
J. Cent. South Univ. (2012) 19: 511-516
DOI: 10.1007/s11771-012-1033-2![]()
Improved hidden Markov model for speech recognition and POS tagging
YUAN Li-chi(Ԭ���)1, 2
1. School of Information Technology, Jiangxi University of Finance and Economics, Nanchang 330013, China;
2. School of Information Science and Engineering, Central South University, Changsha 410083, China
? Central South University Press and Springer-Verlag Berlin Heidelberg 2012
Abstract:
In order to overcome defects of the classical hidden Markov model (HMM), Markov family model (MFM), a new statistical model was proposed. Markov family model was applied to speech recognition and natural language processing. The speaker independently continuous speech recognition experiments and the part-of-speech tagging experiments show that Markov family model has higher performance than hidden Markov model. The precision is enhanced from 94.642% to 96.214% in the part-of-speech tagging experiments, and the work rate is reduced by 11.9% in the speech recognition experiments with respect to HMM baseline system.
Key words:
hidden Markov model; Markov family model; speech recognition; part-of-speech tagging��
1 Introduction
Hidden Markov model (HMM) [1] is a statistical model used by most of speech recognition systems all over the world. It gains great successful applications due to the strong modeling ability for time-sequence structure. In the statistical model based on HMM, the time- sequence structure of speech signal is considered to be a double-stochastic-process: one is the hidden stochastic process, a finite state Markov chain used to simulate the statistic characteristic changes of speech signal; the other stochastic process is the observation sequence related to the state of Markov chain. Hidden Markov model can be categorized as discrete hidden Markov model (DHMM), continuous hidden Markov Model (CHMM) and semi-continuous hidden Markov model (SCHMM) [1].
Hidden Markov model has also been applied successfully to natural language processing [2-11]. Tagging words with their correct part-of-speech (singular proper noun and predeterminer) are important precursor to further automatic natural language processing. Part-of- speech (POS) tagging [12-14] method based on HMM is one of the prominent distinct approaches. Successive word (observations) is assumed to be independent and identical distribution within a tag (state) in hidden Markov tagging model.
The advent of HMM has brought about a considerable progress [15-20] in speech recognition technology over the last two decades, and nowhere has this progress been more evident than in the area of continuous speech recognition with many vocabulary speakers [21-22]. However, a number of unrealistic assumptions [22-25] with HMMs are still regarded as obstacles for their potential effectiveness. A major one is the inherent assumption [26] that successive observations are independent and identical distribution (IID) within a state. In order to overcome the defects of classical HMM, a new statistical model, Markov family model (MFM), was proposed. Markov family model is constructed on a Markov family consisting of multiple stochastic processes which have probability relations between each other. Independence assumption in HMM is placed by conditional independence assumption in MFM. It has also been successfully applied to speech recognition and natural language processing. The independent continuous speech recognition model of the speaker based on MFM was implemented.
2 Hidden Markov model and Markov family model
Definition 1: A hidden Markov model [1, 24] is a five-tuple ��=(S, A, V, B, D), where S![]() {s1, ��, sN} is a finite set of states; V
{s1, ��, sN} is a finite set of states; V![]() {v1, ��, vM} is a finite observation alphabet set; D
{v1, ��, vM} is a finite observation alphabet set; D![]() {d1, ��, dN} is the distribution of initial states.
{d1, ��, dN} is the distribution of initial states.
Define X to be a fixed state sequence of length T and corresponding observation O as
X![]() {x1, x2, ��, xT}
{x1, x2, ��, xT}
O![]() {o1, o2, ��, oT}
{o1, o2, ��, oT}
where
Di=P(x1=s1), 1��i��N (1)
Denote A=(ai,j)N��N to be a probability distribution on state transitions, where
ai,j=P(xt+1=sj|xt=si), 1��i��N, 1��t��T (2)
It means the probability of a transition to state sj from si.
Denote B=(bj,k)N��M to be a probability distribution on state symbol emissions, where
bj,k=P(ot=vk|xt=si), 1��k��M, 1��i��N (3)
It means the probability of observing the symbol vk when in state si.
From the definition of HMM, it can be seen that HMM is based on a double-stochastic-process: a finite state Markov chain is the hidden stochastic process, the other stochastic process is the observation sequence related to the state Markov chain. A major unrealistic assumption with HMM is that successive observations are independent and identically distributed within a state. In order to cope with the deficiencies of classical HMM, Markov family model, a new statistical model was introduced.
Definition 2: Let {Xt}t��1={x1,t, ��, xm,t}t��1 be a m- dimensional stochastic vector, whose componential variables Xi= {xi,t}t��1 (1��i��m) take values in finite sets Si (1��i��m). These componential variables Xi (1��i��m) construct a m-dimensional Markov family model if satisfying the following conditions:
1) Each componential variable Xi (1��i��m) is a ni- order Markov chain:
![]() (4)
(4)
2) What value a variable will take at time t is only related to its previous values before time t and the values that the rest variables take at time t:
![]()
![]() (5)
(5)
3) Conditional independence:
![]()
![]() (6)
(6)
The first condition means that MFM is constructed by a multiple stochastic process. From this point, the standard HMM can be considered as a special case of MFM. The second one demonstrates the relations among these Markov chains of MFM, and it can also simplify the calculation of model. According to the third condition, the previous (ni-1) values that a variable Xi will take before time t and the values that the rest variables will take at time t are independent if the value of variable Xi takes at time t is known. From the view of the statistics, the assumption of independence is stronger than the assumption of conditional independence and it can be inferred from independence to conditional independence. So, the assumption of conditional independence in MFM is more realistic than the assumption of independence in HMM.
3 Using MFM for tagging
Tagging words with their correct part-of-speech (singular proper noun and predeterminer) are important precursors to further automatic natural language processing. Part-of-speech tagging is used as an early stage of linguistic text analysis in many applications, including sub-categorization acquisition, text-to-speech synthesis and corpus indexing. Two prominent distinct approaches in previous researches are rule-based morphological analysis [12] and stochastical model [13] like HMM.
A major unrealistic assumption with HMM tagging model is that successive words (observations) are independent and identically distributed within a tag (state). Under the assumption, the probability of a word depends both on its own tag and previous word, but its own tag and previous word are independent if the word is known. Markov family model has been successfully applied to part-of-speech tagging.
Let S1 be the finite set of part-of-Speech tags, and S2 be the finite set of words. Suppose that word sequence {wi}i��1 and tag sequence {ti}i��1 are Markov chains of MFM. Thus, a word��s tag and its previous word are independent if the word is known:
![]() (7)
(7)
For simplicity, also suppose that word sequence {wi}i��1 and tag sequence {ti}i��1 are both two-order Markov chains, and can find the sequence of tags (t1,n=t1, ��, tn) maximizing the probability of the tag sequence given the word sequence w1,n=w1, ��, wn:
![]()
![]() (8)
(8)
where
![]()
![]() (9)
(9)
According to the properties of MFM, there is
![]() (10)
(10)
Then, from Eq. (7),
![]()
![]()
![]() (11)
(11)
So,
![]()
![]() (12)
(12)
Once there is a probabilistic model, the next challenge is to find an effective algorithm for getting the tag sequence with the maximum probability given as an input. Viterbi Algorithm [24] is a dynamic programming method which efficiently computes a given word sequence (w1, ��, wn) to generate the tag sequence (t1, ��, tn) according to model parameters. The computing procedure is
Step 1: Initialization
Given a sentence of length n; the number of the tag set is T; compute ![]()
![]()
![]() 1��j��T.
1��j��T.
Step 2: Induction
for i: = 1 to n-1 step 1 do
for all tags tj do
![]()
![]()
Step 3: Termination and path-readout
X1, ��, Xn are the tags chosen for words w1, ��, wn; let
![]()
for j: =n-1 to 1 step -1 do
![]()
Step 4![]()
4 Continuous speech recognition model based on MFM
The basic recognition unit was used popularly to represent salient acoustic and phonetic information in speech recognition stochastical model like phone model [1]. Phone models include context-independent phone model, word-dependent phone model and context- dependent phone model, which is also called triphone model. Assume that sl (l=1, ��, D) stands for states, where L is the total number of states in phone model, variable xn is the state at time n (n��1), and yn is the observation feature in state xn. Some related parameters are defined as
![]()
![]()
![]()
![]()
The speech recognition model proposed in this work combines the advantages of both context-independent phone model and word-dependent phone model [1, 25]. Assume that wv (v=1, ��, V) stands for words, where V is the total number of words in the vocabulary of recognition system, and word wv has totally Lv states,
which is represented by![]() W={w1, w2, ��,
W={w1, w2, ��,
wN}, is a word string hypothesis for a given acoustic observation sequence O={o1, o2, ��, oT}, and ![]() is the j-th (1��j��Li) state of the word wi, then the corresponding state sequence can be represented as
is the j-th (1��j��Li) state of the word wi, then the corresponding state sequence can be represented as
![]() (13)
(13)
The task of speech recognition is to find the most likely word sequence W={w1, w2, ��, wT} for an input observation sequence O={o1, o2, ��, oT}, and can be formulated as a search for the most likely state sequence S (then word sequence W can be decided by state sequence S). Given the observation sequence O as
![]()
![]()
![]() (14)
(14)
Let![]() be segment points,
be segment points,
then
![]()
![]()
![]()
![]() (15)
(15)
When i=1, ![]()
![]() K��2 (16)
K��2 (16)
In practice, the cases of K-gram language models that people usually use are for K=2, 3, 4, referred to as bigram, trigram and four-gram, respectively. The probability P(S|W) in Eq. (14) can be calculated as
![]()
![]()
![]() (17)
(17)
According to the properties of MFM, there is
![]()
![]()
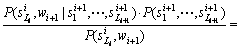
![]() (18)
(18)
Based on the Bayes rule,
 (19)
(19)
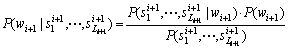 (20)
(20)
Substitute Eqs. (19) and (20) into Eq. (18), then
![]()
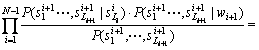
![]()
![]()
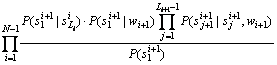 (21)
(21)
To solve the problem of sparse data and take the advantages of both context-independent phone model and word-dependent phone model, the parameters of Eq. (21) can be estimated by smoothing method:
![]()
![]() (22)
(22)
where ![]() is a smoothing parameter.
is a smoothing parameter.
5 Experimental results
5.1 POS tagging experiments
An annotated corpus was used, which was selected from People��s Daily newspaper 1998 for training and testing. The corpus uses 42 tags and has 244 974 tokens. Some properties about the annotated corpus are listed in Table 1. The experimental results are demonstrated in Table 2.
Table 1 Properties of annotated corpus
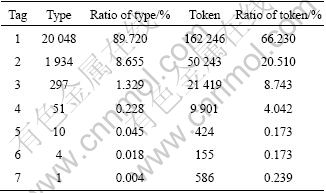
Table 2 Tagging experimental result
![]()
From Table 2, it can be seen that the tagging method based on MFM has higher performance than the conventional POS tagging method based on HMM under the same testing conditions. The precision is enhanced from 94.642% to 96.214%. The reason for this improvement may be that the assumption of conditional independence in MFM is more realistic than the assumption of independence in HMM.
As shown in Fig. 1, the relation between the scale of training corpus and the enhancement of tagging accuracy is not linear. In general, when the scale of training corpus is larger, the obtained probability parameter will be closer to the true language phenomenon and the tagging accuracy will also be enhanced. But, when the scale of training corpus reaches a certain degree, the enhancement amplitude of tagging accuracy becomes smaller, and system performance is improved slowly.
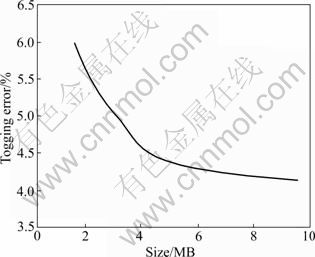
Fig. 1 Relation between training test result and tagging error
5.2 Speech recognition experiments
An investigation of use of new model was carried out in a large-vocabulary speaker independent continuous speech recognition task. The Wall Street Journal Corpus was designed to provide general-purpose speech data with large vocabularies. In these experiments, the standard SI-84 training material, containing 7 240 sentences from 84 speakers (42 males and 42 females) was used to build the phone models, and another Wall Street Journal Corpus with 20k words (20k-WS) was used for testing.
The baseline system is a gender-independent within- word-triphone mixture-Gaussian tied state HMM system. In this model set, all the speech models have three emitting states, left-to-right topology. The evaluations are based on the word error rate (WER) and the experimental results comparison are listed in Table 3.
Table 3 Performance of baseline system and new system
![]()
From Table 3, it can be seen that the efficiency of the proposed approaches is verified and a significant improvement in model quality and recognition performance is obtained. The application of the speech recognition model based on MFM reduces the word error rate for the 20k-WSJ test data by up to 11.9% in respect to HMM baseline system.
We have checked out that the WER of baseline system for slow and fast speech increases up to 2.8 and 2.5 times with respect to the WER for average speech rate, as shown in Fig. 2. The reason for this improvement is that some of the problematic utterances are classified in the normal speech group and then the word accuracy for normal speech slightly decreases.
6 Conclusions
1) An improved HMM was proposed. The speaker independent continuous speech recognition experimental results and the part-of-speech tagging experimental results have verified that the efficiency of the proposed model is improved from 94.642% to 96.214% and the word error rate reduced by 11.9%.
2) Theory about Markov Family model should be progressed right along, and the applications of MFM in speech recognition and natural language processing will be further studied in the future.

Fig. 3 Word error rates for slow speech rate (a) and fast speech rate (b)
References
[1] RABINER L, JUANG B H. Fundamentals of speech recognition [M]. New Jersey, USA: Prentice Hall, 1993: 210-235.
[2] LIU Shui, LI Sheng, ZHAO Tie-jun. Directly smooth interpolation algorithm in head-driven parsing [J]. Journal of Software, 2009, 20(11): 2915-2924. (in Chinese)
[3] AVIRAN S, SIEGEL P H, WOLF J K. Optimal parsing trees for run-length coding of biased data [J]. IEEE Transaction on Information Theory, 2008, 54(2): 841-849.
[4] ZHOU De-yu, HE Yu-lan. Discriminative training of the hidden vectors state model for semantic parsing [J]. IEEE Transaction on Knowledge and Data Engineering, 2009, 21(1): 66-77.
[5] LI Zheng-hua, CHE Wan-xiang, LIU Ting. Beam-search based high-order dependency parser [J]. Journal of Chinese Information Processing, 2010, 24(1): 37-41. (in Chinese)
[6] GOLDBERG Y, ELHADAD M. SplitSVM: Fast space-efficient non-heuristic, polynomial kernel computation for NLP applications [C]// Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics on Human Language Technologies (ALT). Columbus USA, 2008: 237-240.
[7] NIVRE J, McDONALD R. Integrating graph-based and transition- based dependency parsers [C]// Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics on Human Language Technologies (ALT). Columbus USA, 2008: 950-958.
[8] CHE Wan-xiang, LI Zheng-hua, HU Yu-xuan, LI Yong-qiang, QIN Bing, LIU Ting, LI Sheng. A Cascaded syntactic and semantic dependency parsing system [C]// CoNLL 2008: Proceedings of the 12th Conference on Computational Natural Language Learning, 2008: 238-242.
[9] WANG Hong-ling, ZHOU Guo-dong, ZHU Qiao-ming, QIAN Pei-de. Exploring various features in semantic role labeling [C]// Proceedings of 2008 International Conference on Advanced Language Processing and Web Information Technology (ALPIT2008). 2008: 23-25.
[10] VILARES J, ALONSO M A, VILARES M. Extraction of complex index terms in non-English IR: A shallow parsing based approach [J]. Information Processing and Management, 2008, 44: 1517-1537.
[11] ZHENG Yan, CHENG Xiao-chun, CHEN Kai. Filtering noise in Web pages based on parsing tree [J]. Journal of China Universities of Posts and Telecommunications, 2008, 15(9): 46-50.
[12] TURISH B. Part-of-speech tagging with finite-state morphology [C]// Proceedings of the International conference on Collocations and Idioms: linguistic, Computational, and Psycholinguistic perspective. Berlin German, 2003: 18-20.
[13] BRANTS T. A statistical Part-of-Speech tagger [C]// Proceeding of the Sixth Applied Natural Language Processing Conference (ANLP- 2000). Seattle USA, 2000: 224-231.
[14] GIMENEZ J, MARQUEZ L. Fast and accurate part-of-speech tagging: The SVM approach revisited [C]// Proceedings of the 4th International Conference on Recent Advances in National Language Processing (4th RANLP). Bulgaria, 2003: 153-163.
[15] GONG Y. Stochastic trajectory modeling and sentence searching for continuous speech recognition [J]. IEEE Transactions on Speech Audio Processing, 1997, 5(1): 33-44.
[16] YAN Bin-feng, ZHU Xiao-yan, ZHANG Zhi-jiang, et al. Robust speech recognition based on neighborhood space [J]. Journal of Software, 2007, 18(11): 878-883. (in Chinese)
[17] LIU Yu-hong, LIU Qiao, REN Qian. Speech recognition based on fuzzy clustering neural network [J]. Chinese Journal of Computers, 2006, 29(10): 1894-1900. (in Chinese)
[18] TANG Yun, LIU Wen-ju, XU Bo. Mandarin digit string recognition based on segment model using posterior probability decoding [J]. Chinese Journal of Computers, 2006, 29(4): 635-641. (in Chinese)
[19] Hui, DU Li-min. Combination of acoustic models trained from different unit sets for chinese continuous speech recognition [J]. Journal of Electronics and Information Technology, 2006, 28(11): 2045-2049.
[20] YAN Long, LIU Gang, GUO Jun. A study on robustness of large vocabulary chinese continuous speech recognition system based on wavelet analysis [J]. Journal of Chinese Information Processing, 2006, 20(2): 60-65. (in Chinese)
[21] WANG W J, CHEN S H. The study of prosodic modeling for mandarin speech [C]// Proceedings of the International Computer Symposium (ICS). Hualien, China, 2002: 1777-1784.
[22] CHANG E, ZHOU J L, DI S, HUANG C, LEE K F. Large vocabulary mandarin speech recognition with different approaches in modeling tones [C]// Proceedings of the 6th International Conference on Spoken Language Processing (ICSLP 200). San Jose, USA, 2000(II): 983-986.
[23] WANG Zuo-ying, XIAO Xi. Duration distribution based HMM speech recognition models [J]. Chinese Journal of Electronics, 2004, 32(1): 46-49.
[24] MANNING C D, SCHUTZE H. Foundations of statistical natural language processing [M]. London: The MIT Press, 1999: 121-147.
[25] RABINER L R. A tutorial on hidden Markov models and selected applications in speech recognition [J]. Proceedings of the IEEE, 1989, 77(2): 257-285.
[26] HON Hsiao-wuen, WANG Kuan-san. Unified frame and segment based models for automatic speech recognition [C]// Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP 2000). Turkey, 2000: 1017-1020.
(Edited by DENG L��-xiang)
Foundation item: Project(60763001) supported by the National Natural Science Foundation of China; Projects(2009GZS0027, 2010GZS0072) supported by the Natural Science Foundation of Jiangxi Province, China
Received date: 2011-09-22; Accepted date: 2011-10-28
Corresponding author: YUAN Li-chi, Associate Professor, PhD; Tel: +86-791-83983891; E-mail: yuanlichi@sohu.com
Abstract: In order to overcome defects of the classical hidden Markov model (HMM), Markov family model (MFM), a new statistical model was proposed. Markov family model was applied to speech recognition and natural language processing. The speaker independently continuous speech recognition experiments and the part-of-speech tagging experiments show that Markov family model has higher performance than hidden Markov model. The precision is enhanced from 94.642% to 96.214% in the part-of-speech tagging experiments, and the work rate is reduced by 11.9% in the speech recognition experiments with respect to HMM baseline system.
