一种基于信誉度的Web服务质量预测方法
舒振,马建威,罗雪山
(国防科技大学 信息系统工程重点实验室,湖南 长沙,410073)
摘要:基于现有的服务质量预测方法大多是以其他用户的使用感受为依据,但前提都是假设这些信息是准确可信的,一旦这个假设难以得到保证,那预测的结果将会出现重大偏差。从服务用户信誉度的角度,提出一种Web服务质量预测的方法。首先介绍该方法的基本思想与主要过程,随后对评价用户信誉等级划分、评价用户信誉度计算以及服务质量的预测算法等内容进行重点分析;最后,通过仿真实验,将本文提出的方法与传统的算术平均值法进行比较。研究结果表明:该方法能有效提高Web服务质量预测的准确性。
关键词:Web服务;信誉度;服务质量(Qos);服务质量预测;服务用户
中图分类号:TP393 文献标志码:A 文章编号:1672-7207(2012)05-1764-09
A Web service QoS prediction method based on reputation
SHU Zhen, MA Jian-wei, LUO Xue-shan
(Science and Technology on Information Systems Engineering Laboratory,
National University of Defense Technology, Changsha 410073, China)
Abstract: The existing Web service QoS prediction methods are always based on other consumers’ experience, which assume that the QoS data coming from these consumers are effective and trustworthy. If the QoS data coming from these consumers are not reliable, the results of QoS prediction method are not precise. A Web service QoS prediction method based on reputation was proposed. First the basic conceive and main process of this method were introduced, and then the classification of service consumers’ reputation, the calculating method of service consumers’ reputation and the prediction method of web service QoS were stressly analyzed. Finally, a prototype system was implemented to evaluate the proposed method and the traditional arithmetic average method through simulation experiments. The results show that with the proposed approach the preciseness of QoS prediction for Web services can be improved significantly.
Key words: Web service; reputation; quality of service (QoS); QoS prediction; service consumer
随着SOAP,UDDI及WSDL等相关技术的迅猛发展,Web服务已逐步从企业级服务集成过渡到面向互联网环境的服务体系结构之上[1]。互联网上的资源无限膨胀,能满足同一种功能需求的服务也越来越多,如何从众多的服务中选择合适的、最适应用户需求的服务一直是学术界重点关心的问题。有众多研究人员认为,当用户选择服务时,不能仅考虑用户的功能性需求,还应多关注服务所能提供的非功能性指标,即服务质量(Quality of service,简称QoS,具体包括可靠性、可用性、使用时延等属性)。服务质量水平的高低已成为制约某些服务化信息系统(如军事信息系统、交通运输系统等)能否成功应用的关键因素之一。因此,研究人员普遍认为,从服务质量的角度优化选取合适的应用服务,是全面提升面向服务应用系统运行质量的重要手段之一。目前,随着信息化建设的不断发展,部署于网络上的Web服务的数量也在日益增多,即使针对同一功能需求,也会同时存在众多符合要求但质量属性不同的Web服务实例,因此用户经常需要进行服务筛选,而且这种选择过程通常是在信息不完全的情况下进行的。也就是说,在大多数情况下,某个单独的用户不可能完全了解那些可以满足用户功能需求但性能指标不同的候选Web服务的质量信息,比如,网上可能同时存在二十多个能提供酒店预订功能的服务,而对于某一用户来说,可能仅使用过其中三四个,同时又由于使用费用、时间等相关因素的限制,该用户无法也不可能对这些服务进行逐一试用。在这种情形下,用户为了挑选出质量最优、最能满足用户需求的酒店预定服务,就不得不事先对那些未曾使用过的服务进行质量预测,进而为最终的服务优选提供依据。为了保证服务质量预测的客观性、准确性,一个广泛采用的策略就是利用其他曾使用过该服务的用户的评价信息作为服务质量预测的依据。其中,最简单的计算方法就是采用算法平均值法,将各评价用户提交的服务质量(QoS)评价信息的算术平均值作为该服务质量的预测值。但应用这种方法进行服务质量预测时,有个重要前提,就是要保证各用户反馈的评价信息都是真实可靠的。而在实际环境中,由于受到各种因素的影响,这个使用前提可能无法得到有效保证。如有些用户为了提高自身所提供服务的利用率,可能在反馈评价中有意降低其他相关服务的质量评价;而有些用户也可能被服务提供者收买,而在反馈评价中故意提高这些服务的质量评价,从而影响用户反馈信息的可信性,致使用户反馈信息的可信度下降。这就需要我们在进行服务质量预测时,利用用户的信誉度对这些数据进行区别处理。目前,关于Web服务质量预测领域,已经有一些学者专家进行了研究。其中Zeng等[2]提出过2种服务质量(QoS)驱动的服务优化选择方法,但这2种方法的选择依据也只是所有用户评价数据的算术平均,而没有考虑用户评价数据的可信性。Doshi等[3]还提出了一种考虑服务质量动态变化的服务质量(QoS)度量方法。但该方法只有在服务质量发生变化时,才能够较快地得到相对准确的预测值,而且该方法还依赖于特定的度量方法,不具有通用性。Shao等[4]也提出过一种基于协同过滤的个性化服务质量(QoS)预测方法,该方法主要是依据相似消费者的历史经验来对某消费者需要使用的服务进行个性化服务质量(QoS)预测,但该方法中相似度计算只能解决线性相关关系,且没有考虑虚假服务质量(QoS)信息对服务质量预测的影响。另外,将Web服务信誉度应用于服务发现与选择的过程也已经受到一定重视[5-7],在信誉计算方面取得了一些重要进展,提出了简单加权平均模型、贝叶斯模型、离散信任模型、模糊模型和相似度计算模型等方法,形成了集中式信誉系统和分布式信誉系统两种信誉体系结构[8-10],但应用信誉机制来对Web服务质量进行预测研究的还比较少。文献[11]依据用户的反馈对服务提供者发布的服务质量(QoS)进行可信性评价,并提出了针对虚假信息的惩罚机制,但该方法未考虑服务使用者自身的可信性;文献[12]同时考虑了服务提供者与服务使用者的可信性,提供了服务质量(QoS)可信指标的计算方法,但该方法将服务质量视为一个静态常量,未考虑其随时间的动态变化情况;文献[13]从直接和间接2个方面研究了服务信誉度的计算方法,并考虑了服务质量的时效性,但忽略了交往次数很少,间接经验不足的服务信誉度的评价方法;文献[14]提出了一种基于历史经验和可信概率的贝叶斯模型,还给出了奖励函数,但该方法偏重于对用户的未来行为进行约束。本文作者针对服务质量属性预测的现实需要,从服务使用者信誉度的角度出发,建立一种基于信誉度的Web服务质量预测方法,并对服务用户信誉度的计算方法以及基于信誉度的服务质量属性的具体计算过程进行详细分析,最后通过实验进一步分析验证了本方法的正确性和有 效性。
1 应用背景
目前,采用服务化的思想进行信息系统构建已成为未来系统发展的必然趋势,而服务的质量属性对系统的整体质量起着至关重要的作用。而对于目前一些已经实现了基于服务质量(QoS)信息进行服务查找功能的UDDI(如UX[15],UDDIe[16]等)来说,在UDDI系统中存储的大多都是用户使用过服务后所提交的服务质量(QoS)信息的平均值。基于这种方式获取的服务质量信息,虽然在某些情况下能较好的反映服务的质量情况,但是这种方法并没有考虑各服务用户的个体情况,也无法有效防止虚假反馈信息的影响,因此可能造成服务质量信息预测的重大偏差。
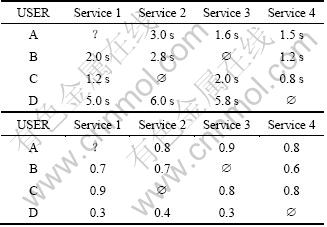
例如某用户A向具有服务质量(QoS)信息查找功能的扩展UDDI系统请求一个网上订票的Web服务,若该扩展UDDI系统中已经存储了4个具有这种功能的订票服务(Service1~Service4),同时该UDDI中还分别存放了4个服务用户(USER A~USER D)对这4个服务的服务质量(QoS)信息的使用反馈(如表1所示(这里仅用响应时间和可用性2项为例来说明服务的服务质量(QoS)信息,其中第1项为响应时间、第2项为可用性)),表中空白的方格就表示对应的用户未曾使用过相应的服务。由表1可知:USER A曾经使用过Service 2、Service 3和Service 4,但未曾使用过Service 1。在这种情况下,USER A若想获取Service 1的质量属性,通常情况下UDDI系统就会以其他用户的反馈平均值,即响应时间(2.0+1.2+5.0)/3=2.73 s,可用性(0.7+0.9+0.3)/3=0.63作为USER A对Service 1的质量属性预测。
表1 存储在UDDI中的服务质量信息
