
DHSWM��һ�ָĽ���WM��ģʽƥ���㷨
�����������¸�
(���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ������ ��ɳ��410083)
ժ Ҫ��
����Ч������ģʽ����ģ����������͵����⣬���һ�ָĽ��㷨����Ԥ�����Σ��ı�ԭ��Hash���е������ṹ������˫��ϣ����ģʽ�������Hash1����ָ�������䣬Hash���д�Ÿô洢�������ʼλ�������䳤�ȣ�Prefix�������ж�ģʽ�����Ƿ�����뵱ǰƥ�䴰�����ı�ǰ��ͬ��ģʽ����Shift���г����ƶ�ֵΪ0ʱ�����ݺ�������ģʽ������λ�õ���Ϣ����ƥ�䴰�ڿɻ����������벢����Shift1���С��ڲ��ҽΣ�����˫��ϣ����Hash1����ijһ�����в���ģʽ���������ڴ��ģģʽ������²��ҹ�����ģʽ����������ƥ�������ƥ�䴰�ڻ����ľ��룬���������ƥ����������̲���ʱ�䡣�о������������ģʽ����ģ�ϴ�ʱ���Ľ�����㷨�����������ƥ���ٶȣ���ģʽ����Ŀ����5 000��ʱ���Ľ��㷨�IJ���ʱ��Ҫ��WM�㷨����40%~47%��
�ؼ��ʣ�
���ּ����ģʽƥ����Wu-Manber�㷨��˫��ϣ������
��ͼ����ţ�TP393 ���ױ�־�룺A ���±�ţ�1672-7207(2011)12-3765-07
DHSWM: An improved multi-pattern matching algorithm based on WM algorithm
LIU Wei-guo, HU Yong-gang
(School of Information Science and Engineering, Central South University, Changsha 410083, China)
Abstract: To resolve the problem that with the constant increase of the number of rules, the performance of Wu-Manber algorithm will become less efficient, an improved Wu-Manber algorithm named double Hash searching Wu-Manber algorithm (DHSWM) was proposed. In the pre-processing stage, the patterns were stored in specified intervals in Hash1 table by double Hash method while Hash table was used to store the parameters which indicate the start address of the interval and its length. Prefix table was used to determine whether the patterns in set and the text of current matching window had the same prefix. When the shifting distance was 0 in Shift table, Shift1 table was used to store the maximum sliding distance of matching window according to the suffixes appearing in other locations of pattern string. In the searching stage, double Hash method was used to look up patterns in the interval of Hash1 table to avoid searching for overlong linked list in the case of large scale pattern set. The sliding distance of matching window was enlarged after the matching procedure, so redundant matching operations was reduced and the search time was shortened. The results indicate that the algorithm can improve the speed of pattern matching when the scale of the pattern set is large. Compared with the WM algorithm, the DHSWM algorithm can reduce the search time by 40%-47% when the number of patterns is more than 5 000.
Key words: intrusion detection; pattern matching; Wu-Manber algorithm; double Hash searching
Ŀǰ��������������ּ��ϵͳ(Network intrusion detection system��NIDS)�ļ��������õ���ģʽƥ�似�������Խ��������ϵͳ����ģʽƥ���ʱ��ռ��NIDS��������ʱ���30%�������������ܼ�����´�80%[1]����ˣ�ͨ���Ľ�ģʽƥ���㷨����Ч�����ϵͳ�ļ���ٶȡ�ģʽƥ���㷨������ģʽƥ���㷨�Ͷ�ģʽƥ���㷨�������ĵ�ģʽƥ���㷨��Knuth-Morris-Patt(KMP)�㷨[2]��Boyer-Moore (BM)�㷨[3] �ȡ����У�BM�㷨Ӧ�ýϹ㷺, �����ٶȱ�KMP�㷨�ٶȿ�3~5 ��������ģʽ����ģ�ϴ�ʱ��BM�㷨��Ч����������ʵ��Ҫ��ģʽƥ���㷨����Aho-Corasick(AC)�㷨[4]��Wu-Manber (WM)�㷨[5]�ȡ�AC�㷨����KMP�㷨�Ļ����ϲ�������״̬��ԭ������ģʽ������ģʽ��Ŀ�϶�ʱ�ܻ�ýϸߵIJ���Ч�ʣ���ͨ������ģʽ����ռ�ô����Ĵ洢�ռ䡣WM�㷨��Ҫ�����ַ���Ծ˼���Hashɢ�м������ܴ�����ƥ���ٶȡ����������ܶ��о���ͨ���Ľ�WM�㷨�Ի�ø��ߵIJ���Ч�ʡ�Yang��[6]���QS�㷨˼��[7]�����QWM�㷨���ڲ��ҽ������ı���ǰƥ����Ϣ�ж��Ƿ����ƥ������������ڵ�������룬�Ľ�����㷨��WM�㷨����ʱ����١�Choi��[8]ͨ���������ģʽ���������L+1-MWM�㷨�����Եõ������Ļ������룻�����ģʽ������С��5ʱ�����㷨��WM�㷨ƽ������ʱ�����38.87%�����Ľ�����㷨�ڴ��ģģʽ������£�Ҳ��WM�㷨�����������ڹ�ϣ���г��ֳ��ȹ�����ģʽ������Ϊ�ˣ��о�����ͨ��������Hash���е���������ʱ�������ƥ���ٶȡ������[9]ͨ���������������Ż��ķ���������ģʽ������֧��ƽ������⣬����WM�㷨�IJ���Ч���ܵõ��ϴ���ߣ�Zhang��[10]�ڲ���ʱͨ���ж�ǰ������ģʽ����ַ�Ƿ��ڹ�ϣ����������ַ��Χ�����������ϣ���е����������������ƥ��������������ٱ���ǰ���й������������⡣�ɼ��������ģʽ����ģ�������������±���WM�㷨�ĸ�Ч��������[11-12]��һ�������������⡣�������߲���˫��ϣ�������Ľ�Wu-Manber�㷨(Double Hash searching Wu-Manber algorithm��DHSWM)���Ӷ�����㷨�IJ���Ч�ʡ�
1 WM�㷨����
1.1 Լ��
����1 �ַ�������һ����Ŀ���ַ����ɵļ��ϣ���Ϊ![]() �����ַ�������Ϊ
�����ַ�������Ϊ![]() ������ȡ��ΪASCII�ַ�����
������ȡ��ΪASCII�ַ�����![]() =128��
=128��
����2 ģʽ����������ƥ����ַ�����Ϊģʽ������Ϊp���ɶ��ģʽ����ɵļ��Ͻ�ģʽ������ΪP={p1��p2������pi}�����У�![]() ��
��![]() (j=1��2������li)��
(j=1��2������li)��
����3 ���������ı��з�����ģʽpi��ȫƥ����ַ���������ƥ�䴰���г�����ģʽ�в�ͬ���ַ�ʱ����ƥ�䴰�����ƻ����ƣ���Ϊ�������ڻ�����������Ծ���ַ�������Ϊ�������롣
����4 ģʽƥ�䣺�����ַ���![]() ��ģʽ��ΪP������Ϊn���ı���T=t1t2��tn��ti��
��ģʽ��ΪP������Ϊn���ı���T=t1t2��tn��ti��![]() (i=1��2������n)������T�����ҵ�pi����ƥ��ɹ�����ƥ��ʧ�ܣ���ƥ�䴰����������һ���������ƥ�䡣��T�в���pi�Ĺ��̳�Ϊģʽƥ�䡣
(i=1��2������n)������T�����ҵ�pi����ƥ��ɹ�����ƥ��ʧ�ܣ���ƥ�䴰����������һ���������ƥ�䡣��T�в���pi�Ĺ��̳�Ϊģʽƥ�䡣
1.2 WM�㷨����
WM�㷨��Ҫ����Ԥ�����Ͳ���2���Ρ�
1.2.1 Ԥ������
��Ԥ�����Σ����ݸ���ģʽ��P��ȷ��ƥ�䴰�ڳ���m=min{length(pi)}��������3�������ƶ���(Shift��)����ϣ��(Hash��)��ǰ��(Prefix��)���ƶ����д洢������T�е�ǰƥ�䴰�ڿɻ����ľ��롣��ϣ���д洢���Ǿ�����ͬ����ģʽ���������ָ�룬ǰ���д洢���Ǿ�����ͬǰ��ģʽ�������ָ�롣
(1) Shift���Ľ�������ÿ�γ���ƥ��ʱ������һ������Ϊk���ַ�������ΪS����Shift���д洢������ƥ��Sʱ���ڿ��Ի����ľ��룬����k���ַ���һ������ƥ��ֵ��ΪShift��������������S��Shift���еĵ�i�����ƥ�䣬ȡ����ģʽ����ǰm���ַ�������2�������
�� ���ַ���S�����κ�ģʽ�г��֣������ȫ�ؽ�ƥ�䴰�����һ���m-k+1���ַ��ľ��룬ȡShift[i]=m-k+1��
�� ��S��ijЩģʽ���г��֣����ҳ�S����Щģʽ�г��ֵ�λ�ã�ȡ���ҳ��ֵ�λ�á�����S��ģʽpi��q����������S�������κ�ģʽ�в��������ڱ�q���λ�ã�ȡShift[i]=m-q��
(2) Hash���Ľ�����ȡģʽ����ǰm���ַ���������k���ַ����Ĺ�ϣֵ�����������洢������ͬ��ϣֵ��ģʽ������ϣ���д洢ָ��������ڵ�ָ�롣
(3) Prefix���Ľ�����Prefix����Hash�����ƣ��ڽ���ʱ����ģʽ��k���ַ�ǰ�Ĺ�ϣֵ����������ͬǰ��ģʽ���洢��ͬһ�����С�
1.2.2 ���ҽ�
�ڲ��ҽΣ����㵱ǰƥ���ı�T�ĺ�k���ַ��Ĺ�ϣֵi��Hash����Shift��������ͬ�Ĺ�ϣֵ��Ϊ��������Shift[i]��0ʱ����ƥ�䴰�����һ���Shift[i]���ַ�������ɨ�裻��Shift[i]=0����Hash[i]����1��ָ��ָ�����о�����ͬ����ģʽ�������������������������ģʽǰk���ַ��Ĺ�ϣֵh��T��ǰk���ַ��Ĺ�ϣֵh������h��h������ɹ��˵�����ͬ��ǰ��ͬ��ģʽ������h=h��������о�ȷƥ�䣬���ɹ������ƥ������ͬʱ����ƥ�䴰�����һ���1λ����ƥ��ʧ�ܣ���ƥ�䴰�����һ���1λ���������ҡ�
1.3 WM�㷨���ڵ���Ҫ����
ͨ����WM�㷨�ķ��������Է����������⣺
(1) ��Ԥ�����ν�����3�����Ĺ������ص������У�Shift�������ж��Ƿ���뾫ȷƥ������ͼ�¼�������룻Hash���洢����ͬ��ģʽ��������Prefix���洢ǰ��ͬ��ģʽ������������ʹ��Shift����Hash��������ģʽ����Ҳ����ʹ��Shift����Prefix��������ģʽ������ˣ�Hash����Prefix���ڹ����Ͽ�����滻��
(2) WM�㷨��ʹ��Prefix�������˾�����ͬ������ͬǰ��ģʽ�����ж��Ƿ���Ҫ��ȷƥ�䡣��ˣ�Prefix��ʵ�������������м��˲��������轨��ģʽ������
(3) ��Hash���д洢��ָ��ָ�������ͬ����ģʽ�������ڽ��о�ȷƥ�����ʱ��Ҫ��������������ʵ��Ӧ�õ����ּ��ϵͳ�У�ģʽ���Ĺ�ģͨ���ܴ�[13]�����¾���ijЩ����ģʽ���������Ƚϳ����ڲ���ʱ������������˷Ѵ�������ʱ�䡣
(4) WM�㷨��ƥ��������֮����ƥ��ɹ����ƥ�䴰�ڵĻ��������Ϊ1����������������ַ��������������ƥ���������ˣ���������������Ŀ��ܡ�
��Щ����ʹ��ʵ��Ӧ����WM�㷨�IJ���Ч�ʽ��ͣ����������Щ����Ľ��㷨��
2 DHSWM�㷨
��DHSWM�㷨�У����˽���Shift����Hash����Prefix��3���������⣬���⽨��Shift 1���� Hash 1����Shift���洢��ǰƥ�䴰�ڿɻ����ľ��룬��Shift�����ƶ�ֵΪ0ʱ��������ģʽ����Shift 1�����ڴ洢����ƥ�������ƥ�䴰�ڿɻ����ľ��롣��WM�㷨�У�Hash���в��������ṹ�洢ģʽ����DHSWM�㷨�в���ά��ԭ�еĴ洢�ṹ��Hash 1���洢ģʽ���е�����ģʽ����������ͬ����ģʽ������˫��ϣ���洢�ڱ��е�ijһ�������䣬�ڲ���ʱֻ����ʱ��е�ָ�����䣻Hash���д洢�IJ�����ʾ�������洢������Hash 1���е���ʼλ�������䳤�ȣ���ģʽ������ʱ��ģʽͷҲ��ȷ���ˡ�Prefix�������ж�ģʽ�����Ƿ�����뵱ǰƥ�䴰�����ı�ǰ��ͬ��ģʽ��
2.1 �㷨����
DHSWM�㷨��WM�㷨һ��Ҳ����Ԥ�����κͲ��ҽΡ�
2.1.1 Ԥ������
��Ԥ�����Σ����ݸ�����ģʽ��P������Shift����Shift 1����Hash����Hash 1���Լ�Prefix����
(1) Shift����Shift 1���Ľ�����Shift���Ľ�����WM�㷨����ͬ����Shift 1����Shift�������Ͻ�����������k���ַ���ɵ��ַ���S��Shift���еĵ�i�����ƥ�䣬��Shift[i]=0��S������ijЩģʽ���Ľ�βʱ���ҳ�S������ģʽ���г���β�������λ�ã���S���������κ�ģʽ���е�����λ��ʱ��ȡShift1[i]Ϊm-k+1����S��ij��ģʽ��pi��q������������S�������κ�ģʽ�в��������ڱ�q�����λ�ã�ȡShift1[i]=m-q����
(2) Hash����Hash1���Ľ�������S������ijЩģʽ�Ľ�βʱ��ͳ�ƾ�����ͬ��S��ģʽ��������ΪN������Щͬ����ģʽ������˫��ϣ���洢��Hash 1���е����������ڣ�����ʼλ����Ϊx���������䳤��Ϊy�������ͬ��S��ģʽ���洢��Hash1[x]��Hash 1[x+y-1]��Hash[i]�洢(x��y)���ڱ�ʾģʽ����Hash1���е�λ�á����ķ������䳤������ͬ����ģʽ����Ŀ������yȡ��ӽ���2N��÷ɭ����[14]��������3���ô���
�� ���ٵõ���������������n=2��3��5��7��13��17�ȣ���2n-1Ϊ÷ɭ����������ֻ��ȡn=2��3��5��7��������Ҫ��
�� ��yȡ����ʱ�����Ա�����yΪ���κ�������ֵ�ı���������ʹ�ö��κ����洢�����ʱ������ѭ�������⡣
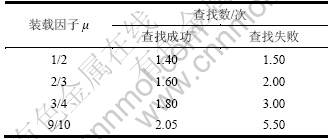
�� ʹ��װ������ԼΪ1/2�������ڷ���˫��ϣ�����õIJ������ܡ����Ϊ��������λ������ܳ��ȵı�ֵ����Ϊװ�����ӡ���1��ʾΪ��ͬװ������ʱ˫��ϣ�����ҳɹ��Ͳ���ʧ����Ԥ�ƵIJ��Ҵ���[15]��
��1 ˫��ϣ�����Ҵ�����װ�����ӹ�ϵ��
Table 1 Relationship between searching times and load factors in double Hash searching
�ڴ洢�Ͳ���ģʽ��ʱ��������˫��ϣ���� Hash 1�����в�����һ�ι�ϣ���������ַ�������ֵ��y����Ľ�������ι�ϣ������1��С��y�ķ�������ֵ�����磬��ģʽpiǰm���ַ�pi1pi2��pim��һ�ι�ϣ����Ϊ��
(pi1*128m-1+ pi2*128m-2+��+ pim*1280)%y=
(��((pi1*128+ pi2)*128+ pi3)��+ pim)%y=
(��(((pi1*128+ pi2)%y *128+ pi3)%y*
128+ pi4)��+ pim)%y
���ι�ϣ����Ϊ��pi1%N+1��
(3) Prefix���Ľ�����Prefix�������жϵ�ǰ�ı��е�ͷ�Ƿ���ģʽ����ͷ�г��֣���ŵ��Dz���ֵ���ֱ�ȡÿһ��ģʽ��ǰk���ַ����������ϣֵh����Prefix[h]���True����ʾ���Լ�����ȷƥ����̣����е�����λ�ô��False����ʾֱ�ӽ�ƥ�䴰����ǰ������
2.1.2 ���ҽ�
�ڲ��ҽΣ�����ƥ�䴰�ڳ���Ϊm��ÿ��ƥ����ַ�������Ϊk�����Ҳ������¡�
(1) ��ƥ�䴰����ƥ���ı�T���˶��룬Tpָ��ƥ�䴰�ڵĽ���λ�ã�Tendָ���ı�����λ�á�
(2) ��Tp��Tendʱ��ȡ��ǰƥ���ı�t1t2��tm�������ı��ĺ�k���ַ�tm-k+1��tm�Ĺ�ϣֵh��
(3) ��Shift[h]>0�������һ���Shift[h]���ַ������ز���(2)����Shift[h]=0����ת����(4)��
(4) ���㵱ǰƥ���ı�ǰt1��tk�Ĺ�ϣֵ�����Prefix���е�ֵ����ΪTrue����ת����(5)����ΪFalse�������һ���Shift1[h]���ַ���ת����(2)��
(5) ����Hash���и����IJ���������˫��ϣ������Hash 1���ж�Ӧ�����䣬�����ı���ģʽ���о�ȷƥ�䣬��ƥ��ɹ����������ģʽ����ƥ�䴰�����һ���Shift1[h]���ַ���Ȼ��ת����(2)����ƥ�䲻�ɹ�����ƥ�䴰�����һ���Shift1[h]���ַ���Ȼ��ת�� ��(2)��
2.2 �㷨Ӧ�÷���
����ģʽ��P={still��trill��study��basic��stability}���ı�TΪ��This chapter will introduce the basic concepts.������ƥ�䴰�ڳ���m=5������k=2�������WM�㷨��DHSWM�㷨��ƥ����̽��жԱȷ�����
Ԥ������WM�㷨��DHSWM�㷨������Shift�����2��ʾ�����м�¼��ֵ������ǰƥ�䴰�ڿɻ����ľ��룬��Shift[i]=0ʱ�����뾫ȷƥ�������DHSWM�㷨����Shift1�����3��ʾ�����м�¼���ƥ�������ƥ�䴰�ڿɻ����ľ��롣WM�㷨��Prefix���洢������ͬͷ��ģʽ��������ͼ1��ʾ�����㡰st���Ĺ�ϣֵ��Ϊ������Prefix[Hash(st)]�洢��ָ��ָ����{stability��still��study}��������ڡ�DHSWM�㷨�ı�Prefix���Ľṹ������ά��ģʽ���������г�{st��tr��ba}��Ӧ��λ�ô�Ų���ֵTrue�⣬������ΪFalse����ʾֻ�е�ƥ���ı���ͷ������ģʽ����ͷʱ��������뾫ȷƥ����������4��ʾ��
��Hash���Ĺ����ϣ�WM�㷨ͨ������ģʽ���е�m-1���͵�m���ַ��Ĺ�ϣֵ��Ϊ��������������ͬ��ϣֵ��ģʽ����������ţ���ͼ2(a)��ʾ��Hash(ll)�洢��ָ��ָ����{still��trill}����������ƥ�䴰�����ı��ĺ�Ϊllʱ����������������DHSWM�㷨���½�Hash 1�����ڴ洢���е�ģʽ����Hash���в���ά��ģʽ��������ͼ2(b)��ʾ��Hash(ll)�д洢����Hash1���е���ʼλ�úͷ������������ij��ȣ���ֵ�ֱ�Ϊ9��3����Ϊll��ģʽ����˫��ϣ�������Hash1[9]��Hash1[11]֮�䡣
��2 Shift��
Table 2 Shift table

��3 Shift1��
Table 3 Shift1 table


ͼ1 WM Prefix���ṹͼ
Fig.1 Storage structure of WM Prefix table

ͼ2 Hash���Ա�ͼ
Fig.2 Comparison of Hash table
��4 DHSWM Prefix��
Table 4 DHSWM Prefix table

���ҽ���ͼ3��ʾ�����У���ͷָ��ǰƥ�䴰�ڵ�β�ַ����ұ�����Ϊ���ڻ����ľ��롣ͼ3(a)��ʾΪWM�㷨���ҹ��̣��������̾���13��ƥ�䣬���г���2���ƶ�ֵΪ0����1��ƥ�䲻�ɹ���������������ƥ�䴰�����һ���1λ����2��ƥ��ģʽ��basic���ɹ�����������ͬʱƥ�䴰�����һ���1λ��ͼ3(b)��ʾΪDHSWM�㷨���ҹ��̣���������11��ƥ�䣬�ڳ����ƶ�ֵΪ0ʱ��ƥ�������ɺ�ʹ��Shift 1���е��ƶ�ֵ����������������4��

ͼ3 ���ҹ���ʾ��ͼ
Fig.3 Searching process
3 ʵ�������
�������ݣ�ƥ���ı�ȡ����Ϊ6.82 MB��Ӣ���ĵ���ģʽ��Ϊ��ASCII�ַ������������ɵ��ַ��������ģʽ������Ϊ5��ģʽ����ģȡ10��50��100��200��500��1 000��5 000��10 000��20 000����̻���ΪWindows XP��JDK1.5.0��
����ʵ��Ա�DHSWM�㷨��WM�㷨�IJ���ʱ�䣬����ģʽ����ģΪ10~1 000ʱƥ��ɹ���ģʽ����Ϊ5������ģʽ����ģ����5 000ʱƥ��ɹ���ģʽΪ50����ʵ�������5��ʾ�����е�1��Ϊģʽ���е�ģʽ��Ŀ����2�к͵�3�зֱ�Ϊʹ��WM��DHSWM�㷨���ı�ƥ��IJ���ʱ�䡣���еIJ���ʱ��ȡ10�β��Խ����ƽ��ֵ����4��ΪDHSWM����ʱ������ʡ�
��5 ʵ����
Table 5 Result of experiment
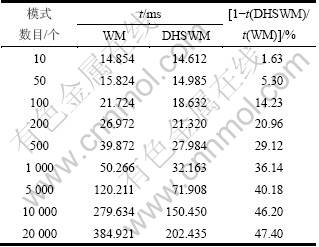
�ӱ�5���Կ���������ģʽ����ģ�IJ��ϼӴ�DHSWM�㷨��WM�㷨��Ȳ���Ч��Խ��Խ�ߡ���ԭ����Ҫ���¡�
(1) ������ƥ�䴰����ƥ�����֮��Ļ������롣��ͨ������£�Shift���е�ֵ����0��ƥ�䴰�ڿ���ͨ�������������ı������ı��Ӵ���ģʽ��������ͬ�ĺ�ʱ��Shift���оͻ����ֵΪ0���������ʱ���뾫ȷƥ�����������ģʽ����ģ������ShiftֵΪ0�ĸ���Ҳ��֮����6��ʾΪģʽ����Ŀ��ͬʱ��Shift�����ƶ�ֵΪ0��ռ�ı������ӱ�6�ɼ�����ģʽ����Ŀ����1 000��ʱ������Shift[i]=0�ĸ��ʳ���30%��ģʽ����ĿΪ20 000��ʱ�ﵽ57%����ʱ��Ƶ�����뾫ȷƥ�������DHSWM�㷨�ڲ��Һ����Shift 1���е��ƶ�ֵ��������WM�㷨����������ַ����Ӷ������˸��������ƥ�������
(2) �����˱���ģʽ��������WM�㷨�У�Hash���������洢������ͬ����ģʽ����7��ʾΪģʽ����ģ��ͬʱ���ӦHash�����������ȵķֲ�������ӱ�7�ɼ�����ģʽ����ģ����500ʱ����ʼ���ֳ��Ƚϳ�(��10)����������ģʽ������5 000ʱ�����ֳ��ȳ���50���������ڲ��ҹ�������������������н���ƥ����������ķѴ����IJ���ʱ�䡣��DHSWM�㷨����˫��ϣ�����в��ң���װ������Ϊ1/2ʱ�����ҵĴ���������2�Σ���ˣ�ʹ��˫��ϣ�������̲���ʱ�䣬�Ӷ���߲���Ч�ʡ�
��6 Shift�����ƶ�ֵΪ0�ı���
Table 6 Percentage of value 0 in Shift table

��7 WM Hash�����������ȷֲ���
Table 7 Distribution of length of linked-list in WM Hash table ��
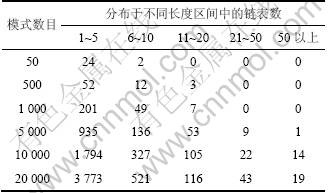
WM�㷨�IJ���ʱ����ģʽ����ģ��������أ�����ʹ��˫��ϣ������Ч�ؽ��Ͳ��Ҵ�����ʹģʽ��Ŀ�����Ӷ�DHSWM�㷨�в���ʱ���Ӱ��Զ���ڶ�WM�㷨�в���ʱ���Ӱ�졣����[6��8��10]������ĸĽ��㷨������Ч�����WM�㷨�IJ���Ч�ʣ�����ʵ����ģʽ��Ŀ������2 000�������Ľ�����ģʽ����ģ������Ч����֤��ģʽ����ģ����ʱ��DHSWM�㷨������Ч����߲���Ч�ʡ�
4 ����
(1) DHSWM�㷨�иı���Prefix���Ĵ洢�ṹ������Shift 1�����ڴ����ƥ��������֮��ƥ�䴰�ڿɻ����ľ��룬�ڲ���ģʽ��ʱͨ������ƥ���ı���ͷ��ʹ��Prefix���ж��Ƿ���о�ȷƥ�䣬�����˽��뾫ȷƥ������Ĵ����������ƥ�������ƥ�䴰�ڲ���Shift 1���еĻ������룬��������������ı��ַ��������˸��������ƥ������������˲��� ʱ�䡣
(2) DHSWM�㷨�ı���Hash���Ĵ洢�ṹ������Hash 1�����ڴ������ģʽ�����ڲ���ģʽ��ʱ���ٲ���WM�㷨�б���ģʽ������ƥ�������ʹ��˫��ϣ����Hash 1�����в���ƥ��ģʽ������ģʽ��Ŀ�϶������£������˱������Ƚϳ���ģʽ������������ƥ��������Ӷ���Ч������˲���Ч�ʡ�
(3) ��ģʽ����ģ�ϴ�ʱ��DHSWM�㷨�IJ������ܸ��š�Ŀǰ�������������������������ֹ���ģʽ���Ĺ�ģ�������ӣ���Ч�ļ������������ʵ�ָ���������������ʵʱ���ּ�⡣
�ο����ף�
[1] Fisk M, Varghese G. An analysis of fast string matching applied to content-based forwarding and intrusion detection[R]. San Diego: University of California, 2002: 1-9.
[2] Knuth D E, Morris H, Pratt V R��Fast pattern matching in strings[J]. SIAM Journal on Computing, 1977, 6(2): 323-350.
[3] Boyer R S, Moore J S. A fast string searching algorithm[J]. Communications of the ACM, 1977, 20(10): 762-772.
[4] Aho A V, Corasick M J. Efficient string matching: An aid to bibliographic search[J]. Communications of the ACM, 1975, 18(6): 333-340.
[5] Wu S, Manber U. A fast algorithm for multi-pattern searching[R]. Tuscon: University of Arizona, 1994: 1-11.
[6] YANG Dong-hong, XU Ke. An improved Wu-Manber multiple patterns matching algorithm[C]//The 25th IEEE International Performance, Computing, and Communications Conference. Phoenix, USA, 2006: 675-680.
[7] Sunday D M. A very fast substring search algorithm[J]. Communications of the ACM, 1990, 33(8): 132-142.
[8] Choi Y H, Jung M Y, Seo S W. L+1-MWM: A fast pattern matching algorithm for high-speed packet filtering[C]//2008 Proceedings IEEE INFOCOM. Phoenix, USA, 2008: 261-265.
[9] ���, ������. ��������Ķ�������⼼��[J]. ͨ��ѧ��, 2007, 28(11): 87-91.
WU Bing, YUN Xiao-chun. Network-based malcode detection technology[J]. Journal on Communications, 2007, 28(11): 87-91.
[10] ZHANG Bao-jun, CHEN Xiao-ping, PING Ling-di. Address filtering based Wu-Manber multiple patterns matching algorithm[C]//Proceedings of the 2009 Second International Workshop on Computer Science and Engineering (WCSE 2009). Qingdao, China, 2009: 408-412.
[11] CAO Bin, LAN Hua, SHEN Xuan-jing. Application of set-based multi-pattern matching algorithm for intrusion detection system[C]//2008 Second International Symposium on Intelligent Information Technology Application. Piscataway, USA, 2008: 706-710.
[12] ��ѩ, Ѧһ��. һ�������ڴ��ģ�������Ŀ���ƥ���㷨[J]. �����������Ӧ��, 2007, 43(34): 168-170.
LI Xue, XUE Yi-bo. High-performance string matching algorithm for large scale string set[J]. Computer Engineering and Applications, 2007, 43(34): 168-170.
[13] Wang J S, Kwak H K, Jung Y J. A fast and scalable string matching algorithm using contents correction signature hashing for network IDS[J]. IEICE Electronics Express, 2008, 5(22): 949-953.
[14] ��ΰѫ. Mersenne��Mp���ǹ�����[J]. ��ѧ�о�������, 2007, 27(4): 693-696.
LI Wei-xun. All Mersenne numbers are anti-sociable numbers[J]. Journal of Mathematical Research and Exposition, 2007, 27(4): 693-696.
[15] ��������. Java �㷨[M]. ���Ľ�, ��. ����: �廪��ѧ������, 2004: 474-478.
Sedgewick R. Algorithm in Java[M]. ZHAO Wen-jin, trans. Beijing: Tsinghua University Press, 2004: 474-478.
(�༭ �²ӻ�)
�ո����ڣ�2010-12-06�������ڣ�2011-03-10
������Ŀ��������Ȼ��ѧ����������Ŀ(61073187)
ͨ�����ߣ�������(1963-)���У����������ˣ���ʿ�����ڣ�������������Ϣ��ȫ��������Ϣ�����о����绰��0731-88830062��E-mail��liuwg@csu.edu.cn
ժҪ�����WM�㷨�IJ���Ч������ģʽ����ģ����������͵����⣬���һ�ָĽ��㷨����Ԥ�����Σ��ı�ԭ��Hash���е������ṹ������˫��ϣ����ģʽ�������Hash1����ָ�������䣬Hash���д�Ÿô洢�������ʼλ�������䳤�ȣ�Prefix�������ж�ģʽ�����Ƿ�����뵱ǰƥ�䴰�����ı�ǰ��ͬ��ģʽ����Shift���г����ƶ�ֵΪ0ʱ�����ݺ�������ģʽ������λ�õ���Ϣ����ƥ�䴰�ڿɻ����������벢����Shift1���С��ڲ��ҽΣ�����˫��ϣ����Hash1����ijһ�����в���ģʽ���������ڴ��ģģʽ������²��ҹ�����ģʽ����������ƥ�������ƥ�䴰�ڻ����ľ��룬���������ƥ����������̲���ʱ�䡣�о������������ģʽ����ģ�ϴ�ʱ���Ľ�����㷨�����������ƥ���ٶȣ���ģʽ����Ŀ����5 000��ʱ���Ľ��㷨�IJ���ʱ��Ҫ��WM�㷨����40%~47%��
