
������Ͻ����㷨�Ļ���ʱ�������ع���ռ����ѡȡ
���ģ�����ר��������
(���ݲƾ���ѧ ����ʡ����ϵͳ�����ص�ʵ���ң����� ������550004)
ժ Ҫ��
�Ͻ����㷨�Ż���ռ��ع������Ļ���ʱ������Ԥ�ⷽ�����÷������Ƚ���ʱ���ӳ٦Ӻ�Ƕ��ά��m����ռ��е���Ϣ���Ż�ģ�ͣ�Ȼ�����һ�ָĽ�����Ͻ����㷨ͬʱ���2���ع������Ӻ�m�������С�������������л���ʱ������Ԥ�⡣ʵ�����������÷����ܹ�ȷ�����ʵ���ռ��ع������Ӻ�m�����Ԥ�⾫�ȡ�
�ؼ��ʣ�
����ʱ����������Ͻ����㷨��Ԥ������Ϣ����
��ͼ����ţ�TP273 ���ױ�־�룺A ���±�ţ�1672-7207(2013)08-3246-08
Parameters determination based on combinative evolutionary algorithm for reconstructing phase-space in chaos time series
LONG Wen, ZHANG Wenzhuan, JIAO Jianjun
(Guizhou Province Key Laboratory of Economics System Simulation,
Guizhou University of Finance and Economics, Guiyang 550004, China)
Abstract: A method of combinative evolutionary algorithm optimized parameters of phase space reconstruction is proposed for predicting chaotic time series. First, it establishes an information entropy optimum mathematical model in phase space for embedding dimension and delay time. It then solves these two parameters with an improved combinative evolutionary algorithm (CEA) simultaneously. The chaotic time series are predicted using least squares support vector machine. The results show that it not only determines two parameters at the same time, but also can improve the performance of chaotic time series prediction.
Key words: chaotic time series; combinative evolutionary algorithm; prediction; information entropy
����ϵͳ����ʵ�������ձ���ڣ�����ʱ�����еķ�����Ԥ�ⶼ�����ع���ռ��н��еģ������ռ��ع��ڻ���ʱ�����з�����Ԥ����������Ҫ���塣��ռ��ع���������Takens[1]����ģ������ӳ�ʱ��Ӻ�Ƕ��ά��m����ȷѡȡ����ռ��ع��ɹ��Ĺؼ����ڡ�Ŀǰ��2��������ѡȡ��Ҫ��2�����һ������Ϊ��������أ����ӳ�ʱ��Ӻ�Ƕ��ά��m��ѡȡ���Զ������У�������[2]�Ȳ��û���Ϣ����ѡȡ�ӳ�ʱ��ӣ�Ȼ�����α�������ȷ��Ƕ��ά��m������[3]���Ȳ�������ط���ѡȡ�ӣ�Ȼ������G-P����ȷ�����ʵ�m����һ�������Ϊ�ӳ�ʱ��Ӻ�Ƕ��ά��m����صģ���ʱ�䴰�ڷ���[4]��C-C����[5]�ȣ�������ȷ���ӳ�ʱ��Ӻ�Ƕ��ά��m��������ij˻���ϵ��Ȼ�����������ع�����ռ䲢��һ����ѣ����ܺܺõر���ԭ����ϵͳ��������ԡ�����[6]��֤���ڲ�ͬ�ӳ�ʱ��Ӻ�Ƕ��ά��mѡ���£�һЩ���ͻ���ϵͳ��Ԥ��ʱ���в�ͬ�������һ��˵����ռ��ع������Ӻ�m��������صġ���Ϣ����ϵͳ�����Ե�һ�ֶ������ڸ���ϵͳʱ�����������ǻ���ʱ�����еķ����о�����Ҫ���á�������[7-8]�ֱ�Ӧ�������ؽ���˻���ʱ�����е�ʱ���ж������Ƕ��ά��m����������2������ֻ�ǹ����������ع������Ӻ�m����Ϣ�صĹ�ϵ��û�н�2���ع������Ӻ�m����Ϣ��ģ��ͳһ��ʾ����������[9]���Ƚ����ӳ�ʱ��Ӻ�Ƕ��ά��m����Ϣ���Ż�ģ�ͣ����Ӻ�m��Ϊһ�����壬Ȼ�����û����Ŵ��㷨���Ż�ģ�ͽ�����⣬���Elman������л���ʱ������Ԥ�⡣Ȼ���������Ŵ��㷨���������ٶ�����������ֲ����ŵ�ȱ�㣬�����������ʱ������ʵʱԤ���Ŀ�ġ����⣬��������ڹ���ϡ�������ֲ���Сֵ������ṹ��ѡ����������ھ����ȱ�ݡ������㷨(evolutionary