
������Ϣƿ����������˹SVM��Web�ĵ������㷨
����ǿ1, 2����ϼ1��Ǯ��2
(1. ���Ϲ�ҵ��ѧ ��Ϣ��ѧ�빤��ѧԺ������ ֣�ݣ�450001��
2. �й���ҵ��ѧ(����) ��������Ϣ����ѧԺ��������100083)
ժ Ҫ��
��ͳ�ĵ���ʾ�ĸ�ά�Լ����ô������ޱ��������������ͬ���Web�ĵ������㷨�ķ������ܣ�����˻�����Ϣƿ����������˹SVM��Web�ĵ������㷨�����㷨�������û�����Ϣƿ���Ĵʾ��������ȡ�����ĵ�����ʾ�ļ�����������Ȼ�����ڽ�ά��ĵ�ά�����ռ�����������˹SVM���������з����о���ʵ�������������㷨���кܺõķ������ܡ�
�ؼ��ʣ�
�����ھ����ĵ���������Ϣƿ����������˹SVM��
��ͼ����ţ�TP18 ���ױ�־�룺A ���±�ţ�1672-7207(2011)S1-0731-06
Web document classification algorithm based on IB and LapSVM
WANG Zi-qiang1, 2, SUN Xia1, QIAN Xu2
(1. School of Information Science and Engineering, Henan University of Technology, Zhengzhou 450001, China;
2. College of Mechanical Electronic and Information Engineering,
China University of Mining and Technology(Beijing), Beijing 100083, China)
Abstract: To effectively overcome the high-dimensionality of document representation and improve the performance of Web document classification algorithm with a large amount of unlabeled data, the Web document classification algorithm based on information bottleneck (IB) and Laplacian support vector machine (LapSVM) was proposed. First, the information bottleneck-based word clustering algorithm was used to obtain the discrimination feature for concise document representation, then the LapSVM classifier was applied to classifying documents in the reduced lower dimensional feature space. Experimental results show that the proposed classification algorithm achieves superior classification performance.
Key words: data mining; document classification; information bottleneck; LapSVM
�ĵ�����������ǽ�һ���������ĵ����䵽һ�����߶��ȷ��������С������������Ŵ��������ֻ��������ĵ������Ǻ��������ɡ��洢�ʹ�ȡ�������θ�Ч�ض���Щ�ĵ�������֯������ͼ��������Ϊһ����Ҫ���о����⡣����ȫ���������������չ�����ϵ��ĵ����ݸ��dzʡ���ըʽ������������о���������Web�ĵ������ܷ��༼�����Եø������кͱ�Ҫ�ˡ��ڹ�ȥ�ļ����У��й�ѧ�߶�Web�ĵ��ķ��༼�������˴�����̽��������˶��ֻ��ڻ���ѧϰ���ĵ��Զ������㷨[1]����Щ�ĵ������㷨���漰������2���ؼ����⣺(1) �����ȡ�����ĵ���ʾ�ļ�����������(2) �����������ȡ�Ļ����϶��µIJ����ĵ����з��ࡣ���ĵ���������ȡ���棬���ĵ������㷨���Dz��������ռ���ߴʴ�(Bag