Multi-objective workflow scheduling in cloud system based on cooperative multi-swarm optimization algorithm
��Դ�ڿ������ϴ�ѧѧ��(Ӣ�İ�)2017���5��
�������ߣ������� Ҧ��˳ �¿���
����ҳ�룺1050 - 1062
Key words��multi-objective workflow scheduling; multi-swarm optimization; particle swarm optimization (PSO); cloud computing system
Abstract: In order to improve the performance of multi-objective workflow scheduling in cloud system, a multi-swarm multi- objective optimization algorithm (MSMOOA) is proposed to satisfy multiple conflicting objectives. Inspired by division of the same species into multiple swarms for different objectives and information sharing among these swarms in nature, each physical machine in the data center is considered a swarm and employs improved multi-objective particle swarm optimization to find out non-dominated solutions with one objective in MSMOOA. The particles in each swarm are divided into two classes and adopt different strategies to evolve cooperatively. One class of particles can communicate with several swarms simultaneously to promote the information sharing among swarms and the other class of particles can only exchange information with the particles located in the same swarm. Furthermore, in order to avoid the influence by the elastic available resources, a manager server is adopted in the cloud data center to collect the available resources for scheduling. The quality of the proposed method with other related approaches is evaluated by using hybrid and parallel workflow applications. The experiment results highlight the better performance of the MSMOOA than that of compared algorithms.
Cite this article as: YAO Guang-shun, DING Yong-sheng, HAO Kuang-rong. Multi-objective workflow scheduling in cloud system based on cooperative multi-swarm optimization algorithm [J]. Journal of Central South University, 2017, 24(5): 1050-1062. DOI: 10.1007/s11771-017-3508-7.
J. Cent. South Univ. (2017) 24: 1050-1062
DOI: 10.1007/s11771-017-3508-7

YAO Guang-shun(Ҧ��˳)1, 2, DING Yong-sheng(������)1, HAO Kuang-rong(�¿���)1
1. Engineering Research Center of Digitized Textile & Fashion Technology of Ministry of Education,
College of Information Sciences and Technology, Donghua University, Shanghai 201620, China;
2. College of Computer and Information Engineering, Chuzhou University, Chuzhou 239000, China
 Central South University Press and Springer-Verlag Berlin Heidelberg 2017
Central South University Press and Springer-Verlag Berlin Heidelberg 2017
Abstract: In order to improve the performance of multi-objective workflow scheduling in cloud system, a multi-swarm multi- objective optimization algorithm (MSMOOA) is proposed to satisfy multiple conflicting objectives. Inspired by division of the same species into multiple swarms for different objectives and information sharing among these swarms in nature, each physical machine in the data center is considered a swarm and employs improved multi-objective particle swarm optimization to find out non-dominated solutions with one objective in MSMOOA. The particles in each swarm are divided into two classes and adopt different strategies to evolve cooperatively. One class of particles can communicate with several swarms simultaneously to promote the information sharing among swarms and the other class of particles can only exchange information with the particles located in the same swarm. Furthermore, in order to avoid the influence by the elastic available resources, a manager server is adopted in the cloud data center to collect the available resources for scheduling. The quality of the proposed method with other related approaches is evaluated by using hybrid and parallel workflow applications. The experiment results highlight the better performance of the MSMOOA than that of compared algorithms.
Key words: multi-objective workflow scheduling; multi-swarm optimization; particle swarm optimization (PSO); cloud computing system
1 Introduction
Workflow emerging as a popular paradigm, is used by many scientists and engineers to model scientific and industrial applications [1-3]. Typically, a workflow application contains a great number of tasks that have precedence constraints, where the input of some of these tasks may depend on the output of the others. And usually, it can be described by a directed acyclic graph (DAG) in which each computational task is represented by a node, and each datum or control dependency between tasks is represented by a directed edge between the corresponding nodes.
In a distributed heterogeneous computing system, how to schedule the tasks of a workflow to the available computing resources, which belongs to a class of NP-complete problem [4], is one of major challenges. Many classical optimization methods, such as suffrage, min�Cmin, max�Cmin, HEFT and auction-based optimization, were reported in Refs. [5, 6]. And many other works proposed a lot of effective algorithms for workflow scheduling in a distributed computing system for different objectives from different perspective [2, 7-9].
Recently, cloud computing becomes a revolutionary paradigm suitable to change the way of providing heterogeneous services and computational resources to customers in a pay-as-you-go model [10-14]. Cloud service providers, such as Amazon EC2 and IBM, can offer flexible and scalable IT infrastructures to customers. With cloud computing, customers can scale up to massive capacities in an instant without having to pay for software licenses and invest in new infrastructure. These characteristics attract an increasing number of individuals and corporations to rent cloud service for their applications.
In the context of cloud computing, the workflow scheduling is even more difficult because there are several factors to be considered. Firstly, the goal is different between customers and cloud service providers. Customers usually interest in minimizing makespan and cost of their application, whereas cloud service providers often interest in maximizing the resource utilization, minimizing the energy consumption or user fairness. In these circumstances, the scheduling must be formulated as a multi-objective optimization problem (MOOP) aiming at optimizing multiple possible conflicting criteria, where it is impossible to find the globally optimal solution with respect to all objectives. Moreover, the cloud data center offers its services to customers in the form of virtual machine (VM) through virtualization technology and the running VMs can scale up and down dynamically according to the workloads in the system. So, the scheduling strategy should be able to check the available computational resources as quickly as possible after the change happened.
