Detection of artificial pornographic pictures based on multiple features and tree mode
��Դ�ڿ������ϴ�ѧѧ��(Ӣ�İ�)2018���7��
�������ߣ���� ë���� ����Ң ZOU Bei-ji(�ޱ���)
����ҳ�룺1651 - 1664
Key words��multiple feature; artificial pornographic pictures; picture detection; gradient boost decision tree
Abstract: It is easy for teenagers to view pornographic pictures on social networks. Many researchers have studied the detection of real pornographic pictures, but there are few studies on those that are artificial. In this work, we studied how to detect artificial pornographic pictures, especially when they are on social networks. The whole detection process can be divided into two stages: feature selection and picture detection. In the feature selection stage, seven types of features that favour picture detection were selected. In the picture detection stage, three steps were included. 1) In order to alleviate the imbalance in the number of artificial pornographic pictures and normal ones, the training dataset of artificial pornographic pictures was expanded. Therefore, the features which were extracted from the training dataset can also be expanded too. 2) In order to reduce the time of feature extraction, a fast method which extracted features based on the proportionally scaled picture rather than the original one was proposed. 3) Three tree models were compared and a gradient boost decision tree (GBDT) was selected for the final picture detection. Three sets of experimental results show that the proposed method can achieve better recognition precision and drastically reduce the time cost of the method.
Cite this article as: MAO Xing-liang, LI Fang-fang, LIU Xi-yao, ZOU Bei-ji. Detection of artificial pornographic pictures based on multiple features and tree mode [J]. Journal of Central South University, 2018, 25(7): 1651�C1664. DOI: https://doi.org/10.1007/s11771-018-3857-x.

J. Cent. South Univ. (2018) 25: 1651-1664
DOI: https://doi.org/10.1007/s11771-018-3857-x

MAO Xing-liang(ë����)1, LI Fang-fang(���)2, LIU Xi-yao(����Ң)2, ZOU Bei-ji(�ޱ���)2
1. Science and Technology on Information Systems Engineering Laboratory,National University of Defense Technology, Changsha 410073, China;
2. School of Information Science and Engineering, Central South University, Changsha 410083, China
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2018
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2018
Abstract: It is easy for teenagers to view pornographic pictures on social networks. Many researchers have studied the detection of real pornographic pictures, but there are few studies on those that are artificial. In this work, we studied how to detect artificial pornographic pictures, especially when they are on social networks. The whole detection process can be divided into two stages: feature selection and picture detection. In the feature selection stage, seven types of features that favour picture detection were selected. In the picture detection stage, three steps were included. 1) In order to alleviate the imbalance in the number of artificial pornographic pictures and normal ones, the training dataset of artificial pornographic pictures was expanded. Therefore, the features which were extracted from the training dataset can also be expanded too. 2) In order to reduce the time of feature extraction, a fast method which extracted features based on the proportionally scaled picture rather than the original one was proposed. 3) Three tree models were compared and a gradient boost decision tree (GBDT) was selected for the final picture detection. Three sets of experimental results show that the proposed method can achieve better recognition precision and drastically reduce the time cost of the method.
Key words: multiple feature; artificial pornographic pictures; picture detection; gradient boost decision tree
Cite this article as: MAO Xing-liang, LI Fang-fang, LIU Xi-yao, ZOU Bei-ji. Detection of artificial pornographic pictures based on multiple features and tree mode [J]. Journal of Central South University, 2018, 25(7): 1651�C1664. DOI: https://doi.org/10.1007/s11771-018-3857-x.
1 Introduction
The Internet has brought convenience to our lives, and it has also brought us some problems. For example, it is very easy for teenagers to view pornographic pictures on social networks. Therefore, the detection of these pictures is a problem for many parents and government organizations. Rapid detection of these pictures can effectively prevent them from spreading on the Internet. There are two main categories of pornographic pictures, real ones and artificial ones. Real pornographic pictures can be detected programmatically by a few picture- based search engines recently. However, artificial pornographic pictures are more difficult to be detected, and this type of pictures begins to appear in social networks more and more frequently. Firstly, features extracted from real pictures may not be suitable for artificial ones directly. Secondly, artificial pornographic pictures are often generated by simulating the characters in a game or in a comic, making it more difficult to define the boundaries of pornography and non-pornography.Large number of researches have been done in pornographic image recognition. In this work, the current methods were grouped into four categories, which were based on keywords, skin color, image content and local features. During the overview of each category, its main ideas and research directions were introduced emphatically and some examples were given. It is worth mentioning that some researchers often integrate multiple methods in their model.
The first type is based on keywords. These methods verify a picture by analysing the text close to the picture. If some pornographic text is detected, then the text associated picture is inferred to be a pornographic one. This method is relatively simple to implement. However, in some normal education for teenagers, it is inevitable that some pornographic keywords are used. Therefore, this type of methods may detect pictures that are not pornographic [1]. This method is mainly applicable to pornographic images recognition in the early social networks.
