

DOI�� 10.11817/j.issn.1672-7207.2021.02.012
���ڸĽ�EM�㷨�Ļ������ó���������
����η1���Ƴ���1�������1������ǰ1, 2
(1. ���ϴ�ѧ �Զ���ѧԺ������ ��ɳ��410083��
2. ����ʡ��ǿ�Ƚ��̼��������칤�̼����о����ģ����� ���£�415701)
ժ Ҫ��
Զ�̼���д�������ȱʧ�����⣬���һ�ֻ��������������㷨��ȱʧ���������㷨��ͨ���������Ʒ������ؿ��巽��(MCMC)������������ϸĽ��������(EM)�㷨�����ȣ����������У���MCMC�����в�������ȱʧֵ��������ֵ��������������ģ���Ը��¹���ֵ��Ȼ��������У�ͨ�����������õ������ֵ��Ϊ�ع�ֵ�����ȱʧ���ݡ�����Ի������ó�ʵ���������ݶԱ���������㷨����ֵ��䷨��EM�㷨��ȱʧ�������Ч�����бȽϡ��о���������������㷨��Ч�ؽ����EM�㷨������ʼֵ�趨�����⣬�������������ȷ�ʡ�
�ؼ��ʣ�
����ȱʧ������������Ľ�EM�㷨������������
��ͼ����ţ�TP311 ���ױ�־�룺A OSID��
���±�ţ�1672-7207��2021��02-0443-07
An improved expectation maximization algorithm for missing data management of concrete pump truck
DENG��Ziwei1, TANG��Zhaohui1, ZHU��Hongqiu1, ZHAO��Yuqian1, 2
(1. School of Automation, Central South University, Changsha 410083, China;
2. Hunan Engineering Research Center of High Strength Fastener Intelligent Manufacturing,Changde 415701, China)
Abstract: To solve the recovery problem of data missing in remote monitoring of concrete pump truck, an improved EM missing data filling model based on the stochastic process was proposed, which combines the Markov Chain Monte Carlo(MCMC) and random variables to improve the EM algorithm. Firstly, in the expectation steps, the missing values were sampled in the MCMC matrix, and were applied in the stochastic approximation to update the estimation. Secondly, the maximization steps in EM algorithm were applied iteratively to find the most possible estimated value as the reconstruction value. Finally, compared with the mean filling method and EM algorithm, the proposed method was verified by using the remote monitoring data of pump truck data. The results show that the improved EM algorithm effectively reduces the dependence on the initial setting value and improves the accuracy of data filling.
Key words: data missing; stochastic process; improved EM algorithm; data recovery algorithm