Recently, some related works [15-17] have proposed their methods for multi-objective workflow scheduling in cloud or grid system. In Ref. [15], the problem was simplified to a single-objective problem by aggregating all the objectives in one analytical function. The main drawback of these approaches is that the computed solution depends on the selected weights, which is usually decided with a-priori, without any knowledge about the workflow, infrastructure, and in general about the problem being solved. Therefore, the computed solution may not be satisfactory for the solved problem if the weights do not capture the user preferences in an accurate way. Other approaches are based on sorting the different objectives in a sequential fashion [16]. Once an objective has been optimized and no further improvement is possible, the next objective is considered. The optimization of this new objective is carried out so that none of the imposed constrains over the previous criteria are violated. ZHAN et al [17] took this kind of approach to optimize makespan and economic cost. However, for the above approaches, the number of objectives is limited and the order in which the objectives are optimized requires some sort of preferential information, which may be difficult to derive.
Recently, some Pareto-based approaches have been used for multi-objective task scheduling. TAO et al [18] proposed a case library and Pareto solution based hybrid genetic algorithm to find Pareto solutions for makespan and energy consumption optimization. DURILLO et al [19] designed a Pareto-based heuristic list scheduling that provided the customers with a set of tradeoff optimal solutions about makespan and energy consumption. They also proposed a similar multi-objective workflow scheduling method for makespan and cost [20]. However, all of the above works have focused on two objectives. As for three objectives (makespan, cost and energy consumption), FARD et al [21] and YASSA et al [22] presented a heuristic list scheduling and a hybrid particle swarm optimization (PSO) algorithm for these objectives, respectively. But none of the above methods has been integrated with the structure of cloud data center, which is composed of multiple physic machines (PMs) and where information can be shared among these PMs through Intranet. The above methods also did not consider the dynamic change of computational resources in the context of cloud computing.
In this work, we also take three objectives (makespan, cost and energy consumption) into consideration, and design a multi-swarm multi-objective optimization algorithm (MSMOOA) for workflow scheduling in cloud computing. In order to obtain the available computational resources for the scheduling, a data center model is designed at first. In this model, a manager server is adopted to collect the information of available computational resources after accepting the workflows submitted from customers, which effectively avoids the influence from the elastic resources to scheduling results. Then, the MSMOOA is executed. Different from previous algorithms [18-22], the MSMOOA takes advantage of the structure of cloud data center to search non-dominated scheduling solutions. In the MSMOOA, each available PM is considered a swarm and employs the improved multi-objective particle swarm optimization algorithm (MOPSOA) to find out non-dominated solutions with one objective. Through the Intranet connection among PMs, some particles in one swarm can get information from other swarms and the velocity update of these particles is also influenced by the states of other swarms, which promote the information sharing and cooperation among swarms. Some new update strategies are designed to improve the particles�� search capability. We compare the MSMOOA with another multi-objective scheduling algorithm in cloud system and further analyze the quality of solutions computed by these algorithms. Simulation results on well-known hybrid and parallel workflow applications highlight the performance of the proposed approach.
The main contributions of this work are as follows: 1) The MSMOOA is proposed by introducing a new multi-swarm cooperative mechanism and modifying the update of the particles�� velocity in the MSMOOA. The update of particles�� velocity at each iteration is affected by not only the personal and global best but also the swarm best. 2) The proposed MSMOOA is used for multi-objective workflow scheduling in cloud system, which is the first workflow scheduling algorithm that takes the structure characteristic of cloud data center into consideration.
2 Problem modeling
In this section, the concept for the MOOP is presented firstly. Then, the model of cloud data center, workflow application and scheduling, including all QoS parameters in this work is formally described. Our goal is to distribute workflow applications to cloud computing system so as to optimize both customers�� criteria (quality of service, QoS) and cloud providers�� profits. Finally, the scheduling model is presented as a MOOP.
2.1 Concept for multi-objective optimization problem
Most real-world engineering problems are MOOPs. The goal of the MOOP is to find a set of good trade-off solutions from which the decision maker can select one according to his preference. Since Pareto offered the most common definition of optimum in multi-objective optimization, lots of research works were presented to solve the MOOPs [23, 24].
The mathematical formulation of a minimization problem for the MOOP with m decision variables and n objectives can be formally defined as
 (1)
(1)
where  is a m-dimensional decision vector; X is the search space;
is a m-dimensional decision vector; X is the search space;  is the objective vector and Y is the objective space.
is the objective vector and Y is the objective space.
Because there are multiple objectives involved in the MOOP, there is no single optimal solution with regards to all objectives. The solutions which have trade-off or good compromise among all objectives should be found, where Pareto optimality is usually adopted. Some Pareto concepts [24] are given as follows (without loss of generality, supposing that the objectives are to be minimized).
Definition 1: Pareto dominance. The vector x1 dominates the vector x2 (denoted by ), if and only if the next statement is verified.
), if and only if the next statement is verified.

 (2)
(2)
Definition 2: Pareto optimality. A decision vector x1 is said to be Pareto optimal if and only if the next statement is verified.
 (3)
(3)
Definition 3: Pareto optimal set. The Pareto optimal set PS is the set of all Pareto optimal decision vectors.
 (4)
(4)
Definition 4: Pareto optimal front. The Pareto front Pf consists of the values of the objectives corresponding to the solutions in PS.
 (5)
(5)
2.2 Cloud data center model
The cloud data center used in this work offers a set of resources by a cloud service provider in the form of VM in a pay-as-you-go model. In our model, the cloud data center consists of a set of PMs,
PM=
which is similar to multiple swarms of same species in nature. Each PM can communicate with other PMs located in the same data center through Intranet and all these connected PMs with a manager server make up the cloud data center. The cloud data center offers its services to customers through Internet via the manager server, which holds the information of available resources in the cloud data center, accepts the workflows submitted from customers and stores the found non- dominated solutions.
Through virtualization technology, each PM is virtualized a set of heterogeneous VMs

which has different performance and prices as shown in Fig. 1. The number of running VMs and PMs can scale up and down dynamically according to the workloads in the system. If the running VMs and PMs are changed, the corresponding information is sent to the manager server immediately. When the manager server accepts a workflow from customers, it is firstly check the information of available VMs and PMs. Based on this information, the multi-objective scheduling, which will be described in next section, is executed without being influenced by the change of available computational resources.
