飞机座舱图形显示加速系统设计及FPGA实现
胡小龙1,周俊明1,夏显忠2,李 迅3,郑博文1
(1. 中南大学 信息科学与工程学院,湖南 长沙,410075;
2. 长沙湘计海盾科技有限公司,湖南 长沙,410007;
3. 国防科学技术大学 机电工程与自动化学院,湖南 长沙,410073)
摘 要:提出一种飞机座舱综合显示系统中基于现场可编程门阵列(FPGA)的2D图形硬件加速引擎设计方案,将图形分解为一系列基本的点和水平线输出。为避免图形加速引擎直接对SDRAM的零碎操作导致的存储器操作瓶颈,引入图形缓存机制,并根据图形像素的存储特点,提出远区域优先(FAF)图形缓存页面淘汰算法。讨论图形加速引擎内部各模块的逻辑结构及其逻辑设计,在对模块进行波形仿真的基础上,实现系统级仿真结果的可视化验证。仿真及实际应用结果表明,所提出的图形加速引擎提高了图形显示性能,满足当前飞机中对2D图形实时显示及飞控系统的可靠性要求。
关键词:2D图形;硬件加速;图形缓存;现场可编程门阵列
中图分类号:TP394;TN61 文献标识码:A 文章编号:1672-7207(2008)05-1042-07
Design and implementation of graphics accelerating display system based on FPGA
HU Xiao-long1, ZHOU Jun-ming1, XIA Xian-zhong2, LI Xun3, ZHENG Bo-wen1
(1. School of Information Science and Engineering, Central South University, Changsha 410075, China;
2. Changsha HCC-Hiden Technology Co.Ltd, Changsha 410007, China;
3. College of Mechatronics and Automation, National University of Defense Technology, Changsha 410073, China)
Abstract: A new design scheme of 2D graphic accelerating engine based on field programmable gate array (FPGA) in aircraft cockpit display system was studied. Graphics were output by transforming into a series of basic points and level lines. In order to avoid the memory bottleneck caused by the fragmentary operations of graphics accelerating engine to SDRAM directly, a graphics cache mechanism using farthest area first (FAF) buffering replacement algorithms was introduced in the graphic engine. The detailed logic architecture and logic design of the graphics engine were discussed. And a visual system-level verification method was proposed. The results of simulation and practical applications show that the graphics accelerating engine greatly improves the graphics display performance, which can meet the requirement of recent aircraft on 2D graphics’ real-time display and reliability of the flight control system.
Key words: 2D graphics; accelerating engine; graphics cache; field programmable gate array
现代飞机座舱显示系统正在向大屏幕综合化方向发展,飞行员可以在有限的视域内依靠1台或几台显示器,及时地获得来自雷达、光电系统、电子战系统、导航和识别等系统的各种信息[1-2]。在飞机座舱显示系统中图形显示占据重要地位,传统的飞行座舱图形显示方法大多通过处理器和软件技术来实现,而对于实时信息处理系统,处理器还需要进行繁重的数据分析和数据通信工作,这将导致图形显示性能受到影 响[3-4]。随着半导体技术的发展,FPGA(Field programmable gate array)的规模和集成度大大增加,并具有灵活、可靠和可重配置等特征[5],使它非常适合于实现飞机座舱图形显示硬件加速的一些特殊功 能[6-8]。将图形显示处理用FPGA硬件来实现,处理器可以像调用函数一样调用图形加速引擎,在显示帧存储器中生成图形画面并在显示设备上显示,从而大大减轻处理器负担。在此,本文作者以FPGA Advantage 7.2作为开发平台,用Verilog HDL语言设计一种用于飞机座舱的图形显示加速系统,并在Xilinx公司的FPGA Virtex-II系列器件XC2V1500上实现。该系统支持汉字和2D图形(点、线、圆、椭圆、多边形等及其填充)的硬件,支持前、背景图层数据的融合叠加,前、背景图层可以在预先设置的至多8个帧存储器中任意选取。由于图形加速引擎和前、背景显示控制共享片外的显示帧存储器,为避免图形加速引擎对SDRAM的零碎存取导致的SDRAM操作瓶颈[9-11],系统中采用图形缓存(Cache)机制。
1 系统总体结钩
基于FPGA的飞机座舱显示系统主要由高等级CPU和FPGA组成。CPU接收来自飞控、导航等系统来的显示数据,对数据进行格式化和预处理后送FPGA显示。FPGA内部包括CPU接口及命令FIFO、图形加速引擎、SDRAM控制及仲裁、显示控制等模块,其总体结构如图1所示。这里对系统中的CPU接口、命令FIFO和SDRAM控制及仲裁、显示控制等相关设计进行讨论。
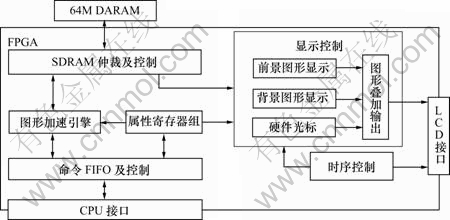
图1 系统总体结构框图
Fig.1 Architecture of graphics accelerating system
1.1 CPU接口及FIFO控制
CPU接口是FPGA与显示控制处理器之间的32bit通信接口,考虑到FPGA与CPU之间的数据通信不对称,即从CPU到FPGA是大量的图形命令,而从FPGA到CPU的是少量且零星的状态及寄存器信息;同时,为方便CPU编程并简化接口设计,CPU通过1个输入数据寄存器(只读)、1个错误状态寄存器(读写)及命令FIFO(只写)完成与FPGA之间的双向数据交换功能。
FIFO控制器是1个有限状态机,一方面对FIFO中的命令序列进行初步错误检查,确保有效的图形命令进入图形加速引擎,另一方面对命令序列进行初步分拣,将图形加速引擎命令和属性寄存器操作命令分离,图形加速命令送图形加速引擎,而属性寄存器操作命令在此直接处理。将图形加速命令和属性寄存器操作命令分离的优点是可以将它们并发处理以提高系统整体性能。CPU为获取属性寄存器内容,必须首先向FIFO发送读取属性寄存器命令,接着读取状态寄存器内容以便判断操作完成后再读取数据寄存器。这种操作方式效率不高,但由于软件很少需要从FPGA内部获取素性寄存器值,而且在软件设计上可以通过保留属性寄存器副本的方法来部分避免这些操作,因此,不会从根本上影响CPU接口的数据传输效率。
1.2 SDRAM仲裁及控制器
系统设计有64MB 128bit位宽SDRAM存储器,内部开设4个1 024×768的真彩色帧缓存,其余保留用于地图数据、自定义位图和自定义光标等。由于前景、背景显示控制器和图形加速引擎共享SDRAM中的帧缓存,为避免存取冲突,设计了带优先级的SDRAM仲裁器,优先顺序依次为前景显示存取、背景显示存取和图形加速引擎存取。另外,为了提高SDRAM数据传输效率,SDRAM控制器采用基于页的萃发(Burst)传输方式[12],这样,当工作频率为66 MHz时可以获得约1 Gb/s的带宽,能够满足屏幕刷新频率为60 Hz时前景、背景显示及图形加速引擎对存储器的带宽需要。
1.3 显示控制
显示控制模块的主要功能是按照屏幕刷新频率将前景、背景帧缓存中的数据取出,并按照分辨率为 1 024×768的VGA显示时序要求进行数据串行化,然后将串行化前景、背景视频数据、硬件光标进行融合与叠加,最终通过LCD接口输出。显示控制器通过DMA方式成块传送数据,为避免存储竞争延迟而导致画面闪烁,在前景、背景显示控制模块分别设置8 K的缓存来暂存待串行化视频数据。
2 图形加速引擎
2.1 图形加速处理过程
图形加速引擎提供按照画笔和填充属性生成2D图形如点、线、圆(弧)、椭圆(弧)和多边形及其填充的硬件加速机制。 2D图形加速处理过程是一个图形加工流水线,从命令FIFO分拣来的图形命令首先经过图形命令输入控制器对命令进行进一步容错处理并对命令参数序列进行格式化后,送图形命令处理器。图形命令处理器根据图形命令和参数的内容,将图形命令分为2类:一类是画椭圆(弧),需要调用相应的图形命令处理单元,将图形命令分解成基本图元,送到基本图元处理单元;另一类是解释性图形命令如清屏,直接转换成SDRAM操作命令。如图2所示。

图2 图形加速命令处理流程
Fig.2 Command process of graphics engine
图元输出完成2种基本图元“打点”和“画水平线”操作,其中打点图元最终分解为水平线图元。水平线图元控制器通过高速缓存控制器完成水平线的输出工作。
2.2 图形命令处理器
图形命令处理器由图形命令调度、线段命令处理单元、椭圆弧命令处理单元、打点命令处理单元、矩形梯形填充命令处理单元和清屏命令处理单元等组成,如图3所示。

图3 图形命令处理器内部逻辑
Fig.3 Graphics engine logic block
图形命令调度单元从图形命令输入控制器获得图形命令参数,并将图形命令参数放至图形命令参数区,最后,根据图形命令启动相应的图形命令处理单元。水平线输出单元进行最基本的图元处理,是其他图形加速操作(甚至画点)的基础,其他所有图形操作命令最终都通过水平线操作来光栅化。水平线的宽度为1个像素,长度可以为1至屏幕宽度,其属性包括颜色和线型掩码。水平线输出单元的功能是根据水平线在屏幕的起点X坐标、终点X坐标和Y坐标计算起止像素点在SDRAM显示缓存的物理地址,然后,根据水平线的颜色属性和线型掩码获得水平线各像素的像素值,并生成高速缓存指令,将像素值写入高速缓存。打点控制也是一个基本图元处理过程,这里定义的“点”由多个像素组成,具有大小和颜色属性。打点控制就是将打点申请转换成一系列水平线,送到水平线输出单元。
清屏的实质就是将整个显示帧缓存全部填充成透明色,尽管处理简单,但通过纯软件实现是非常费时的,因此,也实现了清屏的硬件指令。清屏指令在实现上绕过了高速缓存而直接操作外部SDRAM存储器,所以,清屏命令执行速度非常快。另外,为保证数据的一致性,在清屏之前,还需要对高速缓存进行清空。
2D图形命令如对线段、椭圆等的处理过程是首先将它们分解为“点”,同时“点”也继承了被分解图形如线段、椭圆等图形的画笔颜色、大小等属性,然后,调用打“点”控制单元,并最终通过水平线输出单元光栅化。而矩形和梯形的填充处理是直接将被填充区分解为水平线,然后,调用水平线输出单元光栅化。因此,这些命令的处理过程实质上是一个将图形分解为点或者水平线的过程。
2.2.1 线段命令处理
线段命令的最终结果是在给定的起止点以当前画笔属性在屏幕上画线。因此,线段命令参数包括屏幕坐标系起点坐标、终点坐标和画笔属性(颜色、大小即线宽、线型)。有多种绘制线段的算法如数字微分法、中点画线法和Bresenham算法等[13-15],考虑到FPGA资源的限制和方便硬件实现的特点,本文采用Bresenham算法绘制线段。Bresenham算法的基本思想通过直线上的当前点以及直线的方位(而不是精确的斜率)以步进的方式确定直线上的下一点。具体过程 如下。
a. 通过起点坐标(x0, y0)和终点坐标(xn, yn)的线段可以表达为直线方程:
f(x, y)≡ax+by+c=0。
其中:a=(y0-yn);b=(xn, x);c=x0*yn-xn*y0。
b. 通过点(x0, y0)确定线段上的下一临近点坐标,该点在线段所在方位最临近的3个点中选取。例如,若线段方位角在0~π/2之间,则这3个点为(x0+1, y0),(x0, y0+1)和(x0+1, y0+1),可以得到f(x0+1, y0)=a,f(x0, y0+1)=b和f(x0+1, y0+1)=a+b。显然,这3点不一定恰好在该线段上,但是,选取这3点中离线段最近的1个点,即f(x, y)的函数绝对值最小的点作为线段的下一点,记该点坐标为(x1, y1), f(x1, y1)函数值为δ0。
c. 同样,根据点(x1, y1)确定下一点坐标。下一点在(x1+1, y1),(x1, y1+1)和(x1+1, y1+1)中选取,可以得到f(x1+1, y1)=a+δ0,f(x1, y1+1)=b+δ0和f(x1+1, y1+1)= a+b+δ0。选取3个点的函数值绝对值最小的点作为线段上下一点,记该点坐标为(x2, y2),函数值f(x2, y2)为δ1。依次类推,直到得到线段终点(xn, yn)为止。
采用该算法不必计算直线斜率,不必做乘除法,只使用整数加减法操作和1个累加器,占用硬件资源非常少,算法速度很快,非常适合于用硬件实现。
2.2.2 椭圆弧命令处理
椭圆弧命令处理单元可以完成任意倾斜角度和任意弧的椭圆弧生成。椭圆弧参数包括椭圆中心点坐标、椭圆的2个半轴长度、椭圆的倾斜角度以及弧的起点和终点。
椭圆弧命令处理分2步进行。首先,根据椭圆2个半轴长度参数计算中心在原点、偏转角为0?的椭圆弧;然后,进行椭圆中心位置变换和椭圆角度旋转操作。中心在原点、偏转角为0?的椭圆弧按照步进式的Bresenham算法生成,具体算法见文献[13]。由于椭圆算法需要做大量的乘法运算,而椭圆旋转需要做三角函数运算,因此,计算量远比线段算法计算量大。为了在精度、速度和资源消耗方面取得平衡,在具体实现上考虑以下几点:首先,为满足椭圆计算的精度要求,参数计算过程全部采用64位整数,以保证不会产生累计精度损失;其次,为了达到100 MHz以上的独立综合速度设计要求并将资源消耗控制在合理的水平,采用共享多拍运算器的方法,即多个运算步骤共享1个加法器和1个乘法器,这样,既节约了FPGA的乘法器资源,又可以满足参数计算的时间要求;另外,对椭圆旋转所要求的三角函数运算,采取以空间换取时间及FPGA逻辑资源的策略,设计了三角函数查找表,在保证速度的同时尽可能减少资源的占用。
2.2.3 矩形和梯形填充命令处理
矩形填充命令处理单元将矩形填充区直接分解成若干条水平线,然后,送到画水平线控制单元中完成命令执行。对在屏幕x方向4像素对齐的矩形,可以进行快速矩形填充。快速矩形填充类似于清屏指令的处理:绕过高速缓存系统,直接通过SDRAM控制器对帧存相关区域进行操作。梯形填充命令处理单元同时驱动2个线段Bresenham算法控制单元,以步进方式寻找填充区每一水平线的2个端点,从而将梯形的填充分解为水平线。可通过设置梯形填充命令参数完成更一般的三角形填充,在软件的协助下还可以完成一般多边形的填充。
3 图形高速缓存
图形被分解为点或者水平线,这些操作需要非常频繁但长度较小的随机访问SDRAM中的帧存,而根据SDRAM存储器的操作特点,其少量而频繁的读/写效率远远低于大长度的突发读/写效率;另外,存储操作还需要保证前、背景显示控制以60 Hz的屏幕刷新频率读取帧存的带宽需求,所以,尽力避免图形加速引擎对SDRAM的零碎存储导致的SDRAM操作瓶颈是十分必要的[16-17],为此,在图形加速引擎中引入图形高速缓存。高速缓存控制系统为图形加速引擎提供了一个透明的SDRAM访问机制,并将图形命令所需要的对SDRAM小而频繁的访问合并为较大长度的突发读/写操作,达到高效访问的目的。
3.1 高速缓存结构
高速缓存的大小影响到图形引擎的效率和FPGA内部存储资源的占用。考虑到汉字硬件加速处理(支持32×32点阵)是该图形显示系统的一部分并且共用同一高速缓存系统,此外,对典型图形图像benchmark的统计分析结果表明[18],在基于贴块(tile)的3D图形渲染系统中,32×32像素的贴块是一个合理的选择,因此,本文的设计中也采用32×32像素的图形高速 缓存。
高速缓存结构如图4所示。FPGA内部采用1个256×128(bits)的RAM作为高速缓冲区,以便与128 bit位宽的SDRAM对应。高速缓冲区分成32个页面,每个页面有1 024位(对应32个真彩像素),占用8个128位宽的SDRAM地址。高速缓存与SDRAM之间的操作基本单位是页面,并且采用突发操作交换数据。高速缓存与SDRAM的页面之间采用全相关策略,因此,对64 M的SDRAM,其页面地址为19 bit。

图4 高速缓存控制系统内部结构
Fig.4 Graphics cache architecture
为了对高速缓存进行有效管理,使用32个32位的页面控制寄存器,每个缓存页对应1个页面控制寄存器。页面控制寄存器中有19位页面地址(Page)、1个修改标志位(Dirty)、1个有效位(Valid)和1个11位的计数器(Counter)。Page表示该缓存页中为SDRAM的第Page页数据,即SDRAM的高19位地址。Dirty指示该缓存页数据是否被修改过,Valid指示该缓存页是否有效。计数器Counter对有效且被修改过的页面在缓存中存在的时间进行计数。
3.2 高速缓存工作流程
高速缓存处理单元接收从图形处理单元来的写存储器命令,首先,将写命令中地址的高19位与页面寄存器中的Page域比较,查看目标地址是否在高速缓存中,若命中(在高速缓存),则直接修改相应地址对应的内容。否则,找一个空闲或可以丢弃的缓存页面,将该页面从SDRAM载入缓存,并设置Valid位,这个过程称为“页面置换”。然后,在缓存中完成图形数据的写操作,并在页面修改完成后后,设置Dirty位。
被修改过的页面(Dirty位为“1”)的页面需要及时回写到SDRAM,以保证屏幕内容的及时更新。页面回写的时机有3个:
a. 当图形命令处理器完成一组图形操作后,可以直接发送“Flush Cache”指令将缓存中所有Dirty页面回写。但这种方式使得缓存对图形处理器并不完全透明,故只在极少情况下使用。
b. 在页面置换过程中,当需要调入新的页面,而找不到可以被直接丢弃的页面时,需要找1个Dirty页并将其回写后使用。
c. 定时回写,对每个缓存页面设置计数器,当计数器满时回写。页面回写后,需要将Dirty位清零。
3.3 高速缓存页面置换策略
高速缓存置换策略极大地影响缓存的使用效率,若没有一个好的页面置换策略,则会出现将随后就要使用的页面置换的情况。所以,高速缓存页面置换算法的宗旨就是尽量将以后或短时间之内不会使用的页面淘汰。目前,存在多种高速缓存页面置换算法如随机、LRU(最近最久未使用)、FIFO(先进先出)算法 等[16],其中LRU是性能较好也是最常见的,大多数CPU的指令和数据Cache、操作系统的虚拟存储管理中都采用LRU算法。
图形系统中采用LRU置换算法不失为一种理想的选择,但是,LRU算法不仅需要占用大量的FPGA资源,更重要的是,LRU算法的提出完全是基于程序代码执行和程序数据使用的“局部性”原理,本文设计的图形系统高速缓存中缓存的是图形数据,而在屏幕画图大多局限于比较小的空间区域,因此,根据图形的“空间局部性”原理,提出高速缓存的“远区域优先(FAF-farthest area first)页面置换”算法。
FAF算法的实质就是将离当前图形操作区域最远的区域所占页面淘汰,所以,该算法的精确实现与帧存的大小和存储器组织方式有关。为了简化FPGA设计,采取一种近似策略:即离当前操作地址最远的页面优先淘汰,为提高地址比较速度,使用多个比较器进行并发操作。仿真结果表明,FAF算法在所设计的2D图形加速引擎中效果良好,在小缓存(如32×32)时,FAF与LRU算法性能相近,但在资源使用上比LRU算法更节省。
4 结果及分析
采用Modelsim6.1对图形加速引擎进行功能和时序仿真。仿真结果表明,图形显示加速系统在系统时钟频率为100 MHz时,典型的操作时间为:清屏 2 100 μs;在画笔宽度为1时画长度为100的线段所需操作时间为130 μs;分辨率为100×100的矩形填充时间为200 μs;画分辨率为200×150的斜椭圆时间为230 μs,满足飞机座舱图形显示系统对显示时间的设计要求。
为了方便地进行逻辑功能验证,设计可视化的系统级仿真工具。其基本思想是建立SDRAM存储器仿真模型,将帧存储器中的仿真数据读出并写到1个文本文件中,然后,将文本数据转换成bmp标准格式的图片,便可以通过常用的图片工具进行检查和验证,仿真结果如图5所示。图5中从左到右显示了:4个100×100的正方形,分别填充不同的颜色;画笔宽度为1的20个点;3条画笔宽度不同的直线;2个不同参数的圆;1个圆弧和4个不同参数的椭圆。

图5 仿真结果
Fig.5 Simulating result
本文设计的图形加速系统在Xilinx公司的FPGA Virtex-II系列器件XC2V1500上进行综合,综合工具为Xilinx公司的ISE8.1。综合结果表明,图形加速引擎占用4800多个SLICE和22KB Block RAM,为了满足OSD(On Screen Display)和其他辅助逻辑的需 要,XC2V1500器件资源的综合占用率仍可达75%左右,满足可靠性设计的降额要求。
5 结 论
a. 针对当前飞机座舱对2D图形显示需求,并考虑到FPGA灵活、可靠和可重配置的特点,提出并实现了1个基于FPGA的2D图形加速引擎。通过将基本的2D图形处理及一些扩展操作(如自定义仪表盘、2D地图)进行硬件加速来代替以前的纯软件处理,不仅将CPU从繁重的图形显示工作中解脱出来,而且大大提高了图形显示性能和系统的稳定性。
b. 为避免图形加速引擎直接对SDRAM零碎操作导致的存储器操作瓶颈,引入了图形缓存机制,并根据图形在屏幕像素的存储特点,提出了“远区域优先(FAF)”图形缓存页面淘汰算法。FAF算法在图形加速引擎中应用效果较好,在小缓存(如32×32)时,FAF与LRU算法性能相近,但在FPGA资源使用上FAF比LRU更节省。
c. 为了方便地进行逻辑功能验证,设计了系统级仿真结果的可视化工具。在模块逻辑设计阶段,由于模块功能相对简单,直接进行波形仿真是合理的;但在模块集成时,随着测试覆盖面变广,仿真规模急剧增大,直接使用仿真波形来验证和排错将变得非常困难,而采用可视化工具可以将仿真结果直观地通过图片表达出来。
参考文献:
[1] 张 波, 张焕春, 经亚枝, 等. 基于DSP和FPGA的座舱图形显示系统关键技术研究[J]. 信息与控制, 2003, 32(6): 548-552.
ZHANG Bo, ZHANG Huan-chun, JING Ya-zhi, et al. Research on critical technology of graphics display system in aircraft cockpit based on DSP and FPGA[J]. Information and Control, 2003, 32(6): 548-552.
[2] 孔全存, 李成贵, 张凤卿. 主飞行仪表图形加速显示系统的FPGA设计[J]. 电子技术应用, 2007, 33(4): 93-97.
KONG Quan-cun, LI Cheng-gui, ZHANG Feng-qing. The FPGA design of graphics accelerated system in primary flight display[J]. Application of Electronic Technique, 2007, 33(4): 93-97.
[3] James C. Learn vertex and pixel shade programming with direct X9[M]. Texas Plano: Wordware Publishing Inc., 2004.
[4] Buttussi F, Chittaro L, Nadalutti D. A visual tool for modeling, reuse and sharing of X3D humanoid animations[C]// Proceedings of the 11th International Conference on 3D Web Technology. New York, 2006: 101-108.
[5] Chang C, Wawrzynek J, Brodersen R W. BEE2: A high-end reconfigurable computing system[J]. Design and Test of Computers, 2005, 22: 114-125.
[6] 邹雪城, 陈毅成, 刘政林, 等. 手持设备中图形加速引擎BitBLT的设计[J]. 华中科技大学学报: 自然科学版, 2005, 33(1): 34-38.
ZOU Xue-cheng, CHEN Yi-cheng, LIU Zheng-lin, et al. The design of BitBLT engine embedded in graphics accelerator for handheld devices[J]. Journal of Huazhong University of Science and Technology: Nature Science, 2005, 33(1): 34-38.
[7] Holten L. FPGA-based 3D graphics processor with PCI-bus interface[C]//NORCHIP 2002 Proceedings. Copenhagen, Denmark, 2002: 316-321.
[8] Kelley M, Winner S, Gould K. A scalable hardware render accelerator using a modified scanline algorithm[C]//SIGGRAPH Proceedings. Chicago: Illinois, 1992: 241-248.
[9] 汤晓安, 郝建新, 蔡宣平. 一种高速图形系统帧存的体系结构[J]. 计算机工程与设计, 2001, 22(l): 48-50.
TANG Xiao-an, HAO Jian-xin, CAI Xuan-ping. A kind of system structure of high speed graphics frame buffer[J]. Computer Engineering and Design, 2001, 22(l): 48-50.
[10] Nishimura S, Kunii T L. A scalable graphics computer with virtual local frame buffers[C]//SIGGRAPH Proceedings. New Orleans, 1996: 365-372.
[11] Dunnett G, White M, Lister P, et al. The image chip for high performance 3D rendering[J]. IEEE Computer Graphics and Applications, 1992, 12(3): 41-51.
[12] Duguet F, Drettakis G. Flexible point-based rendering on mobile devices[J]. IEEE Computer Graphics and Applications, 2004, 24(4): 57-63.
[13] 孙家广, 杨长贵. 计算机图形学[M]. 北京: 清华大学出版社, 1995.
SUN Jia-guang, YANG Chang-gui. Computer graphics[M]. Beijing: Tsinghua University Press, 1995.
[14] 苏光大. 微机图象处理系统[M]. 北京: 清华大学出版社, 2000.
SU Guang-da. Micro-computer image processing system[M]. Beijing: Tsinghua University Press, 2000.
[15] David F R. Procedural elements of computer graphics[M]. Boston: McGraw-Hill, 1997.
[16] Antochi I, Juurlink B, Vassiliadis S, et al. Memory bandwidth requirements of tile-based rendering[C]//Proceedings of the Third and Fourth International Workshops SAMOS 2003 and SAMOS 2004 (LNCS 3133). Samos, Greece, 2004: 323-332.
[17] Scott H, Li Z Y, Compton K. Configuration caching management techniques for reconfigurable computing[C]// Proceedings of the IEEE Symposium on Field-Programmable Custom Computing Machines. Napa, California, 2000: 22-36.
[18] Iosif A, Ben J, Stamatis V. Selecting the optimal tile size for low-power tile-based rendering[C]//13th Annual Workshop on Circuits, Systems, and Signal Processing (ProRISC2002). Veldhoven, 2002: 235-242.
收稿日期:2008-03-11;修回日期:2008-05-22
基金项目:国家自然科学基金资助项目(60475035)
通信作者:胡小龙(1969-),男,湖南汉寿人,博士,副教授,从事嵌入式系统及计算机应用研究;电话:13973184869;E-mail: huxl@csu.edu.cn

