QoS-oriented service composition based on mapping relation tree
来源期刊:中南大学学报(英文版)2012年第8期
论文作者:张英 刘晓明 王智学 陈立
文章页码:2194 - 2202
Key words:service composition; quality of service; mapping relation tree; divide and conquer
Abstract: Service composition is a hot and active research area in service-oriented computing which has gained great momentum. An quality of service (QoS) oriented and tree-based approach was proposed to implement service composition efficiently. Firstly, service descriptions were transformed to mapping relations which denote the association between input and output concepts. Then, the service composition problems were resolved by building mapping relation tree dynamically based on the divide and conquer method, and all mapping relation trees were combined without redundant branch to obtain the composition scheme. Finally, the optimal composition scheme was chosen based on quality of service attributes including the preference of service request. Experiment results illustrate that this method can improve the composition efficiency and reduce the searching time by increasing the number of services in repository.
J. Cent. South Univ. (2012) 19: 2194-2202
DOI: 10.1007/s11771-012-1264-2![]()
ZHANG Ying(张英), LIU Xiao-ming(刘晓明), WANG Zhi-xue(王智学), CHEN Li(陈立)
Institute of Command Automation, PLA University of Science & Technology, Nanjing 210007, China
? Central South University Press and Springer-Verlag Berlin Heidelberg 2012
Abstract: Service composition is a hot and active research area in service-oriented computing which has gained great momentum. An quality of service (QoS) oriented and tree-based approach was proposed to implement service composition efficiently. Firstly, service descriptions were transformed to mapping relations which denote the association between input and output concepts. Then, the service composition problems were resolved by building mapping relation tree dynamically based on the divide and conquer method, and all mapping relation trees were combined without redundant branch to obtain the composition scheme. Finally, the optimal composition scheme was chosen based on quality of service attributes including the preference of service request. Experiment results illustrate that this method can improve the composition efficiency and reduce the searching time by increasing the number of services in repository.
Key words: service composition; quality of service; mapping relation tree; divide and conquer
1 Introduction
Service-oriented computing (SOC) is a new and agile computing paradigm which utilizes services as fundamental elements to support rapid, low-cost development of distributed applications in heterogeneous environments within and across organizational boundaries [1]. Services (or web services, or e-services) are self- contained, modular applications that can be described, published, located and dynamically invoked, in a programming language independent way [2]. Research on SOC spans over many interesting issues, and one of the most active areas is seamless and automatic composition of services in dynamic requirement, which has gained great momentum both in academia and in industry.
There are various methods for service composition. Some studies used the workflow-based composition methods [3-6], which were mostly used in the situation that the request had already defined the process model, but automatic program was required to find the atomic services to fulfill the requirement [3]. Some studies fell in the realm of artificial intelligence (AI) planning [7-13] to implement service composition, such as Petri nets [7-8], π-calculus [9], abductive event calculus [10], theorem proving and logic reasoning [11-13]. They regarded the service function, i.e. the IOPE (input- output precondition effect) of a service, as its preconditions and effects in the planning context resolved the composition problem by finding a path from the initial state to the target state. However, if some non-function attributes of services become important to the user, a selection mechanism would be needed to find the optimal plan. Recently, some researchers proposed searching techniques, especially the graph-based searching or tree-based searching methods [14-18] in order to speed up the composition process. They treated services as vertices and resolved the composition problem by finding paths between vertices. LIU et al [17] proposed a non-backtrace backward chaining web services dynamic composition framework based on mediator. However, this method could only obtain one solution of service composition ignoring that there may be more solutions, which may be better than the obtained one. An approach based on backward tree to compose operations of services automatically was proposed by DENG et al [18]. However, the choice of generation path was made before composition, which would result in the phenomena that the chosen path might not be the global optimal one, while the generation path was composed directly ignoring the redundant branch, and the optimal composition scheme was selected merely based on the length of path in the tree. In addition, these two methods didn’t consider the semantic similarity between concepts.
Based on the research mentioned above, an improved QoS (quality of service) oriented tree-based searching method for service composition was proposed in this work.
2 Preliminary definitions
Definition 1: Service definition
A service S is described as a 6-tuple:
S=ás, I, O, P, E, A?
where s is the name of a service; I is the input-set of a service; O is the output-set of the service; P and E represent the preconditions and effects of performing the service, respectively; A is the attribute set of a service, especially the QoS attributes. Five QoS properties were considered in this work: performance duration Qpd(S), whose unit is s; performance cost Qpc(S), whose unit is US $; reliability Qrel(S), availability Qava(S) and reputation Qrep(S), whose value ranges are [0, 1], [0, 1] and [0, 5], respectively. The definition and computation of the properties could be seen in related references, such as Refs. [19-20].