Table 1 Quality information of Service Storing in UDDI

然而,USER A若采用这种计算方法对Service 1的质量属性进行预测,那所获取的预测结果可能并不准确。如果其中某个用户(如USER D)提供了不可信的服务质量评价信息(也有可能反馈信息是真实的,但由于软硬件设备等因素的影响,致使用户反馈的信息与服务真实的质量信息有一定偏差),那么使用上述方法得出的预测结果就无法反映服务真实的质量信息。于是,在进行服务质量预测时,就不应该采用该用户的反馈信息,即使被采用,也应该尽量降低该信息对最终服务质量预测信息的影响。因此,在进行服务质量预测时,一种比较合理的计算方法就是对各用户的反馈信息进行区别对待,先对用户所提供信息的可信度进行判断(即进行用户的信誉度评价),区分出不同用户的信誉等级,然后在进行服务质量预测时,对信誉度等级较高的用户所提供的数据赋予较大的权重,而降低那些信誉度等级较低的用户反馈信息的权重,从而提高最终服务质量预测的准确性。
2 服务质量信息的预测方法
本文采用如下思想进行服务质量的预测:以用户所提供的服务质量(QoS)评价信息为依据,在某用户需要对服务质量属性进行预测时,先比较该用户与其他用户所提供的历史服务质量(QoS)评价信息,在此基础上,为各个曾使用过该服务的用户的信誉度等级进行合理划分,并按照信誉度等级的高低为各评价信息赋予相应的权重,从而提高可信数据在进行服务质量预测时的利用率,增强预测数据的准确性。
因此,本文所提供的方法主要包含以下几个主要步骤:
(1) 数据预处理;
(2) 评价用户信誉度等级划分;
(3) 评价用户信誉度等级计算;
(4) 服务质量预测。
其中数据预处理的目的就是将获取的服务质量信息进行初步整理,并消除噪声数据的影响;信誉度等级的划分是依据实际问题的需要,确定用户的信誉度等级的划分个数;信誉度等级的计算就是依据用户反馈的服务质量评价信息对用户的信誉度进行测算;服务质量预测就是计算确定最终服务质量属性的预 测值。
2.1 问题描述
为了便于本文后续的论述,现将本文所需解决的问题形式化描述如下:
(1) WS={S1, S2, …, Sm}表示一组功能相似但具有不同质量属性的Web服务集合。
(2) USER={U1, U2, …, Un}表示所有服务用户的集合。
(3) 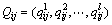 ,1≤i≤n,1≤j≤m,是一个功能向量,表示Ui对Sj的质量评价信息,其中l表示该服务所拥有的服务质量(QoS)属性的个数;
,1≤i≤n,1≤j≤m,是一个功能向量,表示Ui对Sj的质量评价信息,其中l表示该服务所拥有的服务质量(QoS)属性的个数;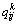 表示Ui对Sj的第k个质量属性值的评价;的取值为实数或空值(
表示Ui对Sj的第k个质量属性值的评价;的取值为实数或空值(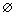 ),若用户使用过该服务,那就表示该用户对第k个服务质量(QoS)属性的使用感受信息,反之,若用户未曾使用过该服务,那就为空值()。
),若用户使用过该服务,那就表示该用户对第k个服务质量(QoS)属性的使用感受信息,反之,若用户未曾使用过该服务,那就为空值()。
(4) 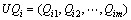 ,1≤i≤n,表示Ui对服务集合WS中所有服务质量的反馈信息,对应于表1中的一行。
,1≤i≤n,表示Ui对服务集合WS中所有服务质量的反馈信息,对应于表1中的一行。
(5)  ,表示了用户集合USER对服务集合WS中各服务质量的反馈信息。
,表示了用户集合USER对服务集合WS中各服务质量的反馈信息。
针对具体问题分析的需要,本文先给出如下定义。
定义1:预测目标服务。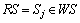 ,表示在进行服务质量预测时所针对的目标服务,表1中服务1就是预测目标服务,或简称目标服务。
,表示在进行服务质量预测时所针对的目标服务,表1中服务1就是预测目标服务,或简称目标服务。
定义2:预测需求用户。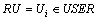 ,表示此次服务质量预测是针对哪一个用户的需求,或者说是由哪个用户发起的服务质量预测,表1中用户A就是预测需求用户,或简称需求用户。
,表示此次服务质量预测是针对哪一个用户的需求,或者说是由哪个用户发起的服务质量预测,表1中用户A就是预测需求用户,或简称需求用户。
定义3:预测目标质量。 ,表示在进行服务质量预测时,需求用户需要获取目标服务哪些方面的质量属性,由前面的形式化描述可知,
,表示在进行服务质量预测时,需求用户需要获取目标服务哪些方面的质量属性,由前面的形式化描述可知,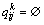 。在表1中,
。在表1中,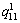 和
