Human interaction recognition based on sparse representation of feature covariance matrices
��Դ�ڿ������ϴ�ѧѧ��(Ӣ�İ�)2018���2��
�������ߣ������� ���� ��˼��
����ҳ�룺304 - 314
Key words��interaction recognition; dense trajectory; sparse coding; MIL
Abstract: A new method for interaction recognition based on sparse representation of feature covariance matrices was presented. Firstly, the dense trajectories (DT) extracted from the video were clustered into different groups to eliminate the irrelevant trajectories, which could greatly reduce the noise influence on feature extraction. Then, the trajectory tunnels were characterized by means of feature covariance matrices. In this way, the discriminative descriptors could be extracted, which was also an effective solution to the problem that the description of the feature second-order statistics is insufficient. After that, an over-complete dictionary was learned with the descriptors and all the descriptors were encoded using sparse coding (SC). Classification was achieved using multiple instance learning (MIL), which was more suitable for complex environments. The proposed method was tested and evaluated on the WEB Interaction dataset and the UT interaction dataset. The experimental results demonstrated the superior efficiency.
Cite this article as: WANG Jun, ZHOU Si-chao, XIA Li-min. Human interaction recognition based on sparse representation of feature covariance matrices [J]. Journal of Central South University, 2018, 25(2): 304�C314. DOI: https://doi.org/10.1007/s11771-018-3738-3.

J. Cent. South Univ. (2018) 25: 304-314
DOI: https://doi.org/10.1007/s11771-018-3738-3
WANG Jun(����), ZHOU Si-chao(��˼��), XIA Li-min(������)
School of Information Science and Engineering, Central South University, Changsha 410075, China
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2018
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2018
Abstract: A new method for interaction recognition based on sparse representation of feature covariance matrices was presented. Firstly, the dense trajectories (DT) extracted from the video were clustered into different groups to eliminate the irrelevant trajectories, which could greatly reduce the noise influence on feature extraction. Then, the trajectory tunnels were characterized by means of feature covariance matrices. In this way, the discriminative descriptors could be extracted, which was also an effective solution to the problem that the description of the feature second-order statistics is insufficient. After that, an over-complete dictionary was learned with the descriptors and all the descriptors were encoded using sparse coding (SC). Classification was achieved using multiple instance learning (MIL), which was more suitable for complex environments. The proposed method was tested and evaluated on the WEB Interaction dataset and the UT interaction dataset. The experimental results demonstrated the superior efficiency.
Key words: interaction recognition; dense trajectory; sparse coding; MIL
Cite this article as: WANG Jun, ZHOU Si-chao, XIA Li-min. Human interaction recognition based on sparse representation of feature covariance matrices [J]. Journal of Central South University, 2018, 25(2): 304�C314. DOI: https://doi.org/10.1007/s11771-018-3738-3.
1 Introduction
Human activity recognition (HAR) is an important step to understand realistic scenes automatically by computers, which has broad application prospects in surveillance systems, human-computer interaction, artificial intelligence, etc. Interactions conducted by two persons such as shaking hands, hugging, fighting are widespread in our daily life, all of which contain considerable information. Therefore, interaction recognition is significant and valuable to understand the video information and to make decisions.
Common research on human interaction recognition mainly has two aspects: feature extraction and classification. As an important link in human interaction recognition, feature extraction can be divided into two categories, namely global feature and local feature. As one kind of the global feature, body parts model feature is widely used in HIR due to its intelligibility. The patch-aware model proposed by KONG et al [1] is feasible to accurately extract the interacting people and can learn discriminative supporting regions for each interacting individual, in that way, the model is an effective solution to the occlusion problem in the interaction. KARUNGARU et al [2] used the distances and orientations between the heads and the hands and legs as features which are also on the basis of human region extraction. HOAI et al [3] introduced a learnable context aware configuration model for detecting as well as predicting the scale and location of each upper body box, the model parameters such as the head orientation and the Euclidean distance between two heads can be used to identify the interaction in complex scenarios. The Group-sparsity-optimization-based feature selection model proposed by YANG et al [4] concatenates multiple local and global features into a feature pool and can also automatically learn to select feature types and vote to identify interactions. ZHANG et al [5] divided human body into head, elbows, legs and feet to extract local behavior features, characterizing the local action with semantic description. Although body parts model can be applied to real-world scenarios, the robustness of recognition in a complex environment is not high because the performance is severely dependent on the accuracy of human detection and location. In contrast, local feature can be directly extracted from the video and the process barely requires any prior knowledge of the location or any other body parts. Consequently, errors caused by preprocessing method such as motion segmentation or human detection can be effectively prevented. Local feature points can be divided into sparse interest points and dense interest points. Dense interest points has shown improved results over sparse interest points for image classification [6�C8]. And WANG et al [7] had found that the dense sampling at regular positions in spatio-temporal volume outperformed state-of-the-art space-time interest point detectors. Dense trajectories can be obtained by tracking the dense sampling points, so dense trajectories are a kind of local features, and characterizing the neighborhood range of them with some kinds of descriptors has become one of the mainstream method. In the aspect of DT extraction, HAO et al [9] proposed a fast dense trajectories algorithm using temporal pyramids, the efficiency of the extraction had been improved obviously. BEAUDRY et al [10] tracked the critical points in the optical flow field with high value of divergence and curl. SEO et al [11] extracted key-trajectories from a distinctive subset and those features have the property of time-invariant. NI et al [12] proposed the motion part regularization framework to choose local motion features which are responsible for the action label and to screen out the irrelevant trajectories. In terms of feature description, WANG et al [8] used motion boundary descriptors to characterize the motion around the dense trajectories. ZHANG et al [13] obtained the local motion patterns using the coherent filtering algorithm. Classification has been achieved by means of MIL.
Local body movements can be well described by dense trajectory, which solves the problem that local motion is sensitive to the light and the scale of the video to a certain extent. However, with the upgrade of the video length or resolution, methods based on dense trajectory will also encounter large amount of data. Video noise and data redundancy will not only greatly improve the computational cost, but also seriously affect the accuracy of recognition. An ideal solution is to encode the extracted primary features with a dictionary. Sparse coding uses a much more accurate reconstruction way to encode features, which overcomes the defect that traditional quantization coding methods are too rough. Therefore, a novel trajectory tunnel descriptor based on dense trajectory is proposed to characterize the local motion in the proposed method.
In terms of classification, the most common approach is the Bag of Words (BOW) model [14�C16]. However, the model ignores the spatial information of the local features as well as the interrelationship between the local spatial regions, which often leads to the same quantization result in different behaviors. Therefore, MIL is exploited in this method.
In this work, a novel method is proposed to recognize the interactions. At the low level processing, dense trajectories has been extracted and clustered into different groups, by which the trajectories with similar motion or motion trend can be clustered into one group and the irrelevant ones can be eliminated. A variety of image features of all the pixels in each trajectory tunnel are calculated and transformed into covariance matrices which has the advantage of strong characterization [17]. After sparse coding and pooling the trajectory channel descriptors resulting from the conversion of the covariance matrices, each cluster center can be represented by certain local feature vectors. Finally, for categorization, MIL is exploited. Flowchart of the proposed method is shown in Figure 1. Subsequent experiments have shown that the proposed method has a high recognition rate.

Figure 1 Flowchart of proposed method.
2 Extraction and clustering of dense trajectories
In terms of video trajectory extraction, typical strategies include sparse points of interest (POI) tracklets and dense trajectories. In the former method, only a small number of tracklets are generated, which is not able to characterize the interaction adequately. At the same time, the former strategy tends to contain a fair amount of noise, exhibiting irregular trajectories, while dense trajectories can produce better motion representation and reveal distinct features. Therefore, the strategy proposed by WANG et al [8] is exploited to extract the dense trajectories in this method.
After the extraction, cluster strategy is adopted to weed out the irrelevant trajectories, whereby the spatio-temporal objects with similar motion can be grouped together. BROX et al [18] presented a trajectory clustering method in the analysis of object segmentation with the point tracklets, defining an affinity matrix firstly and achieving the trajectories grouping using spectral clustering. According to Brox��s opinion, points that move together ought to be assigned high affinities and the distance information between those points are also considered. Regarding two trajectories A and B, the distance between them at a particular time t is defined as
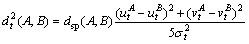 (1)
(1)
The average spatial Euclidean distance between A and B is denoted by dsp(A, B). To ensure the high affinities of proximate points, multiplying with the spatial distance is necessary in Eq. (1). 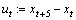 and
and 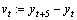 can estimate the motion of the points who span multiple frames better. Then the distance can be normalized as
can estimate the motion of the points who span multiple frames better. Then the distance can be normalized as
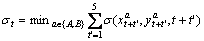 (2)
(2)
The normalized distances d2(A, B) can be turned into affinities using standard exponential as
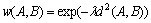 (3)
(3)
So, the whole video shot will output an n��n affinity matrix W, where n denotes the total number of trajectories and �� is a fixed scale whose value is 0.1.
The strategy of spectral clustering is mapping the points into a feature space where the traditional clustering method can be adopted. By an normalized Laplacian eigendecomposition, the Laplacian eigenmap can be obtained:
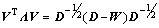 (4)
(4)
The entries of diagonal matrix D is 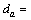
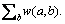 All the eigenvectors ��0, ��, ��m correspond to the eigenvalues ��0, ��, ��m. Finally, by minimizing the energy function which comprises a spatial regularity term, we can achieve the clustering judgment:
All the eigenvectors ��0, ��, ��m correspond to the eigenvalues ��0, ��, ��m. Finally, by minimizing the energy function which comprises a spatial regularity term, we can achieve the clustering judgment:
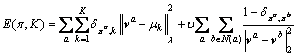 (5)
(5)
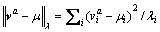 (6)
(6)
where ��a denotes the ath components of all the eigenvectors; via denotes the ith component of the ath eigenvector; ��k denotes the centroid of cluster k. According to Ref. [18], parameter �� is set to 0.5. The norm 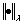 is defined in Eq. (6).
is defined in Eq. (6).
Through dense trajectories clustering, the whole video features can be represented by a plurality of clustering centroid and each clustering center consists of a great deal of trajectories that have same motion or motion trend. Typically, all the centroid of clustering may correspond to some meaningful and significant body movements, which will greatly improve the accuracy in subsequent recognition.
3 Trajectory tunnel descriptor
To extract the motion information from the generated trajectories, the spatio-temporal volume around the trajectories has been selected to calculate the descriptors. According to Ref. [8], each trajectory will generate a tunnel whose cross- section is rectangular. Feature covariance matrices are a kind of data form with high ability of characterization. It can capture the second-order statistics of a dense collection of local features, while lies in a space much lower of dimensionality than that of the collection [17]. Therefore, feature covariance matrices are proposed as the compact representation of the dense local features.
First, descriptors of the pixels in each trajectory tunnel are calculated. Then, for each tunnel, corresponding covariance matrix is calculated, which means mapping the 3D data space to a point in Riemannian manifold where the symmetric positive definite matrix locates. By using the matrix logarithm, the aforementioned points transform into symmetric matrices after mapping from the Riemannian manifold to the linear space. After the vectorization, we will get one vector which represents the spatio-temporal feature around that trajectory, namely trajectory tunnel descriptor x.
3.1 Pixel descriptor
Composition of pixel descriptor has no fixed form as long as containing important image features. So generally it has a wide degree of versatility. In this work, the gradient and optical flow feature are combined to constitute the pixel descriptor and each descriptor has actual physical meaning. Subsequent experiments show the high differentiation of the descriptor.
Gradient can represent the edge and contour information of the target and highlight the transition part of the brightness values of the pixels. We make use of the first-order difference and the second- order partial derivatives of the image as well as the gradient magnitude and orientation to characterize the video. The calculation of first-order difference is as follows:
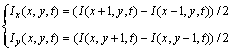 (7)
(7)
The calculation of second-order partial derivatives is as follows:
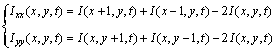 (8)
(8)
The calculation of magnitude and orientation of the gradient is as follows:
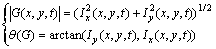 (9)
(9)
The absolute value of the first-order difference and second-order partial derivatives are exploited. Finally, the composition of the gradient descriptor is as follows:
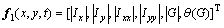 (10)
(10)
Optical flow is the apparent motion of the pixel intensity on the image plane as well as a very important expression of the movement in the field of image processing. Histogram of optical flow (HOF) describes the absolute motion which contains the camera moving, on the other side, motion boundary histogram (MBH) encodes the relative motion of pixels and computes derivatives for the horizontal and vertical components of the optical flow separately. That accounts for the elimination of camera motion. We expand the optical flow into a plurality of components which contains not only the intensity of the pixel but the gradient of the optical flow components, specifically, optical flow descriptor consists of:
1) The horizontal and vertical components of the optical flow;
2) The gradient of optical flow along the x axis;
3) The gradient of optical flow along the y axis;
Wherein steps (2), (3) represent the projection of acceleration of the moving target on image plane, which is equivalent to the map from the motion field of the object to the optical flow field on the image plane. The gradient of the horizontal optical flow along the x axis can be calculated as follows:
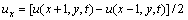 (11)
(11)
Similarly, the other components can be calculated. Consequently the optical flow descriptor is as follows:
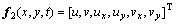 (12)
(12)
where (x, y, t) represents the corresponding pixel coordinates. Then, a cascade of gradient and optical flow descriptor is used as pixel descriptor:
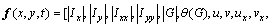
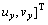 (13)
(13)
3.2 Feature covariance matrices
The purpose of calculating various characteristics for each pixel is to provide a sample to the covariance matrices as a pre-computed column vector. That is to say, the covariance matrix is obtained by calculating the second-order center distance of random vectors, which is the multiple image features mentioned above. Each covariance matrix corresponds with and derives from a trajectory tunnel.
According to Section 3.1, the dimension of the extracted pixel descriptor is 12. Arranging all of the pixel descriptors to a sample matrix according to certain order:
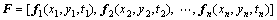 (14)
(14)
where fi(xi, yi, ti) represents the ith pixel descriptor in trajectory tunnel. Therefore, the size of the sample matrix is 12n. The covariance matrix is calculated using sample matrix:
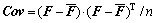 (15)
(15)
The mean value of all the column vectors in the sample matrix, i.e., the arithmetic mean value of the pixel descriptor contained by the trajectory tunnel, is calculated as follows:
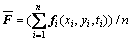 (16)
(16)
Covariance matrix belongs to the category of symmetric matrices and in most cases are positive definite. But in the calculation process, the situation that the covariance matrix is non-positive definite still appeared. At this point, the trajectory tunnel corresponding to the non-positive definite covariance matrix should be discarded. Or we can also plus a small positive real number to the zero eigenvalues and keep the corresponding feature vector unchanged.
3.3 Log-covariance matrices
Due to the space where the covariance matrix is constructed is not a linear space, but a smooth Riemannian manifold, in which the time complexity of the operators is relatively higher than that in the linear space. Moreover, many operational expressions such as Euclidean distance between two points and data superposition calculation are not established in the manifold. Indeed covariance matrix is composed of a commutative Lie group, which is based on a generalized multiplication:
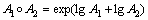 (17)
(17)
The Riemannian manifold where the symmetric positive definite matrix lies was projected into the vector space with the matrix logarithm operation. Therefore, after taking the logarithm on the elements of the symmetric positive definite matrix, the Riemannian manifold is mapped to a linear space, which can bypass the computation with high time complexity and improve the efficiency of subsequent recognition. Logarithmic calculation is as follows:
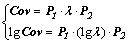 (18)
(18)
where P1 and P2 represent the unitary matrices of the covariance matrix. When there occurs the zero eigenvalue, Eq. (18) will be transformed into:
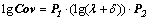 (19)
(19)
lgCov is symmetric matrix, in which nearly half of the data are duplicated. So we only select the data on upper triangular region of lgCov in accordance with the principle of row first to construct the vector x (trajectory tunnel descriptor). For example, when the dimension of the symmetric matrix is m, the data on upper triangular region can be pulled into a descriptor whose length is m(m+1)/2.
After the above transformation, the characteristics of each trajectory tunnel will be turned into a trajectory tunnel descriptor for subsequent coding.
4 Sparse coding
The purpose of sparse coding is to decompose the original signal and to represent the original signal using a small amount of over-complete dictionary column vector as well as the decomposition coefficients. The base signal derives from the atom of over-complete dictionary. So, sparse coding can be seen as a quantitative process. Each atom in the dictionary can be regarded as quantum and the original signal is the linear combination of these quantum.
Decomposition of the original signal has many benefits, on one hand, the video noise can be filtered out and the additional dummy information (such as the shadow of movements or the mutual fusion of interacting people) can be removed whereby the descriptor can be purified and the robustness can be improved. Furthermore, after the decomposition, only the main components of the signal will leave, which is also the most essential ingredient in response to the original signal. Therefore, sparse coding is adopted to encode the extracted dense features.
K-SVD is one of the classic dictionary learning algorithm:
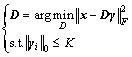 (20)
(20)
In this work, trajectory tunnel descriptors are used as the original signal. Orthogonal matching pursuit algorithm has been used in K-SVD algorithm in the process of learning dictionary. The entire algorithm process consists of two layers of circulation, i.e., updating the dictionary D first, then updating code �� completely:
1) Each descriptor is normalized using L2-norm, and K column is randomly selected as the initial values of the dictionary.
2) Iterating the variables from 1 to K, the corresponding atom in the dictionary is updated in each iteration. Transforming the objective function of formula (20) equivalently into:
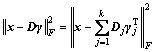 (21)
(21)
3) Orthogonal matching pursuit algorithm is used to calculate the encoding matrix according to the input trajectory tunnel descriptor and the learned dictionary.
4) The ith atom of the dictionary and its corresponding column vector are separated from the formula (21):
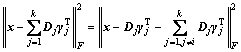 (22)
(22)
Formula (22) can also be seen as 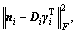 then the zero elements in ��iT are deleted.
then the zero elements in ��iT are deleted.
5) Decomposing ni with singular value and unitary matrix U and V are obtained. Assuming Di=U1 and 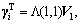 if the atoms in dictionary D are not updated completely, jump to the fourth step; otherwise, implement in order.
if the atoms in dictionary D are not updated completely, jump to the fourth step; otherwise, implement in order.
6) When 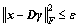 or when the number of iteration exceeds a given number of times, end the process; otherwise, jump to the second step to continue the iteration.
or when the number of iteration exceeds a given number of times, end the process; otherwise, jump to the second step to continue the iteration.
Trajectory tunnel descriptor in each center of trajectory clustering will be encoded with the algorithm above. Given that the characteristics of each clustering center are similar, the average pooling strategy is adopted:
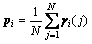 (23)
(23)
where N represents the number of trajectory tunnel descriptor in each clustering center. The resultant vectors after the pooling are normalized using L2-norm.
By encoding and pooling, each clustering center can be represented by a feature vector which characterizes the local region of input video, while an input video contains several clustering center of trajectories.
5 Classification
The traditional strategy of interaction recognition based on dense trajectory is to combine the motion descriptors with the BOW model [8]: computing the Histogram of Gradient (HOG), HOF and MBH along each trajectory, then K-means clustering is applied on all the descriptors in the training set, in that way a so-called codebook has been generated. Next, after quantizing all the descriptors onto the codebook, the input video is represented by a normalized feature vector. Finally, the classification is carried out using standard SVM. However, the model has many flaws: the data volume and its input order has great influence on the effect of K-means algorithm, which diminish the robustness significantly. Moreover, the K value and the size of the codebook are difficult to determined. Therefore, we switch to the MIL for classification.
MIL is a supervised learning strategy that deals with the certainty of bag labels but the uncertainty of instance labels, its training set is the bag consisting of multiple instances. The label of unknown bag depends on an intermediate function which takes each instance as independent variable and determines the attribute of the bag by calculating the maximum output of each instance. In the framework, a positive bag must contain at least one positive instance, while instances in the negative bag are altogether labeled negative. In this paper, each video is considered as a bag, in which each clustering center is viewed as a instance. However, due to the high degree of similarity between some interaction such as push and punch, the instances in the negative bag will not all be labeled negative, which accounts for many misjudgments in the classification.
Considering the limitation mentioned above, MILES (Multiple-instance learning via embedded instance selection) [20] is adopted for classification. As an improvement to the traditional MIL algorithm, MILES does not impose the assumption relating instance labels to bag labels. Consequently, MILES demonstrates high robustness to labeling uncertainty and this advantage makes MILES much more suitable for the classification in computer vision area. Specifically, the algorithm maps all the bags into a feature space defined by the instances in the training bags on the basis of an instance similarity measure. All instances are rearranged to form a set {p1, ��, pn} and n represents the total number of instances in the training set. For a certain bag, the mapping is defined as:
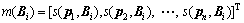 (24)
(24)
The measure of similarity between instance pi and bag Bi is interpreted as:
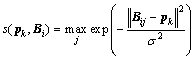 (25)
(25)
For a given training set, applying the mapping (24) yields the following matrix representation:
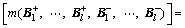
 (26)
(26)
Each column vector of the matrix represents a feature in a bag. A 1-norm SVM is selected to train the classifier in the bag feature space. When the training is completed, the corresponding features can be picked out from the feature space by the support vector.
6 Experiment
In order to verify the effectiveness of the proposed method, we executed experiments on two standard human interaction benchmarks, namely WEB Interaction dataset and UT Interaction dataset. Considering the limited number of sample videos in these two datasets, the leave-one-out cross validation strategy was used to evaluated the performance of the recognition. The algorithm was implemented on VS2012 for simulation with Intel(R) Core(TM) i5-3230M CPU and 2.5G frequency on the Win7 operating system. According to Refs. [8] and [18], the dense sampling step size was set to 5 and the side length of the trajectory tunnel cross-section was set to 16. The number of the clustering center was set to 5, which had been proved to be a proper value in our experiments.
6.1 WEB interaction dataset
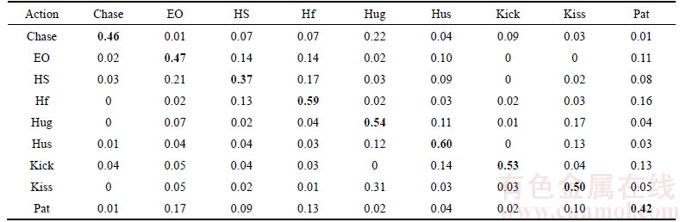
WEB interaction dataset has nine different kinds of unconstrained scenes including pat, kick, chase, exchange object, high-five, hug, handshake, hustle and kiss, as shown in Figure 2. Each interaction type has 50 video clips, and all the clips are collected from media source such as social network, online news or monitor records etc. Condition also varies in different clips: different background clutter, viewpoint, illumination, resolution, occlusion, the size of human, and so on. Some videos even include verbal comments or commercial logos. Table 1 shows the confusion matrix of our method, from which we could find that the overall accuracy rate was 49.78%. The recognition accuracy rates of high-five, hug and hustle were relatively high. The highest accuracy rate is 60% (hustle). Due to the smaller interaction area, the ambiguity of behaviors such as handshake and pat was higher than that of other behaviors, and the lowest accuracy rate is 37% (handshake).
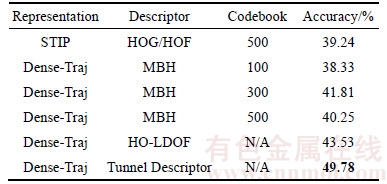
The proposed method had also been compared with the standard STIP-based and dense trajectory- based method. The spatio-temporal interest points and the dense trajectories are generated using the method in Ref. [21], where the interest points were described using the concatenation of HOG and HOF and the dense trajectories were described by MBH. Finally, the standard BOW model was used for encoding and classification. It is noteworthy that the method proposed in Ref. [16] had been added into the comparison as well. They described the spatio- temporal volume around the dense trajectories with HO-LDOF (Histogram of Large-Displacement Optical Flow). The classification was achieved using MIL. The comparison with several baseline results in Table 2.

Figure 2 Samples in WEB interaction dataset
Table 1 Confusion matrix of proposed method on WEB interaction dataset
From Table 2, we can observe that: 1) On the WEB interaction dataset, the performance of the dense trajectory-based strategy is generally better than the STIP-based method in the case of selecting the appropriate size of codebook. 2) The trajectory tunnel descriptor is much more discriminative than the HOG/HOF and MBH.
Table 2 Comparison with STIP-based and dense trajectory-based methods
Then, we changed the coding method and the classification strategy to make comparison. Here, dense trajectories were extracted and grouped first. Feature descriptor remained unchanged, too. Codebook was constructed using K-means algorithm. Table 3 shows that the combination of Sparse Coding and MILES outperformed other strategies significantly.
Table 3 Comparison using different coding and classification strategies
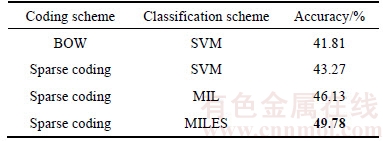
From Table 3, we can observe that: 1) Sparse coding can purify the descriptor, extract the main components of the signal and filter out the noise, which will improve the accuracy of the recognition greatly. 2) The BOW model will lose a great deal of useful information in the process of quantification, which accounts for the phenomenon that the MIL algorithm outperformed the BOW scheme significantly. 3) Compared to the traditional MIL algorithm, MILES breaks the limitation that all the instances in a negative bag should be labeled negative. So it is more applicable to the classification in the computer vision area. The result had shown its superiority.
6.2 UT interaction dataset
UT Interaction dataset contains six different types of interaction including handshake, hug, kick, punch, push and point, as shown in Figure 3. Each interaction type has 20 video clips. The dataset can be further divided into two sets, where videos in SET 1 were taken with static background and little camera jitters, while videos in SET 2 were taken with moving background (moving pedestrians and branches) and more camera jitters. Furthermore, only a pair of people interacts in the SET 1, while multiple pairs of people interact in the SET 2.Table 4 shows the confusion matrix of our method, from which we could find that the overall accuracy rate was 85.83%. The highest accuracy rate is 100% (hug) while the lowest accuracy rate is 75% (handshake and punch).
We compared the proposed method with some other up-to-date recognition strategies, as shown in Table 5. Wherein the approach proposed by XIA [22] is to recognize the complex activity by key frames, which is also applicable to the recognition of interaction.

Figure 3 Samples in UT Interaction dataset
Table 4 Confusion matrix of proposed method on UT interaction dataset
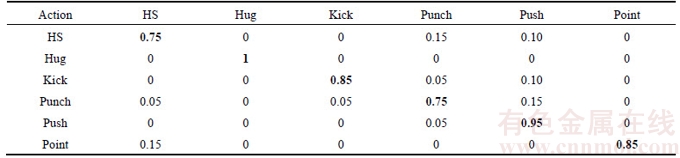
Table 5 Recognition accuracy of different methods
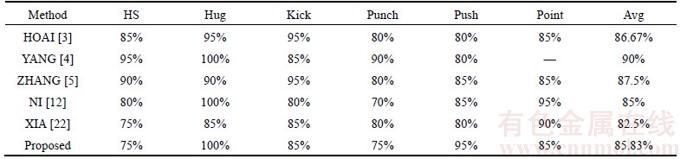
From Table 5, we can observe that: 1) On the UT interaction dataset, the accuracy of the proposed method was closed to that of some other advanced methods (85.83% vs 85%) (85.83% vs 86.67%), is yet still inferior to the method in Refs. [4] and [5].2) The human body parts model proposed in Ref. [3�C5] is relatively complex and their high accuracy is heavily dependent on the good performance of detection and tracking. So the background clutter or the viewpoint transformation will decrease the recognition rate significantly. 3) For most human actions, only a part of the local motion features are responsible for the label of action. Therefore, highlighting this part of the motion features will generate a much more discriminative action representation.
7 Conclusions
1) A human interaction recognition method based on sparse representation of feature covariance matrices is proposed. This method has obvious advantages in recognition precision and can also be used in human activity recognition.
2) Clustering algorithm of the object segmentation is adopted to group the dense trajectories to eliminate the irrelevant tracklets and to get the grouping regions with excellent interaction description.
3) For each trajectory tunnel a corresponding covariance matrix is extracted and transformed into a local trajectory tunnel feature descriptor, which is an effective solution to the problem that the description of feature second-order statistics is insufficient. Sparse coding is used to increase the discrimination of feature descriptors and average pooling for the encoded trajectory tunnel descriptors in each clustering center ensures the high degree of distinctions among each grouping centers.
4) MILES algorithm is selected for classification. The algorithm has high computational efficiency and robustness to the uncertainty of labels. The experimental results on WEB interaction dataset and UT interaction dataset demonstrate the effectiveness of our method.
References
[1] KONG Yu, FU Yun. Modeling supporting regions for close human interaction recognition [C]// Computer Vision-ECCV 2014 Workshops. Zurich: Springer International Publishing, 2014: 29�C44.
[2] KARUNGARU S, KENJI T, FUKUMI M. Human action recognition using normalized cone histogram features [C]// Computational Intelligence for Multimedia, Signal and Vision Processing (CIMSIVP), 2014 IEEE Symposium on. Orkand, FL: IEEE, 2014: 1�C5.
[3] HOAI M, ZISSERMAN A. Talking heads: detecting humans and recognizing their interactions [C]// Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on. Columbus, Dhio: IEEE, 2014: 875�C882.
[4] YANG Lu-yu, GAO Cheng-qiang, MENG De-yu, LU Jiang. A novel group-sparsity-optimization-based feature selection model for complex interaction recognition [M]// Computer Vision�CACCV 2014. Singapore: Springer International Publishing, 2015: 508�C521.
[5] ZHANG J, LIN H, NIE W Z, CHAISORN L, WONG Y K, KANKANHALLI M S. Human action recognition bases on local action attributes [J]. Journal of Electrical Engineering & Technology, 2015, 10(3): 1264�C1274.
[6] NOWAK E, JURIE F, TRIGGS B. Sampling strategies for bag-of-features image classification [M]. Computer vision �C ECCV 2006. Springer Berlin Heidelberg, 2006: 490�C503.
[7] WANG Heng, ULLAH M M, KL SER A, et al. Evaluation of local spatio-temporal features for action recognition [C]// British Machine Vision Conference. London: Springer, 2009: 1�C10.
SER A, et al. Evaluation of local spatio-temporal features for action recognition [C]// British Machine Vision Conference. London: Springer, 2009: 1�C10.
[8] WANG Heng, KLSER A, SCHMID C, et al. Dense trajectories and motion boundary descriptors for action recognition [J]. International Journal of Computer Vision, 2013, 103(1): 60�C79.
[9] HAO Zong-bo, ZHANG Qian-ni, EZQUIERDO E, et al. Human action recognition by fast dense trajectories [C]// Proceedings of the 21st ACM international conference on Multimedia. Barcelona: ACM, 2013: 377�C380.
[10] BEAUDRY C, PETERI R, MASCARILLA L. Action recognition in videos using frequency analysis of critical point trajectories [C]// 2014 IEEE International Conference on Image Processing (ICIP). Paris: IEEE, 2014: 1445�C1449.
[11] SEO J J, BADDAR W J, KIM D H, et al. Human action recognition using time-invariant key-trajectories describing spatio-temporal salient motion [C]// IEEE International Conference on Image Processing. Quebec City: IEEE, 2015: 586�C590.
[12] NI Bing-bing, MOULIN P, YANG Xiao-kai, et al. Motion Part Regularization: Improving action recognition via trajectory group selection [C]// Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3698�C3706.
[13] ZHANG Bo, ROTA P, CONCI N, et al. Human interaction recognition in the wild: Analyzing trajectory clustering from multiple-instance-learning perspective [C]// IEEE International Conference on Multimedia and Expo. Torino: IEEE, 2015: 1�C6.
[14] IOSIFIDIS A, TEFAS A, PITAS I. Merging linear discriminant analysis with Bag of Words model for human action recognition [C]// IEEE International Conference on Image Processing. Quebec City: IEEE, 2015: 832�C836.
[15] ELGUEBALY T, BOUGUILA N. Improving codebook generation for action recognition using a mixture of Asymmetric Gaussians [C]// Computational Intelligence for Multimedia, Signal and Vision Processing (CIMSIVP), 2014 IEEE Symposium on. Orbando, FL: IEEE, 2014: 1�C7.
[16] WANG Yang-yang, LI Yi-bo, JI Xiao-fei. Human action recognition based on global gist feature and local patch coding [J]. Management Review, 2015, 21(11): 38�C43.
[17] GUO Kai, ISHWAR P, KONRAD J. Action recognition from video using feature covariance matrices [J]. IEEE Transactions on Image Processing, 2013, 22(6): 2479�C2494.
[18] BROX T, MALIK J. Object segmentation by long term analysis of point trajectories [C]// Proc European Conference on Computer Vision. Crete, Greece: Springer, 2010: 282�C295.
[19] SENER F, IKIZLER-CINBIS N. Two-person interaction recognition via spatial multiple instance embedding [J]. Journal of Visual Communication & Image Representation, 2015, 32: 63�C73.
[20] CHEN Yi-xin, BI Jin-bo, WANG J Z. MILES: Multiple-instance learning via embedded instance selection [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2006, 28(12): 1931�C1947.
[21] GAO Cheng-qiang, YANG Lu-yu, DU Yin-he, et al. From constrained to unconstrained datasets: An evaluation of local action descriptors and fusion strategies for interaction recognition [J]. World Wide Web-internet & Web Information Systems, 2015, 19(2): 1�C12.
[22] XIA Li-min, SHI Xiao-ting, TU Hong-bin. An approach for complex activity recognition by key frames [J]. Journal of Central South University, 2015, 22(9): 3450�C3457.
(Edited by HE Yun-bin)
���ĵ���
����Э�������ϡ���ʾ�Ľ�����Ϊʶ��
ժҪ��������Ϊʶ���Ǽ�����Ӿ���ģʽʶ�������һ����Ҫ�о������ڼ��ϵͳ���˻��������˹����ܵȷ�����й�����Ӧ��ǰ�������������һ�ֻ���Э�������ϡ���ʾ�Ľ�����Ϊʶ�������ȣ�����Ƶ����ȡ�ij��ܹ켣���о����γɲ�ͬ�Ĺ켣Ⱥ�飬�������ع켣������������������ȡ��Ӱ�졣Ȼ��ͨ��Э�������Թ켣ͨ�����������������õ��н�ǿ���ֶȵĹ켣ͨ������������������ά�ȸ��ͣ������ܹ���Ч�����������������������ͳ����������������⣻����ϡ���ʾ����������������ϡ����롣����ö�ʾ��ѧϰ������Ϊ���ࡣ��UT-Interaction���ݼ���WEB-Interaction���ݼ��ϵ�ʵ��֤���˱��ķ�������Ч�ԡ�
�ؼ��ʣ�����ʶ�𣻳��ܹ켣��ϡ����룻��ʾ��ѧϰ
Foundation item: Project(51678075) supported by the National Natural Science Foundation of China; Project(2017GK2271) supported by the Science and Technology Project of Hunan Province, China
Received date: 2016-06-14; Accepted date: 2017-12-05
Corresponding author: XIA Li-min, PhD, Professor; Tel: +86�C13974961656; E-mail: xlm@mail.csu.edu.cn

