
J. Cent. South Univ. Technol. (2008) 15: 392-398
DOI: 10.1007/s11771-008-0074-z
![]()
Hash-area-based data dissemination protocol in wireless sensor networks
WANG Tian(�� ��)1, 2, WANG Guo-jun(������)1, GUO Min-yi(������)3, JIA Wei-jia(����)2
(1. School of Information Science and Engineering, Central South University, Changsha 410083, China;
2. Department of Computer Science, City University of Hong Kong, Hong Kong, China;
3. Department of Computer Science and Engineering, Shanghai Jiaotong University, Shanghai 200030, China)
Abstract:
HashQuery, a Hash-area-based data dissemination protocol, was designed in wireless sensor networks. Using a Hash function which uses time as the key, both mobile sinks and sensors can determine the same Hash area. The sensors can send the information about the events that they monitor to the Hash area and the mobile sinks need only to query that area instead of flooding among the whole network, and thus much energy can be saved. In addition, the location of the Hash area changes over time so as to balance the energy consumption in the whole network. Theoretical analysis shows that the proposed protocol can be energy-efficient and simulation studies further show that when there are 5 sources and 5 sinks in the network, it can save at least 50% energy compared with the existing two-tier data dissemination(TTDD) protocol, especially in large-scale wireless sensor networks.
Key words:
wireless sensor networks; Hash function; data dissemination; query processing; mobile sinks��
1 Introduction
Recent advances in MEMS(micro electro- mechanical system)-based sensor technology, embedded computing, and low-power wireless communications have enabled the development of sensor networks[1-3], which can be used in a wide range of applications such as military surveillance, industry control, traffic control and ambient conditions detection[4-6].
In recent years, the advances in mobile robots[7-8] have enabled possibility of mobile sinks and the sink mobility has brought new challenges to wireless sensor networks. When the sink moves, how to efficiently find the data it needs and how to forward the data is a hot research topic. A simple approach is that the sinks query the network and then those sensors that have sensed the events respond. But this approach needs to query the whole network, resulting in both rapid energy consumption of sensor nodes and increased collisions in wireless transmissions. The same problem arises in the routing process when sinks move. To address this problem a local location update routing protocol in Ref.[9] was proposed. To address the query problem, LUO et al [10] proposed two-tier data dissemination (TTDD), which is a two-tier data dissemination approach that provides scalable and efficient data delivery to multiple mobile sinks. Each data source in TTDD firstly builds a grid structure which enables mobile sinks to continuously receive data on the move by flooding queries within a local cell only. TTDD does not need to flood the whole network, so it can save energy to some extent, but it needs to build a grid structure for every source which still consumes too much energy, especially when the number of sources is large.
In this work, HashQuery, a Hash-area-based data dissemination protocol in wireless sensor networks was proposed. With this protocol, the mobile sinks need only to query a small area instead of flooding among the whole network, and thus much energy can be saved. Although SYLVIA et al[11] also used the Hash function, they mainly emphasized how to backup and rebuild the data while how to get the data, in an energy-efficient way when the sink moves was focused here.
2 Protocol descriptions
2.1 Assumptions
The proposed HashQuery protocol has the same assumptions as the protocol in Ref.[10].
1) Sensor nodes know the location information of their one-hop neighbors and the location of themselves by some localization algorithms[12].
2) The whole network is time synchronized, which can be implemented by certain synchronization algorithm[13].
2.2 HashQuery protocol design
The basic idea of HashQuery protocol is as follows: mobile sinks and sensor nodes first determine a ��query area�� in the network through a Hash function using time as the key. The sensor node which captures the event happened sends the description of the event to this area, while the sink does not need to query the data from the whole network, instead it queries within this ��query area��. And the Hash function uses time as a key, which makes the query area change its location over time. By doing so, energy consumption can be balanced in the network, and extra communication between mobile sinks and sensor nodes is not needed. More specifically, the protocol can be divided into 5 stages: initialization stage, Hash point establishment stage, event information dissemination stage, query stage, and data forwarding stage.
2.2.1 Initialization stage
Both sinks and sensors know the same Hash function before the network is deployed. The sensor nodes can obtain the geographic location by certain localization algorithm. Because all the sensor nodes are static, the localization algorithm needs to be run only once when the network is initialized.
2.2.2 Hash point establishment stage
Hash point is a two-dimensional coordinate and is the key factor for determining the query area. It is calculated by the Hash function using the current time t as its key. There are many methods to choose a Hash function. Suppose that there exists a Hash function like this:
f(Time t)��Coordinate of area center (X, Y)
Through this Hash function, during a period of time T1, one two-dimensional location (X1, Y1) can be calculated if the current time t is put into the function as its independent variable. In the same way, during the next period of time T2, the other two-dimensional location (X2, Y2) can be calculated if the time t is put into the function as its independent variable. In the long run, the Hash points calculated from this Hash function are distributed evenly in the whole network.
2.2.3 Event information dissemination stage
When a sensor node senses some data for a certain event, it will send the description of the event to all the nodes within the query area using greedy perimeter stateless routing(GPSR)[14], which is a well-known geographic routing protocol. If the sensor nodes are distributed evenly in the network, the query area can be expressed simply as the circular area with the Hash point as its center and R as its radius. But if there are holes in the network and the Hash point is located in one of the holes, the Hash point will not be the area with the Hash point as its center, since there aren��t any nodes in that area. In this case, HashQuery exploits the characteristics of GPSR, i.e. once a destination point is given in the network, GPSR can eventually send the data to the nearest node close to that point. As shown in Fig.1, in the greedy mode, node x sends the data to node A. Because node A cannot find the closer node to node D than itself, GPSR then takes the mode of right-hand forwarding. In that mode, data packets are transferred around the area containing node D, and go back to node A at last. Then node A recognizes that itself is the closest node to the destination node. The closest node to the Hash point is defined as the query node. After the query node obtains the information of the source node, it broadcasts the information within the area called query area, which is centered as the query node, with R as its radius.
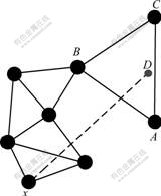
Fig.1 Schematic diagram of determination of query point
2.2.4 Query stage
When the sink needs the data, it first calculates the current location of the Hash point using the same method by sensor nodes, and then sends the query packet to the query node by GPSR. Finally, the query packet floods in the query area. In fact, the sink just needs to send the packet to the query node. The reason for setting a query area is for backup and load balance purposes.
If some node in the query area contains the description of the event required by the sink, it will send query packet to the source node that captures the event by GPSR.
2.2.5 Data forwarding stage
After the query packet reaches the data source, the sensor node sends the data to the sink by GPSR. Because the sink is mobile, HashQuery needs to set a ��proxy sensor�� for the sink in order to keep the communications. That is, the data packet first reaches proxy sensor, and then sends to the sink. When the distance between the agent and the sink extends certain hops, the sink will choose a new proxy sensor. More information on proxy sensor is given in the next section.
As shown in Fig.2, node A detects a certain event happened and sends the event description to the query area determined by the Hash function. Once sink 1 wants to query the event information, it selects a proxy sensor in the neighboring area, and sends a query packet to the Hash area, which contains both the query information required by sink 1 and the geographic location information of the proxy sensor. When the query packet reaches the query area, it finds that node A has the data required by the sink, so the query packet is sent to node A. Then node A sends back the event data to the proxy sensor by GPSR and eventually the event data is sent to the sink from the proxy sensor.
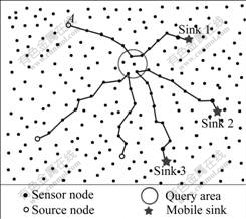
Fig.2 Schematic diagram of HashQuery protocal
2.3 Selection of proxy sensor
Before the sink sends the query packet to the query area, it chooses one of its neighbors as the proxy sensor according to certain rules. Then the sink sends the query data packet to the proxy sensor. After that, all the communications of the sink are delegated to this proxy sensor. When the sink moves, it may not be able to communicate with the proxy sensor. In order to solve this problem, the sink records all the nodes in its moving path, and each of the nodes only records its prior sensor and the next sensor in the path. As shown in Fig.3, the sink chooses node A as its proxy sensor. When it moves out of the communication range of node A, it will choose node B from the neighboring nodes to transfer the data, which can communicate with node A. In the same way, the sink will choose node C in order to keep the communications with A when it cannot reach node B. A max hop number Mhop is set to avoid that the path from proxy sensor to the sink is too long. When the hop number exceeds Mhop between the sink and the proxy sensor, the sink will choose a new proxy sensor, and send the geographic location information of the new one to the source node, by which a new path is built between the source node and the new proxy sensor.