In theory, all these six aspects should be considered during service composition. However, the service definition is predigested to a 4-tuple, namely, S=ás, I, O, A?. When service in repository is mentioned in this work, it refers to the atomic service rather than composite service.
Definition 2: The mapping relation definition
For a given service S=ásn, I, O, A?, for each output ok![]() O, the mapping relation of ok is defined as ásn, I, Ssim?→ok, which means that the input concept I of S (its name is sn) is mapped to output ok by performing the service. Parameter Ssim is the semantic similarity between two concepts, 0≤Ssim≤1. The reason of introducing semantic similarity is based on the fact that if one concept could be provided by a service, its semantic similarity concepts may be produced by the same service, too. Although we use the method mentioned in Ref. [21], it is not the only resolution. The mapping relations could be formally described as a 2-tuple: Rmr=áo, r?, where r=ásn, I, Ssim?.
O, the mapping relation of ok is defined as ásn, I, Ssim?→ok, which means that the input concept I of S (its name is sn) is mapped to output ok by performing the service. Parameter Ssim is the semantic similarity between two concepts, 0≤Ssim≤1. The reason of introducing semantic similarity is based on the fact that if one concept could be provided by a service, its semantic similarity concepts may be produced by the same service, too. Although we use the method mentioned in Ref. [21], it is not the only resolution. The mapping relations could be formally described as a 2-tuple: Rmr=áo, r?, where r=ásn, I, Ssim?.
Moreover, if more than one service in service repository could product the output o, and the number of such services is j, the mapping relations of o could be
defined as ás1, I1, ![]() ?
?![]() …
…![]() ásj, Ij,
ásj, Ij, ![]() ?→o or Rmr=
?→o or Rmr=
ási, Ii, ![]() ?.
?.
áo, R?, ![]()
Definition 3: Mapping relations (MRs) of service repository
For a given service repository RSR=(S1, S2, …, Sn),
![]()
![]() in which Ii is the input set of Si,
in which Ii is the input set of Si,
and Oi is the output set of Si. The mapping relations of service repository are described as
RMR=áO, R?=![]()
![]()
ásk, Ik, ![]() ?
?
![]()
Definition 4: Service request definition
A service request SR is described as a 4-tuple:
SR=áRI, RO, RA, θ?
where RI and RO represent the input-set and output-set of a service request, respectively; RA describes the QoS attributes of the service request; θ is the threshold of semantic similarity.
Generally, the query of candidate services is in sequence. In other words, all registered services must be scanned one by one to perform a service query. This is simple to understand, but the efficiency will decrease with increasing the number of registered services. In order to enhance the query efficiency, an MR table, which lists the mapping relations of service repository, is built in this work. Therefore, the searching space of service query will be reduced by retrieving the MR table instead of the whole service repository. The table will be updated periodically. If there is a new service registered successfully, its related information will be added to the table accordingly.
For example, if there are eight registered services in the service repository, as listed in Table 1, concept D is similar to concept K and Ssim(D, K)=0.8, the mapping relations of the service repository are shown in Fig. 1.
Table 1 Eight registered services of service repository


Fig. 1 Mapping relation of service repository
3 Service composition method
The divide and conquer (D&C) method [22] is an important technique in computer science. D&C works by breaking down a complex problem into some sub- problems of the same or related type, until these sub- problems become simple enough to be solved directly. These sub-problems are resolved independently and respectively. And the solutions to the sub-problems are then combined to give a solution to the original problem. It is a powerful tool for solving conceptually difficult problems.
Given a service request SR and mapping relations RMR of service repository, the D&C service composition method in this work includes three steps. Firstly, for each o![]() RO, build a mapping relation tree (MRT) dynamically. Then, combine all mapping relation trees to obtain the integrated resolution. If there is a redundant branch, eliminate the redundant branch. Finally, compute the QoS of each composition scheme and choose the optimal one by multiple attributes decision making (MADM) [23-27] method.
RO, build a mapping relation tree (MRT) dynamically. Then, combine all mapping relation trees to obtain the integrated resolution. If there is a redundant branch, eliminate the redundant branch. Finally, compute the QoS of each composition scheme and choose the optimal one by multiple attributes decision making (MADM) [23-27] method.
3.1 Building mapping relation tree
Definition 5: A mapping relation tree is a 3-tuple:
TMRT=(V, E, Ψ)
where V is a finite set of nodes, where a node is a 2-tuple Nnode=án, C?, in which n is the identifier of a node, C is a subset of input and output concepts concluded in the service repository; E is a finite set of ordered pairs of nodes, called directed edges, or arrows, where an edge is a 2-tuple Eedge=áe, sn?, in which e is the identifier of an edge, sn is the name of a service in service repository; Ψ:E→áV, V? is a function. The expression Ψ(ei)=áSstart, Send? represents that edge ei is connected from the node Sstart to Send. Its inverse is described as Ψ -1(áSstart, Send?)=ei.
Once a mapping relation tree is constructed, the nodes in the mapping relation tree represent the concepts which could be produced by the input concepts of current service request. The leaf nodes represent the concepts within the input concepts of current service request. A father node of one node represents the concepts that could be produced by the concept of the child node with a service, while the name of the service is represented by the edge between the father node and the child node.
For a given output concept o and mapping relations RMR, the mapping relation tree TMRT of o can be constructed automatically by Algorithm 1 shown in Fig. 2.
In Algorithm 1, if ![]() it means that the output o could not be produced by the current service repository, thus the algorithm is terminated. Otherwise, a first in first out (FIFO) queue Q is used to store the nodes which are waiting to be processed. EnQueue is a function which pushes an item into Q as the end of the queue, while DeQueue is a function which pops the head item of Q then deletes it from Q. Path(n) is a function which is used to return the path from the father node of n to root in a tree. The sub-problems are independent with each other and it is a prerequisite for using divide and conquer method. Here, if the sub-problems are dependent, it means that producing a concept A needs a concept B, while producing the concept B also needs the concept A directly or indirectly. In other words, there is a circular produce relation between two concepts A and B. Therefore,
it means that the output o could not be produced by the current service repository, thus the algorithm is terminated. Otherwise, a first in first out (FIFO) queue Q is used to store the nodes which are waiting to be processed. EnQueue is a function which pushes an item into Q as the end of the queue, while DeQueue is a function which pops the head item of Q then deletes it from Q. Path(n) is a function which is used to return the path from the father node of n to root in a tree. The sub-problems are independent with each other and it is a prerequisite for using divide and conquer method. Here, if the sub-problems are dependent, it means that producing a concept A needs a concept B, while producing the concept B also needs the concept A directly or indirectly. In other words, there is a circular produce relation between two concepts A and B. Therefore,
“![]() ” ensures that
” ensures that
the new child of current node has not been an end node through the path, which avoids the circular producing between two concepts.
Let us understand the algorithm by an instance. If the service request was SR=áRI, RO, RA, q ?, in which RI= {B, C, E}, RO=
1) The initialization is shown in Fig. 3(a), and there is only one node in Q, the root node o. Pop o from Q, and let the current processing node op=o, op・C={D}. Search in the MR and retrieve Rmr=áD, R?, R={áS2, {E}, 1?, áS4, {A, E}, 1?, áS8, {B, E}, 0.8?}. For the first element in R, Rmr・R・I1={E}, newconcept=Rmr・R・I1-RI={E}-{B, C, E} =![]() , it meant that all the necessary concepts to produce D by S2 were provided by service request directly. Then,
, it meant that all the necessary concepts to produce D by S2 were provided by service request directly. Then,
l=![]() , Rmr・R・I1
, Rmr・R・I1![]() Send))={E}
Send))={E}![]()
![]() =
=![]() ,
,
Rmr・R・![]() =1>0.9. Therefore, create a new node of MRT named n1, n1・C=(op・C-{D})
=1>0.9. Therefore, create a new node of MRT named n1, n1・C=(op・C-{D})![]() Rmr・R・I1=
Rmr・R・I1=![]()
![]() {E}= {E}, and create a new edge e1 with n1 as its start while root as its end, then push the node into Q. Similarly, for the second element in R, Rmr・R・I2={A, E}. newconcept= Rmr・R・I2-RI={A, E}-{B, C, E}≠
{E}= {E}, and create a new edge e1 with n1 as its start while root as its end, then push the node into Q. Similarly, for the second element in R, Rmr・R・I2={A, E}. newconcept= Rmr・R・I2-RI={A, E}-{B, C, E}≠![]() , but newconcept-
, but newconcept-

Fig. 2 Mapping relation tree building algorithm
RMR・O=![]() , which meant that some necessary concepts to produce D by S4 were not provided by service request directly, yet these concepts could be produced by some other services in current service repository. Create a new node n2 with n2・C=(op・C-{D})
, which meant that some necessary concepts to produce D by S4 were not provided by service request directly, yet these concepts could be produced by some other services in current service repository. Create a new node n2 with n2・C=(op・C-{D}) ![]() Rmr・R・I2, ={A, E} and a new edge e2, then push the node into Q. For the third element in R, Rmr・R・I3={B, E}, however, Rmr・R・Ssim3=0.8<0.9, which unsatisfied the conditions for creating a new node. Therefore, the new MRT is shown in Fig. 3(b), and there are two items in Q: the first is n1 while the second is n2.
Rmr・R・I2, ={A, E} and a new edge e2, then push the node into Q. For the third element in R, Rmr・R・I3={B, E}, however, Rmr・R・Ssim3=0.8<0.9, which unsatisfied the conditions for creating a new node. Therefore, the new MRT is shown in Fig. 3(b), and there are two items in Q: the first is n1 while the second is n2.
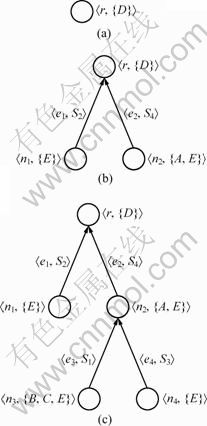
Fig. 3 Example of building MRT of output concept D
2) Pop n1 from Q, and let the current processing node op=n1. Search in the MR and retrieve Rmr=áE, R?, R={áS6, {C, F}, 1?}. Thus, Rmr・R・I={C, F}, newconcept= {F}≠![]() , and newconcept-RMR・O={F}≠
, and newconcept-RMR・O={F}≠![]() , which meant that some necessary concepts to produce D by S6 could be neither provided by service request directly nor produced by some other services in current service repository, and then quit the processing of current node. The tree MRT has no change.
, which meant that some necessary concepts to produce D by S6 could be neither provided by service request directly nor produced by some other services in current service repository, and then quit the processing of current node. The tree MRT has no change.
3) Pop n2 from Q, and let the current processing node op=n2, op・C={A, E}. Firstly, for A![]() op・C, search in the MR and retrieve Rmr=áA, R?, R={áS1, {B, C}, 1?, áS3, {E}, 1?}. For the first element of R, Rmr・R・I1={B, C}, newconcept=Rmr・R・I1-
op・C, search in the MR and retrieve Rmr=áA, R?, R={áS1, {B, C}, 1?, áS3, {E}, 1?}. For the first element of R, Rmr・R・I1={B, C}, newconcept=Rmr・R・I1-![]() , l=
, l=![]()
![]() {E}
{E}![]() {D}=
{D}=![]() , Rmr・R・
, Rmr・R・![]() =1>
=1>
0.9. Therefore, create a new node n3, n3・C=(op・C-{A}) ![]() Rmr・R・I1=={B, C, E}, and create a new edge e3 with n3 as its start and n2 as its end, then push the node n3 into Q. Similarly, for the second element of R, Rmr・R・I2={E},
Rmr・R・I1=={B, C, E}, and create a new edge e3 with n3 as its start and n2 as its end, then push the node n3 into Q. Similarly, for the second element of R, Rmr・R・I2={E},
newconcept=![]() , l=
, l=![]()
![]()
Send)={E}![]() {D}=
{D}=![]() , Rmr・R・
, Rmr・R・![]() =1>0.9. Create a new node n4, n4・C={E}, and create a new edge e4, then push the node n4 into Q. Secondly, for E
=1>0.9. Create a new node n4, n4・C={E}, and create a new edge e4, then push the node n4 into Q. Secondly, for E![]() op・C, it is unsatisfied the conditions for creating a new node (the reason mentioned above). Therefore, the current tree MRT is shown in Fig. 3(c), and there were two items in Q: the first is n3 while the second is n4.
op・C, it is unsatisfied the conditions for creating a new node (the reason mentioned above). Therefore, the current tree MRT is shown in Fig. 3(c), and there were two items in Q: the first is n3 while the second is n4.
4) Pop n3 from Q, op=n3. For B![]() op・C, because B
op・C, because B![]() RMR・O, quit the processing of concept B. For C
RMR・O, quit the processing of concept B. For C![]() op・C, search in the MR and retrieve Rmr=áC, R?, R={áS5, {D}, 1?}, Rmr・R・I={D}, newconcept={D}, l={e3,
op・C, search in the MR and retrieve Rmr=áC, R?, R={áS5, {D}, 1?}, Rmr・R・I={D}, newconcept={D}, l={e3,
e2}. However, because Rmr・R・I![]()
![]() =
=
{D}∩{A, E, D}={D}≠![]() , it meant that there was a circular producing relation between concepts C and D, and then quit the processing of concept C. For E
, it meant that there was a circular producing relation between concepts C and D, and then quit the processing of concept C. For E![]() op・C, it unsatisfied the conditions for creating a new node. Therefore, the tree MRT has no change.
op・C, it unsatisfied the conditions for creating a new node. Therefore, the tree MRT has no change.
5) Pop the head item n4 from Q, op=n4, op・C={E}, it is unsatisfied the conditions for creating a new node.
Because Q was empty, the algorithm was finished, and the final MRT was shown in Fig. 3(c).
3.2 Combining mapping relation trees
After building mapping relation trees of each output concept, the solutions of sub-problems were obtained, and then all mapping relation trees should be combined to the integrated solutions. Each path from leaf node to root node in a MRT represents a service composition scheme for the output concept. However, one mapping relation tree only describes the service composition schemes for one output concept, whereas service request usually has more than one output concept. Therefore, in order to obtain the service composition schemes for all output concepts of service request, the mapping relation trees are combined to the integrated scheme (IIS) of service composition.
Definition 6: Integrated scheme (IIS) of service composition For given ![]() in which
in which ![]() (1≤i≤n) is a MRT of oi, oi
(1≤i≤n) is a MRT of oi, oi![]() RO.
RO. ![]() {pi1, pi2, …, pim}, in which pij (1≤i≤n, 1≤j≤m) is a path from a leaf node to root of
{pi1, pi2, …, pim}, in which pij (1≤i≤n, 1≤j≤m) is a path from a leaf node to root of ![]() i.e. a composition scheme for producing the output concept oi. The integrated scheme of RO is described as
i.e. a composition scheme for producing the output concept oi. The integrated scheme of RO is described as ![]() 1≤i≤n.
1≤i≤n.
Obviously, according to the properties of Cartesian product of sets, the total number of integrated scheme
can be computed as |IIS|=![]() …×
…× ![]()
For instance, Algorithm 1 was used to build MRT of another output concept G, as shown in Fig. 4. ![]()
![]() there were
there were ![]() ×
×![]() integrated schemes, as shown in Fig. 5.
integrated schemes, as shown in Fig. 5.
There may be some redundancies in IIS, which can be eliminated by merging the repeated invoking service. If a service appears in more than one path in a IIS, it should be simplified by combining to one. For instance, the ![]() in Fig. 5 had redundancy because the service S3 was used to produce the concept D as well as the concept G, and it could be simplified, as shown in Fig. 6.
in Fig. 5 had redundancy because the service S3 was used to produce the concept D as well as the concept G, and it could be simplified, as shown in Fig. 6.
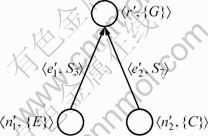
Fig. 4 MRT of output concept G
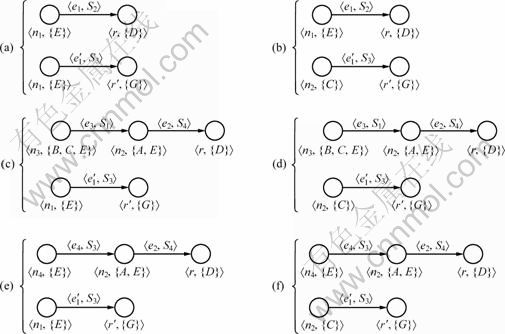
Fig. 5 Integrated schemes of output concepts D and G of service request: (a) IIS1; (b) IIS2; (c) IIS3; (d) IIS4; (e) IIS5; (f) IIS6
![]()
Fig. 6 Result of simplifying IIS5
3.3 Choosing optimal composition scheme based on QoS evaluation
Although there may be several services that have same or similar functions, the QoS attributes of them are different generally. For service composition, this is still true. If there are more than one candidate scheme, how to determine the optimal one is difficult and important. The dynamic service composition method proposed in this work is QoS-oriented, which means that the QoS is considered as an important aspect in choosing the service composition scheme. MADM is widely used in ranking alternatives from limited alternative schemes with respect to multiple criteria. On one hand, if the QoS attributes of the services are taken as alternatives, it could generate the local optimal solution for selecting a single service to composite a larger composed service. On the other hand, if the QoS aggregate values are taken as alternatives, it can rank the integrated schemes in terms of their overall performance and yield the global optimal solution for the composite service. There are four steps as follows:
Step 1: Compute the QoS aggregate values for each scheme, as listed in Table 2.
Table 2 QoS aggregate values for each scheme

For example, in IIS1, the performance relationship between S2 and S3 could be regarded as AND parallel [19]. Therefore, the aggregate values of performance duration, performance cost, reliability, availability and reputation are computed as follows:
![]()
![]()
![]()
![]()
![]()
![]()
The QoS aggregate values for other schemes could be computed similarly.
Step 2: Generally, different QoS criteria use different measurements. For instance, the unit of Qpd uses the unit of money, such as US $, while the unit of Qpc uses the unit of time, such as second. Therefore, it is necessary to normalize the attributes. According to the MADM method, there are two types of indicators in this work: the efficiency indicator which features its value the bigger the better, such as the reliability, the availability and the reputation, whereas the cost-based indicator which features its value the smaller the better, such as the performance duration and the performance cost. The normalized values of efficiency indicators are computed as
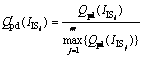 (1)
(1)
 (2)
(2)
The normalized values of cost-based indicators are computed as
 (3)
(3)
 (4)
(4)
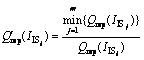 (5)
(5)
in which 1≤i≤m, and m is the number of schemes, i.e. the number of rows. The normalized result of Table 2 is shown in Table 3.
Step 3: Compute the weights of attributes. In typical MADM approaches, weights of attributes reflect the relative importance in decision making process [27]. A method used in this work is based on Shannon’s entropy theory [25-28], which can calculate both the objective weights and the subjective weights.
The Shannon entropy is a measure of uncertainty in information formulated in terms of probability theory. The entropy values ej of attribute j could be calculated as
![]() (6)
(6)
in which k is a constant, and usually let k=1/ln m to ensure 0 ≤ej≤1.
Table 3 Normalized decision matrix N

And the projection value of each criterion is
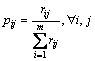 (7)
(7)
Therefore, the degree of divergence dj could be calculated as
dj=1-ej (8)
On one hand, the objective weights, which are computed by solving mathematical models automatically, for each criterion could be computed as
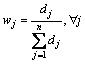 ,
, ![]() ,
, ![]() (9)
(9)
On the other hand, if there is a given subjective weight λj for attribute j, the weight combining with objective and subjective could be computed as
 ,
, ![]() ,
, ![]() (10)
(10)
For instance, if there were no weight information provided by the service requester, the entropy-based objective weights of N could be computed, as listed in Table 4.
Table 4 Entropy-based weights
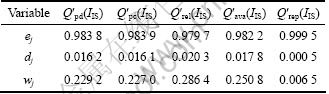
However, if the service requester regards performance duration as the most important factor in service selection, and describes its preference as RA=(0.4, 0.1, 0.1, 0.15, 0.25) in SR, i.e. λ=(0.4, 0.1, 0.1, 0.15, 0.25), then the combining weights of objective and subjective could be calculated based on Eq. (10) as
![]() (0.091 7, 0.022 7, 0.028 6, 0.037 6, 0.001 6, 0.182 3)
(0.091 7, 0.022 7, 0.028 6, 0.037 6, 0.001 6, 0.182 3)
Step 4: Compute the overall evaluate values Sscore of each scheme as
![]() (11)
(11)
where n is the number of attributes, i.e. the number of columns. Sort the schemes according to their Sscore, and the scheme which has the biggest Sscore is optimal.
Use the instance to illustrate again. For the objective weight wj, the Sscore values of each scheme are
![]()
![]()
Because Sscore(IIS5)>Sscore(IIS3)>Sscore(IIS1)>Sscore(IIS5)> Sscore(IIS4)>Sscore(IIS2), IIS5 is the optimal choice for service composition based on the objective weights.
On the other hand, for the given subjective weights λ=(0.4, 0.1, 0.1, 0.15, 0.25), the combining weights ![]() (0.091 7, 0.022 7, 0.028 6, 0.037 6, 0.001 6, 0.182 3) could be used to compute the Sscore of each scheme by
(0.091 7, 0.022 7, 0.028 6, 0.037 6, 0.001 6, 0.182 3) could be used to compute the Sscore of each scheme by
![]() 0.648 3,
0.648 3,
![]() 0.572 4,
0.572 4,
![]() 0.855 2,
0.855 2, ![]() 0.777 1,
0.777 1,
![]() 0.848 7,
0.848 7, ![]() 0.659 8.
0.659 8.
Because ![]() >
>![]() >
>![]() >
> ![]() >
>![]() >
>![]()
![]() is the optimal scheme. It is not same as the result based on the objective weights only.
is the optimal scheme. It is not same as the result based on the objective weights only.
Obviously, the preference of the service request expressed by subjective weights may influence the choice of service composition scheme. It is the reason that the service composition scheme is chosen based on the entropy theory.
4 Experiment and result analysis
The performance of the method was analyzed by some simulation experiments. All experiments were performed on an Intel Core2 Duo 2.33 GHz with 2 GB RAM.
The objective of the first experiment was to observe the impact of the number of output concepts and the scale of mapping relations on processing time. Four different scales of mapping relations, 500, 1 000, 2 000, and 5 000 were used, as shown in Fig. 7. And the numbers of expect output concepts were 3, 5, 10 and 15. Figure 7 shows the average processing time of 50 service requests which all can be satisfied. On one hand, the processing time increases smoothly in different scales of mapping relations with the same number of output concepts. On the other hand, the processing time increases markedly with the increase of output concepts in the same scale of mapping relation set. Therefore, we could conclude that the processing time is mainly affected by the number of output concepts, and our method could alleviate the searching problem which was brought about by the increasing scale of service repository.

Fig. 7 Average processing time of different numbers of output concepts with different scales of MR
In the second experiment, five output concepts were used in a mapping relation set with 1 000 relations in it. The amount of service request was different as 50, 100, 200 and 500, respectively, as shown in Fig. 8, and the service requests included both satisfied and unsatisfied requests with different ratios. The processing time increases smoothly with the increase number of service requests in any ratio. And the more the satisfied service requests are, the longer the processing time is. The reason may be that combining the mapping relation tree and computing QoS evaluation both cost more time. In other words, the preposed method could response quickly for the unsatisfiable requests, which could avoid the waste of time in matchmaking and composition of these requests.
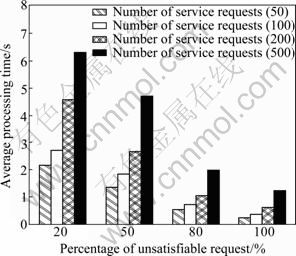
Fig. 8 Average processing time of different unsatisfiable requests in different numbers of service requests
5 Conclusions and future work
1) A QoS-oriented and tree-based approach is proposed. The searching time is reduced by transforming service description to mapping relations which denote the association between input and output concepts. Service composition is completed dynamically by adopting the divide and conquer technique, which builds a mapping relation tree dynamically for each output concept, and combines all mapping relation trees to obtain the integrated resolution without the redundant branch. The optimal integrated scheme of service composition is decided by MADM method, and the preference of service request is considered as subjective weight for each of QoS criteria.
2) The future work will focus on how to increase efficiency of service composition by reusing the mapping relation trees, the more optimal computing method for QoS, service composition with uncertain information, and so on.
References
[1] GEORGAKOPOULOS D, PAPAZOGLOU M P. Service-oriented computing [M]. Massachusetts London: MIT Press, 2009: 1-28.
[2] BERARDI D, CALVANESE D, GIACOMO G D, LENZERINI M, MECELLA M. Automatic service composition based on behavioral descriptions [J]. International Journal of Cooperative Information Systems, 2005, 14(4): 333-376.
[3] RAO Jing-hai, SU Xiao-meng. A survey of automated web service composition methods [C]// Proceedings of the First International Workshop on Semantic Web Services and Web Process Composition. San Diego: Springer-Verlag, 2005, LNCS(3387): 43-54.
[4] YANG Fang-chun, SU Sen, LI Zhen. Hybrid QoS-aware semantic web service composition strategies [J]. Science in China Series F: Information Sciences, 2008, 51(11): 1822-1840.
[5] STEIN S, PAYNE T R, JENNINGS N R. Flexible provisioning of web service workflows [J]. ACM Transactions on Internet Technology, 2009, 9(1): 1-45.
[6] CICIRELLI F, FURFARO A, NIGRO L. A service-based architecture for dynamically reconfigurable workflows [J]. Journal of Systems and Software, 2010, 83(7): 1148-1164.
[7] CHI Y L, LEE H M. A formal modeling platform for composing web services [J]. Expert Systems with Applications, 2008, 34(2): 1500- 1507.
[8] VALERO V, CAMBRONERO M E, D?AZ G, MACI? H. A Petri net approach for the design and analysis of Web Services Choreographies [J]. The Journal of Logic and Algebraic Programming, 2009, 78(5): 359-380.
[9] LUCCHI R, MAZZARA M. A pi-calculus based semantics for WS-BPEL [J]. The Journal of Logic and Algebraic Programming, 2007, 70(1): 96-118.
[10] OZORHAN E K, KUBAN E K, CICEKLI N K. Automated composition of web services with the abductive event calculus [J]. Information Sciences, 2010, 180(19): 3589-3613.
[11] RAO Jing-hai, K?NGAS P, MATSKIN M. Composition of semantic web services using linear logic theorem proving [J]. Information Systems, 2006, 31(4): 340-360.
[12] DING Yong-sheng, SUN Hong-bin, HAO Kuang-rong. A bio-inspired emergent system for intelligent Web service composition and management [J]. Knowledge-Based Systems, 2007, 20(5): 457-465.
[13] WANG Jie-sheng, LI Zhou-jun, LI Meng-jun. Composing semantic web services with description logics [J]. Chinese Journal of Software, 2008, 19(4): 967-980. (in Chinese)
[14] SHIN D H, LEE K H, SUDA T. Automated generation of composite web services based on functional semantics [J]. Web Semantics: Science, Services and Agents on the World Wide Web, 2009, 7(4): 332-343.
[15] LIU Z, RANGANATHAN A, RIABOV A. Modeling web services using semantic graph transformations to aid automatic composition [C]// Proceedings of IEEE International Conference on Web Services. Salt Lake City: IEEE, 2007: 78-85.
[16] HENNIG P, BALKE W T. Highly scalable web service composition using binary tree-based parallelization [C]// Proceedings of IEEE International Conference on Web Services. Miami: IEEE, 2010: 123-130.
[17] LIU Jia-mao, GU Ning, SHI Bai-le. Non-backtrace backward chaining dynamic composition of web services based on mediator [J]. Journal of Computer Research and Development, 2005, 42(7): 1153-1158. (in Chinese)
[18] DENG Shui-guang, WU Jian, LI Ying, WU Zhao-hui. Automatic web service composition based on backward tree [J]. Chinese Journal of Software, 2007, 18(8): 1896-1910. (in Chinese)
[19] KO J M, KIM C O, KWON I H. Quality-of-service oriented web service composition algorithm and planning architecture [J]. The Journal of Systems and Software, 2008, 81(11): 2079-2090.
[20] MABROUK N B, BEAUCHE S, KUZNETSOVA E, GEORGANTAS N, ISSARNY V. QoS-aware service composition in dynamic service oriented environments [C]// Proceedings of 10th International Middleware Conference. Urbana: Springer-Verlag, 2009, LNCS(5896): 123-142.
[21] RESNIK P. Semantic similarity in a taxonomy: An Information- based measure and its application to problems of ambiguity in natural language [J]. Journal of Artificial Intelligence Research, 1999, 11: 95-130.
[22] CORMEN T H, LEISERSON C E, RIVEST R L, STEIN C. Introduction to algorithms (Second Edition) [M]. London: MIT Press, 2001: 27-34.
[23] YAGER R R, XU Ze-shui. The continuous ordered weighted geometric operator and its application to decision making [J]. Fuzzy Sets and Systems, 2006, 157(10): 1393-1402.
[24] XU Ze-shui. On multi-period multi-attribute decision making [J]. Knowledge-Based Systems, 2008, 21(2): 164-171.
[25] XU Jiu-ping, WU Wei. Multiple attribute decision making theory and methods [M]. Beijing: Tsinghua University Press, 2006: 45-47. (in Chinese)
[26] DENG H P, YEH C H, WILLIS R J. Inter-company comparison using modified TOPSIS with objective weights [J]. Computers and Operations Research, 2000, 27(10): 963-973.
[27] WANG T C, LEE H D. Developing a fuzzy TOPSIS approach based on subjective weights and objective weights [J]. Expert Systems with Applications, 2009, 36(5): 8980-8985.
[28] MOHAJERI A, ALIPOUR M. Shannon information entropy of fractional occupation probability as an electron correlation measure in atoms and molecules [J]. Chemical Physics, 2009, 360(1/2/3): 132-136.
(Edited by DENG Lü-xiang)
Foundation item: Project(2007AA01Z126) supported by the National High Technology Research and Development Program of China
Received date: 2011-06-01; Accepted date: 2012-02-22
Corresponding author: ZHANG Ying, PhD Candidate; Tel: +86-13851581621; E-mail: zhywl66@163.com

