J. Cent. South Univ. Technol. (2011) 18: 1121-1127
DOI: 10.1007/s11771-011-0812-5
A speech enhancement algorithm to reduce noise and compensate for partial masking effect
JEON Yu-yong1, LEE Sang-min2
1. Department of Electronic Engineering, Inha University, Incheon, 402-751, Korea;
2. Institute for Information and Electronics Research, Inha University, Incheon, 402-751, Korea
? Central South University Press and Springer-Verlag Berlin Heidelberg 2011
Abstract: To enhance the speech quality that is degraded by environmental noise, an algorithm was proposed to reduce the noise and reinforce the speech. The minima controlled recursive averaging (MCRA) algorithm was used to estimate the noise spectrum and the partial masking effect which is one of the psychoacoustic properties was introduced to reinforce speech. The performance evaluation was performed by comparing the PESQ (perceptual evaluation of speech quality) and segSNR (segmental signal to noise ratio) by the proposed algorithm with the conventional algorithm. As a result, average PESQ by the proposed algorithm was higher than the average PESQ by the conventional noise reduction algorithm and segSNR was higher as much as 3.2 dB in average than that of the noise reduction algorithm.
Key words: speech enhancement; noise reduction; psychoacoustic property; human hearing property
1 Introduction
One of the significant reasons why the quality of speech is degraded is environmental noise. To reduce the environmental noise, the noise spectrum estimation algorithm and noise reduction algorithm are important. In the one-microphone system, the minima controlled recursive averaging (MCRA) algorithm proposed by COHEN [1] is one of the algorithms that has been getting attention. The MCRA algorithm estimates the noise spectrum based on the smoothed input spectrum and ratio of the local minima of the input spectrum to current input spectrum. It is from the assumption that the speech spectrum fluctuates with time and the noise spectrum does not change dramatically. So, if the ratio is larger than the threshold, it is assumed that speech is present. LEE et al [2] tried to reduce the noise using MCRA and spectral subtraction, one of the most general noise reduction algorithms.
However, even after noise reduction, noise still remains and the speech spectrum is distorted. So, a lot of researches about speech reinforcement or residual noise reduction after noise reduction have been performed. LEE et al [2] proposed a formant enhancement algorithm after noise reduction using the MCRA and spectral subtraction. They used a single channel companding; spectral energies of frequencies near the formant are suppressed by broad bandwidth filter and spectral energy of the formant frequencies is enhanced by narrow bandwidth filter. For detecting the formants, they used the Hilbert envelope and LPC (linear prediction coding). And SHIN and KIM [3] proposed a speech reinforcement algorithm based on the partial masking effect. The partial masking effect is one of the most well-known psychoacoustic properties described by MOORE et al [4]. As in MOORE��s model, loudness of speech in the noisy environment is decreased by noise. SHIN controlled the loudness of speech in the noisy environment equal to the loudness in the quiet environment using the partial masking effect. However, he used the gain from only one condition; speech level reaching the cochlea referred to the excitation level is greatly larger than the excitation level of masked threshold by noise. In real situation, because the excitation level of speech is changed dramatically, gains based on various situations are required.
In this work, we proposed a speech enhancement algorithm consisting of the noise estimation algorithm MCRA and speech reinforcement algorithm based on partial masking in various situations. Also, the proposed algorithm was evaluated using the segmental signal-to- noise ratio (segSNR) [5] and the perceptual evaluation of speech quality (PESQ) [6].
2 Proposed speech enhancement algorithm
Figure 1 shows the block diagram of the proposed speech enhancement algorithm. The proposed speech enhancement algorithm consists of the noise estimation algorithm and speech reinforcement algorithm.

Fig.1 Block diagram of proposed speech enhancement algorithm
Input signal was analyzed by fast Fourier transform (FFT) and the noise spectrum D was estimated from spectrum of input signal Y by the noise estimation algorithm. In the speech reinforcement part, speech spectrum X was estimated and gain was calculated based on partial masking effect. And then calculated gain from speech reinforcement part was multiplied to estimated speech X, and reinforced speech spectrum was synthesized by inverse fast Fourier transform (IFFT).
2.1 Noise estimation
To estimate the noise spectrum, the MCRA algorithm was used. The block diagram of the algorithm is shown in Fig.2. In the spectral averaging step, local energy of input signal S was calculated by recursive averaging using the past local energy and input spectrum |Y(k, l)|2:
 (1)
(1)
where ��s is a constant for smoothing input spectrum, k is the frequency bin index, and l is the time frame index.

