DOI: 10.11817/j.issn.1672-7207.2017.10.009
基于Adaboost加权支持向量机的热轧板带弯曲性能质量预警
周鹏1,何飞2,梁冰2,徐科2
(1. 北京科技大学 工程技术研究院,北京,100083;
2. 北京科技大学 钢铁共性技术协同创新中心,北京,100083)
摘要:针对热轧带钢弯曲性能质量监控与预警过程中因正常样本与异常样本的比例严重失衡而导致质量监控过程中预警不灵敏、异常检出率较低的问题,从数据层面和算法层面研究不平衡样本数据的质量预警问题,提出基于Adaboost加权支持向量机的热轧带钢弯曲性能质量预警方法。研究结果表明:采用该方法所得平均异常检出率提高至88.58%,误判率为0.63%。该方法具有较强的异常检出能力,能够为热轧板带生产过程的质量预警提供保障。
关键词:带钢弯曲性能;质量预警;Adaboost加权支持向量机
中图分类号:TG335.5 文献标志码:A 文章编号:1672-7207(2017)10-2622-06
Research on quality warning of strip bending performance based on Adaboost-weighted support vector machine
ZHOU Peng1, HE Fei2, LIANG Bing2, XU Ke2
(1. Engineering Technology Research Institute, University of Science and Technology Beijing, Beijing 100083, China;
2. Collaborative Innovation Center of Steel Technology,University of Science and Technology Beijing, Beijing 100083, China)
Abstract: Due to the data imbalance between normal and abnormal samples, the quality warning is not sensitive and the detection rate is low in the quality monitoring of strip bending performance. To solve this problem, different imbalance solutions to the abnormal detection from data level and algorithm level were studied.The quality warning method based on the Adaboost-weighted support vector machine method was proposed. The results show that the average value of fault detection rate is improved to 88.58%, and the average value of false alarm rate is reduced to 0.63%. The proposed method produces satisfying results in fault detection, which provides support for quality warning in hot rolling strip process.
Key words: strip bending performance; quality early warning; Adaboost-weighted support vector machine
弯曲性能是指材料在经受弯曲负荷作用时的弯曲强度以及抵抗塑性变形的能力。带钢往往要经过多道次的深加工(如冲压、冷弯成型、焊接等)才能成为产品,这就要求带钢除了尺寸精度和表面质量符合标准要求外,更重要的是要有良好的弯曲性能,否则就会在深加工过程出现开裂、塌陷、分离等缺陷[1]。因此,需对带钢弯曲性能数据进行质量预警,根据实际生产数据可以及时检出异常产品,甚至在成熟的质量预警模型的基础上实现质量优化。然而,在质量预警的过程中,异常数据往往占很少一部分,出现不平衡分类问题,为异常的检出带来困难[2]。常用的不平衡数据分类策略包括数据层面和算法层面2类策略[3]。数据层面方法的策略是通过对数据进行重采样(re-sampling)来调整原始数据集的样本分布,具体方法包括过采样(over-sampling)和欠采样(under-sampling) 2种,其主要思想是通过合理增加或者减少一定量的样本去重新实现样本的平衡,从而减轻数据不平衡对分类器造成的负面影响。常规欠采样方法对多数类的数据进行相应处理,将离分类边界较远的数据进行剔除,或随机删除多数类数据,但并没有考虑数据信息的问题[4]。FN欠采样方法(furthest neighbor based under-sampling)试图在样本集的每一区域均保留一定量的样本,以便较好地保留数据的真实性[5]。常规的过采样方法是随机复制某一类样本,而改进后的过采样方法SMOTE(synthetic minority over-sampling technique)算法[6-8]是利用k近邻和线性插值,在相距较近的2个少数类样本间按照一定的规则人为地插入新的样本,使少数类样本数目增加,数据集趋于平衡。本文作者从数据层面和算法层面,尝试多种解决不平衡分类问题的方法,对比其在随机样本集中异常检出率的稳定性以及在不同样本比例下的泛化能力。最终从算法层面对不平衡数据进行分析,采用优秀的支持向量机作为数据分类器,引入加权函数来减少不平衡数据带来的影响[9-10]。Adaboost算法可以通过循环迭代多次更新样本分布,增强分类效果。为此,本文作者提出Adaboost加权支持向量机的质量预警方法,分别从数据层面和算法层面提高不平衡数据的分类效果。
1 热轧带钢生产
1.1 热轧带钢生产过程
热连轧生产常以连铸板坯为原料,将钢材加工为厚度为2~6 mm的板带产品。常用的带钢热连轧生产线一般包括:加热炉区、粗轧区、粗精轧之间的中间辊道及飞剪、精轧区[11]、热输出辊道及层流冷却装置、卷取区等,如图1所示。
带钢热连轧生产过程需要保证成品带钢的质量,具体如下:1) 厚度精度、宽度精度、凸度及平直度等尺寸形状参数;2) 屈服强度、抗拉强度、延伸率、弯曲性能和硬度等力学性能;3) 划痕、裂纹等[1]。
1.2 热轧板带弯曲质量
弯曲性能是衡量带钢冲压成形的重要指标。研究选用的钢种属于高碳钢,弯曲试验主要用于测定其抗弯强度,也能反映塑性指标的挠度。按照国家标准GB232“金属材料弯曲试验方法”,在万能材料机上进行弯曲试验,以测试由轧带钢的弯曲性能。试验时将试样加载,使其弯曲到一定程度,观察试样表面有无裂缝,若有裂缝,则说明弯曲性能异常。
某生产线时常会出现弯曲性能异常的情况,从实际的机理模型出发难以解释其原因,为此,拟从数据分析角度进行质量异常诊断。首先从工艺角度分析,收集可能引起弯曲质量异常的工艺参数和对应的弯曲性能类别。根据实际数据采集情况和工艺需求,主要收集如下3类参数:化学成分信息(包括C,Si,Mn,P和S等的质量分数)、热轧温度信息(包括粗轧出口温度、精轧入口温度、精轧出口温度和卷取温度)、厚度压下率(指精轧入口到出口的压下率)。

图1 热连轧生产过程的布置图
Fig. 1 Layout drawing of hot rolling process
2 Adaboost加权支持向量机
在实际的质量预警中,由于质量数据中出现异常的数据属于少数,给质量预警带来困难,为此,从2个方面解决不平衡数据带来的困难:一是基于支持向量机分类的自身算法针对不平衡数据问题进行改进,另一个是采用加强算法对支持向量机算法进行强化。
2.1 加权支持向量机
由常规支持向量机(SVM)决策分类面:
 (1)
(1)
其中: 为输入空间自变量;
为输入空间自变量; 为将特征空间投影到特征空间的映射函数;
为将特征空间投影到特征空间的映射函数; 为将特征空间投影到输出空间的权重;b为常数项;
为将特征空间投影到输出空间的权重;b为常数项;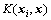 为核函数;y为输入空间因变量;
为核函数;y为输入空间因变量; 为核函数权重。
为核函数权重。
由式(2)可知:SVM在不平衡数据集上对少数类样本分类效果较差的原因在于,核函数中,对多数类样本及少数类样本同等对待,这将导致支持向量的数量不平衡和分布不均衡[12]。对原始SVM方法中的决策函数进行调整,加大少数类样本的支持向量对分类的贡献度,继而提高少数类样本分类的准确率。
则决策函数可以写成
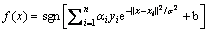 (2)
(2)
其中:σ为核参数,令 。少数类为正类,y=+1,多数类为负类,y=-1,则有
。少数类为正类,y=+1,多数类为负类,y=-1,则有
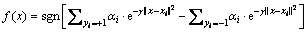 (3)
(3)
其中:参数γ控制不同的支持向量在分类决策函数中的权重。当2类样本数量基本一致,同时支持向量分布均衡时,γ取值应相同,即所有的支持向量权重是相等的;而当样本分布不均衡时,决策函数倾向于将边界处的测试样本划分到多数类样本的范畴中,所以,在新的算法中,应该调整少数类样本权重,使少数类样本支持向量在分类决策函数中的比重加大。为此,引入参数μ来调整多数类与少数类之间的差距。则新的决策函数为
 (4)
(4)
其中:μ为控制少数类样本支持向量在决策函数中的权重,μ≥1。由于γ和μ包含在指数项内,因此,μ取值较小。根据经验,μ取值应该在[1,1.01]之间,称这种带权重的SVM算法为μSVM。
2.2 Adaboost迭代增强算法
Adaboost算法[13]通过循环迭代多次更新样本分布,寻找当前分布下的最优弱分类器,并计算弱分类器误差率;然后聚合多次训练的弱分类器。其完整流程的伪代码如下。
1) 定义。
① 样本空间: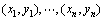 。其中
。其中 ;
;  ;
; 。
。
② 初始化样本分布: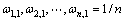 。
。
③ 误差方程: 。
。
④ 弱分类器: 。
。
2) For t=1 to T,T为循环迭代次数。
① 根据样本分布Dt训练弱分类器。选择一个弱分类器,使得误差 最小:
最小:
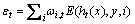 (5)
(5)
并令
 (6)
(6)
② 将弱分类器集合到强分类器中:
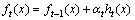 (7)
(7)
③ 更新样本分布权重:
 (8)
(8)
并重新归一化,使得 。
。
3) 输出最终集成得到强分类器:
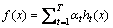 (9)
(9)
其中:是误差项; 为第t-1次分类结果;
为第t-1次分类结果; 为第t次分类结果;
为第t次分类结果; 为第i个样本第t次迭代的分布权重;
为第i个样本第t次迭代的分布权重;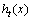 为第t次弱分类结果。
为第t次弱分类结果。
Adaboost具有如下特点:
① 每次迭代改变的是样本的分布,而不是重复采样(re-weight)。
② 样本分布的改变取决于样本是否被正确分类:总是分类正确的样本权值低,总是分类错误的样本权值高(通常是边界附近的样本)。
③ 最终的结果是弱分类器的加权组合,权值表示该弱分类器的性能。
简单来说,Adaboost有很多优点,它是一种较高精度的分类器,可以使用各种方法构建子分类器。Adaboost算法仅为算法提供框架,不存在过拟合问题。基于Adaboost加权支持向量机算法不仅结合了Adaboost算法和加权算法对于解决不平衡问题的优点,而且采用了优秀的分类算法SVM,具有较强的解决不平衡问题的能力,具体流程如图2所示。
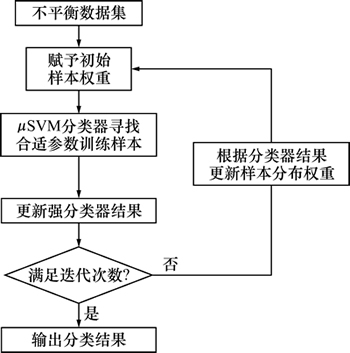
图2 Adaboost加权支持向量机算法流程图
Fig. 2 Flow chart of Adaboost+μ SVM
3 热轧带钢弯曲性能预警
为验证方法的有效性,从实际生产线采集相关数据对算法进行分析。
3.1 数据集
在某热轧带钢生产线中选择同一钢种、同一厚度的带钢作为研究对象,发现其中有71卷带钢的弯曲性能存在异常,而有890个样本的弯曲性能正常,属于典型的不平衡分类问题。分别采用相关算法进行分类预警分析。所有样本的各变量统计值如表1所示。为消除量纲对结果的影响,在分析之前首先对数据集中各变量进行标准化处理。
3.2 各方法在随机样本中的表现
在Adaboost+μSVM方法中,权重系数和迭代次数是非常重要的2个参数,对误差率和检出率影响较大。图3~4所示分别为权重和迭代次数对误差率和检出率的影响。由图3~4可知:当boost循环次数取值大于某一值后误差率和检出率趋于平稳,说明该方法对取值不敏感,可供后续使用。
为验证方法的有效性,重复试验100次,各方法实验结果如表2~3所示。
从表2可以看出:各方法的异常检出率相对于单纯的SVM建模方法均有很大的提高,且都有一定的波动范围;随机过采样+μSVM方法、SMOTE+μSVM方法及Adaboost+μSVM方法的检出率均值达85.00%以上,其中Adaboost+μSVM方法的检出率波动范围最小(标准差为6.47)。在100次随机试验中,比较各方法的检出率,SMOTE+SVM方法胜出次数最多(34次)。从表3可以看出:在检出率提高的同时,误判率也相应增加。在欠采样方法和过采样方法中,误判率增加得更为明显;μSVM方法误判率均值及标准差均最小(均值为0.22,标准差为0.46),其胜出次数也最高(51次)。但若同时考虑检出率及误判率,则Adaboost+μSVM方法可以达到较高的检出率及较低的误判率,且方法相对较稳定,在多次随机试验中,均有较好的效果。因此, Adaboost+ μSVM 具有较好的算法优势,更有利于实际应用。
表1 变量统计值
Table 1 Statistical values of variables

图3 加权SVM模型对测试集的分类效果
Fig. 3 Classification performance of test dataset based on μSVM

图4 测试集分类结果随boost循环次数变化图
Fig. 4 Classification performance of test dataset with the cycle index of boost
表2 100次随机试验异常检出率
Table 2 Fault detection rate of 100 random tests

表3 100次随机试验误判率
Table 3 False alarm rate of 100 random tests

3.3 各方法在不同样本比例下的性能
在不平衡数据分析中,少数样本的比例是一个重要的影响指标。为更好地对比各方法对不平衡程度的影响,对数据集进行9次抽样形成训练集,其中异常样本分别占总样本的10%,20%,…,90%。对训练集进行训练,并应用训练模型对原始数据集分类。以误判率为横轴,检出率为纵轴,绘制ROC曲线[14],如图5所示。
从图5可以看出:Adaboost+μSVM方法的曲线最接近左上方,说明该方法一般化能力最强。对弯曲性能数据分类时,通过对比不同解决方法的改善效果、稳定性以及泛化能力,得出最优解决方案为Adaboost与μSVM结合的方法。通过该最优方案对弯曲性能数据进行分类建模,平均异常检出率从33.33%提高至88.58%,平均误判率为0.63%,对异常样本的预警能力大大提高。
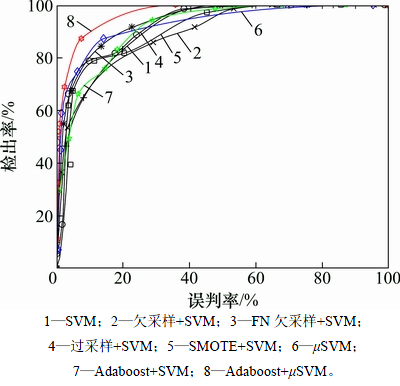
图5 不同样本比例下多种不平衡解决方法的ROC曲线
Fig. 5 ROC curves of multiple unbalanced solutions under different sample ratios
4 结论
1) 提出Adaboost+μSVM的质量预警方法,分别从数据层面和算法层面解决不平衡样本的分类问题。比较多种方法在质量预警效果、稳定性以及泛化能力中的表现,证实Adaboost+μSVM方法在综合性能上表现最优。
2) 通过Adaboost+μSVM方法对热轧带钢弯曲性能数据进行分类建模,异常样本平均检出率从33.33%提高至88.58%,达到较好的质量预警效果。
参考文献:
[1] 何飞, 徐金梧, 梁治国, 等. 基于核熵成分分析的热轧带钢自适应聚类分析[J]. 中南大学学报(自然科学版), 2012, 43(5): 1732-1738.
HE Fei, XU Jinwu, LIANG Zhiguo, et al. Hot rolled strip state clustering based on kernel entropy component analysis[J]. Journal of Central South University (Science and Technology), 2012, 43(5): 1732-1738.
[2] 叶志飞, 文益民, 吕宝粮. 不平衡分类问题研究综述[J]. 智能系统学报, 2009, 4(2): 148-156.
YE Zhifei, WEN Yimin, LV Baoliang. A survey of imbalanced pattern classification problems[J]. China Association of Artificial Intelligence Transactions on Intelligent Systems, 2009, 4(2): 148-156.
[3] 王德成, 林辉. 一种SVM不平衡分类方法及在故障诊断的应用[J]. 电机与控制学报, 2012, 16(9): 48-52.
WANG Decheng LIN Hui. Imbalanced pattern classification method based on support vector machine and its application on fault diagnosis[J]. Electric Machines and Control, 2012, 16(9): 48-52.
[4] 李倩倩, 刘胥影. 多类类别不平衡学习算法: Easy Ensemble. M [J]. 模式识别与人工智能, 2014, 27(2): 187-192.
LI Qianqian LIU Xuying. EasyEnsemble. M for Multiclass Imbalance Problem[J]. Pattern Recognition and Artificial Intelligence, 2014, 27(2): 187-192.
[5] 朱明, 陶新民. 基于随机下采样和 SMOTE 的不均衡 SVM 分类算法[J]. 信息技术, 2012, 1: 39-43.
ZHU Ming TAO Xinmin. The SVM classifier for unbalanced data based on combination of RU-Undersample and SMOTE[J]. Information Technology, 2012, 1: 39-43.
[6] 王超学, 潘正茂, 董丽丽, 等. 基于改进 SMOTE 的非平衡数据集分类研究[J]. 计算机工程与应用, 2013, 49(2): 184-187.
WANG Chaoxue, PAN Zhengmao, DONG Lili, et al. Research on classification for imbalanced dataset based on improved SMOTE[J]. Computer Engineering and Applications, 2013, 49(2): 184-187.
[7] 赵自翔, 王广亮, 李晓东. 基于支持向量机的不平衡数据分类的改进欠采样方法[J]. 中山大学学报(自然科学版), 2012, 51(6): 10-16.
ZHAO Zixiang, WANG Guangliang, LI Xiaodong. An improved SVM based under-sampling method for classifying imbalanced data[J]. Acta Scientiarum Naturalium Universitatis Sunyatseni, 2013, 51 (6): 10-16.
[8] BLAGUS R, LUSA L. SMOTE for high-dimensional class-imbalanced data[J]. BMC Bioinformatics, 2013, 14(3): 106-121.
[9]  J, MALDONADO S. Group-penalized feature selection and robust twin SVM classification via second-order cone programming[J]. Neurocomputing, 2017, 235(c): 112-121.
J, MALDONADO S. Group-penalized feature selection and robust twin SVM classification via second-order cone programming[J]. Neurocomputing, 2017, 235(c): 112-121.
[10] LEE W, JUN C H, LEE J S. Instance categorization by support vector machines to adjust weights in AdaBoost for imbalanced data classification[J]. Information Sciences, 2017, 381: 92-103.
[11] 王健, 刘长青, 肖宏. 热连轧精轧机组预设定和自适应研究[J]. 中南大学学报(自然科学版), 2012, 43(7): 2607-2612.
WANG Jian, LIU Changqing, XIAO Hong, Research on finishing setup and self-adaptive of hot strip mill[J]. Journal of Central South University (Science and Technology), 2012, 43(7): 2607-2612.
[12] 江彤, 唐明珠, 阳春华. 基于不确定性采样的自训练代价敏感支持向量机研究[J]. 中南大学学报(自然科学版), 2012, 43(2): 158-163.
JIANG Tong TANG Mingzhu YANG Chunhua. Self-training cost-sensitive support vector machine with uncertainty based on sampling[J]. Journal of Central South University (Science and Technology), 2012, 43(2): 158-163.
[13] FREUND Y, IYER R, SCHAPIRE R E, et al. An efficient boosting algorithm for combining preferences[J]. Journal of Machine Learning Research, 2003, 4(6): 933-969.
[14] DRUMMOND C, HOLTE R C. Explicitly representing expected cost: An alternative to ROC representation[C]//Proceedings of the sixth ACM SIGKDD international conference on knowledge discovery and data mining. New York, USA: ACM, 2000: 198-207.
(编辑 伍锦花)
收稿日期:2017-01-05;修回日期:2017-02-24
基金项目(Foundation item):国家自然科学基金资助项目(51204018);“十二五”国家科技支撑计划项目(2015BAF30B01);中央高校基本科研业务费专项资金资助项目(TW201711,FRF-TP-16-018A1)(Project (51204018) supported by the National Natural Science Foundation of China; Project (2015BAF30B01) supported by the National Science and Technology Pillar Program during the 12th “Five-year” Plan of China; Project (TW201711, FRF-TP-16-018A1) supported by the Fundamental Research Funds for the Central Universities)
通信作者:何飞,博士,副研究员,从事生产过程质量建模、模式识别、板带控制等的研究;E-mail:hefei@ustb.edu.cn