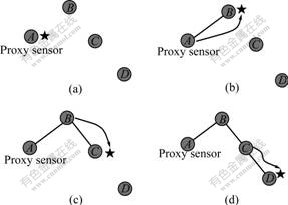
Fig.3 Schematic diagrams of proxy sensor: (a) Beginning to select the proxy sensor; (b) Sink moving to node B; (c) Sink moving to node C; (d) Sink moving to node D
2.4 Query fusion
Query fusion refers to the fusion of query packets. Because there are multiple sinks, there may exist redundant information in the query packets. In the HashQuery protocol, all the query packets are forwarded to the query area, so query fusion can be done in the query area to get rid of the redundant query information. After that, the query packets are sent to the data source. When the number of query packets is large, the amount of communications can be reduced effectively through query fusion and the energy consumption can be reduced as well.
2.5 Setting of query area
Theoretically, the sensor node only needs to send the event information to the query point, and the sink only needs to query the event information from the query point. The reasons for setting a query area other than querying a single sensor node are as follows: 1) since the memory capacity of a single sensor node is limited and unstable, multiple nodes in the query area can be used to backup the information, which can avoid missing the query information due to malfunction of a single node; 2) if the data description packets produced by the data source and the data query packets of the sink are all sent to the query area by geographic routing, it is apparent that the query area is more easier to be found than a single node. The bound of the query area is an adaptive parameter. The larger the query area is, the more reliable the data forwarding and the storage of the event description are. But as the area increases, the cost to maintain it increases too.
It is supposed that all the nodes in the query area store the same event description, which is similar to TTDD algorithm. The difference is that the nodes store the information in TTDD are distributed in the grid network, while in HashQuery they are the ones in the query area. If there are too many data sources, the amount of information is too much to be stored by a single node. But HashQuery can use the nodes in the area to store the information cooperatively as a distributed database does, which is difficult to be implemented by TTDD because each grid has to do so, which brings too much cost.
3 Performance analysis
3.1 Model
It is supposed that a squared sensing field whose side length is L and in which N sensor nodes are randomly distributed and the sensors send their sensed data to the sink. It is assumed that there are k mobile sinks in the field and the sizes of query packet and event packet are the same, denoted by m. The size of data packet is denoted by d. Assume that the communication overhead to flood in an area is directly proportional to the number of sensor nodes in the area and the communication overhead along a route is directly proportional to the number of sensor nodes in that route.
3.2 Cost analysis
With the proposed protocol, source node S firstly sends the event description packet to the query area, so the cost ��1 is
![]() (1)
(1)
where ![]() is the average number of the nodes in the route from node S to the query area (0��c��
is the average number of the nodes in the route from node S to the query area (0��c��![]() . As there are n1 nodes in the query area, the cost when the source node sends its event description packet to the query area is
. As there are n1 nodes in the query area, the cost when the source node sends its event description packet to the query area is
��2=n1m (2)
Similar to it, the cost when the sink finds the data is
![]() (3)
(3)
The query packet is firstly sent to the query area, then it is delivered from that area to the source node, which is why factor 2 is multiplied in formula (3). For easy analysis, the query fusion is not taken into account here. Otherwise the cost calculated should be even smaller than the current one. The cost for the data packet sent from the source to the sink is
![]() (4)
(4)
For k mobile sinks, the total cost for HashQuery is
![]() (5)
(5)
In TTDD, to find the data source, the sink has to flood in the grid which belongs to, the cost is
��5=n2m (6)
where n2 is the number of the nodes in the grid. The cost for the query packet to get to the source is
![]() (7)
(7)
Because a packet in TTDD traverses a grid instead of straight-line path, the path length is increased by a factor of ![]() The cost for the data packet sent from the source to the sink is
The cost for the data packet sent from the source to the sink is
![]() (8)
(8)
For k mobile sinks, by taking the cost in constructing the grid (![]() [10]) into account, the total cost for TTDD is
[10]) into account, the total cost for TTDD is
![]()
(9)
Comparing the total cost of HashQuery with that of TTDD
 (10)
(10)
As n1 and n2 are both much smaller than N, it can be seen clearly from Eqn.(10) that the numerator is smaller than the denominator. To give a simple illustration, assume n1=n2=10, m=1, d=100, c=1, Eqn.(10) can be denoted by
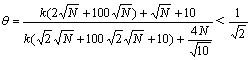 (11)
(11)
Table 1 lists the energy consumption of HashQuery and TTDD when the size of the network and the number of mobile sinks vary. In Table 1 HashQuery is much better than TTDD, particularly in large-scale network. And the difference between them becomes smaller with the increase of the number of mobile sinks. This can be explained that in TTDD the source node should flood in the whole network, so the more the sinks, the less
Table 1 Energy consumption comparison (��)
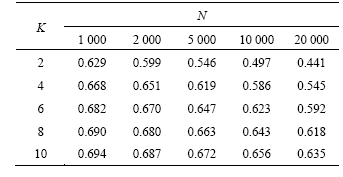
the energy consumption. But the ratio between them will not exceed 1/![]() ��0.707.
