����Ԫ������ģʽ��ʱ�������ھ�
���±�1, 2��LI Song-nian2���콨��1���½�Ⱥ1
(1.���ϴ�ѧ �����ѧ����Ϣ����ѧԺ������ ��ɳ��410083��
2. ���ɭ��ѧ ��ľ����ϵ�����ô� ���࣬M5B 2K3)
ժ Ҫ��Ϊ�˴Ӵ�����ʱ�����ݼ����ھ������ڡ����͡��͡������͡��ġ���Ԫ����������ģʽ�����ȣ����Ҫ��ͬ���ϵͬ�ʣ��������Ԫ������ģʽ�ĸ����������𡱺͡���Ҫ�ء��µġ�����Ĺ�����ϣ���Σ��á�ͼ�ۡ��ķ������������ġ����͡��͡������͡��ȡ���Ԫ������ģʽ���ٴΣ��������Ԫ������ģʽ���ھ��㷨�����롰�ȼ��ࡱ�������Ԫ������ģʽ���ϳ�ʵ��(���й滮)˵������Ԫ������ģʽ��ʱ�������ھ�ģʽ�����ھ��㷨���п����ԡ�
�ؼ��ʣ�����Ԫ������ģʽ��Ҫ�ع������ȼ���
��ͼ����ţ�TP301 ���ױ�־�룺A ���±�ţ�1672-7207(2011)01-0106-09
Mining multivariate association patterns from spatiotemporal data
CHEN Xin-bao1, 2, LI Song-nian2, ZHU Jian-jun1, CHEN Jian-qun1
(1. School of Geosciences and Info-physics, Central South University, Changsha 410083, China;
2. Department of Civil Engineering, Ryerson University, Toronto, M5B 2K3 Canada)
Abstract: To mine multivariate association patterns (MVAP), such as ��star-like�� and ��sequence�� multivariate association patterns, from large spatiotemporal datasets, a combination of multi-class-features (MCF) and multi-association-rules (MAR) was proposed according to entity types and relationships. The MVAP was then established based on the methods of graph theory. A new MVAP algorithm was presented by introducing ��Equivalence Classes�� to quickly identify MVAP. By use of an example in urban planning used to explain the MVAP process for spatiotemporal data mining, the results show that the MVAP and their algorithm have applicability.
Key words: multivariate association patterns; feature association rules; equivalence classes
�ռ����ݹ����ھ�Ϊ���ڿռ������֪ʶ��ȡ�ṩ��;�����ڽ�ͨ[1]������[2-3]��������ȫ[4]������[5]���˿��ղ�[6]�������й㷺����;��������ʮ��ķ�չ��������Կռ����ݹ���ģʽ�ھ���о�[2, 7-14]��ȡ��һЩ�ɹ����Կռ�����ھ���о���Ҫ�����������棺һ���棬������ֵ�͵ĵ���Ҫ�ص�����(Region)���������ھ�����Ҫ�صġ��㡱�����ߡ��͡��桱״��ֵת��Ϊ���ԡ����𡱻����͡��������ڲο������ڵġ�����Ƶ�����������ʺϻ���λ�õĿռ��������ͣ���դ������[15]������ֵ�ĵ���Ҫ�ء�Mennis��[9]�ù������������ܺõ�ڹ����������Ҫ��(��ᾭ��ָ��)����Ȼ����Ҫ��(���ظ���ֵ)��������ƣ����ڹ��������У������ڡ����ռ�ά�Ĺ����ھ�Lee��[4, 16]����ˡ��㡱�����ߡ��͡��桱�ȿռ��ά�Ĺ����ھ�����������Ƕ������㡱�͡��ߡ�����ֵת��Ϊ������ֵ����Ȼ���ڡ����Ļ����Ͻ��з�����ͬ����Ding��[17]����˻��ڡ��������ھ�Ŀ�ܣ������롰����������Ŀռ�Ӱ���(Scoping)����һ���棬������ɢ�Ͷ����������ռ����ݼ��еġ����ס���������ʱ�����ס��Ķ�������ǿռ��������Ҳ�ɶ����Ĺ�ϵ��Yang��[10, 18]���ڿռ����ľ����ϵ̽���ˡ�����(star)������������(sequence)���͡�������(clique)���ȹ���ģʽ��Lee ��[19]��ԡ�trajectory������ģʽ������̽�֡���������Щ���ʽ���������ڿռ�����ϵ�϶��ϵ�һ������ͬ���ͬ�ʡ�Huang��[20]�Ѿ���չ�����ӿռ����(�����ߺͶ��������)���������յ�������㡱�������ھ����ھ��㷨��Agrawal��[21]���������������ģ�ͣ�����������㷨AIS���ھ�˿ͽ������ݿ������Ĺ����������⡣�˺�����о���Ա�Թ���������ھ��㷨�������о���������SETM��Apriori���㷨�����У�Apriori�Ѿ���Ϊ��������ģ���еľ����㷨����������о�[12, 22-25]�Ը��㷨�����˸Ľ���������ǻ�������Ƶ��˼��ĵ����㷨������Ƶ����(k�C1)����ɺ�ѡ��Ƶ��k-��������ݿ�ɨ���ģʽƥ������ѡ����֧�ֶȺ����Ŷȣ�Apriori�㷨Ҫ����������ڷ��������ڵ�ά�����㡢�������������ǣ������ռ����ģʽ���ھ��㷨�����������⣺һ���ھ�Դ��Ҫ�����ڿռ����ݿ⣬��ȱ������ʱ���ʱ���������ھ���̵Ĵ��ڣ����ǿռ����ά�Ⱦ����ڵ�ά����(X��Y)����Ҫ��X��YΪͬ����Ҫ�أ�����Ե㡢�߶��ߺ������ȣ��ռ���������ϵ�һ��Ҫ��ͬ�ʣ���X��Y������ܾ����ڿռ����˹��Ի�ϵĿռ���������о����٣���Ϊ�ھ��㷨��Ե������ʺ϶�������ʽģʽ���ɴˣ��������߶Կռ����ģʽ�ھ�����˽�һ��������(1) �ھ�Դ�ӿռ����ݿ���չ��ʱ�����ݿ⣬�ھ�Ķ���Ҳ�ӿռ�������չ��ʱ�����ݣ����Ӵ�����ʷ�����ռ�Ҫ�����ھ�ij��ʱ�չ���ģʽ��(2) �ռ���������Կռ��ϵ��ʱ̬��ϵΪ�����ռ�����Ķ�����չ������Ҫ�أ���Ҫ�ء������͡������������(3) ��ͼ�۹����ͱ����硰���͡��͡������͡��ȶ�����Ҫ���µĶ����Ĺ������ģʽ��������Ԫ������ģʽ��(4) ̽�֡���Ԫ������ģʽ�µ��ھ��㷨��
1 ��������
�ռ�������ģʽ������ͼ1��ʾ���봫ͳ�ռ�������ģʽ��ͬ������Ԫ������ģʽ�����������ԣ�(1) �ھ������չ������Ҫ�أ��ɴ������ӵĿռ����(���ߺ���ȸŻ��ĵ���Ҫ��)��(2) ����Ҫ�ؼ�Ķ��ֿռ��ϵ(����롢��������˵�)ͬʱ���ڣ�(3) Ҫ�ؼ������ʱ̬��ϵ��(4) Ҫ�ؼ���ܴ���ij��������Ҫ��(��GDP)����������Ҫ�ص�Լ����ϵ����ʱ��ģʽ���ڡ������͡��͡����ϵ���µĶ��Ҫ�ع�ͬ����Ĺ�����ϣ����������ͳ��Ϊ����Ԫ������ģʽ�����Դ���ģʽ���ھ�ͷ��ֳ�֮Ϊ����Ԫ������ģʽ��ʱ�������ھ��ڴ���˵�����������漰���ھ����Ҫ�ض�Դ��������ɢҪ�ؼ�����Ȼ������Ԫ���ĸ���ɸ���Ϊ��Ҫ���ж���ҳ������Ͷ�����(���������͡�)�Լ�Ҫ�ؼ��ϵ���ʶ�����(���������)���־͡���Ԫ������ģʽ�������ھ���һЩ�������������������趨�����ʽ��������
���� 1 ����Ҫ�ء�����Ҫ��(Geographic feature, GF)��ָ�����ռ��о���ȷ����λ�ú���̬�������е��������ʵ�壬������ʵ����ĵ���ʵ���ڼ�����еı������Ҫ��������ͬ������Ҫ�ؿɷֳɶ�������(FeatureType)����㡢�ߡ����ʵ��ȼ���Ҫ�ء�����Ҫ�صĹ��ܲ�ͬ������Ҫ����ɷֳɶ������ͣ�����й滮�еĵ�·(Road)�����ݵȣ�����·��ϸ�ֳɸ���·����·�ȣ����ݿɻ���Ϊ��ס����ҵ�ȡ���F={f1, f2, ��, fr}Ϊ����Ҫ����ϡ�

ͼ1 �ռ�������ģʽ����
Fig.1 Type of association patterns
�涨1 ��ʱ�����ݿ�D={1, obj2����>, ��, objN}�����������1, obj2����, objm>��fiΪ����Ҫ�����fi��m������ʵ��(Instance)���¼(Record)��ÿ��ʵ�������Լ��ɱ�ʾΪ��fIdΪfi����Ҫ�����͵ı�ʶ����ʵ������ʱ̬�ԣ���ʱ����������Ϊ����sTimeΪ��ʼʱ��(ts)��durationΪ���ڳ���ʱ��td��
����2 Ҫ�ع�������Ҫ�ع�������(Feature association rule, FAR)�Ƿ�ӳ����Ҫ�ؼ��ϵ(��ṹ)һЩ�������������������Ҫ���ڿռ��ʱ���ϵ���Ϸ�ʽ���������������ע�ռ����ݣ�ǿ��Ҫ����ʱ��Ϳռ��ϵ�λ�ò��֣���ʱ�䡢�������������Ҫ�ع��������������������ȡ�����������
�涨2 ��Ҫ�ع���������RL������ÿ������������La�е�Ҫ��fi��fj����ʵ��RL(Fp)�����У�

 (1)
(1)
���У�isTempָҪ��fi��fj���ʱ̬��ϵ��isDistָҪ��fi��fj��ľ����ϵ��isOrienָҪ��fi��fj��ķ�λ��ϵ��isTopoָҪ��fi��fj������˹�ϵ��������wij=RL(fi,fj) ����RL(fi,fj)������������ᴩij���еĸɵ�fi��2000��˳��ͨ�������ij������fj��2005�꿢�������ߴ��ڿռ��ཻ��ʱ���Ⱥ��ϵ�����ǣ��ɱ���ɣ�wij=RL(fi,fj)={before, far-away, NO, intersect}������Ӧ��������ʶ��[13]��ʽ{101, 200, 300, 415}��
4�ֹ�����ϵ�����������¡�
(1) ʱ̬��ϵ����ʱ���Ⱥ�ȣ�ʱ̬ν��������isTemp(operator1)�����У�operator1Ϊʱ̬���ӣ���before(ǰ)/after(��)/equal(���)/start(��ʼ)/meet(���)/overlap(���)�ȡ�
(2) �ռ䶨��GIS��λν��������isOrien (operator2)�����У�operator2Ϊ��λ���ӣ���east-of(��)/west-of(��)/ south-of(��)/north-of(��)�ȡ�
(3) �ռ���룬����ν������ΪisDist (operator3)�����У�operator3Ϊ�������ӣ���DisConstant(���볣��)��CloseTo (�ӽ���ϵ)��Far-away (Զ���ϵ)���Լ�������ʾ���������distance����distance(x, y)��DisConstant����x��y�ľ����ϵΪCloseTo������ΪFar-away��
(4) ���˹�ϵ����GIS����ν��������isTopo (operator4)�����У�operator4Ϊ�������ӣ���disjoint(���)/intersect(�ཻ)/contain(����)�ȡ�
���� 3 ����Ԫ������ģʽ�ھ���Ԫ������ģʽ���������͵ĵ���Ҫ�غͶ����ʵĹ�������ͬʱ���ڣ���ô�ھ�Ԫ������ģʽ�ھ�Ĺ��̾��ǶԶ��ֹ������ʽ�ķ��֡�����ֻ�漰ʱ�����ݹ����ھ���ʱ������Դ��������ɢ����Ҫ�ؼ�����ʱ��ʱ�չ����ھ���̵���ʽ������Ϊ��
 ,
,
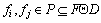 (2)
(2)
ʽ�У�Find(P, F, D)���Ƕ�n����������RL�������� (n��2)�Ĺ�����ϣ��Ӷ��γɹ�������Pģʽ��
�涨 3 �봫ͳ���������ھ�һ��������֧�ֶ�(Support)���͡����Ŷ�(Confidence)��ȷ��Ϊ����һ��Ҫ�ع���������Ҫ�Ե�2���ؼ���ָ�ꡣ�ڹ��������ھ��У����ڵ���Ҫ��ȱ�������ס�����ڴ���Ҫ�ؼ����ij��ʱ�ա���ϵ��������һ�֡����ס�������ʱ�����ݿ��еĶ�γ��������Ƶ��(Frequency)�����ԡ���F={f1, f2, ��, fr}Ϊr������Ҫ�����ÿ����������������ȵĵ�������R={r1, r2, ��, rn}Ϊn��Ҫ�ع�����ϵ�������Ͳ�ͬ��2��Ҫ�ؼ�(X��Y)��ij�ֹ���������P�䡰֧�ֶ�(sup)���͡����Ŷ�(conf)���������£�
 (3)
(3)
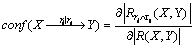 (4)
(4)
���У�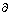 Ϊ����ϵ���������ӡ�ʽ(3)���֧�ֶȱ�����ij�ռ��ʱ���ϵ���ȶȣ�ʽ(4)������ij�ռ��ϵ��ijʱ̬��ϵ�ϵ�ǿ�ȡ�Ҫ�ع�ϵ��������X��Y(S��%��C��%)������֧�ֶ�(S��%)�����Ŷ�(C��%)����1��ʾΪ֧�ֶȺ����Ŷȵļ�����̡�
Ϊ����ϵ���������ӡ�ʽ(3)���֧�ֶȱ�����ij�ռ��ʱ���ϵ���ȶȣ�ʽ(4)������ij�ռ��ϵ��ijʱ̬��ϵ�ϵ�ǿ�ȡ�Ҫ�ع�ϵ��������X��Y(S��%��C��%)������֧�ֶ�(S��%)�����Ŷ�(C��%)����1��ʾΪ֧�ֶȺ����Ŷȵļ�����̡�
�涨4 ���������ͬ�ԡ�����Ժ����������ԡ����������е����ˡ���λ�;���ȹ�ϵͬʱ���ڣ�����Щ��ϵ������ʱ̬�С����ǵ���Ҫ���ڱ������ǵ�ͬ�ġ�����Щ������ϵ���ڲ���ԣ��ռ��ϵ��ʱ̬��ϵΪ��������ͬһ����𣻸��ݿռ������Զ�����ȣ����뼶��������ˣ�������ͷ�λ��ε�ͬ������⡰�������ԣ����㼶�Ĺ�ϵ����Ϊ�Ӳ㼶֮�͡����ھ��㷨�У�������ϵ������Ϊ�����ס�����ÿ�֡���ϵ�������ֵĴ��������Ÿá���ϵ���ġ�Ƶ��������ʱ���á�Ƶ�������ܳ��֡����������ԡ������ߡ�Ƶ������ʾ�á���ϵ�� ���������֡����������ԶԹ���ģʽ���ھ�dz���Ҫ��Ӱ�������ˡ�������ȹ�ϵ��ȡ�ᡣij��ռ��ϵ��Ƶ������ʱ̬��ϵ��Ƶ��������ϣ������γ�ij��ʱ�չ���ģʽ���緽λ�Ҿ����ϵ��������(�������λ�ò��ֺ�Ҫ�ؼ��ڽ�)��ʱ̬��������(����ϵ��ijʱ��εĴ���ӿ�֣����������֮Ϊ��ʱ̬�ۼ���)���γɡ����͡�ģʽ���ռ����˵��ڽ���ϵ(��ʱ����Ϊ�ߡ�Ƶ����)��ʱ���ϵ��Ⱥ����(�ֱ����Ÿߡ�Ƶ����)���γɡ����С�ģʽ��ij�����͵���Ҫ�صĹ���������������ⲽ�裺
(1) if sup(X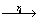 Y)��min_sup, then�ÿռ��ϵri����������otherwise������������
Y)��min_sup, then�ÿռ��ϵri����������otherwise������������
(2) if conf(X Y)��min_conf, then��ri��ʱ̬��ϵrt����������otherwise������������
Y)��min_conf, then��ri��ʱ̬��ϵrt����������otherwise������������
(3) if ri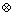 rt, ��������, then RL(ri
rt, ��������, then RL(ri rt)=����������otherwise�����������
rt)=����������otherwise�����������
��1 ��Ҫ��X��Y����ϵ����������ġ�֧�ֶȡ��͡����Ŷȡ�������
Table 1 Calculations of support and confidence degree for FAR of ��X��Y ��

2 �����͡��͡������͡�����ģʽ�
����Ԫ������ģʽ�ھ���ģʽ�Ĵ�ǹؼ�������ֻ����2�ֳ����Ĺ���ģʽ���ֱ�Ϊ�����͡��͡������͡���ͼ1(c)��(d)��ʾ�ֱ�Ϊ��2��ģʽ�ڡ��ռ����������͡�����Ҫ�ء���Ԫ������������ͬ�ı��﷽ʽ���ڡ���Ԫ������ģʽ�У�Ҫ�ؼ�Ĺ�ϵ���Ա���������ͼ(��ͼ��)���ڵ�(Node)��Ӧ��Ҫ������fi��F����(Edge)��ʾ�ڵ�(Ҫ�ؼ�)�Ĺ����ԣ���(Edge)�Ĵ�ϸ��ʾ�ڵ�(Ҫ�ؼ�)�Ĺ����ȶ�ǿ������ͷ(Arrow)�ɱ���Ҫ�ؼ��ʱ̬��ϵ����fi��fj��ʾfi����fj�����߷���(Grid)����ȷ��Ҫ�صĿռ䷽λ(�綫���������ҵ�)�����⣬ͼ1(c)��ʾ�ڵ�(Node)�Ķ���ΧȦ����ʾ��ͬʱ��ε�Ҫ��״̬(����״����С��)������ɫ�������עҪ�ز�ͬ�IJ���ʱ��ȡ�
2.1 ����(Star-like MVAP)
����ģʽΪҪ�ع�������ģʽ��һ��������Ҳ����ʵ�нϳ�����һ������Ҫ����1�������ġ�Ҫ�أ�������Ҫ�ؼ����ٴ���ij�ֹ�����ϵ��������Ҫ�ؼ䲻һ��Ҫ��������ڴˣ�����Ҫ�ؿɳ�֮Ϊ������Ҫ�ء��������͡�ģʽ������ΪPc:{f1, ��, fk}>����ʱ��˳����fc��fl��fc��f2������fc��fk��fc��fl��fc��f2������fc��fk�������͡�ģʽ������ϸ˵����ͼ2��ʾ��
(1) a,b,c,gΪʱ��Ҫ�ص�ʵ������á����͡�ģʽ��ʵ���ɱ�ʾΪ������ͼҪ����ɫ��䲻ͬ����ʾҪ�س��ֵ�ʱ���Ⱥ�˳��ͬ��
(2) ��Ҫ�س��ֵ��Ⱥ�˳����2����ʽ��һ�� �����ġ�Ҫ�س��ֺ�������Ҫ�س��֣���ʱ��Լ��Ϊ(g.ts��a.ts)��(g.ts��b.ts)��(g.ts��c.ts)���������Ҫ����̳��ֺ����ġ�Ҫ�زų��֣���ʱ��Լ��Ϊ(g.ts��a.ts)��(g.ts��b.ts)��(g.ts��c.ts)��
(3) �����ġ�Ҫ�غ͡�����Ҫ�ء�����һ���Ŀռ��ϵ(���������˵�)��

ͼ2 �����͡�ģʽʵ��
Fig.2 An example of ��start-like�� pattern
2.2 ������(Sequence MVAP)
����ģʽΪʱ������ģʽ(Flow patterns)�ĵ���ʵ����Ҫ�ظ���Ϊk������ģʽ�ɱ���ΪP= i:i��[1,k]>��Ҫ��Ҫ�����������ٴ���ʱ��Ϳռ����ڵ�2�ֹ�����ϵ�������С�ģʽ������ΪP1,f2,��,fk>���������͡�ģʽ����˵����ͼ3��ʾ(���У�fjΪ��Ҫ��(�繫·))��
(1) a,b,c,dΪʱ��Ҫ�ص�ʵ�����á����С�ģʽ��ʵ���ɱ�ʾΪ��< a,b,c,d>��Ҫ����ɫ��䲻ͬ����ʾҪ�س����Ⱥ�˳��ͬ��
(2) �ռ����Ҫ���ڽ��������˹�ϵҪ�����롱��CloseTo(fi,,fi+1)��Disjoint(fi,,fi+1)��
(3) ʱ̬Ҫ�����������ʱ��ǰ���ϵ����,fi+1��fi����֣�after(fi,,fi+1)��

ͼ3 �����С�ģʽʵ��
Fig.3 An example of ��sequence-like�� pattern
3 �ھ��㷨
�ԡ����͡��͡������͡��Ĺ���ģʽ����ʱ�������ھ��㷨̽�֡������пռ�����ھ�Apriori�㷨�Ļ����ϣ��ɵ�����ͬ��˫Ҫ���ھ���չ���������µĶ��Ҫ�صĶ�������ʽ��ģʽ�ھ�Ϊ�˷�����ٴ����Ԫ����Ϲ���ģʽ�����롰�ȼ��ࡱ[26]��
3.1 ���ȼ��ࡱ����
����4 �ȼ���[10, 18] (Equivalence classes)��
��fi��fjΪ2�����ϣ���pk=(fi, fj)ΪƵ��k-MVAP����fiΪ(k-1)-MVAPsģʽ�����pkΪk�ȼ��࣬��ΪEk(fi, fj)�����У�EkΪk-�ȼ��༯��Ek fi��Ek fj�ֱ�ΪEk��ǰ�ͺ�Ҫ�أ���Ek(fi,*)Ϊǰ��ͬ��k-�ȼ��༯, Ek(*, fj)Ϊ����ͬ��k-�ȼ��༯����Ek��ǰfi���fjҪ��һ�µĵȼ�����m����������Ӧ��m��k-MVAPsģʽ�ɺϲ���(k+m-1)-MVAPsģʽ��
�ȼ��������һ�������������ͬһ�ȼ����е�Ҫ��������ٴ����Ԫ��ʱ�չ���ģʽ����һ����ɽ���Ƶ�����������ȣ��������ھ��������k�ȼ���涨������2�����ԣ�(1) ��Ϊk��ʱ�չ���ģʽ����Ϊk-MVAPs��(2) ��ǰk-1Ҫ�ؼ���Ϊk-1��ʱ�չ���ģʽ����Ϊ(k-1)-MVAPs��
3.2 �ھ��㷨ʵ��
(1) ɨ��ʱ�����ݿ�1�Σ��������ר��Ҫ�ظ���N(Fi)������ʱ����������N(Fi)�dz��ɸ�����������Ȥ��Ҫ�ػ�Ҫ�ؼ��𣬼�����Ҫ��Ȩ��w(Fi)���ȼ�������ɨ�裬ȥ������Ҫ�����岻���Ҫ�أ�����һ�µı�����w(Fi)��N(Fi)/��N(Fi)��wminSup (Ȩ��֧�ֶ�)����p1i(Fi)Ϊ1-MVAPƵ��ģʽ��P1={p11, p12, ��, p1i}Ϊһ��Ƶ������
(2) ����ʱ��ν�����Ӻ�ʱ�չ�ϵ��λ�������ԭ����ʱ̬����(operator1)����λ����(operator2)����������(operator3)����������(operator4)����һ��Ƶ����(P1)����ɨ�裬����¼�������µĹ�ϵ����������Ҫ��p2i(fi, fj)�������������(1) ��ʱ��������|fit-fjt|��t���ռ��������distance(fj-fi)��d����N(p1i)/ ��N(p1i)��minSup����p2i(fi,fj)Ϊ2-MVAPs�����͡�Ƶ��ģʽ��P2={p21, p22, ��, p2i}Ϊ�����͡�����Ƶ������(2) ��ʱ��������fjt-fit��t(i��j��t��0)���ռ��������distance(fj-fi)��d����N(p1i)/��N(p1i)��minSup����p2i(fi,fj)Ϊ2-MVAPs�����С�Ƶ��ģʽ��P2={p21, p22, ��, p2i}Ϊ�����С�����Ƶ������
(3) �ڶ���Ƶ����(P2)�Ļ����ϣ�����2-�ȼ��࣬����Ҫ��p2i(fi,fj)ΪƵ��2-MVAPsģʽ����fi, fi��P1����p2i(fi,fj)ҲΪ2-�ȼ��࣬��ΪE2(fi, fj)�����У�E2Ϊ2-�ȼ��༯��E2.fi, E2.fj�ֱ�ΪE2��ǰ�ͺ�Ҫ�أ�����E2(fi,*)Ϊǰ��ͬ��Ϊ2-�ȼ��༯��E2(*, fj)Ϊ����ͬ��Ϊ2-�ȼ��༯�����磺p21=(f1, f2)(���У�f1Ϊ1-MVAPƵ��ģʽ)����p21Ϊ2-�ȼ��࣬��ΪE2(f1, f2)����E2(f1,*)Ϊǰ��ͬ��Ϊ2-�ȼ��༯��
(4) ��2-�ȼ��༯(E2)�У�������صȼ��࣬�ֱ�����Ҫ�Ķ�Ԫ����ģʽ����E2��ǰfi���fjҪ��һ�µĵȼ�����m����������Ӧ��m��2-MVAPģʽ�ɺϲ�������(m+1)-MVAP�����͡�ģʽ����E2�ĺ�fjҪ�غ�ǰfi��ͬ������m�������ĵȼ��࣬������Ӧ��m��2-MVAPģʽ�ɺϲ�������(m+1)-MVAP�������͡�ģʽ�����磺
���ڡ����͡�����ģ��
 3-MVAPs
3-MVAPs
���ڡ����С�����ģ��
 3-MVAPs
3-MVAPs
�����㷨ʵ�����£�
 //Algorithm�㷨: MVAPs-Mining
//Algorithm�㷨: MVAPs-Mining
//Ŀ��: ��ʱ������Դ�У��ھ�����ơ����͡��͡����С���ʱ�չ���ģʽ
 Input: Spatiotemporal Database D;
Input: Spatiotemporal Database D;
Spatial Distance threshold R;
Time spanning threshold W;
Minimum Support minSup;
Output: A set of frequent ��Start-like�� St;
A set of frequent ��Sequence�� Se;
1. Scan database D and classified into n thematic layers, formed Fi (if necessary);
2. P1��Gen1-MVAPs(minSup); //Generalize 1-MVAPs;
3. ��(fi��D)��(P1�٦�)
4. FOR Each feature fi��P1 AND i����N(Fi) DO
5. i+=1; // GenRelation-ST(fi,fi+1,R,W,Type): The Solving process of Spatiotemporal relationships
6. St_ P2i��GenRelation-ST(fi,fi+1,R,W,St); //Generalize Candidate with ��Star-like�� pattern;
7. Se_ P2i��GenRelation-ST(fi,fi+1,R,W,Se); //Generalize Candidate 2-MVAPs with ��Sequence�� pattern;
8. St_P2��St_ P2i; Se_P2��Se_ P2i; P2��{St_P2, Se_P2}; // 2-MVAPs
9. END FOR
10. FOR Each relationships Rj��P2 AND j��i DO
11. IF (Rj.fleft��P1) and (Rj.fright��P1) THEN //construct the Equivalence classes
12. k+=1; E2(k)={ Rj.fleft, Rj.fright }; E2��E2(k); //E2 sets
13. END IF
14. END FOR
15. FOR Each class E2(m)��E2 AND m��k DO //fix up those ��star-like�� and ��sequence�� patterns
16. n=p=q=0; St_temp(0)= Se_temp(0)= E2(m);
17. FOR n��k-m DO
17. n+=1;
18. IF (E2(m).fleft)=(E2(m+n).fleft) THEN //the ��star- like�� pattern
19. St_temp (p+1)��{E2(m+n).fright}; END IF
20. IF (E2(m).fright)=(E2(m+n).fleft) THEN //the ��sequence�� pattern
21. Se_temp(q)= E2(m); Se_temp(q+1)��{Se_temp(q)}�� {E2(m+n).fright}; END IF
22. END FOR
23. St��St_temp(p); Se��Se_temp(q);
24. END FOR
4 �ϳ�ʵ����֤-���й滮
���л��ǹ�������ᾭ�÷�չ�����е�ʱ���ݱ���̡����л��ռ�������л��ռ�����ǽ�ʾ���л����̵�2����Ҫ����[13]�����Գ��пռ�滮������о��У������Ƿ��ֳ��и��ռ�Ҫ�ؼ�����������ķ����ͼ������������dz��й滮�о����ȵ��ǰ���Կ��⡣����ʱ�չ���ģʽ���о�������������пռ��λ�úͽṹ����ģʽ�Լ���ʾ���л����̵��ݱ䣬��������������и�����Ҫ�صĿռ�Ч�ú���[27]�����л������е�Ҫ�ط��ϡ�������ɢ�ĵ���Ҫ�ؼ������ԣ����úϳ�ʵ��(���й滮)ڹ�͡���Ԫ������ģʽ��ʱ�������ھ���̣���֤ģʽ�����ھ��㷨�Ŀ����ԡ��ڴˣ�������ģʽ�ӹ滮ʱ�����ݼ��Ĺ�����ģʽ�ھ���������̣��������ھ��㷨��Ч�ʵ����⡣
4.1 �滮Ҫ�ؼ�
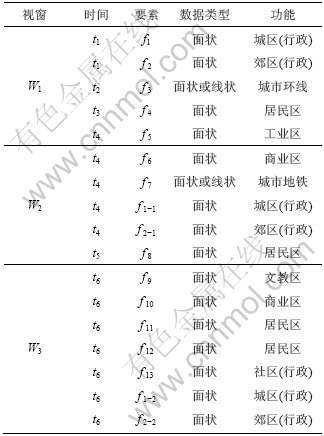
��ʵ�ĵ����滮Ҫ�����ڼ�����е��Ա������ʵ�����ݵĴ洢����������Ҫ�������ݼ����滮Ҫ�ؾ���ʱ��Ϳռ����ԣ���(�ռ�)���ݿⷽʽ�洢�������γ���ν��ʱ�յ���Ҫ�ؼ����滮Ҫ��ʱ�����ݼ����÷���D��ʾ��ʱ�����ݼ�����ʱ�����ԡ���ʱ�����ݼ�D����n������Ҫ��fi�����Էֲ���r�����ݼ��С������ݼ���Ӧ��ʱ�����(Snapshot)ͼ�������ͼ�ɱ�ʾ��:W={W1,W2,��,Wr}�����У�Wi�ǰ�ʱ������W1��W2������Wr�������ݼ���Ӧ��ר��(Thematic maps)ͼ����ר��ͼ�ɱ�ʾ�ɣ�M={m1,m2,��,mr}(���У�mi�ɰ��������ͻ��֣�m1|m2|��|mm��������ά��ʱ�չ����ھ�)�������߶����ڣ������Ȱ�Ҫ�����ͷ��࣬�ٰ�ʱ��������n��Ҫ�ش���q��MVAPs����ģʽ����Ӧ��P={p1,p2,��,pq}��ʱ�����ݼ��ļ�¼�ʹ洢��ʽ����ͼ4�ͱ�2��ʾ��

ͼ4 ʱ������ʵ������ͼ��ʾ
Fig.4 View of spatiotemporal database example
��2 ʱ�����ݵļ�¼�ʹ洢����
Table 2 Records and storage of spatiotemporal data
4.2 �滮Ҫ�ع���ģʽ�ھ����
�ڹ滮�����У��滮Ҫ��Ȩ�ص�ȷ����Ҫ�ص����ÿռ䷶Χ��ʱ��ЧӦ�йء�ʱ�չ���ģʽ���ھ����(�����������̺��㷨)���3~5��ʾ������������˵�����£�
(1) ���ȸ���Ҫ��ר�����ԣ��Թ滮Ҫ�ؽ��з��࣬�ڲ���ʱ��������3��
(2) �����ھ�����������������Ȥ��Ҫ�ز㣬������N(Fi)/��N(Fi)��wminSup������4��
��3 Ҫ�ط���
Table 3 Classification of features

��4 �������ĸ���Ȥ��Ҫ�ز�
Table 4 Interested feature layer

��5 ʱ��Ҫ�ع�����������
Table 5 Indexed matrix of S-T association features

(3) ����ʱ��Ҫ�ع�������������5�����У��������롰Ҫ��Ȩ�ء���
(4) �����ȼ��࣬����Ҫ���Ԫ����ģʽ�����Ƶ�����
�ԡ����͡���
f3��f5��f3��f6 => f3 :{ f5, f6}
f7��f8��f7��f9��f7��f10 =>f7 :{ f8, f9, f10}
�ԡ������͡���
(f3��f7) ��f8��f9��f10��f11
4.3 ���������
�ڱ����˳��ж��������������Ľ�ͨ����Դ�ͻ���Σ�����֮��������п�ʼ��������з�չ����Calthorp�����Ĺ�������չ(TOD)��������ͬ�����¶��������ڳ��й滮�����ʵ��ģʽ֮һ[28]����һģʽ���ų��й滮Ӧ���ý��գ��Թ�����ͨ��Ϊ�������е�֧��ϵͳ���Թ�����ͨ(�����ͨ������ϵͳ)�ڵ���Ϊ���й滮��չ�Ļ�����Χ���Ź�����ͨվ�㲼�ó��з�����ʩ(��ס����ҵ����ҵ��������)��TODģʽ��ͼ4��ʾ��ʱ����ͼ�еõ��ܺõ�ڹ�͡�
�����ͳ��л�·�dz��л���չ�dz���Ҫ�����档�����ͻ�·�Ľ��������������γɷdz���Ҫ�Ĺ�����ͨվ�㣬�������������Ļ�����ʩ�½����������ھ��f3:{f5; f6}��f3:{f8; f9; f10}�ȡ����͡�ģʽ�����Թ滮Ҫ�ضԾ���GDP��Ӱ�죬��TODģʽ��ϡ����͡��͡������͡�ģʽ���Խ�һ��̽�֣�(1) ���н��̵����涯���ڳ��н����ġ��滮���л��ߡ��Ƿ���ڡ�������������������(2) �滮���л���ij�εķ�չ״�����������������ھ����͡�ģʽ���������ȶȺ�ǿ�ȵ���˵������2�㡣
5 ����
(1) �ڹ��������棬����ˡ�Ҫ�ع��������¶��壺һ�ǿռ������չ������Ҫ�أ����ǿռ��ϵ�����˾��롢��λ�����˵ȣ��Լ�ʱ̬��ϵ���ɡ�Ҫ�ع��������¶��壬����ˡ���Ԫ������ģʽ������ͬ����Ҫ�ز����µĶ�����������ϡ��ڹ���ģʽ���棬ͼ�۱����ˡ����͡��͡������͡�����Ԫ������ģʽ��������ھ��㷨�ϣ������ˡ��ȼ��ࡱ�����ٴ����Ԫ������ģʽ��
(2) ����ֻ�漰2�����͵Ĺ���ģʽ���䷢�ֵĹ��̳�Ϊ����ʽ��̽������ģʽԤ�ȶ��壬�ڴ����Ĺ�ϵʵ���н��б��䡣���⣬ʵ��ֻ����˵���ھ�����̣���δ��ʵ�ʰ����е���ʵ����
(3) ��һ�������ǽ�һ�����ƹ���ģʽ�����ͺ�̽���йء���ʽ������ģʽ�ھ���������ʵ֤����Ȼ�����ϡ���������Ҫ��(��GDP)���������Ҫ�ص�Լ����ϵ���ȹ��������������ӵġ������ı�����ĵ���֪ʶ������ģʽҲ�д��ڽ�һ���о���
�ο����ף�
[1] �����, ��Ԩ. �滮֧��ϵͳ(PSS)�����ڳ��пռ�滮�����е�Ӧ��[J]. �人��ѧѧ��: ��ѧ��, 2005, 38(1): 137-142.
DU Ning-rui, LI Yuan. Planning support system (PSS) and its application to decision-making for urban spatial development[J]. Engineering Journal of Wuhan University, 2005, 38(1): 137-142.
[2] Pandey G, Atluri G, Steinbach M, et al. An association analysis approach to biclustering[C]//KDD��09. Paris, France, 2009�� 677-686.
[3] Saha S, Bridges S, Magbanua Z, et al. Discovering relationships among dispersed repeats using spatial association rule mining[J]. BMC Bioinformatics, 2008, 9(Suppl 10): 1-4.
[4] Lee I, Phillips P. Urban crime analysis through areal categorized multivariate associations mining[J]. Applied Artificial Intelligence, 2008, 22(5): 483-499.
[5] Huang Y, Kao L, Sandnes F. Predicting ocean salinity and temperature variations using data mining and fuzzy inference[J]. International Journal of Fuzzy Systems, 2007, 9(3): 143-151.
[6] Chang C, Shyue S. Association rules mining with GIS: An application to Taiwan census 2000[C]//Fuzzy Systems and Knowledge discovery, FSKD��09. Tianjin, China, 2009: 65-69.
[7] Koperski K, Han J. Discovery of spatial association rules in geographic information databases[C]//Proceedings of the 4th International Symposium on Large Spatial Databases. Portland, ME: Berlin: Springer, 1995: 47-66.
[8] Zeitouni K, Yeh L, Aufaure M. Join indices as a tool for spatial data mining[C]//International Workshop on Temporal, Spatial and Spatiotemporal Data Mining. Berlin: Springer, 2000: 102-114.
[9] Mennis J, Liu J. Mining association rules in spatio-temporal data: An analysis of urban socioeconomic and land cover change[J]. Transactions in GIS, 2005, 9: 5-17.
[10] Yang H, Parthasarathy S. Mining spatial and spatio-temporal patterns in scientific data[C]//22nd International Conference on Data Engineering Workshops (ICDEW'06). IEEE Computer Society, 2006: x146.
[11] ����, �ܲ�Ȩ, ����. ���������ڿռ������ھ��е��о�[J]. ����������ֹ���, 2005, 33(6): 71-73.
ZENG Ling, XIONG Cai-Quan, HU Tian. Research on association rules of spatial data ming[J]. Computer and Digital Engineering, 2005, 33(6): 71-73.
[12] ����, ������. ��ģ���Ŵ��㷨�ھ�ռ��������[J]. �人������ѧѧ��, 2006, 28(1): 96-104.
L? Feng, YI Xiao-feng. Ming spatial association rule by fuzzy genetic algorithm[J]. Journal of Wuhan University of Technology, 2006, 28(1): 96-104.
[13] ���ٻ�, ��Ӣϼ, ������, ��. GIS�ռ����ģʽ����[M]. ����: ��ѧ������, 2007: 251-360.
MA Rong-hua, PU Ying-xia, MA Xiao-dong. Mining spatial association patterns from GIS database[M]. Beijing: Science Press, 2007: 251-360.
[14] ��ѩ��. ʱ�չ��̼�����������ھ�[D]. �Ϻ�: ͬ�ô�ѧ�����������Ϣ����ϵ, 2009: 128-134.
ZHANG Xue-wu. Spatiotemporal process and its association rule mining[D]. Shanghai: Tongji University. Department of Surveying and Geo-informatics, 2009: 128-134.
[15] Sheng C, Hsu W, Lee M, et al. Discovering spatial interaction patterns[M]. Berlin: Springer, 2008: 95-109.
[16] Lee I. Mining multivariate associations within GIS environments[J]. Innovations in Applied Artificial Intelligence, 2004: 1062-1071.
[17] Ding W, Eick C, Wang J, et al. A framework for regional association rule mining in spatial datasets[C]//Proceedings of the Sixth IEEE International Conference on Data Mining (ICDM��06). Hong Kong, 2006: 851-856.
[18] Yang H, Parthasarathy S, Mehta S. Mining spatial object associations for scientific data[C]//Proceedings of the 19th International Joint Conference on Artificial Intelligence (IJCAI). Edinburgh, UK. 2005: 902-907.
[19] Lee A, Chen Y, Ip W. Mining frequent trajectory patterns in spatial-temporal databases[J]. Information Sciences, 2009, 179(13): 2218-2231.
[20] Huang Y, Xiong H, Shekhar S, et al. Mining confident co-location rules without a support threshold[C]//Proceedings of the 18th ACM Symposium on Applied Computing (ACM SAC). Melbourne, FL. 2003: 497-501.
[21] Agrawal R, Imielinski T, Swami A. Mining association rules between sets of items in large databases[J]. ACM SIGMOD Record, 1993, 22(2): 207-216.
[22] Han J, Pei J, Y Y. Mining frequent patterns without candidate generation[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data. Dallas, USA. 2000: 1-12.
[23] Lee H, Han J, Miller H, et al. Temporal and spatiotemporal data mining[M]. NewYork: IGI Publishing, 2007: 127-143.
[24] Tanbeer S, Ahmed C, Jeong B, et al. Efficient single-pass frequent pattern mining using a prefix-tree[J]. Information Sciences, 2009, 179(5): 559-583.
[25] Lee A J T, Liu Y H, Tsai H M, et al. Mining frequent patterns in image databases with 9D-SPA representation[J]. The Journal of Systems and Software, 2008, 82: 603-618.
[26] Zaki M J. New algorithms for fast discovery of association rules[R]. New York: Rensselaer Polytechnic Institute, 1997: 10-24.
[27] ������. �ռ�䷨���۵���ά��չ����Ӧ���о�[D]. �人: �人��ѧ���ң����Ϣ���̹����ص�ʵ����, 2006: 36-45.
WANG Jing-wen. Syntax paraphrase for social dimension[D]. Wuhan: Wuhan University. State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, 2006: 36-45.
[28] ���㷿�ز���. ̽�����껨��TOD����ģʽ[EB/OL]. [2008-06-16]. http://house.focus.cn.
Focus on estate. Exploratory TOD community patterns[EB/OL]. [2008-06-16]. http://house.focus.cn.
(�༭ �Կ�)
�ո����ڣ�2010-05-31�������ڣ�2010-08-16
������Ŀ��������ѧ����ί������Ŀ(�����[2007]3020)
ͨ�����ߣ��½�Ⱥ(1968-)��Ů�����������ˣ���ʿ�о����������ؽ�����Ⱦ��ʱ���쳣�ھ���о����绰��13467546368��E-mail: cjq@mail.csu.edu.cn

