DOI: 10.11817/j.issn.1672-7207.2015.06.017
基于色彩聚类的自然场景文本检测
吴慧1, 2,赵于前1, 2, 3,李香花4,邹北骥2,邹润民2
(1. 中南大学 地球科学与信息物理学院,湖南 长沙,410083;
2. 中南大学 信息科学与工程学院,湖南 长沙,410083;
3. 中南大学 有色金属成矿预测教育部重点实验室,湖南 长沙 410083;
4. 中南大学 土木工程学院,湖南 长沙,410075)
摘要:基于场景图像背景复杂,图像中的文本变化多样,提出一种基于色彩聚类的自然场景文本检测算法。其步骤为:首先,用K-均值聚类算法将彩色图像聚成5种色彩层,分析各色彩层中连通域外接矩形的几何特性,去掉离散的非文本连通域;然后,根据相邻连通域外接矩形的几何性质和空间位置关系,将离散的连通域连接形成候选文本块;最后,通过分析候选文本块的几何特性和边缘密度验证文本,得到最终文本检测结果。实验结果证明了本文算法的有效性和可行性。
关键词:场景文本检测;色彩聚类;文本验证
中图分类号:TP391.4 文献标志码:A 文章编号:1672-7207(2015)06-2098-06
Text detection from natural scene images based on color clustering
WU Hui1, 2, ZHAO Yuqian1, 2, 3, LI Xianghua4, ZOU Beiji2, ZOU Runmin2
(1. School of Geosciences and Info-Physics, Central South University, Changsha 410083, China;
2. School of Information Science and Engineering, Central South University, Changsha 410083, China;
3. Key Laboratory of Metallogenic Prediction of Nonferrous Metals, Ministry of Education,
Central South University, Changsha 410083, China;
4. School of Civil Engineering, Central South University, Changsha 410075, China)
Abstract: Considering that the natural scene images have complex background and the text in them is usually various, a text detection method based on color clustering was proposed. The procedures are as follows. Firstly, K-means was utilized to group pixels in color images into five different color layers and the bounding-boxes of connected-components in every color layer were obtained. Some non-text components were removed by analyzing geometrical properties of the bounding-boxes. Subsequently, the scattered components were connected to form candidate text blocks according to their bounding-boxes’ geometrical properties and locations. Finally, text verification was performed by geometrical and edge density identifications. The experimental results show that the proposed method is feasible and effective.
Key words: scene text detection; color clustering; text verification
随着数字图像获取设备的广泛应用,基于内容的图像分析技术得到人们越来越多的关注。这些图像分析技术的内容主要包括对图像中的人、场、景等方面进行分析,其中,对图像中文本的分析显得尤为重要。提取图像中的文本有利于对图像内容的理解和分析,可广泛应用于盲人视觉辅助[1]、地理编码、基于内容的图像检索等领域,因此,研究自然场景图像文本检测具有重要的意义。然而,自然场景图像通常比较复杂,图像中文本的表现形式也多种多样,这给场景文本检测带来了一定困难,为此,国内外学者提出了许多场景文本检测算法。