Pre-emption is not allowed in our model, which means that each task must be completed without interruption once started. It also supposes that each VM cannot perform more than one task at a time.

Fig. 1 Cloud data center model
2.3 Workflow application model
In this work, the DAG is used to represent customers�� workflow applications submitted to cloud computing system. A DAG V=(T, E) consists of R tasks T={t1, t2, ��, tR} which are interconnected through control flow and data flow such as

where Dataij represents the size of which needs to be transferred from task ti to tj. The relationship among tasks, such as serialization, parallelization and selection, is represented by the control flow and data flow. pred(ti) and succ(ti) are used to denote the set of predecessors and successors of task ti, which means that pred(ti) must complete before starting ti. Every task  is characterized by its length, len(ti), measured for example in the total number of instructions, which affects its execution time and energy consumption. Figure 2 shows a customer��s workflow model, which contains four tasks.
is characterized by its length, len(ti), measured for example in the total number of instructions, which affects its execution time and energy consumption. Figure 2 shows a customer��s workflow model, which contains four tasks.

Fig. 2 A customer��s workflow model with four tasks
2.4 Scheduling model
2.4.1 Makespan
The makespan of a task tr on VM vmij (the j-th VM in the i-th PM) can be computed as the sum of the longest input transfer time (from all inputs to tr) and the task computation time [19-21]:
 (6)
(6)
where sched(tp) is the VM which task tp executed on; Datapr is the size of the data to be transferred between tp and tr;  is the network bandwidth between sched(tp) and vmij; len(tr) is the length of the task tr in machine instructions as mentioned before; and sij is the computation speed of vmij. So, the makespan of tr on vmij can be computed as follows:
is the network bandwidth between sched(tp) and vmij; len(tr) is the length of the task tr in machine instructions as mentioned before; and sij is the computation speed of vmij. So, the makespan of tr on vmij can be computed as follows:
 (7)
(7)
The makespan of a DAG task is finally defined as the maximum completion time of all the tasks in the DAG:
 (8)
(8)
2.4.2 Economic cost
Because of marketization characteristic of cloud services, most cloud providers such as Amazon have set a price for their services. They have fixed the price for transferring basic data unit (e.g., per MB) between two services and the price for processing basic time units (e.g., per hour) in pay-as-you-go model. The economic objective O2 of task tr executed on vmij is the sum of data transfer and computation cost [20, 21]:

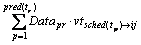 (9)
(9)
where vcij is the hourly price of vmij; Datapr is the size of the data to be transferred from tp to tr; and  is the hourly price of data transfer between sched(tp) and vmij. So, the economic cost of a DAG task is the sum of all tasks�� economic cost:
is the hourly price of data transfer between sched(tp) and vmij. So, the economic cost of a DAG task is the sum of all tasks�� economic cost:
 (10)
(10)
2.4.3 Energy consumption
In this work, our focus is on computational- intensive applications. Therefore, the data transfer and storage energy consumption are ignored and only the energy consumption for computation of tasks is considered. So, the energy consumption of task tr executed on vmij can be expressed as follows [19, 21]:
 (11)
(11)
where veij is the hourly energy consumption of vmij. So, the energy consumption of a DAG task is the sum of all tasks�� energy consumption:
 (12)
(12)
2.4.4 Scheduling model
In this work, a cloud computing system consists of a set of PMs. Each PM offers different VMs and the users submit their DAG applications. PMs compose of a set of tasks that have to be executed on these VMs. The workflow scheduling problem is to construct a mapping of these tasks to VMs that minimizes the following conflicting objectives: makespan, cost, and energy consumption. Therefore, the task scheduling in cloud system can be formulated as the following MOOP:
 (13)
(13)
3 Multi-objective workflow scheduling based on multi-swarm optimization algorithm
3.1 Particle swarm optimization algorithm
Inspired by the social behavior of animals, such as bird flocking and fish schooling, PSO algorithm was proposed by KENNEDY and EBERHART in 1995 [25]. PSO algorithm has got more and more attention from many researchers due to its relative simplicity, fast convergence and population-based feature [26]. In past decades, PSO algorithm has been successfully applied in a variety of fields, such as constrained mixed-variable optimization problems [27] and wireless sensor networks [28, 29]. Some of the existing multi-objective particle swarm optimization (MOPSO) algorithms can be found in Refs. [30-32].
In the PSO algorithm, the population of solution candidates is called a ��swarm��, while each candidate solution is called a ��particle��. Initially, the particles are generated at random and each particle is a candidate solution to the optimization problem. The current position in the search space of a particle represents a potential solution. In its more basic form, the position of the i-th particle in the search space at generations k+1, xi(k+1), is decided by
 (14)
(14)
where the factor vi(k+1) is known as the velocity and is given by
 (15)
(15)
where pi, called the personal best (pbest), is the best solution that xi has viewed, and gi, called the global best (gbest), is the best particle that the entire swarm has viewed. �� is the inertia weight of the particle and controls the tradeoff between the global experience and the local one. r1 and r2 are two uniformly distributed random numbers in the range [0,1], and C1 and C2 are specific parameters which control the effect of the personal particle and the global best one.
At each iteration of the PSO algorithm, each particle improves its position and velocity according to Eqs. (14) and (15). Then, the fitness value of each particle is evaluated according to the desired optimization fitness function and pbest as well as gbest is updated. Analogous to other evolutionary computation algorithms, the PSO algorithm is terminated when the stopping criterion is satisfied.
3.2 MSMOOA
In nature, many swarms of same species can exist in the living space simultaneously. Each swarm occupies a part of the living space and evolves according to the rules benefit for its own swarm. Due to various reasons such as competition for territory or mating, some individuals can communicate with several other swarms. They can get information from the swarms which they have arrived. So, the evolution of the individuals is affected by different swarms�� rules and they also promote information sharing among swarms and cooperative development of whole species.
