�ں�����֪ʶ��ͳ�ƾ䷨����
Ԭ���1, 2
(1. �����ƾ���ѧ ��ϢѧԺ ������֪ʶ���̽���ʡ�ص�ʵ���ң����� �ϲ���330013��
2. ���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ������ ��ɳ��410083)
ժҪ���������塢�������֪ʶ������һ�ֲַ�䷨����ͳ��ģ�ͣ������о䷨����ʵ�顣�о������������ģ�;��й����ͳ�����ϵ��ص㣬���ڲ�η����IJ�ͬ�Σ����ݲ�ͬ��������塢�������Բ��ò�ͬ�ķ����Ͳ�ͬ��ͳ��ģ�ͣ���ģ�ͽ�Ϸִʡ����Ա�ע���о䷨��������һ���ʻ㻯�ľ䷨����ģ�ͣ���ͬʱ���Ƕ�����������ϵ�����ø�ģ�ͣ���ȷ�ʺ��ٻ��ʷֱ�Ϊ87.23%��86.15%�����ۺ�ָ��F��ͷ�����䷨����ģ�͵���������5.25%��
�ؼ��ʣ���Ȼ���Դ������ʾ��ࣻ���Ĵ��������䷨����ͳ��ģ��
��ͼ����ţ�TP391.1 ���ױ�־�룺A ���±�ţ�1672-7207(2012)03-0986-06
Statistical parsing with linguistic features
YUAN Li-chi1, 2
(1. School of Information Technology, Jiangxi University of Finance & Economics, Nanchang 330013, China;
2. School of Information Science and Engineering, Central South University, Changsha 410083, China)
Abstract: By incorporating linguistic features such as semantic dependency and syntactic relations, a novel statistical parsing model was proposed, and experiments were conducted for the refined statistical parser. The results show that the mode not only takes advantage of linguistic features such as semantic dependency or syntactic relations, but also considers context such as adjoining words. The model can take advantage of a few semantic dependencies at the same time. It is a parser based on lexicalized model. It achieves 87.23% precision and 86.15% recall using the model, and comprehensive index F is improved by 5.25% compared with that using the head-driven parsing model.
Key words: natural language processing; word clustering; head-driven parsing model; statistical parsing model
����Ȼ���Եľ䷨�ṹ����������塢���õȶ�桢��Ƕȷ���[1-3]���������ѳ�Ϊ��������ѧ��Ĺ�ʶ��3��ƽ����о��ѳ�Ϊ�ִ������о��е��ȵ㣬��������ߴӲ�ͬ�ĽǶȽ����о�����û�н���ͬ�����������ۺϿ��ǣ�ϵͳ�ؽ���Ӧ�õ��䷨�����У�����������ͳ�Ʒ������ϵľ䷨����ģ�͡����������ͳ�ƾ䷨����[4-10]���ִ��䷨��������������������ͳ�ƾ䷨����ģ�͵�Ŀ�����Ը��ʵ���ʽ�������ɸ����ܵľ䷨�������(ͨ����ʾΪ�����ʽ)���������ɸ����ܵķ��������ֱ��ѡ��1������ܵĽ��������ͳ�Ƶľ䷨����ģ����ʵ����1�����۾䷨��������ĸ������ۺ���������������1���������s�����ľ䷨�������t������1����������P(t|s)�����ɴ��ҳ��þ䷨����ģ����Ϊ�������ľ�
�����������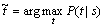 ���䷨��������������ռ�Ϊ