algorithms��EA)�ǽ��귢չ������һ��ģ������������ɶ��ݻ�����ȫ���Ż���������ͨ�����桢�����ѡ�����Ӳ����Ż�Ⱥ�壬ֱ��������ȫ�����Ž�[10]���ڹ�ȥ�ļ�ʮ���У��о���Ա��EA�еĽ��桢�������ӽ����˴������о��������������������Ľ���ͽ��ۣ���Щ���еľ���ͽ��۶ԸĽ������㷨�����ܷdz��а�����ͬʱ���ǻ��۲쵽���������еĽ����㷨������Ż�����ʱ�����õ�һ�Ľ������ӽ�ϵ�һ�ı������ӣ�����һ�����㷨������������ȱ�ݾͲ��ɱ��⡣����ͳ�����۵���С����֧��������(LSSVM)�ǽ���������ѧϰ�������Ҫ�ɹ�֮һ����ѵ��������ѭ�ṹ������С��ԭ�ṹ������ѵ�������и������������Զ�ȷ�������������������֧����������ѧϰ����ת��Ϊ������Է��������⣬�����ھֲ���Сֵ���⣬��ˣ�LSSVM�ɳɹ��˷��������ȱ�ݣ��ڻ���ʱ�����з�����Ԥ�����й㷺��Ӧ��[11-12]�������������Ƚ����ӳ�ʱ��Ӻ�Ƕ��ά��m����ռ��е���Ϣ���Ż�ģ�ͣ�ʹ��ռ��е��ع���������ȶ�����ͬʱ�ֱ����䶯��ѧ��ϵ��Ȼ�����һ�ָĽ�����Ͻ����㷨������Ϣ���Ż�ģ�ͣ������������ع����������е������Թ�ϵ���������С����֧���������Լ�������ʱ�����н���Ԥ�⣬ʵ���������˸÷�������Ч�ԡ�
1 �Ӻ�m����Ϣ���Ż�ģ��
1.1 ��Ϣ��ģ��
����2���������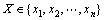 ��
��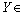
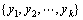 ����������ʷֱ�Ϊ
����������ʷֱ�Ϊ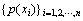 ��
��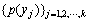 ����Ϣ�ؿɶ���Ϊ[9]��
����Ϣ�ؿɶ���Ϊ[9]��
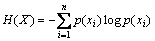 (1)
(1)
ʽ(1)�������������X�IJ����ԣ���Ϊ����X�IJ�ȷ��������Ҫ��ƽ����Ϣ�������Ƶؿ��Զ���������
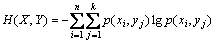 (2)
(2)
���У�p(xi��yj)Ϊ���ϸ��ʡ�
������������p(xi|yj)����������
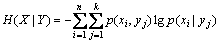 (3)
(3)
ʽ(3)��������֪Y��X���������IJ����ԡ�һ����H(X)��H(X|Y)������֪Y������������X�IJ����ԣ��ر��H(X|Y)=0��ʾY��֪��X�IJ�������ȫ��������Y�ܹ���ȫȷ��X����ʽ(1)��(2)��(3)�����Ƴ�
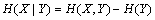 (4)
(4)
1.2 ��ռ��ع������Ӻ�m��Ϣ���Ż�ģ��
�������ϵͳ������ʱ������Ϊx(1)��x(2)������x(n)����������Ƕ�붨�����ܴ��ں��ʵ�ά��m��ʱ���ӳ٦ӵ���ռ�X(n)=(x(n)��x(n+��)������x(n+(m-1)��))��Rm��(n=1��2����)��ʹ���ع���ռ��еġ����ߡ���ԭ����ϵͳ����ͬ���������ǵȼ۵�[9]��������һ���⻬ӳ��F:Rm��Rm�ܸ�ԭ��ԭ����ϵͳ�ġ��˶����̡�����ռ��Ĺ켣Ϊ
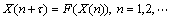 (5)
(5)
����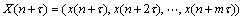 ��
��
��ʽ(5)��ʾΪ������ʽ��
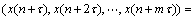
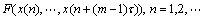 (6)
(6)
ʽ(6)�ɽ�һ������Ϊʱ��������ʽ
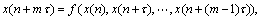
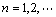 (7)
(7)
ʽ(7)�������ں��ʵ�ʱ���ӳ٦Ӻ�Ƕ��ά��mѡ���£�f�ܷ�ӳԭϵͳ�ġ��˶���ʽ�������ڻ���ϵͳ�ĸ����ԣ�Ҫ������ȷf�Ľ�����ʽ�����ѵġ�����������f�ЦӺ�m�����е�һ���ع�ϵ��Ȼ��������С����֧�����������ƽ�f��
���ڻ���ϵͳ���и߶ȷ����Ե��ص㣬������۲��ʱ�����о���ȷ��������ԣ���δ��ijʱ�̵�ֵ���в�ȷ���ԡ�ʽ(7)˵������֪��x(n)��x(n+��)������x(n+(m-1)��)�����ǡ��ȷ��x(n+m��)������֪���ض���m��ʱ�̵�ֵx(n)��x(n+��)������x(n+(m-1)��)��δ��ijʱ��x(n+m��)�IJ�ȷ������ȫ����������֪������m��ʱ�̵�ֵ������m��ʱ�̵�ֵ��������ȫ����x(n+m��)�IJ�ȷ���ԡ���ˣ�Ϊ������δ��ijʱ�̵IJ�ȷ���ԣ�ʱ���ӳ٦Ӻ�Ƕ��ά��m�ǽ�����ϵ�ġ�ʱ�����еIJ�ȷ���Կ�������Ϣ�����̻������Կ��Խ���ʱ���ӳ٦Ӻ�Ƕ��ά��m���ع�ϵ����X1=x(n)��X2=x(n+��)������Xm=x(n+(m-1)��)�� Xm+1= x(n+m��)����H(Xm+1)��ʾx(n+m��)�IJ����ԣ����������صĶ��壬��H(Xm+1|Xm)��ʾ��֪Xm��Xm+1�ԡ������������ԣ���Ϊֻ֪x(n+(m-1)��)����Ϣ������ȷ��x(n+m��)����Ȼ��H(Xm+1|Xm)��0���Դ����ƣ�����ʽ(7)��
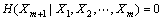 (8)
(8)
��ˣ��õ���Ӻ�m���Ż�ģ��[9]��
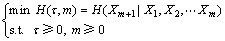 (9)
(9)
����ʽ(4)��������ת��Ϊ�����أ���
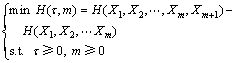 (10)
(10)
��ʽ(9)��(10)��ʾ���Ż������У�����Ŀ�꺯���е��غ����Ǻ�ʱ���ӳ٦Ӻ�Ƕ��ά��m��һ���ܸ��ӵı���ʽ����ͳ�Ļ����ݶ���Ϣ���Ż�����������⡣������Ͻ����㷨���������ٶȿ졢ȫ��Ѱ������ǿ���ص㣬�������һ�ָĽ�����Ͻ����㷨����⡣
2 �Ľ�����Ͻ����㷨�Ż��Ӻ�m
2.1 �Ľ�����Ͻ����㷨
2.1.1 ��Ⱥ��ʼ��
�ɽ����㷨�Ļ�����֪�������������Ⱥ�������Խ�ǿ���������㷨�������ٶ���Ҫ�����ڽ���������������ʼ����Ⱥ�������������������ȫ�����Ž⣬���ܻᵼ�����ӵ����������ﵽ�������Ž⣬���Ʊػ��������㷨�ļ��������ѵ㼯������һ����Ч�ġ����Լ���ʵ�������ʵ�鷽��������ͬȡ���������������£��ѵ�����Ҫ����������ѡȡ�ĵ����и�����[13]����ˣ����IJ��üѵ㼯����������ʼ��Ⱥ���Ӷ���֤����Ⱥ����Ķ����ԡ�ͼ1��ʾΪ���üѵ㼯���������Ĺ�ģΪ80�ij�ʼ��Ⱥ����ֲ���
��ͼ1���Կ����������������ȣ��ѵ㼯�������ɵij�ʼ��Ⱥ����ֲ����ȣ����нϺõĶ����ԡ�
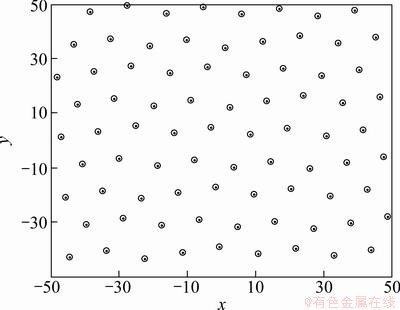
ͼ1 �ѵ㼯���������ij�ʼȺ��ֲ�
Fig. 1 Initial individuals with good point set method
2.1.2 ��Ͻ���ͱ������
���������ǽ����㷨�����������߿ռ����Ҫ��������ͨ����ϸ����������Ϣ�γ��µ��Ӵ����壬�Ǿ��������㷨�Ƿ������Ĺؼ����ڽ����㷨�У����õĽ��������е��㽻�����ӡ���㽻�����ӡ����ν������Ӻ������������ӵȡ���������Ҳ�ǽ����㷨����Ҫ�����������Ա����㷨����ֲ����ţ�ͬʱҲ�ܱ�����Ⱥ�Ķ����ԡ��ڽ����㷨�У����õı��������зǾ��ȱ��졢�����Ա���ͱ߽����ȡ�
�ڹ�ȥ��ʮ�����У������㷨�о���Ա���佻�����Ӻͱ������ӽ����˴������о������ҵõ���һЩ���ԺͶ����Ľ��ۣ������Ѿ��õ���Щ���������ʺ���ȫ����������Щ����������ƽ���㷨��ȫ�ֺ;ֲ�������������Щ��������ܼӿ��㷨�������ٶȵȡ���Щ���е�֪ʶ�;���ԸĽ������㷨�����ܷdz��а�����Ȼ��������ƽ����㷨ʱ������ȴû�б�ϵͳ�����á����⣬����ⲻͬ���Ż�����ʱ������ѡȡ���ֽ������ӽ�����ֱ������ӣ�û��ʲôϵͳ�Ĺ��ɿ�ѭ��ֻ�в��ϵؽ���ʵ����ԣ���һ������Ҫ���ӵļ�������ͬʱ���۲쵽��Ŀǰ�ֽ����㷨�����õ�һ�Ľ������ӽ�ϵ�һ�ı������ӣ�����һ�����㷨�����������Է���ľ������ɱ��⡣һ����˵��������ͬ�Ľ������ӽ�ϲ�ͬ�ı������Ӿ��в�ͬ���������������¸����ܱ���Ⱥ��Ķ����ԣ��������ǿ������������ⲻͬ���͵��Ż����⣬�Ӷ���ǿ���㷨��ͨ���ԡ�
���������������������һ�ֻ���֪ʶ�����Ͻ����㷨�������Ƚ�����������֪ʶ��ͱ�������֪ʶ�⣬�ڽ��������д�2��֪ʶ����������֪ʶ�������ɸ��µĸ��壬�Ӷ���֤��Ⱥ����Ķ����ԣ���˼·����ͼ2���Խ��͡�
���IJ���2�齻�����ӣ������ν�������[14]����������������3��������ӣ��ֱ��ǷǾ��ȱ��졢�����Ա���ͱ߽����[15]��Ҳ����ͼ2�е�s=2��r=3��
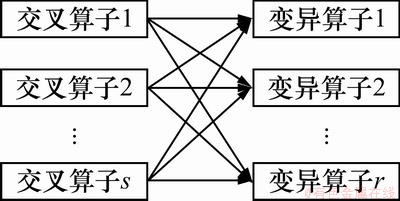
ͼ2 ��Ͻ������Ӻͱ�������ʾ��ͼ
Fig. 2 Illustration of combining crossover and mutation
����2�齻�����Ӻ�3�������������ƽ����㷨ʱƵ��ʹ�ã��������߱�������Ҳ�ѱ��㷺�о�������ϲ��ԵĻ����ص��ǣ����ν������Ӻ��������������ڹ��ڽ����㷨��������ʹ����Ϊ�ձ飬��Ϊ���ν����������㷨���ھ��н�ǿ��ȫ�����������������㷨���ھ��н�ǿ�ľֲ����������������������Ӳ����ĺ������һ����2����������֮��������ϣ�����ӽ�ȫ�����Ž�ĸ�����н�����������ҵ�ȫ�����ź��а������߽���졢�Ǿ��ȱ���Ͷ����Ա����ڹ��ڽ����㷨��������ʹ��Ҳ���ձ顣�߽�������Ӿ��к�ǿ�ľֲ������������Ǿ��ȱ����ڽ������ھ��н�ǿ��ȫ�������������ڽ������ھ��н�ǿ�ľֲ����������������Ա������Ӿ��н�ǿ��ȫ������������
2.1.3 �㷨����
����֪ʶ�����Ͻ����㷨����ͼ��ͼ3��ʾ��
2.1.4 ��ֵʵ��
Ϊ��֤�Ľ���Ͻ����㷨����Ч�ԣ�ѡ��4�������Ժ�����������f1��f2��f3��f4���з���ʵ�顣4�������ľ������ʽ���£�

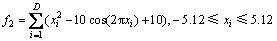
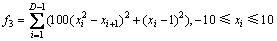
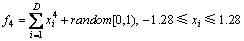
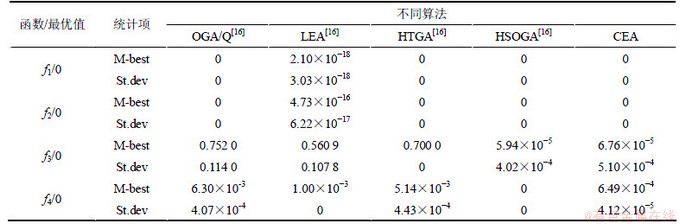
����f1��f2��f4��ά������ΪD=30��f3��ά��ΪD=100��4�����Ժ�����ȫ�ּ�Сֵ��Ϊ0������f2��f3Ϊ��庯�������ж���ֲ���С�㣬������������������ֲ����ţ���Щ�����ܼ����㷨�Ķ�����������������к����������㷨�IJ�������Ϊ����Ⱥ��ģN=200���������pc=0.8���������pm=0.1������������Ϊ3 000�������㷨�IJ������ü��������ס���ÿ������������ͬ�������¶���������30��ʵ�飬��¼��ƽ������ֵ(M-best)�ͱ���(St.dev)���������㷨��ΪCEA����������4�����ܽϺõ��㷨����OGA/Q�㷨[16]��LEA�㷨[16]��HTGA�㷨[16]��HSOGA�㷨[16]��ʵ���������˱Ƚϡ���1������5���㷨��4��������Ѱ�Ž����
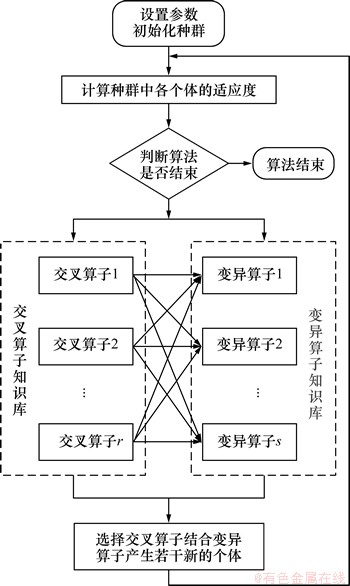
ͼ3 ��Ͻ����㷨����ͼ
Fig. 3 Flow chart of combination evolutionary algorithm
�ӱ�1���Կ��������ں���f1��f2��CEA�㷨30��ʵ����һ�µ��ҵ�ȫ�����Ž⣬���ں���f3��f4��ʵ����Ҳ�dz��ӽ����Ž⡣��OGA/Q�㷨��ȣ�CEA�㷨�ں���f3�ϵõ��Ľ��Ҫ����OGA/Q�㷨���ں���f1��f2��f4�ϵõ��Ľ�����ơ���LEA�㷨��ȣ�CEA�㷨�ں���f1��f2��f3�ϵõ��Ľ��Ҫ����LEA�㷨���ں���f4�ϵõ��Ľ�����ơ���HTGA�㷨��ȣ�CEA�㷨�ں���f3�ϵõ��Ľ��Ҫ����HTGA�㷨���ں���f1��f2��f4�ϵĽ�������൱����HSOGA�㷨��ȣ����˺���f4�ϵõ��Ľ���Բ��⣬������3�������ϵõ������ƵĽ�����������ϱȽϷ������Եó���CEA�㷨���н�ǿ��ȫ��Ѱ�����ܣ����ڻ������������㷨��
��1 5���㷨��4�����Ժ�����ʵ�����Ƚ�
Table 1 Experimental results of five algorithms on four benchmark functions
2.2 �Ľ�����Ͻ����㷨�Ż��Ӻ�m
ʽ(10)��ʾ����Ϣ��ģ�����ع�����ʱ���ӳ٦Ӻ�Ƕ��ά��m�Ż���˼����ͨ�������㷨����һ���ع�����(�ӣ�m)��ʹĿ�꺯���ﵽ��С�����IJ���ǰ���������ĸĽ���Ͻ����㷨(CEA)�������Ż�ʱ���ӳ٦Ӻ�Ƕ��ά��m������������һ���ع���������(�ӣ�m)��ΪCEA�㷨�еĸ��壬���������Ӧ�Ⱥ���ȡʽ(10)������CEA�Ż���Ϣ��ģ���ع������Ӻ�m�ľ��岽�����£�
Step 1 ���ò��������üѵ㼯������ʼ����Ⱥ,ÿ�������Ӧ����Ϣ��ģ��(10)�е�һ���ع����� (�ӣ�m)��
Step 2 ����������Ӧ�ȣ���ֱ�Ӽ����ڸ��������Ӻ�m��������������|H(X1��X2������Xm+1)-H(X1��X2������Xm)|��Ϊ����x����Ӧ�ȡ����þ����ʶ��[8]������������H(X1��X2������Xm)��
Step 3 �ж��Ƿ����������ֹ�����������㣬����������������ʱ���ӳٺ�Ƕ��ά��(�ӣ�m)���������ִ��Step 4��
Step 4 ��ϲ�ͬ�Ľ������Ӻͱ������Ӳ����µ��Ӵ����壬Ȼ��Step 2��
3 ʵ�����������
Ϊ����֤���ķ�������Ч�ԣ�ʹ����С����֧��������(LSSVM)�Ի���ʱ�����н���Ԥ��ʵ�顣LSSVMԤ��ģ�͵ĺ˺������ͺͲ�������������[12]��ͬ��Ϊ������Ԥ��Ч�������������б���
�������(MSE)��
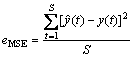 (11)
(11)
���������(RMSE)��
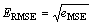 (12)
(12)
�������(e(t))��
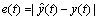 (13)
(13)
������(er(t))��
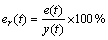 (14)
(14)
���У�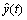 ��y(t)��S�ֱ��ʾԤ��ֵ����ʵֵ��������С��
��y(t)��S�ֱ��ʾԤ��ֵ����ʵֵ��������С��
3.1 Ԥ��Lorenz������ʱ������
Lorenz������ϵͳ�ķ���Ϊ
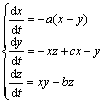 (15)
(15)
��c��28ʱ��Lorenzϵͳ(15)���ڻ���״̬��ѡȡϵͳ����a=10��b=8/3��c=28����ʼֵΪ(0.003 1��0.192 8��0.420 8)������ʱ��Ϊ0.01 s���ɱ���x�����ݣ��õ�Lorenzϵͳ����ʱ��������ͼ4��ʾ��
����ǰ1 500��������Ϊѵ��������������ѵ������LSSVMԤ��ģ�ͣ��ú�1 000��������Ϊ��������������������LSSVMԤ��ģ�͵���Ч�ԡ����ķ����еĸĽ�CEA�㷨��������Ϊ����Ⱥ��ģN=20���������pc=0.8���������pm=0.1������������Ϊ100���õ����ŵ��ع�����Ϊ��Ƕ��ά��m=9��ʱ���ӳ٦�=4����2�����˱��ķ���������[9]�еķ�����Lorenzʱ�����е�Ԥ�����Ƚϡ�
�ӱ�2���Կ��������ķ�����Lorenz������ϵͳ��Ԥ���������������������������ع���ռ��ϵ�Ԥ������ͬʱҲ˵���˸÷����ܵõ����ʵ��ع������������Ԥ�⾫�ȡ�ͼ5��ʾΪ���ķ�����Ԥ������ͼ5��֪�����ķ������н�С��Ԥ����
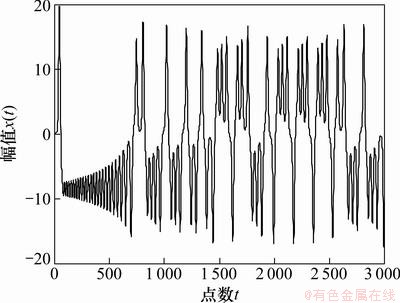
ͼ4 c=28ʱ��Lorenz����ʱ������
Fig. 4 Lorenz chaos time series with c=28
��2 Lorenz����ʱ�����е�Ԥ�����Ƚ�
Table 2 Forecasting results of Lorenz chaos time series
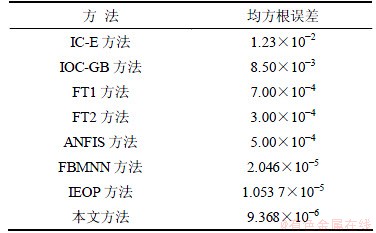
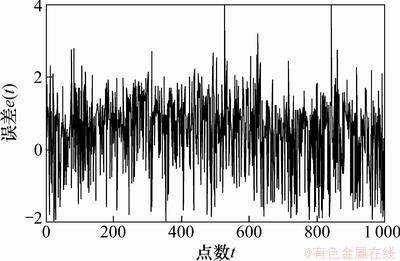
ͼ5 Lorenz����ʱ�����е�Ԥ�����
Fig.5 Forecasting error of Lorenz chaos time series
3.2 Ԥ��Mackey-Glassʱ������
Mackey-Glass����ʱ������Ԥ��ͨ������Ϊ�Ǽ���ͱȽϸ��ַ�����ģ�ͺ��㷨��һ�����������⡣Mackey-GlassϵͳΪ��
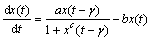 (16)
(16)
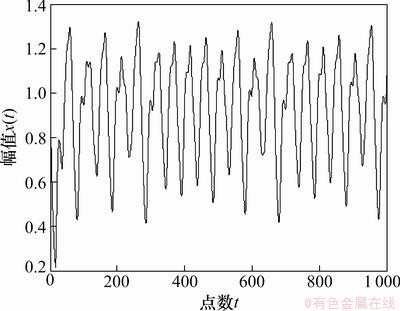
���У���Ϊʱ�Ͳ��������á�17ʱ��ϵͳ(16)���ֳ������ԡ�ѡȡ����a=0.2��b=0.1��c=10����=17����ʼֵx(0)=1.2������Ϊh=0.1�������Ľ�Runge-Kutta������1 000�����ݣ�ͼ6��ʾΪ��=17ʱ��Mackey-Glass����ʱ�����С�
��ǰ500��������Ϊѵ��������������ѵ������LSSVMԤ��ģ�ͣ���500��������Ϊ��������������������LSSVMģ�͵����ܡ����õ�3���еĸĽ���Ͻ����㷨(CEA)�Ż���ռ��ع��������ó�m=10�ͦ�=6����Mackey-Glassϵͳ�ع���ռ�Ƕ��ά��m=10���ӳ�ʱ���=6��
��3�����˱��ķ���������[9]�еķ����õ���Ԥ�����Ƚϡ��ӱ�3��֪����Mackey-Glass���ݽ���Ԥ�⣬���ķ����õ��Ľ��Ҫ�����������������õ��Ľ��Ҫ�š�ͼ7�����˱��ķ�����Ԥ������ͼ7���Կ��������ķ������нϸߵ�Ԥ�⾫�ȡ�
ͼ6 ��=17ʱ��Mackey-Glass����ʱ������
Fig. 6 Mackey-Glass chaos time series with ��=17
��3 Mackey-Glassʱ�����е�Ԥ�����Ƚ�
Table 3 Forecasting results of Mackey-Glass time series
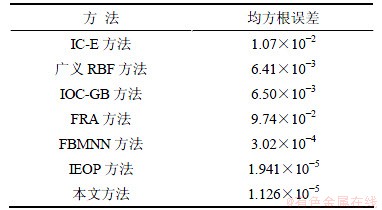

ͼ7 Mackey-Glass����ʱ�����е�Ԥ�����
Fig. 7 Forecasting error of Mackey-Class chaos time series
3.3 Ԥ����ô�ɽèʱ������
���ô�ɽèʱ��������Mackezie������ÿ�겶��ļ��ô�ɽè����������һ���̶��Ϸ�ӳ��Mackezie������ɽè��Ⱥ�Ĵ�С����ˣ���������Ԥ����������һ����ϵͳ��Ⱥ��̬���о�������ʱ���������ݹ���114������Ӧ�����Ϊ1821��1934�꣬�䱻�㷺�������Է�����ģ�͵�Ԥ������[13]����114������ȡ��Ϊ10�Ķ����������ɵ�ʱ��������ͼ8��ʾ��
��ǰ100��������Ϊѵ��������������ѵ������LSSVMԤ��ģ�ͣ���12��������Ϊ��������������������LSSVMģ�͵����ܡ����õ�3���еĸĽ���Ͻ����㷨(CEA)�Ż���ռ��ع��������ó�m=8�ͦ�=3�������ô�ɽèʱ�������ع���ռ�Ƕ��ά��m=8���ӳ�ʱ���=3��
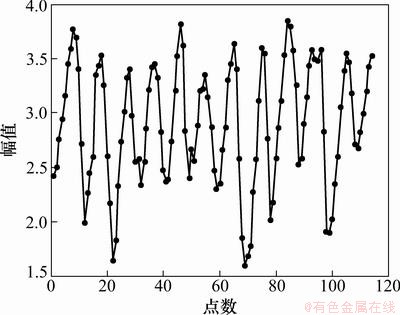
ͼ8 ���ô�ɽè����(log10�߶�)ʱ������
Fig. 8 Canada lynx data time series
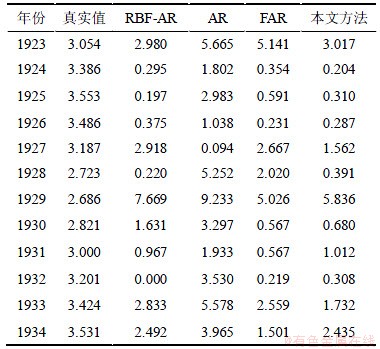
��4�����˱��ķ�����RBFAR����[13]��AR����[13]��FAR����[13]�Լ��ô�ɽèʱ�����е�Ԥ�����Ƚϣ���4�еĽ�������������ʽ�������ӱ�4��֪��������������������ȣ����ķ������нϸߵ�Ԥ�⾫�ȡ�
��4 ���ô�ɽèʱ�����е�Ԥ�����Ƚ�
Table 4 Forecasting results of Canada lynx time series %
4 ����
(1) ����ʱ���ӳ٦Ӻ�Ƕ��ά��m����������ԣ�������Ϣ��֪ʶ�����˦Ӻ�m����Ϣ���Ż�ģ�͡�
(2) ���һ����Ͻ����㷨�������Ϣ���Ż�ģ�ͣ�ͨ�������������Ӻͱ�������֪ʶ�⣬���֪ʶ�Բ����µĸ��壬��ǿ�㷨��ȫ������������
(3) �÷�������֪������ʱ�����еĽ���ģ�ͣ�ֻ��Ҫ����ʷ���ݣ�����LSSVM����ѵ����������ʱ�����е�Ԥ��ģ�ͣ�����ʵ�ֺܺõ�Ԥ�⡣
�ο����ף�
[1] Takens F. Dynamical systems and turbulence[M]. Berlin: Springer-Verlag Press, 1981: 366-381.
[2] Fraser A M. Information and entropy in strange attractors[J]. IEEE Transactions on Information Theory, 1989, 35(2): 245-262.
[3] Albano A M, Muench J, Schwartz C, et al. Singular-value decomposition and the grassberger-procaccia algorithm[J]. Physical Review A, 1988, 38(6): 3017-3026.
[4] Kugiumtzis D. State space reconstruction parameters in the analysis of chaotic time series-the role of the time window length[J]. Physica D, 1996, 95(1): 13-28.
[5] Kim H S, Eykholt R, Salas J D. Nonlinear dynamics delay times and embedding windows[J]. Physica D, 1999, 127(1): 48-60.
[6] Ataei M, Lohmann B, Khaki-sedigh A, et al. Model based method for estimating an attractor dimension from uni/multi- variate chaotic time series with application to Bremen climatic dynamics[J]. Chaos, Solitons and Fractals, 2004, 19(5): 1131-1139.
[7] �����. ����ʱ�����е�ʱ���ж�[J]. ����ѧ��, 1997, 46(3): 442-447.
TIAN Yuchu. Delay indentification in chaotic time series[J]. Acta Physica Sinica, 1997, 46(3): 442-447.
[8] Ф����, �ֹ���, ���. ����ʱ����ռ��ع�����ȷ������Ϣ�۷���[J]. ����ѧ��, 2005, 54(2): 550-556.
XIAO Fanghong, YAN Guirong, HAN Yuhang. Information theory approach to determine embedding parameters for phase space reconstruction of chaotic time series[J]. Acta Physica Sinica, 2005, 54(2): 550-556.
[9] ��ǧ��, ����, �Ŵ���. ������Ϣ���Ż���ռ��ع������Ļ���ʱ������Ԥ��[J]. ����ѧ��, 2010, 59(11): 7623-7629.
MA Qianli, PENG Hong, ZHANG Chuntao. Chaotic time series prediction based on information entropy optimized parameters of phase space reconstruction[J]. Acta Physica Sinica, 2010, 59(11): 7623-7629.
[10] Wang Y P, Dang C Y. An evolutionary algorithm for global optimization based on level-set evolution and Latin squares[J]. IEEE Transactions on Evolutionary Computation, 2007, 11(5): 579-595.
[11] Suykens J A K, Vandewalle J. Least squares support vector machine classifiers[J]. Neural Processing Letters, 1999, 9(3): 293-300.
[12] ����, ������, ����ǿ, ��. ���ڸĽ���Ⱥ�㷨�Ż�������LSSVM���ڸ���Ԥ��[J]. ���ϴ�ѧѧ��, 2011, 42(11): 3408-3414.
LONG Wen, LIANG Ximing, LONG Zuqiang, et al. Parameter selection for LSSVM based on modified ant colony optimization in short-term load forecasting[J]. Journal of Central South University, 2011, 42(11): 3408-3414.
[13] ����. ��������Ż�����Ļ�Ͻ����㷨����Ӧ��[D]. ��ɳ: ���ϴ�ѧ��Ϣ��ѧ�빤��ѧԺ, 2011: 56-58.
LONG Wen. Hybrid evolutionary algorithms for solving two classes optimization problems and applications[D]. Changsha: Central South University. School of Information Science and Engineering, 2011: 56-58.
[14] Wang Y, Cai Z X, Zhou Y R, et al. Constrained optimization based on hybrid evolutionary algorithm and adaptive constraint- handling technique[J]. Structural and Multidisciplinary Optimization, 2009, 37(4): 395-413.
[15] ������, ����, �غ���, ��. ������Ⱥ��������Ե�Լ���Ż������㷨[J]. ���������, 2010, 25(8): 1129-1132.
LIANG Ximing, LONG Wen, QIN Haoyu, et al. Constrained optimization evolutionary algorithm based on individual feasibility of population[J]. Control and Decision, 2010, 25(8): 1129-1132.
[16] ������, ������, ����, ��. ���ȫ���Ż�����Ļ������Ӧ�����Ŵ��㷨[J]. ����ѧ��, 2010, 21(6): 1296-1307.
ZHANG Zhongyang, CAI Zixing, WANG Yong, et al. Hybrid self-adaptive oxthogonal genetic algorithm for solving global optimization problems[J]. Journal of Software, 2010, 21(6): 1296-1307.
(�༭ �°���)
�ո����ڣ�2012-10-04�������ڣ�2012-12-20
������Ŀ������ʡ��ѧ��������������Ŀ(ǭ�ƺ�J��[2013]2082��)������ʡ������125�ش�Ƽ�ר����Ŀ(ǭ�̺��ش�ר����[2012]011��)
ͨ�����ߣ�����(1977-)���У�����¡���ˣ���ʿ����ʦ�����½�ģ�������Ż��о����绰��13639086822��E-mail��lw084601012@gmail.com
ժҪ���о�һ�ֻ�����Ͻ����㷨�Ż���ռ��ع������Ļ���ʱ������Ԥ�ⷽ�����÷������Ƚ���ʱ���ӳ٦Ӻ�Ƕ��ά��m����ռ��е���Ϣ���Ż�ģ�ͣ�Ȼ�����һ�ָĽ�����Ͻ����㷨ͬʱ���2���ع������Ӻ�m�������С�������������л���ʱ������Ԥ�⡣ʵ�����������÷����ܹ�ȷ�����ʵ���ռ��ع������Ӻ�m�����Ԥ�⾫�ȡ�
[1] Takens F. Dynamical systems and turbulence[M]. Berlin: Springer-Verlag Press, 1981: 366-381.
[7] �����. ����ʱ�����е�ʱ���ж�[J]. ����ѧ��, 1997, 46(3): 442-447.
[8] Ф����, �ֹ���, ���. ����ʱ����ռ��ع�����ȷ������Ϣ�۷���[J]. ����ѧ��, 2005, 54(2): 550-556.
[9] ��ǧ��, ����, �Ŵ���. ������Ϣ���Ż���ռ��ع������Ļ���ʱ������Ԥ��[J]. ����ѧ��, 2010, 59(11): 7623-7629.
[13] ����. ��������Ż�����Ļ�Ͻ����㷨����Ӧ��[D]. ��ɳ: ���ϴ�ѧ��Ϣ��ѧ�빤��ѧԺ, 2011: 56-58.
[15] ������, ����, �غ���, ��. ������Ⱥ��������Ե�Լ���Ż������㷨[J]. ���������, 2010, 25(8): 1129-1132.
[16] ������, ������, ����, ��. ���ȫ���Ż�����Ļ������Ӧ�����Ŵ��㷨[J]. ����ѧ��, 2010, 21(6): 1296-1307.
