Integrated search technique for parameter determination of SVM for speech recognition
��Դ�ڿ������ϴ�ѧѧ��(Ӣ�İ�)2016���6��
�������ߣ�Teena Mittal R. K. Sharma
����ҳ�룺1390 - 1398
Key words��support vector machine (SVM); predator prey optimization; speech recognition; mel-frequency cepstral coefficients; wavelet packets; Hooke-Jeeves method
Abstract: Support vector machine (SVM) has a good application prospect for speech recognition problems; still optimum parameter selection is a vital issue for it. To improve the learning ability of SVM, a method for searching the optimal parameters based on integration of predator prey optimization (PPO) and Hooke-Jeeves method has been proposed. In PPO technique, population consists of prey and predator particles. The prey particles search the optimum solution and predator always attacks the global best prey particle. The solution obtained by PPO is further improved by applying Hooke-Jeeves method. Proposed method is applied to recognize isolated words in a Hindi speech database and also to recognize words in a benchmark database TI-20 in clean and noisy environment. A recognition rate of 81.5% for Hindi database and 92.2% for TI-20 database has been achieved using proposed technique.
J. Cent. South Univ. (2016) 23: 1390-1398
DOI: 10.1007/s11771-016-3191-0
Teena Mittal1, R. K. Sharma2
1. Department of Electronics and Communication Engineering, Thapar University, Patiala 147004, Punjab, India;
2. Department of Computer Science and Engineering, Thapar University, Patiala 147004, Punjab, India
 Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Abstract: Support vector machine (SVM) has a good application prospect for speech recognition problems; still optimum parameter selection is a vital issue for it. To improve the learning ability of SVM, a method for searching the optimal parameters based on integration of predator prey optimization (PPO) and Hooke-Jeeves method has been proposed. In PPO technique, population consists of prey and predator particles. The prey particles search the optimum solution and predator always attacks the global best prey particle. The solution obtained by PPO is further improved by applying Hooke-Jeeves method. Proposed method is applied to recognize isolated words in a Hindi speech database and also to recognize words in a benchmark database TI-20 in clean and noisy environment. A recognition rate of 81.5% for Hindi database and 92.2% for TI-20 database has been achieved using proposed technique.
Key words: support vector machine (SVM); predator prey optimization; speech recognition; mel-frequency cepstral coefficients; wavelet packets; Hooke-Jeeves method
1 Introduction
Speech is one of the oldest and most natural ways of information exchange between human beings [1-2]. Speech recognition can be defined as the process of converting an acoustic signal to a set of words. Automatic speech recognition (ASR) is one of the fastest developing fields in the framework of speech science and engineering [2]. Feature extraction from the speech signal and recognition of speech based on these features are the two key steps in ASR. A number of features have been reported in the literature for speech recognition. The methods currently used to extract the features of a speech signal are Mel-frequency cepstral coefficients (MFCC) and wavelet based analysis. Mel-frequency cepstral coefficient is a short-time analysis scheme, in which a signature of the acoustic signal spectrum is computed from a filter-bank with central frequencies projected uniformly on the Mel scale [3]. Wavelet based features are used in various fields of signal processing for compression, detection and classification [4-9]. Various classification approaches for ASR have been reported in the literature, such as hidden markov model (HMM) [10], artificial neural network (ANN) [11], support vector machine (SVM). Ganapathiraju et al [12] have discussed the application of SVMs to large vocabulary speech recognition. Gangashetty et al [13] have proposed an SVM based recognition system for consonant-vowel utterances of speech in three Indian languages, namely, Tamil, Telegu and Hindi.
A well-known problem in SVM is to choose the specific parameters for a kernel, since it has a high impact on the classification accuracy. Inappropriate parameter settings lead to poor classification results [14]. To overcome these problems parameters of SVM (C and ��) should be optimized. Guo et al [15] have proposed a hyper-parameter selection method for least-squares SVM based on PSO technique. Lin et al [16] have developed PSO based approach for parameter determination of the SVM. Ilhan and Tezel [17] have developed a GA-SVM with parameter optimization. Huang and Dun [18] have combined the discrete PSO with the continuous-value PSO to optimize the SVMs kernel parameter settings. Vieira et al [19] have proposed a modified binary PSO method for optimization of SVM parameter setting. Li et al [20] have optimized SVM parameters by integration of PSO with simulated annealing algorithm. Li et al [21] have proposed modified PSO, by adopting the chaotic searching to improve the global searching performance of the PSO.The modified PSO is applied to optimize the key parameters of SVM. Wang et al [22] have presented modified SVM by combining principal component analysis (PCA) and PSO to the intrusion detection system to improve the detection rate. Huang and Wang [23] have presented a GA based approach to optimize the parameters of SVM for pattern classification. Bao et al [24] have optimized SVMs parameters optimization by applying memetic algorithm based on PSO and pattern search. HE et al [25] have developed a method for classifying electronic nose data in rats wound infection detection based on SVM and wavelet analysis. They have applied PSO-SVM classifier for pattern recognition. Wei et al [26] have presented a method based on SVM and PSO for face recognition.
Although some of the global search techniques are used to tune the SVM parameters, still these techniques have some drawbacks while searching the optimum solution. Omran et al [27] have discussed some of the deficiencies of GA and PSO. Sometimes, GA lacks the ability to produce better offspring and causes slow convergence near global optimum solution. Particle swarm optimization is one of the most promising global search techniques because it is easy to implement, fast convergence and global search ability. One of the main drawbacks of PSO is that solution may converge to local solution if its parameters have not set properly [27]. Another disadvantage is that when prey particles come close together during the search then it is difficult to avoid accumulation point. Because of that, PSO sometimes loses its global search ability. To overcome the deficiencies of PSO, many approaches are proposed in literature. One of the potential approaches is inclusion of predator with prey particles in swarm, proposed by Silva et al [28] as predator-prey optimization (PPO) model. The predator attracts towards global best prey particle and prey particles try to escape from predator that enhances the searching capability of PPO. The main motive of predator is to maintain the balance between exploration and exploitation capability of PPO technique and to avoid convergence at local solutions. Costa et al [29] have applied a PPO based approach to design a brushless dc wheel motor. Hydrothermal generation scheduling problem is solved by Narang et al [30] by applying PPO algorithm.
One of the main drawbacks of global search techniques is their inability to fine tune the solution. Martinez-Estudillo et al [31] have hybridized the evolutionary algorithm with local search technique by clustering method. Hamzacebi [32] has suggested that performance of genetic algorithm can be improved by hybridizing it with local search technique. A theoretical and empirical study of local, global and hybrid search technique is done by Harman and McMinn [33]. Finally, they have recommended that hybridization of local and global search technique may be most appropriate.
In this research work, SVM classifier is undertaken because it has few merits as compared to ANN and HMM. The ANNs have been successfully applied for ASR but it has few shortcomings, including, design of optimal model topologies, slow convergence during training, and a tendency to over fit the data [12]. Hidden Markov models have been the core technique for ASR during recent decades but it requires large training data to estimate probabilistic distribution [34]. When compared with HMM, SVM need smaller training data and produces higher accuracy in classification problem. Chen and Luo [35] have shown that SVM has good generalization ability as compared to HMM and ANN based classifier.
The intent of this work is to propose an integrated search technique to optimize SVM kernel parameters. During the initial search, random search technique PPO is implemented and after that local search technique Hooke-Jeeves method is explored to improve the search quality. The SVM with proposed technique is tested to recognize TI-20 database in clean and noisy conditions and Hindi speech database.
2 Feature extraction
A basic requirement of a speech recognition system is to extract some of the characteristics (features) in time/ frequency or in some other domain to identify a word. A feature can be defined as a minimal unit, which distinguishes maximally close word. Feature extraction module transforms the speech signal into a sequence of acoustic feature vectors. The features used in this work are MFCC, discrete wavelet transform, wavelet packet transform and wavelet based MFCC.
2.1 Mel frequency cepstral coefficients
Mel-frequency cepstral coefficients are standard spectral features widely used in speech recognition [4]. Mel frequency cepstral coefficients are obtained using the following steps:
1) In the first step, the Fourier transform of a windowed signal is taken.
2) Now, the log amplitudes of the spectrum obtained above are mapped onto the mel scale, using triangular overlapping windows.
3) In the next step, the discrete cosine transform of the list of mel log-amplitudes is taken and the amplitudes of the resulting spectrum are the desired MFCCs.
2.2 Wavelet based features
Wavelet transform is a powerful tool for feature extraction of speech signal. It has the advantage of using variable size time-windows for different frequency bands that results in a high frequency resolution in low bands and low frequency resolution in high bands. Wavelets are applied in the forms, such as the discrete wavelet transform (DWT) [7-8], and wavelet packets (WP) [5-6, 9].
The DWT can be viewed as the process of filtering the signal using a low pass filter and high pass filter. Thus, first level of DWT decomposition of a signal splits it into two bands giving a low pass version and a high pass version of the signal [4]. In speech signals, the low pass filtered signal gives the approximate coefficients h[n] of the signal while the high pass filtered signal gives the details coefficients g[n]. The second level of decomposition is performed on the low pass signal obtained from the first level of decomposition (as shown in Fig. 1). Thus, wavelet decomposition results in a binary tree like structure which is left recursive [7]. Figure 2(a) shows three levels of the decomposition of discrete wavelet transform.
Wavelet packets (WP) were proposed by Coifman et al [5] as a collection of bases with an underlying tree- structure. Wavelet packet analysis is an extension of the DWT, in which the whole time-frequency plane is subdivided into different time�Cfrequency pieces. Wavelet packet decomposition facilitates the partitioning of the higher frequency into smaller bands, which cannot be achieved by using discrete wavelet transform. Figure 2(b) shows the three levels of the decomposition of wavelet packet transform. The WP decomposes the approximate spaces as well as detail spaces.
3 Support vector machine
Support vector machine is one of the most popular and effective algorithms for pattern classification proposed by Vapnik [36]. Support vector machine is basically a binary classifier and its main aim is to find one hyperplane to separate the two classes of vectors so that the distance from the hyperplane to the closest vectors of both classes is maximized [37].
For a binary classification, the training dataset 
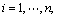 where the input space
where the input space  and
and 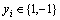 is the labels of the input space xi and n denotes the number of the data items in the training set. Support vector machine aim to generate an optimal hyper-plane to separate the two classes by minimizing the regularized training error
is the labels of the input space xi and n denotes the number of the data items in the training set. Support vector machine aim to generate an optimal hyper-plane to separate the two classes by minimizing the regularized training error
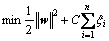
s.t. 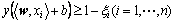
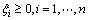 (1)
(1)
where 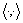 denotes the inner product; w is the weight vector, which controls the smoothness of the model; b is a bias parameter;
denotes the inner product; w is the weight vector, which controls the smoothness of the model; b is a bias parameter; 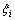 is slack variable which defines the permitted misclassification error In the regularized training error given by Eq. (1), the first term
is slack variable which defines the permitted misclassification error In the regularized training error given by Eq. (1), the first term 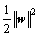 is the regularization term to be used as a measure of flatness or complexity of the function. The second term
is the regularization term to be used as a measure of flatness or complexity of the function. The second term 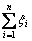 is the empirical risk. Hence, C is referred to as the penalty coefficient and it specifies the trade-off between the empirical risk and the regularization term.
is the empirical risk. Hence, C is referred to as the penalty coefficient and it specifies the trade-off between the empirical risk and the regularization term.
There are various types of kernels used with SVM but the radial basis function (RBF) is widely used and is given as
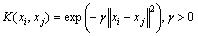 (2)
(2)
where 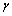 is kernel parameter
is kernel parameter
The kernel parameter should be carefully chosen as it implicitly defines the structure of the high dimensional feature space.
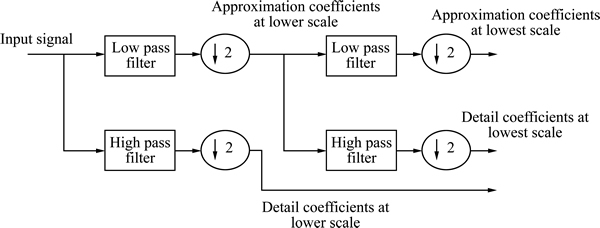
Fig. 1 Decomposition using discrete wavelet transform
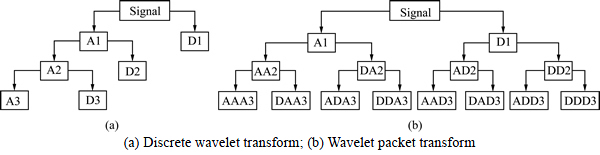
Fig. 2 Three-level decomposition:
SVM has been proposed for binary classification and it has been extended for the design of multiclass SVM classifiers. The two approaches commonly used are the one-against-one approach and one-against-all approach. The one-against-one approach is also known as pair wise classification. This method constructs 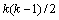 pair wise classifiers, where k is the number of classes. The classifying decisions are made aggregating the outputs of the pair wise classification. Other approach is the one-against-all approach, which trains k binary classifiers each of which separates one from the other (k-1) classes. In this work, one-against-all approach is used for classification task.
pair wise classifiers, where k is the number of classes. The classifying decisions are made aggregating the outputs of the pair wise classification. Other approach is the one-against-all approach, which trains k binary classifiers each of which separates one from the other (k-1) classes. In this work, one-against-all approach is used for classification task.
4 Predator prey optimization
Predator-prey optimization is a population based search technique which consist predator and prey particles into swarm. The nature of predator and prey particles is contradictory. The predator always chases the global best prey and preys are repelled from predator. The predator updates its velocity and position as
 (3)
(3)
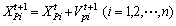 (4)
(4)
where 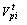 and
and  are predator velocity and position for ith dimension at tth iteration, respectively;
are predator velocity and position for ith dimension at tth iteration, respectively; 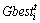 is global best prey position for the ith dimension at the tth iteration; C4 is a scaled random number.
is global best prey position for the ith dimension at the tth iteration; C4 is a scaled random number.
The interaction between predator and prey particles is controlled by maximum value of probability fear. The strength and frequency of interactions between predator and prey particles maintain the balance between exploration and exploitation capability of PPO.
The prey velocity and position are updated as
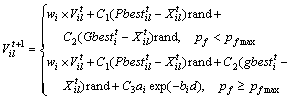 (5)
(5)
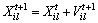 (6)
(6)
where wi is inertia weight and its varied from high to low value with iterations and it is given as
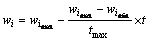 (7)
(7)
where 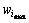 and
and 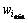 are the maximum and minimum values of inertia weight, respectively;
are the maximum and minimum values of inertia weight, respectively; 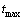 is maximum number of iterations;
is maximum number of iterations; 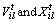 are prey velocity and position, respectively of lth particle for ith dimension at tth iteration;
are prey velocity and position, respectively of lth particle for ith dimension at tth iteration; 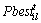 is local best prey position of lth particle for ith dimension at tth iteration; C1 and C2 are acceleration constant; PPO constant ai decides maximum amplitude of the predator effect over a prey; PPO constant bi controls the effect of predator over prey; C3 is a scaled random number; d is the Euclidean distance between predator and prey.
is local best prey position of lth particle for ith dimension at tth iteration; C1 and C2 are acceleration constant; PPO constant ai decides maximum amplitude of the predator effect over a prey; PPO constant bi controls the effect of predator over prey; C3 is a scaled random number; d is the Euclidean distance between predator and prey.
5 Hooke-Jeeves method
Hooke and Jeeves [38] have introduced direct search method for sequential examination of trail solution with its neighboring solutions to improve the quality of solution [38]. The biggest advantage of direct search method is that it does not require any information of derivative or approximation of derivatives of objective function and constraints. In Hooke-Jeeves method, search is performed in two moves. The first move is an exploratory move and second move is pattern move. Exploratory move is performed by perturbing the current point in all possible directions along each variable at a time. The exploratory move is a success if the updated point is different than original point. If the exploratory move is a success then pattern move is performed by acquiring the information from two successive best points. The pattern move is continued for better results. The whole process is repeated until some termination criteria are met. The stepwise procedure of Hooke-Jeeves method is given in algorithm 1.
Algorithm 1: Hooke - Jeeves method
1. Start with decision variable 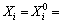
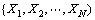
2. Set step length �� and ��
3. Set decision variable counter j=1 and pattern search counter k=0
4. Compute the objective function as
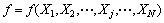
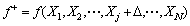

5. Compute the maximum value of objective function as 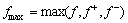
6. If 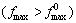 Then
Then
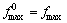
Compute the decision variable corresponding to 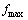 and assign it to
and assign it to 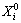
Een if
7. Increment the iteration counter as j=j+1
8. If 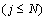 Then
Then
GOTO step 4
Eed if
9. If 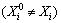 Then
Then
GOTO step 11
Eed if
10. If 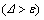 Then
Then
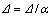
GOTO Step 3
Else
Stop
Eed if
11. Set 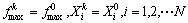
12. 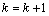
13. Compute the pattern search direction from two previous successive points as 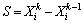
14. 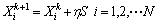
15. Compute 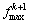
16. If 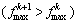 Then
Then
Goto step 12
Else
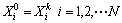

Goto step 10
Eed if
6 Development of proposed algorithm
In this research work, proposed technique based on integration of PPO and Hooke-Jeeves method is applied to optimize the SVM parameter, i.e. error penalty parameter C and kernel parameter �� of SVM. Optimization process is done in two phases. In first phase, PPO technique is applied for a fixed number of iterations. In second phase, local best positions obtained by PPO technique are further improved by applying Hooke-Jeeves method. The implementation of proposed technique is described in detail in following sub-sections.
6.1 Initialization of swarm
In global search technique, each particle in the population is a potential solution to the SVMs parameters. Predator-prey optimization technique has prey and predator particles. The role of predator particle is to influence the prey particle in effective manner so that prey can achieve best solution. The status of particles is characterized according to its position and velocity. In this work, the position and velocity of one particle have two dimensions that denote the two parameters (C and ��) to be optimized in SVMs.
The prey population is randomly initialized between upper and lower limits of decision variables. The position and velocity of prey are initialized as
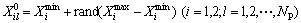 (8)
(8)
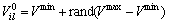 (9)
(9)
where NP is number of prey particles
Single predator position and velocity is randomly initialized within their respective limits as
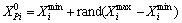 (10)
(10)
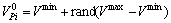 (11)
(11)
6.2 Objective function
The performance of a classifier is evaluated by its accuracy, which is defined as the ratio of total number of good classifications to the total number of available samples. Most of the classification problems have two classes, positive and negative [24]. Thus, the classified test points can be divided into four categories that are represented in the well known confusion matrix: true positives (TP), true negatives (TN), false positives (FP) and false negatives (FN). Given the four categories of the confusion matrix, the accuracy is defined as
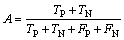 (12)
(12)
6.3 Proposed algorithm for speech recognition
The main aim of this research work is to improve the recognition rate of isolated Hindi words using SVM with RBF kernel. The performance of SVM is improved by searching the decision variables by applying proposed technique. The stepwise procedure to implement the proposed technique is elaborated in algorithm 2.
Algorithm 2: Proposed technique
Step 1: Randomly generate position and velocity of swarm within predefined limits as given by Eq. (8) to Eq. (11).
Step 2: Initialize the iteration counter for proposed technique as t=1.
Step 3: Train SVMs with prey positions.
Step 4: Compute the objective function as given by Eq. (12) of each individual prey in the population.
Step 5: Compare the Pbest of every prey particle with its current objective function value. If the current value is better, assign the current value to Pbest and assign the current prey particle location to the Pbest location.
Step 6:  apply Hooke-Jeeves method to improve Pbest location as given in algorithm-I. (Index TT is set to 10).
apply Hooke-Jeeves method to improve Pbest location as given in algorithm-I. (Index TT is set to 10).
Step 7: Update the Gbest prey position.
Step 8: Update the predator velocity and position using Eq. (3) and Eq. (4), respectively. If updated velocity and position violate the limits then set these to its corresponding limits.
Step 9: Update the prey velocity and position using Eq. (5) and Eq. (6), respectively. If updated velocity and position violate the limits then set these to its corresponding limits.
Step 10: t=t+1
Step 11: Go to step 3 until the algorithm is evaluated for a given maximum number of iterations.
7 Experimental details
In the present work, a speech recognition system is developed to recognize self recorded Hindi database and a benchmark speech database TI-20 (a sub-set of TI-46 database). For Hindi database, the speech samples of Hindi words are recorded and stored in .wav files. A database consisting of 20 words (listed in Table A.1) with 50 utterances for each word spoken by a single female speaker, a total of 1000 utterances has been created. This database was recorded at 44.1 kHz in room conditions. The TI-20 database is recognized under clean and noisy conditions. The TI-20 vocabulary consists of ten English digits ��zero�� through ��nine�� and ten control words ��yes, no, erase, rubout, repeat, go, enter, help, stop, and start��, spoken by eight male and eight female speakers. There are 26 utterances of each word from each speaker out of which 10 have been used for training and remaining 16 have been used for testing. So, TI-20 subset has a total of 3200 training samples and 5120 test samples. All the data samples were digitized with sampling frequency 12.5 kHz.
The experiments have been conducted by extracting MFCC, DWT, WP and WMFCC features for each utterance. Now, the SVM classification technique with RBF kernel is implemented for classification. One- versus-all approach is used to construct the SVM classifier. Parameter tuning of SVM classifier has been done by using proposed technique.
7.1 Experiments using MFCC features
After recording, the speech signal is passed through a first-order FIR high pass filter to spectrally flatten the signal. After this pre-emphasis, the silence region is removed from each utterance. Since the speech is non-stationary signal, so speech analysis must be performed on short segments, in which the signal is assumed to be quasi-stationary. Here, the speech signal is divided into a number of overlapping frames and a speech feature vector is computed to represent each of these frames. But with fixed-size frame, there is a problem of different number of frames due to different length of voice signal so; dynamic-size frames are to be used to obtain a fixed number of frames. The speech signal is divided into a fixed number of 40 frames each of 25 ms with 50% superposition. After framing, the Hamming window is used for windowing as it introduces the least amount of distortion. For each of the 40 frames, 13 MFCC features are extracted for all speech utterances.
7.2 Experiments using wavelet based features
Each speech sample has been decomposed into 7-level approximation and detail coefficients using DWT. Decompositions were carried out using the Daubechies wavelets as they have been reported to be highly successful in speech compression schemes using wavelets [9]. By computing the energy of the samples in the terminal branches, eight features are assigned to each speech signal.
For wavelet packet decomposition of the speech waveforms, the 7-level tree structure has been used. Wavelet packet decomposition has been applied to the speech signal using the Daubechies (db4) wavelet, thus obtaining 128 terminal nodes for each of input speech signal. By computing the energy of the samples in the terminal branches, 128 features are assigned to each speech signal. To get the benefits of both MFCC and wavelets, a hybrid feature extraction technique [5] is implemented. In this technique, first the signal is decomposed into sub-bands using the WPT. After seven-level WPT of the speech signal, it is given to the MFCC analysis block. Thirteen MFCC coefficients from each of the bands are extracted. The Daubechies 4 wavelet is used for the purpose of decomposition of the speech signal.
8 Results and discussion
Proposed technique is applied to get the maximum accuracy by using different feature extraction technique i.e. MFCC, DWT, WPT and WMFCC. The performance of proposed technique has been compared with the accuracy obtained with default parameters and optimized parameters by using PSO and PPO. To obtain the maximum speech recognition accuracy, it is necessary to set proper values of different parameters of proposed technique. A number of trials have been given to get different values of parameters. Detail tuning process is not presented because of space limitation. Table 2 represents the best parameters followed to achieve the solution.
Table 1 Vocabulary used for experiment
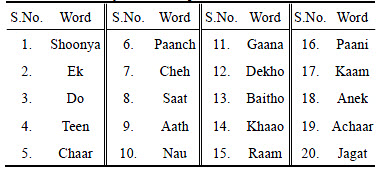
Table 2 Different values of best parameters of proposed technique

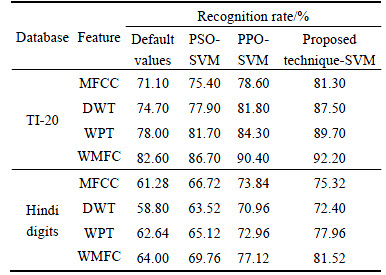
In any population based search technique, population size influences the results in terms of solution quality and simulation time. Too large or small value of population size may not be capable to get the highest accuracy. For each population size (number of prey and one predator) of 10, 15, 20, 25 and 30, 20 trials have been given. Out of these, population size of, 20 achieve best accuracy. Table 3 shows the comparison of speech recognition rate with default parameters of SVM and optimize parameters using PSO, PPO and the proposed technique. The experimental results indicate that proposed technique achieves highest speech recognition rate. It can be further noticed that the best results are obtained by optimized values of SVM using proposed technique with WMFCC features.
Table 3 Recognition rate using default and optimized values of RBF kernel
To assess the effect of noise on recognition accuracy, experiments have also been carried out on noisy test samples. In the experimental work, artificial white noise is added to samples of TI-20 database to get wide range of signal to noise ratio (SNR) (0, 10, 20, 30 and 40 dB). For different SNR, the recognition rates obtained by SVM with various techniques using WMFCC features are presented in Fig. 3. It can be observed from Fig. 3 that recognition rate decreases with increasing value of noise.
8.1 Statistical test
The statistical test on Hindi speech database is carried out to investigate the effect of initial solution on recognition rate. The PSO, PPO and proposed technique with SVM are executed thirty times individually and the best, average and worst recognition rate is computed and compared in Table 4. It is concluded that the best, average and worst recognition rate achieved by SVM with proposed technique outperforms the recognition rate achieved by SVM with PSO and PPO.
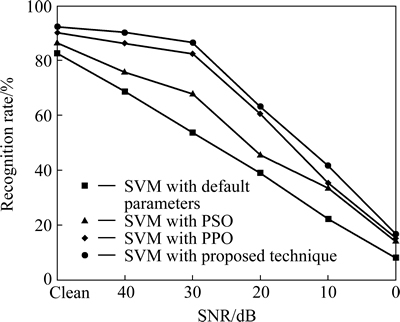
Fig. 3 Recognition rate obtained with different techniques under noisy conditions
Table 4 best, average and worst values of recognition rate (%) for Hindi speech database

8.2 Sensitivity analysis
The sensitivity analysis is also performed to investigate the effect of proposed technique parameters on recognition accuracy. The recognition accuracy is computed for Hindi speech database by applying SVM with proposed technique using WMFCC features. The parameters of proposed technique are perturbed ��10% of the set parameters. The recognition rate achieved with perturbed parameters is given in Table 5. The maximum variation from best recognition rate obtained by proposed technique has been observed as 0.960%, 0.997% and 1.064% for best, average and worst results, respectively. So, from obtained results, it is concluded that proposed technique is very less sensitive to parameters variation.
Table 5 Obtained results with perturbed parameter for Hindi speech database using WMFCC features

9 Conclusions
parameters of SVM are optimized by applying proposed technique to improve learning ability of SVM for recognition of small vocabulary Hindi words database as well as a benchmark TI-20 database. The acoustic features of speech signal in terms of MFCC, DWT, WPT and WMFCC are extracted and recognition rate is computed. The performance of proposed technique with SVM has been compared with default parameters of SVM and parameters optimized with PSO and PPO. In the experiments conducted in this research work, a recognition rate of 92.2% for TI-20 database under clean environment has been achieved. For the Hindi database, a recognition rate of 81.5% has been achieved using SVM with proposed technique. The effect of noise on speech recognition rate has also been analyzed by artificially adding white noise of different SNRs into the test samples of TI-20 database. In order to check the robustness of the proposed technique, a statistical test has also been performed and it has been found that best, average and worst case results achieved by proposed technique outperform their counterparts. A parameter sensitivity analysis has also been done in this work and it is concluded that the parameters of proposed technique are very less sensitive to variations.
References
[1] PEACOCKE R D, GRAF D H. An introduction to speech and speaker recognition [J]. Computer, 1990, 23(8): 26-33.
[2] RABINER L R, JUANG B H. Fundamentals of Speech Recognition [M]. Piscataway, N J, USA: Pearson Education, 1993.
[3] DAVIS S V, MERMELSTEIN P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences [J]. IEEE Transactions on Acoustics, Speech and Signal Processing, 1980, 28(4): 357-366.
[4] MALLAT S. A theory for multi resolution signal decomposition: The wavelet representation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1989, 11(7): 674-693.
[5] COIFMAN R, MEYER Y, QUAKE S, WICKERHAUSER V. Signal processing and compression with wavelet packets [R]. Numerical Algorithms Research Group. New Haven, CT: Yale University, 1990.
[6] AVCI E, AKPOLAT Z H. Speech recognition using a wavelet packet adaptive network based fuzzy inference system [J]. Expert Systems with Applications, 2006, 31(3): 495-503.
[7] NEHE N, HOLAMBE R. DWT and LPC based feature extraction methods for isolated word recognition [J]. EURASIP Journal on Audio, Speech, and Music Processing, 2012, 2012: 1-7.
[8] PATIL S, DIXIT M. Speaker independent speech recognition for diseased patients using wavelet [J]. Journal of Institution of Engineers (India): Series B, 2012, 93(1): 63-66.
[9] WU J D, LIN B F. Speaker identification using discrete wavelet packet transform technique with irregular decomposition [J]. Expert Systems with Applications, 2009, 36(2): 3136-3143.
[10] JUANG B H, RABINER L R. Hidden markov models for speech recognition [J]. Technometrics, 1991, 33(3): 251-272.
[11] WU J, CHAN C. Isolated word recognition by neural network models with cross-correlation coefficients for speech dynamics [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1993, 15(11): 1174-1185.
[12] GANAPATHIRAJU A, HAMAKER J E, PICONE J. Applications of support vector machines to speech recognition [J]. IEEE Transactions on Signal Processing, 2004, 52(8): 2348-2355.
[13] GANGASHETTY S V, CHANDRASEKHAR C, YEGNANARAYANA B. Acoustic model combination for recognition of speech in multiple languages using support vector machines [C]// IEEE Int Conference on Neural Networks. Budapest, 2004: 3065-3069.
[14] ZHAO Ming-yuan, FU Chong, Ji Lu-ping, Tang Ke, Zhou Ming-tian. Feature selection and parameter optimization for support vector machines: A new approach based on genetic algorithm with feature chromosomes [J]. Expert Systems with Applications, 2011, 38(5): 5197-5204.
[15] GUO X C, YANG J H, WU C G, WANG C Y, LIANG Y C. A novel LS-SVMs hyper-parameter selection based on particle swarm optimization [J]. Neurocomputing, 2008, 71(16/18): 3211-3215.
[16] LIN Shih-wei, YING Kuo-ching, CHEN Shih-chieh, LEE Zne-jung. Particle swarm optimization for parameter determination and feature selection of support vector machines [J]. Expert Systems with Applications, 2008, 35(4): 1817-1824.
[17] ILHAN I, TEZEL G. A genetic algorithm�Csupport vector machine method with parameter optimization for selecting the tag SNPs [J]. Journal of Biomedical Informatics, 2013, 46(2): 328-340.
[18] HUANG Cheng-lung, DUN Jian-fan. A distributed PSO�CSVM hybrid system with feature selection and parameter optimization [J]. Applied Soft Computing, 2008, 8(4): 1381-1391.
[19] VIEIRA S M, MENDONCA L F, FARINHAA G J, SOUSA J M C. Modified binary PSO for feature selection using SVM applied to mortality prediction of septic patients [J]. Applied Soft Computing, 2013, 13(8): 3494-3504.
[20] LI Xiang, YANG Shang-dong, QI Jian-xun. A new support vector machine optimized by improved particle swarm optimization and its application [J]. Journal of Central South University of Technology, 2006, 13(5): 567-571.
[21] LI Yan-bin, ZHANG Ning, LI Cun-bin. Support vector machine forecasting method improved by chaotic particle swarm optimization and its application [J]. Journal of Central South University of Technology, 2009, 16: 478-481.
[22] WANG Hui, ZHANG Gui-ling, MINGJIE E, SUN Na. A novel intrusion detection method based on improved SVM by combining PCA and PSO [J]. Wuhan University Journal of Natural Sciences, 2011, 16(5): 409-413.
[23] HUANG Cheng-Lung, WANG Chieh-Jen. A GA-based feature selection and parameters optimization for support vector machines [J]. Expert Systems with Applications, 2006, 31(2): 231-240.
[24] BAO Yu-kun, HU Zhong-yi, XIONG Tao. A PSO and pattern search based memetic algorithm for SVMs parameters optimization [J]. Neurocomputing, 2013, 117: 98-106.
[25] HE Qing-hua, YAN Jia, SHEN Yue, BI Yu-tian, YE Guang-han, TIAN Feng-chun, WANG Zheng-guo. Classification of electronic nose data in wound infection detection based on PSO-SVM combined with wavelet transform [J]. Intelligent Automation & Soft Computing, 2012, 18(7): 967-979.
[26] WEI Jin, ZHANG Jian-qi, XIANG Zhang. Face recognition method based on support vector machine and particle swarm optimization [J]. Expert Systems with Applications, 2011, 38(4): 4390-4393.
[27] OMRAN M G H, ENGELBRECHT A P, SALMAN A. Bare bones differential evolution [J]. European Journal of Operational Research, 2009, 196(1):128-139.
[28] SILVA A, ANA N, ERNESTO C. An empirical comparison of particle swarm and predator prey optimization [C]// Irish Int Conference on Artificial Intelligence and Cognitive Science. Limerick, Ireland: AICS, 2002: 103-110.
[29] COSTA E, SILVA A, COELHO L D S, LEBENSZTAJN L. Multiobjective biogeography-based optimization based on predator-prey approach [J]. IEEE Transactions on Magnetics, 2012, 48(2): 951-954.
[30] NARANG N, DHILLON J S, KOTHARI D P. Multi-objective short-term hydrothermal generation scheduling using predator-prey optimization [J]. Electric Power Components and Systems, 2012, 40(15): 1708-1730.
[31] MARTINEZ-ESTUDILLO A C, HERVAS-MARTINEZ C, MARTINEZ-ESTUDILLO F J, GARCIA-PEDRAJAS N. Hybridization of evolutionary algorithms and local search by means of clustering method [J]. IEEE Transactions on Systems, Man, and Cybernatics-Part B: Cybernatics, 2006, 36(3): 534-545.
[32] HAMZACEBI C. Improving genetic algorithms�� performance by local search for continuous function optimization [J]. Applied Mathematics and Computation, 2008, 196(1): 309-317.
[33] HARMAN M, MCMINN P. A theoretical and empirical study of search based testing: local, global and hybrid search [J]. IEEE Transactions on Software Engineering, 2010, 36(2): 226-247.
[34] SOLERA-URENA R, MARTIN-IGLESIAS D, GALLARDO- ANTOLIN A, PELAEZ-MORENO C, DIAZ-DE-MARIA F. Robust ASR using support vector machines [J]. Speech Communication, 2007, 49(3): 253-267.
[35] CHEN Shi-huang, LUO Yu-ren. Speaker verification using MFCC and support vector machine [C]// Proceedings of the International Multi Conference of Engineers and Computer Scientists. Hong Kong: IMECS, 2009: 532-535.
[36] VAPNIK V N. The nature of statistical learning theory [M]. New York: Springer, 1995.
[37] BURGES C J C. A tutorial on support vector machines for pattern recognition [J]. Data Mining and Knowledge Discovery, 1998, 2(2): 121-167.
[38] RAO S S. Engineering optimization: theory and practice [M]. 3rd ed. New York: John Wiely & Sons, 1996.
(Edited by DENG L��-xiang)
Received date: 2015-04-17; Accepted date: 2015-06-22
Corresponding author: Teena Mittal; Tel: +91-9876576364; E-mail: tnarang28@gmail.com

