Improved pedestrian detection with peer AdaBoost cascade
��Դ�ڿ������ϴ�ѧѧ��(Ӣ�İ�)2020���8��
�������ߣ����� ������ �ޱ��� ������ ������ ����
����ҳ�룺2269 - 2279
Key words��peer classifier; hard negative refining; pedestrian detection; cascade
Abstract: Focusing on data imbalance and intraclass variation, an improved pedestrian detection with a cascade of complex peer AdaBoost classifiers is proposed. The series of the AdaBoost classifiers are learned greedily, along with negative example mining. The complexity of classifiers in the cascade is not limited, so more negative examples are used for training. Furthermore, the cascade becomes an ensemble of strong peer classifiers, which treats intraclass variation. To locally train the AdaBoost classifiers with a high detection rate, a refining strategy is used to discard the hardest negative training examples rather than decreasing their thresholds. Using the aggregate channel feature (ACF), the method achieves miss rates of 35% and 14% on the Caltech pedestrian benchmark and Inria pedestrian dataset, respectively, which are lower than that of increasingly complex AdaBoost classifiers, i.e., 44% and 17%, respectively. Using deep features extracted by the region proposal network (RPN), the method achieves a miss rate of 10.06% on the Caltech pedestrian benchmark, which is also lower than 10.53% from the increasingly complex cascade. This study shows that the proposed method can use more negative examples to train the pedestrian detector. It outperforms the existing cascade of increasingly complex classifiers.
Cite this article as: FU Hong-pu, ZOU Bei-ji, ZHU Cheng-zhang, DAI Yu-lan, JIANG Ling-zi, CHANG Zhe. Improved pedestrian detection with peer AdaBoost cascade [J]. Journal of Central South University, 2020, 27(8): 2269-2279. DOI: https://doi.org/10.1007/s11771-020-4448-1.

J. Cent. South Univ. (2020) 27: 2269-2279
DOI: https://doi.org/10.1007/s11771-020-4448-1
FU Hong-pu(������)1, 2, 3, ZOU Bei-ji(�ޱ���)1, 3, ZHU Cheng-zhang(����)1, 4, 5,
DAI Yu-lan(������)1, 5, JIANG Ling-zi(������)1, 3, CHANG Zhe(����)1, 5
1. School of Computer Science and Engineering, Central South University, Changsha 410083, China;
2. School of Information Science and Engineering, Hunan First Normal University,Changsha 410205, China;
3. Hunan Province Engineering Technology Research Center of Computer Vision and Intelligent Medical Treatment, Changsha 410083, China;
4. School of Literature and Journalism, Central South University, Changsha 410083, China;
5. Mobile Health Ministry of Education-China Mobile Joint Laboratory, Changsha 410083, China
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2020
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2020
Abstract: Focusing on data imbalance and intraclass variation, an improved pedestrian detection with a cascade of complex peer AdaBoost classifiers is proposed. The series of the AdaBoost classifiers are learned greedily, along with negative example mining. The complexity of classifiers in the cascade is not limited, so more negative examples are used for training. Furthermore, the cascade becomes an ensemble of strong peer classifiers, which treats intraclass variation. To locally train the AdaBoost classifiers with a high detection rate, a refining strategy is used to discard the hardest negative training examples rather than decreasing their thresholds. Using the aggregate channel feature (ACF), the method achieves miss rates of 35% and 14% on the Caltech pedestrian benchmark and Inria pedestrian dataset, respectively, which are lower than that of increasingly complex AdaBoost classifiers, i.e., 44% and 17%, respectively. Using deep features extracted by the region proposal network (RPN), the method achieves a miss rate of 10.06% on the Caltech pedestrian benchmark, which is also lower than 10.53% from the increasingly complex cascade. This study shows that the proposed method can use more negative examples to train the pedestrian detector. It outperforms the existing cascade of increasingly complex classifiers.
Key words: peer classifier; hard negative refining; pedestrian detection; cascade
Cite this article as: FU Hong-pu, ZOU Bei-ji, ZHU Cheng-zhang, DAI Yu-lan, JIANG Ling-zi, CHANG Zhe. Improved pedestrian detection with peer AdaBoost cascade [J]. Journal of Central South University, 2020, 27(8): 2269-2279. DOI: https://doi.org/10.1007/s11771-020-4448-1.
1 Introduction
As a popular topic in computer vision, pedestrian detection can be used to assist various applications [1, 2], such as human gait recognition, human identification, traffic surveillance [3] and vehicle navigation. The detection problem is challenging, due to appearance variation between pedestrian examples in different poses, clothes, scales, viewpoints, and other situations and data imbalance.
Numerous models have been proposed for pedestrian detection. Rigid models [4, 5] express pedestrians as single vectors, which are easy to train and fast in detection. These models have achieved considerable success for large pedestrians in simple scenes. Fusing multi-modal visual or other information can improve the performance of rigid models [6]. However, they ignored the deformation of pedestrians and therefore usually failed to detect the pedestrians under variable poses [4, 7]. To make the pedestrian detector invariant to poses, the deformable part-based model (DPM) [7] was proposed, which represented the appearance of human body parts and deformation constraints between them integrally and uses the latent SVM to make use of latent information for optimal training. In recent years, deep neural networks have also been used in pedestrian detection. Deep networks detected pedestrians more accurately, with high computation cost [1, 2, 8].
One key challenge in pedestrian detection is the vast intraclass variation in pedestrians in natural scenes. As pedestrian examples are highly variable, it is very difficult to represent them in one space. Therefore, a single complex model is insufficient to model the pedestrian category. To characterize the complicated intraclass variation, the mixtures of models are proposed for pedestrian detection [7, 8]. The underlying principle of these methods is that a complicated category should be treated as different subcategories. Though those methods achieve great successes [7, 8], they reached a performance plateau when detecting pedestrians in cluttered scenes. Additionally, their performances became worse when the background interacts with the pedestrians largely. These methods allocated pedestrian examples into the subcategories heuristically [7, 9], which cannot treat variable pedestrian examples adaptively. Dividing the pedestrian category into subcategories is still a challenging problem. It is observed that the cascade of AdaBoost classifiers performs slightly better than the mixture of DPM [10]. Therefore, it is reasonable to conjecture that the cascade structure is potential to treat intraclass variation.
When training these detectors, the data imbalance is another severe problem [11, 12]. In the training dataset, the number of pedestrians in one image is small, while that of the negative examples (i.e., background) is too large. If all the negative examples are used for training, the detector will reach low training loss by simply labeling all the examples as background. However, the accuracy of pedestrian detection is sacrificed and unacceptable. To alleviate the adverse impact from the data imbalance, data resampling was usually applied [13]. Thus, only part of the negative examples is used for training. As a resampling strategy, negative mining [4, 5, 7] was widely adopted in pedestrian detection, which added the false positives of the just-trained detector as new negative training examples. To keep the number stable, part of the used negative training examples was discarded, and a limited number of false positive examples were added to the training set at each iteration. After several iterations, a relatively small number of representative negatives were collected for training, which kept training data balance and saved some representativeness of negative examples. However, it decreased the diversity of negative examples, which may lead to the loss of detection accuracy. A region proposal network (RPN) [14] was usually used to compute pedestrian candidates in deep models. The candidates covered the majority of ground-truth pedestrians while also introduced a large number of false positives. Therefore, the data imbalance was still existed.
A cascade structure was usually used to speed up pedestrian detection [11, 15-17]. In these methods, a single strong pedestrian detector was first learned. Using its performance as the target, presetting the number of stages, false positive and detection rates for each stage in the cascade were determined. Then, a series of stage classifiers were trained by adjusting their thresholds. Finally, by cascading these classifiers, a cascade structure was constructed. In addition, the complexity of the classifiers in cascade was strictly controlled to successively increase. The complexity of classifiers in the early stages was low, while the complexity in the late stages increased as the stages progressed. Therefore, when detecting, the majority of negative examples were rejected by simple classifiers at early stages. Thus, only a small number of promising examples required heavy computation, which further accelerated detection. Although it is a good idea, the increasingly complexity structure makes training difficult. It also makes the number of negative examples used for training close to that of training a single strong detector. Therefore, the improvement of the detection accuracy after cascading is not significant.
To solve the above issues, the cascade of complex peer classifiers, specifically AdaBoost classifiers, was proposed for pedestrian detection. The complexity of each classifier is determined by the training examples, which are not limited. First, we mine as many negative training examples as possible to represent the whole negative space by searching the non-pedestrian data. Second, at each iteration in the training procedure, negative examples are mined that are never used in previous iterations. In this way, the classifiers learned in stages are completely different from each other, which causes the cascade to treat the interclass more effectively. Finally, by combining all the trained peer classifiers, the pedestrian detector is obtained. To guarantee that each classifier is trained locally and keep its detection rate high, refining the negative example training set is proposed, by discarding some of the hardest samples rather than decreasing the thresholds of the stage classifiers.
The main contributions of this paper are four-fold:
1) Cascading complex peer AdaBoost classifiers is proposed for improved pedestrian detection. The negative examples are used more efficiently in the proposed method than existing resampling strategies.
2) Refining the negative examples during training is proposed to maintain a high positive recall rate. In contrast to directly adjusting the thresholds of stage classifiers, the generalization guarantee provided by the AdaBoost is preserved.
3) The strategy of the proposed method does not limit the complexity of AdaBoost classifiers in stages. The AdaBoost classifiers in stages are trained locally; thus, training the cascade becomes easy. A similar strategy is used on ensemble convolutional neural networks (CNNs) where each CNN is trained randomly with varying parameters [18].
4) The proposed method is superior to the cascade of increasingly complex AdaBoost classifiers in terms of the miss rate.