���䷨��������������ռ�Ϊ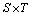 �����У�SΪ���о��ӵļ��ϣ�TΪ���о䷨��������ļ��ϡ�Collins[11]��������Ĵ������ľ䷨����ģ���ǵ�ǰ�䷨����������ģ�ͣ������˼����������������ķ�����������ʻ㻯��Ϣ�Ͷ�������Ĵ���Ϣ����2����Ϣ��������ǿ�˾䷨����ģ�͵�����������Ȼ�������ɱ���ش��������ص�����ϡ�����⡣ͳ�ƾ䷨����[12-17]���ٵ�һ����Ҫ��������η��ֺ����þ���ǿ������������������֪ʶ��ͬʱ��֤����֪ʶ��Ӧ�ò���ʹģ�͵IJ����������Ͷ��������ص�����ϡ�����⡣Ϊ�ˣ��������߽�����1����ӱ�ľ䷨����ģ�͡��þ䷨����ģ�ͻ��ڹ�����ͳ�Ʒ������ϣ���������塢���õ�����ѧ֪ʶ����䷨�����У����ȸ����������֪ʶ�Ծ䷨�ṹ���в�η����������������ܵ�����Է���ͬһ��νṹ֮�����Ϲ�ϵ�����ϵ������������֪ʶ�������ǵ�����˳������Ƕ����䷨�ɷ��еĴ�֮������������ϵ[18-20]��
�����У�SΪ���о��ӵļ��ϣ�TΪ���о䷨��������ļ��ϡ�Collins[11]��������Ĵ������ľ䷨����ģ���ǵ�ǰ�䷨����������ģ�ͣ������˼����������������ķ�����������ʻ㻯��Ϣ�Ͷ�������Ĵ���Ϣ����2����Ϣ��������ǿ�˾䷨����ģ�͵�����������Ȼ�������ɱ���ش��������ص�����ϡ�����⡣ͳ�ƾ䷨����[12-17]���ٵ�һ����Ҫ��������η��ֺ����þ���ǿ������������������֪ʶ��ͬʱ��֤����֪ʶ��Ӧ�ò���ʹģ�͵IJ����������Ͷ��������ص�����ϡ�����⡣Ϊ�ˣ��������߽�����1����ӱ�ľ䷨����ģ�͡��þ䷨����ģ�ͻ��ڹ�����ͳ�Ʒ������ϣ���������塢���õ�����ѧ֪ʶ����䷨�����У����ȸ����������֪ʶ�Ծ䷨�ṹ���в�η����������������ܵ�����Է���ͬһ��νṹ֮�����Ϲ�ϵ�����ϵ������������֪ʶ�������ǵ�����˳������Ƕ����䷨�ɷ��еĴ�֮������������ϵ[18-20]��
1 ģ�͵��ص�ͷ�������
1.1 ģ�͵��ص�
(1) ���������䷨����������Ϊ��ʼ�䷨�����������������ľ䷨��������(�����������)���о䷨�������õ����п��ܵľ䷨�����ھ䷨�������Ļ����ϣ�����������塢���õ�����ѧ֪ʶ���Ծ��ӡ��ṹ(����)���ʽ��о��ӳɷ֡����ϵ������ܡ����Ժ�����˳�������ʹ�ù����ͳ�����ϵķ����Ծ䷨����������ѡ��
(2) ģ�ͽ����ھ���Ļ����ϡ���ͳ������ģ���У��ʵľ���[21-22]�ǽ������ϡ���������Ҫ����֮һ�����������������Եģ����������������Եġ����ԵĻ���ʵ���Ͼ�����������ԶԴʽ��з��࣬���ʵ���Ŀ��ͨ�����ԵĻ��ֲ�������ȫ��ӳ�ʵIJ�ͬ����ԣ����ԣ��б�Ҫ���þ���ķ��������ݲ�ͬ������ԶԴʽ��н�һ�����ࣻ��һ���棬������ͬ����ԵĴʵ��������Բ�һ����ͬ��Ҳ�б�Ҫ�����������Խ��о��ࡣ
(3) �þ䷨����ģ����һ��ģ�Ϳ�ܣ����й����ͳ�Ʒ������ϡ����ͳ��ģ�����ϵ��ص㡣
���ò�η�����˼�룬�ڲ�η����IJ�ͬ�Σ����ݲ�ͬ��������塢�������Բ��ò�ͬ�ķ����Ͳ�ͬ��ͳ��ģ����������⡣
1.2 ģ�͵ķ�������
1.2.1 ���ó�ʼ�䷨�������Ծ��ӽ��з���
���ó�ʼ�䷨�������Ծ��ӽ��з������õ����ܵľ䷨���������������������������ʼ�䷨�������Ծ��ӡ�Astronomers saw stars with telescopes�����з����ɵõ�ͼ1��ʾ��2�þ䷨����

ͼ1 ����Astronomers saw stars with telescopes��2�÷�����
Fig.1 Two parse trees of sentence ��Astronomers saw stars with telescopes��
1.2.2 �Ծ��ӽ��о䷨�ɷַ���
(1) ȷ�����ӳɷֲ�εĶ���ڷ������Ļ����ϣ�ȷ�����ӵ�ν��(������)����ν��(������)��ֱ�����ϵ�����������Щ������ν��(������)�ھ����о���ͬһ��Ρ������У�����������ӵ�ν��(������)���ɶ���(����)�����ġ�
����ͼ1��ʾ2�÷�������ν��(������)����V(saw)������ʽV�� saw�ĸ�����
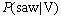 (1)
(1)
2�÷�������ν��(������)V(saw)����ͬһ��εĽṹ(����)�������зֱ�Ϊ��
NP V(saw) NP��NP V(saw) NP PP
(2) �Ծ��ӳɷֲ�εĶ����������ܷ�����
1) �����������֪ʶ�������Զ�����гɷֱ�ע����ͬ�Ķ����ھ����пɵ�����ͬ�ľ��ӳɷ֣�ͬʱ���ӳɷ�����ɺ�����˳����������ƣ�����һ���棬���ӳɷֵ�����˳���нϴ������ԣ����öԾ��ӳɷֵ�����˳��Ҳ�кܴ��Ӱ�졣����ͳ�Ƶķ����Ծ��ӳɷ�����˳��ĸ��ʽ��м��㣬�����ھ��ӳɷ���Ŀ�϶�(���ӳɷ���Ҫ�����ν������״�״���ַ�Ϊʱ�䡢�ص㡢������Ŀ�ġ�ԭ������̶ȡ���ʽ��״��)��������ģ�����µ�����ϡ�����⽫��dz����أ���ˣ��Խṹ(����)���гɷֱ�עӦ�������������֪ʶ��ʹ�ù���ķ������ڽ��гɷֱ�ע��ͬʱ�����ų�һЩ����ķ�������
���磬������2�÷������ijɷֱ�עΪ��
NP-s V-p (saw) NP-o
NP-s V-p (saw) NP-o PP-wadv
���У���-s��-p��-o��-wadv�ֱ��ʾ�ṹ(����)�ľ䷨�ɷֱ�עΪ���ν������ʽ״�
2) ���þ䷨�ɷ���������ijɷ�ν��(���ʶ���)������ܹ�ϵ�����䷨�ɷֹ��ɸ��ʿռ�ֳ���ν��Ϊ������������ĸ����ӿռ䣺
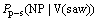 (2a)
(2a)
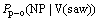 (2b)
(2b)
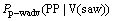 (2c)
(2c)
������������ʽ(2a)��(2b)��(2c)�ֱ��ʾ�������ijɷ�(ν��)Ϊ����(V)sawʱ����������ʽ״��Ϊ����NP�� NP�� PP�ĸ��ʡ��Ծ��ӵĻ�����ɳɷ�(���ӵı�ѡ��ʩ�¡����ºͶ����)���ӳɷ�(���ӵĿ�ѡ��ʱ�䡢���������ߡ�������ԭ��Ŀ�ĺͷ�ʽ��)���������ʲ�����ѵ��������ͬ��������ɳɷ�Ӧ���Ƕ���Ϊ�յIJ���ʽ�������ʣ������ӳɷֲ����Ƕ���Ϊ�յIJ���ʽ�������ʡ�2�÷������ijɷֱ�ע���ɸ��ʵļ���ֱ�����2ʽ������
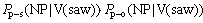 (3)
(3)
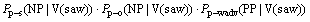 (4)
(4)
Ϊ�˼�������ϡ����������⣬�����������ʵļ���ʽ�ж���saw����saw����������档
1.2.3 ȷ�����ӳɷֵ����Ĵ�(ͷ��)
ȷ����ν������Ĵʺ�1�÷��������������ӳɷ�ΪNP-s��NP-o������(NP-s)�ṹ�����Ĵ���ȻΪAstronomers������NP-o(stars with telescopes)��NP(stars)��PP(with telescopes)��ɣ�����NP(stars)ΪNP-o�������ӽṹ(����)���������Ĵ���ȻΪstars���ʱ���NP-o�����Ĵ�Ϊstars����Щ���Ĵ�(ͷ��)���ӳɷֵij�����Ҫ��2�������йأ��ṹ(����)�����ĴʵĴ���Ҫ�������NP-o�����Ĵ�stars�Ĵ��Ա�Ϊ����(N)�����ӳɷֵ����Ĵ���������ijɷֺ��������ӳɷֵ����Ĵ������������ϵ�������NP-o�����Ĵ�stars��ν��V-p���Ĵ�saw�����������ϵ�����stars���saw�����������ϵ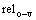 ������Ԫ��
������Ԫ��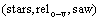 ��ʾ�ʶԺ�����֮��������ϵ�����stars�ij��ָ�������ʽ���㣺
��ʾ�ʶԺ�����֮��������ϵ�����stars�ij��ָ�������ʽ���㣺
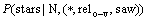 (5)
(5)
���У�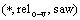 �е�*��ʾ�������saw�����������ϵ
�е�*��ʾ�������saw�����������ϵ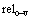 �Ĵʣ���������ʽ(5)��ʾ�ڴ���Ϊ���������saw�����������ϵ�������£���stars�ij��ָ��ʡ�
�Ĵʣ���������ʽ(5)��ʾ�ڴ���Ϊ���������saw�����������ϵ�������£���stars�ij��ָ��ʡ�
�ɱ�Ҷ˹��ʽ�Ͷ����������У�

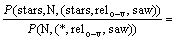
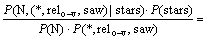
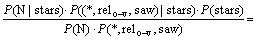
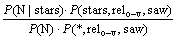 (6)
(6)
�ɱ�Ҷ˹��ʽ���У�
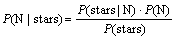 (7)
(7)
��ʽ(7)����ʽ(6)���ã�
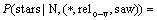
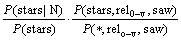 (8)
(8)
ʽ(8)�ĸ�������ʮ����ȷ��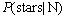 ��ʾ�ڴ���Ϊ���ʵ������£���stars�ij��ָ��ʡ���
��ʾ�ڴ���Ϊ���ʵ������£���stars�ij��ָ��ʡ���
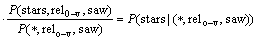 (9)
(9)
ʽ(9)��ʾ����ν��V-p���Ĵ�saw�����������ϵ�������£���stars���ֵĸ��ʡ�
Ϊ�˼�������ϡ����������⣬ʽ(9)��ߵ��������ʵļ���ʽ�У�����saw������stars�������ǵ������������棬����saw��stars��������ֱ�ΪCsaw��Cstars����
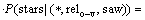
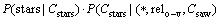 (10)
(10)
1.2.4 �������
(1) �Զ�����в�η�����ȷ��ͬһ��εĶ������������Ȼ�����кܶ��Σ���ͬһ�����ɱȽϼ�һ����2����������һ�������ϵ��ϳ�1���������2�����������˳��ȽϹ̶���������Բ�ȡ��ԱȽϼķ���������
2�÷������ھ䷨��һ��ε���ɷֱ�Ϊ��
NP-o(stars)��NP(stars)PP
PP-wadv(with)��P(with)NP
������ɱȽϼ���ˣ�����ֱ���������������������������ɳ��ֵĸ��ʣ�
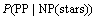 (11)
(11)
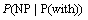 (12)
(12)
(2) ȷ�����������ɲ��ֵ����Ĵ�(ͷ��)��ʵ���ϣ���ɶ���������Ӷ�������Ĵ�(ͷ��)����һ��εķ������Ѿ�ȷ���������ֻ��ȷ��������ɲ��ֵ����Ĵ�(ͷ��)��
NP-o(stars)��NP(stars)PP(with)
PP-wadv(with )��P(with )NP(telescopes)
������Щ���Ĵ�(ͷ��)���ָ��ʵķ�������ӳɷֵ����Ĵ�(ͷ��)�ļ��㷽��������ͬ��Ҳ�Ǽ����ڴ���һ�����������Ӷ�������Ĵ�(ͷ��)����������һ�������������ϵ�������´ʳ��ֵĸ��ʡ������������ϵ���ܲ�ֻ1�֡��ڵ�2�÷������У���telescopes����������ϼ�����ֱ�ӵĺ��Ĵ�with�й�,Ҳ���������ӵ�ν����Ĵ�saw�йء�
��telescopes���with��saw�ֱ�������������ϵrel1��rel2������(5)ʽ���Ƶļ���ɵã�
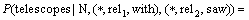
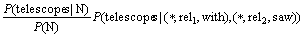 (13)
(13)
���У�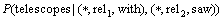 ��ʾ�����with��saw�ֱ�������������ϵrel1��rel2�������£���telescopes�ij��ָ��ʡ�
��ʾ�����with��saw�ֱ�������������ϵrel1��rel2�������£���telescopes�ij��ָ��ʡ�
Ϊ�˼��ٲ����϶����������ϡ������, ʽ(13)�ұߵĵ�2���������ʿ�ʹ�ò�ֵ��������:
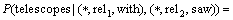

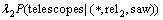
 ��
��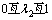 ��
�� (14)
(14)
����

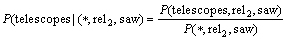
����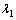 ��
��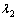 ͨ������ѵ���õ���
ͨ������ѵ���õ���
1.2.4 �����ڲ��Ĵʵķ���
����ֱ���ɴ���ɵĶ�����(����)�����������ϵ�ķ����ɲ��������ķ�������(ʵ���ϣ������with telescopes�ķ��������������)�����ǣ�����Ծ䷨�����Ľ����һ����Ӱ�죬�ھ䷨�ɷַ���ʱ����䷨�ɷֵ���Ŀ���ܽ϶࣬����˳�������йأ�Ҳ�������йأ����ù���ķ�������������⣻���ڶ����ڲ��Ĵʵ�����˳��������Ա�עnԪģ������������磬�Զ���a(ART) good(ADJ) student(N) �ķ������������(����)�����������ϵ�������⣬ͨ������������������������˳��Ŀ����ԣ�
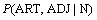 (15)
(15)
��ͨ���Ĵ��Ա�עnԪģ�Ͳ�ͬ�ǣ�ʽ(15)�ļ���ֻ��ֱ���ɴ���ɵĶ����ڲ����У����������������ڴ�֮�䶼���м��㡣
2 ʵ����
����ʵ���ڱ�����������Chinese Treebank (CTB)5.0�Ͻ��С�CTB����������������(LDC)����������һ�����Ͽ⣬Ϊ����䷨�����о��ṩ��һ��������ѵ��������ƽ̨�������������507 222���ʣ�824 983�����֣�18 782�����ӣ���890�������ļ������ļ�301~325(��353�����Ӻ�6 776����) ��Ϊ���Լ������ļ�271~300(��348�����Ӻ�7 980����)��Ϊ���Լ��������ļ���Ϊѵ���������ĵ�����ʵ���У�ģ�͵IJ������Ǵ�ѵ�����в��ü�����Ȼ�����Ƴ����ġ�
���Խ����ȡ�˳��õ�3������ָ�꣬��ȷ��P���ٻ���R���ۺ�ָ��F����ȷ��P���������䷨����ϵͳ�����������гɷ�����ȷ�ijɷֵı������ٻ���R���������䷨����ϵͳ��������������ȷ�ɷ���ʵ�ʳɷ��еı������ۺ�ָ��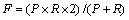 ��
��
ʵ���в��õľ䷨����Baselineϵͳ��Daniel M.Bikel����Collinsģ��ʵ�ֵ�DBParser����1��ʾΪbaselineϵͳ�Ľ�ģ�͵ľ䷨����ʵ������
�� 1 �䷨����ʵ����
Table 1 Experimental results of language parsing

�ӱ�1���Կ������������ò�η�����˼�룬�ڲ�η����IJ�ͬ�Σ����ݲ�ͬ��������塢�������Բ��ò�ͬ�ķ����Ͳ�ͬ��ͳ��ģ��, �Ľ�ģ�͵�ȷ��P���ٻ���R���ۺ�ָ��F�ȣ�ollins��ͷ�����䷨����ģ�����ý������������ߡ�
3 ����
(1) ��������֪ʶ��Ӧ�ö�ͳ�ƾ䷨�����кܴ�Ӱ�죬���һ������ָ���˺���ͳ�ƾ䷨�����о���һ����������ѧ�Ƕ�Ѱ�Ҹ��������֪ʶ����ͳ�ƾ䷨�����ĽǶ�������������һ���õļ���ģ�Ͳ����зḻ����������֪ʶ��
(2) ������������ӵķ�ʽ��ͨ���������ӳɷּ��������������ϵ�������Ծ��ӳɷ�Ϊ�ڵ������������Դ˱�����ӵĽṹ�����ԣ�����Ҫ����������ǣ�ȷ��������о��ӳɷֵ�����ͳɷ�֮��������ϵ���͡���ͳ�ƾ䷨�����У���������֪ʶ��ģ�����о����ġ�
(3) �������塢�������֪ʶ��������һ�ֻ��������ϵ�ķֲ�䷨����ͳ��ģ�ͣ�����������������ɸ��ʵ����������Լ�������Ƚ�����Լ�������������ڸ�ģ���еõ��������ͷ�����䷨����ģ�����, �����ڴʵľ��ࡢ����ķֽ⼰���ʼ�����,���ε�������������������ϵ������֪ʶ���Ľ�ģ�͵�����������ߡ�
�ο����ף�
[1] Manning C D, Schutze H. Foundations of statistical natural language processing[M]. London: the MIT Press, 1999: 184-197.
[2] ������. ���ڡ���Ϣ-֪ʶ-����ת�����ɡ����о�[J]. ����ѧ��, 2004, 32(4): 601-605.
ZHONG YI-xin. A study on information-knowledge-intelligence transformation[J]. Chinese Journal of Electronics, 2004, 32(4): 601-605.
[3] Joshua G. A bit of progress in language modeling[J]. Computer Speech and Language, 2001, 15(4): 403-434.
[4] XUE Nian-wen, XIA Fei, Chiou F D, et al. The Penn Chinese treebank: Phrase structure annotation of a large corpus[J]. Natural Language Engineering, 2005, 11(2): 207-238.
[5] Fung P, Ngai G, Yang Y S, et al. A maximum-entropy Chinese parser augmented by transformation-based learning[J]. ACM Trans on Asian language Processing, 2004, 3(2): 159-168.
[6] Ciprian C, Frederick J. Structured language modeling[J]. Computer Speech and Language, 2000, 14(4): 283-332.
[7] �Ծ�, �Ʋ���. ����������ʶ���ṹ����ģ��[J]. �����ѧ��, 1999, 22(2): 141-146.
ZHAO Jun, HUANG Chang-ning. The model for Chinese basenp structure analysis[J]. Chinese Journal of Computers, 1999, 22(2): 141-146.
[8] ��ˮ, ����, ������, ��. ͷ�����䷨�����е�ֱ�Ӳ�ֵƽ���㷨[J]. ����ѧ��, 2009, 20(11): 2915-2924.
LIU Shui, LI Sheng, ZHAO Tie-jun, et al. Directly smooth interpolation algorithm in head-driven parsing[J]. Journal of Software, 2009, 20(11): 2915-2924.
[9] Aviran S, Siegel P H, Wolf J K. Optimal parsing trees for run-length coding of biased data[J]. IEEE Transaction on information Theory, 2008, 54(2): 841-849.
[10] ZHOU De-yu, HE Yu-lan. Discriminative Training of the hidden vectors state model for semantic parsing[J]. IEEE Transaction on Knowledge and Data Engineering, 2009, 21(1): 66-77.
[11] Collins M. Head-driven statistical models for natural language parsing[D]. Pennsylvania: The University of Pennsylvania, 1999: 65-78.
[12] Ԭ���. �������ƶȵĴʾ����㷨�Ϳɱ䳤����ģ��[J]. С���ͼ����ϵͳ, 2009, 30(5): 912-915.
YUAN Li-chi. Word clustering based on similarity and vari-gram language model[J]. Journal of Chinese Computer Systems, 2009, 30(5): 912-915.
[13] ��Ƽ, �ڳ���. �������б�עģ�͵ķֲ�ʽ����䷨��������[J]. ������Ϣѧ��, 2010, 24(6): 14-22.
JIAN Pink, ZONG Cheng-qing. Layer based dependency parsing by sequence labeling models[J]. Journal of Chinese Information Processing, 2010, 24(6): 14-22.
[14] ����, ������, �ܹ���. �������־䷨�����������ɫ��ע�Ƚ��о�[J]. �����Ӧ��������, 2010, 27(8): 13-16.
ZHANG Yu, WANG Hong-ling, ZHOU Guo-dong. On comparison of semantic role labeling based on two types of syntactic parsing[J]. Computer Applications and Software, 2010, 27(8): 13-16.
[15] ������, ������, Ԭ����, ��. ��������䷨���������������ɫ��ע[J]. ������Ϣѧ��, 2010, 24(1): 25-30.
WANG Bu-kang, WANG Hong-ling, YUAN Xiao-hong, et al. Chinese dependency parse based on semantic role labeling[J]. Journal of Chinese Information Processing, 2010, 24(1): 25-30.
[16] �����, �����, �ܹ���, ��. һ�ֻ�����ʷ��Ϣ�Ķ������ľ䷨��������[J]. �����Ӧ��������, 2009, 26(6): 45-51.
GENG Xiang-hao, LI Jun-hui, ZHOU Guo-dong, et al. A history-based hierarchical Chinese parsing[J]. Computer Applications and Software, 2009, 26(6): 45-51.
[17] ����, ��ʿϲ, ����, ��. ��������ص�����䷨����[J]. ������Ϣѧ��, 2009, 23(2): 18-22.
XIN Xiao, FAN Shi-xi, WANG Xuan, et al. Dependency parsing based on maximum entropy model[J]. Journal of Chinese Information Processing, 2009, 23(2): 18-22.
[18] Seo K J, Nam K C, Choi K S. A probabilistic model of the dependency parse of the variable-word-order languages by using ascending dependency[J]. Computer Processing of Oriental Languages, 2000, 12(3): 309-322.
[19] ������, ������, ��ͦ. �����������ĸ߽�����䷨����[J]. ������Ϣѧ��, 2010, 24(1): 37-41.
LI Zheng-hua, CHE Wan-xiang, LIU Ting. Beam-search based high �Corder dependency parser[J]. Journal of Chinese Information Processing, 2010, 24(1): 37-41.
[20] Ԭ���. ���������ϵ�ľ䷨����ͳ��ģ��[J]. ���ϴ�ѧѧ��: ��Ȼ��ѧ��, 2009, 40(6): 1630-1635.
YUAN Li-chi. Statistical language paring model based on dependency[J]. Journal of Central South University: Science and Technology, 2009, 40(6): 1630-1635.
[21] GAO Jian-feng, Goodman J, MIAO Jiang-bo. The use of clustering techniques for language model-application to Asian language[J]. Computational Linguistics and Chinese Language Processing, 2001, 6(1): 27-60.
[22] Lee L. Similarity-based approaches to natural language processing[D]. Cambridge: Harvard University, 1997: 35-56.
(�༭ �²ӻ�)
�ո����ڣ�2011-06-20�������ڣ�2011-08-25
������Ŀ��������Ȼ��ѧ����������Ŀ(60763001)������ʡ��Ȼ��ѧ����������Ŀ(2009GZS0027,2010GZS0072)
ͨ�����ߣ�Ԭ���(1973-)���У����������ˣ���ʿ�����ڣ���������ʶ������Ȼ���Դ����о����绰��0791-83983891��E-mail: yuanlichi@sohu.com

