

J. Cent. South Univ. (2019) 26: 3338-3350
DOI: https://doi.org/10.1007/s11771-019-4257-6
RVFLN-based online adaptive semi-supervised learning algorithm with application to product quality estimation of industrial processes
DAI Wei(��ΰ)1, 2, HU Jin-cheng(�����)1, CHENG Yu-hu(����)1,WANG Xue-song(��ѩ��)1, CHAI Tian-you(������)2
1. School of Information and Control Engineering, China University of Mining and Technology,Xuzhou 221116, China;
2. State Key Laboratory of Synthetical Automation for Process Industries, Northeastern University,Shenyang 110819, China
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2019
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2019
Abstract:
Direct online measurement on product quality of industrial processes is difficult to be realized, which leads to a large number of unlabeled samples in modeling data. Therefore, it needs to employ semi-supervised learning (SSL) method to establish the soft sensor model of product quality. Considering the slow time-varying characteristic of industrial processes, the model parameters should be updated smoothly. According to this characteristic, this paper proposes an online adaptive semi-supervised learning algorithm based on random vector functional link network (RVFLN), denoted as OAS-RVFLN. By introducing a L2-fusion term that can be seen a weight deviation constraint, the proposed algorithm unifies the offline and online learning, and achieves smoothness of model parameter update. Empirical evaluations both on benchmark testing functions and datasets reveal that the proposed OAS-RVFLN can outperform the conventional methods in learning speed and accuracy. Finally, the OAS-RVFLN is applied to the coal dense medium separation process in coal industry to estimate the ash content of coal product, which further verifies its effectiveness and potential of industrial application.
Key words:
Cite this article as:
DAI Wei, HU Jin-cheng, CHENG Yu-hu, WANG Xue-song, CHAI Tian-you. RVFLN-based online adaptive semi-supervised learning algorithm with application to product quality estimation of industrial processes [J]. Journal of Central South University, 2019, 26(12): 3338-3350.
DOI:https://dx.doi.org/https://doi.org/10.1007/s11771-019-4257-61 Introduction
With the increasing demands for energy saving and consumption reduction in process industries, the optimization and control for product quality, have gradually become the hot researches in the field of industrial process control [1-3]. Generally, the optimization and control depend largely on a good measurement of product quality. Unfortunately, it is often difficult to achieve the real-time measurement of product quality due to economic or technical limitations. In fact, engineers usually employ soft sensor techniques to estimate the product quality. The industrial processes, however, are usually extremely complex [4], which makes it hard to obtain their physical and chemical mechanisms. Therefore, data-driven modeling approaches, seen as the alternative economic methods, have received increasing attention in process industries over the past years [5, 6].
The traditional data-driven modeling techniques are almost supervised learning methods, which require sufficient labeled samples [7]. Unfortunately, for the product quality modeling, labeled data are usually scarce. This is because the absence of product quality analyzer makes the product quality be obtained every 1-2 h or longer time interval in a laboratory test manner. Therefore, for most real industrial plants, there are a large number of process data from the distributed control system (DCS) and few product quality data from laboratory. When it is coming to product quality modeling, a great deal of samples will be unlabeled data. Therefore, how to make use of those unlabeled data to establish product quality model becomes an important problem. Such a motivation opens a hot research direction namely semi-supervised learning (SSL) [8, 9] in the product quality modeling.
The goal of the SSL is to enhance the learning performance using supervised information of labeled data and their relationships to unlabeled data. It has been demonstrated that unlabeled data, when used in conjunction with a small set of labeled data, can often considerably improve the learning accuracy. The SSL family includes self-training algorithm [10], generative models algorithm [11], transductive support vector machine (TSVM) algorithm [12], co-training algorithm [13], graph-based algorithm [14] and so on. The co-training is an important methodology [15], and the role of unlabeled data is to help reduce the training effort. Many variants of co-training were developed [16, 17]. Based on clustering and manifold assumptions [18] that consider the nearby points are likely to have the same label, there are lots of efforts to the graph-based SSL [19] in recent years due to its elegant mathematical formulation and effectiveness by mining the intrinsic geometrical structure inferred from both labeled and unlabeled data. There are also many other algorithms constructed with different criteria, such as TSVM [20], and the method based on statistical physics theories [21]. Real performances on many datasets show their ability to solve the regression problem.
The traditional SSL algorithms are batch learning technologies, which require that the whole training data must be stored beforehand and used in each learning process. It is inefficient to handle stream data, as the learner models must be retrained from scratch whenever new data is arrived. For most industrial applications, the data is accumulated by degrees, and large-scale previous data is always removed as the industrial systems cannot afford to store the massive data before learning. As a consequence, online learning is required. However, conventional SSL approaches, e.g. self-training SVM [22], are generally not tailored for online applications.
To tackle this issue, online semi-supervised least square SVM algorithm with manifold regularization has been proposed [23]. By solving the linear algebraic equations (LAEs), the learner model greatly simplifies the training process. But, the parameter matrix of LAEs satisfying the Karush-Kuhn-Tucker (KKT) theorem is also simplified to derive an online version. Therefore, the learning performance may be unsatisfied with some cases. Furthermore, some existing semi-supervised learner models adopt random vector functional link networks (RVFLNs). The derivations of these online learners are based on the recursive least square (RLS) method, which is a tool to deal with stream data. The drawbacks of RLS are that: 1) model parameters are prone to occur the explosion phenomenon; 2) improper selection of parameters will cause the learning process to end before convergence; 3) when there is noise in the data, the constructed model is easy to be unstable. Hence, RLS-based learner models will inherently suffer from the above problems in the actual application.
In order to enable models to capture the time- varying nature [24] of industrial processes, this paper proposes a novel online adaptive semi- supervised RVFLN (OAS-RVFLN) by introducing a L2-fusion term that can smooth the model parameters to prevent dramatical change. The main contributions of this work are summarized as follows.
1) Different from the previous works, the proposed OAS-RVFLN is a unified framework that makes the offline and online learning interchangeable by adding the L2-fusion term in cost function.
2) A fuzzy inference system (FIS) is employed to establish self-adapting mechanism for L2-fusion factor, according to the drift amplitude of the process characteristics, which is reflected by approximate linear dependence (ALD) [25] criteria and relative prediction error.
The paper is outlined as follows. Section 2 describes conventional RVFLN-based online supervised and semi-supervised learning algorithms. Section 3 derives our proposed OAS-RVFLN. Section 4 discusses the performance evaluation. Section 5 presents a case study in a coal dense medium separation process. Finally, conclusions are given in Section 6.
2 Related works
The most popular learner models including online sequential RVFLN (OS-RVFLN) and semi- supervised online sequential RVFLN (SOS-RVFLN) are briefly reviewed in this section.
2.1 OS-RVFLN
As a special type of single-hidden layer feed-forward neural network (SLFN), RVFLN was proposed in the 1990s [26]. RVFLN randomly assigns the input weight and hidden layer biases, and evaluates the output weight by solving a linear optimization issue. It possesses not only a universal approximation ability but also rapid learning speed [27].
Considering a given dataset of training sample, 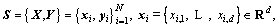 and yi
and yi 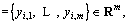 and a RVFLN model with L hidden nodes can be described as follows:
and a RVFLN model with L hidden nodes can be described as follows:
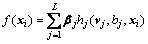 (1)
(1)
where vj and bj are named as hidden-node parameters, which are randomly assigned from adjustable scopes; hj is the activation function of the j-th hidden node; ��j expresses the output weight connecting the j-th hidden node to output node, and it needs to be optimized by solving the following ridge regression issue.
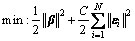
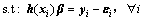 (2)
(2)
where 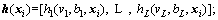
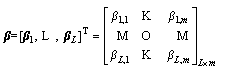
where 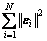 and ||��||2 express the empirical and structural losses, respectively; C is a regularization parameter that can balance the above two losses.
and ||��||2 express the empirical and structural losses, respectively; C is a regularization parameter that can balance the above two losses.
For the firstly given N (N��L) samples, the initial �� can be obtained by using the following batch algorithm:
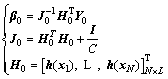 (3)
(3)
where I is a unit matrix; J0 and ��0 are the initialization values of the model, respectively; H0 and Y0 are the initial hidden layer output and training target, respectively.
When the k-th sample block arrives, �� can be updated in the light of the following formulation:
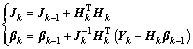 (4)
(4)
where k and k-1 stand for current and previous update time, respectively.
The above online algorithm cannot meet the needs when the labeled data is scarce, so the following online SSL algorithm is proposed.
2.2 SOS-RVFLN
The SOS-RVFLN algorithm is a semi- supervised and online sequential version of the RVFLN. In SSL framework, the labeled data has been denoted as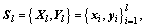 and unlabeled data as
and unlabeled data as 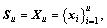 where l and u are the numbers of labeled and unlabeled data, respectively.
where l and u are the numbers of labeled and unlabeled data, respectively.
To take the learning error into account, the cost function of SOS-RVFLN can be formulated as follows:
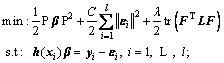
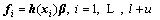 (5)
(5)
where tr(��) denotes the matrix trace; �� is a tradeoff parameter; 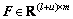 stands for the output matrix of network with its i-th row equal to fi, and m is the dimension of output;
stands for the output matrix of network with its i-th row equal to fi, and m is the dimension of output; 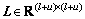 is the graph Laplacian built from both labeled and unlabeled data, and it can be computed as:
is the graph Laplacian built from both labeled and unlabeled data, and it can be computed as:
 (6)
(6)
where W=[wij] is a similarity matrix. wij, which is usually calculated by using Gaussian function,  denotes the pair-wise similarity between two samples xi and xj. The D is a diagonal matrix with its diagonal elements
denotes the pair-wise similarity between two samples xi and xj. The D is a diagonal matrix with its diagonal elements 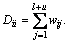
For the firstly given l+u (l+u��L) samples, in which both labeled samples and unlabeled samples are included, the initial �� can be obtained by using the following batch algorithm:
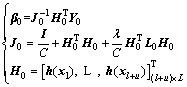 (7)
(7)
where L0 and ��0 are the initial graph Laplacian and output weight, respectively; Y0 is the initial augmented training target with its first l rows equal to Yl and the rest equal to 0.
Let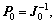 and SOS-RVFLN recursively update P and �� according to following equations:
and SOS-RVFLN recursively update P and �� according to following equations:
 (8)
(8)
From the derivations of above learner models, it can be seen that the existing online algorithms are recursive versions of least square algorithms. It is difficult to achieve satisfactory in industrial applications due to the inherent shortcomings of recursive least square (RLS). This paper attempts to develop a novel online SSL algorithm without using RLS technology.
3 Proposed OAS-RVFLN
This section presents OAS-RVFLN in detail, and gives a design method on a key parameter, namely L2-fusion factor.
3.1 L2-fusion term
Due to the fact that the industrial processes are of slow time-varying nature, the regression coefficients within the adjacent times should vary smoothly. Therefore, the weight deviation constraint 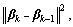 namely L2-fusion term, is added in the cost function to make the model parameters update smoothly. This constraint aims at preventing the model changing dramatically and enhancing the learning stability in slow time-varying environments.
namely L2-fusion term, is added in the cost function to make the model parameters update smoothly. This constraint aims at preventing the model changing dramatically and enhancing the learning stability in slow time-varying environments.
When given different sizes of online learning samples, the idea similar to the batch learning methods is adopted here. Denote Sl and Su as in SOS-RVFLN and them, the cost function in Eq. (5) can be modified to further improve the performance. When the k-th sample block arrives, the model parameters can be updated by solving the following constrained optimization issue:
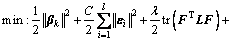
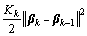
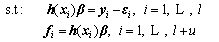 (9)
(9)
where Kk denotes L2-fusion factor that is an adjustable coefficient.
Substitute the constraints into the cost function, and rewrite the above formulation in a matrix form:
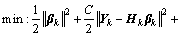
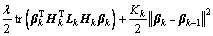 (10)
(10)
where 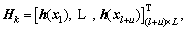 and Lk is the graph Laplacian constructed for the k-th sample block.
and Lk is the graph Laplacian constructed for the k-th sample block.
3.2 Learning algorithm
According to Eq. (10), the online learning form can be directly derived. First, differentiate Eq. (10) with respect to ��:
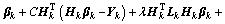
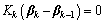 (11)
(11)
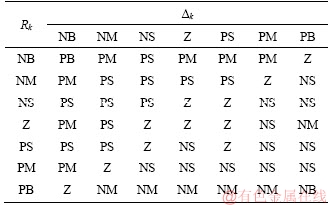
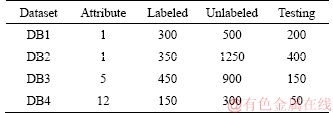
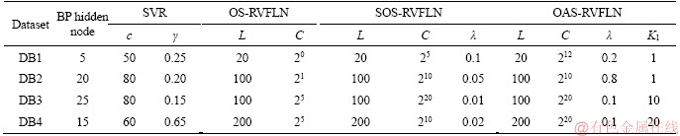
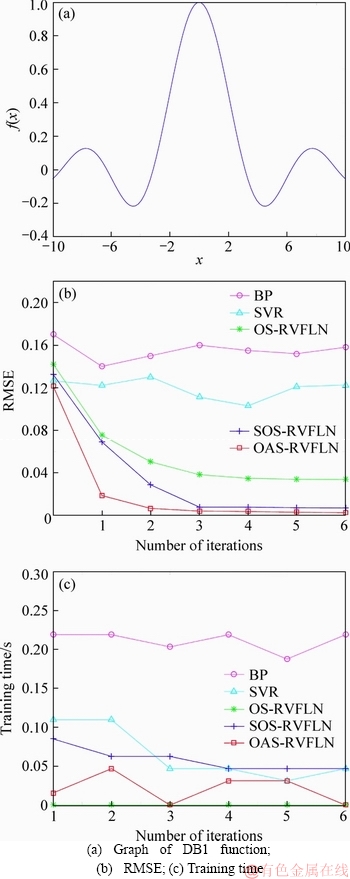
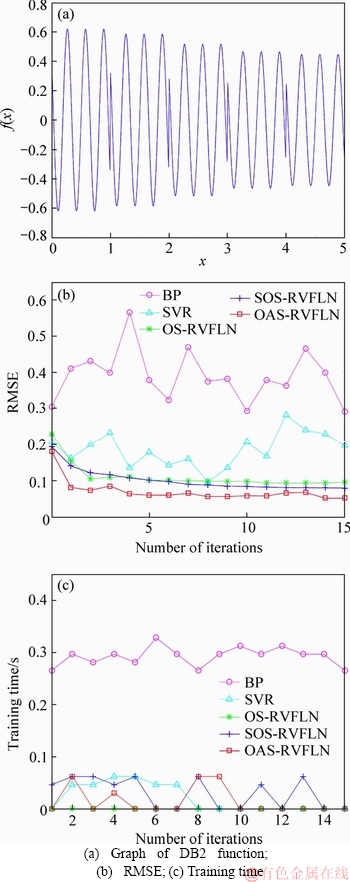
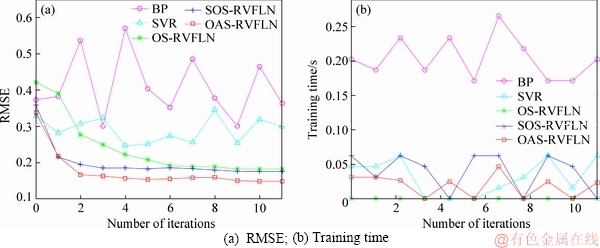
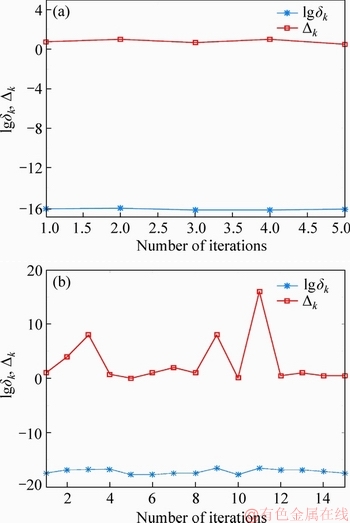
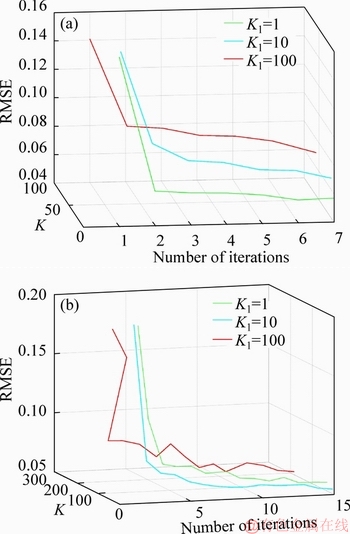
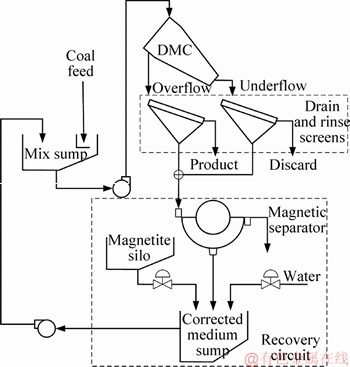
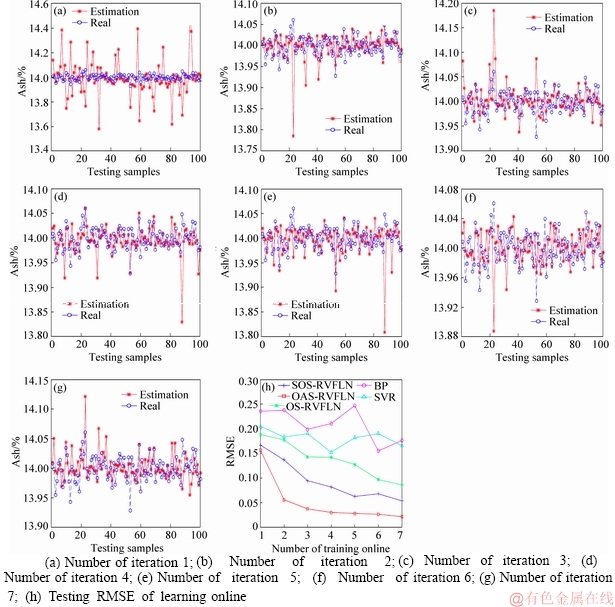
1) l+u If the number of training samples l+u is smaller than the number of hidden neurons L, then Hk will have more columns than rows. This is an underdetermined least squares problem, which may have numerous solutions. To handle this problem, we restrict ��k to be a linear combination of the rows of Hk. When Hk has more columns than rows and is of full row rank, where By substituting Eq. (12) to Eq. (13), we have Then, By substituting Eq. (15) to Eq. (12), we can get where Il+u is an identity matrix of dimension l+u. 2) l+u��L When l+u>L, Hk will be of full column rank. In this case, Eq. (11) is overdetermined. We have the following closed form solution for Eq. (11). where IL is an identity matrix of dimension L. Therefore, the online learning forms of output weight are briefed as follows: If K0=0, we will get the following offline algorithm to calculate the initial output weight ��0. where N0 is the number of initial samples; IN0 is an identity matrix of dimension N0; L0, H0 and ��0 are the initial graph Laplacian, hidden output and output weight, respectively. Similar to OS-RVFLN, the regularization parameter C is fully utilized to avoid over-fitting problem [28]. In the proposed algorithm, Kk is of extremely importance. When Kk=0, ��k will be obtained based on only the k-th sample block, which is equivalent to batch learning. If Kk is set as a large constant, ��k will be enforced to update near the previous value. Therefore, non-zero setting for L2-fusion factor can achieve the smoothness of parameter update. Consequently, by changing the Kk, the degree of model smoothness can be well controlled simultaneously. The following section will give a fuzzy inference system (FIS) based self-adapting mechanism to select this L2-fusion factor online. 3.3 FIS-based self-adapting L2-fusion factor Model accuracy and process drift amplitude are two key influence factors in online learning. This paper adopts root mean square error (RMSE) and approximate linear dependence (ALD) criterion to express those two factors respectively, and then employs a FIS to adaptively adjust the L2-fusion factor online. ALD criterion is used to measure the linear relationship between new sample and previous ones as follows: where ��k represents data change and linear dependence, which indicates the process drift amplitude; xk and where Rk and ��k stand for the model accuracy and process drift amplitude, respectively, which can be used to adjust the L2-fusion factor. For instance, when ��k is larger, the linear dependence degree is poor. It is thus necessary to set the Kk as a smaller value to attenuate the smoothness constraint and vice versa. In addition, if Rk becomes larger, the Kk should be also decreased to make the model get more information from the new data and vice versa. The relationship between Kk and these two indices is a complex non-linear function, and it is difficult to establish the precise mathematical function. To realize the self-adjustment of Kk, several experiences are summarized to expert rule, then a FIS-based self-adapting algorithm is established. When RMSEk/RMSEk-1<1, we keep Kk unchanged; otherwise, we adjust Kk according to following equation: where F stands for fuzzy inference rules, which are shown in Table 1. The basic domain of ��k and Rk are [0, 20] and [-1, 1], respectively, which are both divided into 7 linguistic variables of {NB, NM, NS, Z, PS, PM, PB}, and the fuzzy variables all satisfy the distribution of triangular membership function. The fusion output is also divided into 7 linguistic variables, and its basic domain is {0.5, 1, 5, 10, 15, 20, 25}. The proposed algorithm is summarized in Algorithm 1. Table 1 Fuzzy inference rules for F Algorithm 1 By making full use of unlabeled data information, regularization parameter and the self-adapting parameter, our proposed algorithm provides an effective solution for the online learning problems. 4 Performance evaluation To effectively verify the model performance, comparisons among our proposed learner model, BP neural network, support vector regression (SVR), OS-RVFLN, and SOS-RVFLN are made through four benchmark datasets including two function approximations and two real world regression datasets. DB1 was generated by adding small uniform noise on the sinc function: The training set has 1000 points randomly generated from the uniform distribution [-10, 10]. The testing set, with size of 200, is generated from a regularly spaced grid on [-10, 10]. DB2 was generated by simulating non-linear and slow time-varying characteristics of complex industrial processes: k=1, 1.5, 2, 2.5, �� (24) The training dataset has 2000 points randomly generated from the uniform distribution [-10, 10]. The testing set, of size 400, is generated from a regularly spaced grid on [-10, 10]. DB3 (airfoil self-noise) is downloaded from University of California at Irvine (UCI) dataset repository. It is obtained from a series of aerodynamic and acoustic tests of two- and three-dimensional airfoil blade sections conducted in an anechoic wind tunnel. The whole dataset contains 1506 observations with 5 input and 1 output variables. We randomly selected about 90% samples as the training set while the test set consists of the left 10%. DB4 (forestfires) also comes from UCI dataset repository, and it is related to socio-demographic data, environmental factors, health status, and life habits. The whole dataset contains 517 observations with 12 input and 1 output variables. Both the training and testing datasets are selected in the same way as DB3. Every training set is further partitioned into labeled set and unlabeled set. The number of labeled, unlabeled, testing data and input attribution of all the datasets are listed in Table 2. All experiments on all the datasets are carried out in MATLAB R2016a on a 3.40 GHz machine with 8 GB of memory. Each model is assessed by means of RMSE and training time, which are obtained by 50 independent trials conducted. Table 2 Specification of datasets Selecting suitable parameters on each dataset is fundamental for a proper behavior of the algorithms. It is a sensible choice to employ cross-validation method for determining the algorithms parameters. For the neural networks, the number of hidden nodes L is extracted from [10, 1000]; the hidden-node parameters �� are randomly selected in the interval {0.5��j}, j=-10, -9, ��, 10; the tradeoff parameter �� is assigned from the linear sequence set {0, 0.05, ��, 1}; the penalty coefficient C is randomly selected from the exponential sequence set {10-20, 10-19, ��, 1020}; the K1 is selected from {1, 10, 20, ��, 100}.Table 3 shows the optimal parameters of each learner model with respect to each dataset. In the experimental study, the different numbers of labeled and unlabeled samples are enrolled to learn for distinct datasets. The results can be found from Figures 1-4. It can be observed from Figures 1(b), 2(b), 3(a) and 4(a) that OAS-RVFLN maintains the best accuracy for all datasets, although the other four learner models achieve their own best capability by employing suitable parameters. As observed from the results, OAS-RVFLN almost has much fast learning speed than others for the majority of datasets, except OS-RVFLN. Inability to use unlabeled data enables OS-RVFLN obtain the least computational consumption but relatively poor model performance. From Figures 1-4, it is worth noting that with the increase of online learning times, the trends of all algorithms are relatively stable except BP and SVR, which cannot utilize the information learned online. When given the same number of labeled and unlabeled samples, OAS-RVFLN almost has better results in both batch and online learning. For the sake of evaluating the computational efficiency of learner models, the training time is presented in Figures 1(c), 2(c), 3(b) and 4(b). It can be observed that OAS-RVFLN is similar to OS-RVFLN, SOS-RVFLN and SVR in training time, and several times faster than BP. OAS-RVFLN has not shown evident advantage over SOS-RVFLN, OS-RVFLN and SVR in terms of efficiency, due to the fact that the matrix multiplication HTLH or LHHT is relatively time consuming and dominated the computational cost. For SOS-RVFLN, the calculation of intermediate matrix makes it slower than OAS-RVFLN. To show the changes of training samples, ��k and ��k for DB1 and DB2 are calculated as shown in Figure 5. For convenience, the logarithm operation is used to represent ��k. It can be observed that lg��k in DB2 is larger than that in DB1, which indicates the data of DB2 change more dramatically. ��k jumps almost from 0 to 16 at the 11th iteration in DB2, while ��k just jumps from 0.5 to 1 in the whole online learning process for DB1, which also indicates the tremendous time-varying nature in DB2. Therefore, the sensitivity of ALD to data change can be used to control the model update. Table 3 Algorithm parameters Figure 1 Comparison of the testing RMSE and training time for DB1, set initial labeled samples 20, unlabeled samples 100, and increase 45 labeled samples, 65 unlabeled samples in each iteration of online learning process: Figure 2 Comparison of testing RMSE and training time for DB2, set initial labeled samples 50, unlabeled samples 100, and increase 20 labeled samples, 75 unlabeled samples in each iteration of online learning process: Figure 3 Comparison of testing RMSE and training time for DB3, set initial labeled samples 80, unlabeled samples 100, and increase 30 labeled samples, 70 unlabeled samples in each iteration of online learning process: Figure 4 Comparison of testing RMSE and training time for DB4, set initial labeled samples 20, unlabeled samples 40, and increase 10 labeled samples, 20 unlabeled samples in each iteration of online learning process: Figure 6 compares the learner model performance while the number of iterations increases under K1 of 1, 10, and 100, respectively. When K1=1, Kk is adjusted adaptively in the online learning process according to data. Such superiority is also reflected in the case of K1=10 and K1=100. Therefore, we can obtain that Kk has the robustness, and the proposed algorithm has strong practical application. Based on RMSE, comparisons of the offline, online prediction accuracy and standard deviations (Dev) are conducted in Table 4. From Figures 1-4 and Table 4, it can be seen that OAS-RVFLN has less RMSE and Dev in most cases. Therefore, the experiment result shows the proposed OAS-RVFLN can provide a practical feasible online training solution. 5 Industrial application In this section, we make a further investigation on the advantages of proposed learner model in coal dense medium separation (CDMS) process [29], which is one of the most direct and effective coal cleaning procedures. A classical CDMS process as shown in Figure 7 mainly includes mix sump, dense medium cyclone (DMC), magnetite silo, drain and rinse screens, magnetic separator, corrected medium sump, magnetite silo, and several actuators and instruments. Raw coal after being deslimed and dewatered is first sent to the mix sump and mixed with dense medium into slurry, followed by being fed into the DMC. Under the action of gravity and centrifugal force, the mixed slurry in the DMC is separated into overflow and underflow. Minerals, lighter than the medium float and those denser sinks, exist at the top and bottom of the DMC, respectively. The overflow and underflow are both taken to the drain and rinse screens, in which they are carried to the recovery circuit. The recovered medium flows into magnetic separator, extracted by screening, and then is sent to the corrected medium sump. The recovered medium is blended with concentrated medium and water in there to maintain the density of mixture, dense medium, within a certain range. The valve and screw conveyor are controlled to add water and magnetite, respectively. Table 4 Prediction results Figure 5 Comparison of performance parameters lg��k and ��k for (a) DB1 and (b) DB2 Figure 6 Testing RMSE with increase of iterations and change of K under K1=1, 10 and 100 for (a) DB1 and (b) DB2 Figure 7 Flow diagram of typical CDMS process From the practical experiences, we can obtain that ash content y is a principal criterion for evaluating the coal quality, which is influenced by the mass feedrate of the ore x1 (kg/s), dense medium density x2 (kg/m3), and feed pressure x3 (MPa). The data model constructed is to achieve the following nonlinear mapping: {y}��{x1, x2, x3}. The CDMS dataset is obtained from an industrial control system in practical CDMS process. In real plant, the control system collects a large amount of process data about x1, x2, x3 in real-time, but the ash content y is obtained by manual assay, which makes only few labeled data. In this study, the collected 1200 samples are divided into 1100 training samples (100 labeled and 1000 unlabeled) and 100 testing samples. All the comparative learner models, i.e., BP, SVR, OS-RVFLN, SOS-RVFLN and OAS-RVFLN, are applied to establish the data driven quality model and simulated in the same environment as that in the performance evaluation section.Figures 8(a)-(g) present one result of our trials, but similar results can be obtained for the other trials.Figure 8(h) presents the RMSE of all learner models. The worst performance is obtained in BP followed by SVR. Owing to the use of unlabeled samples information, SOS-RVFLN performs better than OS-RVFLN, but it is inferior to OAS-RVFLN. There is no doubt that the best performance is achieved by our proposed OAS-RVFLN in terms of estimation accuracy. It is known from the above results and analysis, this research can enrich the semi-supervised learning methodology, and provide some new ideas. The practical industrial applications illustrate that the proposed learner model can effectively address the data driven quality modeling problems in process industries. Figure 8 Test results of CDMS process: 6 Conclusions This paper presents a novel effective online semi-supervised learner model, called OAS- RVFLN, to estimate the product quality of process industries through learning from data streams with both labeled and unlabeled samples. By introducing the L2-fusion term, the new learner model can smooth the update of regression coefficient. Besides, the fuzzy inference system is employed to design a self-adapting mechanism to control the update smoothness. The model performance is evaluated by comparing with four traditional learner models. The results demonstrate the proposed OAS-RVFLN can achieve higher accuracy and faster learning speed in different benchmark issues than the other four models. Finally, a data driven product quality model of CDMS process is successfully established based on OAS-RVFLN. In the further study, we would like to apply this new learner model to different potential engineering applications with distinct complexities and properties. References [1] SHEN Ling, HE Jian-jun, YU Shou-yi, GUI Wei-hua. Temperature control for thermal treatment of aluminum alloy in a large-scale vertical quench furnace [J]. Journal of Central South University, 2016, 23(7): 1719-1728. [2] CHAI Tian-you, QIN S J, WANG Hong. Optimal operational control for complex industrial processes [J]. Annual Reviews in Control, 2014, 38(1): 81-92. [3] ZHOU Pin, DAI Wei, CHAI Tian-you. Multivariable disturbance observer based advanced feedback control design and its application to a grinding circuit [J]. IEEE Transactions on Control Systems Technology, 2014, 22(4): 1474-1485. [4] ZHANG Tong, CHEN C L P, CHEN Long, XU Xiang-min, HU Bin. Design of highly nonlinear substitution boxes based on I-Ching operators [J]. IEEE Transactions on Cybernetics, 2018, 48(12): 3349-3358. [5] ZHANG Jing-xin, CHEN Hao, CHEN Song-hang, HONG Xia. An improved mixture of probabilistic PCA for nonlinear data-driven process monitoring [J]. IEEE Transactions on Cybernetics, 2019, 49(1): 198-210. [6] WANG David, LIU Jun, SRINIVASAN R. Data-driven soft-sensor approach for quality prediction in a refining process [J]. IEEE Transactions on Industrial Informatics, 2010, 6(1): 11-17. [7] ZHOU Ping, LU Shao-wen, CHAI Tian-you. Data-driven soft-sensor modeling for product quality estimation using case-based reasoning and fuzzy-similarity rough sets [J]. IEEE Transactions on Automation Science and Engineering, 2014, 11(4): 992-1003. [8] CHAPELLE O, LKOPF B S, ALEXANDER Z. Semi-supervised learning [J]. IEEE Transactions on Neural Networks, 2009, 20: 542-542. [9] ZHU Xiao-jin. Semi-supervised learning literature survey [R]. Madison: University of Wisconsin, 2005. [10] PIROONSUP N, SINTHUPINYO S. Analysis of training data using clustering to improve semi-supervised self- training [J]. Knowledge-Based Systems, 2018, 143: 65-80. [11] FUJINO A, UEDA N, SAITO K. A hybrid generative/discriminative classifier design for semi- supervised learning [J]. Transactions of the Japanese Society for Artificial Intelligence, 2006, 21(3): 301-309. [12] JOACHIMS T. Transductive inference for text classification using support vector machines [C]// Proceedings of the 16th Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc, 1999: 200-209. [13] BLUM A, MITCHELL T. Combining labeled and unlabeled data with co-training [C]// Proceedings of the 11th Computational Learning Theory. New York, USA: ACM Press, 1998, 98: 92-100. [14] BELKIN M, NIYOGI P. Laplacian eigenmaps and spectral techniques for embedding and clustering [J]. Advances in Neural Information Processing Systems, 2001, 14: 585-591. [15] PANICKER R C, PUTHUSSERYPADY S, SUN Ying. Adaptation in P300 brain-computer interfaces: A two-classifier cotraining approach [J]. IEEE Transactions on Biomedical Engineering, 2010, 57(12): 2927-2935. [16] DASGUPTA S, LITTMAN M L, DAVID M. Pac generalization bounds for co-training [C]// Proceedings of the 14th Neural Information Processing Systems. Massachusetts: MIT Press, 2001: 1-8. [17] BALCAN M F, BLUM A, YANG K. Co-training and expansion: Towards bridging theory and practice [C]// Proceedings of the Neural Information Processing Systems. Massachusetts: MIT Press, 2004: 89-96. [18] TIAN Z, KUANG R. Global linear neighborhoods for efficient label propagation [C]// Proceedings of the 2012 SIAM International Conference on Data Mining. Philadelphia, USA: Society for Industrial and Applied Mathematics, 2013: 863-872. [19] NIE Fei-ping, XIANG Shi-ming, LIU Yun, ZHANG Chang-shui. A general-graph based semi-supervised learning with novel class discovery [J]. Neural Computing and Applications, 2010, 19(4): 549-555. [20] JOACHIMS T. Transductive inference for text classification using support vector machines [C]// Proceedings of the 16th International Conference on Machine Learning. San Francisco: MarganKaufmann Publishers Inc, 1999: 200-209. [21] UEFFING N, HAFFARI G, SARKAR A. Semi-supervised model adaptation for statistical machine translation [J]. Machine Translation, 2007, 21(2): 77-94. [22] LI Yuan-qing, GUAN Cun-tai, LI Hui-qi, CHIN Zheng-yang. A self-training semi-supervised SVM algorithm and its application in an EEG-based brain computer interface speller system [J]. Pattern Recognition Letters, 2008, 29(9): 1285-1294. [23] GOLDBERG A B, LI Ming, ZHU Xiao-jin. Online manifold regularization: a new learning setting and empirical study [C]// Proceedings of the European Conference on Machine Learning & Knowledge Discovery in Databases. Berlin: Springer-Verlag, 2008: 393-407. [24] GEORGAKIS C. Design of dynamic experiments: A data-driven methodology for the optimization of time-varying processes [J]. Industrial & Engineering Chemistry Research, 2013, 52(35): 12369-12382. [25] TANG Jian, YU Wen, CHAI Tian-you, ZHAO Li-jie. On-line principal component analysis with application to process modeling [J]. Neurocomputing, 2012, 82: 167-178. [26] PAO Y H, TAKEFUJI Y. Functional-link net computing: Theory, system architecture, and functionalities [J]. Computer, 1992, 25(5): 76-79. [27] SCARDAPANE S, WANG Dian-hui. Randomness in neural networks: An overview [J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2017, 7(2): 1-18. [28] GALLAGHER N B, WISE B M, BUTLER S W, WHITE D D J, BARNA G G. Development and benchmarking of multivariate statistical process control tools for a semiconductor etch process: improving robustness through model updating [J]. IFAC Proceedings Volumes, 1997, 30(9): 79-84. [29] ZHANG Li-jun, XIA Xiao-hua, ZHU Bing. A dual-loop control system for dense medium coal washing processes with sampled and delayed measurements [J]. IEEE Transactions on Control Systems Technology, 2017, 25(6): 2211-2218. (Edited by ZHENG Yu-tong) ���ĵ��� �������Ȩ���������������Ӧ��ලѧϰ�㷨�����ڹ�ҵ���̲�Ʒ���������е�Ӧ�� ժҪ����ҵ���̵IJ�Ʒ����������������⣬���½�ģ�����д��ڴ������ޱ����������˽�����Ʒ����������ģ����Ҫ���ð�ලѧϰ(SSL)��������ҵ����ͨ��������ʱ�����ԣ����������������ģ��ҲӦ��֮�ı�������Ҿ���һ����ƽ���ԡ������һ���ԣ��������Ȩ������RVFLN�������һ����ӱ��������Ӧ��ලѧϰ�㷨����OAS-RVFLN�������㷨ͨ������L2�ں������Ȩֵƫ��Լ���������ߺ�����ѧϰ��ͳһ����ʹģ�Ͳ������Ż�����õ�ƽ���ԡ��ڻ����Ժ��������ݼ��ϵ�ʵ���о������������OAS-RVFLN��ѧϰ�ٶȺ;��Ⱦ����ڴ�ͳ������������Ӧ����ú̿��ҵ���ؽ���ѡú���̣����Ʋ�Ʒ�ҷ֣���һ����֤������Ч���Լ���ҵӦ�õ�DZ���� �ؼ��ʣ���ලѧϰ�� L2�ں�� ��������Ӧ�� ���Ȩ������ Foundation item: Projects(61603393, 61973306) supported in part by the National Natural Science Foundation of China; Project(BK20160275) supported by the Natural Science Foundation of Jiangsu Province, China; Projects(2015M581885, 2018T110571) supported by the Postdoctoral Science Foundation of China; Project(PAL-N201706) supported by the Open Project Foundation of State Key Laboratory of Synthetical Automation for Process Industries of Northeastern University, China Received date: 2018-12-16; Accepted date: 2019-07-03 Corresponding author: DAI Wei, PhD, Associate Professor; Tel: +86-13952235853; E-mail: daiweineu@126.com, weidai@cumt.edu.cn; ORCID: 0000-0003-3057-7225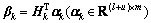 (12)
(12)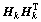 is invertible. Multiplying both side of Eq. (11) by
is invertible. Multiplying both side of Eq. (11) by  we get
we get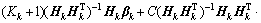
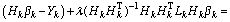
 (13)
(13)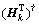 is the Moore-Penrose generalized inverse of
is the Moore-Penrose generalized inverse of 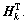
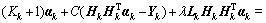 (14)
(14)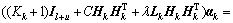
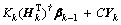 (15)
(15) (16)
(16)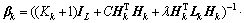
 (17)
(17) (18)
(18) (19)
(19) (20)
(20)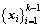 represent the new data and old modeling data, respectively. The larger ��k means that the current process characteristics have changed greatly; otherwise, it means little fluctuate. To realize the self-adjustment of L2-fusion factor, we first calculate the relative RMSE (Rk) and relative ALD (��k) as follows:
represent the new data and old modeling data, respectively. The larger ��k means that the current process characteristics have changed greatly; otherwise, it means little fluctuate. To realize the self-adjustment of L2-fusion factor, we first calculate the relative RMSE (Rk) and relative ALD (��k) as follows: (21)
(21)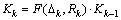 (22)
(22)

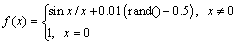 (23)
(23)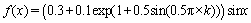 ,
,


Abstract: Direct online measurement on product quality of industrial processes is difficult to be realized, which leads to a large number of unlabeled samples in modeling data. Therefore, it needs to employ semi-supervised learning (SSL) method to establish the soft sensor model of product quality. Considering the slow time-varying characteristic of industrial processes, the model parameters should be updated smoothly. According to this characteristic, this paper proposes an online adaptive semi-supervised learning algorithm based on random vector functional link network (RVFLN), denoted as OAS-RVFLN. By introducing a L2-fusion term that can be seen a weight deviation constraint, the proposed algorithm unifies the offline and online learning, and achieves smoothness of model parameter update. Empirical evaluations both on benchmark testing functions and datasets reveal that the proposed OAS-RVFLN can outperform the conventional methods in learning speed and accuracy. Finally, the OAS-RVFLN is applied to the coal dense medium separation process in coal industry to estimate the ash content of coal product, which further verifies its effectiveness and potential of industrial application.