��0.707.
3.3 Storage complexity
In HashQuery, only the nodes in the query area need to maintain the event description and the number of these nodes is n1. While in TTDD, there is at least one node that needs to maintain the event information in every grid, and the number of these nodes is at least (![]() +1)2. The ratio of the number of nodes in HashQuery to that in TTDD is
+1)2. The ratio of the number of nodes in HashQuery to that in TTDD is
![]() ��
��![]() (12)
(12)
As n1 and n2 are both much less than N, then n1n2/N is much less than 1. Table 2 lists numerical results from formula (12) when n1=n2=30. It can be seen clearly that HashQuery has lower complexity, especially in large-scale network.
Table 2 Storage complexity comparison
![]()
4 Simulation studies
4.1 Simulation scenario
The performances of HashQuery and TTDD are compared by programming in C++. The scenario is in a square area with the side length of L and N sensor nodes placed inside randomly. There are several mobile sinks moving in such area to get data through querying first. The mobility model is like this: the sink randomly selects one sensor as its target and moves towards that sensor at fixed velocity, and after the sink reaches the sensor it selects a new sensor as its target and repeats the above process. The length of the side of TTDD area is 120 m, and the Hash area is a circle area with radius of 50 m and Mhop of 3. The energy consumption of communications among nodes follows the First Order Radio energy model[15]. Other parameters can be seen in Table 3.
Table 3 Parameter values of simulation

4.2 Simulation results
Fig.4 shows the comparison of energy consumption between HashQuery and TTDD when there are 5 mobile sinks in a 720 m![]() 720 m network. Fig.4(a) demonstrates the comparison of energy consumption of the whole network. It can be seen that along with the increase of the number of data sources, both the energy consumptions applying HashQuery and TTDD tend to increase. Moreover, this tendency approaches linearly. However, TTDD obviously consumes more energy than HashQuery. And this difference becomes more apparent as the number of data sources increases. This result accords with our analysis that TTDD in which every data source must maintain a grid is not suitable for applications with multiple data sources. This can also be seen in Fig.4(b), which demonstrates the ratio of energy consumption of HashQuery to TTDD when only the energy consumption of sinks querying data is taken into account under the condition of neglecting the cost of routing. It can be seen that this ratio is close to 0.35, indicating that the energy needed for querying data in HashQuery is much less than that in TTDD.
720 m network. Fig.4(a) demonstrates the comparison of energy consumption of the whole network. It can be seen that along with the increase of the number of data sources, both the energy consumptions applying HashQuery and TTDD tend to increase. Moreover, this tendency approaches linearly. However, TTDD obviously consumes more energy than HashQuery. And this difference becomes more apparent as the number of data sources increases. This result accords with our analysis that TTDD in which every data source must maintain a grid is not suitable for applications with multiple data sources. This can also be seen in Fig.4(b), which demonstrates the ratio of energy consumption of HashQuery to TTDD when only the energy consumption of sinks querying data is taken into account under the condition of neglecting the cost of routing. It can be seen that this ratio is close to 0.35, indicating that the energy needed for querying data in HashQuery is much less than that in TTDD.