Fig.2 Block diagram of MCRA algorithm
The estimated noise spectrum D was obtained by averaging the past noise spectrum and local energy using the smoothing parameter ��d calculated by the signal presence probability p:
 (2)
(2)
 (3)
(3)
 (4)
(4)
where I is the speech presence indicator.
The speech presence indicator I was obtained from the ratio of the local energy S to its minimum value. If the ratio is larger than experimentally determined value 10, the value of I(k, l) is 1. If not, the value of I(k, l) is 0.
Local minimum value is updated in every frame and every window. In each frequency band, local minimum value is determined between input value and local minimum value in past frame (Eq.(5)). And temporal minimum value is determined by the same method (Eq.(6)). If the frame index is equal to window size L, local minimum value and temporal minimum value were updated by Eq.(7) and Eq.(8), respectively:
 (5)
(5)
 (6)
(6)
 (7)
(7)
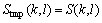 (8)
(8)
2.2 Speech reinforcement
Figure 3 shows the block diagram of the proposed speech reinforcement algorithm. Speech spectrum was estimated using estimated noise spectrum and input spectrum. Following the proposal of MARTIN [7], the speech spectrum |X(k, l)| was estimated with a subtraction factor f, a limitation of the maximum subtraction by a spectral floor constant subf (Eq.(9)). And subtraction factors for each frequency bin were smoothed by Eq.(4).
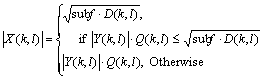 (9)
(9)
where


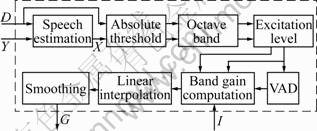
Fig.3 Block diagram of speech reinforcement algorithm
The absolute hearing threshold of normal people from the international organization for standardization (ISO) [8] was applied to the estimated speech spectrum to estimate the noise spectrum for applying the human hearing property. And the estimated speech and noise spectrum were divided into several octave bands. The excitation level of each sub-band was calculated by averaging the magnitude of frequency bin in each sub-band. Based on the excitation level of speech and noise, the gain for each sub-band was calculated. However, if the excitation level of speech is much smaller, the gain is calculated to be high. This means that estimated speech is amplified largely even if the speech is absent, and it becomes the noise and degrades the speech quality. To prevent this, voice activity detection (VAD) is used. If the excitation level of speech in the each sub-band is smaller than the threshold value of 5 dB, the band gain is determined as 1. Otherwise, if the excitation level of speech is larger than the threshold value and the sum of the speech presence indicator I in each frame is larger than the speech presence threshold ��, the band gain is calculated based on the partial masking effect described by MOORE [4]. Figure 4 shows the specific loudness as a function of signal excitation level. If the speech excitation level is fixed and the noise is present, the specific loudness is decreased as the noise is increased. The gain is to amplify the loudness of speech in the noisy environment equal to the loudness of speech in the quiet environment.

Fig.4 Specific loudness as function of signal excitation level
In the MOORE��s partial masking model, specific loudness of speech and noise was defined in several noisy conditions. For example, Eq.(10) is for specific loudness in quiet condition and Eq.(11) is for specific loudness of speech when the excitation level of speech is larger than hearing threshold of normal person in noisy condition and sum of excitation level of speech and noise is smaller than 1010:
 (10)
(10)



 (11)
(11)
The band gain lets the loudness of speech in noisy environment 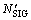 be the same as the loudness of speech in quiet environment
be the same as the loudness of speech in quiet environment  i.e.
i.e. 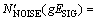
 is given by
is given by
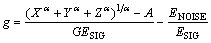 (12)
(12)
X=ESIGG+A
Y=[ENOISE(1+K)+ETHRQ]G+A
Z=ETHROG+A
where ESIG and ENOISE are the excitation levels of speech and noise, respectively; ETHRQ is the excitation level of speech when the speech level is on the absolute threshold; K, A, G and �� are the frequency dependent constants.
As above, the gain was calculated in four conditions: 1) ESIGTHRN and ESIG+ENOISE��1010, 2) ESIGTHRN and ESIG+ENOISE>1010, 3) ESIG��ETHRN and ESIG+ENOISE ��1010, and 4) ESIG ��ETHRN and ESIG+ENOISE> 1010.
ETHRN is the excitation level of speech in the masked threshold by noise.
Then, band gain was interpolated linearly for frequency bins and smoothed to prevent the dramatic change of gain.
3 Performance evaluations
3.1 Waveform and spectrogram
Figure 5 shows a waveform of three-times repeated sample speech /yak gook/ mean pharmacy in 30 types of speech for comparison of waveform and spectrogram.
Figure 6 shows the waveforms of noisy speech mixed white noise as 0dB SNR, noise reduced speech by MCRA and spectral subtraction, and enhanced speech by proposed algorithm. Figures 6(a1), (a2) and (a3) show the wavforms of noisy speech mixed with white, babble and car noise, respectively. Figures 6(b1), (b2), (b3) show the waveforms of noise reduced speech by MCRA and spectral subtraction. It is indicated that the noise is reduced definitely; however, speech component might be reduced simultaneously. Figures 6(c1), (c2), (c3) show the waveforms of enhanced speech by the proposed method. Although in babble noise environment, noise between speeches is increased by proposed method, it does not enough degrade the perceptual score. On the other side, noise is reduced successfully in white and car noise, and speech is enhanced more than MCRA and spectral subtraction algorithm.
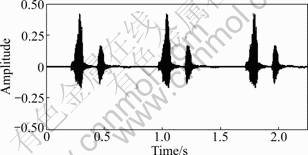
Fig.5 Waveform of sample speech/yuk gook/ mean pharmacy
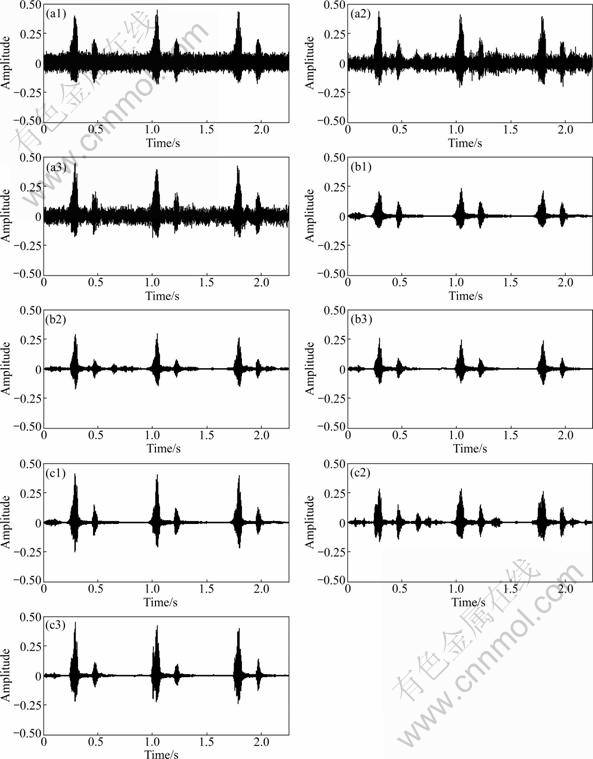
Fig.6 Waveforms of noisy speech (a), noise reduced speech (b) and enhanced speech by proposed method (c) with different noise conditions: (a1-c1) White noise; (a2-c2) Bobble noise; (a3-c3) Car noise
Figure 7 shows the spectrograms of original speech, noisy speech (white noise), noise reduced speech, and enhanced speech by the proposed algorithm. As shown in the spectrograms, the noise reduction algorithm and proposed algorithm can reduce noise; however, the high frequency components degraded by noise are enhanced by the proposed algorithm.

Fig.7 Spectrograms of original speech (a), noisy speech (b), noise reduced speech (d) and enhanced speech by proposed algorithm (d)
In waveforms after noise reduction or proposed algorithm, there are some components from start to about 200 ms. It is just an error occurred in estimating the noise spectrum. Because it is shown during about 200 ms, effect on perceptual score or SNR is not significant.
3.2 Objective measure
To evaluate the effectiveness of the proposed algorithm objectively, PESQ and segSNR were introduced. Thirty types of Korean two-syllable words used in hospital for speech test were used for the evaluation and three types of noise (white, car, babble) were mixed, respectively, to each speech by three types of SNR (-5, 0 and 5 dB). PESQ is one of the standards for automated assessment of the speech quality in telephony system and segSNR is a method for calculating the SNR by averaging the SNR of segment data as
 (14)
(14)
where L is the number of segments, and N is length of a segment.
Figure 8 shows the average PESQ and average segSNR of 30 types of speech between noisy speech (NS), noise reduced speech by the MCRA and spectral subtraction (NR), enhanced speech by previous method (without smoothing) (NR+CM) [9], and the proposed method with MCRA (NR+PM) in each noise environment.
Figures 8(a1), (b1) and (c1) show the average PESQ scores in each input SNR and each noise environment. In babble noise environment, differences of average PESQ score between NS and NR+PM are 0.07, 0.18, and 0.11 for -5, 0 and 5 dB SNR, respectively. They are smaller than the differences in white noise (0.11, 0.17, and 0.25) or car noise (0.2, 0.25, and 0.28) environment. This is because the property of babble noise is similar to that of speech and noise estimation algorithm defines babble noise as speech. However, average PESQ score by NR+PM is larger than PESQ score by other method. And the PESQ scores by the proposed method are higher than those of the conventional method and noise reduction using the MCRA and spectral subtraction algorithm and noisy speech.
Figures 8(a2), (b2), and (c2) show the average segSNR values in various noisy environment. In white noise and car noise environment, segSNR is increased by proposed algorithm definitely compared with that of noisy speech and noise reduced speech. In babble noise environment, segSNR is not increased compared with other algorithms by the error of the noise estimation algorithm. However, in every condition, the PESQ and the segSNR of the speech by the proposed method are higher than those of the conventional method and noise reduction using the MCRA and spectral subtraction algorithm and noisy speech.