1) 基于边缘(梯度)的文本检测方法[2-6]。场景图像中的文本区域通常含有丰富的边缘信息,而背景区域较少,因此,可以利用边缘信息检测文本。这类方法通常利用边缘滤波器进行文本区域定位,并通过文本判定方法验证文本。当图像复杂、背景区域边缘信息丰富时,这种方法的文本检测效果不佳。Shivakumara等[2]提出了一种基于滤波器和边缘特征的文本检测方法。该方法将图像分为16块,对每个块应用不同的边缘滤波器,用得到的边缘信息确定文本边界。Wei等[3]提出了一种金字塔式的基于边缘信息的文本检测方法。该方法对原始图像进行插值运算,得到不同大小的图像,提取它们的梯度信息定位文本,并分别采用投影和分类方法精确研究边缘并验证文本。Neumann等[4]通过检测图像的最大稳定极值区域(maximally stable extremal regions,MSER),定位文本。Minetto等[5]通过对不同方向梯度直方图(histogram of oriented gradients, HOG)进行分析,提出了一种基于HOG纹理描述符的文本检测方法。Liu等[6]分别用4个不同方向的边缘探测器对图像进行滤波,并使用形态学方法定位文本,然后通过分析候选文本的边缘强度、边缘密度和边缘方向的变化来区分文本和非文本。
2) 基于纹理的方法[7-11]。图像中文本区域与背景区域有不同的纹理特征,根据这些特征可对图像分类,得到文本区域。提取纹理特征的方法有小波分解、Gabor滤波、快速傅里叶变换、离散余弦变换等。Zhao等[7]应用小波变换提取图像的纹理信息,并将图像分成多个小块,对每个块进行分类,得到候选文本块,然后运用平滑和投影法精确定位文本区域。Saoi等[8]对彩色图像的3种色彩通道分别进行二维小波变换,并使用K均值聚类提取文本像素点,合并3个通道上的文本像素点,得到最终文本区域。Zhou等[9]提出了一种多语言场景文本检测算法,该方法提取图像的梯度方向直方图、平均梯度值和局部二值模式(local binary pattern, LBP)作为特征,通过分类器得到文本区域。Pan等[10]根据梯度和边缘信息对图像进行滤波,并运用投影法定位文本,得到候选文本块。用训练好的分类器验证文本块,合并性质相似的候选块形成连通的文本区域。Angadi等[11]对图像进行离散余弦变换和高频滤波,以增强文本区域,并根据均一性和对比度验证文本区域。
3) 基于连通区域的方法[12-16]。这种方法是基于同一视频图像中的文本在颜色、大小、形状和空间排列等方面具有相似性,提取特征相似像素点组成连通区域,分析连通区域的几何特性组成文本块。该方法可检测不同方向排列的文本,但对颜色变化比较敏感,对背景复杂的图像检测效果不佳。Shivakumara等[12]提出了一种基于贝叶斯分类器和边缘生长的文本检测算法。该方法结合Laplace算子和Sobel算子增强图像,并使用贝叶斯分类器对像素点分类,得到候选文本字符。通过边缘生长的方法,将具有相似几何特征的候选字符形成连通块。Koo等[13]提出了一种新的场景文本检测算法,该算法2次应用分类器检测文本块。第1次应用相邻连通块的特征进行分类得到候选字符,第2次应用文本块和非文本块之间的不同特征进行分类得到最终检测结果。Yi等[14]提出了基于字符结构划分和分类的场景文本检测算法,该方法根据梯度和色彩信息提取字符,分析字符的几何特性,将特征相似的字符连接形成文本区。Le等[15]应用Mean-shift方法对图像进行聚类,分析每一类中连通区域的边缘特征,移除非文本块。Zhang等[16]使用两步条件随机场(conditional random field, CRF)对文本块和非文本块进行标记。首先使用CRF找到确定的文本块,然后对不确定的文本块再次应用CRF,得到最终检测结果。
本文作者基于连通区域的思想,提出一种基于色彩聚类的自然场景文本检测算法。首先提取图像的色彩特征进行K均值聚类,得到候选字符;然后分析候选字符外接矩形的几何性质,去掉离散的非文本连通域;接着分析相邻连通区域外接矩形的几何性质和空间位置关系,合并特征相似的连通域,得到候选文本区;最后对候选文本区进行验证,得到最终检测结果。
1 算法
1.1 色彩聚类
同一自然场景图像中的文本色彩相近,利用这种特性可定位文本。分别提取图像在R,G和B 3个通道上的色彩分量作为特征,用K-均值算法对图像上的像素点进行聚类。具体算法流程如下。
Step 1 从图像中任意选择K个像素点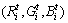 作为初始聚类中心(其中,
作为初始聚类中心(其中,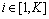 ,t表示迭代次数)。
,t表示迭代次数)。
Step 2 分别计算图像中每个像素点p与第i个聚类中心的色彩距离Di,并对该像素点所属类别进行划分:
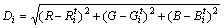 (1)
(1)
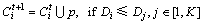 (2)
(2)
式中: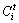 表示第t次迭代后第i类像素点的集合。
表示第t次迭代后第i类像素点的集合。
Step 3 计算每个类中像素点色彩的均值,作为新的聚类中心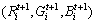 :
:
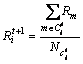 ,
,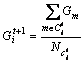 ,