The remainder of this paper is organized as follows. Section 2 describes the proposed method; Section 3 describes the algorithms to train the cascade of complex peer AdaBoost classifiers; Section 4 provides the results of the experiments; and Section 5 summarizes the work.
2 Proposed method
Focusing on data imbalance and large intraclass variation, the goal of this work is to learn a detector with high detection accuracy by constructing a cascade of complex peer AdaBoost classifiers. Contrasting to increasingly complex AdaBoost cascade, the proposed one has two different aspects. First, the complexity of the AdaBoost classifiers in stages is not limited. Thus, more training negative examples are used. Second, hard negative refining is introduced in training process. The optimized thresholds of the AdaBoost classifiers are kept. These classifiers can keep strong and be different from each other. So, the cascade becomes more powerful and is robust to intraclass variation. As described in this section, the training of the proposed cascade is easier than the increasingly complex one.
In the following subsections, the AdaBoost classifier used in proposed method is first introduced, which is named as ��peer AdaBoost classifier��. Then, the optimization framework of the cascade is reviewed; the proposed method is introduced; and the optimization of the peer complex cascade is discussed. The refining negative operation is also introduced here.
2.1 Peer AdaBoost classifier
An AdaBoost classifier consists of many weak classifiers [19, 20]:
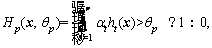
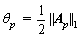 (1)
(1)
where ht is a weak classifier; ��t is its weight; and np is the number of weak classifiers in the AdaBoost classifier Hp. ��x? a:b�� is a ternary operator; if its first operand x is true, then return the value of the second operand a; else, return the value of the third operand b. Ap is the weight vector of all the weak classifiers in Hp; and || ||1is one norm that calculates the sum of modulus of all elements in a vector.
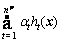 is the response of the classifier Hp to the example x. The output of an AdaBoost classifier is a logic value. An AdaBoost classifier is trained by minimizing the error in training positive and negative example set:
is the response of the classifier Hp to the example x. The output of an AdaBoost classifier is a logic value. An AdaBoost classifier is trained by minimizing the error in training positive and negative example set:
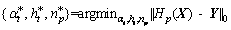 (2)
(2)
where X is the training dataset and Y is its true label; and || ||0 is zero norm, calculating the number of non-zero elements of a vector.
The AdaBoost algorithm optimizes Eq. (2) by an adaptive boosting training procedure [21]. In the training procedure, to emphasize those examples that are incorrectly classified, they are reweighted based on the loss vector of training examples after each round. The weight of each weak classifier is set as the logarithm of the ratio of its training accuracy and error rate. The threshold of the trained AdaBoost classifier is set as half of the sum of weights of all weak classifiers, as shown in Eq. (1). It is well known that, by doing so, the theoretical guarantee provided by the AdaBoost training procedure is strong [20, 22].
However, in the increasingly complex cascade, the AdaBoost classifiers are inferior to some degree. First, the numbers of the weak classifiers of stages are selected by hand to keep them in ascending order. They are usually not the optimum. Second, after training, the increasingly complex cascade thresholds the AdaBoost classifier with a small threshold value such that almost all the pedestrian examples are classified correctly. By doing so, the theoretical guarantee provided by the AdaBoost training procedure is broken.
The threshold and the number of weak classifiers of each peer AdaBoost classifier are the optimums of Eq. (2), which partly benefit from not limiting the complexity. In our peer complex cascade, the AdaBoost classifiers are trained using the same set of positive examples and different negative examples of peer hardship. It is expected that complex peer AdaBoost classifiers have peer detection performance. However, when only randomly extracted negative examples with fixed size are used in training, the detection performance of the AdaBoost classifier is not as good. Nevertheless, this AdaBoost classifier can reject many negative examples easily. For example, in the Inria pedestrian dataset [4], the number of negative examples with fixed size (64��32 pixels) randomly extracted from an image is more than 1600, while for those mined by the AdaBoost classifier trained using these negative examples, the number of negative examples in multi-scale sizes is no more than 650 for any image. Such an AdaBoost classifier can be used to speed up detection. The AdaBoost classifiers in stages are powerful in the peer complex cascade. The AdaBoost classifiers in the peer complex cascade are called peer AdaBoost classifiers in this paper.
2.2 Cascade of peer AdaBoost classifiers
For the cascade, the overall form of the detection process is that of a degenerated decision tree [19]. A positive result from the former stage triggers the evaluation of the AdaBoost classifier in the next stage. A negative outcome at any stage leads to the immediate rejection of the example. This is also the fact for our cascade of the peer AdaBoost classifiers, and it is illustrated in Figure 1. The character ��F�� represents that a stage predicts example x as a negative example and ��T�� as a pedestrian. A cascade consisting of S classifiers can be defined as follows:
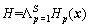 (3)
(3)
where �� is the ��AND�� operator; p is the serial index of stages; and S is the total number of stages. An AdaBoost classifier Hp(x) is ��AND�� with the next classifier in a short-circuit way, and the ��AND�� evaluates classifiers in succession.
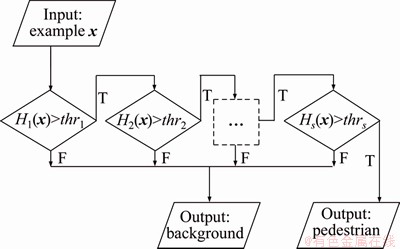
Figure 1 Detection procedure of peer AdaBoost cascade
For a cascade of classifiers, similar to a decision tree, subsequent classifiers are trained using negative examples that pass through all the previous stages. To minimize the error and complexity of a cascade, one can define the optimization framework by trading off the following three items [19]:
1) The number of classifier stages, S.
2) The complexity of each stage, Cp. Considering that each stage classifier is an AdaBoost classifier, it is replaced by the number of weak classifiers, np, in this paper.
3) The threshold of each stage, ��p.
For the cascade of increasingly complex AdaBoost classifiers, there is an additional limitation for the length of stages. Therefore, strictly, this type of cascade should be defined as:
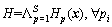 j
j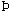
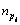 <
<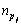 (4)
(4)
where pi is the serial index of the stage classifier Hpi(x); npi is the number of its weak classifiers.
With this extra limitation, the optimization is tremendously difficult [19]. A non-optimal method is usually adopted. First, a strong AdaBoost detector is trained to determine the target false positive rate F and detection rate D. Then, after determining the number of stages by hand, the detection and false positive rate for each stage are set up. Then, the number of weak classifiers at each stage is carefully adjusted several times to satisfy the limitation of increasingly complexity. Moreover, the thresholds of the AdaBoost classifiers are lowered by hand to obtain a high detection rate, which makes the classifiers inferior.
The proposed method is different from those increasingly complex cascade methods. The complexity of the classifiers is not limited. In the proposed peer cascade, the complexity constraint between AdaBoost classifiers is eliminated and the optimization function is rewritten in the following form:
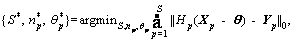
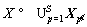 (5)
(5)
where Xp is the training dataset and Yp is the true label in stage p. With negative mining, the peer AdaBoost classifiers can be trained locally one by one. Thus, the optimization becomes:
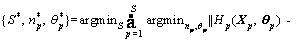
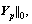
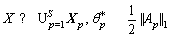 (6)
(6)
In each stage, we train the AdaBoost classifier based on the current training examples and optimize np* and ��p*locally. The training stops when the negative examples that can be used in training are less than a threshold.
2.3 Refining hard negative examples
In a cascade, an example is labeled as negative as soon as it is rejected by a stage classifier. In a soft cascade, subsequent stages make use of evaluating information of all the prior stages. And an example is also discarded as soon as it is rejected. So it is very important to keep the detection rate of positive examples high for each peer AdaBoost classifier. The AdaBoost algorithm does not aim to optimize for a high recall rate. When the training dataset contains too many hard negative examples, the learned classifier is more likely to erroneously label the positive examples, which are similar to those hard negative examples as negative examples. As a result, the trained AdaBoost classifier erroneously labels similar pedestrian examples as background, and the detection rate becomes lower. To keep the detection rate high, we proposed removing some negative examples with the highest response from the negative example training set and training the AdaBoost classifier again with a smaller negative example set. This removing operation is named ��refining�� hard negative training example. The experimental results show that refining operation can increase the recall rate efficiently. Please note that the removed negative examples will be discriminated from positive examples by the following stages.
In the increasingly complex cascade framework, as the training progresses, the simple negative examples are discarded in the early stages, while the harder negative examples are retained, which makes the classification task increasingly difficult. This is an obstacle for training [17]. However, in our peer complex cascade, the difficulty of the classification tasks for each stage is almost the same; thus, the training difficulty decreases.
3 Training peer AdaBoost classifier cascade
Without the limitation of increasingly complexity for AdaBoost classifiers, training peer cascades is a greedy procedure, along with negative mining. The AdaBoost classifiers are trained locally one by one based on the current training examples. All the positive examples are used in each stage, and the number of negative examples is limited to match that of the positive training examples. The first used negative training examples are randomly extracted from non-pedestrian data. Those used subsequently are mined by the cascade of the trained AdaBoost classifiers, that is, those negative examples misdetected as positive.
As mentioned above, our philosophy is to fully use negative examples, and the training of the peer complex cascade is stopped when the number of negative training examples used is too small. Two scenarios can lead to few negative training examples. First, the number of mined negatives is small. Second, the number of refined negatives is small after refining several times. Next, the refining operation process and the training of a peer AdaBoost classifier are described. Then, the algorithm of training the peer complex cascade is presented. After that, the discussion is presented.
3.1 Training peer AdaBoost classifier
In an increasingly complex cascade, the false positive rate and detection rate of each stage are all preset for training. In the proposed method, only the overall target detection rate is set, and overfitting is prevented by keeping the detection rate high while training.
As more peer AdaBoost classifiers are trained, the mined negative examples become harder and more dispersive, especially in the later stages. If needed, the hardest negative examples are refined out to keep the detection rate of the next trained classifier high, as mentioned above. The mined negative examples X0e are sorted in descending order by the response to the cascade of trained classifiers H. Some number (N0rf) of negative examples with the highest response are removed from the negative example training set. The details are shown in Algorithm 1.
Algorithm 1 Refining negatives

With the introduction of refining hard negative operation, it often requires several iterations to train a peer AdaBoost classifier with a sufficiently high detection rate. Algorithm 2 shows the procedure for learning a peer AdaBoost classifier. The cascade is evaluated immediately after a new AdaBoost classifier is trained (line 3 and line 8). If its detection rate is lower than the threshold Dt, the refining operation is called, and a new classifier is trained. The loop ends when the detection rate is high enough, or the number of negative training examples is too small. We do not consider the false positive rate here because when more negative training examples are used as the training progresses, the cascade becomes more powerful for classifying negative examples correctly. Algorithm 2 outputs a high-detection-rate AdaBoost classifier; the detection rate, which is used in an end condition for the cascade training (refer to Algorithm 3); and hard negative examples refined from the current negative training example set, which are used for training the following peer AdaBoost classifier.
Algorithm 2 Training peer AdaBoost

3.2 Training peer AdaBoost classifier cascade
Algorithm 3 shows the training process of the cascade of peer AdaBoost classifiers. The inputs are the set of positive examples X1 and the set of negative examples X0. To maintain the training data balance, the number of negative training examples N0t should be close to that of positive examples. The rate of hard negative examples rrf represents the percentage of hard negative examples that should be refined if needed. As mentioned above, the minimum target overall detection rate Dt is used to prevent overfitting.
At the beginning, the current cascade is initialized as empty. When the detection rate of the cascade of trained AdaBoost classifiers is too low, N0rf hard negative examples are refined out. N0t negative examples are randomly selected as the first negative training example set. The negative training set consists of the negative examples that pass through the current cascade. The negative training sets in stages are different from each other, so the difference of peer AdaBoost classifiers is maintained.
At each iteration, after a peer AdaBoost classifier is trained, the detection rate is checked. If it is high enough, the just trained AdaBoost classifier is appended to the current cascade; otherwise, the training process ends. The intention is to use as many negative training examples as possible, so when enough negative training examples cannot be found, the training process also ends.
Algorithm 3 TrainingPeerCascade

3.3 Discussion
In our cascade of peer classifiers, the intraclass difference is treated to some degree, which creates a better representation for pedestrians. In addition to positive examples, each classifier is trained using a set of negative examples. This set of negative examples is refined through a refining operation; thus, they have some of the same properties. Each classifier is trained to reject a set of similar negative examples, and the cascade of these classifiers can reject different negative examples.
In a cascade, only those examples that pass through all stages are predicted as positives. Considering the impact on no maximum suppression (NMS) of detection windows/proposals, the response of examples to the cascade should be reconsidered. Obviously, different examples may be responded differently in each stage. For the increasingly complex cascade, only the classifier in the last stage is determinate, so it is correct to directly use the response of an example in the last stage. However, for the peer complex cascade, the determination is made by all peer classifiers, and the responses in all stages should be considered. One way is to use the sum of responses in all S stages. Another way is to use the weighted sum of responses, as follows:
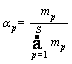 (7)
(7)
where mp=1-Dp, is the miss rate of the AdaBoost classifier Hp; and Dp is the detection rate.
4 Experiments
To verify the effectiveness of the peer AdaBoost classifier cascade detector (named MPO, the multipeer AdaBoost classifier detector), experiments are carried out on two popular datasets, the Inria pedestrian dataset [4] and the Caltech pedestrian detection benchmark [23]. The Inria pedestrian dataset is produced by DALAL et al [4] and divided into two formats: (a) original images with corresponding annotation files and (b) positive images in normalized 64��128 pixel format with original negative images. The Caltech pedestrian dataset consists of approximately 10 h of 640��480 30 Hz video taken from a vehicle driving through regular traffic in an urban environment. Approximately 250000 frames (in 137 approximately one-minute-long segments) with a total of 350000 bounding boxes and 2300 unique pedestrians are annotated [23]. The annotation also includes temporal correspondence between bounding boxes and detailed occlusion labels, but they are not used in our experiments to train the multi-peer detector.
Following the experimental protocol, for the Inria dataset, the 2474 normalized positive images are used as positive training examples and patches randomly sampled from 1218 person-free training photos as the initial negative set. For the Caltech dataset, the training data consists of six sets, set00 to set05, while the test data consists of five sets, set06 to set10. Each set contains 6 to 13 one- minute-long sequence files. By extracting one image per 30 frames, the training data have 4250 images, and the test data contain 4024 images.
The ROC and the mean miss rate are used to compare methods as suggested in [4, 23]. The mean miss rate defined in Piotr��s MATLAB toolbox is used in this paper, which is the mean of the miss rates at 0.0100, 0.0178, 0.0316, 0.0562, 0.1000, 0.1778, 0.3162, 0.5623 and 1.000 false positive per image [23].
4.1 Implementation
The implementation uses Piotr��s toolbox [23]. For the handcrafted features, considering that a large template cannot substantially detect small examples, we use a 36��16.2 pixel pedestrian template and a 54��27 pixel padded detection window for small pedestrian detection; the 50��20.5 pixel pedestrian template with 64��32 pixel detection window is tested in our experiment on the Inria and Caltech datasets. For each window, we extract the aggerate channel feature (ACF) as the feature [10, 23]. ACF is a channel feature with 10 channels, which includes three LUV color channels, gradient magnitude channels, and 6 quantized gradient channels. ACF uses a shrinking factor to control the dimension of the final feature and remove small invalid patches. The shrinking factor of ACF is set to three, so each example is a 1620 feature vector.
For the deep learning feature, the Region Proposal Network (RPN) introduced by Faster R-CNN is used to generate proposal examples [14]. The result is generated by the combination of RPN and MPO. When training, the candidates are used to train the MPO, along with true labels. While testing, the candidate samples are classified by MPO. The training and testing scheme of RPN-based classifier are as same as that of the handcrafted features.
The AdaBoost code in Piotr��s toolbox is used to train each peer classifier, but the soft-cascade threshold [17] is used for detection. Thus, essentially, the base classifier used in this paper is a soft-cascade classifier. When using ACF, our MPO detector trained on the Caltech pedestrian dataset contains 16 stages and costs approximately 20 h on an 8 G RAM, Intel Pentium CPU G630 PC. It is easier for Inria, which requires only three stages and less than an hour. Using RPN trained by ZHANG et al [14], it costs about 2 d for training on a computer station with one GPU.
4.2 Parameters
There are three independent arguments in the peer cascade training process: the number of negative training examples X0t to sample from X0, the rate of hard negative examples rrf to refine, and the minimum target overall detection rate Dt. As an intermediate variable, the number of hard negative examples N0rf to refine is determined by N0t and rrf. Some experiments are firstly conducted to find the best values of these parameters.
4.2.1 Number of training negatives
To maintain data balance, the number of negative training examples should be close to that of positive training examples. The experiments on the Inria dataset and Caltech pedestrian dataset show that, when training a single AdaBoost classifier, the performance remains high as the number of negative training examples is between three to six times the number of positives. Table 1 shows the results on the Inria dataset. The first row is the rate of the number of negative training examples to that of the positives, and the second row is the average miss rate (%) of trained classifiers, which is consistent with the rate of negatives and positives used in the work of DOLLAR et al [10], where, after mining negative examples several times, 4250 positive examples and 15000 negative examples are used to train a soft-cascade classifier for pedestrian detection.
Table 1 Influence of number of negative examples

4.2.2 Overall detection rate
Before training a peer cascade, an AdaBoost classifier is trained with three times�� negative mining. Then, it is evaluated on a validation set to determine its detection rate. This detection rate is used as the minimum target overall detection rate Dt.
4.2.3 Control of refining speed
Experiments show that when the rate rrf is small, the performance of the trained cascade is good. Keeping N0t to be three times the number of training positive examples, when rrf is less than 0.2, the trained cascade��s performance increases little. In the following experiments, the N0t is set to be three times of the number of positives, and rrf is set to 0.2.
4.3 Results
For ACF, the proposed MPO detector is compared with HOG [4], Viola-Jones [19] and ACF-Caltech [10] on the Caltech pedestrian dataset [23]. The results of the MPO detector are denoted as MPOs for the 36��16.2 pixel size template and MPO for the 50��20.5 pixel size template. The template size of MPO is as same as those of other detectors in Figure 3, except MPOs. The reasonable resolution pedestrian example is taller than 50 pixels.
On the Inria pedestrian dataset, the average detection error of MPO is 14%, below ACF��s 17%, as shown in Figure 2. There are 18 subexperiments on the Caltech pedestrian benchmark to compare detection performance under different conditions [23]. In all 18 subexperiments, the performance of the MPO outperforms ACF-Caltech with approximately 6%-16%, which is a cascade detector of increasingly complex AdaBoost classifiers. Among all these nondeep methods evaluated in the Caltech pedestrian detection benchmark, the proposed MPO detector achieves the lowest average miss rate. The ROC of the reasonable size pedestrians is shown in Figure 3.
Using RPN, the result on Caltech pedestrian benchmark is shown in Figure 4. Though RPN has reduced the data imbalance largely, the proposed method (RPN+MPO) is still better than RPN+BF [14].
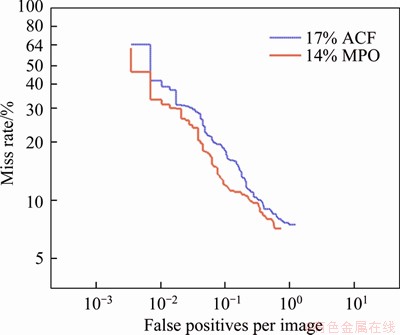
Figure 2 Qualitative result on Inria dataset
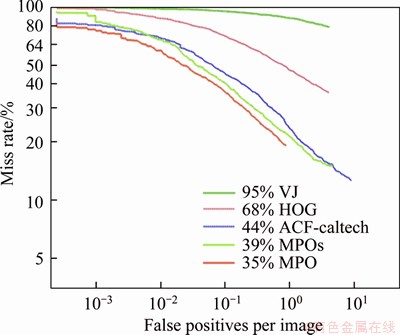
Figure 3 Results on Caltech dataset
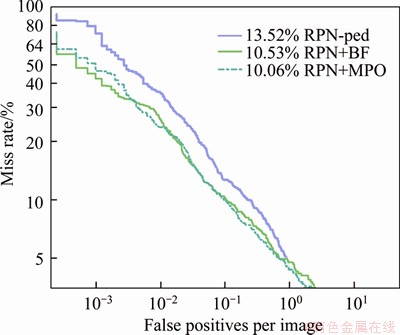
Figure 4 Results on Caltech dataset using RPN
4.4 Detection speed
In the experiments, the first several AdaBoost classifiers to be trained are allowed in increasingly length naturally, and the peer AdaBoost classifiers are further translated to soft-cascade form [17] for speeding up. Thus, the MPO detector finds the pedestrian fast, almost as fast as a single 2048-weak classifier AdaBoost detector trained by DOLLAR et al [10].
5 Conclusions
In this paper, a novel, multi-peer classifier detector is proposed for pedestrian detection. The cascade framework adaptively combines AdaBoost classifiers. By using peer AdaBoost classifiers, more negative examples are used in training. Algorithms are designed to train the cascade of peer AdaBoost classifiers. Using aggerate channel feature (ACF), the proposed pedestrian detectors are trained on Inria and Caltech pedestrian datasets. Experimental results show that the MPO detector finds pedestrians from each image in high accuracy and fast speed by transforming classifiers into soft cascades. By concatenating complex peer classifiers in the proposed method, negative examples can be fully used for training; thus, a more powerful detector is trained. Recently, the deep model has shown considerable advantages in computer vision tasks, including pedestrian detection. The experiment using RPN also shows the effectiveness of the proposed method in deep learning framework.
References
[1] LI J, LIANG X, SHEN S, XU T, FENG J, YAN S. Scale- aware fast R-CNN for pedestrian detection [J]. IEEE Transactions on Multimedia, 2018, 20(4): 985-996. DOI: 10.1109/TMM.2017.2759508.
[2] BRAZIL G, LIU X. Pedestrian detection with autoregressive network phases [C]// Computer Vision and Pattern Recognition (CVPR). IEEE, 2019: 7231-7240. DOI: 10.1109/CVPR.2019.00740.
[3] XIA Li-min, HU Xiang-jie, WANG Jun. Anomaly detection in traffic surveillance with sparse topic model [J]. Journal of Central South University, 2018, 25(9): 2245-2257. DOI: 10.1007/s11771-018-3910-9.
[4] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C]// Computer Vision and Pattern Recognition (CVPR). IEEE, 2005: 886-893. DOI: 10.1109/ CVPR.2005.177.
[5] BENENSON R, MATHIAS M, TUYTELAARS T, GOOL L V. Seeking the strongest rigid detector [C]// Computer Vision and Pattern Recognition (CVPR). IEEE, 2013. DOI: 10.1109/CVPR.2013.470.
[6] YAN Y, REN J, ZHAO H, SUN G, WANG Z, ZHENG J, MARSHALL S, SORAGHAN J J. Cognitive fusion of thermal and visible imagery for effective detection and tracking of pedestrians in videos [J]. Cognitive Computation, 2018, 10(1): 94-104. DOI: 10.1007/s12559-017-9529-6.
[7] FELZENSZWALB P F, GIRSHICK R, MCALLESTER D, RAMANAN D. Object detection with discriminatively trained part-based models [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645. DOI: 10.1109/TPAMI.2009.167.
[8] OUYANG W, ZENG X, WANG X. Learning mutual visibility relationship for pedestrian detection with a deep model [J]. International Journal of Computer Vision, 2016, 120(1): 14-27. DOI :10.1007/s11263-016-0890-9.
[9] CHEN Y, ZHANG L, LIIU X, CHEN C. Pedestrian detection by learning a mixture mask model and its implementation [J]. Information Sciences, 2016, 372: 148-161. DOI: 10.1016/ j.ins.2016.08.050.
[10] DOLLAR P, APPEL R, BELONGIE S, PERONA P. Fast feature pyramids for object detection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(8): 1532-1545. DOI: 10.1109/TPAMI.2014.2300479.
[11] HUANG C, LOY C C, TANG X. Discriminative sparse neighbor approximation for imbalanced learning [J]. IEEE Transactions on Neural Networks, 2018, 29(5): 1503-1513. DOI: 10.1109/tnnls.2017.2671845.
[12] LIN T, GOYAL P, GIRSHICK R, HE K, DOLLAR P. Focal loss for dense object detection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318-327. DOI: 10.1109/TPAMI.2018.2858826.
[13] ZHANG X, ZHU C, WU H, LIU Z, XU, Y. An imbalance compensation framework for background subtraction [J]. IEEE Transactions on Multimedia, 2017, 19(11): 2425-2438. DOI: 10.1109/TMM.2017.2701645.
[14] ZHANG L, LIN L, LIANG X, HE K. Is faster RCNN doing well for pedestrian detection? [C]// European Conference on Computer Vision. 2016: 443-457. DOI: 10.1007/978-3-319- 46475-6_28.
[15] WENG R, LU J, TAN Y, ZHOU J. Learning cascaded deep auto-encoder networks for face alignment [J]. IEEE Transactions on Multimedia, 2016, 18(10): 2066-2078. DOI: 10.1109/TMM.2016.2591508.
[16] CAI Z, VASCONCELOS N. Cascade R-CNN: Delving into high quality object detection [C]// Computer Vision and Pattern Recognition (CVPR). IEEE, 2018. DOI: 10.1109/ cvpr.2018.00644.
[17] BOURDEV L, BRANDT J. Robust object detection via soft cascade [C]// Computer Vision and Pattern Recognition (CVPR). IEEE, 2005. DOI: 10.1109/CVPR.2005.310.
[18] WEN G, HOU Z, LI H, LI D, JIANG L, XUN, E. Ensemble of deep neural networks with probability-based fusion for facial expression recognition [J]. Cognitive Computation, 2017, 9(5): 597-610. DOI: 10.1007/s12559-017-9472-6.
[19] VIOLA P, JONES M J. Robust real-time face detection [J]. International Journal of Computer Vision, 2004, 57(2): 137-154. DOI: 10.1023/B:VISI.0000013087.49260.fb.
[20] FREUND Y, SCHAPIRE R E. A decision-theoretic generalization of on-line learning and an application to boosting [J]. Conference on Learning Theory, 1997, 55(1): 119-139. DOI: 10.1006/jcss.1997.1504.
[21] FU Hong-pu, ZOU Bei-ji. A fast training method for AdaBoost classifier [J]. Journal of Yunnan University: Natural Sciences Edition, 2020, 42(1): 50-57. DOI: 10.7540/ j.ynu.20190214. (in Chinese)
[22] WEI Gao, HOU Zhi-hua. On the doubt about margin explanation of boosting [J]. Artificial Intelligence, 2013: 1-18. DOI: 10.1016/j.artint.2013.07.002.
[23] DOLLAR P, WOJEK C, SCHIELE B, PERONA P. Pedestrian detection: An evaluation of the state of the art [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 743-761. DOI: 10.1109/TPAMI. 2011.155.
(Edited by ZHENG Yu-tong)
���ĵ���
������AdaBoost���������������˼��
ժҪ�����ѵ�����ݲ�ƽ������ڲ��죬���������ʹ�õ�ͬ���Ӷ�AdaBoost�������ļ�����������ˣ���Ϊ�����������Ѹ������ھ������̰��ѵ��һϵ�е�AdaBoost�η����������������Ʒ������ĸ��Ӷȣ��Ӷ��������ø��ฺѵ�����������ң����ļ�����Ϊ��ǿ�������ļ��ɣ��Ӷ�����һ���̶���Ӧ�����˵����ڲ��졣Ϊ�͵�ѵ��������ʵ�AdaBoost������������ᴿ����������һЩ�Ѹ��������ᴿ�����������ֱ�ӽ��ͷ�������ֵ�IJ�����������ÿ����������ѵ���Ż����ܡ�ʵ������������Inria��Caltech pedestrian benchmark���������������ݼ���ʹ�þۺ�ͨ������(ACF)�����ļ�����ܱ��������ӷ����������ļ�����ܺúܶࡣʹ��RPN��ȡ�����ѧϰ����ʱ���������������Ը��á�
�ؼ��ʣ����������Ѹ������ᴿ�����˼�⣻����
Foundation item: Project(2018AAA0102102) supported by the National Science and Technology Major Project, China; Project(2017WK2074) supported by the Planned Science and Technology Project of Hunan Province, China; Project(B18059) supported by the National 111 Project, China; Project(61702559 ) supported by the National Natural Science Foundation of China
Received date: 2019-11-26; Accepted date: 2020-05-13
Corresponding author: ZHU Cheng-zhang, PhD, Associate Professor; Tel: +86-731-88877701; E-mail: anandawork@126.com; ORCID: https://orcid.org/0000-0001-8825-0992