The second type is based on skin color [2, 3]. The main idea of this method is to determine whether a pixel is skin-colored or not. PUJOL et al [4] proposed a face detection method based on skin color segmentation. This paper studied a new representation of color spaces, such as RGB, HSV and YCbCr, to interpret the information of a picture. FLECK et al [5] first extracted the skin region by colour and texture features together. Then, the skin region was judged by a geometric filter. A method that considers a picture as the combination of visual words shows promising results. The main target of skin color based pornographic image recognition is to find some useful rules or models to judge whether pixels in a picture belong to human skin or not. PEREZ et al [6] first used three color channels along with other features to fusion together. Then, deep learning techniques and motion information were adopted to video pornography detection. ZHUO et al [7] first extracted rotated BRIEF (ORB) descriptors from the skin-color regions. Then, based on bag-of-words model, a feature descriptor with many dimensions was constructed to represent the key information of a picture. Finally, support vector machine (SVM) was used as the classification model for web pornographic image recognition. The method could achieve better accuracy as well as reduce the detection time. SHARIF et al [8] studied a total of 18 different prefilters and compared them in ORB-based object detection.
The third type is based on body structure. These methods first extract the skin region from the picture by some extraction algorithms. Then, a database including many different body structures is adopted to determine whether the picture is pornographic or not. Pictures containing large naked skin or skin-like areas may be detected as pornographic. Sexual organ detectors with semantic information were adopt for pornographic image detection [9]. HUANG et al [10] designed a pornographic image-filtering system based on body parts. The system extracted Haar-like features describing local grayscale distribution of the body parts and used these features to train and obtain a classifier for body parts using the Adaboost learning algorithm. The candidate body part areas can be obtained with the classifier. The main problem with these methods is that the human body posture has an infinite variety of types, so the database construction of the body postures is not comprehensive, and the precision of these methods is usually not very high [11, 12].
The fourth type is based on image content [13�C17]. These methods determine the picture by analysing whether the content of a picture is pornographic or not. A fuzzy classification algorithm was adopted to determine whether the picture is pornographic or not, which combined skin, shape, face and other features [18]. An RSOR (recognition, selection and operations regions) algorithm was adopted for pornographic contents recognition on the Internet [19]. The algorithm combined different techniques for digital image processing to judge whether a picture contain any nudity. A novel scheme utilizing the deep convolutional neural networks (CNN) was proposed [20]. In order to improve the efficiency of the scheme, a fast image scanning method based on the sliding window approach was adopted in the paper. Feature extraction plays an important role in image content based method. Scale invariant feature transform (SIFT), speeded up robust features (SURFs), oriented fast and rotated BRIEF, fast retina keypoint, binary robust invariant scalable keypoints and KAZE are six local feature extraction algorithms with excellent performance. They were compared with each other in Web pornographic image recognition [21]. SURF achieved the best recognition precision. Deep learning model was adopted for the recognition of pornographic imagery [22]. Three state-of-the-art neural networks were evaluated and the model could learn and identify new image content.
In general, the above methods have their own unique advantages and have achieved good performance in the detection of pornographic pictures. However, they are mainly designed for the detection of real pornographic pictures not the artificial ones. Directly applying them to the detection of artificial ones will bring many new issues. The first is that the features extracted from real pictures may not be suitable for artificial ones directly. The second problem is the requirement for timeliness of the recognition model. Rapid detection of these pictures will reduce harm of them spreading on social networks. The imbalance of sample set is the third problem. Compared to normal pictures, artificial pictures are in the minority, which creates an imbalance of training corpus.
Therefore, in this work, how to detect artificial pornographic pictures is studied, especially when they are on social networks. The proposed method has the following properties. Firstly, multiple features that favour the detection of artificial pornographic pictures were selected. Secondly, in view of the imbalanced corpus of artificial and normal pictures, the training dataset of artificial ones was expanded. Therefore, the number of features that can be extracted was expanded too. Thirdly, a method for the rapid extraction of the above features was designed. Finally, three tree models were compared. The one with the best accuracy was selected as the model for the final detection.
2 Artificial pornographic pictures detection
The proposed detection algorithm is summarized in Figure 1. Both the artificial pornographic pictures and normal pictures are gathered from the Internet, and then the pictures are put into two categories, the training dataset and the testing dataset. A training picture is processed in three stages, which are feature selection, training pictures expansion and feature extraction. For test pictures, the detection capabilities of three tree models (CART, RF and GBDT) are compared. The model that achieved the best results is chosen to detect whether a picture belongs to the artificial pornographic one.

Figure 1 Framework of proposed approach
In the first stage, since the original pictures cannot be used directly in the training of the detection model, it is very important to extract the features of the original pictures to represent them. A variety of image features have been put forward by researches and they can be summarized into two categories, global features and local features. For example, size and color belong to the global features, and SURF and SIFT are the local features. In this research, these two categories of features are integrated together to represent the whole features of pictures. Therefore, seven types of features are selected in this research. The features in each type have the same length and the same represented meaning.
In the second stage, since the number of artificial pornographic images is far less than the number of normal ones, the training dataset is imbalanced, which is a key problem to make the model learning more effective, so it is necessary to solve the problem. In this research, the number of training pictures is expanded in many ways to alleviate the imbalance of artificial pornographic pictures and normal ones.
In the third stage, based on the expanded training dataset, the number of features is expanded too. Furthermore, in order to recognize artificial pornographic images in social networks as soon as possible, a rapid feature extraction method is proposed to reduce the detection time of the model.
For testing pictures, firstly, features of them are extracted according to the steps of stage 1, stage 2 and stage 3. Secondly, different tree models are conducted on training dataset respectively. Finally, the model with the best results is selected as the classifier for the detection of testing pictures.
2.1 Feature selection
Feature selection is very important for the detection accuracy of the model. In this section, two problems should be solved. Firstly, features that favour recognition of the real pornographic pictures may not be suitable for the artificial ones. Therefore, how to select features that can be used to identify artificial pornographic images is the first problem.
Secondly, since there are a huge number of pictures of various types and sizes on the Internet, how to select appropriate features with the same length and the same meaning from different pictures is the second problem. If the selected features have different lengths or represent different meanings, there is no consistency in the feature representation, and the subsequent detection step cannot be performed. In this section, seven types of features are selected. The selection of these seven features is mainly due to the following reasons. Firstly, the selected features should be based on the global feature of the picture as much as possible. Secondly, the selected features should be simple and easy to expand. Finally, for images with different sizes, the selected features should have the same length and the same meaning.
2.1.1 Picture size
Size is one of the widely used picture features. For artificial pornographic pictures, the size is usually moderate, not too small or too large. In social networks, small pictures do not attract the attention of internet users; ones that are too large cannot be released and spread quickly. Therefore, picture size can be used as a basic feature to distinguish artificial pornographic pictures from normal ones.
Six features that relate to picture size adopted in this work are height, width, max (height, width), min (height, width), height��width and height/width. Except for the first two features, the features are the expanded features. Through expansion, higher- dimensional feature vectors with better ability to distinguish between different picture sizes are obtained. In the specific description of these features, numerical values rather than Boolean values are adopted to distinguish different picture sizes with better accuracy. For all pictures, the above 6 features can be described in the same length and with the same represented meaning.
2.1.2 Skin colour region
Skin colour has a reference value for judging whether a picture is pornographic or not, and it has been widely used in the recognition of real pornographic pictures. Although the skin colour of an artificial pornographic picture is generated by computer software and is different from a real pornographic picture, it still has a certain degree of similarity. Therefore, skin colour is of some help for artificial pornographic picture detection.
The extraction method of skin colour in this work is referred to Ref. [23]. Specific steps are as follows. First, the original RGB picture is converted into an YCbCr picture in the colour space. Second, if the value of a pixel satisfies a certain threshold, it is determined to be a skin colour pixel. If a picture does not contain any skin colour pixel, it is assigned a feature vector of zeros. Finally, based on the extracted region, five features are selected, which are Pscs/Pi, Psc/Pr, Ncr, Pmsc/Pscs, and Pmsc/Pr, where Pscs/Pi represents pixels of the skin colour regions divided by pixels of the whole picture, if the value of Pscs/Pi is large, the picture has large exposed skin regions and the likelihood that the picture is pornographic is great; Psc/Pr represents pixels of the skin colour region divided by pixels of the rectangle in which it is located; Ncr represents the number of skin colour pixel connected regions; Pmsc/Pscs represents pixels of the maximum skin colour region divided by pixels of the total skin colour regions; Pmsc/Pr represents pixels of the maximum skin colour region divided by pixels of the rectangle in which it is located. With the above five features, the ratio of the skin colour region to the whole picture is obtained, and the largest connected skin colour region is determined, which can be used more comprehensively to judge whether the picture is pornographic or not.
2.1.3 Grey histogram
Grey histogram is a basic statistical feature of a picture, and it is of some help for artificial pornographic picture detection. Eight features that relate to grey histogram are adopted, which are mp, grey, ��, ��, med, ent, skew and bias. They are computed on the basis of the grey histogram. The calculations are shown in formula (1) [24].
 (1)
(1)
where p(i) is the proportion of the pixels with grey value i relative to the set of all pixels of the picture, which represents a normalized grey histogram; mp represents the maximum value of p(i); grey represents the grey value of the pixel corresponding to the mp; �� and �� are the average grey value and standard deviation of the histogram; med and ent are the median value and entropy of the histogram; and skew is the skewness of the histogram, a skewed (non-symmetric) distribution is a distribution in which there is no mirror-imaging; bias is the bias between �� and med.
2.1.4 Picture colour
A coloured picture includes colour information for each pixel. Colour is one of the basic features of a picture. Compared with other features, colour is not sensitive to picture translation, scaling, rotation and so on. It is very robust and easy to calculate. Because artificial pornographic pictures are generated by computer software, colour is different from a normal picture. Therefore, picture colour is of some help in recognition and it is selected as a feature in this work. For each picture in our dataset, the pixels are clustered by the K-means algorithm in RGB space first.
Then, six features that relate to picture colour are calculated, which are m, mk, ��, ��k, rk and e. The calculations are shown in formula (2) [25].
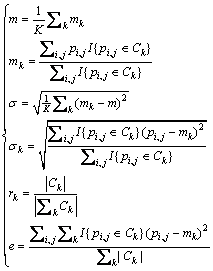 (2)
(2)
where pi,j represents the pixel in row i and column j of the picture; K is the number of the clustered classes; Ck represents the k-th clustered class; and |Ck| is the number of elements in Ck; m is the average pixel value of all classes; mk is the average pixel value of Ck; �� represents the standard deviation of all classes; ��k represents the standard deviation of Ck; rk represents the number of elements in Ck divided by the number in all classes; e represents the average value of the squared errors, which represents the closeness degree of all clustered classes.
To make the above features of different pictures have the same represented meanings, the clustered classes are sorted in a descending order according to the number of elements contained in each cluster. For different pictures, the features in the k-th clustered class all reflect the detailed information of the largest colour block. Therefore, the features selected above all have the same represented meanings. Finally, the number of extracted features of each picture is 3K+3.
2.1.5 Edge density and direction
Texture plays an important role in image segmentation or classification [26]. Edge density and directional features are used to represent textures of pictures. Different from a real picture, the texture of an artificial pornographic picture is smoother and relatively simple. Therefore, texture can be used as an important feature for recognition. Formula (3) [27] is the calculation of edge density and directional features.
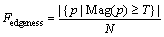 (3)
(3)
First, a gradient-based edge detection operator is applied to the original picture to obtain a gradient picture. Each pixel p of the gradient picture contains two pieces of information, Mag(p) and Dir(p), which represent magnitude and direction of gradient, respectively. Second, based on Mag(p), the edge density distribution of the unit area of the picture [28] is calculated by formula (4). Third, Mag(p) and Dir(p) are divided into a number of grades (10 in this paper). In this way, two normalized histograms Hmag and Hdir can be obtained from one picture.
 (4)
(4)
Finally, the above two histograms are combined to form the edge density and directional feature, as formula (4) shows.
2.1.6 Grey level co-occurrence matrix
For a grayscale picture I, the grey level distribution of the picture is described by grey level co-occurrence matrix (GLCM) [29], which is recorded as Cd (i, j) in this paper. Given a direction vector d =(dr, dc), the GLCM of the picture is defined as:
 (5)
(5)
Generally, the normalized Cd (i, j) is recorded as Nd (i, j) in this paper, which is defined as:
 (6)
(6)
Five features that relate to GLCM are adopted, which are ene, hom, ent, corr and cont. The calculations are shown:
 (7)
(7)
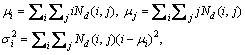
 (8)
(8)
where ene and hom are the energy and homogeneity of Nd, ent and corr are the entropy and correlation of Nd, and cont is the contrast of Nd. Given a direction vector d, a GLCM can be obtained. Finally, the GLCM feature of a picture is represented by a vector (m) as follows.
m=[ene1, hom1, ent1, corr1, cont1, ene2,hom2, ent2, corr2, cont2, ��] (9)
2.1.7 Local binary patterns
Local binary patterns (LBP) is an effective and simple computed texture feature and is widely used in face recognition [30]. It is also helpful in classification of pictures. The texture features of artificial pornographic pictures are different from normal ones and are used as an important feature. Detailed steps of the calculation of LBP feature are shown in Algorithm 1.
Algorithm 1
Input: Original picture.
Step 1 Divide the window that the picture located into cells (e.g., 16��16 pixels for each cell).
Step 2 For each pixel p in a cell, the gray value of pixel p is compared with the gray values of its 8 neighboring pixels and an 8-bit binary number b1b2b3b4b5b6b7b8 is constructed, where bi is assigned a value of 0 or 1.
Step 3 If bi is assigned a value of 0, this indicates that the gray value of the i-th neighboring pixel is less than or equal to the gray value of p. Otherwise, it is assigned a value of 1.
Step 4 Compute the histogram by counting the frequency of each number over the cell (i.e., the gray value of which pixel is smaller or larger than the center pixel). This histogram can be seen as a 256-dimensional feature vector.
Step 5 Optionally normalize the histogram. An LBP picture which has the same size as the original picture is obtained.
Output: LBP features of the picture.
2.2 Training pictures expansion
Although seven types of features are selected above, the number of features is still not enough when distinguishing artificial pornography pictures from all types of pictures in social networks. Therefore, the selected features must be expanded. Three ways of expansion are adopted.
2.2.1 One picture into four sub pictures
When we extract features of the original picture, we can also extract features of its sub block pictures. The features of sub pictures can reflect the features of original ones to some extent. Therefore, the first way to expand is to divide original pictures into sub blocks and then extract features from each sub block, as shown in Figure 2. Features of the sub blocks are finally combined to constitute features of the original one. For example, suppose an artificial picture is divided into four sub blocks; then, the above seven types of features can be extracted from these four sub blocks. In this manner, the number of features of artificial pornographic pictures is expanded. The expanded features include space distribution information of the original one, and the distinguishing ability of the features is enhanced.
2.2.2 Single channel into three channels
Similarly, when we extract features of the single channel of the original picture, we can also extract features of its other channels. The features of any channel can reflect the features of original pictures to some extent. Therefore, another way to expand the number of picture channels from which features are extracted is from a single channel to multiple channels, as shown in Figure 3. Features of these channels are finally combined to constitute features of the picture. For example, when we extract features related to a grey histogram, we can extract them on R, G, and B channels separately and then combine features of each channel together to constitute the final histogram features of the picture.
2.2.3 Different picture transformations
For a given training dataset, it is difficult to generate a new dataset, but the existing dataset can be expanded. In social networks, the disseminator of artificial pornographic pictures often uses some simple transformations to release the picture again, such as changing the picture colour tone. Therefore, similar transformations can be implemented on the training dataset to expand the number of pictures, as shown in Figure 4. Specific steps are as follows.
Step 1 Resizing the original picture proportionally; the resized picture constitutes a new picture in the training dataset.
Step 2 Transforming the original picture in some ways, such as rotation transformation and symmetry transformation; the transformed picture constitutes a new picture in the training dataset.
Step 3 Down-sampling the original picture into a smaller one using filters; the down-sampled picture constitutes a new picture in the training dataset.
Step 4 Tuning the hue of the original picture slightly by randomly changing some pixel values of the picture on a few channels.
By applying the above four steps, the training dataset can be expanded four times. Compared to the original training dataset, the expanded one can alleviate the imbalance of the artificial pornographic pictures to normal pictures, and it can improve the generalization ability of the recognition model.
2.3 Feature extraction
After the features have been selected and the training images have been expanded in the above two stages, the next stage is to extract them. In this stage, two problems must be solved. The first problem is the lack of training features. Compared to all types of pictures on the Internet, artificial pornographic ones are very few. Therefore, the number of features of these pictures is relatively small. The other problem is the efficiency of the detection model. The detection of artificial pornographic pictures on social networks requires high efficiency of the algorithm. Because dissemination of pictures in social networks is wide and fast, the detection of these pictures should be as quick as possible to prevent them from spreading widely and causing greater harm to people, especially to teenagers.

Figure 2 Features extraction on sub pictures

Figure 3 Features extraction on three channels

Figure 4 Features extraction on transformed pictures
For the first problem, since the training dataset has been expanded, the number of features extracted from the training dataset will be greatly expanded too. Therefore, this problem can be solved. For the second problem, since the feature extraction takes a long time in the detection algorithm, a rapid feature extraction method is proposed. Detailed descriptions are as follows.
1) For picture size related 6 features, which are height, width, max(height, width), min(height, width), height��width and height/width, are fixed attributes of a picture, and the extraction time of these features have little relationship to the size of the picture. Furthermore, if the size of a picture is changed, then the above size related 6 features will be changed too. Therefore, picture size will not be changed when extracting these features.
2) For skin colour region related 5 features, which are Pscs/Pi, Psc/Pr, Ncr, Pmsc/Pscs, and Pmsc/Pr respectively, the extraction time of these features are proportional to the size of the picture. Since the above 5 features are the proportion of pixels in a region to the whole image, the calculation of them are independent of the image size to some extent. For example, Pscs/Pi represents pixels of the skin colour regions divided by pixels of the whole picture, and suppose picture B is a picture that is scaled proportionally from picture A, then calculating the value of Pscs/Pi on picture B is almost the same as calculating on the original picture A. The remaining 4 features are similar to this feature. Since the extraction of these 5 features are invariant to the size of the picture, then we can extract these features on the scaled picture rather than the original one.
3) For grey histogram related 8 features, which are mp, grey, ��, ��, med, ent, skew and bias respectively, the extraction time of these features are proportional to the size of the picture. Since the above 8 features are the proportion of pixels in a region to the whole image, the calculation of them are independent of the image size to some extent. For example, p(i) is the proportion of the pixels with grey value i relative to the set of all pixels of the picture, which represents a normalized grey histogram, the value of p(i) calculated on picture B is almost the same as on the original picture A. Furthermore, for grey histogram related features, if a picture is scaled proportionally, the histogram shape of the scaled picture is almost exactly the same as that of the original one, as shown in Table 1.
Table 1 Histogram comparison between original picture and scaled picture

4) For picture colour related 6 features, which are m, mk, ��, ��k, rk and e respectively, the extraction time of these features are proportional to the size of the picture. Since the above 6 features are the proportion of pixels in a region to the whole image, the calculation of them are independent of the image size to some extent. For example, rk represents the number of elements in Ck divided by the number in all classes, a clustering operation is performed during its extraction. If the size of the picture is large, many pixels need to be clustered, and the feature extraction will be time consuming. Furthermore, the value of rk calculated on the picture B is almost the same as on the original picture A.
5) For edge density and direction related features, since Fedgeness is the marginal distribution density per unit area, it is invariant to picture size. Similarly, since Fmagdir is the normalized histogram of gradients of magnitude and direction, it is also invariant.
6) For GLCM and LBP related features, the above analysis is also applicable.
In summary, if a high-dimensional feature vector is extracted from the original pictures, it will take considerable time, making it hard to meet the requirement of speed for image recognition. If the extraction of some features is invariant to the size of the picture, then we can extract these features on the scaled picture rather than the original one. Therefore, a rapid feature extraction method is proposed. Except for picture size related features, the other six types of features are extracted on the proportionally scaled pictures rather than the original ones. With this method, the time cost of feature extraction can be greatly reduced.
After applying the above methods on the seven types of features, finally, an 888 dimensional feature vector is formed, which represents the original picture to participate in the next model training. During the process of feature expansion, the number of features most expanded is grey histogram, followed by LBP and edge density and direction. The number of features related to picture size and skin colour region is unchanged. Table 2 shows the dimension of each type of feature in detail.
2.4 Picture detection model
A tree model is adopted to combine different types of features for picture classification. It can be applied in the ensemble-based learning framework naturally and conveniently. Therefore, it is applied in this stage.
There are many excellent machine learning models for classification, such as logistic regression (LR), support vector machine (SVM), and tree model (TM). Logistic regression is a probability model which is used to estimate the probability of a response based on one or more predictor variables. Although the name of LR contains the word regression, actually it is a two-classification model. Support vector machines have achieved great success in many applications that have been tested, which are supervised learning models that assign new examples to one category or the other. It has many unique advantages in solving small sample, nonlinear and high dimensional pattern recognition. Tree model is good at combining different types of features for picture classification. It can be applied in the ensemble-based learning framework naturally and conveniently, and in this manner the generalization ability of the model can be greatly improved. Each model has its own advantages, disadvantages and optimal applications.
Table 2 Dimension numbers of feature expansion

Classification and regression tree (CART), random forest (RF) and gradient boost decision tree (GBDT) are three excellent tree models. CART is good at nonparametric identification, which is based on statistical theory. It is very powerful in statistical analysis and it can achieve better results when the input data and the prediction data are incomplete. CART is a kind of decision tree model, which is a tree representation of the mapping from independent variable to dependent variable. Each node in the tree represents a judgment of the independent variable, and each branch represents the result of the judgment. Leaf node in the tree represents the dependent variable output of the independent variable that reaches the leaf node. CART is a two binary tree, which can be used separately for classification and regression problems according to the specified loss function, so it is called classification and regression tree. The learning algorithm of CART is mainly the splitting operation of nodes. According to the difference of loss functions, there are different splitting criterions. In classification problem, the Gini criterion is generally adopted, and the Gini purity is the degree of chaos in the sample set. Gini decomposition criterion is used to find a splitting point, so that the weighted Gini of the two split sets is not the least. In fact, the learning algorithm of CART also has pruning and other operations, such as the limited tree height does not exceed a certain value, pruning corresponds to the structural risk minimization criterion, which can prevent overfitting.
Random forests and gradient lifting decision trees are ensemble models, which refer to the combination of weak models to form a strong model. Such as Adaboost is the famous combination model. RF is a multiple decision tree classifier that uses multiple trees to train and predict samples. As a newly developed machine learning algorithm, RF has a wide range of applications. Each tree in a random forest is independent. During the prediction of a new sample in a random forest model, each tree in the forest gives a predictive value for the new sample. For the classification problem, the class of which is predicted by the most trees, and the random forest outputs the class as the result. When training random forests, sample sampling and feature sampling are needed. That is to say, each tree in the forest is a sampling sample which is put back and returned to the original sample, and a new sample is obtained, and several selected original features are trained. In a random forest, a single tree does not need pruning operations, and the sampling process and the tree combination process can avoid overfitting automatically.
RF is combined by Bagging, while GBDT is combined by Gradient Boost, which is the application of the gradient elevator in decision tree model. Both RF and GBDT are excellent machine learning models, and they all have a lot of advantages. With the combination of simple CART trees, they can easily solve multiple types of data with high latitude, and do not need the process of feature selection. Since each tree in RF is independent, it is easy to be made parallel algorithms. After the process of data training, it also provides information about the importance of features. GBDT is an iterative decision tree algorithm, which consists of multiple decision trees, and the results of all the trees are accumulated to make the final decision. Because of its boosting property, the fitting data of GBDT is generally better than RF. It is considered as a powerful generalization algorithm.
CART, RF and GBDT are good at combining different types of features for picture classification. This paper happens to be a picture classification problem based on a variety of features. In addition, CART, RF and GBDT can be used very conveniently in the integrated learning framework, which makes the generalization ability of the model greatly enhanced. Therefore, it is feasible in theory to make use of the three tree models for the detection of artificial pornographic pictures. In this work, recognition precisions of CART, RF and GBDT are compared, and the one with the highest precision is selected as the final model for picture detection.
3 Experimental results and analysis
3.1 Experiment setting
To evaluate the effect of the proposed algorithm, 9808 pictures from Baidu post bar were collected. In this data set, the proportion of artificial pornographic pictures to normal pictures was approximately 1:6. The data set was divided into a training set and test set. There were 7860 and 1948 pictures in the training set and test set, respectively. 1191 of the training set and 308 of the test set were artificial pornographic pictures. Examples of selected images are shown in Figure 5.
Three groups of experiments were performed, which are listed in Table 3.
Experiment A is mainly used for feature extraction in original pictures and scaled ones respectively, in order to find out whether the former or the latter has a faster extraction time. The purpose of Experiment B is to compare the generalization ability of the original dataset and the expanded one. Finally, based on the results of Experiments A and B, better feature extraction methods and generalization ability can be obtained. The results will be used as input in CART, RF and GBDT models, and the models are compared in Experiment C.
3.2 Experiment A
In experiment A, 1000 pictures of a variety of sizes were selected randomly. Two different methods were adopted to calculate the features. One method is based on the original pictures, and the other is based on the proportionally scaled pictures. Using the configuration of Core I5, RAM 4G, the results are shown in Table 4. During the experiment, we observed that if the above features are calculated directly on the original pictures, it will take too much time. For a large-sized picture, the feature calculation will take almost 1 s, which is obviously not able to meet the picture recognition in social networks such as post bar. If the original picture is scaled first, the time will be shortened greatly to approximately 25 ms per picture. For 1000 pictures, the total time will be reduced more than 20-fold.
3.3 Experiment B
In Experiment B, based on the rapid feature extraction method and GBDT algorithm, the generalization abilities of the algorithm on the original and the expanded features were compared, to prove that after the features were expanded, the GBDT algorithm could achieve better generalization ability. The results are shown in Figure 6. The X-axis and Y-axis represent the values of false positive rate (FPR) and true positive rate (TPR), respectively. The calculations are shown in Eq. (10).
 (10)
(10)
where TP or TN is the result that a test properly indicates the presence or absence, respectively, of a condition, such as the correct recognition of a picture as pornographic or normal. FP or FN is the result that a test improperly indicates the presence or absence, respectively, of a condition, such as the incorrect recognition of a picture as pornographic or normal. The horizontal axis FPR represents the proportion of normal pictures judged to be artificial pornographic pictures compared to all normal pictures. The vertical axis TPR represents the recall rate. It can be observed that based on the same GBDT model, the training dataset with expanded features has better generalization ability than the training set without expanded features.

Figure 5 Examples of partial data sets
Table 3 Three groups of experiments

Table 4 Time cost comparison for feature extraction (1000 pictures)


Figure 6 Generalization ability comparison between expanded and non-expanded features
3.4 Experiment C
In experiment C, based on the results of Experiments A and B (that is, based on the rapid feature extraction method and the expanded training dataset and features), three tree models ��CART, RF and GBDT�� were compared, p, r and F1 were used for the evaluation of the results. The calculations are shown in Eq.(11).
p=TP/(TP+FP); r=TP/(TP+FN); F1=2pr/(p+r) (11)
The results of Experiment C are shown in Table 5. It can be observed that the GBDT model has the best performance. The GBDT model achieved better results even with a small training dataset. For artificial pornographic pictures, the precisions of the CART, RF, and CBDT models are 69.7%, 96.2% and 98.3%, respectively, and recall rates of the three models are 82.8%, 89.6% and 92.9%, respectively. The GBDT model achieved the highest values, which means that in social networks, it can filter out more than 90% of the artificial pornographic pictures with an error rate of only 1.7%. For normal pictures, all of the three models have high precision and recall rates, but the GBDT model still achieved the highest values.
Table 5 Comparison between CART, RF and GBDT

As expected, GBDT��s performance is the best. The gradient lifting method is a very successful integration method, which has many advantages, such as preventing over fitting. It can also achieve excellent results in the case of a small number of training data sets. In addition, we can also balance the relationship between the recall rate and the accuracy by adjusting the threshold. If the threshold is raised, the recall rate is reduced and the accuracy is increased. High threshold can be used in the real-time automatic filtering process in social networks. Low threshold ensures the recall of most suspected artificial pornographic pictures, which can be manual confirmed next.
4 Conclusions
Different from the traditional real pornographic pictures recognition, a multiple feature model for the detection of artificial pornographic pictures is proposed.
1) In the process of feature selection, seven types of features were selected to distinguish artificial pornographic pictures from normal ones.
2) Because the training dataset of artificial pornographic pictures is relatively small, a dataset expansion method is proposed to improve the imbalance of samples between the pornographic and normal pictures.
3) A rapid feature extraction method is proposed to reduce the time cost of picture recognition.
4) Constructing a large training dataset of artificial pornographic pictures. The number of artificial pornographic pictures in the training dataset has a certain influence on the accuracy of the recognition model, therefore, to construct a large dataset as much as possible is very important in the future work.
5) Designing an on-line learning model. The methods used in this paper are based on off-line training model, and in social networks, pornographic picture spreaders often change the feature of these pictures so as to escape the filter that trained beforehand. Therefore, the model should be retrained periodically to adapt the new situation. If we can design an on-line learning model, and the model can change its parameters automatically with the change of the pornographic pictures, then the recognition accuracy of this model will be greatly improved.
References
[1] LIU B B, SU J Y, LU Z M, LI Z. Pornographic images detection based on cbir and skin analysis [C]// Fourth International Conference on Semantics, Knowledge and Grid. Piscataway: IEEE, 2008: 487�C488.
[2] JONES M, REHG J. Statistical color models with application to skin detection [J]. International Journal of Computer Vision, 2002, 46(1): 81�C96.
[3] ZAIDAN A A, AHMAD N N, ABDUL K H, LARBANI M, ZAIDAN B B, SALI A. On the multi-agent learning neural and Bayesian methods in skin detector and pornography classifier: An automated anti-pornography system [J]. Neurocomputing, 2014, 131: 397�C418.
[4] PUJOL F A, PUJOL M, JIMENO-MORENILLA A, PUJOL M J. Face detection based on Skin color segmentation using fuzzy entropy [J]. Entropy, 2017, 19(26): 1�C22.
[5] FLECK M M, FORSYTH D A, BREGLER C. Finding naked people [C]// Proceedings of European Conference on Computer Vision. Berlin: Springer, 1996: 593�C602.
[6] PEREZ M, AVILA S, MOREIRA D, TESTONI V, VALLE E, GOLDENSTEIN S, ROCHA A. Video pornography detection through deep learning techniques and motion information [J]. Neurocomputing, 2017, 230(C): 279�C293.
[7] ZHUO L, GENG Z, ZHANG J, LI X G. ORB feature based web pornographic image recognition [J]. Neurocomputing, 2016, 173(P3): 511�C517.
[8] SHARIF H, H LZEL M. A comparison of prefilters in ORB-based object detection [J]. Pattern Recognition Letters, 2017, 93: 154�C161.
LZEL M. A comparison of prefilters in ORB-based object detection [J]. Pattern Recognition Letters, 2017, 93: 154�C161.
[9] TIAN C, ZHANG X, WEI W, GAO X. Color pornographic image detection based on color-saliency preserved mixture deformable part model [J]. Multimedia Tools & Applications, 2018, 77(6): 6629�C6645.
[10] HUANG J, NI P Y. Pornographic-image filtering based on body parts [J]. Journal of Applied Sciences, 2014, 32(4): 416�C422. (in Chinese)
[11] HU W, WU O, CHEN Z, FU Z, MAYBANK S. Recognition of pornographic web pages by classifying texts and images [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6): 1019�C1034.
[12] ZHUO Li, ZHANG Jing, ZHAO Ying-di, ZHAO Shi-wei. Compressed domain based pornographic image recognition using multi-cost sensitive decision trees [J]. Signal Processing, 2013, 93(8): 2126�C2139.
[13] ZHANG Jing, SUI Lei, ZHUO Li, LI Zhen-wei, YANG Yun-cong. An approach of bag-of-words based on visual attention model for pornographic images recognition in compressed domain [J]. Neurocomputing, 2013, 110: 145�C152.
[14] DONG Kai-kun, GUO Li, FU Quan-sheng. An adult image detection algorithm based on bag-of-visual-words and text information [C]// 10th International Conference on Natural Computation. Piscataway: IEEE, 2014: 556�C560.
[15] MOREIRA D, AVILA S, PEREZ M, MORAES D, TESTONI V, VALLE E, GOLDENSTEIN S, ROCHA A. Pornography classification: The hidden clues in video space-time [J]. Forensic Sci Int, 2016, 268: 46�C61.
[16] CAETANO C, AVILA S, SCHWARTZ W R, GUIMAR ES S J F, ARA
ES S J F, ARA JO A. A mid-level video representation based on binary descriptors: A case study for pornography detection [J]. Neurocomputing, 2016, 213: 102�C114.
JO A. A mid-level video representation based on binary descriptors: A case study for pornography detection [J]. Neurocomputing, 2016, 213: 102�C114.
[17] LI Fang-fang, LUO Si-wei, LIU Xi-yao, ZOU Bei-ji. Bag-of-visual-words model for artificial pornographic images recognition [J]. Journal of Central South University, 2016, 23(6): 1383�C1389.
[18] DRIMBAREAN A F, CORCORAN P M, CUIC M, BUZULOIU V. Image processing techniques to detect and filter objectionable images based on skin tone and shape recognition [C]// Proc IEEE Int Conference on Consumer Electronics. Piscataway: IEEE, 2001: 278�C279.
[19] COLMENARES-GUILL N L E, VELASCO F J A. Filter for web pornographic contents based on digital image processing [J]. International Journal of Combinatorial Optimization Problems and Informatics, 2016, 7(2): 13�C21.
N L E, VELASCO F J A. Filter for web pornographic contents based on digital image processing [J]. International Journal of Combinatorial Optimization Problems and Informatics, 2016, 7(2): 13�C21.
[20] NIAN F, LI T, WANG Y, XU M, WU J. Pornographic image detection utilizing deep convolutional neural networks [J]. Neurocomputing, 2016, 210: 283�C293.
[21] GENG Z, ZHUO L, ZHANG J, LI X. A comparative study of local feature extraction algorithms for Web pornographic image recognition [C]// IEEE International Conference on Progress in Informatics and Computing. Piscataway: IEEE, 2016: 87�C92.
[22] MAYER F, STEINEBACH M. Forensic image inspection assisted by deep learning [C]// International Conference on Availability, Reliability and Security. New York: ACM, 2017: 53�C61.
[23] MARCIAL-BASILIO J A, AGUILAR-TORRES G, SANCHEZ-PEREZ G, KARINA TOSCANO-MEDINA L, PEREZ-MEANA H M. Detection of pornographic digital images [J]. International Journal of Computers, 2010, 2: 298�C305.
[24] WIKIPEDIA. Histogram [EB/OL]. [2018�C07�C08]. https://en. wikipedia.org/wiki/Histogram.
[25] WIKIPEDIA. Color [EB/OL]. [2018�C07�C08]. https://en. wikipedia.org/wiki/Color.
[26] MANJUNATH B S, MA W Y. Texture features for browsing and retrieval of image data [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1996, 18(8): 837�C842.
[27] MARR D, HILDRETH E. Theory of edge detection [J]. Proceedings of the Royal Society of London, 1980, 207(1167): 187�C217.
[28] SHAPIRO L G, STOCKMAN G C. Computer vision [M]. Upper Saddle River, New Jersey, USA: Prentice-Hall, 2011.
[29] HARALICK R M, SHANMUGAM K, DINSTEIN I H. Textural features for image classification [J]. IEEE Transactions on Systems, Man and Cybernetics, 1973(6): 610�C621.
[30] AHONEN T, HADID A, PIETIKAINEN M. Face description with local binary patterns: Application to face recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(12): 2037�C2041.
(Edited by FANG Jing-hua)
���ĵ���
���ڶ���������ģ�͵�����ɫ��ͼƬʶ��
ժҪ�����������罻���������ɫ��ͼƬ�Ƚ����ס��о��߶���ʵɫ��ͼƬ�ļ������˴����о������Ƕ�����ɫ��ͼƬ���о����١�������Ҫ����罻����������ɫ��ͼƬ��ʶ��������о���������������������ɣ�����ѡ���ͼ��ʶ��������ѡ���У�����ѡ����7�����͵���������ͼ��ʶ���У���Ҫ����3�����衣1��Ϊ�˻��������������IJ�ƽ�����ݣ����Ķ�����ɫ��ͼƬ�����������������䡣2�������һ������������ȡ�ķ�����3���Ա����������͵���ģ�ͣ���ѡ��������Ч����õ�GBDTģ����Ϊ����ͼƬʶ���ģ�͡�ͨ��ʵ����֤�˱��ķ����ܹ���ýϺõľ��ȣ�ͬʱ��ʱ�϶̡�
�ؼ��ʣ�������������ɫ��ͼƬ��ͼƬʶ��GBDT
Foundation item: Projects(61573380, 61303185) supported by the National Natural Science Foundation of China; Projects(2016M592450, 2017M612585) supported by the China Postdoctoral Science Foundation; Projects(2016JJ4119, 2017JJ3416) supported by the Hunan Provincial Natural Science Foundation of China
Received date: 2017-11-28; Accepted date: 2018-13-21
Corresponding author: LI Fang-fang, PhD, Associate Professor; Tel: +86�C15274960018; E-mail: lifangfang@csu.edu.cn; ORCID: 0000-0001-7829-1539