,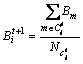 (3)
(3)
式中: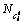 为第t次迭代后第i类中像素点的个数。
为第t次迭代后第i类中像素点的个数。
Step 4 重复Step2和Step 3,直到每个聚类中心色彩分量不再发生变化为止。
由于不同场景图像色彩的复杂程度不同,选择合适的聚类数目对文本检测的效果影响很大。为了确定聚类数目,本文对ICDAR2003数据库[17]中的训练集进行实验,分别得到不同聚类数的文本检测结果。当聚类数较小时,复杂图像中的文本无法与背景分离;当聚类数较大时,文本会出现过分割现象。综合考虑训练集中的图像,当聚类数为5时,得到的聚类结果最佳。
1.2 字符验证
K-均值聚类得到的5个色彩层都包含了文本和大量离散的非文本连通域。为了减小字符合并时的计算量,移除离散的背景信息,本文对每个色彩层的连通域进行字符验证。找到色彩层中每个连通域的最小外接矩形,分析外接矩形的几何性质。
连通区域外接矩形几何性质计算举例如图1所示,其中W和H分别表示外接矩形的宽和高。对ICDAR2003数据库训练集中的文本进行分析发现,文本外接矩形的几何性质通常满足一定条件,本文移除不满足下列条件的连通区域:1) W>8;2) H>10;3) 0.4<H/W<8;4) N>50(其中,N为连通区域内像素点的个数)。
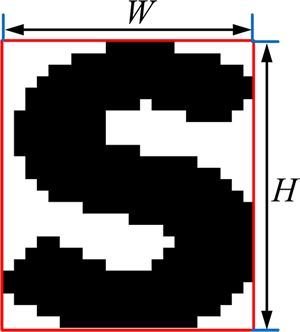
图1 连通区域外接矩形几何性质计算举例
Fig. 1 Example of geometrical properties computation on connected-component’s bounding-box
1.3 字符合并
字符验证后的色彩层,包含文本块和颜色相近的非文本块。为了将分散的文本字符连接形成连通的文本区域,提出基于几何特性和空间位置关系的字符合并算法。对于每一个连通域,找到其最大外接矩形,通过比较相邻连通域外接矩形的几何性质和空间位置关系,判断是否属于同一文本块。相邻连通域外接矩形几何性质和空间位置关系计算举例如图2所示。图2中:W1和W2分别为2个连通域外接矩形的宽,H1和H2分别为2个连通域外接矩形的高;V为两连通域在垂直方向上重合的长度。
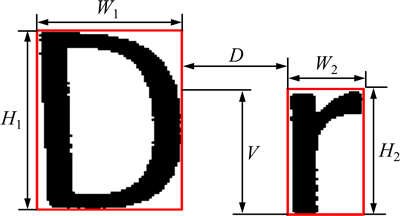
图2 相邻连通域外接矩形几何性质与空间位置关系计算举例
Fig. 2 Example of geometrical properties and spatial locations computation on neighboring connected-components’ bounding-boxes
一般来说,属于同一文本块的相邻2个字符,其外接矩形的几何性质相似,2个字符间的距离和垂直方向上重复的长度都在一定范围内变动。本文对相邻2个字符间的性质进行如下定义,其中RW,RH和RN分别表示相邻字符的宽度比、高度比和像素点的个数比,N1和N2分别表示2个字符包含像素点的个数:
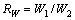 (4)
(4)
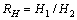 (5)
(5)
 (6)
(6)
本文将满足条件式(7)~(11)的2个相邻连通域连接形成1个文本候选块。
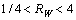 (7)
(7)
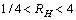 (8)
(8)
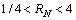 (9)
(9)
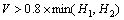 (10)
(10)
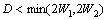 (11)
(11)
图3所示为字符合并过程。从图3可以看出:通过比较相邻连通区域的几何性质和空间位置关系,可将特性相似的离散字符合并形成文本块;遍历色彩层中的所有连通域,通过字符合并得到候选文本块,其中既包含了真实文本块,也包含了错误检测的非文本块。对于由字符合并形成的候选文本块,如图4(a)所示,黑色背景中包含的连通域数目大于1。本文假设只对包含字符数目大于1的文本块进行检测,去掉字符合并后连通域数目为1的候选文本块,如图4(b)所示,图中黑色背景中包含的目标连通区域为1。
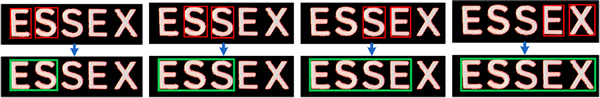
图3 字符合并过程举例
Fig. 3 Example of character grouping process

图4 候选文本块举例
Fig. 4 Examples of candidate text blocks
1.4 文本块验证
通过字符合并,且去掉连通域数目为1的候选文本块,得到文本块,同时产生因大量错误合并形成的非文本块,为了提高文本检测的正确率,需要对候选文本块进行验证。本文分别采用几何性质分析和边缘密度判断的方法对候选文本块进行验证。
1.4.1 几何性质分析
文本块的几何性质通常满足一定条件,因此,分析候选文本块的几何特性可以排除非文本块。分别计算第i个候选文本块的宽Wi、高Hi、比率Ri=Wi/Hi和文本块中连通域像素点之和Ni,将不满足以下条件的候选文本块判定为非文本块:
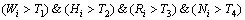 (12)
(12)
本文取T1,T2,T3和T4分别为20,20,1和100。对图5(a)所示字符合并结果图中候选文本块进行几何性质分析,所得结果如图5(b)所示,可见较明显的非文本块被去除。

图5 几何性质分析结果举例
Fig. 5 Examples of geometrical property analysis
1.4.2 边缘密度判断
从图5(b)可以看出:几何性质分析可以去除较明显的非文本块,但检测结果中仍然包含非文本块。为了进一步提高文本检测的准确率,本文通过边缘密度判断的方法去掉非文本块。边缘密度Ed定义如下:
Ed=BSobel/BArea (13)
其中:BSobel为候选文本块中包含的Sobel边缘像素点个数;BArea为候选文本块的面积。本文将真实文本块的判定条件设为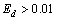 。
。
对图5(b)中的候选文本块进行边缘密度判断,所得结果如图6(a)所示。显然,大部分非文本块被移除。

图6 边缘密度判断结果举例
Fig. 6 Example of edge density identification result
2 实验结果与讨论
选取ICDAR2003数据库对算法进行验证。ICDAR2003数据库由509幅场景图像组成,其中,训练集258幅,测试集251幅。这些场景图像中包含不同大小、样式和颜色的水平方向排列的文本。将本文算法在测试集上试验,图7所示为随机选择的部分结果。从图7可以看出:由本文算法可以检测出不同场景图像中的文本。

图7 文本检测结果举例
Fig. 7 Examples of text detection results
为了进一步说明本文算法的有效性,将它与文献[4],[9],[15],[17]和[18]中的算法进行比较,并采用回召率Rr、正确率Pr和系数Fm作为比较变量,分别定义如下:
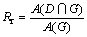 (14)
(14)
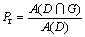 (15)
(15)
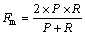 (16)
(16)
其中: 为两幅图像的交集,运算
为两幅图像的交集,运算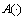 计算像素点的个数,因此,
计算像素点的个数,因此,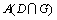 表示检测结果中属于真实文本区域的像素点个数;A(G)为真实文本区域中像素点的总数;A(D)为检测结果中像素点的总数。回召率Rr表示检测结果中正确检测的像素点个数与真实文本区域中像素点总数的比值,Rr越大,表明算法检测出的文本越多;正确率Pr表示检测结果中正确检测像素点个数与检测到的总像素点个数的比值,Pr越大,表明检测出的正确文本比例越大,算法效率越高;系数Fm综合衡量了算法的回召率和正确率,Fm越大,表明算法的总体效果越好。
表示检测结果中属于真实文本区域的像素点个数;A(G)为真实文本区域中像素点的总数;A(D)为检测结果中像素点的总数。回召率Rr表示检测结果中正确检测的像素点个数与真实文本区域中像素点总数的比值,Rr越大,表明算法检测出的文本越多;正确率Pr表示检测结果中正确检测像素点个数与检测到的总像素点个数的比值,Pr越大,表明检测出的正确文本比例越大,算法效率越高;系数Fm综合衡量了算法的回召率和正确率,Fm越大,表明算法的总体效果越好。
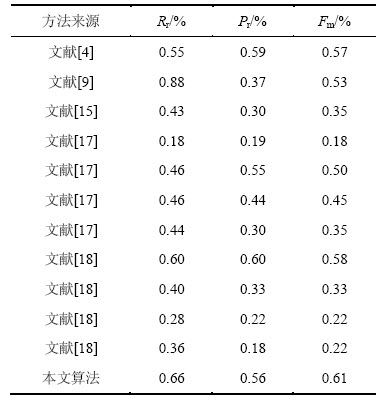
根据上述标准,不同算法的检测结果比较见表1。从表1可以看出:与其他算法相比,本文算法取得了较高的Rr,Pr和最高的Fm,分别为0.66,0.56和0.61。这说明本文算法能检测出较多的文本块,且检测结果中正确文本块的比例较高,综合检测性能最好。
表1 不同算法检测结果比较
Table 1 Comparison of detection results with different methods
3 结论
1) 提出了一种基于色彩聚类和字符合并的场景文本检测方法。首先对彩色图像进行K-均值聚类,得到5个不同的色彩层;然后对色彩层进行预处理,去除离散的非文本连通域,分析连通域外接矩形的几何性质和空间位置关系,合并满足条件的相邻连通域组成候选文本块;最后分析候选文本块的几何特性和边缘密度,移除非文本块,得到最终检测结果。
2) 本文算法能检测出不同场景图像的文本,并取得了较好的Rr,Pr和Fm,与其他场景文本检测算法的比较也表明了本文算法的优越性。
参考文献:
[1] YI Chucai, TIAN Yingli. Assistive text reading from complex background for blind persons[C]//The 4th International Conference on Camera-based Document Analysis and Recognition, Beijing, China, 2012: 15-28.
[2] Shivakumara P, Phan T Q, Tan C L. Video text detection based on filters and edge features[C]//IEEE International Conference on Multimedia and Expo. New York, USA, 2009: 514-517.
[3] WEI Yicheng, Lin Changhong. A robust video text detection approach using SVM[J]. Expert Systems with Applications, 2012, 39(12): 10832-10840.
[4] Neumann L, Matas J. A method for text localization and recognition in real-world images[C]//The 10th Asian Conference on Computer Vision. Queenstown, New Zealand, 2010: 770-783.
[5] Minetto R, Thome N, Cord M, et al. T-HOG: An effective gradient-based descriptor for single line text regions[J]. Pattern Recognition, 2013, 46(3): 1078-1090.
[6] LIU Xiaoqing, Samarabandu J. Multiscale edge-based text extraction from complex images[C]//IEEE International Conference on Multimedia and Expo. Toronto, Canada, 2006: 1721-1724.
[7] ZHAO Ming, LI Shutao, Kwok J. Text detection in images using sparse representation with discriminative dictionaries[J]. Image and Vision Computing, 2010, 28(12): 1590-1599.
[8] Saoi T, Goto H, Kobayashi H. Text detection in color scene images based on unsupervised clustering of multi-channel wavelet features[C]//IEEE International Conference on Document Analysis and Recognition. Seoul, Korea, 2005: 690-694.
[9] ZHOU Gang, LIU Yuehu, MENG Quan, et al. Detecting multilingual text in natural scene[C]//2011 1st International Symposium on Access Spaces. Yokohama, Japan, 2011: 116-120.
[10] PAN Yifeng, LIU Chenglin, HOU Xinwen. Fast scene text localization by learning-based filtering and verification[C]//IEEE International Conference on Image Processing. Hong Kong, China, 2010: 2269-2272.
[11] Angadi S A, Kodabagi M M. A texture based methodology for text region extraction from low resolution natural scene images[C]//IEEE 2nd International Advance Computing Conference. Patiala, India, 2010: 121-128.
[12] Shivakumara P, Phan T Q, Tan C L. A Laplacian approach to multi-oriented text detection in video[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(2): 412-419.
[13] Koo H I, Kim D H. Scene text detection via connected component clustering and nontext filtering[J]. IEEE Transactions on Image Processing, 2013, 22(6): 2296-2305.
[14] YI Chucai, TIAN Yingli. Text string detection from natural scenes by structure-based partition and grouping[J]. IEEE Transaction on Image Processing, 2011, 20(9): 2594-2605.
[15] Le H P, Toan N D, Park S, et al. Text localization in natural scene images by mean-shift clustering and parallel edge feature[C]//Proceedings of the 5th International Conference on Ubiquitous Information Management and Communication. Seoul, Korea, 2011:116.
[16] ZHANG Hongwei,LIU Changsong,YANG Cheng, et al. An improved scene text extraction method using conditional random field and optical character recognition[C]//IEEE International Conference on Document Analysis and Recognition. Beijing, China, 2011: 708-712.
[17] Lucas S M, Panaretos A, Sosa L, et al. ICDAR 2003 robust reading competitions[C]//IEEE International Conference on Document Analysis and Recognition. Edinburgh, UK, 2003: 682-687.
[18] Lucas S M. Text locating competition results[C]//IEEE International Conference on Document Analysis and Recognition. Seoul, Korea, 2005: 80-85.
(编辑 陈灿华)
收稿日期:2014-06-24;修回日期:2014-08-28
基金项目(Foundation item):国家自然科学基金资助项目(61172184, 61174210, 61379107, 61402539);新世纪优秀人才支持计划项目(NCET130603);高等学校博士学科点专项科研基金资助项目(20130162110016);湖南省科技基本建设项目(20131199);中南大学中央高校基本科研业务费专项资金资助项目(2015zzts052) (Projects (61172184, 61174210, 61379107, 61402539) supported by the National Natural Science Foundation of China;Project (NCET130603) supported by Program for New Century Excellent Talents in University;Project (20130162110016) supported by the Specialized Research Fund for the Doctoral Program of Higher Education;Project (20131199) supported by Science and Technology Basic Construction of Hunan Province; Project (2015zzts052) supported by the Fundamental Research Funds for the Central Universities of Central South University)
通信作者:李香花,博士,副教授,从事管理与决策支持、信号与信息处理等研究;E-mail:lpstonecsu@163.com