和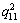 都是预测目标质量,或简称目标质量。
都是预测目标质量,或简称目标质量。
定义4:提供评价用户。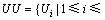
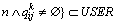 ,表示一组用户的集合,且该用户对预测目标质量的评价都不为空,如表1中,用户B,C和D都是提供评价用户集合中的元素,或简称评价用户。
,表示一组用户的集合,且该用户对预测目标质量的评价都不为空,如表1中,用户B,C和D都是提供评价用户集合中的元素,或简称评价用户。
2.2 数据预处理
采用本文的方法进行服务质量预测时,通常都是指对某个指定的服务质量属性进行预测(若同时要对多个质量属性进行预测,可以逐一使用本方法进行预测)。因此,在进行服务质量预测前,先要对服务的质量属性进行分类处理:
(1) 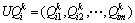 ,1≤i≤n,表示Ui对服务集合WS中第k个质量属性的评价信息;
,1≤i≤n,表示Ui对服务集合WS中第k个质量属性的评价信息;
(2) 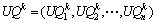 ,表示所有用户对服务集合WS中第k个质量属性的评价信息;
,表示所有用户对服务集合WS中第k个质量属性的评价信息;
(3) 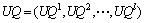 ,从服务质量属性的角度分类表示了服务用户对服务集合WS的质量评价信息,其中l代表了服务质量(QoS)属性的个数。
,从服务质量属性的角度分类表示了服务用户对服务集合WS的质量评价信息,其中l代表了服务质量(QoS)属性的个数。
UQ就是最终数据预处理后的转换结果,表1中数据预处理后的转换结果如表2所示。
表2 预处理后的数据结果
Table 2 Results of data pretreatment
2.3 评价用户信誉等级的划分
信誉的概念最早出现在商业活动领域,是用来对各个商家的诚实度、可靠性、可信性以及所提供产品的质量信息等多方面属性的综合评价。由此可知:在计算用户信誉度时涉及的因素非常多,而且目前关于用户信誉度的评价也没有统一的标准和较好的计算方法。在本文中,出于最终计算的需要,将用户使用某一服务后的评价信息与其真实的感受信息是否吻合作为判断用户信誉等级的重要依据。
在利用用户信誉度对服务质量进行预测前,先要对用户的信誉等级进行合理地划分。对处于不同信誉级别的用户来说,其反馈信息的可信程度也不相同,通常来说,信誉级别越高的用户反馈信息的可信度也就越高,反馈信息也就越可信。本文采用0至1之间的数值来表示用户的信誉度,数值越大表示用户的信誉度越高,0表示不可信用户,而1表示可信用户。为了适应不同应用场景的具体需求,在应用中还引入了信誉度阀值的概念来区分用户是否可信,该值实际上就是用户是否可信的临界点。若某用户的信誉度大于信誉度阀值时,可以认为该用户提供的信息是基本可信的;反之,则表示该用户提供的信息是不可信的。这里用字母W来表示信誉度阀值,字母T来表示所需划分的信誉等级的个数,借鉴标准普尔的评级方法,可以对用户的信誉度等级进行如下区分:
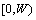 ,
, 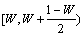 , …,
, …,
 ,
, 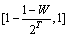
用户的信誉度处于哪个区间就表示该用户的信誉度属于哪个等级,若用户的信誉度处于第一个区间,即表示其信誉度小于信誉度阀值W,则该用户就被认为是不可信用户,而且在进行服务质量预测时应舍弃这部分用户的反馈信息。对于拥有不同信誉等级的用户来说,其反馈信息的价值也不一样,一般来说,用户的信誉等级越高,其反馈的信息也就越可信,相应的权重也就越大;而信誉等级越低,其反馈信息的权重也就越小。为了鼓励用户尽量提供真实可信的评价信息,对用户的行为还实行了“惩罚”机制,一旦发现用户提供虚假的评价信息或实施了欺骗行为,就立即将该用户的信任等级降低几个级别(降低的幅度可根据实际情况进行确定),以此来对用户进行处罚,从而尽量减少欺骗行为的发生。这里各服务用户Ui的信誉等级用符号Li来表示。
2.4 评价用户信誉度的计算
服务用户信誉度的计算是通过衡量该用户对所使用服务的反馈评价信息与用户真实感受情况之间的吻合程度来评判的,但由于用户真实的感受信息难以获取(这需要对分布于网络各处的用户节点都加装相应的实时监控设备,这会极大增加网络的运行维护成本与网络内的数据流量),致使该方法基本不可行。因此,采用需求用户的评价信息来代替用户的真实感受,因为在不考虑外部环境因素(如硬件设备及网络环境)影响的情况下,不同用户对同一服务的感受应该是类似的,也就是说需求用户与评价用户对同一服务的评价信息应该是相似的。于是,可以将需求用户与评价用户就同一服务评价信息之间的相似度作为计算评价用户信誉度的重要依据,若评价用户的质量评价信息与需求用户的评价信息之间的差值在允许的误差范围内,则可以认为该评价用户的评价信息是可信的,否则,就认为评价用户的评价信息是不可信的。实际上,该方法在考虑外部因素影响的情况下也是可行的。若评价用户分别处于不同的网络环境和软硬件条件下,则需求用户也会尽量采用那些与其自身感受类似的评价用户的评价信息作为服务质量预测的依据。因为这些用户与需求用户所处的环境类似,相应的对服务的评价信息也会类似。而那些环境与需求用户相差较大的评价用户,即使提供了真实的感受信息,也会因为其评价信息与需求用户自身的感受信息相差较大,而被认为是不可信的用户,并尽量不使用该信息作为服务质量预测的依据。因此,这里评价用户信誉度实际上是一个相对的概念,对于不同的需求用户而言,同一评价用户的信誉度可能不同。
评价用户信誉度计算的算法描述如下:
Algorithm 评价用户的信誉度计算算法
Input:评价用户
需求用户 RU
目标质量RQ
Output:评价用户的信誉度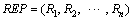
//初始化差异度容忍值和共用服务列表
Initialize: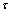 ,
,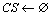
//计算评价用户列表中各评价用户的信誉度
foreach 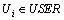 do
do
{
//查找需求用户与评价用户共同使用过的服务
CS=GetCommonService(Ui,RU)
foreach service  do
do
{
//获取需求用户对该服务目标质量的使用评价
RQ=GetQoSValueFromRUser(RU,Si,RQ)
//获取评价用户对该服务目标质量的使用评价
UQ=GetQoSVaulueFromUser(Ui,Si,RQ)
//比较需求用户使用评价与评价用户使用评价的差异程度
dif=CalDifference(RQ,UQ)
//判断差异值是否在允许范围之内
IF dif< then
//计算可信评价的次数
SumRi=SumRi+1
}
//其中Sum(CS)表示共用服务的个数
Ri=SumRi/Sum(CS)
}
return REP
该算法的主要含义是对每个评价用户,先在扩展的服务注册中心(UDDI)中查找该用户与需求用户曾共同使用过的Web服务,然后再获取这两个用户对共用服务质量的使用评价,若两者的差值在一定的范围内(如10%),则认为该评价用户提供的评价信息是可信的,最后再通过统计评价用户反馈的可信评价次数与总的共同评价次数的比值,便可计算出该评价用户的信誉度。需要说明的是:在进行评价信息的差异度衡量时,也可以使用数据正规化处理方法。该方法是先将处于不同区域的数据映射到一个统一的区间中,如高斯法[17]就是先将数据统一映射到区间[0,1]中,然后通过比较该用户的使用评价与均值评价的差值是否在3σ(σ为数据的标准差)范围之内,来判定用户提供的信息是否可信。因为按照高斯分布的规律,99%的数据都应落在3σ范围之内。在表1中,若要计算USER B的信誉度,则可以先获取USER A与USER B对共用服务(Service 2与Service 4)中目标质量属性(响应时间)的评价信息,然后,通过比较这些评价信息的相似度来求出USER B的信誉度。
上述算法的计算过程虽比较简单,但能较好地解决用户信誉度计算的问题。然而,该算法在使用过程中,还存在一个问题就是若评价用户与需求用户之间没有共用服务,该如何确定评价用户的信誉度。在这种情况下,可采用评价用户之间信誉度传递的方法来解决。假设评价用户F与需求用户A之间无共用服务,这时可以先找到一组与需求用户A存在共用服务的评价用户(USERS),再从该组评价用户(USERS)中找出与评价用户F有共用服务且信誉度最高的评价用户(如用户C),然后运用上述算法(将评价用户C看作需求用户)计算出评价用户F相对于评价用户C的信誉度,最后综合评价用户F与评价用户C的信誉度,便可计算得出评价用户F相对于需求用户A的信誉度。在最坏情况下,若所有的评价用户与需求用户都没有共用服务或其中某个评价用户与其他相关的评价用户之间也不存在共用服务的情形下,一般将信誉均值(0.5)作为该评价用户的信誉值。
2.5 服务质量预测
在得到各评价用户的信誉度后,便可利用该信息来对服务的目标质量进行预测。进行服务质量预测的基本过程如下。
(1) 确定评价用户的信誉等级。依据所述的评价用户信誉等级划分方法,并结合各评价用户的信誉度Ri,就可计算出相应的信誉等级Li。用户的信誉度值Ri处于信誉等级的哪个区间,该用户的信誉等级就是该区间所代表的信誉等级。
(2) 确定评价用户评价信息的权重。在确定用户评价信息权重时,所采用的基本原则就是:信誉等级越高的用户,其反馈评价信息的权重就越大,反之就越小。而信誉等级相同的用户,其反馈信息的权重也相同。具体可采用如下的计算公式来确定各评价用户评价信息的权重:
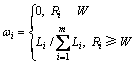
其中:Ri<W表示该用户的信誉度小于信誉度阀值,也就是说该用户是不可信用户,其所反馈的信息是无效信息,因此,该信息的权重为0。
(3) 预测服务目标质量。服务质量预测的结果就是以上述各用户评价信息的权重为基础,对各评价用户提交的关于目标质量数据的加权平均,具体的计算公式如下:
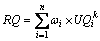
其中: 表示评价用户Ui的权重;
表示评价用户Ui的权重;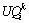 表示评价用户Ui提交的对目标质量RQ的感受程度。
表示评价用户Ui提交的对目标质量RQ的感受程度。
上述计算公式充分考虑了不同评价用户信誉度对最终服务质量预测的影响,即使在最坏情况下,即无法通过计算获取任意一个评价用户的信誉度时(这时强制指定各评价用户的信誉度都为0.5),采用该方法计算得出的服务质量预测值与算法平均值法的计算结果也是相同的。但若可以通过计算确定其中一些评价用户的信誉度,那将可以有效提高服务质量预测的准确性,下面通过实验来进行验证。
3 实验与结果分析
为了验证本文提出的服务质量预测方法的可行性与准确性,本节特设计了一组仿真实验,用以检验算法对服务质量预测的准确性,并证明该方法的有效性。
3.1 实验环境设置
本文选择ExUDDI[18]原型系统作为服务的注册中心和服务代理,其实现框架如图1所示。ExUDDI系统的主要功能是完成Web服务的注册发布、收集用户提交的服务质量(QoS)信息以及在此基础上进行用户信誉度计算和服务质量预测。
其中,服务注册模块主要负责服务的注册,服务用户通过用户代理在ExUDDI中查找合适的服务并进行调用。
信息收集工具主要用来收集用户调用服务后的使用评价数据,其收集信息的内容主要包括评价用户的ID、所调用服务的ID以及相关的服务质量(QoS)信息,若评价用户的ID和所调用服务的ID相同,则可以认为是同一用户对同一服务的多次调用。

图1 ExUDDI上的实现框架
Fig.1 Realization frame based on ExUDDI
QoS预处理模块和Qos计算模块负责对用户提交的服务质量(QoS)数据进行初步的计算和预处理,并存储在ExUDDI中。
信誉度计算模块主要负责依据ExUDDI中存储的相关评价用户的评价信息,计算各评价用户的信誉度,并对信誉度数据库中的数据进行更新。
信誉度数据库表示一个数据库,用来存储评价用户信誉度的相关信息。
服务质量属性预测模块主要是利用用户的信誉度以及用户提交的评价信息,来对服务的质量(QoS)属性进行预测。在该模块中共集成了2种服务质量预测的方法:一种是算术平均值法,另一种就是本文提出的方法。运用前一种方法进行服务质量预测时,就是将各评价用户提交的目标质量评价信息的平均值作为预测结果;而后一种方法就是以信誉度数据库中的各评价用户的信誉度以及各评价用户提交的目标质量评价信息为基础,并使用本文所提出的算法计算得出服务质量的预测值。
3.2 实验方案说明
由于目前还没有标准的测试平台与测试数据集,因此本文采用了模拟服务数据作为测试用例。为了实验需要,模拟产生了50个服务。这50个服务主要提供5种主要功能,对应于每种功能各有10个性能指标各不相同的服务能满足其需求。另外,还编写了服务调用代理程序(对应上述框架中的用户代理模块和信息收集模块),该程序负责模拟不同的用户,并可以依据不同用户的实际需求选择调用所需的服务,在完成服务调用后还可以将服务质量信息反馈至ExUDDI。为了防止1次随机调用的偶然误差对整体服务质量信息的影响,在实验中每个用户都对其中随机选取的40个服务调用100次,并将这些信息的平均值作为ExUDDI中的用户反馈信息的记录值。
在本实验中主要以响应时间和可用性这两个服务质量(QoS)属性为例来进行验证。其中响应时间是指用户发出消息与用户收到消息之间的时间间隔,即:

其中:Tdelay为响应时间;Tsend为发出消息的时间;Treceive为接收消息的时间。
可用性是指用户对某服务成功调用的次数与调用该服务的总次数之间的比值,即:
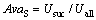
其中:AvaS为服务S的可用性;Usuc为成功调用的次数;Uall为调用的总次数。
在实验中,为了模拟实际环境中不同信任程度的用户,对ExUDDI中记录的数据进行一些人工处理。在ExUDDI中对每个用户都存储了2类反馈信息,其中一类是服务用户的真实感受信息,另一类是在真实感受信息的基础上人为进行了一些调整而生成的模拟数据(为了模拟恶意用户)。比如有一种调整方案就是对其中任意10%用户的数据在真实数据的基础上进行了偏差幅度大于50%的修改,40%用户的数据在真实数据的基础上随机进行了偏差幅度在0~50%之间修改,剩余50%用户的信息则没有进行修改,而在进行用户的信誉度评判时则以这些修改后的数据作为依据,同样在进行服务质量预测时也是采用修改后的数据进行计算。
实验方案的基本设想就是将所要预测的数据(真实数据)排出在外,然后利用剩下的数据(模拟数据)来对目标质量进行预测,并通过衡量不同方法所产生的预测数据与真实数据之间的相似程度来判断方法的优劣。另外,为了分析不同数量的虚假信息对最终服务质量预测的影响,每次实验时都假设x%(x以10为步长,从0到80)的用户提供了虚假信息(其虚假信息与真实信息的差异幅度在0%与100%之间随机变化),并且为了保证每次实验的可信性,针对每个x的取值,反复进行10次实验。在每次实验时,分别记录已知的真实信息与通过预测获知的预测信息。其中: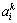 表示针对第i个x取值的实验中所保留的第k个质量信息的真实值;
表示针对第i个x取值的实验中所保留的第k个质量信息的真实值;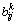 表示针对第i个x取值的第j次实验中对第k个质量信息的预测值。
表示针对第i个x取值的第j次实验中对第k个质量信息的预测值。
在本实验中,主要将本文所提出的算法与算术平均值法进行比较,并且采用2个评价指标来进行分析。
其中一个评价指标就是平均误差。其含义就是通过统计针对某个具体的x取值,在10次实验中所获取的预测值与真实值之间差值之和并进行平均,其数学函数表达如下:
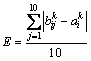
该评价指标通过统计比较各次实验的误差和,能够从全局上对算法的好坏进行衡量。但该评价指标也存在一个不足之处,就是若在某组实验中,其中有一次实验产生的误差很大而其他实验的误差都很小的话,那么其最终的误差结果也可能很大,从而影响对算法的评价。因此,又提出了另一个评价指标:误差精确率,就是指在针对某个具体x取值所采取的实验中,其所获取的预测值与真实值的偏差程度小于容忍值的次数占总实验次数的比例。这里认为服务质量预测值与其真实值的差异若在某个范围之内(在本实验中容忍值取10%),便可认为这次预测的结果是正确的。其数学函数表达如下:
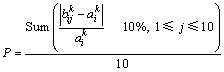
其中: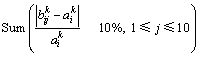 ,表示统计在
,表示统计在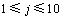 时,
时,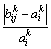 <10%出现的次数。
<10%出现的次数。
3.3 实验结果分析
3.3.1 平均误差分析实验
图2(a)和图2(b)分别所示为算术平均值法与本算法在平均误差时的统计比较。图2中横坐标表示虚假用户在全体用户中所占的比例,纵坐标是平均误差。从图2可以看出:2种算法随着虚假反馈信息的增加,其平均误差都有所增加,但算术平均值法增加的幅度更为明显。而本文所提出的算法在总体上其误差程度都要小于算术平均值法,当虚假用户的比例小于20%时,算术平均值法与本文算法所产生的误差相差不是很明显,但随着虚假用户比例的加大,误差的差距也是越来越大。其原因是因为算术平均值法没有考虑虚假用户反馈信息的影响。
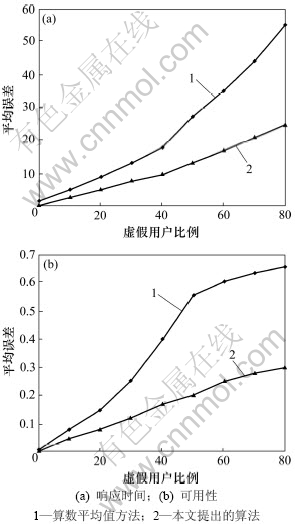
图2 2种不同的预测方法产生平均误差的比较
Fig.2 Comparison of average difference produced by two different prediction methods
3.3.2 误差精确率分析实验
图3(a)和图3(b)分别所示为算术平均值法与本算法在误差精确率方面的统计比较。同样图3中横坐标表示了虚假用户在全体用户中所占的比例,纵坐标是误差精确率。从图3可以看出:2种算法随着虚假反馈信息的增加,其误差精确率都呈下降趋势。尤其是算术平均值法,当虚假用户的比例大于60%时,其误差精确率都在15%以下,也就是说很难准确预测出服务的质量属性。而本文所提出的算法总体上也是优于算术平均值法。
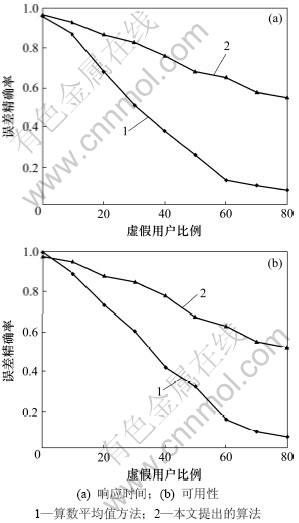
图3 2种不同的预测方法误差精确率的比较
Fig.3 Comparison of difference precision rate on two different prediction methods
4 结论
(1) 从服务用户信誉度的角度提出一种新型的服务质量预测方法。该方法的核心是在服务质量预测时区分了不同信誉等级用户反馈信息的权重。针对目前服务质量预测大多采用算术平均值法,提出了服务用户信誉度等级的计算方法,并依据用户的信誉等级确立用户评价信息的计算权重,然后,在此基础上综合得出服务质量的预测信息。实验结果表明:本文提出的方法在平均误差和误差精确率等方面都优于算术平均值法,预测的准确性得到了有效提高。
(2) 对用户信誉度的评价方法有待进一步深入研究,研究不同的信誉度等级区分方法以及信誉度阀值对服务预测质量的影响。另外,由于本文所进行的实验还只是在局域网范围内,具体在实际的广域网环境下算法的效果如何,还有待进一步研究分析。
参考文献:
[1] 胡春华, 吴敏, 刘国平. Web服务工作流中基于信任关系的QoS调度[J]. 计算机学报, 2009, 32(1): 42-53.
HU Chun-hua, WU Min, LIU Guo-ping. QoS scheduling based on trust relationship in Web service workflow[J]. Chinese Journal of Computers, 2009, 32(1): 42-53.
[2] Zeng L Z, Benatallah B, Ngu A H H, et al. QoS-Aware middleware for Web services composition[J]. IEEE Transactions on Software Engineering, 2004, 30(5): 311-327.
[3] Doshi P. Dynamic workflow composition using Markov decision processes[C]//IEEE International Conference on Web Service (ICWS 2004). Chicago, USA: IEEE Computer Society, 2004: 576-582.
[4] Shao L S, Zhang J, Wei Y, et al. Personalized QoS prediction for Web services via collaborative filtering[C]//IEEE International Conference on Web Service (ICWS 2007). Salt Lake City: IEEE Computer Society, 2007: 439-446.
[5] Hamadi R, Benatallah B. A Petri net-based model for Web service composition[C]//Proceedings of the Australasian Database Conference. Adelaide, Australian, 2003: 191-200.
[6] Zhang R, Arpinar B, Aleman-Meza B. Automatic composition of semantic Web services[C]//Proceedings of International Conference on Web Services. Las Vegas, USA, 2003: 38-41.
[7] Liu Y T, Ngu A H H, Zeng L Z. QoS computation and policing in dynamic Web service selection[C]//Proceedings of the 13th International World Wide Web Conference (WWW 2004). New York: ACM Press, 2004: 66-73.
[8] Jang S, Ma L R, Bo Y D. A survey of trust and reputation systems for online service provision[J]. Decision Support Systems, 2007, 43(2): 618-644.
[9] Fu X D, Zou P, Jiang Y, et al. QoS consistency as basis of reputation measurement of web service[C]//Proceedings of the First International Symposium on Data, Privacy and E-Commerce. Chengdu, China: IEEE Computer Society Press, 2007: 391-396.
[10] Hart E, Timmis J. Application areas of AIS: The past, the present and the future[J]. Applied Soft Computing, 2008, 8(1): 191-201.
[11] Tian M, Gramm A, Ritter H, et al. Efficient selection and monitoring of QoS-aware Web services with the Ws-QoS framework[C]//IEEE/WIC/ACM International Conference on Web Intelligence (WI 2004). Beijing: IEEE Press, 2004: 152-158.
[12] Shuping R. A model for Web services discovery with QoS[J]. ACM SIGCOM Exchanges, 2003, 4(1): 1-10.
[13] Jurca R, Binder W, Faltings B. Reliable QoS monitoring based on client feedback[C]//Proceedings of Sixteenth International World Wide Web Conference (WWW 2007). Banff, Alberta, Canada: ACM Press, 2007: 1003-1011.
[14] 李研, 周明辉, 李瑞超, 等. 一种考虑QoS可信性的服务选择方法[J]. 软件学报, 2008, 19(10): 2620-2627.
LI Yan, ZHOU Ming-hui, LI Rui-chao, et al. Service selection approach considering the trustworthiness of QoS data[J]. Journal of Software, 2008, 19(10): 2620-2627.
[15] Zhou C, Chia L T, Silverajan B, et al. UX: An architecture providing QoS-aware and federated support for UDDI[C]// Proceedings of the 2003 Symp on Applications and the Internet Workshops. Las Vegas: IEEE Computer Society, 2003: 171-176.
[16] ShaikhAli A, Rana O F, Al-Ali R, et al. UDDIe: An extended registry for Web services[C]//Proceedings of the 2003 Symp on Applications and the Internet Workshops. Las Vegas: IEEE Computer Society, 2003: 85-89.
[17] Ortega M, Rui Y, Chakrabarti K, et al. Supporting ranked Boolean similarity queries in MARS[J]. IEEE Transactions on Knowledge and Data Engineering, 1998, 6(10): 905-925.
[18] 郭得科, 任彦, 陈洪辉, 等. 一种QoS有保障的Web服务分布式发现模型[J]. 软件学报, 2006, 17(11): 2324-2334.
GUO De-ke, REN Yan, CHEN Hong-hui, et al. A QoS-guaranteed and distributed model for Web service discover[J]. Journal of Software, 2006, 17(11): 2324-2334.
(编辑 杨幼平)
收稿日期:2011-05-17;修回日期:2011-08-03
基金项目:国防预研重点基金资助项目(9140A06020407KG0127);国家自然科学基金资助项目(71071160,61070216)
通信作者:舒振(1977-),男,江西上饶人,博士研究生,讲师,从事指控系统总体技术、服务计算等研究;电话:13574802777;E-mail: sz_1226@sina.com