����������������������Ϣ�����ķ�չ���ڹ�ҵ�����л����˴��������ݣ����������Щ��ҵ�����ݶ��ƶ������������ܻ�������Ҫ����[1-6]��Ȼ��������ʵ��Ӧ���вɼ��Ĵ������в��ɱ���ش���ȱʧֵ������Ӱ���˴����ݷ�������ģЧ������ˣ���ȱʧ���ݽ�����������ȷ�ؽ�������ģ����Ϊ��Ҫ���Ի������ó�Ϊ���������й����вɼ����������������ݲɼ������д������쳣�Լ����ݴ�����������ݶ�ʧ��Ӱ�죬������ݲ��걸���⣬Ӱ����Զ�̼�ء��������������Լ��������ݵĹ�����ϵ�Ӧ��Ч�������һ������ó�������ͨ��ȱʧ����ƫ��һ���������ݵ�Ӧ�ô����˼������ѣ���ˣ��о�ȱʧ���ݵ���䷽����Ϊ��Ҫ[7]��ȱʧ���ݻָ������ݷ����о���һ���ȵ����⣬Ҳ�ǻ������ݵķ������������Ļ�����Ŀǰ�����Ƕ��й�ȱʧֵ�������������˴����о�����Բ�ͬ��Ӧ�ó����������һϵ�н������[8-9]����λ��/����/��ֵ�岹�������ڷֲ�ģ�͵�ȱʧ���ݲ岹����[10]����Ҷ˹�����ʱ�����з���[11]�������ɵ�[12]��SNM�㷨���������ظ���¼���ݵ���ϴ�����Ե�[11]�ڻ������ر�Ҷ˹����ѵ����ʼ���ݼ��Ļ����ϣ���ÿ������ȱʧ�ı���������Ӧ�ĵ�����Ԥ�����ģ�������ȱʧֵ��BATISTA��[13]��KNN���������ڶ�ʧ���ݵ���䡣��������[14]������С����֧���������ֱ���ж������͵�������������������IJ���ȣ����һ�������ֵ�������������[15]��Ը�����ҵ����ú���ķ����������������ݳ��ֵ�ȱʧ�����ͨ���������ƹ�������Դ�������ݵ�������ԣ����һ�ֻ������Ȩ��Ϣϵ����ұ����ҵ����ú��ϵͳ�����������������ޱ��[16]�������ر�Ҷ˹ģ�Ľ���EMȱʧ��������㷨������������Ի������ó��������ص㣬�ڷ���EM�㷨�Ļ������о�ȱʧ���ݵ�����㷨�����һ�ֻ���������̸Ľ���EMȱʧ��������㷨��ʹ�����Ч�������ȱʧ���ݡ����������㷨Ӧ���ڻ������ó�ʵ������������䣬�����ֵ��䷨�ͻ���ԭʼEM�㷨��ȱʧ���������бȽϣ���֤���������㷨����Ч�ԡ�
1 EM��������㷨����Ľ�
EM�㷨��һ��Ӧ�ýϹ㷺��ȱʧ��������㷨��ͨ������Ѱ�����ݷֲ�����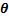
1.1����ͳEM�㷨
������ͳ���У������Ȼ����(the maximum likelihood estimation��MLE)���к��������ײ����Ե��ص㣬�������ڸ����������ݹ�������ֲ���ij����ij�����ؼ��������Ӷ��ﵽͨ�������������������ݵ�Ŀ��[17]��MLE��һ�ַdz���Ч�IJ������Ʒ�����������������ȱʧֵʱ����ȡMLEʮ�����ѡ�EM�㷨���Խ����ƹ��̷�Ϊ2������һ�����������Ա㽫����IJ���ȥ�����ڶ�������Ȼ�����ļ���ֵ��
����۲쵽����ȱʧֵ�ıó�����x����ij�ָ��ʷֲ���z��ʾȱʧ���ݣ���ˣ���EM�㷨�У�(x��z)����Ϊ����ȫ���ݡ�����f(x��z��
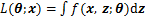
ʽ(1)�Dz��������ݵ���Ȼ������Ŀ�����ҵ����ʵ�
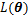
1) ������(E��)������������x�͵�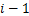
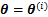
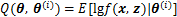
2) ���(M��)����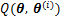
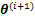
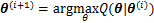
�����������1����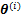
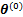
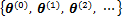
EM�㷨�ĺ��ľ�������ȱʧֵ(�����DZ����z��������ЧӦ����
1.2����������㷨
����������̵�ԭ�����Ľ�EM�㷨������ģ������һϵ��������ȱʧֵ��ģ�����������кܶ��ַ�������Ϊ�˸��õش����ݷֲ�������������ѡ�������Ʒ������ؿ��緽��(��MCMC�㷨��Markov Chain Monte Carlo)�������˼���ǣ�����һ��Markov����ʹ��ƽ�ȷֲ�Ϊ���������ĺ���ֲ���ͨ�����������Ʒ�����������ֲ������������Ի��������Ʒ����ﵽƽ�ȷֲ�ʱ������(��Ч����)�������ؿ�����֡�
MCMC�㷨�IJ���Ϊ�����ȹ���1��Markov��������������ƽ�ȷֲ�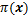
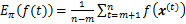
����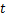
MCMC��Ҫ����Metropolis-Hastings�㷨[18]��Gibbs[19]����2�ַ�������������Ϊһ�ִӸ�ά���Ӹ��ʷֲ��н��Ʋ����ķ����������������ѧ�������������ֵ�⣬�����ͳ���ϵ��������ַ��̵Ľ�ȡ����IJ���Metropolis-Hastings�㷨������⡣
1.3��������̸Ľ�EM�㷨
EM�㷨��������ʵ�����ʱ�����ý�������ܳ�ʼֵ�趨��Ӱ�졣Ϊ�˱�����һ���⣬�������������EM�㷨������Ľ���EM�㷨��ʹ��MCMC����ع���ȱʧֵ�����ø÷������������ȱʧֵ���ƾ��ȡ�
�����㷨�Կɷ�Ϊ����(E)�������(M)���������㷨�����������Խ�һ��ϸ��Ϊģ�ⲽ��������Ʋ�2����
1) ������(E��)��Ϊģ�ⲽ��������Ʋ���
ģ�ⲽ����MCMC�㷨ת�ƾ���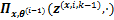
������Ʋ���
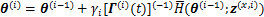
2) ���(M��)��
һ�������ƫ���������������ݵ���Ȼ����lc(
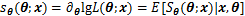
����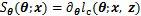
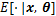
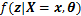
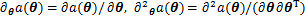
�̵Ķ���ƫ��Ϊ
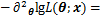
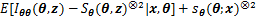
����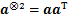
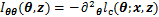
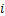
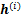
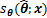
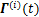
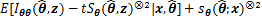
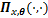
1) �ڵ�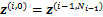
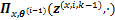
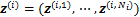
2) ���¹���ֵ���£�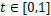
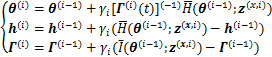
����
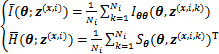
ʽ(10)��(11)�У���������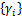
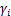
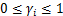

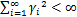

2 ʵ����֤������
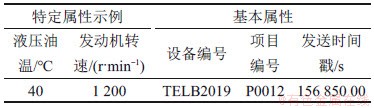
����ʹ�õ�ʵ�����ݾ�������ʵ�����������л������ó������������ݡ�ÿ���ź����ļ��ڶ����������ض������Լ�3���������Լ�����ʱ������豸��ź���Ŀ��š������źŵ�����ʾ���������1��ʾ��
��1����ͬ�ź����ļ��ֶμ�ʾ������
Table 1��Different semaphore file fields and sample data
Ϊ����֤���᷽������Ч�ԣ������ݷ�Ϊѵ���������Լ�����֤����ͨ��ѭ�������Ż�ģ��[20]��ʵʱ�ɼ��ó��������ݣ���Ϊ�ذ�һ���������ģ�������쳣�����ݶ�ʧ��ѵ���������Լ�����֤�������ֱ�Ϊ10%��15%��20%��Ȼ��ģ������ع�ȱʧֵ��ԭʼ���ݽ��бȽϣ��������㷨�����Ч���������ۡ�
Һѹ���ºͷ�����ת�ٷֱ���ͼ1��ͼ2��ʾ��
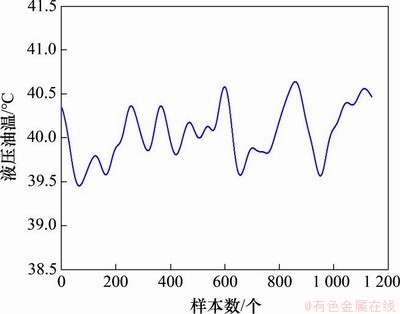
ͼ1���豸Һѹ���±仯����
Fig. 1��Temperature change curve of equipment hydraulic oil
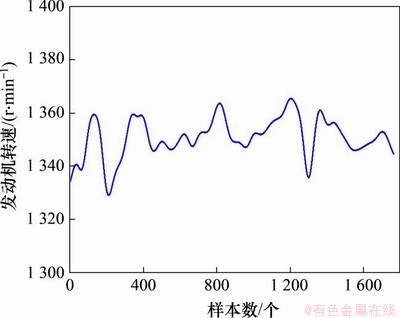
ͼ2��������ת�ٱ仯����
Fig. 2��Engine rotating speed change curve
��Σ��ֱ��3̨�豸��Һѹ���ºͷ�����ת�ٽ�������ͳ�Ʒ���������ѡ��ƽ���������Mad����ƽ�����ƽ��Rmse�ͱ�����Sd��3��ͳ������Ϊ���۱������嶨�����¡�
1) ƽ���������Mad��
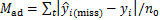
����
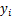
2) ��ƽ�����ƽ����Rmse��
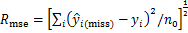
3) ����Sd��

����
���þ�ֵ����㷨��EM����㷨�ͱ���������㷨��Һѹ���ºͷ�����ת�ٵ�ȱʧ���ݽ�����䲹ȫ�õ��Ľ�����2��ʾ���ӱ�2���Կ������ڲ�ͬȱʧ���£���������ĸĽ�EM�㷨���ı�ƫ����ӽ��������ݼ��ı�ƫ�EM�㷨�ı�ƫ���֮����ֵ����㷨�ı�ƫ�������ˣ�����������㷨���нϸߵ�ȷ�Ⱥ��ȶ��ԡ�
��2��3����䷽���ıȽϽ��(����)
Table 2��Comparison results of three filling methods(Sd)

���⣬���������ͬ��䷽����Mad��Rmse�����жԱȣ����3��ʾ���ӱ�3���Կ�������������ĸĽ�EM�㷨��Mad��Rmse��3������ȱʧ���¾��Ⱦ�ֵ����EM�㷨�ĵͣ�������ȱʧ���������ȷ�����м�С��Ϊ�˸���ֱ�۵رȽ�3�ַ����ڲ�ͬȱʧ���µ�Ч����ͼ3��ͼ4��ʾ�ֱ�ΪҺѹ��������Mad��Rmse�ĶԱȡ���Ȼ���������᷽����Mad��Rmse��Ϊ��С��֤���˱������᷽������Ч�ԡ�
��3��Һѹ���������Ƚ�
Table 3��Comparison results of hydraulic oil temperature filling
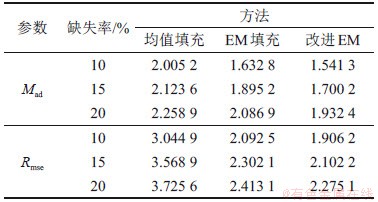
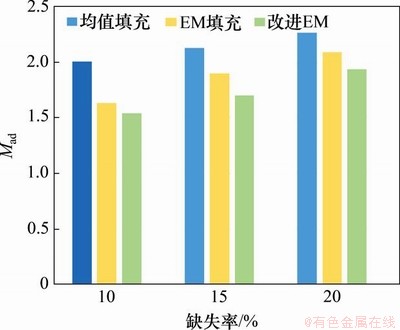
ͼ3��Һѹ�����Mad�Ƚ�
Fig. 3��Comparison results of Mad of hydraulic oil temperature filling
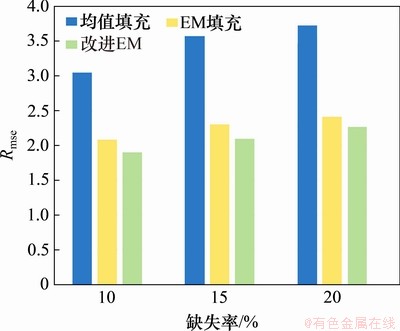
ͼ4��Һѹ�����Rmse�Ƚ�
Fig. 4��Comparison results of Rmse of hydraulic oil temperature filling
3 ����
1) �ڻ������ó�Զ�̼�����������ݲɼ��Լ���������У���ɱ���ش��������쳣�����ݶ�ʧ������Ը����⣬��MCMC������EM�㷨��ϣ����һ�ֻ���������̵�EMȱʧ��������㷨��ͨ������������̽��Ƶİ취���Ľ�EM�㷨�����Ч�������ȣ����������У�MCMC�����в�������ȱʧֵ��Ȼ����ֵ��������������ģ���Ը��¹���ֵ�����������ͨ�����������õ������ֵ��Ϊ�ع�ֵ�����ȱʧ���ݡ������ʵ�ʵ�Զ�̼�����ݶ����᷽��������֤�����������ֵ��䷽����EM��䷽�����бȽϡ�
2) �Ľ���EM�㷨��Mad��Rmse��3������ȱʧ���¾��Ⱦ�ֵ����EM�㷨�ĵͣ���������ȱʧ���������ȷ�����½��������øĽ���䷽�����ԽϺõ����EM�㷨�����ܣ���Ч�����EM�㷨������ʼֵ�趨�����⣬�����������ݵ�ȷ�ʡ�
�ο����ף�
[1] �����, �۳�. ��ҵ�����ݷ��������ķ�չ�������ٵ���ս[J]. ��Ϣ�����, 2018, 47(4): 398-410.
HE Wentao, SHAO Cheng. The development and challenges of industrial big data analysis technology[J]. Information and Control, 2018, 47(4): 398-410.
[2] ��ޱ, ��Ӣ, �ѷ�. �����ݷ����������ҵ��������ս�ͻ���[J]. ���ֽ�����ѧѧ��, 2015, 32(3): 89-92.
LIU Wei, CHEN Ying, GAO Jiafeng. Large data analysis and the challenge and opportunity to enterprise management[J]. Journal of Jilin Jianzhu University, 2015, 32(3): 89-92.
[3] ��־��, ����־, ���, ��. ����ҵ�еĴ����ݷ�������Ӧ���о�����[J]. ��е, 2018, 45(6): 1-13.
LIANG Zhiyu, WANG Hongzhi, LI Jianzhong, et al. A review on the application of big data analysis in manufacture industry[J]. Machinery, 2018, 45(6): 1-13.
[4] MORENO J, GOMEZ J, SERRANO M A, et al. Application of security reference architecture to big data ecosystems in an industrial scenario[J]. Software:Practice and Experience, 2020, 50(8): 1520-1538.
[5] QIN S J. Process data analytics in the era of big data[J]. AIChE Journal, 2014, 9(60): 3092-3100.
[6] LEI Y, LI N, GONTARZ S, et al. A model-based method for remaining useful life prediction of machinery[J]. IEEE Transactions on Reliability, 2016, 65(3): 1314-1326.
[7] �˽���, ��·��, �ص�ǿ, ��. ȱʧ���ݵĴ����������䷢չ����[J]. ͳ�������, 2019, 35(23): 28-34.
DENG Jianxin, SHAN Lubao, HE Deqiang, et al. Processing method of missing data and its developing tendency[J]. Statistics and Decision, 2019, 35(23): 28-34.
[8] �º���, ��ϲ��, ������. һ��Ԥ���SVDDBNȱʧ���ݲ岹�㷨[J]. �����������Ӧ��, 2020, 56(7): 81-87.
CHEN Haiyang, LIU Xiqing, HUAN Xiaoming. One-step prediction SVDDBN missing data interpolation algorithm[J]. Computer Engineering and Application, 2020, 56(7): 81-87.
[9] ���, ����. ���ڶ�Ԫ�ع�KNN������ȱʧ������䷽��[J]. ��Ϣ����, 2020, 44(4): 79-83.
GAO Zheng, XU Zhen. Filling method of missing data in oilfield based on multiple regression KNN[J]. Information Technology, 2020, 44(4): 79-83.
[10] ������, ���½�. ���ڷֲ�ģ�͵�ȱʧ���ݲ岹�����о�[J]. ͳ���о�, 2018, 35(11): 95-106.
YU Lichao, JIN Yongjin. Research on comparison of missing data imputation methods based on multilevel models[J]. Statistical Research, 2018, 35(11): 95-106.
[11] ����, ����Ⱥ, ������, ��. ��EM�Ķ����ȱʧ������㷨���������������е�Ӧ��[J]. �й�������ѧ, 2019, 27(3): 11-19.
JIANG Hui, MA Chaoqun, XU Xuqing, et al. An EM-similar imputation algorithm for multivariable data missing and its application in credit scoring[J]. Chinese Journal of Management Science, 2019, 27(3): 11-19.
[12] ������, ����, ������. ���ھ������������ۺ�Ȩֵ��SNM�Ľ��㷨[J]. ��ҵ���Ƽ����, 2017, 30(9): 27-31.
YANG Qiaoqiao, GUO Zhenbo, WANG Kaixi. Improved SNM algorithm based on clustering-based grouping and attribute weights[J]. Industrial Control Computer, 2017, 30(9): 27-31.
[13] BATISTA G E A P A, MONARD M C. An analysis of four missing data treatment methods for supervised learning[J]. Applied Artificial Intelligence, 2003, 17(5/6): 519-533.
[14] ������, �ŷ���, ����, ��. ��Ԫʱ������ȱʧ���������[J]. ϵͳ��������Ӽ���, 2018, 40(1): 225-230.
LI Zhengxin, ZHANG Fengming, WANG Ying, et al. Method of missing data imputation for multivariate time series[J]. Systems Engineering and Electronics, 2018, 40(1): 225-230.
[15] ����, �ԬB, ��ӱ, ��. �������Ȩ��Ϣϵ����ú�������[J]. ����������Ӧ��, 2015, 32(5): 646-654.
LU Zheng, ZHAO Jun, LIU Ying, et al. Missing data imputation based on maximal variance weight information coefficient for gas flow in steel industry[J]. Control Theory & Applications, 2015, 32(5): 646-654.
[16] ��ޱ, �����. �������ر�Ҷ˹��EMȱʧ��������㷨[J]. �ͻ���Ӧ��, 2011, 30(16): 75-77, 81.
ZOU Wei, WANG Huijin. EM algorithm to implement missing values based on Naive Bayesian[J]. Microcomputer & Its Application, 2011, 30(16): 75-77, 81.
[17] ������. ���ɾʧ�����¼�����Ȼ������������[J]. ��������ѧԺѧ��(��Ȼ��ѧ��), 2019, 33(2): 1-7.
KANG Hongliang. Properties of maximum likelihood estimator under random censored data[J]. Journal of Lanzhou University of Arts and Science(Science and Technology), 2019, 33(2): 1-7.
[18] ³��, �ϵǻ�. ���ڹ��弫ֵ�ֲ���Metropolis-Hastings�����㷨�ı�Ҷ˹MCMC��ˮƵ�ʷ�������[J]. ˮ��ѧ��, 2013, 44(8): 942-949.
LU Fan, YAN Denghua. Bayesian MCMC flood frequency analysis based on generalized extreme value distribution and Metropolis-Hastings algorithm[J]. Journal of Hydraulic Engineering, 2013, 44(8): 942-949.
[19] ������, ����Ӣ. ��Gibbs�����㷨���㶨����βʱWeibull�ֲ��ı�Ҷ˹����[J]. ����ͳ�������, 2000, 19(2): 35-40.
QIAO Shijun, ZHANG Shiying. Bayesian analysis of weibull distribution by using Gibbs sampler[J]. Application of Statistics and Management, 2000, 19(2): 35-40.
[20] ������, ��·��. ���ھ�ʸ�������ԵĻ���ѧϰ����������[J]. ���ϴ�ѧѧ��(��Ȼ��ѧ��), 2009, 40(6): 1636-1641.
CHEN Xianlai, YANG Luming. Partitioning machine learning sample set using similarity to mean vector[J]. Journal of Central South University(Science and Technology), 2009, 40(6): 1636-1641.
(�༭ �²ӻ�)
�ո����ڣ� 2020 -06 -20; �����ڣ� 2020 -09 -08
������Ŀ(Foundation item)�����ҹ��Ų��ص�������Ŀ(TC19083WB) (Project(TC19083WB) supported by Key Program of the National Ministry of Industry and Information)
ͨ�����ߣ������ʿ�����ڣ����¸��ӹ�ҵ���̼�⡢�Ż�����Ƶ��о���E-mail:hqcsu@csu.edu.cn
���ø�ʽ�� ����η, �Ƴ���, �����, ��. ���ڸĽ�EM�㷨�Ļ������ó���������[J]. ���ϴ�ѧѧ��(��Ȼ��ѧ��), 2021, 52(2): 443-449.
Citation: DENG Ziwei, TANG Zhaohui, ZHU Hongqiu, et al. An improved expectation maximization algorithm for missing data management of concrete pump truck[J]. Journal of Central South University(Science and Technology), 2021, 52(2): 443-449.
ժҪ����Ի������ó�Զ�̼���д�������ȱʧ�����⣬���һ�ֻ��������������㷨��ȱʧ���������㷨��ͨ���������Ʒ������ؿ��巽��(MCMC)������������ϸĽ��������(EM)�㷨�����ȣ����������У���MCMC�����в�������ȱʧֵ��������ֵ��������������ģ���Ը��¹���ֵ��Ȼ��������У�ͨ�����������õ������ֵ��Ϊ�ع�ֵ�����ȱʧ���ݡ�����Ի������ó�ʵ���������ݶԱ���������㷨����ֵ��䷨��EM�㷨��ȱʧ�������Ч�����бȽϡ��о���������������㷨��Ч�ؽ����EM�㷨������ʼֵ�趨�����⣬�������������ȷ�ʡ�
[1] �����, �۳�. ��ҵ�����ݷ��������ķ�չ�������ٵ���ս[J]. ��Ϣ�����, 2018, 47(4): 398-410.
[2] ��ޱ, ��Ӣ, �ѷ�. �����ݷ����������ҵ��������ս�ͻ���[J]. ���ֽ�����ѧѧ��, 2015, 32(3): 89-92.
[3] ��־��, ����־, ���, ��. ����ҵ�еĴ����ݷ�������Ӧ���о�����[J]. ��е, 2018, 45(6): 1-13.
[7] �˽���, ��·��, �ص�ǿ, ��. ȱʧ���ݵĴ����������䷢չ����[J]. ͳ�������, 2019, 35(23): 28-34.
[8] �º���, ��ϲ��, ������. һ��Ԥ���SVDDBNȱʧ���ݲ岹�㷨[J]. �����������Ӧ��, 2020, 56(7): 81-87.
[9] ���, ����. ���ڶ�Ԫ�ع�KNN������ȱʧ������䷽��[J]. ��Ϣ����, 2020, 44(4): 79-83.
[10] ������, ���½�. ���ڷֲ�ģ�͵�ȱʧ���ݲ岹�����о�[J]. ͳ���о�, 2018, 35(11): 95-106.
[12] ������, ����, ������. ���ھ������������ۺ�Ȩֵ��SNM�Ľ��㷨[J]. ��ҵ���Ƽ����, 2017, 30(9): 27-31.
[14] ������, �ŷ���, ����, ��. ��Ԫʱ������ȱʧ���������[J]. ϵͳ��������Ӽ���, 2018, 40(1): 225-230.
[15] ����, �ԬB, ��ӱ, ��. �������Ȩ��Ϣϵ����ú�������[J]. ����������Ӧ��, 2015, 32(5): 646-654.
[16] ��ޱ, �����. �������ر�Ҷ˹��EMȱʧ��������㷨[J]. �ͻ���Ӧ��, 2011, 30(16): 75-77, 81.
[17] ������. ���ɾʧ�����¼�����Ȼ������������[J]. ��������ѧԺѧ��(��Ȼ��ѧ��), 2019, 33(2): 1-7.
[19] ������, ����Ӣ. ��Gibbs�����㷨���㶨����βʱWeibull�ֲ��ı�Ҷ˹����[J]. ����ͳ�������, 2000, 19(2): 35-40.
[20] ������, ��·��. ���ھ�ʸ�������ԵĻ���ѧϰ����������[J]. ���ϴ�ѧѧ��(��Ȼ��ѧ��), 2009, 40(6): 1636-1641.