Fig.8 Comparison of PESQ score (a1, b1, c1) and segSNR (a2, b2, c2) between noisy speech (NS), noise reduced speech (NR), reinforced speech by previous method (NR+CM) and proposed method (NR+PM) in each noise environment: (a1, a2) White noise; (b1, b2) Babble noise; (c1, c2) Car noise
4 Conclusions
1) An algorithm was proposed to reduce the noise and reinforce the speech. To estimate the noise, the MCRA algorithm for noise estimation and spectral subtraction rule for speech estimation are used and the speech is amplified based on the partial masking effect using the estimated speech spectrum and the noise spectrum for speech reinforcement.
2) To evaluate the efficiency of the proposed algorithm, the waveforms of original speech, noise reduced speech and enhanced speech by proposed algorithm were observed in various noise conditions and spectrograms. In waveforms and spectrograms, proposed algorithm reduces the noise and reinforces the speech successfully, furthermore reinforces the high frequency component of speech. And PESQ and the segSNR were also calculated. Although PESQ and segSNR are not increased dramatically, PESQ and segSNR by proposed algorithm are increased compared with those by conventional method, noise reduction only and noisy speech. This means that the proposed algorithm is effective in enhancing the speech quality.
References
[1] COHEN I. Noise estimation by minima controlled recursive averaging for robust speech enhancement [J]. IEEE Signal Processing Letter, 2002, 9(1): 12-15.
[2] LEE Young-woo, LEE Sang-min, JI Yoon-sang, LEE Jong-shill, CHEE Young-joon, HONG Sung-hwa, KIM S I, KIM In-young. An efficient speech enhancement algorithm for digital hearing aids based on modified spectral subtraction and companding [J]. IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, 2007, E90-A(8): 1628-1635.
[3] SHIN Jong-Won, KIM Nam-Soo. Perceptual reinforcement of speech signal based on partial specific loudness [J]. IEEE Signal Processing Letters, 2007, 14(11): 887-890.
[4] MOORE B C J, GLASBERG B R, BAER T. A model for the prediction of thresholds, loudness, and partial loudness [J]. J Audio Eng Soc, 1997, 45(4): 224-240.
[5] QUACKENBUSH S R. Objective Measures of Speech Quality [M]. Prentice-Hall, NJ, 1988.
[6] Beerends, John G., Hekstra, Andries P., Rix, Antony W., Hollier, Michael P. Perceptual evaluation of speech quality (PESQ) the new itu standard for end-to-end speech quality assessment. Part II: Psychoacoustic model [J]. J Audio Eng Society, 2002, 50(10): 765-778.
[7] MARTIN R. Spectral subtraction based on minimum statistics [C]// Proc 7th European Signal Processing Conf. EUSIPCO-94. Edinburgh, Scotland, 13�C16, 1994: 1182-1185.
[8] ISO 226 2003 Acoustics-Normal equal-loudness-level contours, International Organization for Standardization (ISO) [S]. 2nd ed. Geneva: ISO, 2003.
[9] JEON Yu-yong, LEE Sang-min. A speech enhancement algorithm based on human psychoacoustic property [J]. Transactions of The Korean Institute of Electrical Engineers (KIEE), 2010, 59(6): 1120-1125.
(Edited by YANG Bing)
Received date: 2011-01-25; Accepted date: 2011-03-23
Corresponding author: LEE Sang-min, Professor, PhD; Tel: +82-32-860-7420; E-mail: sanglee@inha.ac.kr

