
��¯�������̵�����Ԥ�⽨ģ
���ۣ�����Ȼ�����ܾ������������Ŀ�
(�㽭��ѧ ��������ѧԺ���㽭 ���ݣ�310027)
ժ Ҫ��
�̵ĸ����ԡ��������Լ�ǿ��ϡ���������Ѳ������ص㣬�����ˮ�躬�������ܸ��϶����Ԥ��ģ�ͶԸ�¯�������̽��н�ģ������ϵͳ��Ϊ�����֣��������߽�����ͬ��������ˮ�躬���Ķ����Ԥ��ģ�ͣ�Ȼ������ģ��������������ģ�������ʵ�������ģ��Ȩ��֮��Ķ�Ӧ��ϵ�����ж�ģ�������ںϣ����ɸ���ģ�ͣ�������������ߵ������Ż�Ԥ����̡��о�������������ô˷����������ڶ̣��Ա��ض���ı仯�н�ǿ��³���ԣ���ϵͳԤ�����С���ܹ�������Ӧ�����ı仯��ʵ���Ժá�
�ؼ��ʣ�
��¯����Ԫ��������С����֧����������ģ�������������ں�ģ����
��ͼ����ţ�TP273 ���ױ�־�룺A ���±�ţ�1672-7207(2012)05-1787-08
Intelligent predictive modeling of blast furnace system
LIU Hui, LI Pei-ran, BAO Zhe-jing, WANG Chao, YAN Wen-jun
(Institute of Automation, Zhejiang University, Hangzhou 310027, China)
Abstract: In order to predict the production process of complicated nonlinear blast furnace (BF), the intelligent mixed multi-variable predictive models are proposed. The prediction strategy including two parts is used: the models reflecting different working conditions are established by adopting the support vector machine (SVM) in offline part. Then fuzzy reasoning is employed to train and derive the weight of every model, multiplying those weights by the corresponding models gives the actual prediction output. And the online correction is called to adjust those weights to optimize the prediction system. The intelligent mixed prediction model has been successfully applied and validated in several real-life iron-making scenarios and clearly demonstrates its effectiveness for silicon content prediction in the BF with the less time consumption and the robustness to the change of working conditions.
Key words: blast furnace; PCA; LSSVM; fuzzy reasoning; intelligent mixed model
���Ź��õķ�չ����������ᾭ���е���Ҫ��Խ��Խͻ�Գ��������и�¯����ռ������ҵ��95%��ʹ�ø�¯����ұ�������е���Ҫ���ڣ�����¯¯�µ��ʺ����ȶ����Ǹ�¯��ˮ�����ı�֤���Ǹ�¯���١��߲����ͺĵı�֤[1]����¯������ָ��¯����ʱ��¯��װ������ʯ����̿���������ۼ�(ʯ��ʯ)����λ��¯���²���¯�ܵķ�ڴ��뾭Ԥ�ȵĿ������ڸ����£�һ���ֽ�̿(�еĸ�¯Ҳ�紵ú�ۡ����͡���Ȼ���ȸ���ȼ��)�е�̼ͬ��������е���ȼ�����ɵ�һ����̼����¯��һ����̼���������г�ȥ����ʯ�е������Ӷ���ԭ�õ����Ͷ�����̼�����Ϊ��ӻ�ԭ��Ӧ��һ�㷢���ڸ�¯���¶ȵ���1 100 ���ʱ����һ���ֽ�ֱ̿�����������������Ӧ��ԭ����������Ϊֱ�ӻ�ԭ��Ӧ��һ���ڸ�¯�нӽ������¶���ߵĵط�������ֱ�ӻ�ԭ��Ӧ������һ�������������ﱻ������ԭ�����ɵ�ˮһ���ֱ�̼��һ����̼��ԭΪ����������һ�����ڸ�¯�ϲ�������ʯ�ͽ�̿���գ��Խ���¯¯�ڵ��¶ȣ�������¯����������ˮ�ӳ����ڷų�������ʯ��δ����ԭ�����ʺ�ʯ��ʯ���ۼ��������¯�����������ų���������ú����¯������������������Ϊ�ȷ�¯������¯����¯����¯�ȵ�ȼ��[2]����ʵ�����������У����ڸ�¯�ṹ�ĸ�����ʹ��ֱ�Ӳ�����¯�ڲ��¶ȳ��ֲ�������ѣ���¯������ˮ������������أ��ʿ�������ˮ�躬��������¯¯�£�����ˮ�躬��������һ���ķ�Χ�ھͳ�Ϊ�˸�¯�о�����Ҫ���ݡ�Ŀǰ�������о��ıȽ϶���ǽ�����¯��ר��ϵͳ�������ձ�����ˮ���ġ�ADVANCED GO-STOPϵͳ���������������˾��ר��ϵͳ�Լ��������ȵĸ�¯�쳣¯��������ר��ϵͳ��[3]����������ר��ϵͳҲ����һЩ���⣺���ȣ�����ȷ����Ҫȡ����֪ʶ���֪ʶ���ټ���ȷ�ʣ���ˣ�ר��ϵͳ�ɹ����Ҫ�������ľ������̶ȣ���Σ�֪ʶ������ݡ�����һ����б���¯���ص㣬���ڸ�¯����IJ��죬֪ʶ������ݡ�������Ҫ�ܴ�ĸı䣬ϵͳ��ֲ�����Ϊ�˿˷���Щȱ�㣬��������������ܸ���ģ�ͣ�����ʷ���ݽ���Ԥ����������SVM������ͬ�����µ���ˮ�躬��Ԥ��ģ�ͣ�Ȼ��Ӧ��ģ����������ҳ���ģ��Ȩ�������������ģ�����֮��Ĺ�ϵ���Ӷ��õ���ͬʱ�̸���ģ�͵�Ȩ�أ����ж�ģ�͵������ںϣ������õ�����Ԥ��ģ�Ͳ��������ߵ������Ա���ƺ��Ż���¯�������̡�
1 ��¯������������Ԥ����
1.1 �������̽�ģ���
������ģ���̿������¼���������ɣ���������ģ�顢���ݴ���ģ�顢������ģ��ȷ��ģ�顢ģ����ģ�顣
��������ģ���ڻ���㹻�����ʷ���ݺ����Щ���ݽ��з�������ȡ���ܹ���ӳ��¯�������������ĵ㣬����ͬ�Ĺ�����
���ݴ���ģ����ݸ��������IJ�ͬ�ص�������ݽ����˲�ȥ�롢������Ԥ������
������ģ��ȷ��ģ������SVM�ֱ�Ը���������ʷ���ݽ��н�ģ���õ������������Ͼ���Ҫ��� ģ�ͣ�
ģ����ģ������ģ���������õ���ģ�͵�Ȩ��ϵ�������ж�ģ�͵��������ϡ�
��������ģ�����ʵ������븴��ģ�����֮������������ģ��Ȩ�ء�
��������ĸ�¯�������̵�ģ���Ǹ���ұ���¯ϵͳ���ֳ������Լ�ϵͳ���ջ���������SVM�����IJ�ͬ�����µĶ����ģ�͡�������ģ������ͼ1 ��ʾ��
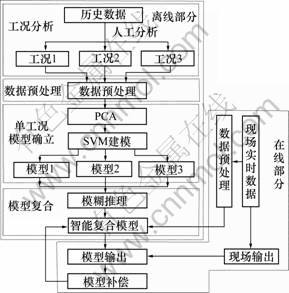
ͼ1 ���ܸ���ģ������ͼ
Fig.1 Flow of intelligent mixed predictive model
1.2 ��������
Ϊ�˻�ø��Ӿ�ȷ�ĸ�¯����ģ�ͣ����Ļ��ڶԴ����ĸ�¯����������ʷ���ݵķ���������ר�Ҿ������ˮSi��������ʷ���ݣ����ָø�¯һ���ȶ���3�������㣬�����¡����º͵��£����������Si������ͼ2��ʾ��
1.3 ����Ԥ����
��¯��ˮ�躬���ܵ��ڶ����ص�Ӱ�죬����ר�Ҿ���¯�½ϵ�ʱһ��ѡ���Ϊ���е�7�������������������¡���ѹ����ú���������������ԡ�¯�� ѹ����
���ڸ�¯���ݵIJ���ʱ������һ������������ͷ�ѹ�ȱ���ÿ��1 s����1�Σ�����ˮ�躬��������ÿ¯����ʱ����1�Σ�������Ҫ�Ƚ����в����õ������ݻ�Ϊͬһ����ʱ������
�������ڲ��������п��ܻ���������š����������ȵ�������ɲ����õ������ݰ������������Բ��û����˲����������ݽ���Ԥ���������õ��������ߵİ����ߣ�ȡ�����������°����ߵ�ƽ���õ��������ݡ�ͼ3��ʾΪ����ú����������������3������Ϊ���������˾����˲������ʷ�������ߡ�
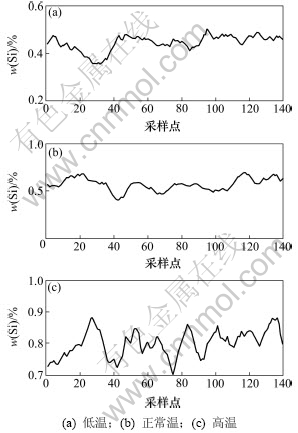
ͼ2 �������µ�Si����
Fig.2 Content of Si in every work condition
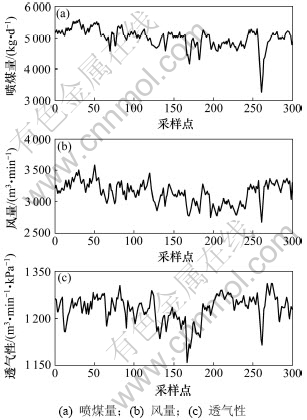
ͼ3 �����˲��������
Fig.3 Filtered parameter data
2 ������ģ�͵Ľ���
2.1 ��Ԫ����
��Ԫ�����Ƕ�Ԫͳ���е�һ�������ھ������ý�ά��˼�룬�ڲ���ʧ��Ҫ��Ϣ��ǰ����ѡ����ٵļ����ۺϱ�������ԭ���϶�ı��������ų�ԭ��Ϣ����ص��IJ���[4-5]����֧��������(SVM)��Vapnik��[6-8]������������ϵ�����ýṹ������С��ԭ�������ѵ�����ͷ����������ڽ��С�����������ԡ���ά�����ֲ���Сֵ��������ռ���ơ���¯�½ϵ���һ����Ϊ����������ģ�ͽ��������������¡�
����x=(x1, x2, ��, xn)T��n=7������7�������ľ������������ʷ���ݣ��������ϵ������R=(rij)7��7��������øþ�������ֵ��1, ��2, ��, ��7����ͼ4��ʾ���������ʾ���ɾ���ı�����������Ϊ������ÿ��������Ӧ������ֵ�Ӵ�С���С�
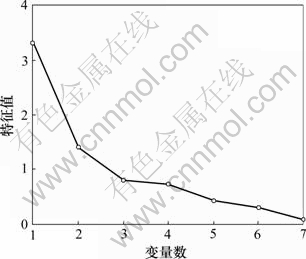
ͼ4 ����������Ӧ������ֵ
Fig.4 Eigenvalues of components
�ɸ�������������ֵ������ø���������ˮ�躬���Ĺ�����![]() ���䷽��ٷֱ����1��ʾ��
���䷽��ٷֱ����1��ʾ��
һ����˵��ѡ�����������2�ַ�����һ����ѡ�����ʴ���1�����б�����һ����ѡ�������ۻ�����85%�����б������ڴ˸���ģ�;���ѡ�����������
��1 �ɷַ���ٷֱ�
Table 1 Component of variance %

����ѡ���������ı����õ����ӵ÷�ϵ���Ӷ��õ���Ӧ���ɷֱ���ʽ��������Ϊ���룬����֧����������������ˮ�躬��֮�����ѧģ�ͣ�������ģ�;��ȣ�������Ҫ����Ϊֹ��������Ҫ��ľ��ȣ������ѡ��������С�ı�����
2.2 ֧����������ģ
����������������![]() ����ϣ�x��ʾ�������������ӵ����ɷֺ������ر�ʾ����f(��)�ĸ��Ӷȣ���ع������ת��Ϊ�����С���պ���
����ϣ�x��ʾ�������������ӵ����ɷֺ������ر�ʾ����f(��)�ĸ��Ӷȣ���ع������ת��Ϊ�����С���պ���![]() �����У�lΪ��������L(��)Ϊʵ�����yi���������f(xi)֮���ֵ����ʧ����[9]��
�����У�lΪ��������L(��)Ϊʵ�����yi���������f(xi)֮���ֵ����ʧ����[9]��
��Hilbert-Schmidtԭ��������[10]��֪�������������պ����Ĺ����У�ֻ�漰����������ڻ�����(xi, xj)��ֻҪ�ҵ�1������K(xi, xj)����Mercer�����������ܶ�Ӧijһ�任�ռ��е��ڻ����Ϳ����øú���������ڻ���
���ݾ��飬���õ���4�ֺ��������Ժ˺���������ʽ�˺�������˹������˺����������˺�����������ѡȡ���ζ���ʽ�˺���![]() ��d=3������ѵ�����ʼ���ѡȡ�����ʽϴ�ı������ظ����ϲ��裬ֱ�����ȴﵽҪ���������Ч����ͼ5��ʾ����������Ҳ��ͬ���ķ�������ģ�͡�
��d=3������ѵ�����ʼ���ѡȡ�����ʽϴ�ı������ظ����ϲ��裬ֱ�����ȴﵽҪ���������Ч����ͼ5��ʾ����������Ҳ��ͬ���ķ�������ģ�͡�
ͼ5��ʾΪ��¯��Ԥ��Ч����ͼ5(a)�У�ʵ�߱���ʾΪԤ������ʵ�ʹ躬����ȵ�����ͼ5(b) ʾʵ�ʵĹ躬���������߱�ʾ�躬��Ԥ������ͼ5(b)���Կ�����Ԥ������ܹ�������8%���ڣ������ø�ģ����Ϊ����ģ���еĵ�ģ�������ƺ��Ż��������̡�
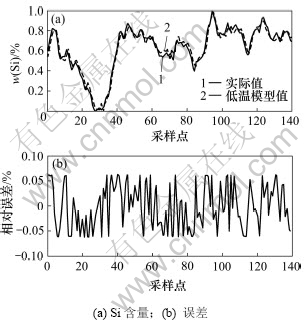
ͼ5 ��¯��Ԥ��Ч��
Fig.5 Regression result at low temperature
Ȼ������ʵ�ʵ����������У���¯��ȷ������ijһ�����������һ��������������¸�¯��������ȫ��������Щȷ���Ĺ��������Ǵ���ijЩ�����Ĺ��ɽΡ���ʱ��ֻ�е��������ֵ��㹻ϸ�£����ܷ�ӳ��¯��ÿ�����������ǣ����ֻ�ʹ��ģ����൱���ӣ���������˼����������Һܶ�ʱ���¯������������ĸ�����Ҳʹ�ø�¯�Ļ��ֹ����Ĺ�����ú����ѡ�����������������IJ�������ģ��ģ�����ϣ����ȿ��Է�ӳ��¯����������ֿ��Է�ӳ������Щ�����֮��Ĺ�����������ҹ�������û�����Ӻܶ࣬�ڹ������ǿ�ʵ�ֵġ�
3 ģ�����ܸ���
�õ����������µ�Ԥ��ģ�ͺ��л��ڹ���Ķ�ģ�͵������ںϺ����ߵ�������������ģ������Ȩ�س˻�֮����Ϊʵ�ʵ�Ԥ�������һ��������ģ���л�������ϵͳ�����任������Ӱ�죬��һ���������¯���жϲ���ȷ������һϵ��Ӱ�졣�˷�����ģ�ͽṹ�ı仯���ر����ƣ�ֻҪģ�͵ı仯��ģ�ͼ������ķ�Χ�ڼ���[11]�������˼���ǣ�����ǰϵͳ����������ģ�ͺ�õ���ģ�͵�Ԥ�������������ЩԤ��������¯��ʵ���������֮�������仯�ʣ�����ģ������������ϸ���������Ȩֵ�����ɴ�����Ȩ���������µ�ģ���Եõ�����Ԥ��ģ�ͣ��ٸ��ݸ���ģ�͵�Ԥ��������¯ʵ�����֮��IJ�ֵ����仯����������3��ģ�͵�Ȩֵ��
ģ����������ģ�������ۡ�ģ�������Լ�ģ��������Ϊ�����ļ�������ܿ��ƣ��������������Zadeh��������ģ�����20����ķ�չ��ģ�������������о���ʵ��Ӧ�÷��涼ȡ�����ش�չ[12-14]��
ͼ6��ʾΪ������Ƶĸ���ģ�͵��������̣�ͼ�У�![]() ��
��![]() ��
��![]() �ֱ�Ϊģ��1��2��3�Ե�ǰ�����Ԥ�������
�ֱ�Ϊģ��1��2��3�Ե�ǰ�����Ԥ�������![]() Ϊ����ģ�͵�Ԥ�������e1��e2��e3�ֱ�Ϊģ��1��2��3��Ԥ���������ˮ�躬��ʵ��ֵ֮�����eΪ����ģ���������ˮ�躬��ʵ��ֵ֮�����
Ϊ����ģ�͵�Ԥ�������e1��e2��e3�ֱ�Ϊģ��1��2��3��Ԥ���������ˮ�躬��ʵ��ֵ֮�����eΪ����ģ���������ˮ�躬��ʵ��ֵ֮�����![]() ��
��![]() ��
��![]() ��ֱ�Ϊ��ϵõ���3��ģ��Ȩ��[15]��������仯����Ϊ���������������3��Ȩ��ϵ��Ϊ����������
��ֱ�Ϊ��ϵõ���3��ģ��Ȩ��[15]��������仯����Ϊ���������������3��Ȩ��ϵ��Ϊ����������
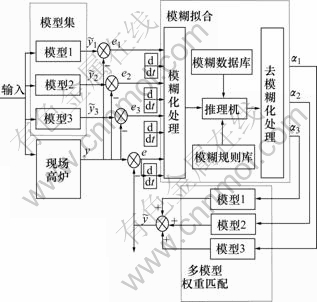
ͼ6 ģ���ϵ���������
Fig.6 Reasoning process of ally models
3.1 ģ����
��ǰϵͳ��������뵽������ģ�ͣ��õ�����ģ�͵�Ԥ�������ģ������������ֱ�Ϊ3��ģ�͵���������仯�ʣ����и���ģ�͵�����������仯�ʣ�ģ�����������Ϊ3��ģ�͵�Ȩ��ϵ��������Ϊ����������ģ�����ָʽ��
(1) |e|��ʾ������ֵ��ѡ��3�����Ա���S��M��B�ֱ��������С���С���
(2) ![]() ����de/dt����ӳ|e|�ı仯�ʺͱ仯���ֱ���NB��NM��NS�Լ�PS��PM��PB�������ĸ����С���С����С�����С�����
����de/dt����ӳ|e|�ı仯�ʺͱ仯���ֱ���NB��NM��NS�Լ�PS��PM��PB�������ĸ����С���С����С�����С�����
(3) �����![]() ָ���Ǹ�ģ�͵�Ȩ��ϵ�����ֱ���S��M��B������ģ���뵱ǰ������ƥ��̶�Ϊ���á�һ��ͺá�
ָ���Ǹ�ģ�͵�Ȩ��ϵ�����ֱ���S��M��B������ģ���뵱ǰ������ƥ��̶�Ϊ���á�һ��ͺá�
ѡ��������������Ⱥ���Ϊ�������Ǻ��������ݸ������������Ⱥ��������Խ��Ƶó��������Ա����ĸ�ֵ��
3.2 ģ���������
ģ�����������һ�ֲ�ȷ���������������������ģ����������Ҫ�ҳ��ڲ�ͬʱ��3��ģ��Ȩ�ز������������Լ����仯��֮���ģ����ϵ���������в��ϼ��|e|��![]() ������ģ�����������3��Ȩ��ϵ�����������ģ���������ƾ��ȵ�Ҫ����ˣ�����3��Ȩ�ص��������Կ������£�
������ģ�����������3��Ȩ��ϵ�����������ģ���������ƾ��ȵ�Ҫ����ˣ�����3��Ȩ�ص��������Կ������£�
(1) ��|e1|��|e2|��|e3|����1����С��������2���ܴ�ʱ��˵������С��ģ���뵱ǰ����ƥ��̶Ƚϸߡ�
(2) ��|e1|��|e2|��|e3|����2����С��������1���ϴ�ʱ��˵��ϵͳ��ǰ������������С��2��ģ��֮�䡣��ʱ��Ҫ���ݸ���ģ�͵��������2������С��ģ�͵����仯�ʹ�ͬ����ģ��ƥ��ȡ�
(3) ��|e1|��|e2|��|e3|��ij����������������Χ����˵�����Ӧ��ģ�����̫���ʺϵ�ǰ���������Զ�����Ȩ������ΪС��
������Щ����ԭ���Լ���¯ר�ҵľ��飬���Եõ���Ӧ��ģ��������ʽ���£�
IF |e1| is S and |e2| is B and |e3| is B,
then ![]() is B and
is B and ![]() is S and
is S and ![]() is S;
is S;
IF |e1| is M and |e2| is M and |e3|is B and ![]() is NM and
is NM and ![]() is PM,
is PM,
then ![]() is B and
is B and ![]() is S and
is S and ![]() is S��
is S��
3.3 ȥģ����
�������ķ����������С�仯�������������һ�㶼�ᷢ��һ���ı仯�������ֱ仯�Ƚ�ƽ������ģ����ϵ�ȥģ�����㷨�������ķ���ȡģ�������Ⱥ��������������Χ�ɵ����������Ϊģ�����������������
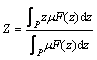 (1)
(1)
���У�PΪ�������FΪ��ģ���Ӽ���
3.4 Ȩ����������
��ʵ�������У�ϵͳ���ݵ�ǰ������ģ����������õ���ģ��Ȩ��![]() ��
��![]() ��
��![]() ���Ӷ��õ�����ģ�����
���Ӷ��õ�����ģ�����![]() ��
��
������ģ�������ϵͳʵ�����֮������e����仯��![]() ģ���������Ѿ������õ�ģ������һ�����ߵ�����Ȩ��ֵ������
ģ���������Ѿ������õ�ģ������һ�����ߵ�����Ȩ��ֵ������![]() �Ƚϴ�
�Ƚϴ�![]() �Ƚ�С��
�Ƚ�С��![]() Ҳ�Ƚ�С��ͬʱe�Ƚ�С���м�С���ƣ�˵��
Ҳ�Ƚ�С��ͬʱe�Ƚ�С���м�С���ƣ�˵��![]() ��Ӧ�Ĺ����ȽϷ��ϵ�ǰ��������������������
��Ӧ�Ĺ����ȽϷ��ϵ�ǰ��������������������![]() �����������ģ���������������
�����������ģ���������������
IF ![]() is B and
is B and ![]() is S and
is S and ![]() is S and e is S and
is S and e is S and ![]() is NM,
is NM,
THEN ![]() is Bigger��
is Bigger��
3.5 ģ���������
����ģ����������������ɱ���¯3����ģ�͵�Ȩ�أ�������������ģ�͡�ͼ7��ʾΪȡ���ڵ���������֮�����ʷ���ݽ�����֤�Ľ������ʾ�˸���ģ�͵�Ԥ������
��ͼ7���Կ���������ģ��Ԥ�����Ƚ�С���ܹ��ȶ���7.5%���ڣ����㾫��Ҫ��Ϊ��ǿϵͳ����Ӧ�ԣ�ʵ������ʱ����Ҫ����������������ģ���Ƿ�����˸�¯���е�����״�������û�У�����ݳ��ֵ������������ģ�ͣ�����ϵͳ����Ԥ�⣬�Դ˲�������ϵͳ��
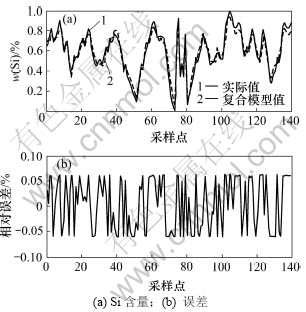
ͼ7 ����ģ��Ԥ����
Fig.7 Final regression result
4 �����֤
4.1 ��ģ���븴��ģ�͵Ľ���Ա�
Ϊ�˶Ա������õ������ܸ���ģ�͵�Ԥ�⾫�Ƚ�����֤��ѡȡ��5����ʷ���ݡ���5�����ݷֱ�Ϊ�ߡ��С�����3�������µ����ݣ��Լ����ڸߡ����º��С�����֮������ݡ�������5�����ݣ��ֱ��õ�ģ�ͺ���ģ�ͽ���Ԥ�⣬���õ���Ԥ�������жԱȣ������ͼ8~10��ʾ��
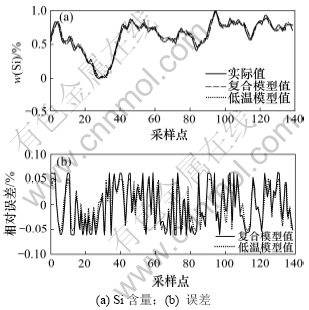
ͼ8 ����ʱ2��ģ�͵�������Ա�
Fig.8 Output-error of two models at low temperature
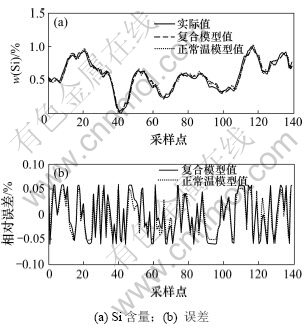
ͼ9 �����¶�ʱ2��ģ�͵�������Ա�
Fig.9 Output-error of two models at normal temperature
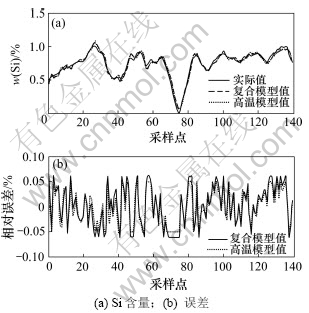
ͼ10 ����ʱ2��ģ�͵�������Ա�
Fig.10 Output-error of two models at high temperature
�����¶Ⱥ���ʱ��2��ģ�͵�������ԱȽ���ֱ���ͼ9~10��ʾ����ͼ9~10���Կ���������ģ�ͶԴ���ij�ض��������������������Ȼ������ģ�ͣ������ܹ����㾫��Ҫ��
ͼ11��12��ʾ�ֱ�Ϊ���ڵ����¡��и���ʱ3��ģ�͵�������Աȡ�
��ͼ11��12���Կ�������ʵ�������������ij2�ֹ���֮��ʱ������ģ�͵�������ȸ���ģ�͵�ҪС��
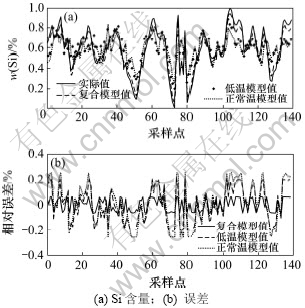
ͼ11 ���ڵ�����ʱ3��ģ�͵�������Ա�
Fig.11 Output-error of three models at lower temperature

ͼ12 �����и���ʱ3��ģ�͵�������Ա�
Fig.12 Output-error of three models at higher temperature
4.2 ����ģ�����ģ�͵Ľ���Ա�
Ŀǰ���ڶ���Ĺ�ҵ�����о��Ƚ϶���Ƕ� ģ�͡�
��ģ���Ǹ���ϵͳ��ʷ���ݣ��ֱ��ö��������ģ�ͣ����ݾ������ÿ��غ���������ϵͳ��ǰ��������ڶ��������ģ��֮������л���
����i-model and mixed�������ܹ����㾫��Ҫ��Ϊ�˽�һ����֤����ģ�͵���Ч�ԣ�ѡȡһ������˶�����������ݣ��ֱ��ô�ͳ��ģ�ͺ���ģ�ͽ���Ԥ�⣬�����ͼ 13��ʾ����ͼ13���Կ�������ͳ��ģ�͵������ڸ���ģ�͵����ر����ڹ��������ϴ������£���ģ�͵���Ͼ���ԶС�ڸ���ģ�͵���Ͼ��ȡ�
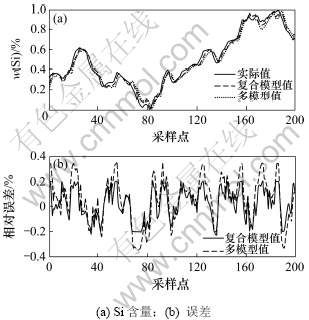
ͼ13 ��ͳ��ģ���븴��ģ�͵�������Ա�
Fig.13 Output-error of multi-model and mixed model
5 ����
(1) ������������Ԥ��ģ�ͣ��Ƚ�����ͬ�����µ���ˮ�躬�������Ԥ��ģ�ͣ�Ȼ������ģ�������õ���ǰ�������̽ӽ�ij��ģ�͵ij̶ȣ����л��ڹ���Ķ�ģ�������ںϺ����ߵ�����������ģ������Ȩ�س˻�֮����Ϊʵ�ʵ�Ԥ����������봫ͳ��ģ�ͽ��бȽϡ�
(2) �����Ĺ����Ƚ�С����ֱ�����ô�ͳר��ϵͳ����ܹ���Ч����������ƥ��������õ�ʱ�䣬ʹ�����������̣�Ԥ��Ѹ�٣��Ա��ض���ı仯�н�ǿ��³���ԣ�ʵ���Ժá�
(3) ��һ�㹤ҵ���õ�ģ�ͻ��߶�ģ����ȣ��˷����ܹ����������л����̣���߹����л����̵�Ԥ�⾫�ȡ�
�ο����ף�
[1] �Ŵ�ξ, ��¯¯��Ԥ��ר��ϵͳ���о�[D]. �Ϸ�: �Ϸʹ�ҵ��ѧ�������Զ�������ѧԺ, 2005: 1-52.
ZHANG Da-wei. The research of expert system for blast furnace situation forecast[D]. Hefei: Hefei University of Technology. School of Electrical Engineering and Automation, 2005: 1-52.
[2] �����, ����. ��¯���������Ż������ܿ���ϵͳ[M]. ����: ұ��ҵ������, 2003: 1-270.
LIU Xiang-guan, LIU Fang. Blast furnace ironmaking process optimization and intelligent control system[M]. Beijing: Metallurgical Industry Press, 2003: 1-270.
[3] �ν���. ��¯�������������[M]. ����: ұ��ҵ������, 2005: 1-338.
SONG Jian-cheng. Blast furnace theory and operation[M]. Beijing: Metallurgical Industry Press, 2005: 1-338.
[4] Reid M, Spencer K. Use of principal components analysis (PCA) on estuarine sediment datasets: The effect of data pre- treatment[J]. Environmental Pollution, 2009, 157: 2275-2281.
[5] Honda K, Ichihashi H. Fuzzy PCA-guided robust k-means clustering[J]. IEEE Transactions on Fuzzy Systems, 2010, 18(1): 67-79.
[6] Vapnik V. The nature of statistical learning theory[M]. New York: Springer-Verlag, 1995: 1-88.
[7] ��ѧ��, ����ͳ��ѧϰ������֧��������[J]. �Զ���ѧ��, 2000, 26(l): 32-42.
ZHANG Xue-gong. About statistical learning theory and support vector machine [J]. Acta Automatica Sinica, 2000, 26(l): 32-42.
[8] ������, ��ѧ��. ͳ��ѧϰ����[M]. ����: ���ӹ�ҵ������, 2004: 1-594.
XU Jian-hua, ZHANG Xue-gong. Statistical learning theory[M]. Beijing: Electronic Industry Press, 2004: 1-594.
[9] ���ܾ�. ֧�������������ܽ�ģ��ģ��Ԥ������е�Ӧ��[D]. ����: �㽭��ѧ��������ѧԺ, 2007: 1-109.
BAO Zhe-jing. Application of support vector machine in intelligent modeling and model predictive control[D]. Hangzhou: Zhejiang University. College of Electrical Engineering, 2007: 1-109.
[10] ����. ֧���������ڸ�¯¯��Ԥ���е�Ӧ��[D]. ����: �㽭��ѧ��ѧϵ, 2006: 1-58.
JIAN Ling. Application of SVM to predict silicon content in hot metal[D]. Hangzhou: Zhejiang University. Department of Mathematics, 2006: 1-58.
[11] ������, �߱�, ����, ��. ����ģ��PID���л����Ƶ��г��Զ���ʻϵͳ�����ƶ�[J]. ���������, 2010, 25(5): 794-800.
DONG Hai-rong, GAO Bing, NING Bin, et al. Fuzzy-PID soft switching speed control of automatic train operation system[J]. Control and Decision, 2010, 25(5): 794-800.
[12] ������. �Ƚ�PID���ƺ�MATLAB����[M]. ����: ���ӹ�ҵ������, 2004: 1-470.
LIU Jin-kun. Advanced PID control and MATLAB Simulink[M]. Beijing: Electronic Industry Press, 2004: 1-470.
[13] ������, ����÷, ������, ��. ����ģ��Ԥ����ƵĻ����ƶ����Ʒ���[J]. ���ϴ�ѧѧ��: ��Ȼ��ѧ��, 2009, 40(5): 1329-1335.
LIU Jian-feng, LIU You-mei, GUI Wei-hua, et al. Locomotive brake control method based on fuzzy predictive control[J]. Journal of Central South University: Science and Technology, 2009, 40(5): 1329-1335.
[14] ������, ½�½�, ��Ⱥ��. ģ��PID�����ڵ������ƽ̨�е�Ӧ��[J]. ���ϴ�ѧѧ��: ��Ȼ��ѧ��, 2005, 36(4): 631-636.
XU Liang-qiong, LU Xin-jiang, LI Qun-ming, Application of fuzzy PID control to electromagnetic suspension platform [J]. Journal of Central South University: Science and Technology, 2005, 36(4): 631-636.
[15] Milosavljevic C. General conditions for the existence of a quasi-sliding mode on the switching hyper plane in discrete variable structure systems[J]. Automation and Remote Control, 1985, 46(3): 307-314.
(�༭ ����ƽ)
�ո����ڣ�2011-05-29�������ڣ�2011-07-17
������Ŀ��������Ȼ��ѧ����������Ŀ(60574079)���㽭ʡ��Ȼ��ѧ����������Ŀ(601112)
ͨ�����ߣ����Ŀ�(1965-)���У��㽭�����ˣ����ڣ�����³���������Ż������о����绰��13606643948��E-mail: yanwenjun_zju@163.com
ժҪ����Ը�¯�������̵ĸ����ԡ��������Լ�ǿ��ϡ���������Ѳ������ص㣬�����ˮ�躬�������ܸ��϶����Ԥ��ģ�ͶԸ�¯�������̽��н�ģ������ϵͳ��Ϊ�����֣��������߽�����ͬ��������ˮ�躬���Ķ����Ԥ��ģ�ͣ�Ȼ������ģ��������������ģ�������ʵ�������ģ��Ȩ��֮��Ķ�Ӧ��ϵ�����ж�ģ�������ںϣ����ɸ���ģ�ͣ�������������ߵ������Ż�Ԥ����̡��о�������������ô˷����������ڶ̣��Ա��ض���ı仯�н�ǿ��³���ԣ���ϵͳԤ�����С���ܹ�������Ӧ�����ı仯��ʵ���Ժá�
