J. Cent. South Univ. (2012) 19: 2266-2271
DOI: 10.1007/s11771-012-1270-4
Aware conflict detection of non-uniform memory access system and prevention for transactional memory
WANG Rui-bo(���), LU Kai(¬��), LU Xi-cheng(¬����)
School of Computer, National University of Defense Technology, Changsha 410073, China
? Central South University Press and Springer-Verlag Berlin Heidelberg 2012
Abstract: Most transactional memory (TM) research focused on multi-core processors, and others investigated at the clusters, leaving the area of non-uniform memory access (NUMA) system unexplored. The existing TM implementations made significant performance degradation on NUMA system because they ignored the slower remote memory access. To solve this problem, a latency-based conflict detection and a forecasting-based conflict prevention method were proposed. Using these techniques, the NUMA aware TM system was presented. By reducing the remote memory access and the abort rate of transaction, the experiment results show that the NUMA aware strategies present good practical TM performance on NUMA system.
Key words: transactional memory; non-uniform memory access (NUMA); conflict detection; conflict prevention
1 Introduction
Parallel programming has been employed for many years, mainly in high performance computing. With the development of multi-core and many-core processors [1], desktop developers started using parallel programs to exploit processor cores. Most parallel programs used locks as synchronization mechanism [2-3], but it was not easy to avoid deadlock [4], priority inversion and lock convoying. Given the above problems, it was not surprising to see a large amount of researches aiming at making parallel programming easier. One of the most appealing solutions is transactional memory (TM) [5-9]. Transactional memory was a synchronization primitive providing atomic and isolated execution for regions of code. Developers could simply use the atomic primitive to define a critical section, and the data race inside the critical section would be resolved automatically.
Transaction memory was originally designed for shared memory system such as multi-core and SMP (symmetric multi-processing) system. With the development of direct connect architecture, the processor is optionally directly connected to other CPUs through a proprietary extension running on top of additional natively implemented interfaces allowing support of a cache-coherent NUMA (CC-NUMA) multi-CPU memory access protocol. In other words, the modern SMP systems are NUMA now. Under NUMA, a processor could access its own local memory faster than non-local memory, which is totally different from SMP. The performance of existing TM implementations running on NUMA system is poor, and slow non-local memory access might be an issue [10].
To solve the problem, a latency based conflict detection method is presented. Traditional conflict detection process is divided into two levels according to the different memory access latency. Each level has a specific detecting strategy. With the new method, the remote memory access is reduced dramatically.
To reduce the transaction conflicts, a forecasting based conflict prevention method is presented. A new scheduler is added before each transaction starts. The scheduler uses a forecasting algorithm to predict the future conflict probability of transaction. The probability was used to make choice of suspending or starting the transaction immediately.
Using these techniques, a NUMA aware TM system was presented. Currently, there is no other TM designed for NUMA system, but some researchers tried to deploy TM on distributed memory system such as cluster. The similar point is that one could view NUMA as a very tightly coupled form of cluster. MANASSIEV et al [11] presented a system which was a version-based distributed transactional memory that replicated all program states on all machines. Their implementation was based on distributed shared memory (DSM) [12]. The approach was likely to have problems scaling to a large number of machines even if the underlying computation was highly paralleled because all ��writes�� operations must be sent to all nodes and all nodes must agree with all transaction commits.
Cluster-STM [13] and DiSTM [14] did not rely on the DSM mechanism to achieve memory coherence. Cluster-STM was a word-based software transaction memory system which was implemented on top of GASNet [15] communication library. The design required moving objects to the local node before writing to it. Because the approach did not contain mechanisms to cache or prefetch remote objects, latency might be an issue. DiSTM focused on providing TM for clustered computing. It used ProActive [16] framework to do the remote memory access. The essential differences were: 1) Cluster-STM was word-based and DiSTM was object- based; 2) Cluster-STM was designed for large-scale cluster and DiSTM mainly focused on small-scale cluster.
2 Preliminary experiment
To realize the different TM performance impacts from traditional SMP and NUMA system, a preliminary experiment was built on a simulated machine equipped with four processors. Each processor had four 1.0 GHz x86-64 cores and was attached with 4 GB RAM.
The system was simulated by GEMS and Simics. To allow the operating system to identify the NUMA hardware and locality information, Simics should simulate several ACPI forms such as SRAT and SLIT. All the precise hardware operation latencies were provided by GEMS. With the lack of support of NUMA architecture, a NUMA-behavior module was added to the system. Three typical transactional memory systems were chosen to analyze the memory access pattern on NUMA system: RSTM [17], TinySTM [18] and TL2 [19].
For simplicity, the simulations had an IPC of 1. Each processor core has a 64 kB instruction cache and a 64 kB data cache with three-cycle access latency. The 1MB L2 cache with an access time of 16 cycles was shared by the four cores in one processor chip. Local memory has an access latency of 240 cycles. The of non-local memory access latency NUMA system varied from 2 to 8 times of 240 cycles. The operating system was Fedora 5 with a Linux kernel version 2.6.15.
The benchmark was Stmbench7 [20]. It was complex enough and its workloads were more realistic. All the executables used in the experiment were created using ���CO3�� and ���CDNDEBUG�� compilation settings of GNU g++. The TM implementations were compiled with their default settings. All results were averaged over multiple runs. The benchmark was configured with a small data structure and read-write workloads with 60% read-only operations.
Figure 1 shows the total throughput in operations per second with thread number ranging from 2 to 16, where ��CC-NUMA 1:2�� represents that the ratio between local and remote memory access latency is 1:2.
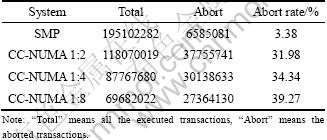
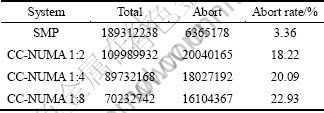
With increasing the remote memory access latency, the performances of three TM implementations drop very quickly. According to the results, the remote memory access latency is the key factor influencing TM performance on NUMA system. How to reduce the remote access is the key problem while the remote access is inevitable. To analyze the results, the transaction statistics of RSTM running with 16 threads is listed in Table 1.
The abort rate on NUMA system is about 10 times of the SMP system. If the abort rate remains high, the computing resource will be wasted on transaction��s rollback and restarting. How to reduce the abort rate is the emerging challenge. HARRIS and FRAISER [21] evaluated several TM implementations on a NUMA system compared to a 4-processor SMP system. They might not be aware of the different TM performance behaviors between SMP and NUMA.
3 Latency-based conflict detection
To reduce the remote memory access, a latency- based conflict detection method was proposed.
A typical node of the NUMA system was an SMP machine with several multi-core processors. The local memory access inside a node was fast while the remote memory access among nodes was much slower depending on the network hops. There were two conflict detection strategies widely used in TM implementations, eager and lazy. No matter which strategy was chosen, the conflict detection was processed among all the transactions. Figure 2(a) shows the status of the traditional conflict detection, where the dashed line represents the relationship of detection. The frequent memory access in conflict detection makes significant performance degradation on NUMA systems.
To reduce the expensive network communications, a latency-based conflict detection was presented. The whole system should be separated into slow and fast parts according to the different memory access latencies. For simplicity, the physical node was used as the separation boundary assuming all the nodes were fully connected. The fast part uses the eager policy to detect the conflict as early as possible while the slow part uses the lazy policy to detect the conflict as late as possible in order to reduce the network communications. Figure 2 shows the differences between the new strategy and the traditional conflict detection.
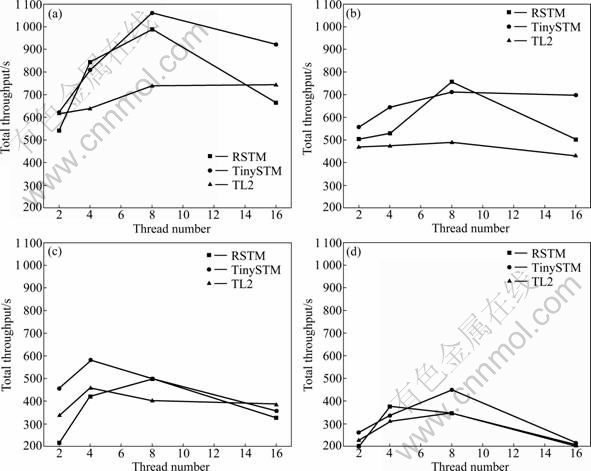
Fig. 1 Stmbench7 throughput results on SMP and NUMA systems: (a) SMP; (b) CC-NUMA 1:2; (c) CC- NUMA 1:4; (d) CC-NUMA 1:8
Table 1 Transaction statistics of RSTM in benchmark Stmbench7 (16 threads)
3.1 Detection inside a node
This is the first level of the conflict detection process. The visible reader and the eager writer were used. The detection was followed by every memory ��read�� and ��write�� operation. The conflict would be detected as early as possible. This policy could benefit from the fast local memory access inside a node. The committed transaction would enter the next level for further processing.
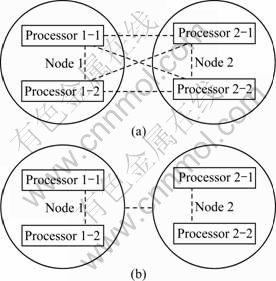
Fig. 2 Comparison of traditional and latency-based conflict detection: (a) Traditional conflict detection; (b) Latency-based conflict detection
3.2 Detection among nodes
A transaction reached here would be queued to do the global commitment. First, the transaction would ask for a global token. It meant that only one transaction could commit globally at a time. Secondly, the transaction would broadcast its write-set to the other nodes. All the data would be bloom filtered in order to make the network packet smaller. The other nodes would check if there were any conflicts. The conflicted transactions would abort and restart. After all the acknowledgements were received, the committing transaction would update the data globally and return the token. The policy was a lazy strategy similar to TCC [22].
4 Forecasting-based conflict prevention
The traditional TM design was used to maximize the number of running transactions to improve performance. But the design was not suitable for NUMA architecture. A conflict prevention method was used to deal with the problem. As shown in Fig. 3, the prevention method was scheduled before the transaction started. It used a forecasting algorithm to predict the probability of the future conflict of this transaction. The transaction would be suspended if it has a large potential for conflict with other running transactions.
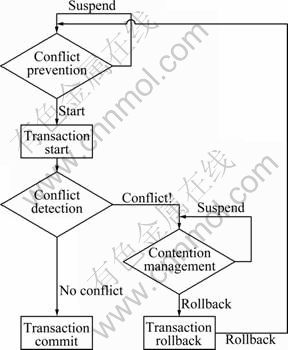
Fig. 3 Transaction flow with conflict prevention
Define D(a, b) as the distance between transactions a and b which represents the hops between running processor cores of each transaction. If the processor cores are in the same chip, D(a, b)=0; otherwise, it would be the hops between chips. Define P(a, b) as the number of historical conflicts between transaction a and b and Q as the running transaction set. The probability of future conflict Sa is
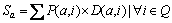
If Sa reaches the threshold Y, suspend the transaction until Sa is lowered. The intention of the conflict prevention method is reducing conflicts to increase the successful rate of transactions.
The time complexity of the algorithm was O(n). The TM system should preserve a two-dimensional array P. The array P could be packed because it is a sparse matrix.
Actually, the key problem is the threshold value Y. For simplicity, each running thread has its own threshold value. The initial value is 1. When the transaction is successful committed, Y=Y+1; when the transaction fails, Y=(Y+S)/2. The S here represents the future conflict value of the running transaction of thread.
5 Experiment
The experiment environment is the same as that in Section 2. The NUMA TM prototype is based on RSTM.
Figure 4 shows the total throughput in operations per second with thread count ranging from 2 to 16. Due to the algorithm overheads, the performance of NUMA aware implementation is not good on SMP system while there is no difference between local and remote memory accesses. With increasing the remote memory access latency, the NUMA aware implementation shows better performance and scalability. For example, the performance of RSTM-NUMA is nearly doubled on CC-NUMA 1:8.
To analyze the results, the transaction statistics of NUMA aware implementation running with 16 threads is listed in Table 2. The abort rate is only about half of the before. The NUMA aware methods reduced the abort rate and provided a good practical performance.
6 Conclusions
1) Currently, there is no other TM designed for NUMA system. The NUMA aware implementation here presents a new research idea for transactional memory.
2) Using TM on NUMA system is totally different from the SMP system because of the slower remote memory access. The TM design derived from multi-core or SMP system is not suitable on NUMA architecture.
3) To achieve high performance, the NUMA aware conflict detection and prevention methods are introduced. By reducing the remote memory access and abort rate of transaction, the NUMA aware implementation has got a good practical performance.
4) The TM research community should be aware of the different performance behaviors between SMP and NUMA systems. This work motivates more detailed study of using TM on NUMA system.
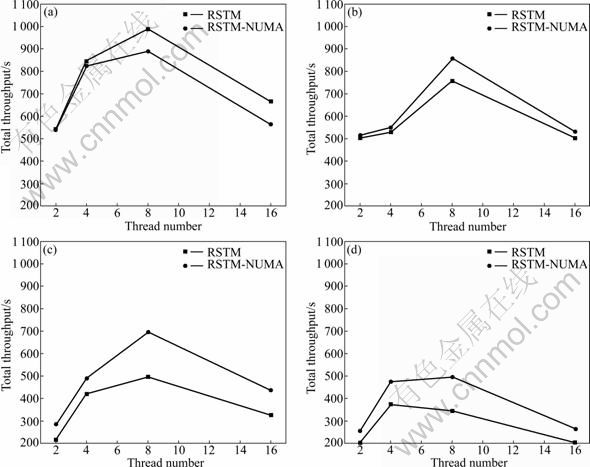
Fig. 4 Stmbench7 throughput results on SMP and NUMA systems: (a) SMP; (b) CC-NUMA 1:2; (c) CC- NUMA 1:4; (d) CC-NUMA 1:8
Table 2 RSTM-NUMA��s transaction statistics in benchmark Stmbench7 (16 threads)
References
[1] MUDGE T. Multicore architectures [C]// Proceedings of the 2007 International Conference on Compilers, Architecture, and Synthesis for Embedded Systems. Salzburg, Austria: ACM, 2007: 208.
[2] KONGETIRA P, AINGARAN K, OLUKOTUN K. Niagara: A 32-way multithreaded SPARC processor [J]. IEEE MICRO, 2005, 25(2): 21-29.
[3] HERLIHY M. The art of multiprocessor programming [C]// Proceedings of the Twenty-Fifth Annual ACM Symposium on Principles of Distributed Computing. Denver, CO, USA: ACM, 2006: 1-2.
[4] SMARAGDAKIS Y, KAY A, BEHRENDS R, YOUNG M. General and efficient locking without blocking [C]// Proceedings of the 2008 ACM SIGPLAN workshop on Memory Systems Performance and Correctness. Seattle, WA, USA: ACM, 2008: 1-5.
[5] HERLIHY M, MOSS J. Transactional memory: Architectural support for lock-free data structures [C]// Proceedings of the 20th Annual International Symposium on Computer Architecture. San Diego, CA: IEEE Computer Society Press, 1993: 289-300.
[6] SHAVIT N, TOUITOU D. Software transactional memory [C]// Proceedings of the 14th ACM Symposium on Principles of Distributed Computing. Ottawa, Ontario, Canada: ACM, 1995: 204- 213.
[7] HARRIS T, CRISTAL A, UNSAL O, AYGUADE E, GAGLIARDI F, SMITH B, VALERO M. Transactional memory: An overview [J]. IEEE MICRO, 2007, 27(3): 8-29.
[8] MCDONALD A, CARLSTROM B, CHUNG J, MINH C, CHAFI H, KOZYRAKIS C, OLUKOTUN K. Transactional memory: The hardware-software interface [J]. IEEE MICRO, 2007, 27(1): 67-76.
[9] HERLIHY M. The transactional manifesto: Software engineering and non-blocking synchronization [C]// Proceedings of the 2005 ACM SIGPLAN Conference on Programming Language Design and Implementation. Chicago, IL, USA: ACM, 2005: 280.
[10] WANG Rui-bo, LU Kai, LU Xi-cheng. Investigating transactional memory performance on ccNUMA machines [C]// Proceedings of the 18th ACM International Symposium on High Performance Distributed Computing. Garching, Germany: ACM, 2009: 67-68.
[11] MANASSIEV K, MIHAILESCU M, AMZA C. Exploiting distributed version concurrency in a transactional memory cluster [C]// Proceedings of the 11th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. New York, USA: ACM, 2006: 198-208.
[12] AMZA C, COX A, ZWAENEPOEL W. Conflict-aware scheduling for dynamic content applications [C]// 4th USENIX Symposium on Internet Technologies and Systems. Seattle, Washington, USA: USENIX, 2003: 71-85.
[13] BOCCHINO R, ADVE V, CHAMBERLAIN B. Software transactional memory for large scale clusters [C]// Proceedings of the 13th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. Salt Lake City, UT, USA: ACM, 2008: 247-258.
[14] KOTSELIDIS C, ANSARI M, JARVIS K, LUJAN M, KIRKHAM C, WATSON I. DiSTM: A software transactional memory framework for clusters [C]// Proceedings of the 37th International Conference on Parallel Processing. Portland, Oregon, USA: IEEE Computer Society, 2008: 51-58.
[15] BONACHEA D. GASNet specification, v1.1 [R]. Berkeley: CS Division, EECS Department, University of California, 2002.
[16] BADUEL L, BAUDE F, CAROMEL D, CONTES A, HUET F, MOREL M, QUILICI R. Grid computing: Software environments and tools [M]. 1st Edition. London: Springer, 2006: 205-229.
[17] MARATHE V, SPEAR M, HERIOT C, ACHARYA A, EISENSTAT D, SCHERER W, SCOTT M. Lowering the overhead of nonblocking software transactional memory [R]. Rochester: Department of Computer Science, University of Rochester, 2006.
[18] FELBER P, FETZER C, RIEGEL T. Dynamic performance tuning of word-based software transactional memory [C]// Proceedings of the 13th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. Salt Lake City, UT, USA: ACM, 2008: 237-246.
[19] DICE D, SHALEV O, SHAVIT N. Transactional locking II [C]// Proceedings of the 20th International Symposium on Distributed Computing. Stockholm, Sweden: Springer-Verlag, 2006: 194-208.
[20] GUERRAOUI R, KAPALKA M, VITEK J. STMBench7: A benchmark for software transactional memory [C]// Proceedings of the Second European Systems Conference. Lisbon, Portugal: ACM, 2007: 315-324.
[21] HARRIS T, FRASER K. Language support for lightweight transactions [C]// Proceedings of the 2003 ACM SIGPLAN Conference on Object-Oriented Programming Systems, Languages and Applications. Anaheim, CA, USA: ACM, 2003: 388-402.
[22] HAMMOND L, CARLSTROM B, WONG V, CHEN M, KOZYRAKIS C, OLUKOTUN K. Transactional coherence and consistency: Simplifying parallel hardware and software [J]. IEEE Micro, 2004, 24(6): 92-103.
(Edited by DENG L��-xiang)
Foundation item: Projects(61003075, 61170261) supported by the National Natural Science Foundation of China
Received date: 2011-03-14; Accepted date: 2011-12-30
Corresponding author: WANG Rui-bo, PhD; Tel: +86-13874800145; E-mail: ruibo@nudt.edu.cn