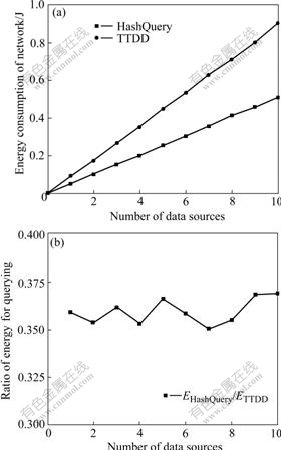
Fig.4 Energy consumption vs number of data sources: (a) Energy consumption of whole network; (b) Energy comparison for querying
Fig.5 shows the comparison of energy consumption between HashQuery and TTDD when there are 5 data sources in a 720 m![]() 720 m network. As shown in Fig.5(a), when there is only one sink, the energy consumption of the total network applying TTDD is more than twice of HashQuery. When the number of sinks increases, energy consumption of HashQuery increases approximately in a linear style, while in TTDD, although the energy consumption increases too, and the slope tends to decrease. Fig.5(b) shows the ratio of energy consumption of HashQuery to TTDD when only the energy consumption of the sinks querying data is considered. At the beginning, HashQuery is much better than TTDD, but as the number of sinks increases the difference between them tends to become small. And if the number of sinks is large enough, energy consumption of TTDD can even be less than that of HashQuery because all the sinks can share one grid maintained by the data source. Therefore, more energy can be saved as there are more sinks. In that case, the differences between the two patterns are mainly in routing, which is consistent with the analysis in Section 3.
720 m network. As shown in Fig.5(a), when there is only one sink, the energy consumption of the total network applying TTDD is more than twice of HashQuery. When the number of sinks increases, energy consumption of HashQuery increases approximately in a linear style, while in TTDD, although the energy consumption increases too, and the slope tends to decrease. Fig.5(b) shows the ratio of energy consumption of HashQuery to TTDD when only the energy consumption of the sinks querying data is considered. At the beginning, HashQuery is much better than TTDD, but as the number of sinks increases the difference between them tends to become small. And if the number of sinks is large enough, energy consumption of TTDD can even be less than that of HashQuery because all the sinks can share one grid maintained by the data source. Therefore, more energy can be saved as there are more sinks. In that case, the differences between the two patterns are mainly in routing, which is consistent with the analysis in Section 3.
Fig.6 shows the comparison of energy consumption between HashQuery and TTDD using 5 data sources and
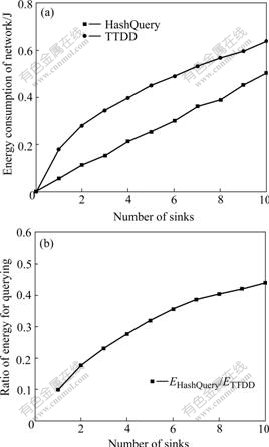
Fig.5 Energy consumption number of sinks: (a) Energy consumption of whole network; (b) Energy comparison for querying
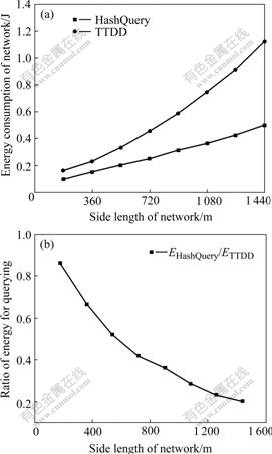
Fig.6 Energy consumption vs size of network: (a) Energy consumption of whole network; (b) Energy comparison for querying
5 mobile sinks as the network scales. As shown in Fig.6(a), both the energy consumptions applying HashQuery and TTDD tend to increase. This is because as the network scales, the distance between a node and a sink also increases. And averagely more energy will be consumed for sending the packets to the sink. If the scale is relatively small, there will be little difference between the two. Nonetheless, TTDD will consume increasingly more energy as the network scales. The reason is that as the network scales, the size of grid maintained by each data source must be enlarged, and this size varies directly with the square of the side length of the network. This can be further indicated from Fig.6(b), which shows as the network becomes larger, HashQuery will consume less energy than TTDD on querying data. This ratio can even drop to 0.2 in 1 440 m![]() 1 440 m network. Therefore, HashQuery is much superior to TTDD in large-scale network.
1 440 m network. Therefore, HashQuery is much superior to TTDD in large-scale network.
5 Conclusions
1) To find the data efficiently in the network, the proposed HashQuery protocol assumes the mobile sinks and sensors share a Hash function in advance. A Hash area can be determined through the Hash function. Data source sends description of the event to the Hash area, and the sink can then send query packets to the Hash area to fetch the needed data even when the sink moves.
2) Theoretical analysis shows that the proposed protocol can be energy efficient and simulation studies further show that when there are 5 sources and 5 sinks in the network, it can save at least 50% energy compared with the existing TTDD protocol. So the proposed protocol provides a viable solution to be used in large-scale wireless sensor network with mobile sinks.
References
[1] REN Feng-yuan, HUANG Hai-ning, LIN Chuang. Wireless sensor networks [J]. Journal of Software, 2003, 14(2): 1148-1157. (in Chinese)
[2] LI Jian-zhong, LI Jin-bao, SHI Sheng-fei. Concepts, issues and advance of sensor networks and data management of sensor networks [J]. Journal of Software, 2003, 14(10): 1717-1727. (in Chinese)
[3] CUI Li, JU Hai-lin, MIAO Yong, LI Tian-pu, LIU Wei, ZHAO Ze. Overview of wireless sensor networks [J]. Journal of Computer Research and Development, 2005, 42(1): 163-174. (in Chinese)
[4] WANG Guo-jun, WANG Huan, CAO Jian-nong, GUO Min-yi. Energy-efficient dual prediction-based data gathering for environmental monitoring applications [C]// Proc IEEE WCNC 2007. New York: IEEE Communication Society Press, 2007: 3516-3521.
[5] JIA Wei-jia, WANG Tian, WANG Guo-jun, GUO Min-yi. Hole avoiding in advance routing in wireless sensor networks [C]// Proc IEEE WCNC 2007. New York: IEEE Communication Society Press, 2007: 3522-3526.
[6] WANG Guo-jun, CAO Jian-nong, WANG Huan, GUO Min-yi. Polynomial regression for data gathering in environmental monitoring applications [C]// Proc IEEE GLOBECOM 2007, New York: IEEE Communication Society Press, USA, 2007: 1307-1311.
[7] CAI Zi-xing, DUAN Zhuo-hua, ZHANG Hui-tuan, YU Jin-xia. Identification of abnormal movement state and avoidance strategy for mobile robots [J]. Journal of Central South University of Technology, 2006, 13(6): 683-688.
[8] DUAN Zhuo-hua, FU Ming, CAI Zi-xing, YU Jin-xia. An adaptive particle filter for mobile robot fault diagnosis [J]. Journal of Central South University of Technology, 2006, 13(6): 689-693.
[9] WANG Guo-jun, WANG Tian, JIA Wei-jia, GUO Min-yi, CHEN H, GUIZANI M. Local update based routing protocol in wireless sensor networks with mobile sinks [C]// Proc IEEE ICC 2007. New York: IEEE Communication Society Press, 2007: 3094-3099.
[10] LUO Hai-yun, YE Fan, CHENG Jerry, LU Song-wu, ZHANG Li-xia. TTDD: Two-tier data dissemination in large-scale wireless sensor networks [J]. Wireless Networks, 2005, 11(1/2): 161-175.
[11] SYLVIA R, BRAD K, SCOTT S, DEBORAH E, RAMESH G, LI Y, FANG Y. Data-centric storage in sensornets with GHT, A geographic hash table [J]. Mobile Networks and Applications, 2003, 8(4): 427-442.
[12] NICULESCU D. Positioning in ad hoc sensor networks [J]. IEEE Network, 2004, 18(4): 24-29.
[13] GAO Q, BLOW K J, HOLDING D J. Simple algorithm for improving time synchronization in wireless sensor networks [J]. Electronics Letters, 2004, 40(14): 889-891.
[14] KARP B, KUNG H T. GPSR: Greedy perimeter stateless routing for wireless networks [C]// Proc the Sixth Annual ACM/IEEE Internation Conference on Mobile Computing and Networking (Mobicom 2000), ACM. New York: ACM Press, 2000: 243-254.
[15] HEINZELMAN W, CHANDRAKASAN A, BALAKRISHNAN H. Energy-efficient communication protocol for wireless sensor networks [C]// Proc Hawaii International Conference System Sciences. Hawaii: IEEE Computer Society Press, 2000: 1-10.
(Edited by CHEN Wei-ping)
Foundation item: Project(07JJ1010) supported by Hunan Provincial Natural Science Foundation of China; Projects(2006AA01Z202, 2006AA01Z199) supported by the National High-Tech Research and Development Program of China; Project(7002102) supported by the City University of Hong Kong, Strategic Research Grant (SRG); Project(IRT-0661) supported by the Program for Changjiang Scholars and Innovative Research Team in University; Project(NCET-06-0686) supported by the Program for New Century Excellent Talents in University
Received date: 2007-09-18; Accepted date: 2007-10-23
Corresponding author: WANG Guo-jun, Professor, PhD; Tel/Fax: +86-731-8877711; E-mail: csgjwang@mail.csu.edu.cn