The cloud data center consists of several PMs and information can communicate among PMs through Intranet as mentioned in Section 2.2. Each PM is virtualized to a set of heterogeneous VMs through virtualization technology. Thus, the structure of cloud data center is similar to multiple swarms of same species in nature. So, in this work, we design the multi-swarm cooperative PSO called MSMOOA for multi-objective workflow scheduling in cloud computing environment. It has been proved that the multi-swarm cooperative PSO can get better performance than typical MOPSO [32]. In our proposed algorithm, each available PM performs as a swarm and can communicate with each other through Intranet. So, the particles of each swarm in the MSMOOA are divided into two classes. The first class of particles belongs to only one swarm and develops according to the rule of this swarm. The second class of particles can communicate with multiple swarms and get evolutionary information from these swarms, so the update of these particles�� position and velocity is affected by different swarms�� rules. The second class of particles also promotes information sharing among swarms and cooperative evolution in the whole process for multi-objective optimization. The spirit of dividing each swarm into two classes is similar to the idea presented in Ref. [33]. However, the functions and evolutionary strategies for the particles in Ref. [33] and this work are different from each other. Furthermore, the method proposed in Ref. [33] is used for the multimodal functions and is not suit for the multi-objective scheduling in this work.
In the MSMOOA, each swarm employs the MOPSO algorithm to find out non-dominated particle with one objective. Then, all non-dominated particles obtained by different swarms cooperate to find the final global non-dominated solutions. Like most of the existing MOPSO algorithms, the external archives with maximal capacity, called the local external archive (LEA) in each PM and the global external archive (GEA) in the manager server, are adopted to store non-dominated optimal solutions for one swarm and all swarms, respectively. The details are presented as follows.
3.2.1 Particle representation
To solve an optimization problem with the PSO algorithm, one needs to encode the candidate solution to the underlying problem into a particle vector form, then the evolved vector is decoded to the solution form to evaluate its merit of fitness. In our work, each particle is represented with a vector of n elements (n is the total number of tasks in a DAG application), and each element has three integer values, which indicate the number of task in the DAG, the number of PM, and the number of VM, respectively. It also indicates that the position satisfies the precedence constraint between tasks. For example, Fig. 3 shows a feasible particle for the DAG application as shown in Fig. 2. This particle indicates that task 1 is scheduled to the second VM in the first PM, task 2 is scheduled to the first VM in the second PM, and so on.
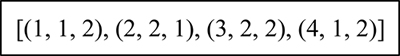
Fig. 3 A particle example for DAG application in Fig. 2
3.2.2 Handing workflow scheduling using MSMOOA
Our work has three fitness functions: 1) minimizing makespan O1(V) according to Eq. (8), 2) minimizing economic cost O2(V) according to Eq. (10), and 3) minimizing energy consumption O3(V) according to Eq. (12).
In this work, each available PM is considered a swarm and corresponds to one of multi-objective in the workflow scheduling. And each swarm employs the MOPSOA to find out non-dominated solutions with this objective, which are stored in the LEA. Then, all non-dominated solutions obtained by different swarms cooperate to find the final global non-dominated solutions, which are stored in the GEA. So, the evolution of all particles in the MSMOOA is affected by not only the personal and the swarm��s information but also the global information. So, it is different from the similar algorithm presented in Ref. [34] called vector evaluated particle swarm optimization (VEPSO), which does not have global information.
Inspired by division of same species into multiple swarms in nature and information sharing among swarms to promote cooperative evolution, particles of each swarm in the MSMOOA are divided into two classes as mentioned before. The first class of particles only belongs to one swarm and develops according the rule of this swarm. So, the velocity update of these particles  the velocity of the i-th particle in the s-th swarm) is modified as
the velocity of the i-th particle in the s-th swarm) is modified as

 (16)
(16)
Like some individuals can communicate with several other swarms in nature, the other class of particles in the MSMOOA can migrate among several other swarms and get information from these swarms. So, the velocity update of these particles is expressed as
 (17)
(17)
where  (called pbest) is the personal best position for the i-th particle in the s-th swarm;
(called pbest) is the personal best position for the i-th particle in the s-th swarm;  (called sbest) is the best position in the s-th swarm and
(called sbest) is the best position in the s-th swarm and  (called gbest) is the global best position in the s-th warm;
(called gbest) is the global best position in the s-th warm;  (called osbest) is the best position of the k-th swarm, with which the i-th particle in the s-th swarm can communicate. r3 as well as r4 is a uniformly distributed random number in the range [0, 1] like r1 and r2, and the same to C3 and C4. All particles�� position is expressed as follows
(called osbest) is the best position of the k-th swarm, with which the i-th particle in the s-th swarm can communicate. r3 as well as r4 is a uniformly distributed random number in the range [0, 1] like r1 and r2, and the same to C3 and C4. All particles�� position is expressed as follows
 (18)
(18)
1) Update of the pbest for one particle. After updating the position and the velocity of one particle according to Eq. (18) and Eq. (16) or Eq. (17) at every iteration, the fitness function of this particle is evaluated according to Eqs. (8), (10) and (12). If the current value dominates the previous one, then the pbest is updated by current value. Conversely, it is changeless. If the current value and the previous position can not dominate with each other, the one with the minimum value of this swarm��s objective is selected as the new pbest. The update of the pbest for the i-th particle in the s-th swarm is expressed as follows:
 (19)
(19)
where 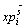 indicates the one with a minimum value of the s-th swarm��s objective
indicates the one with a minimum value of the s-th swarm��s objective
2) Update of the LEA and the sbest for one swarm. After updating position of each particle in one swarm, all particles in this swarm and in the LEA are assessed by three fitness functions and non-dominated solutions are added to the LEA via the Pareto dominance-based species technique. If the LEA is not full, all the non-dominated solutions are kept in the LEA. If the size exceeds the maximal capacity of LEA, the non- dominated solution with a maximal fitness of this swarm��s objective is deleted until the LEA is not full. Every solution in one LEA can not dominate any other particles stored in the same LEA. In the MSMOOA, the solutions in each LEA are sorted according to the objective function with this swarm at each iteration. Then the solution with minimum fitness of this objective is selected as new sbest for this swarm. The process of updating the LEA and the sbest for s-th swarm is depicted as follows.
for this swarm. The process of updating the LEA and the sbest for s-th swarm is depicted as follows.
Input: all particles after Eq.(8)
Output: undated LEA and sbest for all particles
1
Evaluate all particles in the s-th swarm and the s-th LEA according to Eqs. (8), (10) and (12)
2
Select all non-dominated solutions and add them to the s-th LEA
3
While ( the s-th LEA is full )
a) delete the non-dominated solution with a maximal fitness of the objective of the s-th swarm
4
End while
5
Sort solutions in the s-th LEA by the objective function with s-th swarm
6 Select solution with a minimum fitness of this objective as as new sbest for the s-th swarm
for the s-th swarm
3) Update of the osbest for the second class of particles. The second class of particles can communicate with different swarms through Intranet and get sbests of these swarms. For each particle in the second class, if one of these sbests dominates others, it is selected as osbest. Otherwise, the sbest with the minimum objective value of the swarm, which the particle belongs to, is selected as osbest.
4) Update of the GEA and gbest for all particles. GEA, which is the output of the MSMOOA, consists of solutions from all LEAs. After updating all LEAs, the solutions from these LEAs are added to GEA and dominated solutions are deleted. If the size of the archive exceeds the maximal capacity of GEA, it is truncated on the basis of the density of elements to keep high performance of output. The crowding distance [35] is adopted to estimate each element��s density. The higher crowding distance value signifies the better solution. So, the crowding distance of every solution in GEA is calculated at each iteration. Then, the binary tournament with these crowding distance values is done to update GEA. By this approach, the most distributed elements are retained in the archive.
After GEA updated, every solution does not dominate any other solutions in GEA. The selection of suitable gbest from the GEA for the particles in different swarms with different objectives becomes an important problem, for it will affect the solution searching ability and the convergence of the algorithm directly. In the MSMOOA, two external archives, LEA and GEA, are adopted to store non-dominated optimal solutions of one swarm and all swarms, respectively. For one swarm, LEA has stored the found non-dominated solutions with the objective of this swarm and sbest, which has a minimum fitness of this objective, is selected to guide the particles in this swarm at each iteration. So, the selection of gbest for the particles in different swarms should has priority on other objective.
In MSMOOA, all solutions in the GEA are sorting in multi queues according to the fitness of different objective at first. Then, for one swarm with a predefined objective, the solution in GEA with a minimum fitness of another objective is randomly selected as the gbest. The general step of unpdating the GEA and gbest is depicted in follows.
Input: all particles after undating LEA and sbest
Output: undated GEA and gbest for all particles
1
Add all solutions from LEA to GEA
2
Delete the dominated solutions from GEA
3
While ( the GEA is full )
a) Compute crowding distance of every solution in GEA
b) Update GEA by the binary tournament with these crowding distance values
4
End while
5
Sort the solutions into multi queues according to the fitness of different objective
6
For s=1 to S (S is the number of all swarms)
a) Select the solution with a minimum fitness of another objective as the gbest from GEA
7 End for
The general steps of the MSMOOA based workflow scheduling in cloud computing system are outlined as follows.
Input: DAG, the information of all available VMs in Manager server
Output: the set of non-dominated solutions for the DAG
1
For s=1 to S (S is the number of all PMs)
a) For i=1 to Snums (Snums is the size of particle swarm in the s-th swarm)
i) Select one objective as main function for the s-th swarm
ii) Determine velocity  and position
and position  randomly
randomly
iii) Initialize the pbest of the i-th particle in the s-th swarm 
b) End For
c) Update LEAs and sbest
2
End For
3
Select osbest for the second class of particles
4
Update GEA and gbest
5
For t=1 to T (T is the maximum number of iterations)
a) For s=1 to S (S is the number of all PMs)
i) For i=1 to Snums (Snums is the size of particle swarm in the s-th swarm)
1) Calculate the new velocity according to Eq. (16) or (17) and new position  according to Eq. (18)
according to Eq. (18)
2) Update the pbest  according to Eq. (19)
according to Eq. (19)
ii) End For
iii) Update LEAs and sbest
b) End For
c) Select osbest for the second class of particles
d) Update GEA and gbest
6
End For
7 Return the Pareto front (the set of non-dominated solutions from GEA)
By using the above method, each available PM concentrates its effort on looking for itself non- dominated optima through two classes of particles. Based on the non-dominated particles and Pareto optimal solutions of every PM, the GEA is able to evolve a diverse and well-distributed nearly optimal Pareto front. Thus, the proposed algorithm leads to cooperation search among the swarms to the multi-objective workflow scheduling in cloud computing system and can get a set of non-dominated scheduling strategies.
4 Performance evaluation
In this section, the overall setup of our experiment and the results obtained from it is described to validate the proposed MSMOOA. In our experiment, two well-known workflow applications, montage and epigenomics [36], are chosen as test cases. The Montage workflow, created by the NASA/IPAC Infrared Science Archive, is a hybrid workflow and can be used to generate custom mosaics of the sky using input images in the flexible image transport system format. The Epigenomics workflow, created by the USC Epigenome Center and the Pegasus Team, is a parallel workflow used to automate various operations in genome sequence processing. Figure 4 shows their simplified representations. DEELMAN et al [3] provided a detailed characterization for each workflow.

Fig. 4 Structure of evaluated workflows:
The WorkflowSim toolkit [37] has been chosen as a simulation platform, as it is a modern simulation framework aimed for workflow scheduling in cloud computing environments. The experiments have performed on 5 PMs and the available VMs are changed dynamically. The pricing models given by Amazon EC2 (http://aws.amazon.com/ec2) and Amazon CloudFront (http://aws.amazon.com/cloudfront/) are chosen as the processing costs and the transferring data costs, respectively. To estimate the energy consumption, we rely on the cube-root rule [21, 38] which approximates the clock frequency of a chip as the cube-root of its power consumption.
