
J. Cent. South Univ. (2016) 23: 2578-2586
DOI: 10.1007/s11771-016-3319-2
Complex human activities recognition using interval temporal syntactic model
XIA Li-min(������), HAN Fen(����), WANG Jun(����)
School of Information Science and Engineering, Central South University, Changsha 410075, China
 Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Abstract:
A novel method based on interval temporal syntactic model was proposed to recognize human activities in video flow. The method is composed of two parts: feature extract and activities recognition. Trajectory shape descriptor, speeded up robust features (SURF) and histograms of optical flow (HOF) were proposed to represent human activities, which provide more exhaustive information to describe human activities on shape, structure and motion. In the process of recognition, a probabilistic latent semantic analysis model (PLSA) was used to recognize sample activities at the first step. Then, an interval temporal syntactic model, which combines the syntactic model with the interval algebra to model the temporal dependencies of activities explicitly, was introduced to recognize the complex activities with a time relationship. Experiments results show the effectiveness of the proposed method in comparison with other state-of-the-art methods on the public databases for the recognition of complex activities.
Key words:
1 Introduction
Human activities recognition is an important area of computer vision which has been applied extensively in many areas such as surveillance systems, patient monitoring system, and a variety of systems that involve interactions between persons and electronic devices such as human-computer interfaces. Though a number of techniques have been presented for human activities recognition, understanding human activities by computers still remains unresolved.
Feature extract is an important link in human activities recognition. Generally speaking, the features can be categorized as two groups: global features and local features. The space-time volume (STV) and Fourier descriptor belong to global features which are extracted by globally considering the whole image. However, the global features are sensitive to noise, occlusion and variation of viewpoint. KUMARI and MITRA [1] used discrete Fourier transforms (DFTs) of small image blocks as the selected features for activity recognition. Instead of using global features, some methods were proposed to consider the local image patches as local features. The local features, which capture the characteristics of an image patch, are ideally invariant to background clutters, appearance and occlusions, and also invariant to rotation and scale in some cases. Local spatio-temporal feature is a quite successful description of activity recognition. LAPTEV et al [2] applied the spatio-temporal interest point to videos by using extended Harris detector. Other feature descriptors were proposed, which ranged from high order derivatives, gradient information, optical flow, luminosity information and the extended spatio-temporal of image descriptor [3-5], such as 3D scale-invariant feature transform (3D-SIFT) [6], 3D histogram of oriented gradient (HOG3D) [7], Lucas-Kanade-Tomasi (LKT) features. ERIC et al [8] used match-time covariance (MTC) to design a normalized cross-correlation similarity descriptor (NCC-S). But this algorithm had a complex and large computation process. BREGONZIO et al [9] proposed a new action representation based on computing a rich set of descriptors from key point trajectories, and developed an adaptive feature fusion method to combine different local motion descriptors for improving model robustness against feature noise and background clutters. However, the above mentioned feature representations are either local feature descriptors or global feature descriptors, which could not fully capture the whole human activity.
Recent years, many methods for human activity recognition have been proposed. DAI et al [10] constructed dynamic Bayesian network system (DBNS) to recognize group activities in a conference room. ZHANG et al [11] proposed a method based on interval temporal Bayesian network (ITBN) to recognize complex human activities. DAMEN and HOGG [12] built a Bayesian networks using a Markov chain Monte Carlo (MCMC) for the recognition of bicycle-related activities. They used the Bayesian network to modeling the relationship of atomic-level action, and applied the MCMC to updating the Bayesian network iteratively. ZHANG and GONG [13] used a structured probabilistic latent semantic analysis (PLSA) algorithm to human recognition, which learned the representation of activities as the distribution of latent topics in an unsupervised way, where each action frame was characterized by a codebook representation of local shape context. ARSIC and SCHULLER [14] analyzed simple activities by HMM and further recognized complex activities by coupled hidden Markov models (CHMM). SUGIMOTO et al [15] adopted a rule-based activities recognition algorithm, which used the human profile as the representation of activities and the rule classifier to recognize activities. FERNANDEZ- CABALLERO et al [16] employed finite state machines to recognize human activity, which classified the motion characteristics of images as activity symbols of different levels by multi- layer abstraction. The atomic activities in the lower level were detected and the information was input into grammar rules to detect the points of interest. For a moving object, the shape and the trajectory were also considered. HUANG [17] proposed a method for complex human activities recognition based on the stochastic context-free grammar (SCFG), which used continuous-space relevance model (CRM) to recognize simple human activities and SCFG to recognize complex human activity. XIA et al [18] presented a new method for complex activity recognition in videos by key frames. The recognition error was further reduced because of ignoring the recognition of simple activities. But all those methods didn��t deal well with interleaved activities because they didn��t consider the temporal relationship.
In this work, a new recognition method is proposed to recognize complex activities in video flow based on interval temporal syntactic model. The trajectory shape descriptor, SURF descriptor and HOF descriptor are extracted according to the density trajectory. These extracted features contain the shape information, structure information and motion information that can fully describe the whole human activity. The bag of words (BOW) model is introduced to merge these local features and global features providing robust activity representation. Two steps are applied to achieve the process of complex human activities recognition. First, the PLSA model is used to recognize the simple activities. Then, the interval temporal syntactic method which combines the syntactic model with the interval temporal relationship is adopted to recognize complex activity which consists of simple activities based on the result of the first step. Experimental results show the effectiveness of the proposed method in comparison with other related works in the literature.
2 Trajectory-based activity feature extracting
Features from the given video images are extracted for human activities recognition in the first place. The detailed approach is showed as follows.
2.1 Density trajectory of interesting point
In order to acquire the trajectory shape descriptor, the first step is to sample interesting points, then use the optical flow method to get motion trajectories of the interesting points, and finally obtain the trajectory shape descriptor.
First, we divide the image into grids with each cell size of W��W when sampling interesting points, and execute pixels sampling in each grid. During the sampling process, we select the central point of the grid as the sampling point, and compute the final interesting point by using three-valued interpolation method for every sampling point to gain more particular information of the image. Experiments prove that it could acquire the best results in all databases when W=5. We could get at most 8 spatial scales according to the resolution of the video. In order to get enough interesting points, the spatial scale increases by a factor of 
Although our aim is to track all the sample points of the video, it is impossible to track any point in homogeneous image areas without any structure. We remove points in these areas. Here, we use the criterion proposed by SHI and TOMASI [19], that is, points on the grid are removed, if the eigenvalues of the auto- correlation matrix are very small. A threshold �� is set on eigenvalues of each image I as
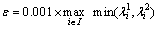 (1)
(1)
where the 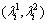 is the eigenvalues of point i in the image I. We discard the point whose eigenvalues are lower than the threshold and keep the point whose eigenvalues are higher than the threshold. The experiment results show that it has a good coordination between significant and density of the sample point when the parameter is set as 0.001.
is the eigenvalues of point i in the image I. We discard the point whose eigenvalues are lower than the threshold and keep the point whose eigenvalues are higher than the threshold. The experiment results show that it has a good coordination between significant and density of the sample point when the parameter is set as 0.001.
We use the optical flow to track every interesting point in each spatial scale to gain the trajectory of motion after getting the interesting points. For frame It, its density optical region  is computed with respect to the next frame It+1, where uxt and uyt are components of the optical flow at the horizontal and vertical coordinates respectively. And for every given point
is computed with respect to the next frame It+1, where uxt and uyt are components of the optical flow at the horizontal and vertical coordinates respectively. And for every given point 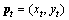 in the image It, the position in the frame It+1 could be got using median filter smoothing on ut as shown below:
in the image It, the position in the frame It+1 could be got using median filter smoothing on ut as shown below:
 (2)
(2)
where M is the nuclear of median filter and its size is 3��3 pixels. The median filter improves trajectories for points at motion boundaries that would otherwise be smoothed out.
Points of subsequent frames are concatenated to generate a trajectory: 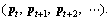 To avoid the drift of trajectories from their initial locations during the tracking process, the length of the video frames is limited to L. In this paper, we set L=15. For each image frame if there is no point found in a W��W neighborhood, then another new point is sampled and added to the tracking process so that a dense coverage of trajectory is ensured.
To avoid the drift of trajectories from their initial locations during the tracking process, the length of the video frames is limited to L. In this paper, we set L=15. For each image frame if there is no point found in a W��W neighborhood, then another new point is sampled and added to the tracking process so that a dense coverage of trajectory is ensured.
The static trajectory is pruned in the post-processing stage because it does not contain motion information. Trajectories with sudden large displacements, most likely to be erroneous, are also removed. Such trajectories are detected, if the displacement vector between two consecutive frames is larger than 70% of the overall displacement of the trajectory.
2.2 Trajectory shape descriptor
Given two consecutive points along a trajectory: 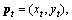
 we compute the displacement vector between the two points as
we compute the displacement vector between the two points as 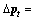
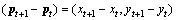 . For a single trajectory of length L, we can then obtain a series of displacement vectors
. For a single trajectory of length L, we can then obtain a series of displacement vectors  The final resulting vector is normalized by the sum of displacement vector magnitudes:
The final resulting vector is normalized by the sum of displacement vector magnitudes:
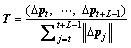 (3)
(3)
In the following, we refer this vector as trajectory shape descriptor that is a global descriptor. Because we use trajectories with a fixed length of L=15 frames, we obtain a 30-dimensional descriptor.
2.3 Motion and structure descriptor
In addition to the trajectory shape descriptor, SURF descriptor and HOF descriptor are adopted as they contain complementary information to our trajectory features. The SURF descriptor captures the local static appearance information well with advantage of fast and robustness, while the HOF descriptor expresses the local motion information well on the other side.
In order to get these two descriptors, first, a 3D spatio-temporal volume is built around the interesting point. The size of volume is N��N pixels and the L frames long. To embed structure information, the volume is then subdivided into spatio-temporal grid of size  where n��=2 and n��=3. Then, we compute the SURF and HOF in each cell of the spatio-temporal grid respectively. For both SURF and HOF, orientations are quantized into eight bins with full orientation and magnitudes are used weighting. Because an additional zero bin is added for HOF, which accounts for pixels whose optical flow magnitudes are lower than the threshold (LAPTEV [2]), the final descriptor size is 96 (2��2��3��8) for SURF and 108 (2��2��3��9) for HOF. For the sake of convenience, descriptors SURF and HOF are expressed as S and H.
where n��=2 and n��=3. Then, we compute the SURF and HOF in each cell of the spatio-temporal grid respectively. For both SURF and HOF, orientations are quantized into eight bins with full orientation and magnitudes are used weighting. Because an additional zero bin is added for HOF, which accounts for pixels whose optical flow magnitudes are lower than the threshold (LAPTEV [2]), the final descriptor size is 96 (2��2��3��8) for SURF and 108 (2��2��3��9) for HOF. For the sake of convenience, descriptors SURF and HOF are expressed as S and H.
In order to fuse all three descriptors for providing robust activity representation, we employ the BOW method. For each trajectory, its associated descriptors T, S and H are normalized with their L2 norm and concatenated to form a global descriptor Gt=(pt, T, S, H) of the interesting point pt. The creation of BOW representation of video consists of two steps. The detailed process is described as follows. First, we quantise the global descriptor Gt for all trajectories using the K-means clustering algorithms to obtain Nv clusters (codebook). Then, codewords are defined as the centers of the obtained clusters, namely visual words. Second, descriptor Gt is converted to the ��bag-of-words�� representation by a histogram vector d with Nv dimensions:
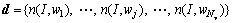 (4)
(4)
where wj stands for the j-th visual word, and n(I, wj) is the number of visual words included in activity video I.
In the following, we refer this histogram vector d as activity video.
3 PLSA-based simple activities recognition
To recognize complex activity, the self-adapting video segmentation method proposed in Ref. [20] is applied to divide a complex activity into several simple activities, and the PLSA algorithm is used to recognize the simple activities. PLSA model is a statistical model and combine the words with document by latent topic variable. We regard each document as a mixture of topic, and the model of PLSA is shown in Fig. 1.
Supposing that document, word and topic are represented by di, wj, zk respectively, the joint probability of document, word and topic are expressed as
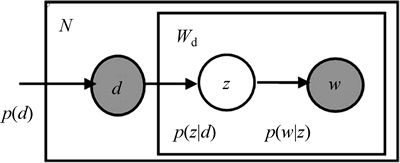
Fig. 1 Graph model of PLSA (Nodes represent random variables, shaded nodes are observed and non-shaded ones are unseen variables. Plates stand for repetitions)
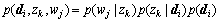 (5)
(5)
where  is the probability of wj appearing in topic zk;
is the probability of wj appearing in topic zk; 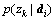 is the probability of zk occurring in document di; and p(di) is the probability of a word included in document di. The probability
is the probability of zk occurring in document di; and p(di) is the probability of a word included in document di. The probability could be represented by
could be represented by
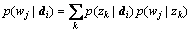 (6)
(6)
In order to apply the PLSA model to recognize simple activities, we regard the visual word in the BOW as word wj, the related simple activity video as the document di, and each simple activity category as the topic variable zk. Thus, there are two steps for simple activity recognition: training and testing of PLSA.
1) Supervision training of PLSA
Step 1: For every k and j, calculate 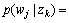
 as the initialization of
as the initialization of 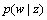 and the random initialization of
and the random initialization of 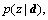 where nj,k is the number of the k-th activity category related to the j-th word and nk is the number of video images related to the k-th activity category in the above formula .
where nj,k is the number of the k-th activity category related to the j-th word and nk is the number of video images related to the k-th activity category in the above formula .
Step 2: E-step, for all 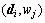 pairs, calculate
pairs, calculate
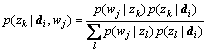
Step 3: M-step, substitute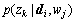 as calculated in Step 2, for all k and j, calculate
as calculated in Step 2, for all k and j, calculate
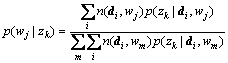
where 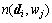 is the number of word wj occurring in document di.
is the number of word wj occurring in document di.
Step 4: M-step, substituteas calculated in Step 2, and for all i and k, calculate
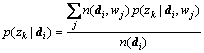
where 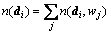 is the length of document di.
is the length of document di.
Step 5: Repeat Step 2 to Step 4 until the convergence condition is met.
2) Categories testing of PLSA
Step 1: For all k and j, calculate
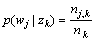
Step 2: E-step, for all 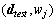 pairs, calculate
pairs, calculate
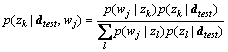
where dtest is the testing document which is the video frame needed to be recognized.
Step 3: Local M-step, substituteas calculated in Step 1, and for all k, calculate
Step 4: Repeat steps 2 to 3 until the convergence condition is met.
Step 5: Calculate activities categories
4 Syntactic models based complex activities recognition
After simple activity recognition, the complex activity, which is composed of simple activities, is recognized using syntactic models. Syntactic approaches model human activities as a string of symbols, where each symbol corresponds to a simple activity. Syntactic method has a remarkable characteristic which describes the activities that is highly structured. Hence, the level-structured method is employed to represent activities under the syntactic method in this paper. There are two types of symbols: terminal and non-terminal. Terminal is the atomic observation which is further non-decomposable, while non-terminal is the observation that could be decomposed into terminal and non-terminal. The following rules describe the relationship between terminal and non-terminal:
 (7)
(7)
In the above rules, the capital letter represents the non-terminal while the lowercase letter is the terminal. S is the starting symbol which equals the first generation and is represented by sequence AB. non-terminal A, B are related to generation sequences a and b. (|) is used to confirm the multi-terminals related to the same non- terminal. There is a requirement to the illustrate of complex activities model: the terminal is always the original observation, and the non-terminal is the middle structure to denote a series of complex activities. All the efficient activities begin with the starting symbol S.
Most syntactic methods use a bottom-up method to recognize high level complex activities. First, the simple activities are detected by some independent methods at the low level. Then, a grammar analyzer is used to recognize complex activities at the high level with the detection value. In our work, the statistical probabilities of simple activities gained through the PLSA model are applied to the syntactic model to realize the complex activities recognition. We formulate the starting symbol of the m-th complex activity as S(m), then each simple activity forming the complex activity could be represented by the probability p computed through PLSA model, thus, we could have a rule to describe complex activities as follows:
 (8)
(8)
The syntactic rule representing complex activities in the formula (8) dose not consider the temporal relationship among simple activities. But the temporal relationship among simple activities is very important for complex activity recognition. In this work, the Allen��s temporal logic [21] is introduced into the syntactic model. According to Allen��s axiomatization of time periods, there are 8 temporal relations {before, meet, overlap, start, during, finish, equal, inverse-finish} that can hold between two activities. Thus, we have the expression after adding temporal relationship to the syntactic model:
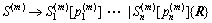 (9)
(9)
where {R} is the temporal matrix, which describes all possible temporal relations.
Figure 2 shows an example of syntactic model. An activity S is composed of three simple activities A, B and C. The part enclosed by the dashed lines in Fig. 2(a) illustrates the temporal relationship of the three simple activities: A before B and C, B during C . The syntactic rule is shown in Fig. 2(b).
A minimum description length (MDL) based rule induction algorithm is adopted to learn activity syntactic rules [22]. With this algorithm, too many candidates will be generated, which increases the evaluation costs. Furthermore, some rule candidates without any semantic meanings, may disturb the subsequent induction process. Thus, we remove redundant rule candidates and retain meaningful rule candidates by calculating the similarity between two complex activities [23]. In order to select the effective candidate, we set a threshold  . If the similarity between two complex activities is lower than the threshold, then the candidate is add to the rule sets; otherwise, it is removed. The similarity between two activities Si and Sj is measured by their spatiotemporal distance, which is defined as
. If the similarity between two complex activities is lower than the threshold, then the candidate is add to the rule sets; otherwise, it is removed. The similarity between two activities Si and Sj is measured by their spatiotemporal distance, which is defined as
 (10)
(10)
where  is the spatial distance between two complex activities, and
is the spatial distance between two complex activities, and 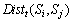 is the temporal distance between two activities Si and Sj. The value of �� is set by experience, and the spatial distance is defined as
is the temporal distance between two activities Si and Sj. The value of �� is set by experience, and the spatial distance is defined as
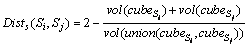 (11)
(11)
where 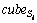 is the average spatial range of all instances of complex activities Si, and the spatial range is represented as {(xmin, xmax), (ymin, ymax), (omin, omax)}, which records spread range of simple activities in the x-axis, y-axis and motion orientation respectively. is represented as a three-dimensional cube with x, y-axis and the orientation axis.
is the average spatial range of all instances of complex activities Si, and the spatial range is represented as {(xmin, xmax), (ymin, ymax), (omin, omax)}, which records spread range of simple activities in the x-axis, y-axis and motion orientation respectively. is represented as a three-dimensional cube with x, y-axis and the orientation axis. 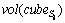 is the volume of the
is the volume of the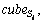 and
and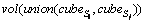 is the minimum volume of the cube that contains the and
is the minimum volume of the cube that contains the and 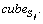
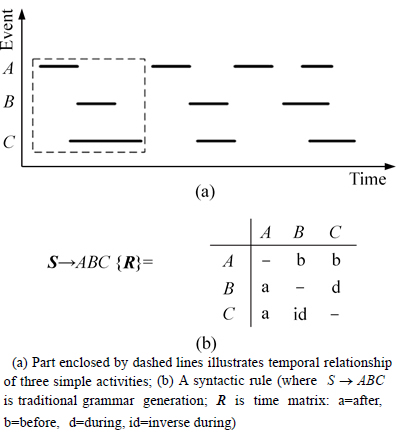
Fig. 2 Illustration of syntactic rule:
Temporal distance could be calculated as follows:
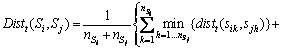
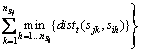 (12)
(12)
where
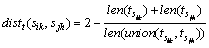 (13)
(13)
where 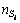 is the total number of S��i s instances in the current event stream;
is the total number of S��i s instances in the current event stream; is the temporal interval (start_point, end_point) of activity sik,
is the temporal interval (start_point, end_point) of activity sik, 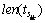 is the length of ;
is the length of ; 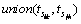 is the minimum temporal interval that contains and
is the minimum temporal interval that contains and 
Provided the learned activity rules, we use the multi-thread parsing algorithm [23] to recognize complex activity.
5 Experiments
In order to verify the effectiveness of the proposed method, we selected standard public datasets to test our framework. These datasets are YouTube action database [24] and University of Central Florida (UCF) sports action database [25]. The complex activities were divided into several simple activities using the self- adapting video segmentation method proposed in Ref. [20]. The PLSA model was employed to simple activities recognition at first step, and the interval temporal syntactic model was adopted for complex activities recognition afterwards. Our method is compared with other three state-of-art methods: ITBN [11], PLSA [13] and rule-based method [15]. The algorithm was implemented in VC6.0 for simulation with Intel(R) Core(TM) i3-2310M CPU and 2.5G frequency on the Windows 2007 operating system. The specific process and results are shown as follows.
5.1 YouTube action database
This database is the most extensive realistic action dataset available to public. It is composed of 1168 videos collected from YouTube. These videos contain a representative collection of real world challenges, such as shaky cameras, cluttered background, variation in object scale, variable and changing view-point and illumination, and low resolution. The YouTube action dataset contains 11 action categories: basketball shooting, biking, diving, golf swinging, horseback riding, soccer juggling, swinging, tennis swinging, trampoline jumping, volleyball spiking and walking with a dog. For each category, there are 25 groups of videos with more than four action clips in it.
The video clips in the same group may share some common features, for instance, the same actor, similar background, similar viewpoint, and so on. In this work, we performed recognition experiments on those actions: tennis swinging (a1), jumping (a2), basketball shooting (a3), horseback riding (a4), soccer juggling (a5), biking (a6), diving (a7) and golf swinging (a8). Figure 3 shows the figure of motion trajectory on this database. Table 1 lists the confusion matrix of our method on this database.

Fig. 3 Figure of trajectory in YouTube action database (Pictures from up to bottom are tennis swinging (a), jumping (b), basketball shooting (c), horseback riding (d), soccer juggling (e), biking (f), diving (g) and golf swinging (h) respectively)
Table 1 Confusion matrix of proposed method in YouTube database
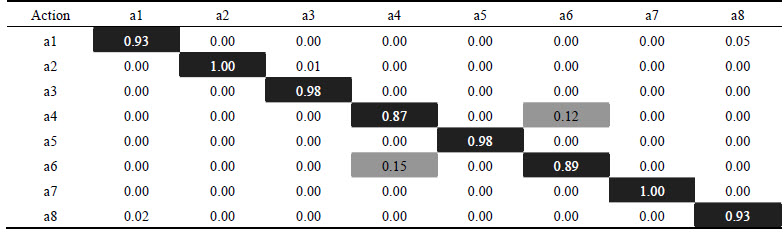
From Fig. 3 and Table 1, it could be found that our method works well on the YouTube action database. It could recognize jumping and diving completely, and recognize well on other testing actions.
5.2 UCF sports action database
This database consists of several actions collected in 2008 from various sporting events. The database contains 150 video sequences and includes 9 different types of human actions in sport broadcasting videos: diving (16 videos), kicking (25 videos), horseback riding (14 videos), golf swinging (25 videos), running (15 videos), skating (35 videos), lifting (15 videos), swinging (35 videos) and walking (22 videos). This database is very challenging due to large variations in camera motion, object appearance and pose, object scale, view point, cluttered background, and illumination conditions.
In this work, we performed experiments on those actions: skating (b1), golf swinging (b2), kicking (b3), horseback riding (b4), running (b5), walking (b6), lifting (b7) and diving (b8). Figure 4 shows the figure of motion trajectory on this database. Table 2 is the confusion matrix of our method on this database.
From Fig. 4 and Table 2 it could be found that our method works well on UCF sports action database. It could recognize golf swing, walking and lifting completely and achieve a perfect result on other sports action as well.
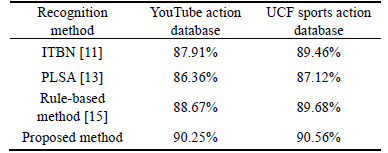
The recognition results of the proposed method compared to other existing methods on YouTube database and the UCF sports database are listed in Table 3. The experimental results indicate that our method works improves accuracy of recognition in almost every situation. ITBN is effective in recognizing sequential interactions, but when the temporal relationship among activities is non-sequential, such as parallel interactions, it might make misrecognition, which leads to decrease in recognition accuracy. The PLSA is a statistical model that does not consider the temporal relationship, so the recognition rate is limited. The rule-based activities recognition algorithm uses the human silhouette as the representation of activities and the rule classifier to recognize activities, as silhouette is unreliable and can��t effectively describe activities due to cluttered background and large variations in object appearance and object scale, the identification accuracy is not high. Our method is superior to other methods in the recognition of complex activity composed of simple activities, that is mainly because of the features and recognition methods used in the work. The features adopted contain complimentary information which could describe human activities better, which are robust against feature noise and background clutters. In addition, the method for simple activities recognition using PLSA can promise a high precision. What is more, as it considers the complex temporal relationship among simple activities, the interval temporal syntactic model is able to deal well with interleaved activities, which improves the recognition accuracy of complex activity.

Fig. 4 Trajectory in UCF sports action database (Pictures from up to bottom are skating (a), golf swinging (b), kicking (c), horseback riding (d), running (e), walking (f), lifting (g) and diving (h) respectively)
Table 2 Confusion matrix of proposed method in UCF sports action database
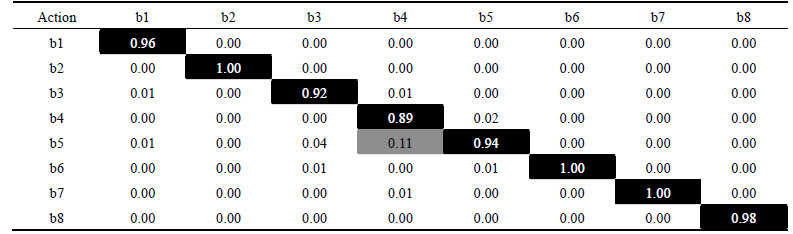
Table 3 Recognition results of different methods
6 Conclusions
1) A method for human complex activity recognition is proposed based on interval temporal syntactic model. This method has obvious advantages in recognition precision and can be used interleaved activities.
2) Trajectory shape descriptor, SURF descriptor and HOF descriptor are adopted to describe human activity. Our descriptors improve model robustness against feature noise and background clutters.
3) The PLSA model is employed to the simple activities recognition, and the interval temporal syntactic model is introduced to the complex activities recognition. The proposed method could reduce the recognition error.
4) Two databases are used to test the proposed methods: the YouTube action database and the UCF sports action database. The experimental results show that the proposed method is applicable in different databases and has a higher recognition accuracy than the existing methods.
References
[1] KUMARI S, MITRA S K. Human action recognition using DFT[C]// IEEE National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics. Hubli: IEEE, 2011: 239-242.
[2] LAPTEV I. On space-time interest points [J]. International Journal of Computer Vision, 2005, 1(2/3): 432-439.
[3] DOLLAR P, RABAUD V, COTTRELL G, BELONGIE S. Behavior recognition via sparse spatio-temporal features [C]// IEEE International Workshop on Visual Surveillance & Performance Evaluation of Tracking & Surveillance. Beijing: IEEE, 2005: 65-72.
[4] LAPTEV I, MARSZALEK M, SCHMID C, ROZENFELD B. Learning realistic human actions from movies [C]// Conference on Computer Vision and Pattern Recognition. Anchorage: IEEE, 2008: 1-8.
[5] SCHULDT C, LAPTEV I, Caputo B. Recognizing human actions: A local SVM approach [C]// International Conference on Pattern Recognition. Cambridge: IEEE, 2004: 32-36.
[6] SCOVANNER P, ALI S, SHAH M. A 3-dimensional sift descriptor and its application to action recognition [C]// Proceedings of the 15th International Conference on Multimedia. NY: ACM, 2007: 357-360.
[7] KLASER A, MARSZALEK M, SCHMID C. A spatio-temporal descriptor based on 3d-gradients [C]// Proceedings of the 19th British Machine Vision Conference. Leeds: Springer Verlag, 2008: 275: 1-10.
[8] ERIC C, VINCENT R, ANDREW Z. Match-time covariance for descriptor [C]// Proceedings of the 24th British Machine Vision Conference. Bristol: Springer Verlag, 2013: 270-281.
[9] BREGONZIO M, LI J, GONG S, TAO X. Discriminative topics modeling for action feature selection and recognition [C]// Proceedings of the 21th British Machine Vision Conference. Aberystwyth: Springer, 2010: 1-11.
[10] DAI Peng, DI Hui-jun, DONG Li-geng, TAO Lin-mi. Group interaction analysis in dynamic context [J]. IEEE Transactions On Systems, Man and Cybernetics��Part B, 2009, 39(1): 34-42.
[11] ZHANG Y, ZHANG Y, SWEARS E, LARIOS N,WANG ZH,JI Q. Modeling temporal interactions with interval temporal bayesian networks for complex activity recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(10): 2468- 2483.
[12] DAMEN D, HOGG D. Recognizing linked events: Searching the space of feasible explanations [C]// Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 927-934.
[13] ZHANG J, GONG S. Action categorization by structural probabilistic latent semantic analysis [J]. Computer Vision and Image Understanding, 2010, 114(8): 857-864.
[14] ARSIC D, SCHULLER B. Real time person tracking and behavior interpretation in multi-camera scenarios applying homography and coupled HMMs [C]// International Conference on Analysis of Verbal and Nonverbal Communication and Enactment. Budapest, Hungary: Springer-Verlag, 2011: 1-18.
[15] SUGIMOTO M, ZIN T T, TORIU T, NAKAJIMA S. Robust rule-based method for human activity recognition [J]. International Journal of Computer Science and Network Security, 2011, 11(4): 37-43.
[16] FERNANDEZ-CABALLERO A, CASTILLO J C, RODRIGUEZ- SANCHEZ J M. Human activity monitoring by local and global finite state machines [J]. Expert Systems with Applications, 2012, 39(8): 6982-6993.
[17] HUANG Jin-xia. Complex human activity recognition based on SCFG [D]. Changsha: Central South University, 2013. (in chinese)
[18] XIA Li-min, SHI Xiao-ting, TU Hong-bin. An approach for complex activity recognition by key frames [J]. Journal of Central South University,2015, 22(9): 3450-3457.
[19] SHI J, TOMASI C. Good features to track [C]// Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 1994: 593-600.
[20] XIA Li-min, YANG Bao-juan, TU Hong-bing. Recognition of suspicious behavior using case-based reasoning [J]. Journal of Central South University, 2015, 22(1): 241-250.
[21] ALLEN J F. Maintaining knowledge about temporal intervals [J]. Communications of the ACM, 1983, 26(11): 832-843.
[22] GRUNWALD P. A minimum description length approach to grammar inference [C]// Connectionist, Statistical and Symbolic Approaches to Learning for Natural Language Processing, Montreal: Springer Verlag, 1996: 203-216.
[23] ZHANG Z, TAN T, HNANG K. An extended grammar system for learning and recognizing complex visual events [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(2): 240-255.
[24] YouTube action dataset [EB/OL]. 2011-11-01. http:// www.cs.ucf. edu/liujg/ YouTubeActiondataset.html.
[25] UCF sports action dataset [EB/OL]. 2012-02-01. http://vision.eecs. ucf.edu/datasetsActions.html.
(Edited by YANG Hua)
Foundation item: Project(50808025) supported by the National Natural Science Foundation of China; Project(20090162110057) supported by the Doctoral Fund of Ministry of Education, China
Received date: 2015-07-06; Accepted date: 2015-12-07
Corresponding author: XIA Li-min, Professor, PhD; Tel: +86-13974961656; E-mail: xlm@mail.csu.edu.cn
Abstract: A novel method based on interval temporal syntactic model was proposed to recognize human activities in video flow. The method is composed of two parts: feature extract and activities recognition. Trajectory shape descriptor, speeded up robust features (SURF) and histograms of optical flow (HOF) were proposed to represent human activities, which provide more exhaustive information to describe human activities on shape, structure and motion. In the process of recognition, a probabilistic latent semantic analysis model (PLSA) was used to recognize sample activities at the first step. Then, an interval temporal syntactic model, which combines the syntactic model with the interval algebra to model the temporal dependencies of activities explicitly, was introduced to recognize the complex activities with a time relationship. Experiments results show the effectiveness of the proposed method in comparison with other state-of-the-art methods on the public databases for the recognition of complex activities.
