J. Cent. South Univ. Technol. (2009) 16: 0275-0279
DOI: 10.1007/s11771-009-0047-x
An efficient embedding tree matching algorithm based on metaphoric dependency syntax tree
FENG Shao-rong(冯少荣)1, 2, XIAO Wen-jun(肖文俊)2
(1. College of Information Science and Technology, Xiamen University, Xiamen 361005, China;
2. School of Computer Science and Engineering, South China University of Technology, Guangzhou 510641, China)
Abstract: To find out all dependency relationships in which metaphors probably exist between syntax constituents in a given sentence, a dependency tree matching algorithm oriented to Chinese metaphor processing is proposed based on a research of unordered tree inclusion matching. In this algorithm, the pattern library is composed of formalization dependency syntax trees that are derived from large-scale metaphor sentences. These kinds of metaphor sentences are saved in the pattern library in advance. The main process of this algorithm is up-down searching and bottom-up backtracking revising. The algorithm discovers potential metaphoric structures in Chinese sentences from metaphoric dependency pattern library. Finally, the feasibility and efficiency of the new matching algorithm are further testified by the results of a series of experiments on dependency pattern library. Hence, accurate dependency relationships can be achieved through this algorithm.
Key words: pattern recognition; tree matching algorithm; dependency tree; rule matching; metaphor information processing
1 Introduction
Pattern matching is an important research subject in pattern recognition, finding wide application in many fields such as data mining, coded matching [1], image retrieval and matching [2], and natural language processing. Pattern matching of the tree structure [3-4] is widely used in various fields. A lot of valuable research work was made by researchers at home and abroad, a number of matching algorithms were proposed, and some theories and models were thus formed. However, these algorithms and models still have some shortcomings. WILLIAM and THOMAS [5] used the traditional query matching technology of cataloging information of the library science and information science based on keyword matching. Because the query based on keyword matching cannot embody the relationship between the queried keywords, precision ratio of their methods is low. XML (eXtensible Markup Language) -based query language (XQL), proposed by TORSTEN [6], can only be used find out the results that match the query conditions exactly, therefore, its recall ratio is not high. A new kind of query model and algorithm proposed by SCHLIEDER et al [7] cannot achieve high query efficiency because of the exponential computational complexity of this algorithm. THORSTEN [8] presented a query method based on the
structural XML document. Although this method is of a high recall ratio and mostly uses polynomial computational complexity, it still uses the matching idea of ordered trees. Since there is no restriction of order in description information of the same level, this query method that is based on matching idea of the ordered trees, is not suitable for mining dependency structure mode in syntax components of the given sentences which may have metaphoric relationship. There are numerous tree matching types. The matching type mentioned in this work is the embedding matching of trees. The matching between two dependency trees can be reduced to the corresponding relationship between the nodes of two trees. TORSTEN [6] gave some relative concepts about the tree node mapping and matching, which are not suitable for the situation where the nodes have a many-to-many relationship.
In this work, the nodes relationship between dependency trees, as well as related definitions of embedding matching, were studied by taking actual situation of dependency trees into consideration. Moreover, based on the structural characteristics of dependency trees and the related theories of unordered trees matching [9-11], a dependency tree embedding matching algorithm that uses the method of top-down searching and bottom-up backtracking revising was proposed.
2 Matching based on metaphoric dependency relationship tree
2.1 Dependency syntax and dependency syntax tree
Dependency tree is generated on the basis of the dependency syntax analysis. The tool used to analyze sentence syntax in this work is the dependency syntax analysis system made by the Information Retrieval Laboratory of Harbin Institute of Technology, China [12-14]. The syntax analysis generates sentences with dependency syntax mark. Sentence dependency relationship is expressed in visual graph, as shown in Fig.1. The words’ lexical categories are marked under them. Relationships of dependency between words are expressed by directional arcs marked with attributes and pointed from the controlled words to the center words.
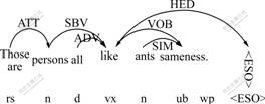
Fig.1 Dependency syntax structure graph
In this work, the dependency syntax is expressed in dependency syntax tree structure, with the center words as root nodes. On this basis, correlational pattern matching is performed. As pattern matching carried out in this work does not involve word meaning analysis, but only pays attention to the syntax structure. Dependency syntax tree is standardized, only with lexical category information and dependency relationship retained. Because the center words are the father nodes of the controlled words, i.e. the directional arc point from child nodes to father nodes, as shown in Fig.1, in the process of dependency tree generation, the arrow of directional arc is removed and a sentence for which matching is to be made is constructed into a dependency tree, as shown in Fig.2.
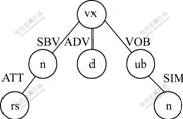
Fig.2 Standardized dependency syntax tree
2.2 Relevant definition of dependency syntax tree Definition 1 Dependency syntax tree
Dependency syntax tree is represented by T, T = (V, E, root(T)), where V is a limited node set, root(T) is the root node of dependency syntax tree and the center of the sentence, E denotes an edge set of binary relationship in V, satisfying the requirement of anti-reflexive, antisymmetricy and transitivity. If (u, v)∈E, node u is the parent of node v, and it is denoted as u = father(v). If two nodes v1 and v2 satisfy (v1, v2)∈E+ (where E+ is the transitive closure of E), v1 is the ancestor of v2, and is defined as v1=ancestor(v2). The height of node v is defined as height(v). In this work, dependency tree is defined as a disordered tree, and the left or right order of brother nodes is meaningless.
Definition 2 Node label
Each node v of dependency syntax tree has a label. The label consists of the node’s lexical category and the dependency relationships between the node and its father node, denoted respectively as label(v) and dependency(v). Since v is a root node, dependency(v) = “HEAD”, where “HEAD” is the sign of the head-phrase sentence and indicates dependency relationships of the root node.
Definition 3 Different nodes
In the dependency syntax tree, there exist T=(V, E, root(T)), node v, u∈V, and height(v)=height(u), label(v)=label(u), dependency(v)=dependency(u), and father(v)=father(u), possibly v≠u. For example, nodes 5 and 6 of dependency tree T2 belong to different nodes, as shown in Fig.3.
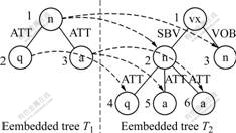
Fig.3 Example of mapping and embedding matching
Definition 4 Corresponding nodes
Assuming that T1=(V, E, root(T1)) and T2=(W, F, root(T2)) are two dependency trees, if v∈V, w∈W, when the following conditions are satisfied: (1) if v is the root node, label(v)=label(w), and (2) if v is non-root node, label(v)=label(w) and dependency(v)= dependency(w), w will be called the corresponding node of v in T2.
From Definitions 3 and 4, one node of dependency tree T1 may have a number of corresponding nodes in dependency tree T2. In Fig.3, node 1 of T1 corresponds to nodes 2 and 3 of T2, node 3 of T1 corresponds to nodes 5 and 6 of T2.
A node that satisfies this definition is not always a corresponding embedding matching node that satisfies the eventually embedding matching conditions.
Definition 5 Embedding matching and embedding matching node
Assume that T1=(V, E, root(T1)) and T2=(W, F, root(T2)) are two dependency trees. If the following conditions are satisfied: (1) ?wt∈W and wt is the corresponding node of root(T1) in T2; (2) for all non-root nodes v in V, ?w∈W, thus w is the corresponding node of v in T2 and wt=ancestor(w), height(v) is equal to the path length from w to wt, and father(w) is the corresponding node of father(v) in T2; (3) the number of w which satisfies Condition (2) should not be smaller than the number of nodes with the same height, label and father node of v in T1, then there exists embedding matching from dependency tree T1 to T2. T1 is the embedded tree, and T2 is the embedding tree. If nodes wt and root(T1) satisfy the above conditions, w and v are embedding matching nodes to each other.
Condition (1) ensures that root node of T1 has the corresponding node wt in the target tree. In Condition (2), wt =ancestor(w), and height(v) equal to the path length from w to wt, ensure that node w is in the sub-tree whose root node is wt and the height of w in the sub-tree is equal to the height of node v in T1. However, with these conditions it cannot be fully guaranteed that the nodes are the ultimate embedding matching nodes, for example, node 3 in T1 does not match node 5 in T2, as shown in Fig.4. In Condition (2) it is specified that father(w) is the corresponding node of father(v) in T2 so as to ensure matching correctness. Therefore, Conditions (1) and (2) will ensure that each node of T1 has the corresponding embedding matching node in T2. Since some nodes in T2 may correspond to the same nodes in T2, the number of matching nodes in T2 is smaller than the number of the corresponding nodes in T1, as shown in Fig.5. Condition (3) is additionally used to rule out such situation. Fig.3 shows the embedding matching from T1 to T2, wherein nodes 1, 2 and 3 in T1 correspond to embedding matching nodes 2(3), 4 and 5 (6) in T2.
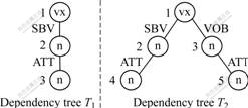
Fig.4 Example of embedding matching in which Condition (2) in Definition 5 is satisfied (T1 is embedded into T2)
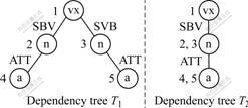
Fig.5 Example of embedding matching in which Condition (3) in Definition 5 is not satisfied (T1 cannot be embedded in T2)
2.3 Dependency pattern library of metaphor syntax
Dependency pattern library used for dependency syntax pattern matching is composed of different types of metaphoric dependency syntax trees obtained by Metaphor Computation Study Group of Art, Mind and Computation Laboratory of Xiamen University, China. Each dependency tree is a metaphoric dependency pattern. These patterns represent the most fundamental relationships of metaphoric dependency, with no nested or repeated relationship in between. In this pattern matching, a target sentence can match a number of patterns in pattern library at the same time. At present, the dependency pattern library has 50 basic patterns.
3 Dependency pattern embedding matching algorithm
3.1 Algorithm description
To facilitate description, dependency tree in the pattern library is defined as the rule tree and the dependency syntax tree of embedding matching is defined as the target tree.
The aim of the algorithm is to find out the situation of all rule trees in the dependency pattern library embedded in the target tree, and to record the mark of an embedding matching node in the target tree corresponding to the node in a certain rule tree of the dependency pattern library under each situation of embedding matching, so as to use such mark for other computation process. For instance, the rule tree shown in Fig.3 belongs to the embedding target tree, here what needed to record is that target tree node 2 corresponds to rule tree node 1, node 3 corresponds to rule tree node 1, node 4 corresponds to rule tree node 2, node 5 corresponds to rule tree node 3, and node 6 corresponds to rule tree node 3.
The basic idea of the algorithm is to determine whether all sub-trees with each node as root in the target tree have embedding matching with all rule trees in the dependency pattern library. The process is as follows: From top to bottom, perform level traversing to all nodes of the rule tree in the dependency pattern library, and determine whether all nodes of the rule tree have corresponding matching nodes in this target sub-tree; if yes, in a temporary result recording unit, record the marks of the target tree nodes that correspond to the nodes of rule tree; then, from the leaf node of the rule tree, perform bottom-to-top backtracking revising to correct the recorded marks in the record unit; finally, determine whether the results in the record unit satisfy the overall requirement of embedding.
3.2 Algorithm implementation
The relevant data structures of algorithm are as follows. Dependency tree uses an array to store nodes, and the dependency relationship is recorded in child nodes. So each array node contains the following data: the label of lexical category is denoted as label, dependency relationship is denoted as dependency, and the label of father node is denoted as father. The dependency relationship recorded in root node is denoted as “HEAD”, and the label of the father node is denoted as -1. The characteristic results are marked as record arrays: tempResult and modifiedResult, with sizes equal to the number of nodes in target tree. The arrays are used to store all labels of embedding matching nodes corresponding to the target node in the sequence of nodes in the target tree. For example, if node 1 of the target tree corresponds to nodes 3 and 4 of a certain rule tree, it recorded as tempResult[1] = “3, 4”. The process of the algorithm is as follows.
(1) For: take each node targetNode of target tree as sub-tree root node.
(2) Update node targetNode dependency relationship as “HEAD” and record original dependency relationship of targetNode.
(3) For: Each rule tree ruleTree of dependency pattern library.
(4) flag:=1, judge whether each node of rule tree ruleTree has matching node in target tree.
(5) For: By breadth-first, traverse each node ruleNode in the rule tree ruleTree.
(6) Determine whether an embedding matching module is included;
/* judge whether node ruleNode has embedding matching node in the target tree’s sub-tree whose root node is targetNode. If yes, record the corresponding matching in tempResult, return true and continue. If no, let flag: =0, return false, exit.*/
(7) End for
(8) If (flag =1) then
(9) Module of backtracking revising result record unit.
/*backtrack upward from leaf nodes of rule tree ruleTree, revise the record of tempResult, and record the new results in modifiedResult;*/
(10) Finally, judge whether embedding matching modules are generated.
/*based on the rule tree embedding standard, the step determines whether embedding matching has happened in the record of modifiedResult. If yes, record targetNode, the number of rule tree ruleTree in dependency pattern library and modifiedResult as one of final values;*/
(11) End if
(12) End for
(13) Restore the originally dependency relationship of node targetNode;
(14) End for
3.2.1 Judgment of embedding matching node modules
The module uses up-to-down judgment method to determine whether node ruleNode of the rule tree ruleTree has embedding matching nodes in the target tree’s sub-tree whose root is node targetNode (a judgment using Condition (2) of rule tree Definition 5). If yes, let the embedding matching node be node and record the mark of ruleNode in tempResult[node]. Because breadth-first traversing is used, if a certain non-root node of rule tree has embedding matching nodes in the target tree, the embedding matching situation of the non-root node’s father is surely recorded in tempResult. Otherwise, the node is impossible to have matching node. The main realization steps are as follows.
(1) In the target tree’s sub-tree whose root node is targetNode, find out the node node that situates at the same level and has the same lexical category and dependency relationship as node ruleNode in rule tree ruleTree does.
(2) If ruleNode is root node, add record in tempResult, let tempResult[node] be equal to the mark of ruleNode.
(3) If ruleNode is non-root node, judge again whether tempResult[node->father] includes the mark of ruleNode->father. If yes, add mark of ruleNode in tempResult[node].
(4) Do not skip to Step (1) until such a node is found.
(5) If there exists at least one node that matches node ruleNode of rule tree ruleTree, then return true. If no, flag: =0, return false.
3.2.2 Module of backtracking revising result record unit
TempResult records the label of rule tree ruleTree’s embedding matching node that corresponds to the node in the target tree. However, these records may contain wrong situation, we should perform upward backtracking in the module and make revising. The new result is recorded in modifiedResult. The main realization steps are as follows.
(1) Find a leaf node leaf in the rule tree ruleTree.
(2) Find a unit resultNode that includes a leaf label in tempResult, add leaf label in modifiedResult [resultNode], then let resultNode be equal to father node of resultNode in target tree, let leaf be equal to its father node in rule tree ruleTree. Repeat the above adding till the rule tree’s root node is reached.
(3) Determine whether rule tree ruleTree has leaf node. If yes, go to Step (1); if no, return. To vividly describe the backtracking process, the function of the module is explained through example. As shown in Fig.6, after revising the module, wrong matching label in tempResult is cancelled (The label in the target tree is the label of the target tree nodes that correspond to the rule tree’s matching nodes). Fig.6(b) shows the result of tempResult after labeling target tree from top to bottom.

Fig.6 Examples of module function of backtracking revising result record unit: (a) Rule tree; (b) Target tree from top to bottom; (c) Target tree from bottom to top
Fig.6(c) shows the result of modifiedResult after revising the tempResult in backtracking of the target tree from bottom to top.
3.2.3 Judgment of embedding matching modules
In addition to the previous two modules implemented, the following conditions should be satisfied to get the embedding.
If the number of different labels recorded in a unit m of modifiedResult is more than 1, which is denoted as n, then the number of units recorded in modifiedResult and with the same content as that recorded in a unit m must be equal to or greater than n, i.e. Condition (3) of Definition 5 must be satisfied.
For example, the case shown in Fig.5 (where the label in the target tree is the label of the matching node in the target tree and such a node corresponds to the node in the rule tree) does not satisfy such a condition and therefore is not a tree embedding matching.
If the above conditions are satisfied, the rule tree is embedded in the target tree. Then the label of root node targetNode, the label of rule tree and modifiedResult are recorded as the results that will serve as the basis for other related computation after dependency pattern matching.
4 Conclusions
(1) The research of dependency syntax pattern matching algorithm is a preliminary stage of Chinese metaphor computation study [15-16]. After giving a Chinese sentence carried out dependency syntax analysis, the algorithm performs searching in the dependency pattern library for all patterns that satisfy embedding matching and notes down the corresponding situation of the corresponding node under such pattern matching.
(2) As testified through a series of arbitrarily given target sentences, the algorithm achieves the goal of accurate matching. Thus the searching process for embedding matching is actually to separate out different parts of the sentence and their dependency relationships as a unit to be processed, and then to transit to next phases of metaphor judgment. At present, the further research work is under way.
References
[1] YANG Zong-kai, LIU Guang-ran, HE Jian-hua. New code match strategy for wideband code division multiple access code tree management [J]. Journal of Central South University of Technology, 2006, 13(3): 265-269.
[2] TONG Xiao-hua, WU Song-chun, WU Shu-qin, LIU Da-jie. A novel vehicle navigation map matching algorithm based on fuzzy logic and its application [J]. Journal of Central South University of Technology, 2005, 12(2): 214-219.
[3] PEKKA K. Tree matching problems with applications to structured text databases [D]. Helsinki: Department of Computer Science, University of Helsinki, 1992.
[4] PASCAL F, CHRISTOPHE G. An edit distance between quotiented trees [J]. Algorithmic, 2003, 36(1): 1-39.
[5] WILLIAM B F, THOMAS P P. An empirical study of representation methods for reusable software components [J]. IEEE Transactions on Software Engineering, 1994, 20(8): 617-630.
[6] TORSTEN S. ApproXQL: Design and implementation of an approximate pattern matching language for XML [R]. Berlin: Freie Universit?t Berlin, 2001.
[7] SCHLIEDER T, BERLIN F U, NAUMANN F. Approximate tree embedding for querying XML data [C]// Proceedings of ACM SIGIR Workshop on XML and Information Retrieval. Athens: The Research Publication Repository of KFUPM, 2000.
[8] THORSTEN R. A new measure of the distance between ordered trees and its applications [R]. Bonn: Department of Computer Science, University of Bonn, 1997.
[9] DENNIS S, JASON T L W, SHAN H Y, ZHANG K Z. ATreeGrep: Approximate search in unordered tree [C]// Proceedings of the 14th International Conference on Scientific and Statistical Database Management. Edinburgh: IEEE Computer Society, 2002: 89-98.
[10] DENNIS S, JASON T L W, ZHANG K Z, FRANK Y S. Exact and approximate algorithm for unordered tree matching [J]. IEEE Transactions On Systems, Man and Cybernetics, 1994, 24(4): 668-678.
[11] ZHANG K Z, RICK S, DENNIS S. On the editing distance between unordered labeled trees [J]. Information Processing Letters, 1992, 42(3): 133-139.
[12] GABRIEL G I L, MAARTEN D R, KHALIL S. A general probabilistic model for dependency parsing [C]// Proceedings of the 14th Dutch-Belgian Artificial Intelligence Conference. Leuven: Leuven University Press, 2002: 139-146.
[13] ALEXIS N, OWEN R. A simple string-rewriting formalism for dependency grammar [C]// Workshop on Recent Advances in Dependency Grammar, International Conference on Computational Linguistics. Geneva, Switzerland: COLING, 2004: 25-32.
[14] XIONG D Y, LI S L, LIU Q, LIN S X, QIAN Y L. Parsing the Penn Chinese treebank with semantic knowledge [J]. Lecture Notes in Computer Science, 2005, 3651: 70-81.
[15] DING Y W. Comparative study on metaphors in eastern and western cultures [J]. Academic Exchange, 2004, 129(12): 159-161.
[16] WANG Z M, WANG H F, DUAN H M, HAN S, YU S W. Chinese noun phrase metaphor recognition with maximum entropy approach [J]. Lecture Notes in Computer Science, 2006, 3878: 235-244.
Foundation item: Project(50474033) supported by the National Natural Science Foundation of China
Received date: 2008-08-29; Accepted date: 2008-10-24
Corresponding author: FENG Shao-rong, PhD; Tel: +86-592-2186825; E-mail: shaorong@xmu.edu.cn
(Edited by CHEN Wei-ping)