We evaluate the performance of the proposed MSMOOA on the workflow instances described previously and compare our results with those of another multi-objective workflow scheduling algorithm called MOHEFT [20] for cloud system. The quality of solutions computed by these algorithms is compared. Both MOHEFT and MSMOOA can offer a set of tradeoff solutions to users. In order to facilitate comparison, we take the single result from HEFT, one of widely-used heuristics for workflows scheduling in distributed heterogeneous computing systems, as the baseline to compare the gain over this baseline for the multiple scheduling objectives. As for the gain, the result with big value is better than the one with small value. We also compare the running time of each algorithm. The running time of an algorithm is its execution time for obtaining the output schedule of a given workflow.
As mentioned before, both MOHEFT and MSMOOA can offer a set of tradeoff solutions, so the experiments run MOHEFT and MSMOOA ten times, respectively, and compare the gain of makespan, cost and energy consumption over HEFT by the average result of MOHEFT and MSMOOA, respectively at first. Secondly, one solution from the results of MSMOOA and MOHEFT is selected, respectively. This solution is the closest one to the result of HEFT in the sense of Euclidean distance. Then, we consider the gain of makespan, cost and energy consumption over HEFT by the selected solution from MSMOOA and MOHEFT, respectively. At last, in order to compare the performance of MOHEFT and MSMOOA, we focus on the hypervolume indicator [39], a useful indicator to measure the quality of a set of tradeoff solutions.
The experiment results of Montage workflow are shown in Table 1 and Fig. 5. From Table 1, we can see that the MSMOOA gets the similar result with MOHEFT in makespan and both of them are better than HEFT. Moreover, the average gain about makespan of MSMOOA is better than MOHEFT for Montage_1000, while the average makespan of MOHEFT is better than
MSMOOA for the three other workflows. Although the performance of MOHEFT in makespan does not degrade compared to MSMOOA, MOHEFT is initialized with the solution computed by HEFT and MSMOOA is initialized with stochastic solution. So, the MSMOOA has better search ability. As for cost and energy consumption, the performance of MOHEFT and MSMOOA has significant improvement and the average gain by MSMOOA is better than that by MOHEFT in most cases. This is because HEFT is a single-objective scheduling algorithm and does not consider other objectives, such as cost and energy consumption, and MSMOOA designs the multi- objective workflow scheduling by integrating with the structure characteristics of cloud data center, while MOHEFT left out of consideration.
Table 1 Average gain over HEFT of Montage workflow


Fig. 5 Comparative analysis of Montage workflow:
Performance analysis of one selected solution from MOHEFT and MSMOOA is given in Fig. 5 for Montage workflow. This selected solution is the closest one to the result of HEFT in the sense of Euclidean distance and the gain of makespan, cost and energy consumption over HEFT by the selected solution of MOHEFT and MSMOOA is displayed on Figs. 5(a)-(c). MOHEFT and MSMOOA get the similar result to HEFT about makespan as shown in Fig. 5(a). As for cost and energy consumption, MSMOOA and MOHEFT get better performance than HEFT as shown in Figs. 5(b) and (c), and the improvement gets more and more obviously with the increase of the number of workflow tasks. In the case of Motage_25 (the number of tasks is 25), the gain over HEFT in cost is 13.30% and 15.21% for MOHEFT and MSMOOA, respectively and the gain over HEFT in energy consumption is 11.10% and 13.06%. When the number of tasks is 1000 (Montage_1000), the gain in cost is 17.40% and 21.20% respectively and the gain in energy consumption is 14.10% and 19.77%. We can also see that the performance of MSMOOA is better than MOHEFT as illustrated in Fig. 5(d). The explanation for this behavior is that multi-swarms are designed to find the solutions collaboratively in MSMOOA and each swarm corresponds to one objective of multi-objective in the workflow scheduling. At the same time, two classes of particles are designed to promote information sharing in these swarms and different strategy for updating LEA and GEA is adopted. So, the selected solution of MSMOOA is better than that of MOHEFT.
Furthermore, we also compare the running time used by MOHEFT, MSMOOA and MOPSO [32] for each Montage workflow and the results are presented in Fig. 6. The compared time of each algorithm is also the average result of the corresponding algorithm for ten times. The running times of all algorithms increase with the growing up of task number as shown in Fig. 6. It is also presented that the running times of MSMOOA and MOPSO are more than the results of MOHEFT. The reason for this phenomenon is that both MSMOOA and MOPSO are meta-heuristic methods and MOHEFT is a list scheduling algorithm based on HEFT. When considering the previously compared results, it is valuable to consume sustainable time for better scheduling result, especially about the cost and energy consumption. It is also indicate that the results of MSMOOA are better than those of MOPSO. This is due to a fact that the iterations of MSMOOA are less than MOPSO, although the used time for each iteration of MSMOOA is more than that of MOPSO.

Fig. 6 Average running time of algorithms about Montage workflow
As for epigenomics workflow, the results summarized in Fig. 7, Fig. 8 and Table 2 are similar to the previous experiment and confirm the findings of Montage workflow in terms of the compared metrics. The gain over HEFT in makespan, cost and energy consumption is shown in Figs. 7(a), (b) and (c), respectively. The hypervolume of MSMOOA and MOHEFT is indicated in Fig. 7(d). The comparison about running time is presented in Fig. 8.
5 Conclusions
1) A manager sever is adopted to avoid the influence from the elastic characteristic of cloud system to scheduling results and collect the information of available computational resources when the system accepts a workflows submitted from customers.
2) The proposed MSMOOA can find out better non- dominated solutions effectively, which has been proved by experiences.
3) Compared with HEFT and MOHEFT by simulating them with both hybrid and parallel workflow applications having different structures, the MSMOOA

Fig. 7 Comparative analysis of epigenomics workflow:

Fig. 8 Average running time of algorithms about epigenomics workflow
Table 2 Average gain over HEFT of epigenomics workflow
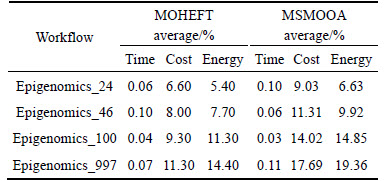
has better performance than HEFT and MOHEFT, not only in terms of the cost but also in terms of the energy consumption.
4) The MSMOOA can be only used for stable computing environment. In real world, the computing resources are not useful all the time. In future work, other objectives such as robust, reliability and security in addition to the objectives in this work should be considered.
References
[1] YU J, BUYYA R. Scheduling scientific workflow applications with deadline and budget constraints using genetic algorithms [J]. Scientific Programming, 2006, 14(3): 217-230.
[2] VISWANATHAN S, VEERAVALLI B, ROBERTAZZI T G. Resource-aware distributed scheduling strategies for large-scale computational cluster/grid systems [J]. IEEE Transactions on Parallel and Distributed Systems, 2007, 18(10): 1450-1461.
[3] DEELMAN E, VAHI K, JUVE G, RYNGE M, CALLAGHAN S, MAECHLING P, MAYANI R, CHEN W, SILVA R F, LIVNY M, WENGER K. PEGASUS, a workflow management system for science automation [J]. Future Generation Computer Systems, 2015, 46: 17-35.
[4] PINEDO M L. Scheduling: Theory, algorithms, and systems [M]. New York: Springer, 2012.
[5] TOPCUOGLU H, HARIRI S, WU M. Performance-effective and low-complexity task scheduling for heterogeneous computing [J]. IEEE Transactions on Parallel and Distributed Systems, 2002, 13(3): 260-274.
[6] BRAUN T D, SIEGEL H J, BECK N, B LNI L L, MAHESWARAN M, REUTHER A I, ROBERTSON J P, THEYS M D, YAO B, HENSGEN D FRUND R F. A comparison of eleven static heuristics for mapping a class of independent tasks onto heterogeneous distributed computing systems [J]. Journal of Parallel and Distributed computing, 2001, 61(6): 810-837.
LNI L L, MAHESWARAN M, REUTHER A I, ROBERTSON J P, THEYS M D, YAO B, HENSGEN D FRUND R F. A comparison of eleven static heuristics for mapping a class of independent tasks onto heterogeneous distributed computing systems [J]. Journal of Parallel and Distributed computing, 2001, 61(6): 810-837.
[7] CAO Jun-wei, HWANG K, LI Ke-qin, ZOMAYA A Y. Optimal multiserver configuration for profit maximization in cloud computing [J]. IEEE Transactions on Parallel and Distributed Systems, 2013, 24(6): 1087-1096.
[8] TSAI C, HUANG Wei-cheng, CHIANG M H, CHIANG M C, YANG Chu-sing. A hyper-heuristic scheduling algorithm for cloud [J]. IEEE Transactions on Cloud Computing, 2014, 2(2): 236-250
[9] LUO Jiang-ying, RAO Lei, LIU Xue. Temporal load balancing with service delay guarantees for data center energy cost optimization [J]. IEEE Transactions on Parallel and Distributed Systems, 2014, 25(3): 775-784.
[10] BUYYA R, YEO C S, VENUGOPAL S, BROBERG J, BRANDIC L. Cloud computing and emerging IT platforms: Vision, hype, and reality for delivering computing as the 5th utility [J]. Future Generation Computer Systems, 2009, 25(6): 599-616.
[11] FU Zhang-jie, REN Kui, SHU Jian-gang, SUN Xing-ming, HUANG Feng-xiao. Enabling personalized search over encrypted outsourced data with efficiency improvement [J]. IEEE Transactions on Parallel and Distributed Systems, 2016, 27(9): 2546-2559.
[12] XIA Zhi-hua, WANG Xin-hui, SUN Xing-ming, WANG Qian. A secure and dynamic multi-keyword ranked search scheme over encrypted cloud data [J]. IEEE Transactions on Parallel and Distributed Systems, 2015, 27(3): 340-352.
[13] FU Zhang-jie, SUN Xing-ming, LIU Qi, ZHOU Lu, SHU Jian-gang. Achieving efficient cloud search services: Multi-keyword ranked search over encrypted cloud data supporting parallel computing [J]. IEICE Transactions on Communications, 2015, E98-B(1): 190- 200.
[14] REN Yong-jun, SHEN Jian, WANG Jin, HAN Jin, LEE S Y. Mutual verifiable provable data auditing in public cloud storage [J] Journal of Internet Technology, 2015, 16(2): 317-323.
[15] GARG S K, BUYYA R, SIEGEL H J. Scheduling parallel applications on utility grids: Time and cost trade-off management [C]// The Thirty-Second Australasian Conference on Computer Science. Australian: Australian Computer Society Inc., 2009: 151-160.
[16] TENG S, HAY L L, PENG C E. Multi-objective ordinal optimization for simulation optimization problems [J]. Automatica, 2007, 43(11): 1884-1895.
[17] ZHAN Fan, CAO Jun-wei, LI Ke-qin, KHAN S U, HWANG K. Multi-objective scheduling of many tasks in cloud platforms [J]. Future Generation Computer Systems, 2014, 37: 309-320.
[18] TAO Fei, FENG Ying, ZHANG Lin, LIAO T W. CLPS-GA: A case library and Pareto solution-based hybrid genetic algorithm for energy-aware cloud service scheduling [J]. Applied Soft Computing, 2014, 19: 264-279.
[19] DURILLO J J, NAE V, PRODAN R. Multi-objective energy-efficient workflow scheduling using list-based heuristics [J]. Future Generation Computer Systems, 2014, 36: 221-236.
[20] DURILLO J J, PRODAN R. Multi-objective workflow scheduling in Amazon EC2 [J]. Cluster Computing, 2014, 17(2): 169-189.
[21] FARD H M, PRODAN R, FAHRINGER T. Multi-objective list scheduling of workflow applications in distributed computing infrastructures [J]. Journal of Parallel and Distributed Computing, 2014, 74(3): 2152-2165.
[22] YASSA S, CHELOUAH R, KADIMA H, GRANADO B. Multi-objective approach for energy-aware workflow scheduling in cloud computing environments [J]. The Scientific World Journal, 2013, doi: 10.1155/2013/350934.
[23] CHENG Ji-xiang, ZHANG Ge-xiang, LI Zhi-dan, LI Yuan-quan. Multi-objective ant colony optimization based on decomposition for bi-objective traveling salesman problems[J]. Soft Computing, 2012, 16(4): 597-614.
[24]  J, GIL C,
J, GIL C,  AL, MONTOYA F G, MONTOYA M G. A Pareto-based multi-objective evolutionary algorithm for automatic rule generation in network intrusion detection systems [J]. Soft Computing, 2013, 17(2): 255-263.
AL, MONTOYA F G, MONTOYA M G. A Pareto-based multi-objective evolutionary algorithm for automatic rule generation in network intrusion detection systems [J]. Soft Computing, 2013, 17(2): 255-263.
[25] KENNEDY J, EBERHART R C. Particle swarm optimization [C]// The 1995 IEEE International Conference on Neural Network. Perth: IEEE, 1995: 1942-1948.
[26] COELLO C C A. Evolutionary multi-objective optimization: A historical view of the field [J]. IEEE Computational Intelligence Magazine, 2006, 1(1): 28-36.
[27] GAO Lei, HAILU A. Comprehensive learning particle swarm optimizer for constrained mixed-variable optimization problems [J]. International Journal of Computational Intelligence Systems, 2010, 3(6): 832-842.
[28] HU Yi-fan, DING Yong-sheng, HAO Kuang-rong, REN Li-hong, HAN Hua. An immune orthogonal learning particle swarm optimization algorithm for routing recovery of wireless sensor networks with mobile sink [J]. International Journal of Systems Science, 2014, 45(3): 337-350.
[29] HU Yi-fan, DING Yong-sheng, REN Li-hong, HAO Kuang-rong, HAN Hua. An endocrine cooperative particle swarm optimization algorithm for routing recovery of wireless sensor networks with multiple mobile sinks [J]. Information Sciences, 2015, 300: 100-113.
[30] COELLO C A C, PULIDO G T, LECHUGA M S. Handling multiple objectives with particle swarm optimization [J]. IEEE Transactions on Evolutionary Computation, 2004, 8(3): 256-279.
[31] LIU Da-sheng, TAN K C, GOH C K, HO W K. A multiobjective memetic algorithm based on particle swarm optimization [J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 2007, 37(1): 42-50.
[32] GAO Hong-yuan, CAO Jin-long. Non-dominated sorting quantum particle swarm optimization and its application in cognitive radio spectrum allocation [J]. Journal of Central South University, 2013, 20(7): 1878-1888.
[33] YEN G G, DANESHYARI M. Diversity-based information exchange among multiple swarms in particle swarm optimization [J]. International Journal of Computational Intelligence and Applications, 2008, 7(1): 57-75.
[34] PARSOPOULOS K E, TASOULIS D K, VRAHATIS M N. Multiobjective optimization using parallel vector evaluated particle swarm optimization [C]// The IASTED International Conference on Artificial Intelligence and Applications. America: IEEE, 2004, 2: 823-828.
[35] DEB K, PRATAP A, AGARWAL S, MEYARIVAN T. A fast and elitist multiobjective genetic algorithm: NSGA-II [J]. IEEE Transactions on Evolutionary Computation, 2002, 6(2): 182-197.
[36] JUVE G, CHERVENAK A, DEELMAN E, BHARATHI S, MEHTA G, VAHI K. Characterizing and profiling scientific workflows [J]. Future Generation Computer Systems, 2013, 29(3): 682-692.
[37] CHEN Wei-wei, DEELMAN E. Workflowsim: A toolkit for simulating scientific workflows in distributed environments [C]// IEEE 8th International Conference on E-Science (e-Science). Chicago: IEEE , 2012: 1-8.
[38] BROOKS D M, BOSE P, SCHUSTER S E, JACOBSON H, KUDVA P N, BUYUKTOSUNOGLU A, WELLMAN J, ZUUBAN V, GUPTA M, COOK P W. Power-aware microarchitecture: Design and modeling challenges for next-generation microprocessors [J]. IEEE Micro, 2000, 20(6): 26-44.
[39] ZITZLER E, THIELE L, LAUMANNS M, FONSECA C M, FONSECA V G. Performance assessment of multiobjective optimizers: An analysis and review [J]. IEEE Transactions on Evolutionary Computation, 2003, 7(2): 117-132.
(Edited by YANG Hua)
Cite this article as: YAO Guang-shun, DING Yong-sheng, HAO Kuang-rong. Multi-objective workflow scheduling in cloud system based on cooperative multi-swarm optimization algorithm [J]. Journal of Central South University, 2017, 24(5): 1050-1062. DOI: 10.1007/s11771-017-3508-7.
Foundation item: Project(61473078) supported by the National Natural Science Foundation of China; Project(2015-2019) supported by the Program for Changjiang Scholars from the Ministry of Education, China; Project(16510711100) supported by International Collaborative Project of the Shanghai Committee of Science and Technology, China; Project(KJ2017A418) supported by Anhui University Science Research, China
Received date: 2015-06-17; Accepted date: 2016-09-30
Corresponding author: DING Yong-sheng, Professor, PhD; Tel: +86-21-67792323; E-mail: ysding@dhu.edu.cn