of Words)ģ������ʾ�ĵ��������ڸ��ĵ�������ʾ�У��ĵ��е�ÿ���ʶ�ӳһ�����������ܸ�ģ�;��и����ֱ�������ص㣬�����䲻��֮�������ײ�����ά�����ѡ����⣬�⽫����Ӱ�����ĵ��������ķ������ܺͼ���Ч��[2]�� ���⣬��������ѡ�����ĵ�������ȡ֮�����һ���ؼ����⣬Ŀǰ���õķ������㷨���Է�Ϊ�ල���мල�Ͱ�ල3�����͡������ǽ���������ͼ�İ�ලѧϰ�������������ڶ�ģʽ����������ȡ���˺ܺõķ������ܶ��ܵ����ǵĹ㷺��ע[3]�����ǽ���Ӧ���ڴ��ģ��άWeb�ĵ����Զ������һ���д��о����ѵ�����֮һ��Ϊ����Ч�ؿ˷���ͳ�ĵ���ʾ�ĸ�ά�Լ����ô������ޱ��������������ͬ����ĵ������㷨�ķ������ܣ����������һ�ֻ�����Ϣƿ��[4-7]��������˹SVM��Web�ĵ������㷨����ͨ���ڴ��ģ�ĵ��������ݼ��ϵ�ʵ����˵�����㷨����Ч�ԡ�
1 Web�ĵ�������������ȡ
Ϊ����Ч�ػ�ȡWeb�ĵ�����ʾ�ļ������������Կ˷��ĵ���ʾʱ�ġ�ά�����ѡ����⣬��ߺ���ĵ��������ķ������ܺͼ���Ч�ʣ����Dz��û�����Ϣƿ����Web�ĵ�������������ȡ�������÷������ŵ��ǣ�������Ϣƿ����õĴʾ����ʾ�ܹ��ڻ�ô�֮�������Զ����Ż����ͬʱȡ����С������ɢ�Ⱥ�������ɢ�ȣ��Ա����̶ȵػ�������ĵ���ʾ����ʾ�ļ�����������
��Ϣƿ��(IB)ּ��ͨ�����������X���ֳ��ܹ����ֺ���һ����ر���Y֮�以��Ϣ�IJ�ͬ����ʵ�ֶ�X����ر�������ʾ���������X��Y֮������ϸ��ʷֲ�ΪP(X��Y)��X�Ļ���(��������)Ϊ![]() ������IB���Ż�Ŀ�꺯������ʽ�����������£�
������IB���Ż�Ŀ�꺯������ʽ�����������£�
![]() (1)
(1)
Լ������Ϊ��
![]() (2)
(2)
ʽ�У��±�ʾ�Ա���X�е���ϢԼ��̶ȣ�![]() ��
��![]() �ֱ��ʾ����
�ֱ��ʾ����![]() ��Y��X֮��Ļ���Ϣ���䶨�����£�
��Y��X֮��Ļ���Ϣ���䶨�����£�
![]() (3)
(3)
![]() (4)
(4)
ʽ�У�H(X)��ʾ�������X���أ��䶨�����£�
![]() (5)
(5)
ʽ(1)�е�IB���Ż�Ŀ��ּ����С��X�Ļ��ֺ������Y�Ļ���Ϣ֮��Ѱ��һ���Ż����ԡ���ʵ�ϣ���ʽ(2)Լ���£�ʽ(1)�е��Ż�����Ľ����������ʽ��������
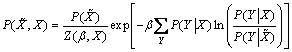 (6)
(6)
ʽ�У�Z(�£�X)��һ���������ӣ���������Լ����Ϣ����������ϵ����һ������ģ���˻�����������Ҫ�ľ�����Ŀ�����������Ŀ��Ӧ��أ�![]() �����������±�Ҷ˹������м��㣺
�����������±�Ҷ˹������м��㣺
![]() (7)
(7)
![]() (8)
(8)
��������Ϣƿ��(IB)�㷨���дʾ����Ի���ĵ�����ʾ�Ĺ����У����������еı���X��ʾ�������ĵ��еĴʣ�����Y��ʾ�ĵ�������ǣ�����Ԫ��(w��c)���������ϸ��ʷֲ�P(X��Y)�����У�w��ʾ�ĵ��еĴʣ�c��ʾ������w���ĵ�������ǡ�����ָ���ľ�����Ŀk��IB�㷨��������һ������ȫ���������ݵľ��࣬Ȼ����ÿ��ѭ������������ģ���˻�ϵ����ʽ(6)~(8)�Ծ�����л���ֱ���ﵽ���ѭ����������Ϊֹ�����ÿ���ʷ��䵽һ���ʾ����в�������յĴʾ��������Ա��ں���ĵ��������ĸ�Ч�����о���
2 �ĵ����������
����Web�ĵ��������⣬һ��������Ϣƿ���㷨��ø�ά�ĵ����ݵĵ�ά����ʾ֮���ĵ�����������ƺ��Ż�������һ����Ҫ����Ĺؼ����⡣������Web�ĵ����������У����Ǻ����õ�����û������ǵ��������ݣ��õ����б���������������ܵ������Ͳ��������ƶ�ʮ�����ޣ�������DZ�����û��ڰ�ලѧϰ�ķ�������������ò����б�ǵ��������ݺʹ������ޱ��������������ͬ����ĵ������㷨�ķ������ܺͷ��������������������ǣ��������������������������������˹SVM(LapSVM)[8]�ĵ���������
�������l��������ǵ��ĵ����ݼ�![]() ��u��������ǵ��ĵ����ݼ�
��u��������ǵ��ĵ����ݼ�![]() �����У������
�����У������![]() ��ʾ�ĵ�����xi��������𣬼������һ��ͨ�õķ�����ߺ���f����������ܵİ�ලѧϰ��Ŀ������С������Ŀ�꺯����
��ʾ�ĵ�����xi��������𣬼������һ��ͨ�õķ�����ߺ���f����������ܵİ�ලѧϰ��Ŀ������С������Ŀ�꺯����
![]() (9)
(9)
ʽ�У�V(��)��ʾ��������������ĵ��ϵ���ʧ��������A���ڿ��������ϣ�����ؿռ�(Hilbert Space)�Ͼ��ߺ���f�ĸ����ԣ���M���ڿ����ڴ������ݷֲ���չʾ���������μ��νṹ�Ͼ��ߺ���f�ĸ����ԡ�
���ݺ˿ռ������еı�ʾ������֪��ʽ(9)�е���С�Ż�����Ľ�����б�Ǻ��ޱ���������ݵ�������չ���ɣ�
![]() (10)
(10)
���У�K(��)��ʾ�˺�����
������ʽ(9)�п���ͨ��ʹ�ò�ͬ����ʧ����V(��)��������![]() ���γɲ�ͬ�İ�ල�������㷨���ڱ����У����Dz�����SVM�������е�������ʧ������
���γɲ�ͬ�İ�ල�������㷨���ڱ����У����Dz�����SVM�������е�������ʧ������
![]() (11)
(11)
���⣬�ɺ˿ռ����ۿ�֪����ϣ�����ؿռ��ϵľ��ߺ���f�ɱ�ʾΪ������ʽ��
![]() (12)
(12)
���У�w��ʾSVM�еķ��������ձ�ʾ�ĵ����ݵ�ϣ�����ؿռ�ķ�����ӳ�䣻K��ʾ�����º˺������ɵĺ˾���
![]() (13)
(13)
ͬʱ���ɺ˿ռ��еĿ��������ۿ�֪��w��ϣ�����ؿռ��е������б���������ޱ����������������϶��ɣ�����
![]() (14)
(14)
ʽ�У�![]() ��
��![]() ��
��
���⣬��������(ƽ��)�������ۿ�֪��������ͬ���νṹ�ĵ���ܾ�����ͬ������ǡ���������ѧϰ�У��ĵ����ݵ��������νṹ��ͨ���б�Ǻ��ޱ�����ݹ�ͬ���ɵļ�Ȩ����ͼ�������ģ�����ʽ(9)�е�ʽ�ұߵĵ�3�����дΪ������ʽ��
![]() (15)
(15)
ʽ�У�L=D-W����Ϊͼ������˹���ԽǾ���D�ļ��㷽ʽ���£�
 (16)
(16)
���⣬ʽ(15)�о���f�ı�ʾ��ʽ����ʽ(10)����дΪ������ʽ��
![]() (17)
(17)
���ǣ���ʽ(17)����ʽ(15)�ɵ�:
![]() (18)
(18)
��ʽ(11)��(12)��(18)�ֱ����ʽ(9)�ɵ�������˹SVM�������Ż�Ŀ�꺯����
![]() (19)
(19)
Լ������Ϊ:
![]() (20)
(20)
Ϊ�˻����ʽ(20)Լ���µ�ʽ(19)�е��Ż��⣬����ͨ���������պ�����������¶�ż�����ã�
![]() (21)
(21)
Լ������Ϊ:
![]() (22)
(22)
![]() (23)
(23)
ʽ�У�
![]() (24)
(24)
![]() (25)
(25)
����ʽ(21)�е�������˹SVM�Ż�������һ�����ι滮���⣬��ˣ����ǿ�����ѵ����ͳSVM�ĸ�Чѵ��������ѵ��������˹SVM��һ������Ż��Ħ�*��������ʽ(25)���֧�������������ǣ�����һ���µ��ĵ���������x��������˹SVM�����������������¾��ߺ����ж�������ǣ�
![]() (26)
(26)
3 �ĵ������㷨����
������Ϣƿ����������˹SVM��Web�ĵ������㷨�ľ���ʵ�ֹ��̿��������£�
����1����Ϣƿ��(IB)��Ŀ�꺯����������X��ʾ�������ĵ��еĴʣ�����Y��ʾ�ĵ�������ǣ�����Ԫ��(w��c)���������ϼ��ʷֲ�P(X��Y)������w��ʾ�ĵ��еĴʣ�c��ʾ������w���ĵ�������ǡ�����ʽ(1)��(2)����IB���Ż�Ŀ�꺯������ʹ����С����X���ֵ�ͬʱ�����Y֮��Ļ���Ϣ��
����2�����������ĵ���ά������ʾ�Ĵʾ��ࡣ���ȣ�������ÿ��ѭ������������ģ���˻�ϵ����ʽ (6)~(8)�Դʾ�����л���ֱ���ﵽ���ѭ����������Ϊֹ��Ȼ��ÿ���ʷ��䵽һ���ʾ����в�������յĴʾ��������Ա㽫ÿ���ʾ�����Ϊ�ĵ���ά��ʾ�ļ������������뵽���������˹SVM�������н���ѵ����
����3���ڽ�ͼ�м�Ȩ����Ĺ��졣���ڵ�ά�����ռ��д���l��������ǵ��ĵ�������![]() ��
��![]() ��������ǵ��ĵ�������
��������ǵ��ĵ�������![]() ������������(l+u)���ĵ��������ݼ����������ڽ�ͼ����ͼ�м�Ȩ����Wij�Ĺ��췽�����£�����ڸ��ڽ�ͼ�ж���i����ʾ���ĵ���������xi�Ƕ���j����ʾ���ĵ���������xj������ھ�֮һ�����ڶ���i�Ͷ���j֮�䴴��һ���ߣ��Ҹñߵ�Ȩ��Wij=1������Wij=0��
������������(l+u)���ĵ��������ݼ����������ڽ�ͼ����ͼ�м�Ȩ����Wij�Ĺ��췽�����£�����ڸ��ڽ�ͼ�ж���i����ʾ���ĵ���������xi�Ƕ���j����ʾ���ĵ���������xj������ھ�֮һ�����ڶ���i�Ͷ���j֮�䴴��һ���ߣ��Ҹñߵ�Ȩ��Wij=1������Wij=0��
����4���˾���ļ��㡣����ʽ(13)������˾���K�е�ÿ��Ԫ��Kij��
����5��������˹SVM�Ż�Ŀ�꺯���Ľ���������ʽ(19)��(20)����������˹SVM���Ż�Ŀ�꺯�����������������պ������õ����ż����(ʽ(21))��
����6��������˹SVM���������о��������������ȣ�ͨ�����ʽ(21)�еĶ��ι滮�������Ż��Ħ�*��Ȼ����ʽ(25)������Ż���֧���������������ʽ(26)����������˹SVM���������о��������µ��ĵ��������ݽ��з���Ԥ�⡣
4 ʵ����
Ϊ�˼����������Ļ�����Ϣƿ����������˹SVM��Web�ĵ������㷨�����ܣ����Dz�����WebKB[9]��20NG[10]��2���������ĵ��������ݼ���Ϊʵ��������Դ���ĵ������㷨���������۲����˳��õ�3��������������ȷ��(Classification Accuracy)�������(Break-Even Point)ֵ��F1ֵ�����ǵ�ֵԽ��˵���ĵ������㷨�ķ�������Խ�á�
Ϊ�˲������������Web�ĵ������㷨�ķ������ܣ����Ƕ�����3���ĵ������㷨��WebKB��20NG���ݼ��ϵķ������ܽ������ۺϲ��ԱȽϣ�
��1�֣����ȣ�����DZ����������(LSI)���Ը�ά�ĵ����ݽ���������ȡ��Ȼ��������֧��������(SVM)�����������ĵ����࣬���LSI-SVM�㷨��
��2�֣����ȣ�������Ϣƿ��(IB)���Ը�ά�ĵ����ݽ���������ȡ��Ȼ��������֧��������(SVM)�����������ĵ����࣬���IB-SVM�㷨��
��3�֣����ȣ�������Ϣƿ��(IB)���Ը�ά�ĵ����ݽ���������ȡ��Ȼ��������������˹SVM(LapSVM)�����������ĵ����࣬���IB-LapSVM�㷨��
֧��������(SVM)��������˹SVM(LapSVM)�еĺ˺��������˸�˹�˺�����
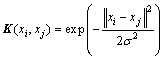 (27)
(27)
ʽ�У��˿��Ȳ���������ʮ�ν�����֤�������Ż����ã�LapSVM�е�����ھ�������Ϊ10����A�ͦ�M��ȡֵ�������������������Ż����á�
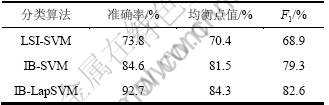
Ϊ�˲����ĵ������㷨LSI-SVM��IB-SVM��IB-LapSVM���ĵ��������ݼ�WebKB��20NG�ϵķ������ܣ��������ѡ��ÿ�����е�20%������ǵ��ĵ����ݼ���ʣ���30%�ޱ������������Ϊѵ�������ٽ�ʣ����ĵ������Ӽ���Ϊ���Լ���ͬʱ��Ϊ��ȷ�������㷨���Ե��ȶ��ԣ���10���������ѵ�����Ͳ��Լ���ƽ�����н����Ϊ���ղ��Խ������1�ͱ�2�ֱ����������3���ĵ������㷨��WebKB��20NG���ݼ��ϵķ���ȷ�ʡ������ֵ��F1����ֵ�IJ��Խ����
�ӱ�1�ͱ�2�е�ʵ�����ݿ��Կ��������������Web�ĵ��㷨IB-LapSVM�ķ������������Ƚϵ�3�ַ����㷨�б�����ã��㷨LSI-SVM�ķ������ܱ�������Ҫԭ�����ڣ�������Ϣƿ��(IB)�Ĵʾ�����ܹ��ڻ�ô�֮�������Զ����Ż����ͬʱȡ����С������ɢ�Ⱥ�������ɢ�ȣ�������̶ȵشﵽ�˷�������Ŀ�ģ�����˺���ĵ������������ܺͼ���Ч�ʡ����⣬LapSVM�����������ܹ���Ч�������������б��������Ϣ������������в�ͬ�����ĵ����ݣ����һ��ܹ����ô������ޱ����Ϣ�������ĵ��������ڵľֲ����νṹ���Ӷ���һ�������LapSVM�������ķ�������������������������LapSVM�㷨���ĵ��������ݼ�WebKB��20NG��ȡ���˺ܺõķ������ܡ�
��1 ��WebKB���ݼ��ϵķ������ܱȽ�
Table 1 Classification performance comparison on WebKB

��2 ��20NG���ݼ��ϵķ������ܱȽ�
Table 2 Classification performance comparison on 20NG
���⣬���ڲ�����A�ͦ�M�Ƿ����㷨IB-LapSVM�е�2���ؼ����������в�����A���ڿ�����ϣ�����ؿռ��Ͼ��ߺ���f�ĸ����ԣ�������M���ڿ��������μ��νṹ�Ͼ��ߺ���f�ĸ����ԡ�Ϊ�˲��Բ�����A�ͦ�M���㷨IB-LapSVM�ķ������ܣ�ͼ1
��2����������֮��ı�ֵ![]() �����ȷ��֮
�����ȷ��֮
��Ĺ�ϵ����ͼ1��2���Կ�����������1��������A�֦�Mʱ�������㷨IB-LapSVM�ڲ������ݼ�WebKB��20NG�ϵķ���ȷ����ߡ�ԭ�����ڣ�����A�֦�Mʱ���㷨IB-LapSVM�ܹ����������мල��Ϣ�ʹ������ල��Ϣ֮��ﵽһ��ƽ�⣬�����ܹ���ֵ������������б��������Ϣ������������в�ͬ�����ĵ����ݣ�ͬʱ�����������ô������ޱ��������������ʾ�ľֲ����νṹ����һ�����������������������ȡ���˽ϸߵķ���ȷ�ʡ�
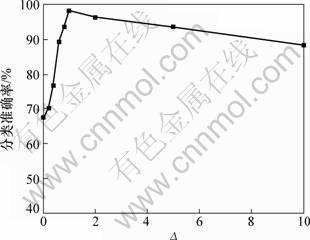
ͼ1 ��WebKB�Ц���ȷ��֮��ı仯ʾ��ͼ
Fig.1 Accuracy variation with �� on WebKB
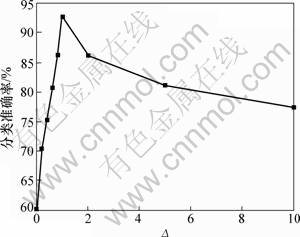
ͼ2 ��20NG�Ц���ȷ��֮��ı仯ʾ��ͼ
Fig.2 Accuracy variation with �� on 20NG
5 ����
Ϊ����Ч�ؿ˷���ͳ�ĵ���ʾ�ĸ�ά�Լ����ô������ޱ��������������ͬ����ĵ������㷨�ķ������ܣ����������һ�ֻ�����Ϣƿ����������˹SVM��Web�ĵ������㷨���ڴ��ģ�ĵ�����WebKB��20NG�ϵ�ʵ�������������㷨���кܺõķ��� ���ܡ�
�ο����ף�
[1] Sebastiani F. Machine learning in automated text categorization[J]. ACM Computing Surveys, 2002, 34(1): 1-47.
[2] �ս���, �Ų���, ���. ���ڻ���ѧϰ���ı����༼���о���չ[J]. ����ѧ��, 2006, 17(9): 1848-1859.
SU Jin-shu, ZHANG Bo-feng, XU Xin. Advances in machine learning based text categorization[J]. Journal of Software, 2006, 17(9): 1848-1859.
[3] Belkin M, Niyogi P. Semi-supervised learning on Riemannian manifolds[J]. Machine Learning, 2004, 56(1/3): 209-239.
[4] Tishby N, Pereira F C, Bialek W. The information bottleneck method[C]//Proceedings of the 37th Annual Allerton Conference on Communication, Control and Computing(ACCCC��99). Champaign, USA, 1999: 368-377.
[5] Al-Mubaid H, Umair S A. A new text categorization technique using distributional clustering and learning logic[J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(9): 1156-1165.
[6] Bekkerman R, El-Yaniv R, Tishby N, et al. Distributional word clusters vs. words for text categorization[J]. Journal of Machine Learning Research, 2003, 3: 1183-1208.
[7] Dhillon I S, Mallela S, Kumar R. A divisive information-theoretic feature clustering algorithm for text classification[J]. Journal of Machine Learning Research, 2003, 3: 1265-1287.
[8] Belkin M, Niyogi P, Sindhwani V. Manifold regularization: A geometric framework for learning from labeled and unlabeled examples[J]. Journal of Machine Learning Research, 2006, 7: 2399-2434.
[9] Craven M, DiPasquo D, Freitag D, et al. Learning to extract symbolic knowledge from the world wide Web[C]//Proceedings of the Fifteenth National Conference on Artificial Intelligence(AAAI��98). Madison, USA, 1998: 509-516.
[10] 20 News Group[EB/OL]. [1999-10-20]. http://kdd.ics.uci.edu/ databases/20newsgroups/20newsgroups.html.
(�༭ �)
�ո����ڣ�2011-04-15�������ڣ�2011-06-15
������Ŀ��������Ȼ��ѧ����������Ŀ(70701013)������ʡ��Ȼ��ѧ����������Ŀ(102300410020)
ͨ�����ߣ�����ǿ(1973-)���У�����̫���ˣ���ʿ�������ڣ����»���ѧϰ��ģʽʶ���о����绰��13838368359��E-mail��wzqagent@126.com
ժҪ��Ϊ����Ч�ؿ˷���ͳ�ĵ���ʾ�ĸ�ά�Լ����ô������ޱ��������������ͬ���Web�ĵ������㷨�ķ������ܣ�����˻�����Ϣƿ����������˹SVM��Web�ĵ������㷨�����㷨�������û�����Ϣƿ���Ĵʾ��������ȡ�����ĵ�����ʾ�ļ�����������Ȼ�����ڽ�ά��ĵ�ά�����ռ�����������˹SVM���������з����о���ʵ�������������㷨���кܺõķ������ܡ�
