZHANG Li-ning, DU Hai-feng. Immune secondary response and clonal selection inspired optimizers [J]. Progress in Natural Science, 2009, 19(2): 237-253.
[11] TAN Guan-zheng, ZHOU Dai-ming, JIANG Bin, DIOUBATE M I. Elitism-based immune genetic algorithm and its application to optimization of complex multi-modal functions [J]. Journal of Central South University of Technology, 2008, 15(6): 845-852.
[12] GONG Mao-guo, JIAO Li-cheng, ZHANG Li-ning. Baldwinian learning in clonal selection algorithm for optimization [J]. Information Sciences, 2010, 180(8): 1218-1236.
[13] QIN A K, HUANG V L, SUGANTHAN P N. Differential Evolution Algorithm With Strategy Adaptation for Global Numerical Optimization [J]. IEEE Transactions on Evolutionary Computation, 2009, 13(2): 398-417.
[14] WANG Yu, LI Bin, WEISE T, WANG Jian-yu, YUAN Bo, TIAN Qiong-jie. Self-adaptive learning based particle swarm optimization [J]. Information Sciences (Accepted).
[15] STORN R. On the usage of differential evolution for function optimization [C]// Proceedings of the Fuzzy Information Processing Society. Berkeley, CA, USA: IEEE, 1996: 519-523.
[16] ZHANG Wen-jun, XIE Xiao-feng. DEPSO: Hybrid particle swarm with differential evolution operator [C]// IEEE International Conference on Systems, Man and Cybernetic. Washington D C, United States: Institute of Electrical and Electronics Engineers Inc., 2003: 3816-3821.
[17] LIANG J J, SUGANTHAN P N, DEB K. Novel composition test functions for numerical global optimization [C]// Proceedings of the Swarm Intelligence Symposium. Pasadena, CA, USA: IEEE, 2005: 68-75.
[18] LIANG J J, QIN A K, SUGANTHAN P N, BASKAR S. Comprehensive learning particle swarm optimizer for global optimization of multimodal functions [J]. IEEE Transactions On Evolutionary Computation, 2006, 10(3): 281-295.
[19] HANSEN N, OSTERMEIER A. Completely derandomized self-adaptation in evolution strategies [J]. Evolutionary Computation, 2001, 9(2): 159-195.
[20] GARC?A-MART?NEZ C, LOZANO M, HERRERA F, MOLINA D, S?NCHEZ A M. Global and local real-coded genetic algorithms based on parent-centric crossover operators [J]. European Journal Of Operational Research, 2008, 185(3): 1088-1113.
[21] WOLPERT D H, MACREADY W G. No free lunch theorems for optimization [J]. IEEE Transactions on Evolutionary Computation, 1997, 1(1): 67-82.
(Edited by DENG L��-xiang)
Foundation item: Project(2010ZC13012) supported by the Aviation Science Funds of China
Received date: 2011-01-21; Accepted date: 2011-10-08
Corresponding author: XU Bin, PhD Candidate; Tel: +86-25-84893691; E-mail: zhuangyi@263.net

