
���ڷ�Χ����ķ�һ�������ݿ�ۼ���ѯ
л ������ ��
(���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ������ ��ɳ��410083)
ժ Ҫ��
ժ Ҫ�����ڷ�һ���Թ�ϵ���ݿ�ķǾۼ���ѯ��������չ��ͨ��һ���Բ�ѯӦ������壬�����һ�������ݿ�ķ�Χ���壬��������һ���Բ�ѯ��Χ��ʵ�ʾۼ���ѯ��д���������ػ�����������ľۼ���ѯ��Χֵ��ͨ���Գ�ʼ�������Ժͼ����Ծۼ��õ���ѡ��������ٹ������ʼ��������ֵ���ͻ�Ͳ������ʼ��ѯ��Ԫ�顣������Сֵ�����˵����ܲ�һ�µ�Ԫ�飬ȥ������ֵ���õ�һ����ֵ���������ֵ���õ����ܵ�����ѡֵ��ʵ�����TPC-H�����ò�ͬ�IJ��������о����о�����������ۼ����Ժ�ͶӰ�������������ݿ��Լ���ʼ��ѯ�Ľ��������д��ѯ�ĸ�����������Ӱ�죬����һ�������ݱ���������ͬ��ֵԪ������Ӱ���С��������д��ѯ�ȳ�ʼ��ѯ��ִ��ʱ�䳤�����ǿ��Խ��ܡ�
�ؼ��ʣ�
��ϵ���ݿ�����һ�������ݿ����ۼ���ѯ��
��ͼ����ţ�TP311 ���ױ�ʶ�룺A ���±�ţ�1672-7207(2008)04-0810-06
Aggregation queries based on range semantics in inconsistent databases
XIE Dong, WU Min
(School of Information Science and Engineering, Central South University, Changsha 410083, China)
Abstract: Based on the query technique without aggregation in inconsistent databases, the common semantics of consistent query answering was developed to present the range semantics and a practical rewriting approach for aggregation queries based on the range of consistent answer, which returned to the range values. The candidate set was obtained by aggregating the original grouping and key attributes, and filtering the tuples that conflicted with the original grouping attribute values and were dissatisfied with the original query. For the minimum, the approach filtered possible inconsistent tuples and discarded the possible values to obtain the consistent values. For the maximum, the possible greatest candidate values were obtained. In the experiment, TPC-H was used to study the performance with different references. The results show that the overload of rewritten query is obviously affected by some aspects such as the number of aggregation and projection attributes, the size of database and result sets of the original query, but the overload has little effect on the proportion of inconsistent data and the number of tuples with the same key values. The running time of rewritten queries is longer than that of the original queries, but the overload is reasonable and the approach is effective.
Key words: relational database; inconsistent database; aggregation query
������Լ��(integrity constraint��IC)��Ч�ر�֤�����ݵ������ԡ�Ȼ������ʵ�����һ��ʵ�������ݿ��г�����Ӧ�����һ�µ����ݡ����ڸ�����Լ�������ݿ�����Ƿ�һ�������ݿ�(inconsistent database, IDB)[1]�����磬���ݴӶ�������Լ���Ķ�������Դ������[2]�����ܾͲ�����Լ����������ϴ[3]��ʶ��;��������еĴ��ָ����ݿһ����״̬�������ּ����ǰ��Զ��ģ��Ҵ������۰���һ�����������������õģ�������Ϊ�˱������ݵ�һ���Զ������ݣ��������õ����ݶ�ʧ�����IC���ܱ�ǿ�������Ƽ���ϵͳ�����������ԡ����еļ������ǻ���һ�������ݿ�ģ���֧����IDB�ϵõ��IJ�������һ�������ݵġ���������ѯ��������������ϴ��һ�ַ�����һ���Բ�ѯӦ��(Consistent query answering, CQA)[1]��CQA����Դ���ݲ��ı䣬�ڲ�ѯʱ�����һ���ԣ�ʶ��һ�������ݡ�
��һ�������ݻ����У����ۼ���ѯ�ܻ��ȷ������ֵ�������ڷ�һ�������ݿ���Ԫ����ֵ�IJ�ȷ���ԣ��ۼ���ѯ���ܷ���һ���Խ������ˣ���Ҫ��CQA������е���[4-5]���ڷ�Χ�����£���ϵ���������Ե����ֵ����Сֵ�ļ�����Ա�һ�ײ�ѯ��ʾ����ѯӦ��[6]���ص���С����ֵ�����ں�ѡ���ݿ��л�õľۼ�����ֵ��ConQuerϵͳ[7-10]��չ��һ�־ۼ���ѯ��д��ܣ�����һ�ײ�ѯ��д�����Դ����״����IJ�ѯ������д����Ч����������DBMS�Ĺ��ܣ�����������ֵ�����䡣Hippoϵͳ[11-12]����Ԫ���ͻͼ�ŵ��ڴ���ȥ����һ���Խ����ǰ�������ݿ���ֻ���ڽ��ٵij�ͻԪ�飬�����ij�ͻ��ͼ�㹻С���ܴ洢�������С������������ݿ��д��ڴ����ij�ͻԪ�飬���ͻͼ���ص��ڴ��л���ɶ����ϵͳ���ء�����ڲ�ѯ��д��Infomixϵͳ[13-14]�ܴ������е�һ�ײ�ѯ�����������Լ�����ͣ������ص��ǻ����ȶ�ģ������Ŀɱ����Ժͻ�ȡ��ȷ��������������Ǽ������Ч�ԺͿ���չ�ԣ����ܲ�����Ч�Ľ�������
CQA�ľۼ���ѯ���㸴������һ����ս�����⣬������ۼ������ļ�����NP��ȫ���⣬Ҳ��ʾһЩ�ۼ���ѯ�ܱ���Ч�ؼ���[4-5]���ڼ�����Դ��������£��ۼ���ѯ���ں�����������һ�����ľۼ�������Ӧ��(MIN(A), MAX(A), COUNT(*), COUNT(A), SUM(A)��AVG(A)) ��ɡ�
�������������з�һ���Թ�ϵ���ݿ�ķǾۼ���ѯ�����Ļ����ϣ������һ�������ݿ�ķ�Χ���壬��������һ���Բ�ѯ��Χ��ʵ�ʾۼ���ѯ��д���������ػ�����������ľۼ���ѯ�ķ�Χֵ��ʵ�����TPC-H����֧�ֻ�[15]���ò�ͬ�IJ���(���ݳߴ硢��һ�������ݵı����Լ�Υ����Լ����Ԫ�����)�����о�����������÷�������Ч�ġ�
1 ��ظ���
һ�����ݿ�ģʽ�Ǿ�������Ԫ���Ĺ�ϵ������Ԫ��ļ��ϡ�CQA�ڹ�ϵ���ݿ��У����ù̶��Ĺ�ϵģʽS=(U, R, B)�����У�U��ʾ���ܵ��������ݿ���R��ʾһ�����ݿ�ν�ʣ�B��ʾһ�����ݿ�����ν��(�����٣������ݣ�������)�����ģʽ������һ��ν��������L(S)��һ�����ݿ�ʵ��D���Կ��������ݿ�Ԫ��R*(c1, ��, cn)��������(R*��R��1��ν�ʣ�c1, ��, cn��U�еij���)��������Լ��C��L(S)�е���䣬����ģʽ��һ�ײ�ѯ���ԡ���ˣ�һ����ѯ��L(S)��һ����ʽQ(x1, ��, xn)�����У�x1, ��, xn�����ɱ�����n��0����ÿ��D���Rep(D, C)��D��|Q(t��)����Ԫ��t��=(t1, ��, tn)��һ���Խ��������x1, ��, xn�ֱ�ȡֵt1, ��, tnʱ����n��0�����ѯ�Dz�����ѯ������ÿ��D���Rep(D, C )����D��|=Q(t��)�����ѯΪ�棬����Ϊ�١�
����1 ��һ�������ݿ�[1]����I�����ݿ�D��1��ʵ��������D�ϵ�����������Լ��C����![]() I�bC����D��һ�£�����D�Ƿ�һ�������ݿ⡣
I�bC����D��һ�£�����D�Ƿ�һ�������ݿ⡣
����2 ��Լ��(Soft constraint, SC)���û�������һ��������Լ���ƣ�û�н����ڿ��ܵķ�һ�������ݿ�D�ϣ����ǽ��������û���ѯDʱ���ѡ���Ϊ��ѯһ�������ݵĿ������أ�������Լ����Ϊ��Լ����
����3 �ԳƲ�(Distance[1])�������ݿ�ʵ��I��I�䣬��2�����ݿ�ʵ���ĶԳƲ�?(I, I��)=( I-I��)��(I��-I)��
����4 ��ѡ���ݿ�(Repaired/Candidate database��CDB[1])������һ��������Լ���ƺ����ݿ�ʵ��I����I��|�ƣ���I����I���ڡƵ�1��CDB���Ҳ�����I*�b�ƺ�?(I, I��)![]() ?(I, I*)��
?(I, I*)��
I���ǹ�ϵ������Ƶ�I���Ӽ�����I����С������Rep(I, ��) ��ʾI���ڡƵ�CDB��
����5 һ���Բ�ѯӦ��(CQA[1])����I��ģʽR��1�����ܲ�����һ��������Լ���Ƶ����ݿ�ʵ��������1����ѯQ��������I���ڡƵ�ÿ��CDB IREP������t��Q(IREP)����t�ǹ��ڡƵ�һ���Խ������ʾΪt���QCQA(I,��)����Ϊ������ѯ����QCQA(I,��)��true(false)��
����6 �ۼ���ѯq��ʾΪ������ʽ(����G��һ��������ԣ�agg1(e1), ��, aggn(en)�Ǿۼ�����ʽ)��
SELECT G, agg1(e1) e1, ��, aggn(en) en FROM R [WHERE SC] GROUP BY G
���ڿ��ǵ��Ƿ�һ�������ݣ�������Լ�����ܽ�����Υ��Լ�������ݿ��ϣ���SQL��ѯ������������GROUP BY����У���û�г�����SELECT����У���ˣ��������¼ٶ���
�ٶ�1 �ٶ��о���������Լ����Ϊ��Լ����
�ٶ�2 �ٶ���ѯ��GROUP BY���������Ҳ������SELECT����С�
����7 ����(Interval[4])����һ��������Լ���ƺ����ݿ�ʵ��I�����ۼ���ѯq��ÿ����ѡ���ݿ��Ϸ��ص�v![]() [a, b]����q��I�ϵ�һ���Խ��������[a, b](���ޣ�a��b����)����ʾΪI�bq��
[a, b]����q��I�ϵ�һ���Խ��������[a, b](���ޣ�a��b����)����ʾΪI�bq��![]() [a, b]����[a, b]��һ���Խ������aΪ�½磬bΪ�Ͻ硣��û����������һ���Խ������[a, b]�����ŵ�һ���Խ�������У�a����½�(greatest-lower-blound-answer, glb-answer)��bΪ��С�Ͻ�(least-upper-blound-answer, lub-answer)��
[a, b]����[a, b]��һ���Խ������aΪ�½磬bΪ�Ͻ硣��û����������һ���Խ������[a, b]�����ŵ�һ���Խ�������У�a����½�(greatest-lower-blound-answer, glb-answer)��bΪ��С�Ͻ�(least-upper-blound-answer, lub-answer)��
�Ծۼ����ﷵ�ط�Χ(�߽�ֵ)������ȷ����ֵ�����ڷ�Χ���壬��Ҫ����CQA�����壬����8�����˷�Χ��֤��������G��ÿ��ֵ��һ���Խ����
����8 һ���Բ�ѯ��Χ(Range of consistent answer, ROCA)����D��һ�����ݿ⣬qG��һ���ۼ���ѯ��q��qGȥ���ۼ���IJ�ѯ������һ���ѯԼ��������ÿ����ѡ���ݿ�I����t��q��D�ϵ�һ���Խ������ÿ���ۼ�ֵv����glb-answer(����½�)��v��lub-answer(��С�Ͻ�)����(t, glb-answer, lub-answer)��qG��D�ϵ�һ���Բ�ѯ��Χ��
2 �ۼ���ѯ��д
��1 ������ʾ�ͻ����Ĺ�ϵR(custkey, nation, mkt, balance)���ֱ��ʾ�ͻ��ţ������г���������t1, ��, t6Ԫ���ʵ��I={(c1, n1, b1, 1 000), (c1, n2, b1, 100), (c2, n2, b1, 2 000), (c2, n2, b2, 200), (c3, n2, b2, 3 000), (c3, n1, b2, NULL)}���������²�ѯ��
SELECT nation, SUM(balance) FROM R WHERE mkt= ��b1�� GROUP BY nation
I�����µ�CDB��I1={t1, t3, t5}��I2={t1, t3, t6}��I3={t1, t4, t5}��I4 ={t1, t4, t6}��I5={t2, t3, t5}��I6={t2, t3, t6}��I7={t2, t4, t5}��I8={t2, t4, t6}��ÿ��CDB��һ�µģ���������I�ӽ���������ܺͷֱ�Ϊ6 000��3 000��4 200��1 200��5 100��2 100��3 300��300���������һ���Խ�������ݷ�Χ���壬����������ΧΪ300��sumbal��6 000���ٶ���ϵR��2n(n��0)��Ԫ��(ÿ��Ԫ���������һ����ͻԪ��)������2n����ѡ���ݿ⡣SUM(pay)�ڿ��ܵ�ָ������CDB�н�����ָ������ֵ(0��2n+1)���Dz��ɼ���ġ�
��ˣ����Dz��ò�ѯ��д��������ѯ��д�Dz���һ�ײ�ѯ��д�����Դ����״����IJ�ѯ������д����д�IJ�ѯҲ��һ�ģ����Ա�SQL��ʾ����ˣ�CQA�����ܱ���ͬ�����ݿ��ѯ����ֱ�����á�������д��ѯ����PTIME�Ͷ��������ݵ�;���µõ�����������ַ����ڼ��㸴�Ӷ�ʱ��PTIME�ġ�
t1��t2��t3�������ʼ��ѯ��Ԫ�飬ROCA����n1��n2����ֵ��ɡ�����ROCA������õ�ÿ���ͻ��������±߽�ֵ��Ȼ����͡�8��CDB���������ֵ�ֱ�Ϊ{(n1, 1 000), (n2, 2 000)}, {(n1, 1 000), (n2, 2 000)}��{(n1, 1 000), (n2, 0)}, {(n1, 1 000), (n2, 0)}, {(n1, 0), (n2, 2 100)}, {(n1, 0), (n2, 2 100)}, {(n1, 0), (n2, 100)}��{(n1, 0), (n2, 100)}����ˣ�ROCA��{(n1, 0, 1 000), (n2, 0, 2 100)}����ÿ��CDB�У�nationΪn1�Ŀͻ���������0��1 000֮�䣬1 000��I1��I2��I3��I4�У�0������CDB�У�nationΪn2�Ŀͻ���������0��2 100֮�䣬2 100��I5��I6�У�0������CDB�С��������µ���д��ѯ�õ�ROCA��
WITH cand AS(
SELECT nation, custkey, MIN(balance) minb,MAX(balance) maxbal
FROM R WHERE mkt = 'b1'
GROUP BY nation,custkey ),
min_cand1 AS(
SELECT custkey FROM cand
GROUP BY custkey
HAVING COUNT(*)=1),
min_cand2 AS(
SELECT custkey FROM min_cand1 m WHERE NOT EXISTS(SELECT *
FROM R c
WHERE c.custkey=m.custkey AND (c.mkt<>'b1' OR
c.mkt IS NULL))),
min_cand3 AS(SELECT nation,minb
FROM cand c, min_cand2 m
WHERE c.custkey=m.custkey),
max_cand AS(
SELECT nation,SUM(minb) minb,
SUM(maxbal) maxbal FROM cand
GROUP BY nation)
SELECT m2.nation,(CASE WHEN m1.nation IS NULL THEN 0 ELSE m1.minb END) minbal,maxbal
FROM max_cand m2 LEFT OUTER JOIN min_cand3 m1 ON m2.nation =m1.nation
�㷨1�����������Ӿۼ���ѯ��д�㷨������˼�����£�
a. ��Сֵ���ڴ��ڿ���ֵ(����ͻԪ�����СֵΪ0)������Ҫ�ѿ���ֵ�ų������õ���Ȼֵ(һ����Ԫ��)��Ȼ�������ֵ�����ȣ��Գ�ʼ��ѯ��������ԣ��Գ�ʼ�������Ժͼ����Խ��оۼ������ֵ����Сֵ���õ�cand�������
b. ���ڳ�ͻԪ�����СֵΪ0��min_cand1������cand�еij�ʼ��������ֵ���ͻ��Ԫ�顣��SC������ѡ��ν���У������в�����ѡ���������������ѡ�������෴(����NSC��ʾ)��ѡ����������ֵΪ��(����ISNULL(SCA)��ʾ)����������ڼ�����ֵ��˵�����ڴ��ڶ��ѡ���������ֵ�������Dz������ʼ��ѯ��Ԫ����֣���ˣ�����СֵҲΪ0����Ҫ��min_cand1�Ĺ��˻����ϣ��ٹ��˵��������ʼ��ѯ��Ԫ�飬�õ�min_cand2�������
c. �Թ��˲�������Сֵmin_cand2��������ѡ������������ӣ��������˵ij�ʼ�������Ե���Сֵ0���������ֵ�ǿ��ܵ�����ѡֵ����ˣ���cand������ij�ʼ�������Ծۼ���Ͳ�����max_cand3 ������е����ֵ��ȷ���ģ�û�б�min_cand2���˵���Сֵ��ȷ���ġ�
d. ���max_cand�����������min_cand3���������min_cand3�ij�ʼ��������Ϊ�գ���Ϊ0��������ȷ������Сֵ�����ֵ��
�㷨1. RewriteAgg(q,��)
���룺�ۼ���ѯq����Լ����
�������д��ѯQ��
WITH cand AS(
SELECT G,key,MIN(e1) AS
min_e1, MAX(e1) AS max_e1,��,
MIN(en) AS min_en,MAX(en) AS max_en
FROM R WHERE SC GROUP BY G, key),
min_cand1 AS(SELECT key
FROM cand GROUP BY key
HAVING COUNT(*)=1),
min_cand2 AS(
SELECT key FROM min_cand1 m
WHERE NOT EXISTS( SELECT * FROM R
WHERE R.key =m.key AND
(NSC OR ISNULL(R.SCA)))),
min_cand3 AS(
SELECT G,min_e1,��, min_en
FROM cand c,min_cand2 m
WHERE c.key =m.key),
max_cand AS(
SELECT G, SUM(min_e1) AS min_e1,��, SUM(max _en) AS max _en,SUM(max_e1) AS max_e1,��, SUM(max _en) AS max _en
FROM cand GROUP BY G)
SELECT m2.G,(CASE WHEN m1.G IS NULL THEN 0 ELSE m1.min_e1 END) min_e1, max_e1,��, CASE WHEN m1.G IS NULL THEN 0 ELSE m1.min_en END) min_en, max_en
FROM max_cand AS m2 LEFT OUTER JOIN
min_cand3 AS m1 ON m2.G=m1.G
3 ʵ�����
������д������ʵ�黷��ΪIntel Celeron 2.53 GHz���ڴ�Ϊ512 MB��Windows XP professional��SQL Server2005��ʵ�����TPC-H�淶��ѯ�е�Q1��Q6[15]��Q1��Q6��ͶӰ�;ۼ����������ֱ�Ϊ10��8��1��1������TPC-H��ѯ����ı����ã����ɲ�ͬ�ߴ�ķ�һ�������ݣ����������²�����
a. ���ݳߴ�s������s=0.1��0.5��1��2 GB(1 GB���ݿ�Լ��800��Ԫ��)��
b. �����ݿ�ķ�һ���Բ��֣�Υ���˼�Լ����n��Ԫ�鹲��һ����ͬ�ļ�ֵ��ʵ���n ȡ2��
c. ���ݿ��һ���Եİٷֱ�p�����������ݿ�ÿ����ϵ����ͬ��p��ʵ���p����0��0.01��0.05��0.10��0.20��0.50��
ͼ1��ʾΪp=5%��n=2��1GB���ݿ�ļ��㸺�ء�����(Tr-To)/To(Tr��ʾ��д��ѯʱ�䣬To��ʾ�� ʼ��ѯʱ��)��ʽ�����㣬Q1����д��ѯ����Ϊ9.89��Q6����д��ѯ����Ϊ0.88����д��ѯ�ȳ�ʼ��ѯִ��ʱ��Ҫ��������Ҫ����Ϊ����д��ѯ�еķ�Χֵ�ļ�����Ҫ�����ʱ�䡣����Q1���и���ľۼ����Ժ�ͶӰ���ԣ���ˣ�Q1����д��ѯִ��ʱ���Q6�ij�����ɾ��Q1�����з��飬��õ�590���Ԫ��Ľ���������������в�ѯ�Ľ������С��12���Ԫ�����¡��㷨��Ҫ���м�Ľ�������м��㣬���Ȳ�����ѡ��cand��Ȼ����min_cand1��min_cand2��min_cand3��max_cand�������м������ܴ���ˣ������˽ϴ�IJ�ѯ���ء�
�ı�1 GB���ݿ��p��n���о����ݿ�ķ�һ���Ա�����Ӱ�졣ͼ2��ʾΪp��0��0.5��n��2�����н����p�Գ�ʼ��ѯ����д��ѯ������ʱ��ֻ�к�С��Ӱ�졣���ı�pʱ��Q6������Ĵ�С���䣬��Ϊ�������ݿ��С��ͬ��
ͼ1��ͼ2��ʾ�����������д��ѯ�ĸ�����Ҫ�ɳ�ʼ��ѯ�Ľ��(�����Ƿ���)��ۼ����Ժ�ͶӰ�����������ơ�
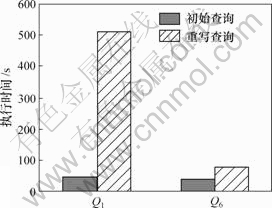
ͼ 1 Q1��Q6��ִ��ʱ��
Fig.1 Running time of Q1 and Q6
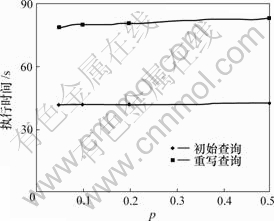
ͼ 2 ��һ�������ݱ���p��ͬʱQ6��ִ��ʱ��
Fig.2 Running time of Q6 at different p
ͼ3��ʾΪ�ı�nֵ�̶�p=0.1��Q6������ʱ�䡣n���κ�2���ɹ�ѡ����д������ʱ���Ӱ���Ǻ�С�ġ�ͼ4��ʾΪ��ͬ�ߴ���Q6�IJ�ѯ��д��ִ��ʱ��(n=2)������100 MB��500 MB��1 GB��1.5 GB��2 GB�����ݿ⡣Ϊ�˱�֤һ���ԵıȽϣ����ݿ��Υ��Լ����Ԫ���������ֳ���������40�����һ����Ԫ�飬��pֵ2.5��3.3��5��10��50�ֱ��Ӧ2 GB��1.5 GB��1 GB��500 MB��100 MB���ݿ⡣���Կ���������ʱ�������ݿ�Ĵ�С�����Ա仯��
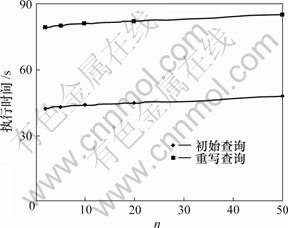
ͼ3 Ԫ����n��ͬʱQ6��ִ��ʱ��
Fig.3 Running time of Q6 at different n
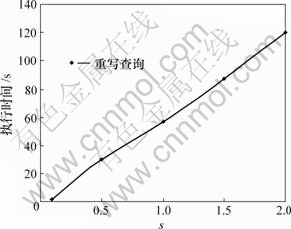
ͼ4 ���ݴ�Сs��ͬʱQ6��ִ��ʱ��
Fig.4 Running time of Q6 at different s
4 �� ��
a. ����˷�һ�������ݿ�ķ�Χ���壬�����˻���һ���Բ�ѯ��Χ��ʵ�ʾۼ���ѯ��д���������ػ�����������ľۼ���ѯ�ķ�Χֵ��
b. �ۼ����Ժ�ͶӰ�������������ݿ��С�Լ���ʼ��ѯ�Ľ������С����д��ѯ�ĸ�����������Ӱ�죬����һ�������ݱ���������ͬ��ֵԪ������Ӱ���С��������д��ѯ�ȳ�ʼ��ѯ��ִ��ʱ��Ҫ�������ǿ��Խ��ܣ���������Ч�ġ�
c. ��һ���Ĺ�����Ҫ���Ƕ����ϵ�����µľۼ���д��ѯ���⣬��һ����չ�ۼ���ѯ�����÷�Χ��
�ο����ף�
[1] Arenas M, Bertossi L, Chomicki J. Consistent query answers in inconsistent databases[C]//Proceedings of the ACM Symposium on Principles of Database Systems. New York: ACM Press, 1999: 68-79.
[2] ��С��, ������, κ����, ��. ���ڷֲ�ʽAgent��ERP��ϵͳ���[J]. ���Ϲ�ҵ��ѧѧ��: ��Ȼ��ѧ��, 2003, 34(4): 424-427.
ZOU Xiao-bing, CAI Zi-xing, WEI Shi-yong, et al. Design of an ERP sub-system based on distributed agent[J]. Journal of Central South University of Technology: Natural Science, 2003, 34(4): 424-427.
[3] Dasu T, Johnson T. Exploratory data mining and data cleaning[M]. New York: John Wiley, 2003.
[4] Arenas M, Bertossi L, Chomicki J. Scalar aggregation in FD-inconsistent databases[C]//Proceedings of the International Conference on Database Theory. Berlin: Springer-Verlag, 2001: 39-53.
[7] Fuxman A, Fazli E, Miller R J. ConQuer: efficient management of inconsistent databases[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data. New York: ACM Press, 2005: 155-166.
[8] Fuxman A, Miller R J. Towards inconsistency management in data integration systems[C]//Proceedings of the IJCAI Workshop on Information Integration on the Web. New York: ACM Press, 2003: 143-148.
[9] Fuxman A, Fuxman D, Miller R J. ConQuer: A system for efficient query answering over inconsistent databases[C]// Proceeding of the International Conference on Very Large Databases. New York: ACM Press, 2005: 1354-1357.
[10] Fuxman A, Miller R J. First-order query rewriting for inconsistent databases[C]//Proceedings of the International Conference on Database Theory. Berlin: Springer-Verlag, 2005: 337-351.
[11] Chomicki J, Marcinkowski J, Staworko S. Computing consistent query answers using conflict hypergraphs[C]//Proceeding of the International Conference on Information and Knowledge Management. New York: ACM Press, 2004: 417-426.
[12] Chomicki J, Marcinkowski J, Staworko S. Hippo: a system for computing consistent query answers to a class of SQL queries[C]//Proceedings of the International Conference on Extending Database Technology. Berlin: Springer-Verlag, 2004: 841-844.
[13] Eiter T, Fink M, Greco G, et al. Efficient evaluation of logic programs for querying data integration systems[C]//Proceedings of the International Conference on Logic Programming. Berlin: Springer-Verlag, 2003: 163-177.
[14] Lembo D, Lenzerini M, Rosati R. Source inconsistency and incompleteness in data integration[C]//Proceedings of the International Workshop on Knowledge Representation Meet Databases. Berlin: Springer-Verlag, 2002: 79-86.
[15] Transaction Processing Performance Council. TPC-H standard specification[EB/OL]. [2006-05-30]. http://www.tpc.org.
�ո����ڣ�2007-10-25�������ڣ�2008-01-28
������Ŀ������ʡ��Ȼ��ѧ����������Ŀ(07JJ6113��07JJ3119)������ʡ���������л���������Ŀ(07C832��07C385)
ͨ�����ߣ�л ��(1971-)���У����ϰ����ˣ���ʿ�������ݹ����ͷ�һ�������ݿ��о����绰��13657381116��E-mail: lgxzy@163.com
[1] Arenas M, Bertossi L, Chomicki J. Consistent query answers in inconsistent databases[C]//Proceedings of the ACM Symposium on Principles of Database Systems. New York: ACM Press, 1999: 68-79." target="blank">[1] Arenas M, Bertossi L, Chomicki J. Consistent query answers in inconsistent databases[C]//Proceedings of the ACM Symposium on Principles of Database Systems. New York: ACM Press, 1999: 68-79.
[3] Dasu T, Johnson T. Exploratory data mining and data cleaning[M]. New York: John Wiley, 2003." target="blank">[3] Dasu T, Johnson T. Exploratory data mining and data cleaning[M]. New York: John Wiley, 2003.
[4] Arenas M, Bertossi L, Chomicki J. Scalar aggregation in FD-inconsistent databases[C]//Proceedings of the International Conference on Database Theory. Berlin: Springer-Verlag, 2001: 39-53." target="blank">[4] Arenas M, Bertossi L, Chomicki J. Scalar aggregation in FD-inconsistent databases[C]//Proceedings of the International Conference on Database Theory. Berlin: Springer-Verlag, 2001: 39-53.
[7] Fuxman A, Fazli E, Miller R J. ConQuer: efficient management of inconsistent databases[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data. New York: ACM Press, 2005: 155-166." target="blank">[7] Fuxman A, Fazli E, Miller R J. ConQuer: efficient management of inconsistent databases[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data. New York: ACM Press, 2005: 155-166.
[8] Fuxman A, Miller R J. Towards inconsistency management in data integration systems[C]//Proceedings of the IJCAI Workshop on Information Integration on the Web. New York: ACM Press, 2003: 143-148." target="blank">[8] Fuxman A, Miller R J. Towards inconsistency management in data integration systems[C]//Proceedings of the IJCAI Workshop on Information Integration on the Web. New York: ACM Press, 2003: 143-148.
[9] Fuxman A, Fuxman D, Miller R J. ConQuer: A system for efficient query answering over inconsistent databases[C]// Proceeding of the International Conference on Very Large Databases. New York: ACM Press, 2005: 1354-1357." target="blank">[9] Fuxman A, Fuxman D, Miller R J. ConQuer: A system for efficient query answering over inconsistent databases[C]// Proceeding of the International Conference on Very Large Databases. New York: ACM Press, 2005: 1354-1357.
[10] Fuxman A, Miller R J. First-order query rewriting for inconsistent databases[C]//Proceedings of the International Conference on Database Theory. Berlin: Springer-Verlag, 2005: 337-351." target="blank">[10] Fuxman A, Miller R J. First-order query rewriting for inconsistent databases[C]//Proceedings of the International Conference on Database Theory. Berlin: Springer-Verlag, 2005: 337-351.
