A novel approach for speaker diarization system using TMFCC parameterization and Lion optimization
��Դ�ڿ������ϴ�ѧѧ��(Ӣ�İ�)2017���11��
�������ߣ�V. Subba Ramaiah R. Rajeswara Rao
����ҳ�룺2649 - 2663
Key words��speaker diarization; Mel frequency cepstral coefficient; i-vector extraction; Lion algorithm
Abstract: In audio stream containing multiple speakers, speaker diarization aids in ascertaining ��who speak when��. This is an unsupervised task as there is no prior information about the speakers. It labels the speech signal conforming to the identity of the speaker, namely, input audio stream is partitioned into homogeneous segments. In this work, we present a novel speaker diarization system using the Tangent weighted Mel frequency cepstral coefficient (TMFCC) as the feature parameter and Lion algorithm for the clustering of the voice activity detected audio streams into particular speaker groups. Thus the two main tasks of the speaker indexing, i.e., speaker segmentation and speaker clustering, are improved. The TMFCC makes use of the low energy frame as well as the high energy frame with more effect, improving the performance of the proposed system. The experiments using the audio signal from the ELSDSR corpus datasets having three speakers, four speakers and five speakers are analyzed for the proposed system. The evaluation of the proposed speaker diarization system based on the tracking distance, tracking time as the evaluation metrics is done and the experimental results show that the speaker diarization system with the TMFCC parameterization and Lion based clustering is found to be superior over existing diarization systems with 95% tracking accuracy.
Cite this article as: V. Subba Ramaiah, R. Rajeswara Rao. A novel approach for speaker diarization system using TMFCC parameterization and lion optimization [J]. Journal of Central South University, 2017, 24(11): 2649�C2663. DOI:https://doi.org/10.1007/s11771-017-3678-3.
J. Cent. South Univ. (2017) 24: 2649-2663
DOI: https://doi.org/10.1007/s11771-017-3678-3
V. Subba Ramaiah1, R. Rajeswara Rao2
1. Mahatma Gandhi Institute of Technology, Kokapet, Hyderabad, Telangana 500075, India;
2. Jawaharlal Nehru Technological University Kakinada, Kakinada, Andhra Pradesh 535002, India
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2017
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2017
Abstract: In audio stream containing multiple speakers, speaker diarization aids in ascertaining ��who speak when��. This is an unsupervised task as there is no prior information about the speakers. It labels the speech signal conforming to the identity of the speaker, namely, input audio stream is partitioned into homogeneous segments. In this work, we present a novel speaker diarization system using the Tangent weighted Mel frequency cepstral coefficient (TMFCC) as the feature parameter and Lion algorithm for the clustering of the voice activity detected audio streams into particular speaker groups. Thus the two main tasks of the speaker indexing, i.e., speaker segmentation and speaker clustering, are improved. The TMFCC makes use of the low energy frame as well as the high energy frame with more effect, improving the performance of the proposed system. The experiments using the audio signal from the ELSDSR corpus datasets having three speakers, four speakers and five speakers are analyzed for the proposed system. The evaluation of the proposed speaker diarization system based on the tracking distance, tracking time as the evaluation metrics is done and the experimental results show that the speaker diarization system with the TMFCC parameterization and Lion based clustering is found to be superior over existing diarization systems with 95% tracking accuracy.
Key words: speaker diarization; Mel frequency cepstral coefficient; i-vector extraction; Lion algorithm
1 Introduction
Due to the decreasing cost of the processing and increase in access to the power, storage capacity and network bandwidth are facilitating the amassing of large volume of audios inclosing broadcast voice mails, meetings and other spoken documents. The large volumes of audios are difficult to retrieve. There is growing interest toward the speech recognition technologies in automatic searching indexing and retrieval of audio information. It is possible via extraction of the meta-data from the contents [1, 2]. Speaker recognition is a technique to recognize the identity of the speaker from a speech utterance. The speaker recognition is based on the speaker identification or the speaker verification, text dependent or text independent, closed set or open set. The speaker diarization is the open set, text independent speaker verification process which helps in the context analysis without any prior knowledge about the speaker [3].
In the context of automatic analysis of meetings, robust localization and tracking of active speakers are of fundamental importance [4]. Accordingly, speaker diarization techniques are in high demand in our presently information-rich society, with a diversity of useful applications such as audio-conferencing, smart video monitor system [5], robot, human machine interface, far distance speech capture and recognition [6].Speaker diarization was first introduced as the factor analysis with an online stream method. In a multi-speaker scenario, such as a meeting, knowing when the identity of the active speaker changes is a valuable piece of information for assistive listening devices as it can be used to re-steer [7], audio diarization is defined as the task of marking and categorising the audio sources within a spoken document. The types and details of the audio sources are application specific. At the simplest, diarization is speech versus non-speech, where non-speech is a general class consisting of music, silence, noise, etc., that need not to be broken out by type.
Speaker diarization is a process of finding a conversation of a target speaker from the mixed signals of several persons. In a first step, speech is segmented into homogeneous segments containing only one speaker, without any use of a priori knowledge about speakers. Then, the resulting segments are checked to belong to one of the target speakers. Technically, speaker diarization is a process of online and real-time labelling of the segments of a given speech steam with the labels defining the identity of the speakers [8]. The general speaker diarization system is shown in Fig. 1. The major steps resulting in the speaker diarization are feature extraction, voice activity detection and labeling. The output is the labeled signal output corresponding to the identity of the speaker defined by the voice activity detection. But the important constraint considering the diarization is that there is no primary model for speakers and the system should be operating in an open-set manner. This means that the system should first determine if there exists a trained model of the current speaker in the model set or the utterance corresponds to a new speaker.
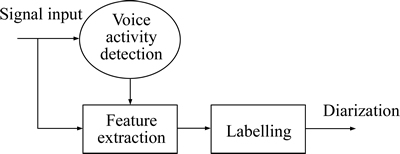
Fig. 1 Speaker diarization system
Speaker diarization process can be ensured by several ways. The most common technique consists of moving a mobile camera towards the target. Another possible technique uses fixed special cameras that possess large visibility coverage: ��panoramic cameras�� [9], and proceed to a selection of the wanted region of interest. There are four general classes of tracking technologies: sensor-based [10], motion-based, microphone-array-based and speaker recognition-based. While all the four methods can be used for a single speaker, only the third and the last ones are normally used for multi-speaker audience. In the case of multi- speaker data [11], the problem is to determine the number of speakers, and then localize and track the speakers from the signals collected using a number of spatially distributed microphones. It is also necessary to separate speech of the individual speakers from the multi-speaker signals. Then, the speaker diarization system can use different techniques to track a moving speaker with more accurately.
However, simultaneous diarization of multiple persons in real-world environments is an active research field and several approaches have been proposed, based on a variety of features and algorithms. One of the common algorithms to diarize the speaker��s signal is particle filters [12] which introduce a problem called loss of diversity among the particles. When there are more than two speakers speaking simultaneously, zero frequency filtering [13] is used to increase the diarizing performance. Difficulty may arise in deriving the Hilbert Envelope signal that contains peaks specific to a single speaker. Another one important technique used for speaker diarization system using distributed Kalman filter [14] is a linear quadratic estimation algorithm that performs the series of measurements observed over time and it can be used only for linear state transitions. The main drawback behind this Kalman filter is that it can be used only for linear state transitions.
The main contribution of the work is to propose a novel speaker diarization system by improving the speaker segmentation as well as the speaker clustering. The two main contributions of the proposed system are as follows:
1) TMFCC feature parameterization. Tangent weighted Mel frequency cepstral coefficient (TMFCC) is taken to represent the audio signal instead of the Mel frequency cepstral coefficient (MFCC) in the proposed system. This improves the performance of the system by covering the low energy frame as well as the high energy frame separately. The recognition accuracy of the speech activity detection is improved by the new feature since the delay between the users signals is identified as well as the coefficient is more robust compared to the other coefficients taken for the diarization.
2) Lion algorithm. The segmented speech out of the speech activity detection is clustered into group of identical speaker based on the Lion optimization algorithm. The Lion optimization provides better clustering accuracy over the agglomerative clustering or Integer linear program (ILP) clustering [15].
The organization of the paper is as follows. The next section provides the literature works based on the speaker diarization system with different source features and clustering algorithms. The motivation for the proposal of the paper is described in section 3. Section 4 presents the detailed discussion about the proposed novel speaker diarization system. The results for the proposed speaker diarization using different audio signals are deliberated in section 5. The conclusion of the paper is provided in section 6.
2 Literature review
Some of the literature works based on the speaker diarization system is presented in this section. Accordingly, nine papers with the diarization perspective are reviewed here. Based on the review, most of the research papers differ from one another certainly based on the type of the modelling used, filtering used for the change detection and algorithm used for the clustering. Table 1 lists the literature review of the speaker diarization system.
In Ref. [12], the speaker diarization was done using the Bayesian filtering for the change in the speaker activity detection. Even though, the filtering provides separation of the signal with better signal interference ratio, the computational complexity because of the Bayesian filtering was more. Beam former methods were used in Ref. [6] in which the directionality of the speech signal was identified with the negative SNR. Beam forming was one of the spatial filtering techniques. They have used the room impulse response (RIR) for the feature extraction. The Kalman filtering based diarization was introduced in Ref. [14], but it is restricted to the linear state transitions. The Kalman filtering was used to label the extracted features. Particle and zero filtering techniques were used for the speech separation in Refs. [18, 19], respectively. They provided accurate recognition of the signal even with more speakers. But the exertion arises in the resampling and the representation of the enveloped signal. The methods used in Refs. [4, 11] were more simple considering other diarization techniques taken for the literature works. They lean towards the separation of the signal even in the noisy environment. The grim arises due to the increased frequency signal etc.
Table 1 Literature review
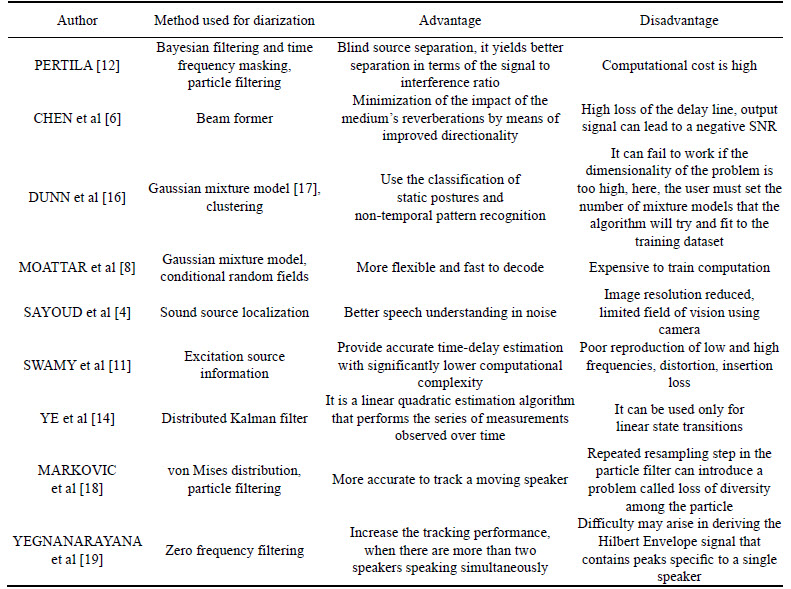
The model based diarization took over its part instead the direction oriented filtering techniques. In Res. [8, 16], the Gaussian mixture model (GMM) was used. The effect of the GMM model was on the computational side. The computations to train the GMM model were more difficult. But the flexibility and the speech recognition of the GMM model based speaker recognition are improved.
3 Motivation
The motivation for the proposal of the paper concerning the speaker diarization is discussed in this section. The problem statement and the challenges of the existing speaker diarization system are provided in this section.
1) Problem statement
Let us assume that the audio signal made available for the speaker diarization system be X. The audio signal is with the multiple speakers. For example, it is given by X={x1, x2, x3, ��, xm} where m is the number of the speakers. The spectral feature extracted is TMFCC, i.e. Cs={Cs(1), Cs(2), ��, Cs(cn)} where n=1, ��, N. The ultimate challenge is to identify the voice activity detection (VAD) which can be signified as VAD={Di, Di} where 1��i��n. Here, i-vector features extracted from the VAD are represented as W={w1, w2, ��, wm}. The vector elements are grouped using the Lion algorithm into the k clusters based on the identity of the speakers. It can be represented as K={K1, K2, ��, Kk} where 1��k��n.
2) Challenges
Speaker segmentation based on the change of the activity detection and the clustering algorithm for the grouping of the speech signals based on the identity is the important task to consider. The recognition accuracy of the system is mainly concerned with the activity detection. Normal, MFCC based detection is affected by the limitations because of the energy band values taken into for the processing. The coefficients are generated by considering the filter bank as a whole which minimizes the energy value and decreases the performance of the system. The clustering algorithm used along the speaker segments must be optimized in a way to improve the overall performance of the system. The selection of the source feature and the clustering algorithm is the task to be considered for the efficient speaker diarization system. When analysing the existing diarization system, these are challenges identified to further extend the work.
In speech diarization, the speech stream is gradually fed to the system and hence, there is not much information about the future data [8]. Therefore, we are limited to make decision using only current and previous seen speech data.
In speaker diarization, the mobile camera has several problems due to the noise produced by the driving motors, the mechanic oscillations [4] and an important delay due to the mechanic response time of these ones.
Furthermore, localization and tracking of active speakers from multiple far-field microphones are challenging tasks in smart room scenarios, where the speech signal is corrupted with noise from presentation devices and room reverberations [4].
However, in general the cross-correlation function of the multi-speaker signals does not show unambiguous prominent peaks at the time delays. This is mainly because of the damped sinusoidal components in the speech signal due to resonances of the vocal tract, and also because of the effects of reverberation and noise [11]. These effects can be reduced by exploiting the characteristics of the excitation source of speech.
In Ref. [11], speaker diarization is performed using linear prediction (LP) residual which is not considered the time delay between the user��s signals. This time delay will heavily affect the tracking performance because it assumes the time delay as constant. On the other hand, in conference or meeting, the speaker will not be in a same position. They may move in different directions and positions. So, the handling of movement to recognize and determine the speakers should be considered in the future works.
4 Proposed algorithm: Speaker diarization with TMFCC spectral feature and Lion algorithm for clustering
The proposed speaker diarization with TMFCC spectral feature and Lion algorithm is discussed in detail in this section. The overall block diagram of the proposed algorithm is shown in Fig. 2. Majorly, the basic steps involved in the speaker diarization are feature extraction, change of activity detection and clustering.
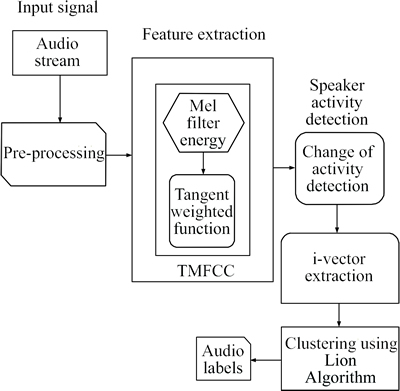
Fig. 2 Overall block diagram of proposed TMFCC and Lion algorithm based speaker diarization
Initially, the audio signal which is to be segmented based on the identity of the speaker is given as the input to the speaker diarization system. The first block shown in Fig. 2 is the audio stream which is the accepted input signal. Followed by the acceptance, pre-processing of the audio signal is done. In the pre-processing section, the acoustic beam forming is completed. The spatial filtering process is to make the audio signal stabilized for the upcoming diarization procedure helping in speech detection. The acoustic beam forming aids in helping the audio signal from the multiple channel suitable for the diarization. Fixed and adaptive beam forming techniques are available, but the ability to eliminate the noise source is limited in the fixed one. The sensitive errors due to channel delays are handled by the pre-processing section. After the pre-processing, feature from the audio signal is extracted.
Feature extraction is one of the main parts of a signal processing applications and can cause a significant impact on the system performance. Feature extracted from the acoustic signal gives away the information of the speaker signal to optimally spate them. For the feature extraction, Mel filter bank creation is necessary. The Mel filter bank is created based on the input signals power spectrum. Once the filter bank is created, the energy band of the bank is calculated and the weighted tangent function is added to get the Tangent weighted Mel filter cepstral coefficients, i.e. TMFCC. MFCC coefficients are coefficients that collectively make up a Mel filter cepstrum. The 12 order TMFCC along with their first order derivatives are taken for the speaker diarization system. The fusion with the delta and delta-delta function increases the robustness and reliability of the TMFCC coefficients.
Step out of the feature extraction is the change of activity detection. Voice activity detection is the most crucial front end processing in the diarization. The change of activity is the interval in speaker signal variation among one another. The general approach used is the maximum likelihood classification with the Gaussian mixture models. Activity change is detected and the vectors are extracted corresponding to the change in the signal. The change of the speech is detected using the Bayesian Inference criterion (BIC). The corresponding feature i-vector extraction from the change detected signal is the next step to be followed. The i-vector is extracted considering the total variability in the space. The expectation maximization algorithm is used to extract the vector using the mean of the posterior probability. Clustering of the audio signal based on the identity is done utilizing the Lion optimization algorithm. The optimized cluster is formed out of the clustering yielding the signal with separate labels corresponding to their identity.
4.1 TMFCC feature extraction
The feature extraction of the proposed speaker diarization system is deliberated in this section. TMFCC is the proposed feature parameterization.
In audio processing, the Mel frequency cepstrum (MFC) is a representation of the short term power spectrum of the audio signal based on the linear cosine transforms of a log power spectrum [20].
The source parameterization of the proposed diarization system is the Tangent weighted Mel frequency cepstral coefficients, i.e. TMFCC. Figure 3 shows the modular representation of the feature extraction. Initially, framing the signal into the short frames is done in the pre-emphasis stage. The periodogram estimate of the power spectra for the framed signal is calculated using the hamming window function and Fourier transform. The Mel filter coefficients are extracted from the filter bank. The log of the signal and the filter coefficient is multiplied along with the tangent weighted function to create the energy of the filter. The discrete cosine transform of the log filter bank energies is under gone from which the TMFCC coefficients are considered discarding the values other than 13. The logarithmic of the energy is taken and added with the tangent weighted function. The step by step procedure for the feature extraction of speaker diarization is discussed below:
Step 1: Initially, the audio signal taken for the diarization frame work is converted into framed signal with the frame number i. Let x(n) be the input signal. The framed signal is xi(n) where n is the number of samples and i is the number of frames.
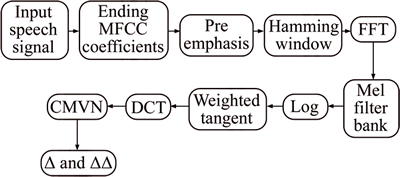
Fig. 3 Modular representation of the TMFCC feature extractor
Step 2: The power spectrum of the frame i is calculated using
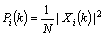 (1)
(1)
where Xi(k) is the discrete Fourier transform (DFT) of the framed signal which is given by
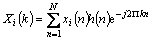 (2)
(2)
where h(n) is (N sample length) analysis window, i.e., hamming window and k is the length of the DFT.
The periodogram spectral estimate still contains a lot of information not required for the speech verification. To nullify this effect, clump the periodogram bins and sum them up based on the energy. This is done by using the Mel filter bank creation.
Step 3: Mel filter bank creation is the next step following the power spectra creation. For the Mel filter bank creation, choose the low frequency and the high frequency components from the power spectrum. Let FL and FH be the low frequency and the high frequency component chosen. Initially, the frequency is converted into Mel scale using
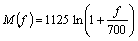 (3)
(3)
The Mel scale values are converted into the frequency components using
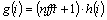 (4)
(4)
Then using the above calculated values, the filter bank is created based on
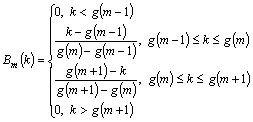 (5)
(5)
where m=1 to M and is number of filters and g() is the Mel spaced frequency.
Step 4: The filter bank energy is calculated using the tangent weighted function as
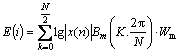 (6)
(6)
where Wm is the weighted tangent function which is the proposed one and calculated as
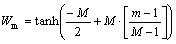 (7)
(7)
Step 5: The discrete cosine transform of the energy is calculated for the feature extraction coefficients, i.e. Tangent weighted Mel frequency cepstral coefficients.
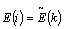 (8)
(8)
where 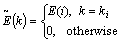 .
.
Step 6: The cepstral coefficient TMFCC is calculated from the energy using
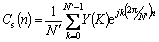 (9)
(9)
Thus, the TMFCC feature is extracted from the accepted input audio signal by the successive follow of steps 1 to 6. The residual mismatch in the feature vectors is reduced by the cepstral mean variance normalization (CMVN). The addition of the delta and delta-delta of a coefficient with TMFCC coefficients improves [21] the recognition accuracy in the speech verification and does not improve the robustness in the noise as well as the reverberation.
4.2 Change of speech detection
The change of the activity detection in the proposed speaker diarization system using the TMFCC coefficients is discussed in this section.
The change of the speech detection is the activity detection of the voice (VAD) [22]. VAD is one of the crucial front end tasks because the output of the other sub steps in the speaker diarization system is highly connected with it. The VAD separates the signal into the segment corresponding to the identity of the speaker [23, 24]. In the VAD, TMFCC coefficient vectors are modelled along with the audio signal and a threshold is set for each frame. The Bayesian inference criterion (BIC) value for the individual frame is calculated. The frame with value greater than the threshold denotes the voice change.
The VAD detection is the model based one which depends on the frame wise classification. The model used in the proposed system is the Gaussian mixture models (GMM). The cepstral features are often modelled using the GMM to model the speakers [25]. GMM is a popular tool for modelling multi-modal data which is of the following form:
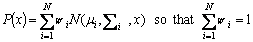 (10)
(10)
In some cases, to capture the variability of the speech universal background model (UBM) is adapted for the segment to obtain in the speaker model. The formula utilized for the activity detection is the BIC [26]. It is given by for the signal x,
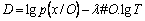 (11)
(11)
where O is the GMM model and # is the number of the parameters and data utilized in the model.
To detect the voice change between the x1 and x2 feature vectors, the following equation is utilized.
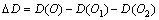 (12)
(12)
The positive value for the BIC suggests the change between the two signals. O is the model with the feature vectors x 1 and x 2 from the same distribution, namely they are concatenated. But O1 and O2 are modelled for the vectors x1 and x2 with the different distribution. Using the change in the value, the activity along the audio signal is detected and then separated based on the identity into the segment vectors.
4.3 i-vector extraction
The step regarding i-vector extraction for the further processing of the proposed speaker diarization system is described in this section.
The diagram for the modular representation of i-vector extraction is shown in Fig. 4.
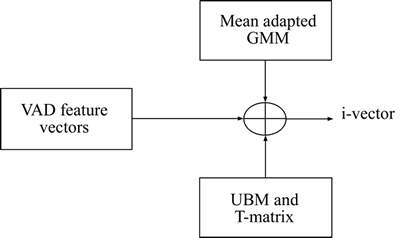
Fig. 4 Modular representation of i-vector extraction
The concepts of i-vector extraction are based on the joint factor analysis [3, 27]. i-vectors are extracted using universal background model (UBM) model. The feature vectors are the training data set for the UBM modelling. The UBM modelling and the T-matrix which is the covariance matrix with low rank value act upon the feature vector along with the mean adapted GMM modelling to obtain the i-vectors.
i-vector is extracted considering the feature in the total variability space. i-vector of the feature vector is the projection of the GMM super vectors onto the total variability space.
The total variability space is given by
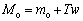 (13)
(13)
where mo the super vector of UBM; Mo is the super vector of the GMM and T is the covariance matrix; w is the random vector corresponding to the identity vector.
Initially, the UBM is adapted to form the GMM super vector and in the total variability space Eigen vectors are extracted to get i-vector values.
The steps involved in the i-vector extraction are given below.
Step 1: In UBM with a C component c={1, 2, 3, 4, ��, C}, the Baum-Welch statistics [28] (the 0th and 1st order) are calculated using the equation,
 (14)
(14)
where c is the mixture component; xt is the feature frames; 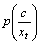 is the probabilistic alignment (Posterior probability of the cth component for the tth observation)
is the probabilistic alignment (Posterior probability of the cth component for the tth observation)
Step 2: The i-vector is extracted using the expectation maximization algorithm. The mean of the posterior components of the UBM delivers the corresponding vector.
The value for the corresponding feature vector is calculated using the probability function,
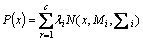 (15)
(15)
The element ��i is calculated using the probabilistic alignment of the statistical values. The i-vector for the corresponding feature vector is calculated using the formula,
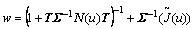 (16)
(16)
where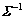 is the diagonal covariance matrix; N(u) is the diagonal matrix of the feature vector dimension; T is the total variability matrix.
is the diagonal covariance matrix; N(u) is the diagonal matrix of the feature vector dimension; T is the total variability matrix.
By making use of this equation, the i-vector for the corresponding feature vectors is attained.
4.4 Speaker clustering using Lion algorithm
The feature vectors from the i-vector extraction are clustered using the Lion algorithm [15] to separate the speakers based on the identity provided in the voice activity detection. The solution encoding using the Lion algorithm for the clustering of the speaker provides the way in which the activity detected signal is clustered based on i-vector element using the Lion algorithm.
1) Solution encoding
i-vector feature extracted from the VAD signal presumes the vector elements as the male, female and the nomad lion. Then, using the Lion algorithm, the optimal centroid point is selected, namely i-vector element is chosen.
The change of activity detection, i.e. VAD of the input audio signal, yields the segmented signal with the different speaker.
Figure 5 defines the solution encoding of the proposed speaker diarization system. Let D be the input audio signal. The input audio signal is with the combination of the three speakers. The task is to separate the signal based on the identity of the speaker. It doesn��t recognize who is instead and it can verify the speaker signal. The voice activity detection finds the change in the voice over the signal denoted as the activity detection. The i-vectors are extracted from the VAD feature.
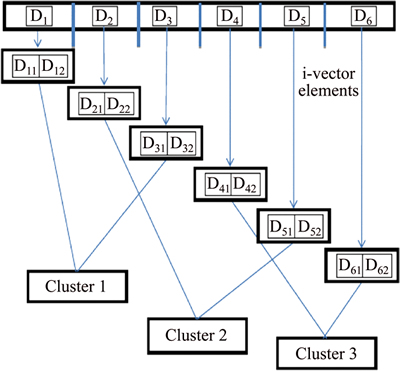
Fig. 5 Solution encoding
Each activity detected signal has the corresponding i-vector. If D1 is the activity detected signal, i-vector elements for the signal is D11 and D12 . The extracted i-vector elements from the VAD feature is clustered using the Lion algorithm.
2) Steps involved in the clustering using the Lion algorithm
Step 1: Pride generation and subject to solution constraints
Let ZM, ZF and ZN be the generation of lion with pride considered for the Lion algorithm. Here, M denotes the male lion, F denotes the female lion and N denotes the nomad lion. The values of ZM and ZF are given by
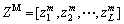 (17)
(17)
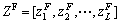 (18)
(18)
where L is length of the solution vector.
Once the initial lion is selected randomly, the optimal one is chosen based on the fitness value. The fitness value is calculated for the lions. The lion with greater value replaces the older one of the pride. The fitnesses of ZM, ZF and ZN are calculated using the fitness equation, i.e. mean square error.
The fitness values of the all the lions are stored. The reference fitness is set as the fitness value of the male lion. The fitness evaluation is elaborated in step 2.
Step 2: Fitness evaluation
The fitness evaluation for choosing the optimal i-vector element as the centroid point for the clustering is discussed in this section. The fitness evaluation is completed using the mean square error (MSE) formula.
The fitness is evaluated at two stages in the lion optimization algorithm. Initially, i-vector elements chosen as the solution point randomly need the evaluation to continue the optimization algorithm.i-vector feature with the greater fitness value considering other elements is selected for the clustering. Lastly, at the output of the optimization algorithm, the Cub of the parental lion generated by the cross over and mutation fitness value is necessary. Similarly, the replacement of the male lion by the nomad lion also needs the fitness value.
The diagrammatic representation for the fitness evaluation is shown in Fig. 6. The Lion algorithm gives away the multiple i-vector elements as the centroid point. The best optimal one for the clustering of the input audio signal based on the identity of the speaker is evaluated using the MSE. For the random i-vector elements selected as the centroid point, the distance of the individual i-vector element from the centroid i-vector element is estimated.
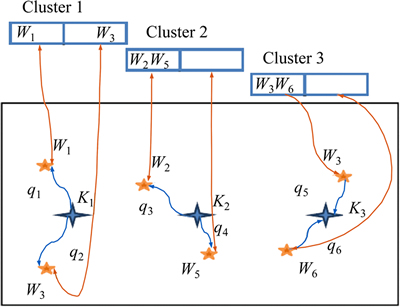
Fig. 6 Fitness evaluation
The distance is calculated using the Euclidean distance formula. Based on the distance value, the vector element with the reduced distance attains the cluster centroid point and forms the group. The distance of the individual identity vector element from the selected centroid element is calculated. Then the mean difference between the distances is calculated to obtain the best possible centroid point for the grouping of the vector elements of different activity detected speaker.
The fitness calculation using the MSE is given by
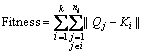 (19)
(19)
where Q is the distance for the vector elements in the relevant cluster and K is the centroid point for k clusters.
The net distance Q due to the i-vector elements is given by the equation,
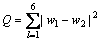 (20)
(20)
The Euclidean distance formula for i-vector elements is calculated using the equation given below. For the i-vector W1=[W11, W12] and W2=[W21, W22], the distance formula is calculated as
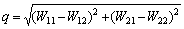 (21)
(21)
Step 3: Fertility evaluation
To avoid the converging of the local optima, the fertility of the lion and lioness are evaluated.Many factors get incorporated with the parental lion and lioness for the fertility evaluation. Here, the factors considered for the evaluation are listed: fref is the reference fitness function of ZM; Lr is Laggardness rate; Sr is Sterility rate; wc is the female update count; qc is the female generation count; ZF+ is the updated female lion.
Since the value of the laggardness rate and the sterility rate are set from the biological motivation, they are chosen irrespective of the gender of the lions.
The fertility evaluation starts with the initiation of zero for the Sr and Lr respectively. During the fertility evaluation, the values get incremented. Primarily, the generation count of the female lion is set based on the trial and error method. The value of the generation count is set around 10. Calculation of ZF+ is
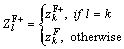 (22)
(22)
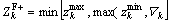 (23)
(23)
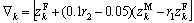 (24)
(24)
where l and k are the vector elements of the solution vector L. They are random integers generated within the interval [0, L]. 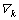 is the female update count function; r1 and r2 are the random integers generated within the interval [0,1].
is the female update count function; r1 and r2 are the random integers generated within the interval [0,1].
Step 4: Cross over and mutation
The parental lion successful after the fertility evaluations is subjected to the cross over and mutation. The parental lion yields the cub lions as the offspring. For the evolutionary optimization algorithms, mutation and cross over are the significant factors.
1) Cross over
The traditional cross over on the pride lion leads to the situation of the copies of the parental lion. But the evolutionary optimization algorithm enhances only by the duplicate removal. So the single point cross over with the dual probability is adapted in the lion algorithm for the cross over. For the random cross over probability Cr, cross over operation is given as
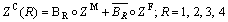 (25)
(25)
where ZC represents the cub obtained from the cross over; R is cross over mask length and the value is 1 or 0 based on the Cr; 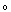 is Hadamord product.
is Hadamord product.
2) Mutation
The cubs due to the cross over are mutated to form the new offspring��s. ZC is subjected to mutation to form ZNew. The mutation is done with the mutation probability Tr. The obtained ZC and ZNew are placed in a cub pool and then subjected to gender clustering.
3) Gender clustering
Gender clustering selects the best possible off spring as the replacement for the parental pride lion.
The gender clustering is done to extract the male and the female cubs separately. The physical nature and the cubs with the first and second fitness are selected as ZM_C and ZF_C, respectively.
M_C denotes the male cub and F_C denotes the female cub.
Step 5: Cub growth function
The cub growth function compares the offspring out of the cross over and mutation based on the function value. The offspring with the better fitness value is selected as the new cub male and the female. Once the cubs are selected, the age Ac is incremented illustrating the growth of the cub towards the maturity. The selection of the growth rate and the mutation rate must be in a way which does not exceed one another. Nr is denoted as the growth rate.
Step 5: Territorial defence
The search space of the pride lion group increases only because of the territorial defence. The pride lion must defend its place from the nomad lion to protect its generation. On the survival fight, if the nomad lion wins, it updates the territorial lion.The nomad lions taken here are 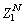 and
and 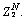 The male lions are only considered for the survival fight so that the laggardness rate is initialized leaving the sterility rate. The survival fight is originated with the nomad lion having the maximal fitness function. If it fails to survive, the next nomad with less fitness considering the initial one continues the survival fight. The initialization is based on the laggardness rate since only the male lions are considered for the territorial defence.
The male lions are only considered for the survival fight so that the laggardness rate is initialized leaving the sterility rate. The survival fight is originated with the nomad lion having the maximal fitness function. If it fails to survive, the next nomad with less fitness considering the initial one continues the survival fight. The initialization is based on the laggardness rate since only the male lions are considered for the territorial defence.
The update of the nomad lions happens only if the following condition is achieved.
If 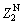 is to be updated because of the loss in fight of the
is to be updated because of the loss in fight of the 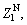 then
then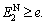 The value of
The value of 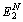 is calculated using
is calculated using
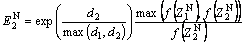 (26)
(26)
where d1 is the Euclidean distance between 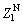 and ZM; d2 is the Euclidean distance between
and ZM; d2 is the Euclidean distance between 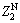 and ZM.
and ZM.
Step 6: Territorial takeover
The territorial takeover is the process with in which the parental lions are replaced by the cub lions once the maturity in the growth is attained. When the takeover takes place, the age Ac is a maximum for the cub lion. After the takeover, the generation count qc is updated.
Step 7: Iteration
The lion algorithm is iterated until
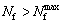 (27)
(27)
where Nf is the number of function evaluation. After the optimal centroid selection by repeating the fitness evaluation (step 2), the grouping is done based on the best possible centroid.
5 Results and discussion
The results and the discussion interrelated with the proposed speaker diarization system using the TMFCC as the spectral feature and Lion algorithm based clustering are discussed in this section. The performance of the system is evaluated with the existing system [11]. The experimentation is done on the multi-speaker signals.
5.1 Experimental setup
The experimentation signal source, the simulation tool used and the evaluation metrics used for the proposed speaker diarization system are discussed in this section.
The audio signal taken for the experimentation is from ELSDSR corpus dataset [29]. The English Language Speech Database for speaker recognition corpus data set contains the training set of audios with different Id��s. The dataset taken for the experimentation is the concatenation of the speaker signal from the different Id��s.
1) Generation of mixed signal
In the ELSDSR, the recording environment is with the deflection board to deflect the reflection of the speakers and the recording is manipulated with one fixed high quality microphone. The equipment for the recording is MARANTZ PMD670 portable solid state recorder. It can record in a variety of compression algorithm, associated bit rate, file format and recording type. For the experimentation, the speaker set from the ELSDSR is concatenated. The audio signals having three, four and five concatenated speaker signal are taken as the input for the proposed speaker diarization system.
2) Simulation
The simulation of the diarization system is done using the MATLAB (R2014a) software tool in a personal computer having Intel core i3 processor, 2 GB RAM, Windows 7 operating system.
3) Evaluation metrics
The evaluation metrics taken into consideration for the experimentation are enumerated in this section. The evaluation metrics considered for the performance evaluation are the tracking accuracy and the tracking distance.
I) Tracking accuracy
Tracking accuracy is the accuracy of the speaker diarization system. The system with the better accuracy verifies the individual speaker signal more precisely. The formula for the tracking accuracy is given by 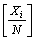
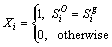 (28)
(28)
where i=1, ��, N and is number of samples; 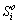 is the speaker output signal and
is the speaker output signal and 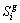 is the original signal.
is the original signal.
II) Tracking distance
Tracking distance must be reduced for the optimized performance of the speaker diarization system. The tracking distance is calculated using the formula,
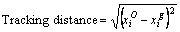 (29)
(29)
where 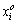 is the speaker output signal and
is the speaker output signal and 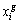 is the original signal.
is the original signal.
5.2 Experimental results
The experimental results with the multi-speaker audio signal having three, four and five different speakers are viewed in this section. The speech input signal and the corresponding TMFCC frames after the input acceptance are viewed in Figs. 7 and 8.
1) In Fig. 8, two plots resembling the input speech signal and the frame of the speech input after the TMFCC feature extraction are shown. Here, the speech input signal consists of four different speakers. Individual speaker set has the different amplitudes over the time with the ��n�� number of the samples in Fig. 8(a). The proposed approach uses the TMFCC parameter as the spectral feature. The input speech signal with the ��n�� number of the sample signals is framed and the TMFCC features corresponding to the frames are extracted in Fig. 8(b). The 20 TMFCC features are extracted from the individual speaker set and represented in the signal form which is the combination of the 20 signals. The spectral feature corresponds to the Mel filter energy band values. The speaker signals are verified using the TMFCC feature set in the change of voice activity detection.
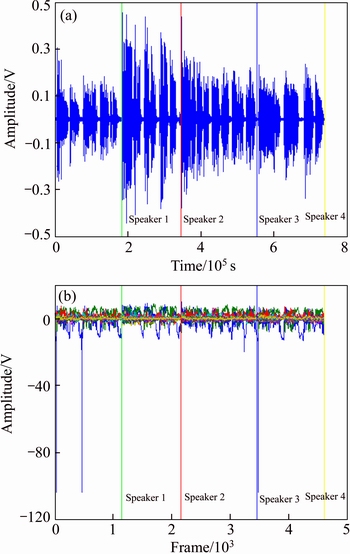
Fig. 7 Plots showing multi-speaker speech signal with four speakers (a) and corresponding speaker frame after TMFCC parameterization (b)
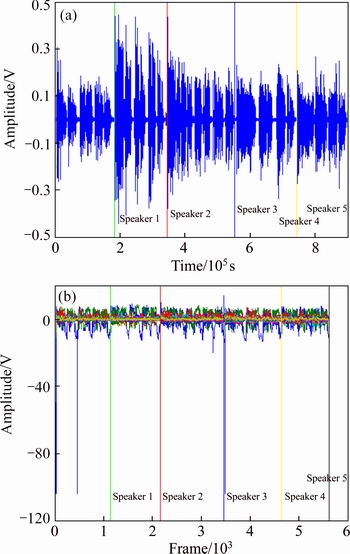
Fig. 8 Plots showing multi-speaker speech signal with five speakers and corresponding (a) and speaker frame after TMFCC parameterization (b)
2) The speech input signal with the five different speakers and the framed speech after the TMFCC feature extraction are shown in the Fig. 8. In Fig. 8(a), the multi-speaker signals with the five different speakers signal varying over the time with different amplitudes are plotted. The speech input frames after TMFCC feature extraction with 20 features signal over the Mel filter energy bands are shown in Fig. 8(b).
The TMFCC feature extracted signals are then clustered using the Lion optimization algorithm to verify speaker signals.
5.3 Evaluation based on tracking accuracy
The evaluation of the proposed novel speaker diarization system using the tracking accuracy as the evaluation metrics is analyzed in this section. The speech input signals with multi-speaker are taken and the individual speaker signals are diarized and verified. The proposed system uses the TMFCC as the source parameter and Lion optimization algorithm for the speaker clustering.
The performance of the proposed system in terms of the tracking accuracy is compared with the existing system [11] which uses the MFCC spectral feature and the Integer linear program (ILP) clustering. The comparison is done over the diarization system with MFCC and ILP clustering, MFCC and Lion clustering, TMFCC and Lion clustering and the proposed TMFCC and Lion based speaker diarization systems.
1) In Fig. 9, the experimentation using three different speakers are analyzed based on the tracking accuracy. For the speech input signal, the tracking accuracy over different size of the frame and for the change in the wavelength values is plotted separately in Figs. 9(a) and 9(b). In Fig. 9(a), the tracking accuracy for the five different sizes of the frames is noted. For the frame of size 0.03, the tracking accuracy for the proposed speaker diarization system is 66.19% where as for the system with ILP and MFCC, Lion and MFCC, TMFCC and Lion tracking accuracy is 65%. It shows that the performance of the proposed speaker diarization system is more advanced than that of the existing system. With increase in the frame size, the tracking accuracy gets increase. But the proposed system has the increased tracking accuracy of about 95% compared to the other existing diarization systems. Figure 9(b) shows the tracking accuracy plotted between the accuracy and the �� value. The plot shows the relation over different �� values i.e. 6, 8, 10, 12 and 14. For ��=12, the tracking accuracy attained by the proposed system is 95%. At the same �� value, the tracking accuracy attained by the existing speaker diarization system is 65%, 75.71%, 86.53%, respectively. The tracking accuracy values emphasize the fact that the proposed system is with the improved tracking accuracy over the existing systems.
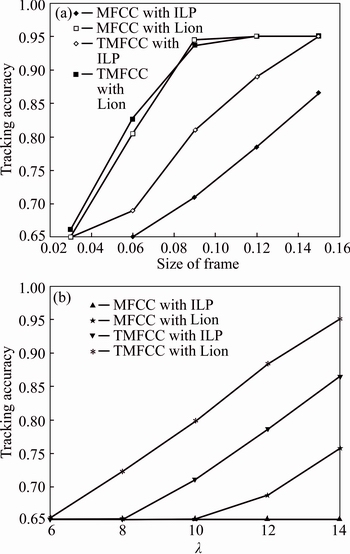
Fig. 9 Analysis based on tracking accuracy in multi-speaker signal with three different speakers over change in size of frame (a) and wavelength(��) (b)
2) The analysis of the speaker diarization system with four different speaker signals based on the tracking accuracy is shown in Fig. 10. Figure 10(a) corresponds to the tracking accuracy with the change in the size of the frames and Fig. 10(b) corresponds to the tracking accuracy with the change in the �� value. In Fig. 10(a), at the frame size of 0.12, the tracking accuracy attained by the speaker tracking system with the TMFCC spectral feature is 95%. The existing tracking system attains the accuracy of about 89% with MFCC and ILP, 65% with TMFCC and ILP which is very low compared to the proposed system. The proposed TMFCC parameter and Lion clustering based diarization have the increased effect on the tracking accuracy over the existing speaker diarization system. The tacking accuracy with different �� values also attains the increased accuracy of about 95% at ��=14 for the proposed system where as the existing system yields only about 72%. The system with the MFCC and Lion, and TMFCC and ILP achieved 84.739% and 95% respectively. From the graph, it is clear that for increased value of the �� only the proposed system gives away increased tracking accuracy.
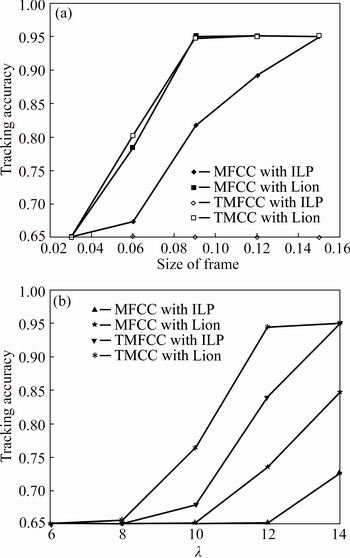
Fig. 10 Analysis based on tracking accuracy in multi-speaker signal with four different speakers over change in size of frame (a) and wavelength (��) (b)
3) The tracking accuracy analysis of the speech signal with five different speaker set is shown in Fig. 11. Figure 11(a) shows the plot between the size of the frame and the tracking accuracy and Fig. 11(b) shows the plot between the lambda value and the tracking accuracy. The tracking accuracy by adjusting two parameters is listed. For the frame size of 0.15, the accuracy attained by the existing system is 95%. The proposed system also attains 95% accuracy, proving that it is more efficient than the existing system. At the same frame size, the speaker tracking system with the TMFCC and ILP based clustering attains the accuracy of about 65%.
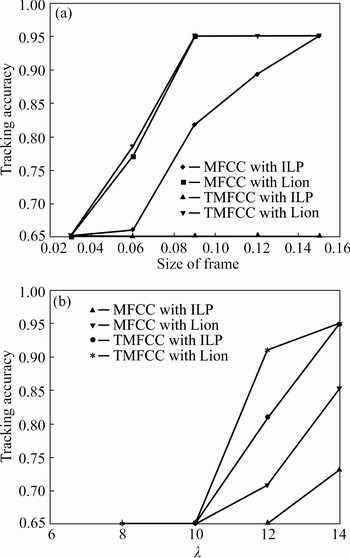
Fig. 11 Analysis based on tracking accuracy in multi-speaker signal with five different speakers over change in size of frame (a) and wavelength (��) (b)
In plot relating the lambda value and tracking accuracy, the tracking accuracy for the value 0.12 is 65.000%, 70.840%, 80.960% and 91.080%, respectively. Comparing these values, increased accuracy of 91% is attained by the proposed system. The tracking accuracy value gets increase with the increase in the lambda value. For the lambda value 0.15, the accuracy attained is 95% which is 21.9% more than that of the existing systems. The system adaptation with the Lion based clustering itself improves the tracking accuracy. When the parameterization covering the higher and lower energy level frames (TMFCC) is adapted along with the lion clustering, the speaker verification has more effect.
The analysis based on the tracking accuracy shows that the proposed speaker diarization system has the increased accuracy of 95% compared with the existing systems. It proves that the adaptation of the TMFCC as the spectral feature and Lion based clustering for the speaker diarization system improves speaker verification.
5.4 Evaluation based on tracking distance
The analysis of the proposed speaker diarization system based on the tracking distance as the evaluation metrics is discussed in this section. The tracking distance with the change in the size of the frames and the value of the lambda are plotted separately. The analyses over the speech signals with multi-speaker, i.e., three speakers, four speakers and five speakers, are shown in Figs. 12-14.
1) Figure 12 shows the analysis based on the tracking distance in a multi-speaker signal with three different speakers. The plot between the distance and the size of the frame is shown in Fig. 12(a) and the plot between the lambda value and the tracking distance is shown in Fig. 12(b). For the frame of size 0.03, the tracking distance achieved by the existing system is 410.88, system with the MFCC and Lion attains 308.16, system with TMFCC and ILP attains 102.61. The proposed system attains the 304.4 distance which is lower compared to the existing algorithm. The reduced tracking distance value provides the optimized performance of the speaker diarization system. For the frame 0.15, the tracking distance attained is 1918.1, 1438.6, 1531.1, and 500.98, respectively. The reduced distance 500.98 is only attained by the proposed system which is 937.62 lower than the existing tracking system. For the change in the lambda value shown in Fig. 12(b), at ��=10 the tracking distance estimated for the proposed system is 627.6. The tracking distance of the existing system is 2510.6. The tracking system with the MFCC and Lion achieves 1883.0 distance value and the system with the TMFC and ILP attains the value of 1255.3. The reduced tracking distance value 627.6 attained by the proposed system proves the proposed one more effective for the speaker verification.
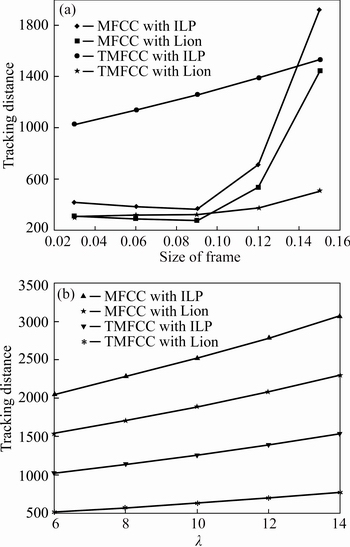
Fig. 12 Analysis based on tracking distance in multi-speaker signal with three different speakers over change in size of frame (a) and wavelength (��) (b)
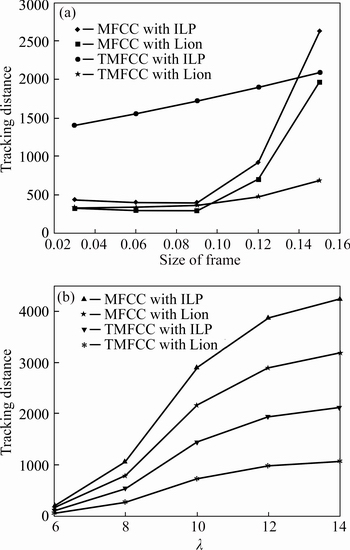
Fig. 13 Analysis based on tracking distance in multi-speaker signal with four different speakers over change in size of frame (a) and wavelength (��) (b)
2) The analysis curve based on tracking distance for the multi-speaker signal with four different speakers is shown in Fig. 13. In Fig. 13(a), the curve is plotted between the tracking distance and size of the frames. The distance value of 429.69 is attained in the existing system; the system with MFCC and Lion attains the distance of 322.7; the system with the TMFCC and ILP attains the distance of the 1398.3; the proposed system achieves the tracking distance value of about 317.17 for the frame of size 0.03. The tracking distance value of the proposed system is reduced than that of the existing system, which proves that the performance of the proposed speaker diarization system is more efficient comparing the other existing diarization system. Even though the increment in the frame size increases the distance value, the proposed systems tracking distance is less than that of the existing methods, thereby proving its efficiency. In Fig. 13(b), the curve for the analysis is plotted between the lambda value and the tracking distance. For the lambda value of 12, the tracking distances attained by the experimented systems are 3859.20, 2894.40, 1929.30 and 964.65, respectively. The tracking distance value less than the 1000 is only attained in the proposed one whereas the existing system distance value exceeds than 2000. The change in the lambda value also increases the distance value, but it is not more than the existing systems tracking distance.
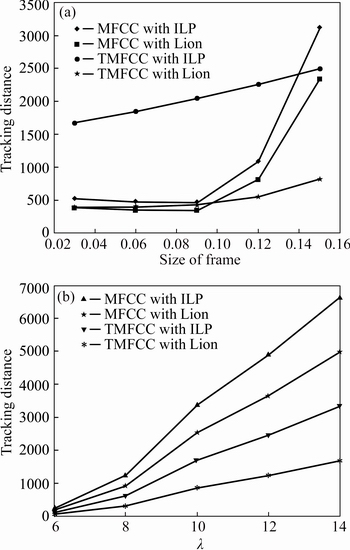
Fig. 14 Analysis based on tracking distance in multi-speaker signal with five different speakers over change in size of frame (a) and wavelength (��) (b)
3) The analysis of the multi-speaker signal with five different speakers based on the tracking distance is shown in Fig. 14. The separate plot for the tracking distance with respect to the size of the frame and lambda value is shown in Figs. 14(a) and (b), respectively. For the frame size of 0.15, the tracking distance value 814.23 is attained in the proposed system. At the same frame size, the distance values for the existing methods are 3120.3, 2340.3, and 2492.0, respectively. The reduced distance is attained only by the proposed system. The change in the frame size over the proposed system provides reduced tracking distance over the existing ones. In Fig. 14(b), for the lambda value 14 tracking distances of the existing speaker tracking systems are 6638.1, 4978.6 and 3318.8, respectively. The distance value for the proposed system is 1659.4. The distance value is found to be increased over the change in the lambda values for the proposed one but it is comparatively reduced over the existing systems.
The analysis of the proposed speaker diarization system based on the tracking distance shows that the proposed one yields the speaker verification with the reduced tracking distance. Thereby, the proposed TMFCC and Lion based speaker diarization is proved to be more efficient than the existing speaker indexing systems.
6 Conclusions
A novel approach for the speaker diarization system was presented. The speaker diarization system was proposed by making use of the TMFCC as the spectral feature parameter and the Lion algorithm for the speaker clustering. The Mel frequency cepstral coefficient (MFCC) was modified by the tangent weighted function into the Tangent weighted Mel frequency cepstral coefficient (TMFCC) which makes use of the low energy frame as well as the high energy frame. Thereby, the overall performance of the speaker diarization is improved. The speaker clustering based on the Lion optimization algorithm verifies the individual speaker signals. The Lion optimization algorithm was adapted to separate the audio of the individual speakers. The performance of the proposed system was analyzed over the audio signal with the multiple speakers signal with three different speakers, four different speakers and five different speakers based on the tracking accuracy and the tracking distance as the evaluation metrics. The experimental results give away the individual speaker signal more precisely with 95% tracking accuracy.
References
[1] MOATTAR M H, HOMAYOUNPOUR M M. A reveiw on speaker diarization systems and approaches [J]. Speech Communications. 2012, 54(10): 1065-1103.
[2] TRANTER S E, DOUGLAS A. Reynolds, an overview of automatic speaker diarization systems [J]. IEEE Transactions on Audio, Speech and Language Processing, 2006, 14(5): 1557-1565.
[3] KENNY P, GUPTA V, STAFYLAKIS T, OUELLET P, ALAM J. Deep neural networks for extracting baum welch statistics for speaker recognition [C]// Proceedings of the Speaker and Language Recognition. 2014: 293-298.
[4] SAYOUD H, OUAMOUR S, KHENNOUF S. Virtual system of speaker tracking by camera using an audio-based source localization [C]// Proceedings of World Congress on Engineering. 2012, 2.
[5] HUANG Y, BENESTY J, ELKO G W. Micro phone arrays for video camera steering [M]// Acoustic Signal Processing for Telecommunication. Hingham, MA, USA: Kluwer Academic Publishers, 2000: 239-260.
[6] CHEN Jian-feng, LOUIS S, WEE S. A new approach for speaker tracking in reverberant environment [J]. Signal Processing, 2002, 82: 1023-1028.
[7] HU M, SHARMA D, DOCLO S, BROOKES M, NAYLOR P A. Speaker Change detection and speaker diarization using spatial information [C]// Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing. Brisbane, QLD, Australia: IEEE, 2015: 5743-5747.
[8] MOATTAR M H, HOMAYOUNPOUR M M. Variational conditional random fields for online speaker detection and tracking [J]. Speech Communication, 2012, 54: 763-780.
[9] SUN X, FOOTE J, KIMBER D, MANJUNATH B S. Region of interest extraction and virtual camera control based on panoramic video [J]. IEEE Transactions on Multimedia, 2005, 7(5): 981-990.
[10] CHEN Yun-qiang, RUI Yong, Real-time speaker tracking using particle filter sensor fusion [J]. Proceedings of the IEEE, 2004, 92(3): 485-494.
[11] SWAMY R K, RAMA M K, YEGNANARAYANA B. Determining number of speakers from multi-speaker speech signals using excitation source information [J]. IEEE Signal Processing Letters, 2007, 14(7): 481�C484.
[12] PERTILA P. Online blind speech separation using multiple acoustic speaker tracking and time-frequency masking [J]. Computer Speech and Language, 2013, 27: 683-702.
[13] MA Zhong-hong, YANG Yong, GE Qi, DENG Li-jun, XU Zhen-xin, SUN Xu-na. Nonlinear filtering method of zero-order term suppression for improving the image quality in off-axis holography [J]. Optics Communications, 2014, 315: 232-237.
[14] Ye Tian, CHEN Zhe, YIN Fu-liang. Distributed Kalman filter-based speaker tracking in microphone array networks [J]. Applied Acoustics, 2015, 89: 71-77.
[15] RAJAKUMAR B. The Lion��s algorithm: A new nature-inspired search algorithm [J]. Procedia Technology, 2012, 6: 126-135.
[16] DUNN R B, REYNOLDS D A, QUATIERI T F. Approaches to speaker detection and tracking in conversational speech [J]. Digital Signal Processing, 2000, 10: 93-112.
[17] DAI Xiao-feng, LAHDESMAKI H, YLI-HARJA O. A stratified beta-gaussian mixture model for clustering genes with multiple data sources [C]// Proceedings of Biocomputation, Bioinformatics, and Biomedical Technologies. Bucharest, Romania: IEEE, 2008: 94-99.
[18] MARKOVIC I, PETROVIC I. Speaker localization and tracking with a microphone array on a mobile robot using von Mises distribution and particle filtering [J]. Robotics and Autonomous Systems, 2010, 58: 1185-1196.
[19] YEGNANARAYANA B, MAHADEVA PRASANNA S R. Analysis of instantaneous F0 contours from two speakers mixed signal using zero frequency filtering [C]// Proceedings of Acoustics Speech and Signal Processing. Dallas, TX, USA: IEEE, 2010: 5074-5077.
[20] ALAM M J, OUELLET P, KENNY P, O��SHAUGHNESSY D. Comparative evaluation of feature normalization techniques for speaker verification [J]. Advances in Nonlinear Speech Processing, 2011, 7015: 246-253.
[21] KUMAR K, KIM C, STERN R M. Delta-spectral cepstral Coefficients for robust speech recognition [C]// Proceedings of ICASSP. Prague, Czech: IEEE, 2011: 4784-4787.
[22] GUPTA V, BOULIANNE G, KENNY P, OUELLET P, DUMOUCHEL P. Speaker diarization of the French broadcast news [C]// Proceedings of ICASSP. Las Vegas, NV, USA: IEEE, 2008: 4365-4368.
[23] BARRAS C, ZHU Xuan. MEIGNIER S, GAUVAIN J L. Multistage speaker diarization of broadcast news [J]. IEEE Transactions on Audio, Speech and Language Processing. 2006, 14(5): 1505-1512.
[24] MIRO X A, BOZONNET S, EVANS N, FREDOUILLE C, FRIEDLAND G, VINYALS O, DIARIZATION S. Speaker diarization: A review of recent research [J]. IEEE Transactions on Audio, Speech and Language Processing, 2012, 20(2): 356-370.
[25] CAMPBELL W M, STURIM D E, REYNOLDS D A. Support vector machines using GMM supervectors for speaker verification [J]. IEEE Signal Processing Letters, 2006, 13(5): 308-311.
[26] PEELING P, CEMGIL A T, GODSILL S. Bayesian hierarchical models and inference for musical audio processing [C]// Proceedings of IEEE Wireless Pervasive Computing. Las Vegas, NV, USA: IEEE, 2008: 278-282.
[27] ZHENG Rong, ZHANG Ce, ZHANG Shan-shan, XU Bo. Variational bayes based i-vector for speaker diarization of telephone Conversations [C]// Proceedings of IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP). Florence, Italy, IEEE, 2014: 91-95.
[28] KENNY P, GUPTA V, STAFYLAKIS T, OUELLET P, ALAM J. Deep neural networks for Baum-Welch statistics for speaker Recognition [C]// Proceedings of Neural Networks for Speaker and Language Modelling, 2014.
[29] FLSDSR corpus dataset. [2016�C05�C02]. http://cogsys.compute.dtu. dk/soundshare/elsdsr.zip.
(Edited by YANG Hua)
Cite this article as: V. Subba Ramaiah, R. Rajeswara Rao. A novel approach for speaker diarization system using TMFCC parameterization and lion optimization [J]. Journal of Central South University, 2017, 24(11): 2649�C2663. DOI:https://doi.org/10.1007/s11771-017-3678-3.
Received date: 2016-05-05; Accepted date: 2016-09-23
Corresponding author: V. Subba Ramaiah, Assistant Professor; E-mail: subbubd@gmail.com

