Strategies for multi-step-ahead available parking spaces forecasting based on wavelet transform
来源期刊:中南大学学报(英文版)2017年第6期
论文作者:季彦婕 高良鹏 陈晓实 郭卫红
文章页码:1503 - 1512
Key words:available parking spaces; multi-step ahead time series forecasting; wavelet transform; forecasting strategies; recursive multi-input multi-output strategy
Abstract: A new methodology for multi-step-ahead forecasting was proposed herein which combined the wavelet transform (WT), artificial neural network (ANN) and forecasting strategies based on the changing characteristics of available parking spaces (APS). First, several APS time series were decomposed and reconstituted by the wavelet transform. Then, using an artificial neural network, the following five strategies for multi-step-ahead time series forecasting were used to forecast the reconstructed time series: recursive strategy, direct strategy, multi-input multi-output (MIMO) strategy, DIRMO strategy (a combination of the direct and MIMO strategies), and newly proposed recursive multi-input multi-output (RECMO) strategy which is a combination of the recursive and MIMO strategies. Finally, integrating the predicted results with the reconstructed time series produced the final forecasted available parking spaces. Three findings appear to be consistently supported by the experimental results. First, applying the wavelet transform to multi-step ahead available parking spaces forecasting can effectively improve the forecasting accuracy. Second, the forecasting resulted from the DIRMO and RECMO strategies is more accurate than that of the other strategies. Finally, the RECMO strategy requires less model training time than the DIRMO strategy and consumes the least amount of training time among five forecasting strategies.
Cite this article as: JI Yan-jie, GAO Liang-peng, CHEN Xiao-shi, GUO Wei-hong. Strategies for multi-step-ahead available parking spaces forecasting based on wavelet transform [J]. Journal of Central South University, 2017, 24(6): 1503-1512. DOI: 10.1007/s11771-017-3554-1.
J. Cent. South Univ. (2017) 24: 1503-1512
DOI: 10.1007/s11771-017-3554-1
JI Yan-jie(季彦婕)1, GAO Liang-peng(高良鹏)1, CHEN Xiao-shi(陈晓实)2, GUO Wei-hong(郭卫红)3
1. School of Transportation, Southeast University, Nanjing 210096, China;
2. Fujian Communications Planning & Design Institute, Fuzhou 350000, China;
3. Transport Operations Research Group, School of Civil Engineering & Geosciences, Newcastle University, UK
 Central South University Press and Springer-Verlag Berlin Heidelberg 2017
Central South University Press and Springer-Verlag Berlin Heidelberg 2017
Abstract: A new methodology for multi-step-ahead forecasting was proposed herein which combined the wavelet transform (WT), artificial neural network (ANN) and forecasting strategies based on the changing characteristics of available parking spaces (APS). First, several APS time series were decomposed and reconstituted by the wavelet transform. Then, using an artificial neural network, the following five strategies for multi-step-ahead time series forecasting were used to forecast the reconstructed time series: recursive strategy, direct strategy, multi-input multi-output (MIMO) strategy, DIRMO strategy (a combination of the direct and MIMO strategies), and newly proposed recursive multi-input multi-output (RECMO) strategy which is a combination of the recursive and MIMO strategies. Finally, integrating the predicted results with the reconstructed time series produced the final forecasted available parking spaces. Three findings appear to be consistently supported by the experimental results. First, applying the wavelet transform to multi-step ahead available parking spaces forecasting can effectively improve the forecasting accuracy. Second, the forecasting resulted from the DIRMO and RECMO strategies is more accurate than that of the other strategies. Finally, the RECMO strategy requires less model training time than the DIRMO strategy and consumes the least amount of training time among five forecasting strategies.
Key words: available parking spaces; multi-step ahead time series forecasting; wavelet transform; forecasting strategies; recursive multi-input multi-output strategy
1 Introduction
One of the biggest concerns for travelers driving into a busy city center is to know where available parking spaces (APS) are [1]. Accurate forecasting of APS in real time can inform drivers ahead of time where APS can be found. If APS could be predicted far enough in advance, drivers would be able to reserve parking spaces and plan their journeys accordingly. Therefore, the need exists for an available parking spaces forecasting method that can be used for longer periods of time, i.e., a long-term or multi-step prediction, rather than the duration offered by short-term forecasting methods.
Among the limited existing research on long-term forecasting methods, LIU et al [2] developed a weighted one-rank local-region method to predict unoccupied parking spaces for a period of 1 h (in 12 steps) using the recursive strategy. JI et al [3] proposed a multi-step forecasting model that combined a wavelet neural network and the largest Lyapunov exponent method and took into account different characteristics of multi-step ahead APS forecasting in earlier and later stages to improve the accuracy and stability of the forecast. In the domain of multi-step ahead time series forecasting, it has been found that the direct strategy, the multi-input multi- output (MIMO) strategy, and a combination of the direct and MIMO strategies (DIRMO) strategy can also be used for multi-step-ahead forecasting [4-6]. Many studies have compared the different multi-step ahead forecasting strategies in pairs. ZHANG et al [7], SORJAMAA et al [8], and HAMZA et al [9] suggest that the direct strategy is better than the recursive strategy for this use because the direct strategy prevents the error accumulation found in the recursive strategy. Conversely, WEIGEND et al [10] and BIRATTARI et al [11] favor the recursive strategy over the direct strategy, claiming that the direct strategy suffers from intermediate information loss during model building. With respect to the MIMO strategy, KLINE et al [12] and CHENG et al [13] argue that the MIMO strategy provides worse forecasting performance than the recursive and direct strategies. However, because MIMO can preserve the stochastic dependency between predicted values, in the research of BONTEMPI et al [14, 15], the comparison among the MIMO, recursive, and direct strategies favors MIMO. Finally, TAIEB et al [16, 17] suggest that the DIRMO strategy gives better forecasting results than either the direct or the MIMO strategy when the parameter controlling the degree of dependency between forecasts is correctly identified, because it offers a trade-off between the property of preserving the stochastic dependency between forecasted values and the flexibility of the modeling procedure.
In this work, a new strategy for multi-step-ahead forecasting is proposed that preserves the most appealing aspects of the recursive and MIMO strategies. The recursive strategy uses the value just forecasted as one of the input variables for forecasting the next step, which results in increasingly worse forecasting accuracy due to the accumulation of errors with an increasing forecasting horizon. Accordingly, in theory as well as in practice, the forecasting performance of the recursive strategy improves when the iterated values become more accurate, likely to a level of accuracy that is better than the direct strategy [18]. And because the wavelet transform can effectively improve the accuracy of time series forecasting [18], by way of analogy with the DIRMO strategy, the RECMO strategy, which is the combination of the recursive and MIMO strategies, is proposed here. Meanwhile, the accuracy of the outputs of the MIMO strategy, which are iterated values in the RECMO strategy, is improved by applying the wavelet transform.
2 Changing characteristics of APS
Through a macroscopic and microscopic observation of available parking spaces (APS) changing characteristics, analyzing its predictability and randomness, a more reasonable choice of training dataset and forecasting approach can be made.
In this work, we used data collected from the Eldon Multi-Story Car Park in Newcastle upon Tyne, England, during the period of August 12-15, 2014, to understand the changing characteristics of APS. The Eldon Multi- Story Car Park is a parking garage attached to a shopping mall that can accommodate 492 vehicles. The time series analysis was applied using an interval of 5 min, which is a common choice when undertaking a characteristics analysis (see Fig. 1). Through macroscopic observation, it can be seen that changes in the APS happened periodically and that there are very few cars in the parking garage between the hours of 22:00 and 06:00. Consequently, data taken between the hours of 06:00 to 22:00 is sufficient for training the forecasting model.
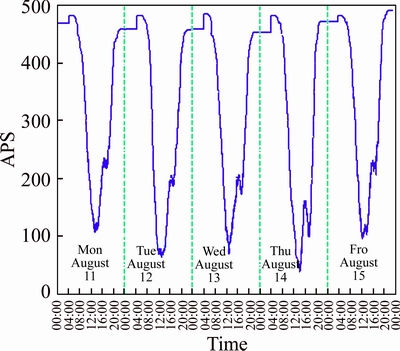
Fig. 1 Curve of a whole day’s available parking space change in Eldon Multi-Story garage (from August 11, 2014 to August 15, 2014)
A fluctuation ratio was used to depict the microscopic changing characteristics of APS in detail [18]. This fluctuation ratio reflects the fluctuation characteristic of adjacent data for the APS directly. The fluctuation ratio at the time point of m is given by
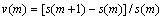 (1)
(1)
where s(m) is the APS data when the time point is m.
The fluctuation ratio of the APS time series is drawn to plot as shown in Fig. 2.
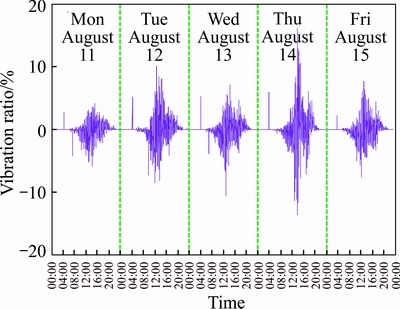
Fig. 2 Fluctuation ratio of available parking spaces
Figure 2 shows that APS data has a strong fluctuation from 12:00 to 16:00 but not at other times, where the fluctuation ratio is relatively low and irregular. However, the wavelet transform is a powerful tool for processing non-stationary numerical signals and has good applicability in non-stationary time series analysis and forecasting. Additionally, it can improve the accuracy of forecasting models through decomposing and reconstructing APS time series with the appropriate wavelet function, separating the low-frequency signal which reflects the essential changing tendency, and the high-frequency signal which reflects the uncertain factors, and then shielding the interference signal in the time series into the high-frequency signal [19, 20].
3 Methodology
The main process for the forecasting method proposed in this work is shown in Fig. 3. Furthermore, the fundamentals of the wavelet transform and the strategies for use in multi-step ahead time series forecasting and forecasting models are introduced in this section.
3.1 Wavelet transform
Realization of the wavelet transform includes two elements: the discrete wavelet transform and the continuous wavelet transform. The APS time series are discrete time series, which means that the orthonormal dyadic wavelet transform is suitable for decomposition and reconstruction of the APS time series. Thus, the Mallat algorithm is chosen for wavelet decomposition and reconstruction.
The Mallat algorithm [21] can be represented as
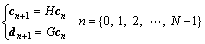 (2)
(2)
where H is the low-pass order filter; G is the high-pass order filter, N is the decomposing scale, and c0 is the original time series. Wavelet decomposition automatically produces pyramidal successive decomposition results. Accordingly, the low-frequency coefficient vector cN and high-frequency coefficient vectors d1, d2, …, dN can be obtained from the Mallet algorithm.
The time series samples will reduce by a half after each decomposition with the Mallat algorithm, and it is not suitable for use in forecasting. However, a time series decomposed by the Mallat algorithm can be reconstructed by the following equation:
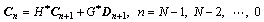 (3)
(3)
where H* and G* represent the dual operators of H and G, respectively. Wavelet reconstruction can increase the samples of the time series. D1, D2, …, DN and CN, whose numbers of samples are the same as those for the original time series, which can be obtained after reconstructing d1, d2, …, dN and cN, respectively, and the reconstructed time series can be represented as C0=CN+D1+D2+…+DN.
3.2 Strategies for multi-step-ahead time series forecasting
One task in multi-step-ahead time series forecasting is to predict the next H values [yN+1, …, yN+H] of a historical time series [y1, …, yN] with N observations, where H>1 is the forecasting horizon. This section will introduce four existing forecasting strategies and one newly proposed strategy, compare the form and required number of forecasting models for each of those forecasting strategies, and analyze their forecasting characteristics.
In order to facilitate the introduction of these strategies, some notations must be defined. Here, f and F denote the functional dependency between past and future observations; r represents the number of past values used to make predictions; and w refers to random errors including disturbances, modeling error and noise.
3.2.1 Recursive strategy
The recursive strategy is the oldest and most intuitive strategy for multi-step-ahead time series forecasting [22, 23], which only trains a single model f to perform a one-step ahead forecast, i.e.,
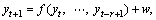
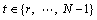 (4)
(4)
When the forecasting horizon is H steps, we begin by applying the model to forecast the first step. Subsequently, the value just forecasted is used as an input variable to forecast the next step with the same one-step ahead model. All forecasts for each step up to the forecasting horizon are obtained in this manner.
If  is the trained one-step ahead model, then the forecasts are given by
is the trained one-step ahead model, then the forecasts are given by

Fig. 3 Main process of forecasting method
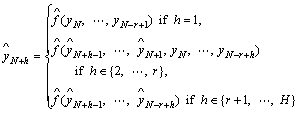 (5)
(5)
The recursive strategy may yield unsatisfactory forecasting results in multi-step ahead forecasting task due to the noise present in the time series and the forecasting horizon. Accumulation of errors with an increasing forecasting horizon is the main reason for the poor accuracy of the recursive strategy. Errors produced in past forecasts will propagate forward as these forecasts are used as input values for making subsequent forecasts.
3.2.2 Direct strategy
The idea of the direct strategy [7, 10, 11] is to forecast each horizon independently from the others. In other words, for H models, fh need to be learned (each horizon needs one model) from the time series [y1, …, yN] where
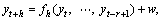
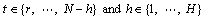 (6)
(6)
The forecasts are obtained by using the H learned models 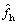 as follows:
as follows:
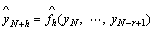 (7)
(7)
Accordingly, no approximated values are used to compute the forecasts Eq. (7) in direct strategy, preventing the direct strategy from suffering from the same accumulation of errors found with the recursive strategy. However, the H forecasts are conditionally independent, as the H models are learned independently. This also has a negative impact on forecasting accuracy, as this strategy does not consider complex dependencies between the variables  In addition, a vast amount of time consumption is demanded for the direct strategy, since a number of models equal to the horizon size need to be learned.
In addition, a vast amount of time consumption is demanded for the direct strategy, since a number of models equal to the horizon size need to be learned.
3.2.3 MIMO strategy
The recursive and direct strategies described previously are single-output strategies [17], which model the data as a single-output function with multiple inputs.
Modeling by single-output mapping neglects the stochastic dependencies between future values, consequently affecting the forecast accuracy [14, 15]. To avoid this limitation, the multi-input multi-output (MIMO) strategy has been proposed.
The MIMO strategy learns one multiple-output model F from the time series [y1, …, yN], where
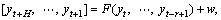
 (8)
(8)
F: RR→RH is a vector-valued function; and is a noise vector with a covariance that is not necessarily diagonal.
The forecasts are returned in one step by a multiple- output model 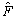 , where
, where
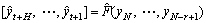 (9)
(9)
The MIMO strategy preserves the stochastic dependency between predicted values, thus avoiding the conditional independence of the direct strategy as well as the accumulation of errors of the recursive strategy. Due to these advantages, the MIMO strategy has been successfully applied to several real-world multi-step ahead time series forecasting tasks [14, 15].
However, the MIMO strategy forecast all horizons with the same model structure, thereby reducing the flexibility of the forecasting approach [16]. To overcome this shortcoming, a new multiple-output strategy, DIRMO, has been put forward, and this strategy is presented next.
3.2.4 DIRMO strategy
Aiming to preserve the advantages of both the direct and the MIMO strategies, the DIRMO strategy [16] takes a middle approach. This strategy divides the horizon H into several blocks, and then it forecasts each block in a MIMO fashion. Therefore, an H-step-ahead forecasting task consists of n multiple-output forecasting tasks (n=H/s), each with an output of size s. 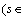 {1, …, H}).
{1, …, H}).
The DIRMO strategy is an intermediate configuration between the direct and MIMO strategies, which depends on the value of the parameter s. When the value of the parameter s is 1, the DIRMO strategy corresponds to the direct strategy, whose number of forecasting tasks n is equal to H. When the value of the parameter s is H, the DIRMO strategy corresponds to the MIMO strategy, whose number of forecasting tasks equals 1.
Tuning of the parameter s allows us to improve the flexibility of the MIMO strategy by calibrating the dimensionality of the outputs (no dependency in the case of s=1 and maximal dependency for s=H). This provides a beneficial trade-off between preserving a larger degree of the stochastic dependency between future values and having greater flexibility with the predictor.
The DIRMO strategy learns n models Fp from the time series [y1, …, yN], where

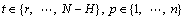 (10)
(10)
And F: RR→Rs is a vector-valued function if s>1.
The H forecasts are returned by the n learned models as follows:
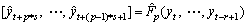 (11)
(11)
3.2.5 RECMO strategy
The recursive strategy and the direct strategy have been engaged in a close race in past research [7-11], and the DIRMO strategy has good applicability in the multi-step ahead time series forecasting domain [16, 17]. Accordingly, by analogy with the development of the DIRMO strategy, aiming to preserve the most appealing aspects of both the recursive and the MIMO strategies, while improving the flexibility of the MIMO strategy through calibrating the dimensionality of the outputs, this work proposes a new forecasting strategy that combines the recursive strategy and the MIMO strategy, called RECMO.
The procedure for the RECMO strategy is as follows: first, we determine the integer parameter s, which calibrates the dimensionality of the output. For a given s, the training set of the RECMO strategy is composed of n=H/s portions. After training a forecasting model F whose size of output is s, according to the principle of the recursive strategy, we first forecast the first s steps by applying the multi-output model F. Subsequently, the values just forecasted are included among the input variables used to forecast the next s steps with the same model. We continue in this manner until the entire horizon has been forecasted.
In this strategy, a single model F is trained to perform an s-step ahead forecast, i.e.
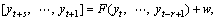
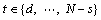 (12)
(12)
where: RR→Rs is a vector-valued function if s>1.
Let the trained s-step ahead model be . Then the forecasts are given by
 (13)
(13)
where  and ceil(X) rounds the value x to the nearest integer towards infinity. In the next section, the RECMO strategy will be applied to a multi-step ahead available parking spaces forecasting problem to verify its effectiveness.
and ceil(X) rounds the value x to the nearest integer towards infinity. In the next section, the RECMO strategy will be applied to a multi-step ahead available parking spaces forecasting problem to verify its effectiveness.
In conclusion, five possible forecasting strategies have been introduced for use in multi-step ahead forecasting tasks: the recursive, direct, MIMO, DIRMO and RECMO strategies. The relationship among these strategies is shown in Fig. 4.
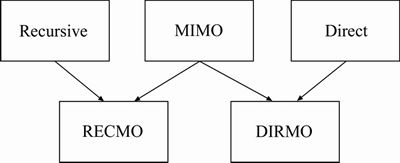
Fig. 4 Relationship among different forecasting strategies
3.3 Forecasting model
Each of the forecasting strategies demands the definition of a specific forecasting model or learning algorithm, in order to estimate either the scalar-valued function f or the vector-valued function F, which represent the temporal stochastic dependencies. As the goal of this work is not to compare forecasting models, but rather multi-step ahead forecasting strategies, the choice of an underlying forecasting model is required in order to set up the experiments. In this work, the artificial neural network model is adopted, as it is a popular type of global learning model that has been shown to be particularly effective in time series forecasting tasks [24].
The back-propagation neural network (BPNN) is one of the most common artificial neural networks, which belongs to the category of multilayer feedforward neural networks and trains neural networks with an error back-propagation algorithm. This work establishes a three-layer BPNN model as its forecasting model, whose topological structure is shown in Fig. 5. In this structure, the number of input nodes is r, the number of hidden nodes is l, and the number of output nodes is m. BPNN is a scalar-valued function when m equals 1 but is a vector-valued function when m>1. To implement BPNN,the MATLAB function (feed forward net) is used in this work.
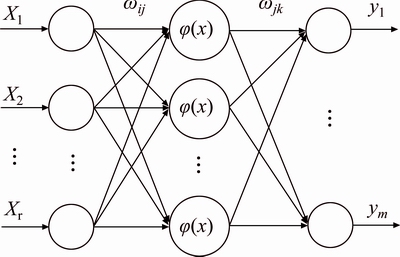
Fig. 5 Topological structure of back-propagation neural network
4 Case study
4.1 Data description
Data collected in the Eldon Multi-Story Car Park from August 12, 2014 to August 15, 2014, and from September 9, 2014 to September 12, 2014, and data collected from the John Dobson Car Park from September 9, 2014 to September 12, 2014 are selected for use as a case study. The data is first processed into time series using 5 min as the interval. Thereafter, data from August 12, 2014 to August 15, 2014 from the Eldon parking garage is used for pre-testing, for the purpose of mining optimal parameters. Next, using the data collected from September 9, 2014 to September 12, 2014 from both the Eldon and John Dobson parking garages, we conduct a forecasting experiment with the optimal parameters, thus verifying the effectiveness and universality of the forecasting method. As few vehicles were parked in these garages during the late night hours, we select the hours from 6:00 to 22:00 on three consecutive days, for 579 time points, as the training set. Then, using the subsequent fourth day from 6:00 to 22:00, consisting of 193 time points, as the testing set, we conduct a multi-step ahead APS forecasting with 1 h (12 steps) as the forecasting horizon.
4.2 Assessment criteria
The mean absolute percentage error (MAPE, Emap) of the testing set is used as the assessment criterion, and it can be calculated as follows:
 (14)
(14)
where N is the length of the testing set; yn(k) is the expected output of the kth time point; and y(k) is the actual output of the kth time point.
Due to the randomness of the forecasting results obtained from the BPNN model, we do every forecasting test 10 times and then take an average to eliminate this contingency.
4.3 Determination of structure of BPNN
According to the topological structure of the BPNN, r nodes of the input layer denote that the inputs of the BPNN are APS data from r time points that are known or have been forecasted, while m nodes of the output layer denote that the outputs of the BPNN are APS data of m time points that are unknown.
As the optimal number of the hidden-layer nodes l is related to the number of input-layer nodes r and the number of output-layer nodes m [25], r and l should both change when s, which is the parameter calibrating the dimensionality of the output in the DIRMO and RECMO strategies, changes in the process of tuning the parameters. Accordingly, a search for the optimal topological structure of the BPNN is necessary along with the change in the number of output-layer nodes m. In this work, we first determine the range of r and l, and then, for some value of parameter m, conduct forecasting tests with all combinations of r and l. Finally, we choose one combination that offers the minimum number of forecasting errors as the optimal combination of r and l.
Choosing the range of r from 3 to 10, where the range of m is known from 1 to 12, the range of l can be calculated according to empirical formula [25], from 3 to 15. As taking into consideration the optimal topological structure of the BPNN, the forecasting errors index we choose is the mean square error (MSE, Ems), which is irrelevant to the APS time series themselves, rather than the MAPE. The MSE can be calculated as follows:
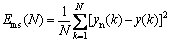 (15)
(15)
where N is the length of the testing set; yn(k) is the expected output of the kth time point; and y(k) is the actual output of the kth time point.
In the following, data from August 12, 2014 to August 15, 2014 from the Eldon Multi-Story Car Park was used for pretesting, mining the crucial parameters in the BPNN and the forecasting strategies.
Figure 6 shows the MSE corresponding to all combinations of r and l for m=6, and when the MSE approached it minimum, the corresponding r and l are found to be 7 and 5. For the purpose of analogy, other optimal combinations of r and l for other values of parameter m can also be obtained.

Fig. 6 MSE for different combinations of r and l when m equals 6
4.4 Adopting WT to three single forecasting strategies
Having obtained the optimal structure of BPNN, we next seek to observe the optimization effect found after adopting the wavelet transform on the forecasting performance for each single forecasting strategy in each forecasting horizon. Consequently, we used BPNN combined with the recursive, direct, and MIMO strategies to conduct forecasting experiments with forecasting horizons from 1 to 12, under two situations, namely with or without adopting the wavelet transform.
The Daubechies function (“db2”) was used as the wavelet function in this work, and three-layer decomposition was adopted for the APS time series collected from August 12, 2014 to August 15, 2014 at the Eldon Multi-Story Car Park. This resulted in four APS time series, the high-frequency time series D1-D3, which reflects the uncertain factors, and the low-frequency time series C3, which reflects the essential changing tendency, as shown in Fig. 7.
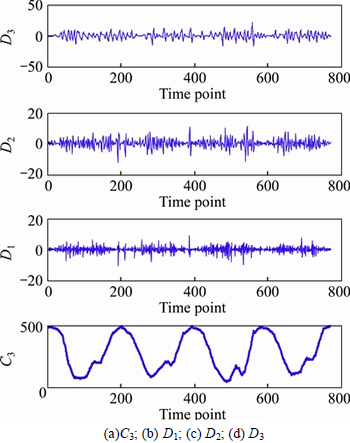
Fig. 7 Multi-resolution analysis of wavelet transform:
Recognizing that drivers are most concerned about the dynamic and changing process of APS in a parking lot, we assessed the total error for each forecasting horizon by taking the average of each step’s forecasting error (MAPE). This approach signifies the understanding that each step’s forecasting result has the same importance to drivers.
The forecasting results before and after the adoption of WT are shown in Fig. 8, while Fig. 9 compares the forecasting accuracy for each of the three single strategies after adopting WT with different forecasting horizons.
From the results above, it can be seen that the forecasting accuracy of the recursive, direct, and MIMO strategies all improve after the adoption of the wavelet transform, thus verifying the effectiveness of the wavelet transform. Also, it is noteworthy that the MIMO strategy shows superior forecasting performance, especially when the forecasting horizon is from 1 to 4 (as shown in Fig. 9), providing theoretical support for the use of the RECMO strategy, which relies on the MIMO strategy’s high accuracy for several steps forward. Next, 12-step ahead APS forecasting will be conducted with the DIRMO and RECMO strategies after adopting the wavelet transform.
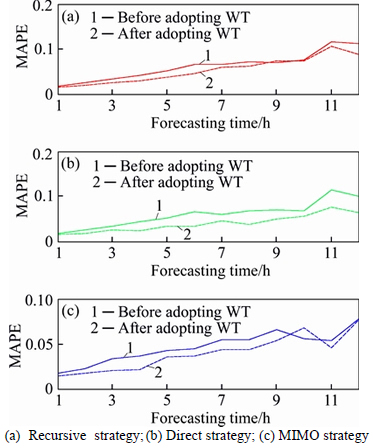
Fig. 8 Forecasting results before and after adoption of wavelet transform in three single strategies:
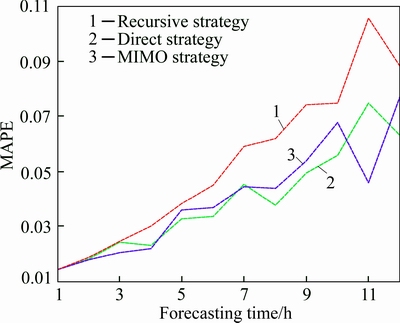
Fig. 9 Comparison of forecasting accuracy for three single strategies after adopting WT
4.5 Mining of parameter s in two combined forecasting strategies
Before applying the DIRMO and RECMO strategies, we should mine the optimal parameter s for calibrating the dimensionality of the output, by first choosing s to be the divisors of 12, namely, 1, 2, 3, 4, 6 and 12, and then conducting the multi-step ahead forecasting experiment by applying the DIRMO and RECMO strategies with each of the six values of s. Through this process, it can be found that the DIRMO and RECMO strategies both achieve the best outcome when the parameter s is 3, as shown in Table 1.
Table 1 MAPE of two combined strategies with different values of parameters
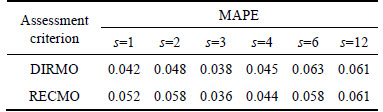
This result is consistent with the relatively high accuracy found with the MIMO strategy when the forecasting horizon is from 1 to 4, as presented in the last subsection.
4.6 Results from five forecasting strategies
After obtaining the optimal dimensionality- calibrating parameter s above, five forecasting strategies combining BPNN and WT were applied to multi-step ahead APS forecasting with data obtained from the Eldon Multi-Story Car Park during the period from September 9, 2014 to September 12, 2014 and from the John Dobson Car Park from the period of September 9, 2014 to September 12, 2014. The forecasting results from the two parking garages are shown in Table 2, and more detailed information is shown in Fig. 10.
Table 2 Average MAPE and time consumption of five forecasting strategies with data from two parking garages
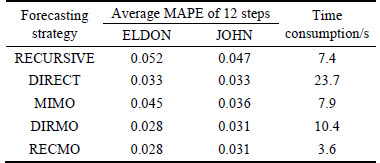
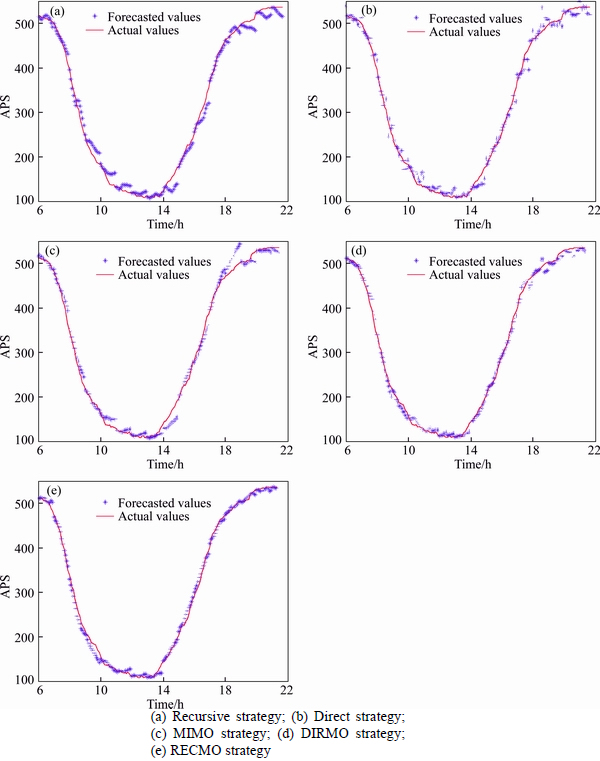
Fig. 10 Fitting curve of five forecasting strategies (John Dobson parking garage):
As seen from the table and figures above, the DIRMO and RECMO strategies offer better forecasting accuracy compared with the three single strategies, and the RECMO strategy consumes the least amount of training time among the five forecasting strategies. The reason for this phenomenon can be explained as follows. Although the recursive strategy suffers from lower forecasting accuracy as compared with the direct strategy along with its increase in forecasting horizon, combining this strategy with the MIMO strategy improves the recursive strategy’s flexibility by calibrating the dimensionality of the output. Further, this combination reduces the accumulation of errors to some extent by using the accurate outputs of the MIMO strategy as iterated values when adopting the wavelet transform, and consequently improving its forecasting accuracy. Meanwhile, the RECMO strategy preserves the recursive strategy’s advantage in terms of consuming little training time, as it only demands one model for training, and it reduces the iterations because more outputs are provided at one time.
As seen from the table and figures above, the DIRMO and RECMO strategies offer better forecasting accuracy compared with the three single strategies, and the RECMO strategy consumes the least amount of training time among the five forecasting strategies. The reason for this phenomenon can be explained as follows. Although the recursive strategy suffers from lower forecasting accuracy as compared with the direct strategy along with its increase in forecasting horizon, combining this strategy with the MIMO strategy improves the recursive strategy’s flexibility by calibrating the dimensionality of the output. Further, this combination reduces the accumulation of errors to some extent by using the accurate outputs of the MIMO strategy as iterated values when adopting the wavelet transform, consequently improving its forecasting accuracy. Meanwhile, the RECMO strategy preserves the recursive strategy’s advantage in terms of consuming little training time, as it only demands one model for training, and it reduces the iterations because more outputs are provided at one time.
5 Conclusions
1) After applying the wavelet transform, multi-step ahead APS forecasting with the three individual strategies (recursive, direct and MIMO) all shows improvements in accuracy.
2) With respect to the combined forecasting strategies, the DIRMO and RECMO strategies offer similar results in terms of forecasting accuracy (the average MAPE results of 12-step ahead forecasting for the two methods are 0.028 and 0.031, respectively, in experiments using the parking data from the two parking garages), and show higher accuracy than the three single strategies.
3) The RECMO strategy not only has great forecasting accuracy but also consumes the least amount of training time among the five forecasting strategies. In fact, its training time requirements are nearly one-third of the time consumed by the DIRMO strategy, thus satisfying the real-time requirement for APS forecasting.
4) In further work, it would be interesting to seek other more effective forecasting models that forecasting strategies may rely on multi-step-ahead APS forecasting, and to apply the RECMO strategy to data sets from other parking garages whose surrounding land use is different, thus examining the strategy’s effectiveness and universality.
References
[1] YANG Zhao-sheng, LIU Hong-hong, WANG Xin-yue. The research on the key technologies for improving efficiency of parking guidance system [J]. Intelligent Transportation Systems, 2003, 2(2): 1177-1182.
[2] LIU Shi-xu, GUAN Hong-zhi, YAN Hai, YIN Huan-huan. Unoccupied parking space prediction of chaotic time series [C]// Tenth International Conference of Chinese Transportation Professionals. New York: ASCE, 2010: 2122-2131.
[3] JI Yan-jie, TANG Dou-nan, GUO Wei-hong, BLYTHE P T, WANG Wei. Forecasting available parking space with largest Lyapunov exponents method [J]. Journal of Central South University, 2014, 21(4): 1624-1632.
[4] TAIEB S B, BONTEMPI G, ATIYA A F, SORJAMAA A. A review and comparison of strategies for multi-step ahead time series forecasting based on the NN5 forecasting competition [J]. Expert Systems with Applications, 2012, 39(8): 7067-7083.
[5] GUO Zheng-hai, ZHAO Wei-gang, LU Hai-yan, WANG Jian-zhou. Multi-step forecasting for wind speed using a modified EMD-based artificial neural network model [J]. Renewable Energy, 2012, 37(1): 241-249.
[6] AMENDOLA A, NIGLIO M, VITALE C. Multi-step SETARMA predictors in the analysis of hydrological time series [J]. Physics and Chemistry of the Earth, Parts A/B/C, 2006, 31(18): 1118-1126.
[7] ZHANG Xi-ru, HUTCHINSON J. Simple architectures on fast machines: practical issues in nonlinear time series prediction [C]// Time Series Prediction: Forecasting the Future and Understanding the Past. New Mexico: Santa Fe Institute, 1993: 22-31.
[8] SORJAMAA A, HAO J, REYHANI N, JI Yong-nan, LENDASSE A. Methodology for long- term prediction of time series [J]. Neurocomputing, 2007, 70(16): 2861-9.
[9] HAMZA EBI C, AKAY D, KUTAY F. Comparison of direct and iterative artificial neural network forecast approaches in multi- periodic time series forecasting [J]. Expert Systems with Applications, 2009, 36(2): 3839-3844.
[10] WEIGEND A S, HUBERMAN B A, RUMELHART D E. Predicting sunspots and exchange rates with connectionist networks [C]// Nonlinear Modeling & Forecasting. New Mexico: Santa Fe Institute, 1991: 201-237.
[11] BIRATTARI M, BONTEMPI G, BERSINI H. Lazy learning meets the recursive least squares algorithm [J]. Advances in neural Information Processing Systems, 1999: 375-381.
[12] KLINE D M, ZHANG G. Methods for multi-step time series forecasting with neural networks [J]. Neural Networks in Business Forecasting, 2004: 226-250.
[13] CHENG Hai-bin, TAN Pang-ning, GAO Jing, SCRIPPS J. Multistep-ahead time series prediction [C]// Advances in Knowledge Discovery and Data Mining. Singapore: DBLP, 2006: 765-774.
[14] BONTEMPI G. Long term time series prediction with multi-input multi-output local learning [C]// Proc 2nd ESTSP, 2008: 145-154.
[15] BONTEMPI G, TAIEB S B. Conditionally dependent strategies for multiple-step-ahead prediction in local learning [J]. International journal of forecasting, 2011, 27(3): 689-699.
[16] TAIEB S B, BONTEMPI G, SORJAMAA A, LENDASSE A. Long-term prediction of time series by combining direct and mimo strategies [C]// International Joint Conference on Neural Networks. America: IJCNN, 2009: 3054-3061.
[17] TAIEB S B, SORJAMAA A, BONTEMPI G. Multiple-output modeling for multi-step-ahead time series forecasting [J]. Neurocomputing, 2010, 73(10): 1950-1957.
[18] YANG Fei. Traffic flow predition model based on echo state networks and related research [D]. Beijing University of Posts and Telecommunivations, 2012. (in Chinese)
[19] ICHIR M M, MOHAMMAD-DJAFARI A. Hidden Markov models for wavelet-based blind source separation [J]. Image Processing, IEEE Transactions on, 2006, 15(7): 1887-1899.
[20] PAIVA H M, GALV O R K H. Optimized orthonormal wavelet filters with improved frequency separation [J]. Digital Signal Processing, 2012, 22(4): 622-627.
[21] MALLAT S G. A theory for multiresolution signal decomposition: the wavelet representation [J]. Pattern Analysis and Machine Intelligence, 1989, 11(7): 674-693.
[22] TIAO G C, TSAY R S. Some advances in non-linear and adaptive modelling in time-series [J]. Journal of Forecasting, 1994, 13(2): 109-131.
[23] WEIGEND A S, GERSHENFELD N A. Time series prediction: Forecasting the future and understanding the past [M]. New Jersey: Addison Wesley, 1994.
[24] KARUNASINGHE D S, LIONG S Y. Chaotic time series prediction with a global model: Artificial neural network [J]. Journal of Hydrology, 2006, 323(1): 92-105.
[25] WU Chang-you. The research and application on neural network [D]. Northeast Agricultural University, 2007. (in Chinese)
(Edited by FANG Jing-hua)
Cite this article as: JI Yan-jie, GAO Liang-peng, CHEN Xiao-shi, GUO Wei-hong. Strategies for multi-step-ahead available parking spaces forecasting based on wavelet transform [J]. Journal of Central South University, 2017, 24(6): 1503-1512. DOI: 10.1007/s11771-017-3554-1.
Foundation item: Project(51561135003) supported by the International Cooperation and Exchange of the National Natural Science Foundation of China; Project (51338003) supported by the Key Project of National Natural Science Foundation of China
Received date: 2015-11-04; Accepted date: 2016-12-01
Corresponding author: JI Yan-jie, Associate Professor, PhD; Tel: +86-13813996939; E-mail: jiyanjie@seu.edu.cn

