
J. Cent. South Univ. Technol. (2011) 18: 782-790
DOI: 10.1007/s11771-011-0763-x![]()
Continuous query scheduler based on operators clustering
M. Sami Soliman, TAN Guan-zheng(̷����)
School of Information Science and Engineering, Central South University, Changsha 410083, China
? Central South University Press and Springer-Verlag Berlin Heidelberg 2011
Abstract:
Data stream management system (DSMS) provides convenient solutions to the problem of processing continuous queries on data streams. Previous approaches for scheduling these queries and their operators assume that each operator runs in separate thread or all operators combine in one query plan and run in a single thread. Both approaches suffer from severe drawbacks concerning the thread overhead and the stalls due to expensive operators. To overcome these drawbacks, a novel approach called clustered operators scheduling (COS) is proposed that adaptively clusters operators of the query plan into a number of groups based on their selectivity and computing cost using S-mean clustering. Experimental evaluation is provided to demonstrate the potential benefits of COS scheduling over the other scheduling strategies. COS can provide adaptive, flexible, reliable, scalable and robust design for continuous query processor.
Key words:
data stream management systems; operators scheduling; continuous query; clustering��
1 Introduction
In applications such as network monitoring, telecommunications data management, manufacturing, and sensor networks, data take the form of continuous data streams rather than finite stored data sets, and clients require long-running continuous queries in contrast to one-time queries. In a streaming data system [1], queries run indefinitely, and they must process datasets that are constantly growing. Stream environments are usually highly dynamic.
Various approaches to adaptive query processing are possible given that the data may exhibit different types of variability. For example, a system could modify the structure of query plans, or dynamically reallocate memory among query operators in response to changing conditions [2], or take a holistic approach and do away with fixed query plans altogether, as in the Eddies architecture [3]. Like Chain algorithm [4], in this work, we focus on adaptively changing arrival characteristics of the data. As mentioned earlier, most data streams exhibit considerable burstiness and arrival-rate variation. It is crucial for any stream system to adapt gracefully to such variations in the data arrival, making sure that we do not run out of critical resources such as main memory during the bursts while ensuring that output latency is bounded. When processing high-volume, burst data streams, the natural way to cope with temporary bursts of unusually high rates of data arrival is to buffer the backlog of unprocessed tuples and work them through during periods of light load. However, it is important for the stream system to minimize the memory required for backlog buffering. Otherwise, total memory usage can exceed the available physical memory during periods of heavy load, causing the system to page to disk, which often causes a sudden decrease in overall system throughput.
The operator scheduling strategy used by the data stream system has a significant impact on the system performance. The question we address in this work is how to schedule the execution of query operators most efficiently to keep the total memory required for backlog buffering at a minimum, assuming that query plans and operator memory allocation are fixed and the processing resources are also limited. We focus on memory requirements, without ignoring another metrics. It is also important that a stream system ensures reasonable output latency. On the contrary, in some situations, minimizing latency could be the most significant factor that should be considered.
DSMS needs an intelligent scheduling strategy in order to execute queries using a limited amount of memory. The aim of this work is to design scheduling strategy that will form the core of a resource manager in a data stream system. Here are some desirable properties of such scheduling strategy [5]:
1) The strategy should have provable guarantees on its performance in terms of metrics such as the resource utilization, response times, and latency. Because it will be executed every few time steps, the strategy should be efficient to execute.
2) The strategy should include a superior scalable ability; it has the capability to handle growing amounts of operators in a graceful manner and perform suitably efficiently and practically.
3) The strategy should also be able to act in a robust way, which means that it can withstand changes in procedure or circumstance and is capable of coping well with variations in processing resources.
There are many scheduling algorithms that can be used to control continuous query operators running in a graph threaded approach, which means that only one thread manages the complete query graph.
Chain algorithm [4] is a priority based strategy. The development of the Chain algorithm has focused solely on minimizing the maximum run-time memory usage, ignoring the important aspect of output latency. While minimizing the run-time memory usage is important, many stream applications also require responses to stream inputs within specified time intervals. However, so far, it cannot be used in such a scenario. The Chain algorithm should be modified to handle the latency issue.
A hybrid approach termed HTMS [6] can be viewed as a generalization of GTS and OTS. The core concept of the architecture is the merge adjacent of operators into a single virtual operator. Each of these virtual operators (VOs) runs in its own thread. The communication between virtual operators is established through queues. The main problem in the construction of VOs is the placement of the queues. From a formal point of view, this is a graph partitioning problem, where each partition corresponds to a VO. The computation of an optimal partitioning for an arbitrary graph is NP-complete. For this reason, this work focuses on the development of a suitable heuristics with an objective to partition the query graph so that stalled operators are avoided.
2 Continuous query processing schema
A continuous query is a query that is logically issued once but run forever. At any point of time, the answer to a continuous query reflects the elements of the input data streams seen so far, and the answer is updated as new stream elements arrive. For example, continuous queries over network packet streams can be used to monitor network behavior to detect anomalies (e.g., link congestion) and their causes (e.g., hardware failure, intrusion, denial-of-service attack). Continuous queries can be extremely long lived, which makes them susceptible to changes over time in performance and load, data arrival rates, or data characteristics.
Often, the usefulness of a result depends upon how quickly it is produced. This means that minimizing latency and maximizing throughput are typically very important. Techniques for accomplishing this range from shedding tuples in order to reduce the load on the system, and for scheduling operator queues in order to reduce the amount of tuples are needed by the system optimally [7].
To run multiple continuous queries in a DSMS, the common approach is to unify them in a query graph, in particular, to gain advantage from subquery sharing. Formally, a query graph is a directed acyclic graph. Its nodes are sources, operators (e.g. selection, join) and sinks; the edges between them represent the data flow. Sources, such as sensors, only deliver data, while sinks only consume data. Thus, sources are always at the bottom of the query graph, whereas sinks are at the top (see Fig.1). Operators are sources and sinks as well; they receive data from their sources, process it, and deliver the results to their sinks. In order to execute a query graph, pull-based processing or push-based processing can be used. These processing paradigms were introduced [8-10] in the context of DSMS.
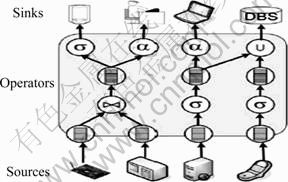
Fig.1 Query graph of DSMS
A common characteristic of DSMS architectures is to associate a queue with each operator to support continuous queries over data streams and to effectively handle the unpredictable characteristics of a continuous data stream. There is an analysis based on the queuing theory to study the behavior of stream data in a query processing system [11]. This approach makes it possible to compute the mean number of tuples, the variance of the number of tuples, and the mean as well as the variance of the waiting time of tuples in the system. However, this analysis is not enough to evaluate continuous query processor algorithms especially scheduling since it is very difficult to be mathematically modeled because of its nonlinear nature. So, a simulation model for continuous query processor has been built based on the queuing theory for modeling its basic element, and this simulation could be used to evaluate and compare different scheduling algorithms and other related algorithms in continuous query processing [12].
In order to compare different techniques used in continuous query processing, the processing schema is modeled and simulated. A queueing system is widely used to model various software and hardware systems [13-14]. For each operator in a given query plan, it has been modeled as the service facility of a queueing system, and its input buffers (queues) have been modeled as a logical input queue with different classes of input tuples if it has more than one input streams. The relationship between two operators is modeled as a data flow between two queueing systems. Eventually, a query plan is modeled as a network of queueing systems. In this model, the bottom queueing system that accepts the external input streaming data is called as the leaf queueing system (data stream source), and the top queueing system that outputs the final results of the query as the terminal queueing system (data stream sink).
For each external input stream, there exists an operator path from the bottom operator to the top operator, and we call the corresponding path in our queueing network model queueing path. Considering this subset of query plans, only one operator in these subset query plans is served at any time instant. Therefore, a scheduling algorithm is necessary to choose operators to serve at each time instant, leaving all other operators idle.
3 K-means and S-means
3.1 K-means
K-means [15] basically divides a given data set into K clusters via an iterative refining procedure. The procedure simply consists of four steps:
Step 1: Initialize K centroids (ci, 1��i��K) in the vector space.
Step 2: Calculate the distances from every point to every centroid. Assign each point to group i, if ci is its closest centroid.
Step 3: Update centroids. Each centroid is updated as the mean of all the points in its group.
Step 4: If no point changes its membership or no centroid moves, then exit; otherwise, go to Step 2.
The iterative procedure uses hill climbing to minimize the objective function:
![]() (1)
(1)
where ![]() denotes the Euclidean distance between point xj and the corresponding centroid ci. The Euclidean distance can be substituted by any distance measure.
denotes the Euclidean distance between point xj and the corresponding centroid ci. The Euclidean distance can be substituted by any distance measure.
However, one of the major problems of K-means is that we do not know the right number of clusters in advance. A common approach is to score the results of multiple runs with different K values according to a given criterion. The criterion might incur new risk and parameter setting problems. S-means is proposed to use a similarity driven approach in clustering that does not require specification of K.
3.2 S-means
The clustering problem we need to solve is: given N data points, group them into clusters such that within each cluster, all members have similarity ��T with the centroid, where T is a user-defined threshold. Similarity is a central notion in classification problem. The definition of cluster also implies that the cluster members should have high similarity with each other. The most popular Euclidean distance is a dissimilarity measure, which can be converted to a similarity measure in Gaussian form:
![]() (2)
(2)
It is also called the radial basis function (RBF kernel) in kernel machines. Kernel methods all use similarity measures instead of dissimilarity.
Similarity value is usually normalized to a value between 0 and 1; a confidence threshold in [0, 1] also makes intuitive sense to users. There are a large number of similarity measures available beside the RBF, such as correlation r, R-squared (the square of r). Indeed, any kernel function can be considered a similarity measure. Therefore, the clustering problem, if defined in terms of similarity, is more user-friendly and will gain more popularity due to the increasing amount of interests in kernel methods.
S-means starts from K=1 by default. The procedure for S-mean is as follows.
Step 1: Initialize K centroids.
Step 2: Calculate the similarities from every point to every centroid.
Step 3: For any point, if the highest similarity to centroid ci is T, group it to cluster I; otherwise, add it to a new cluster (the (K+1)-th cluster).
Step 4: Update each centroid, using the mean of all member points by default. If one group becomes empty, remove its centroid and reduce K by 1.
Step 5: Repeat Step 2 and Step 3 until no new cluster is formed and none of the centroids moves.
Note that S-means is similar to K-means but with some differences [16]. The major difference lies in the second step, which basically groups all the points to a new cluster whose highest similarity to existing centroids is below the given threshold. In K-means, all points must go to one of the existing K groups, which is unfair for some points when their similarities to corresponding closest centroid are very low. This simple difference makes large impact on the output of clusters. Also, we can let K start from 1 and it will converge to a value, which eliminates the need of specifying a fixed K value.
4 Clustered operators scheduling (COS)
4.1 Problem statement
The tuple latency and memory requirement of a query plan are two fundamental performance metrics. Based on these two metrics and input characteristics, we can further estimate the system performance. The main goal of the intelligent scheduling technique is to minimize the tuple latency and memory requirement to improve the entire system performance. The scheduling architectures for DSMS that have been proposed so far use, for processing, either one thread for each operator in the DSMS (full multi-threaded) or one thread for one graph that unifies all queries in the DSMS. Therefore, we call these approaches operator-threaded scheduling (OTS) and graph threaded scheduling (GTS). However, both approaches do not scale well for large query graphs.
OTS does not scale for query graphs with a large number of operators due to the significant overhead for the thread management and also because the CPU resources will be distributed among this large number of operators in the same time, which will cause hindrance for all queries. We are not aware of any platform that can handle a large number of threads effectively [17].
GTS faces two problems that adversely affect its scalability. Since one thread manages the complete query graph, it can only run one operator exclusively. Thus, the execution of one expensive operator can stall the processing of the whole DSMS. Furthermore, GTS cannot take advantage of new features of today��s CPUs, like multiple processors or hyper-threading. Furthermore, the QoS could not be effectively applied for different DSMS queries.
These drawbacks are overcome with the flexible clustered operators scheduling (COS) approach. COS is a multi-threaded approach, which provides a proper adjustment of the number of threads for processing, in compliance with the current needs of the DSMS. This usually leads to a number of threads, which lies between the two extreme cases of OTS and GTS. COS adaptively forms clusters that collect similar operators using some heuristic statistics and system prediction model. So, our problem is to divide query plan operators into a number of groups, and these groups will share the CPU. This approach will avoid the problem of stalling the processing and also the overhead for thread management because there will be a small number of threads compared with OTS.
As discussed above, OTS is well-suited to avoid stalling in query graphs with expensive operators while GTS is preferable for query graphs with many low cost operators. We believe that in practice usually both cases simultaneously occur in a query graph. COS assigns dynamically cluster operators into a number of clusters and runs each group of operators in single thread. In order to keep the balance between concurrency and overhead, COS offers to schedule each partition with respect to a separate strategy. This feature is relevant to large query graphs in the presence of multiple QoS guidelines.
4.2 COS architecture
COS consists of three-level architecture. The first level consists of operators and queues. On the second level, partitions of first-level operators are constructed by clustering them based on their cost and selectivity. The clustering can be done using S-means. This level provides an explicit scheduling, and each group of operators will run in different thread. It is possible to choose arbitrary strategies on the second level, provided that they comply with the first level. Choosing the Chain priority scheme in each thread to select the next operator to run will ensure the memory minimizing.
The third level runs multiple second-level units concurrently. Concurrency is managed by a round-robin fashion thread termed as thread scheduler (TS). This concept breaks up the atomic execution as given in the second-level units. The default TS accomplishes a round-robin strategy. It simply runs all the threads that have ready operators simultaneous with an equal priority that allows them to share the CPU resources with identical shares, and it assigns time slices to each thread in equal portions and in circular order so that starvation is prevented. In this level, the similarity threshold T is assigned to the second level based on the system status and requirements.
Flexibility of COS means that it allows using only the levels which are needed in the context of a concrete application. OTS and GTS are special cases of our architecture. For OTS, it can be achieved by simply assigning a small value to T so the number of clusters will be equal to the number of the operators and it will run just as a multi-threaded manner. For GTS, the first-level is the same as described for OTS. On the second-level, T will have a large value so the number of clusters will be equal to one; so all operators will relay in only one cluster. We can seamlessly switch between these approaches during runtime. For instance, we want to change from OTS to GTS. As the first level is equal in both approaches, it is not necessary to change the graph structure. The GTS scheduler is instantiated with a strategy and the entirety of operators that are assigned to OTS. Then, all OTS threads can be stopped instantly and the GTS scheduling starts. Changes on the second level are discussed in the pervious section, where we elaborate the method for clustering the operators. The third level is responsible for choosing T, which will control the behavior of the COS based on the system status and input rates.
4.3 Operators clustering
The S-means clustering method now is ready to apply. First, the features of operators should be extracted in order to be used in the similarity measurements. Query execution can be captured by a data flow diagram [18], where every tuple passes through a unique operator path. Thus, queries can be represented as rooted trees. Every operator is a filter that operates on a tuple and produces s tuples, where s is the operator selectivity. For example, we assume that a selection operator with selectivity of 0.5 will select about 500 tuples of every 1 000 tuples that it processes. Henceforth, a tuple should not be thought as an individual tuple, but should be viewed as a convenient abstraction of a memory unit, such as a page, that contains multiple tuples. Over adequately large memory units, we can assume that if an operator with selectivity s operates on inputs that require one unit of memory, its output will require s units of memory.
Now, each operator has a tuple of two elements (C, S), where C is the computing cost needed for this operator to process its input and produce the output with S ratio of the input memory requirement. All operators of the query plan have been projected in one figure. After S-means clustering is used with a specified similarity ratio, operators are divided into a number of clusters, as shown in Fig.2.
5 Experiments
OMNeT++ (Version 3.3) environment has been used to implement the continuous query plan simulation based on our model. OMNeT++ [19] is a public-source, component-based, modular and open-architecture simulation environment with strong GUI support and an embeddable simulation kernel. Its primary application area is the simulation of a discrete event system like our case because of its generic and flexible architecture [20]. A screenshot of the simulation framework is shown in Fig.3.
The implementation of FIFO processes each block of the input stream tuples to completion before processing the next block of tuples in strict arrival order. Round-robin cycles through a list of operators, and each ready operator is scheduled for one time unit. The size of the time unit does affect the performance of Round-robin cycles, but it does not change the nature of the results presented here.
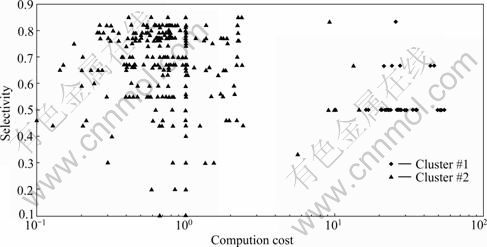
Fig.2 Operator clusters for query plan
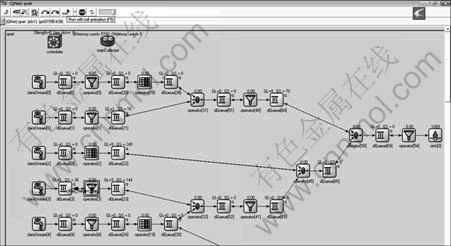
Fig.3 Snapshoot for running continuous query plan simulation
The notion of the progress chart captures the average behavior of the query execution in terms of the sizes of memory units as they make progress through their operator paths. The experiments we describe are designed by choosing a particular progress chart to use for both the real and synthetic data sets and then adjusting selection conditions and joining prediction to closely reflect the progress chart. Of course, during actual query execution, there are short-term deviations from the average behavior captured in the progress chart. In our experiments, we follow the query execution and report the memory usage at various times. The experiments described here use static estimates for operator selectivities and processing times (derived from a preliminary pass over the data) to build the progress charts.
5.1 Experiment setting
In all experiments, only selecting, projection and joining operators are used. Joining has been modeled as a sliding-window joins. The query plan consists of multiple queries with the same structure with different operator selectivities. Each query uses two data stream sources and applies two successive selections for each data stream. After that, a joining operator is applied with specific sliding window. The output from joining operator will pass thought anther two filtering operators (select operators). Finally, using a projection operator, the output stream will be generated and sent to the data stream sink. Each query consists of eight operators: six selections, one projection and one join operator.
During the experiment, each operator uses a fixed computing cost per tuple processing, and the same cost is used for calculating the total cost model and then the clustering phase.
5.2 Performance comparison
In this experiment, the performance of the COS is compared with two GTS algorithms, which are FIFO and Chain algorithms besides the OTS (multi-threaded). Only one example will be shown, for large query plan (320 operators). The set of the tests is a large query plan with a normal data arrival and a large query plan with a burst data arrival. The four scheduling methods (GTS-FIFO, GTS-Chain, OTS and COS) are applied for all experiments in order to compare them.
Figure 4 illustrates the result for large query plan with a normal data arrival. It can be seen that the COS has an average memory requirement less than Chain, FIFO and multi-threaded one and has a great improvement in the latency issue better than all of them. In the case of the large query plan with the burst data arrival shown in Fig.5, the COS proves its advantage in burst mode by having the lowest memory requirement and nearly the best latency. For the small query plan, the power of the COS is not quite clear but in the large query plan the enormous performance has been verified.
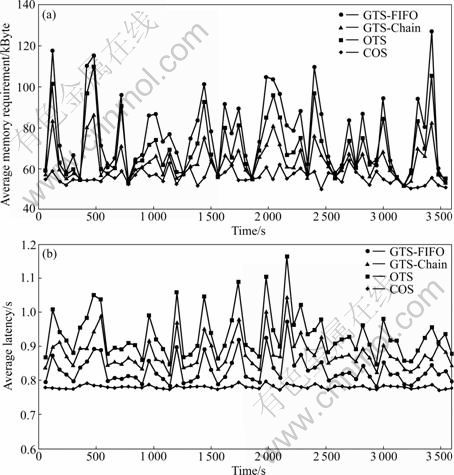
Fig.4 Average memory requirement (a) and latency (b) for 320 operators query plan in normal data mode
5.3 Scalability comparison
In this experiment, the scalability of the COS means that it can handle growing amounts of operators in a graceful manner and perform suitably efficiently and practically when being applied to large query plans. It is compared with two GTS algorithms, which are FIFO and Chain algorithms besides the OTS (multi-threaded). This comparison is done by running the four techniques with an incremental number of operators and the system performance metrics are compared.
First, in normal mode, the difference in performance metrics for a small number of operators is not quite clear, especially in memory requirements; on the other hand, with the increase of the number of the operators, the differences in performance become more and more clear and the advantages of COS become obvious. The same behavior for all the methods has been achieved in the case of the burst inputs, as shown in Fig.6. The differences in the memory requirement and latency in the burst mode happen to be larger than those in the normal mode. This ensures the reliability of the COS. The result from these experiments ensures that COS has an excellent scalability manner.
5.4 Robustness comparison
In order to examine the robustness of COS and compare it with other techniques, the simulation model runs for all techniques with different available computing resources. As shown in Fig.7 the memory requirement for COS is increased with the decrease of the computing resources, but it is still less than the other methods with the same behavior. The same manner has been achieved for the latency, as shown in Fig.8. The great characteristic of the COS is that even when the other methods loss their stability (when the computing resource becomes 1 200 computing unit per second), COS still works with reasonable requirement. This experiment demonstrates the better robustness of the COS compared with the other techniques and its ability to have very good results even with limited resources, which is the typical case in the DSMS.
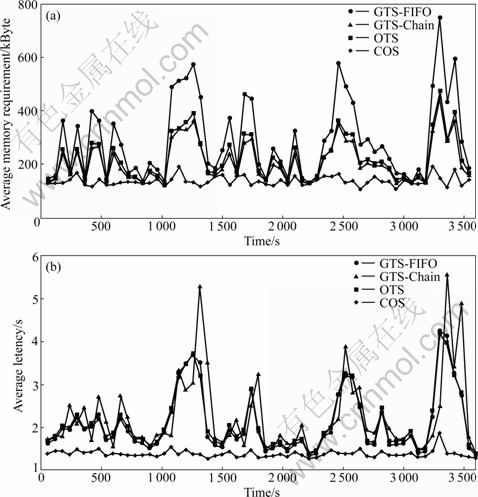
Fig.5 Average memory requirement (a) and latency (b) for 320 operators query plan in burst data mode
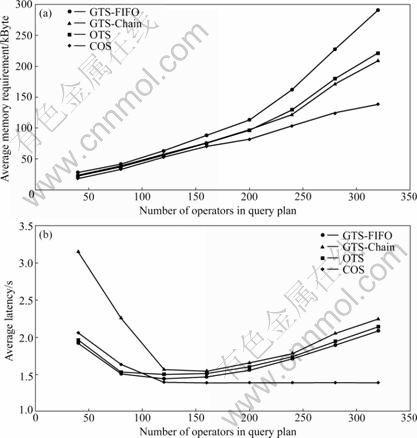
Fig.6 Average memory requirement (a) and latency (b) comparison for different scheduling techniques vs number of operators in burst data mode
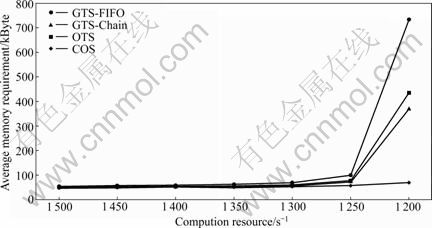
Fig.7 Average memory requirement vs available computing resources
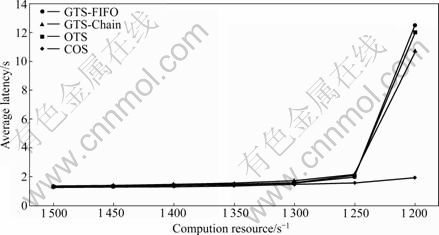
Fig.8 Average latency vs available computing resources
6 Conclusions
1) The issue of continuous query processing is studied. The problem of operator scheduling in query processor has been focused on, with the goal of minimizing memory requirements and tuples latency. An adaptive operator scheduling COS is proposed. It clusters different operators into a number of groups based on its selectivity and computing cost. S-means is used to clustering the operators that does not require specification of clusters count.
2) COS is compared with the conventional scheduling methods, FIFO, Chain and OTS. COS is proved to have high performance for all situations compared with the other techniques. Furthermore, it is shown that COS scheduling performs very well in terms of scalability and robustness. COS is also able to use the memory and the computation resources in an efficiency manner that makes it continue working with limited resources, while other techniques lose their stability.
3) As a final result, the proposed technique provides adaptive, flexible, reliable, scalable and robust design for continuous query processor that can be the core for adaptive DSMS.
References
[1] JIANG Qing-chun, CHAKRAVARTHY S. Anatomy of a data stream management system [C]// Proceedings of the Advances in Databases and Information Systems. Thessaloniki, Greece, 2006: 233-258.
[2] MOTWANI R, WIDOM J, ARASU A, BABCOCK B, BABU S, DATAR M, MANKU G, OLSTON C, ROSENSTEIN J, VARMA R. Query processing, approximation, and resource management in a data stream management system [C]// Proceedings of First Biennial Conference on Innovative Data Systems Research. Asilomar, CA, USA, 2003: 238-249.
[3] AVNUR R, HELLERSTEIN J M. Eddies: continuously adaptive query processing [C]// Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data. Dallas, Texas, USA, 2000: 261-272.
[4] BABCOCK B, BABU S, DATAR M, MOTWANI R, THOMAS D. Operator scheduling in data stream systems [J]. Very Large DataBases Journal: Special Issue on Data Stream Processing, 2004, 13(4): 29-36.
[5] PINEDO M L. Scheduling: theory, algorithms, and systems [M]. 3rd ed. New York: Springer, 2008.
[6] CAMMERT M,HEINZ C, KR?MER J, SEEGER B, VAUPEL S,WOLSKE U. Flexible multi-threaded scheduling for continuous queries over data streams [C]// Proceedings of First International Workshop on Scalable Stream Processing Systems. Istanbul, Turkey, 2007: 624-633.
[7] KR?MER J, SEEGER B. A temporal foundation for continuous queries over data streams [C]// Proceedings of 11th International Conference of Management of Data. Goa, India, 2005: 70-82.
[8] GRAEFE G. Query evaluation techniques for large databases [J]. ACM Computing Surveys, 1993, 25(2): 73-170.
[9] MADDEN S, FRANKLIN M J. Fjording the stream: An architecture for queries over streaming sensor data [C]// Proceedings of International Conference on Data Engineering. San Jose, California, USA, 2002: 555-567.
[10] The STREAM Group. STREAM: The Stanford stream data manager [J]. IEEE Data Engineering Bulletin, 2003, 26(1): 19-26.
[11] JIANG Qing-chun, CHAKRAVARTHY S. Queueing analysis of relational operators for continuous data streams [C]// Proceedings of the ACM CIKM International Conference on Information and Knowledge Management. New Orleans, Louisiana, USA, 2003: 271-278.
[12] LIAN Hong, WAN Zhen-kai. The computer simulation for queuing system [J]. World Academy of Science, Engineering and Technology, 2007, 34(1): 176-179.
[13] KLEINROCK L. Queueing systems: Theory [M]. New York: Wiley Interscience, 1975: 119-125.
[14] MEDHI J. Stochastic models in queueing theory [M]. 2nd ed. New York: Academic Press, 2002: 101-109.
[15] MacKAY D. Information theory, inference and learning algorithms [M]. Cambridge: Cambridge University Press, 2003: 285-290.
[16] LEI H, TANG L, IGLESIAS J, MUKHERJEE S, MOHANTY S. S-means: Similarity driven clustering and its application in gravitational-wave astronomy data mining [C]// Proceedings of the International Workshop on Knowledge Discovery from Ubiquitous Data Streams. Warsaw, Poland, 2007: 1124-1135.
[17] CARNEY D, CETINTEMEL U, RASIN A, ZDONIK S B, CHERNIACK M, STONEBRAKER M. Operator scheduling in a data stream manager [R]. Technical Report CS-03-04, Brown University: Department of Computer Science, 2003.
[18] CAMMERT M,KR?MER J,SEEGER B,VAUPEL S. A cost-based approach to adaptive resource management in data stream systems [J]. IEEE Transactions on Knowledge and Data Engineering, 2008, 20(2): 230-245.
[19] VARGA A. OMNeT++ discrete event simulation system version 3.2 user manual [EB/OL]. [2009-01-04] www.omnetpp.org/doc/ manual/usman.htm
[20] PERROS H. Computer simulation techniques: The definitive introduction [EB/OL]. [2009-10-20]. www.csc.ncsu.edu/faculty/ perros/simulation.pdf.
Foundation item: Project(50275150) supported by the National Natural Science Foundation of China; Project(20040533035) supported by the National Research Foundation for the Doctoral Program of Higher Education of China
Received date: 2010-01-27; Accepted date: 2010-05-11
Corresponding author: TAN Guan-zheng, Professor, PhD; Tel: +86-731-85863426; E-mail: tgz@mail.csu.edu.cn
