
J. Cent. South Univ. (2016) 23: 145-149
DOI: 10.1007/s11771-016-3057-5
Voice activity detection based on deep belief networks using likelihood ratio
KIM Sang-Kyun1, PARK Young-Jin2, LEE Sangmin1, 3
1. Department of Electronic Engineering, Inha University, Incheon, 402-751, Korea;
2. Korea Electrotechnology Research Institute (KERI), 111 Hanggaul ro, Sangrok Gu, An-San shi, Kyunggi Do, 426-170, Korea;
3. Institute for Information and Electronics Research, Inha University, Incheon, 402-751, Korea
 Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Abstract:
A novel technique is proposed to improve the performance of voice activity detection (VAD) by using deep belief networks (DBN) with a likelihood ratio (LR). The likelihood ratio is derived from the speech and noise spectral components that are assumed to follow the Gaussian probability density function (PDF). The proposed algorithm employs DBN learning in order to classify voice activity by using the input signal to calculate the likelihood ratio. Experiments show that the proposed algorithm yields improved results in various noise environments, compared to the conventional VAD algorithms. Furthermore, the DBN based algorithm decreases the detection probability of error with [0.7, 2.6] compared to the support vector machine based algorithm.
Key words:
voice activity detection; likelihood ratio; deep belief networks��
1 Introduction
A voice activity detector (VAD) distinguishes speech from noise in adverse conditions, and is one of the crucial components in various speech processing applications such as speech enhancement, speech recognition, and speech coding [1�C3]. For example, without the proper use of a VAD, acoustic feedback may occur in hearing aids because of the acoustic coupling between system output and input through feedback paths. Unfortunately, this acoustic feedback decreases speech quality and intelligibility. For this reason, KIM et al [4] proposed a variable step-size affine projection algorithm (VSS-APA) based on global speech absence probability (GSAP). The step-size is adjusted according to the properties of the input signal. Furthermore, noise power estimation plays a significant role in speech enhancement. The general method of speech enhancement updates the noise power during non-speech frames detected by a VAD [5]. If the noise power is updated during speech frames, speech quality decreases due to the inaccurate estimates of the speech spectral components. For these reasons, robust speech processing in adverse environments has become an important issue in recent years. In particular, it is difficult to locate speech signals under conditions that contain non-stationary noise.
Conventional VAD algorithms utilize energy levels, cepstral coefficients, and linear prediction coding (LPC) parameters [6]. A statistical model-based VAD that provides superior performance was proposed by SOHN et al [7]. They assumed the discrete Fourier transform (DFT) of noisy speech and noise signals to follow the Gaussian distribution and estimated the speech DFT by employing the decision-directed (DD) method [8]. More recently, VADs based on the conditional maximum a posteriori (CMAP) criterion have been proposed and shown to have superior performance [9]. This was accomplished by incorporating a simple CMAP criterion that selects the hypothesis with the higher probability conditioned on the current data, and the voice activity decision in the previous frame.
However, the statistical model-based VAD does not efficiently utilize the benefits of multiple-feature vectors, because it is used to obtain the geometric mean of the likelihood ratio (LR) for the decision rule of the discriminant function. To resolve this problem, JO et al [10] applied a support vector machine (SVM) to the VAD using the LR, which produced better performance than the statistical model-based VAD. However, the performance improvement is limited because the SVM based VAD employs relatively small number of hidden layers [11]. Recently, many VAD algorithms based on the neural network have been proposed [12�C14]. One main drawback of these approaches is the full learning time to extract the feature vectors.
In this work, we propose a novel approach for improving the VAD accuracy by using deep belief networks (DBN) based on LR. The proposed algorithm can explore the underlying manifold and regularity of multiple features when compared with the shallow model such as SVM [15]. The restricted Boltzmann machine (RBM) [16] is used to train the initial parameters of the proposed DBN-based VAD algorithm.
2 Statistical model-based feature extraction
In this section, we describe the feature extraction derived from the statistical model. Figure 1 presents an overall block diagram of a typically statistical processing algorithm. In the time domain, we assume that a noisy speech signal y(t) is the combination of a clean speech signal s(t) and a noise signal n(t) as follows:
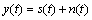 (1)
(1)
where t is a discrete time index.
The input signal is transformed using the short-time Fourier transform (STFT) as follows:
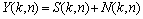 (2)
(2)
where Y, S and N are DFT coefficients of the noisy speech, clean speech and noise, respectively. The frequency bin and frame index are expressed as k and n, respectively.
Assuming that speech is degraded by uncorrelated additive noise, two hypotheses, H0(n) and H1(n) indicate speech absence and presence in the noisy spectral component respectively:
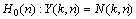 (3)
(3)
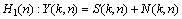 (4)
(4)
With the Gaussian probability density function (PDF) assumption [7], the distributions of the noisy spectral components conditioned on both hypotheses are given by
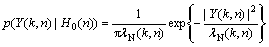 (5)
(5)
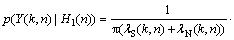
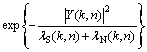 (6)
(6)
where ��S(k, n) and ��N(k, n) denote the speech and noise variances for the kth frequency bin, respectively.
The likelihood ratio (LR) of each frequency bin can be shown to be [7]
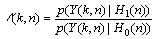
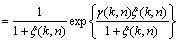 (7)
(7)
where ��(k, n) and ��(k, n) denote the a posteriori signal-to-noise ratio (SNR) and the a priori SNR, respectively [7]:
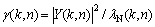 (8)
(8)
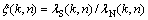 (9)
(9)
The a posteriori SNR ��(k, n) is estimated using ��N(k, n) and the a priori SNR ��(k, n) is estimated by the well-known decision directed (DD) method as follows [8]:
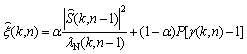 (10)
(10)
where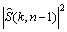 is the speech spectral amplitude estimate of the previous frame obtained using the minimum mean-square error (MMSE) estimator [8]. The smoothing parameter �� is a weight that is usually assigned a value between 0.95 and 0.99 [5] and P[��] is an operator that is defined by
is the speech spectral amplitude estimate of the previous frame obtained using the minimum mean-square error (MMSE) estimator [8]. The smoothing parameter �� is a weight that is usually assigned a value between 0.95 and 0.99 [5] and P[��] is an operator that is defined by
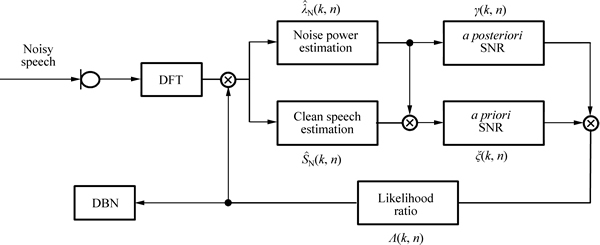
Fig. 1 Block diagram of feature extraction
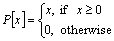 (11)
(11)
The derived LR values are employed as the input features for the proposed algorithm.
3 Proposed DBN-based VAD
The previous section shows that the LR features are extracted from the statistical model-based VAD. Figure 2 presents an overall block diagram of the proposed VAD algorithm. In this section, we explain the training and classification portion of the DBN algorithm.
3.1 DBN-based learning
In this section, we briefly review DBNs, which have been used successfully in various applications such as speech processing and image recognition [17]. The DBN is a probabilistic generative model consisting of multiple stochastic hidden layers. The lowest layer of the DBN is defined as the visible layer that represents the input feature vectors. Because the units in the same layer are not connected to each other, the conditional probabilities can be calculated with relative ease.
For DBN training, we use a Bernoulli-RBM (B- RBM) [16], which employs binary visible and hidden units. The structure of the RBM is the same as the structure of the top two layers in the DBN. In the B-RBM, the joint probability distribution P(v, h) and energy function E(v, h) of visible units v and hidden units h are defined as
 (12)
(12)
 (13)
(13)
 (14)
(14)
where Z is the normalization term, W is the weight matrix of the symmetric connection between the visible and the hidden units, and b and c are the bias terms of the visible and the hidden units, respectively. Because the units in these layers are binary, the conditional probability distributions for the visible and the hidden layers can be easily obtained as follows:
 (15)
(15)
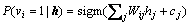 (16)
(16)
where sigm(��) is a sigmoid function.
The parameter set (W, b, c) in the RBM can be optimized to minimize the negative log likelihood of v. This parameter set in the RBM is obtained by using the contrastive divergence algorithm with the aforementioned conditional probabilities, as described in Ref. [18]. After the initial parameter is trained using the B-RBM, back propagation is performed for fine-tuning.
3.2 DBN-based decision
By using the trained parameter of the DBN, the input frame is classified into either speech or noise as follows:
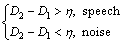 (17)
(17)
where �� is the tunable threshold. D is the probabilistic output of the softmax classifier, and is defined as
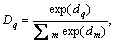 q=1, 2 (18)
q=1, 2 (18)
where m is the number of classes.
dq is obtained as follows:
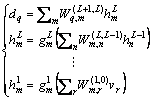 (19)
(19)
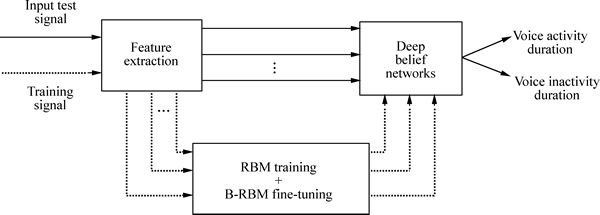
Fig. 2 Block diagram of proposed VAD algorithm
where 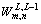 denotes the weights between the adjacent layers, with m as the mth unit of the Lth layer and n as the nth unit of the (L�C1)th layer.
denotes the weights between the adjacent layers, with m as the mth unit of the Lth layer and n as the nth unit of the (L�C1)th layer. 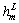 and
and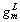 represent the output and nonlinear activation functions, respectively.
represent the output and nonlinear activation functions, respectively.
In this work, the sigmoid function is used as the activation function in all cases, and is given by
 (20)
(20)
4 Experiments and results
Conventional methods and the proposed method were evaluated with clean speech data degraded by different noise types at different noise levels. The input using for the training and test is the derived likelihood ratio from the statistical model. The VAD performance has been evaluated with respect to the ground truth obtained by the manual labeling of speech and non-speech for every 10 ms [7]. For the training material, 230 s of speech was recorded by four males and four females; it was then sampled at 8 kHz. In particular, the clean speech data were obtained by concatenating the clean speech sentences (each with the duration of 8 s). The proportion of manually marked speech frames was 58.2% and consisted of 44.5% voiced speech and 13.4% unvoiced speech. To simulate various noise environments, quasi-stationary noise (e.g., cars) and non-stationary noise (e.g., street noise, office noise and babble noise) were directly added to the clean speech data, resulting in SNRs of 5, 10, and 15 dB. Therefore, total length of the training data set is 2760 s (230 s��3 SNR��4 noises).
For testing, we used different speech material (220 s in duration) manually labeled using 10 ms frames for evaluation. To simulate noisy conditions, car, office, and street noises were again added to the clean speech data using SNRs of 5, 10, and 15 dB.
Table 1 shows comparative results for the teager energy based VAD [2], the SVM based method [9], and the proposed method, using Pe (probability of error), Pm (probability of miss), and Pf (false alarm probability). To facilitate future replication of these tests, a standardized VAD (such as ITU-T G.729 Annex B Appendix III [19]) is also included. From the results, it is evident that the proposed VAD algorithm provides improved performance in most environmental conditions, when compared to previously reported VAD methods. In particular, the performance improvement range observed under quasi-stationary noise condition was [0.7, 1.2]. Furthermore, the performance improvement ranges observed under non-stationary noise conditions were [0.7, 2.6] for street noise, [1, 2.1] for office noise and [1.1, 2.5] for babble noise. The proposed approach provided superior performance especially for speech corrupted with non-stationary noise. This is ascribed to the characteristic that the DBN-based scheme is relevant to rapidly changing spectral. For this reason, proposed VAD algorithm seems to be suitable in the real noise environment condition.
The parameter settings of DBN are presented in Table 2. The critical parameter settings are for minimizing the detection errors. A minibatch size of 200 training samples for the pre-training and fine-tuning is used. The maximum number of hidden layers is set to be 2 with 93 and 96 units that are derived heuristically. To
derive the well performance, we have run 200 epoches and selected a model.
Table 1 Comparison of voice activity detection probability of error (Pe), probability of miss (Pm) and false alarm probability (Pf) among method of teager energy based VAD [2], SVM based method [10], G.729 Appendix III [19] and proposed technique
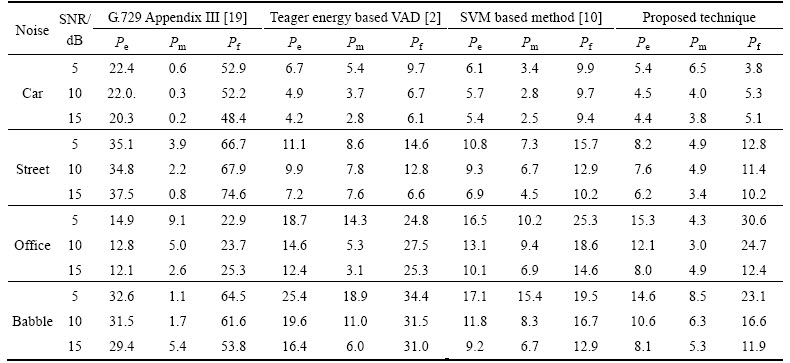
Table 2 Parameter settings of DBN

5 Conclusions
We have proposed a novel VAD technique based on a DBN algorithm using the LR feature for robust VAD decision. The input features of the proposed DBN-based VAD were extracted using the conventional VAD algorithm based on a statistical model. The proposed approach yields superior performance in various noise environments, when compared to conventional VAD methods especially for environments with non-stationary noise. This is attributed to the fact that the DBN-based approach is appropriate for highly varying spectral conditions.
Acknowledgments
This research was supported by the KERI Primary Research Program through the Korea Research Council for Industrial Science & Technology funded by the Ministry of Science, ICT and Future Planning (No. 15-12-N0101-46).
References
[1] MAK M W, YU H B. A study of voice activity detection techniques for NIST speaker recognition evaluations [J]. Computer Speech & Language, 2014, 28(1): 295�C313.
[2] PARK Y S, LEE S M. Voice activity detection using global speech absence probability based on teager energy for speech enhancement [J]. IEICE Trans Inf & Syst, 2012, E95-D(10): 2568�C2571.
[3] KIM S K, CHANG J H. Voice activity detection based on conditional MAP criterion incorporating the spectral gradient [J]. Signal Processing, 2012, 92(7): 1699�C1705.
[4] KIM Y S, SONG J H, KIM S K, LEE S M. Variable step-size affine projection algorithm based on GSAP for adaptive feedback cancellation [J]. Journal of Central South University, 2014, 21(2): 646�C650.
[5] KWON K S, SHIN J W, SONOWAT S, CHOI I K, KIM N S. Speech enhancement combining statistical models and NMF with update of speech and noise bases [C]// Acoustics, Speech, and Signal Processing, IEEE International Conference on (ICASSP). Florence, 2014: 7053�C7057.
[6] RABINER L R, SAMBUR M R. Voiced-unvoiced silence detection using Itakura LPC distance measure [C]// Acoustics, Speech, and Signal Processing, IEEE International Conference on (ICASSP). Hartford, 1977: 323�C326.
[7] SOHN J, KIM N S, SUNG W. A statistical model-based voice activity detection [J]. IEEE Signal Processing Letters, 1999, 6(1): 1�C3.
[8] EPHRAIM Y, MALAH D. Speech enhancement using a minimum mean-square error short-time spectral amplitude estimator [J]. IEEE Trans Acoustic Speech Signal Processing, 1984, 32(6): 1109-1121.
[9] SHIN J W, KWON H J, JIN S H, KIM N S. Voice activity detection based on conditional MAP criterion [J]. IEEE Signal Processing Letters, 2008, 15: 257�C260.
[10] JO Q H, PARK Y S, LEE K H, CHANG J H. A support vector machine-based voice activity detection employing effective feature vectors [J]. IEICE Trans Commun, 2008, E91-B(6): 2090�C2093.
[11] QI Z, TIAN Y, SHI Y. Robust twin support vector machine for pattern classification [J]. Pattern Recognition, 2013, 46(1): 305�C316.
[12] ZHANG X-L, WU J. Deep belief networks based voice activity detection [J]. IEEE Trans ASLP, 2013, 21(4): 697�C710.
[13] ZHANG X-L, WU J. Denoising deep neural networks based voice activity detection [C]// Acoustics, Speech, and Signal Processing, IEEE International Conference on (ICASSP). Vancouver, 2013.
[14] HUGHES T, MIERKE K. Recurrent neural networks for voice activity detection [C]// Acoustics, Speech, and Signal Processing, IEEE International Conference on (ICASSP). Vancouver, 2013.
[15] BENGIO Y, LECUN Y. Scaling learning algorithms towards AI [J]. Large-scale Kernel Machines, 2007, 34(5): 321-360.
[16] HINTON G. A practical guide to training restricted Boltzmann machines [M]// Neural Networks: Tricks of the Trade. Springer Berlin Heidelberg, 2012: 599-619.
[17] SELTZER M L, YU D, WANG Y. An investigation of deep neural networks for noise robust speech recognition [C]// Acoustics, Speech, and Signal Processing, IEEE International Conference on (ICASSP). Vancouver, 2013: 7398�C7402.
[18] HINTON G, Training products of experts by minimizing contrastive divergence [J]. Neural Computation, 2002, 18(7): 1527�C1554.
[19] ITU-T. Appendix III: G.729 Annex B enhancement in voice-over-IP applications-Option 2 [R]. 2005.
(Edited by YANG Bing)
Received date: 2015-06-12; Accepted date: 2015-11-08
Corresponding author: LEE Sangmin, Professor, PhD; Tel: +82-32-860-7420; E-mail: sanglee@inha.ac.kr
Abstract: A novel technique is proposed to improve the performance of voice activity detection (VAD) by using deep belief networks (DBN) with a likelihood ratio (LR). The likelihood ratio is derived from the speech and noise spectral components that are assumed to follow the Gaussian probability density function (PDF). The proposed algorithm employs DBN learning in order to classify voice activity by using the input signal to calculate the likelihood ratio. Experiments show that the proposed algorithm yields improved results in various noise environments, compared to the conventional VAD algorithms. Furthermore, the DBN based algorithm decreases the detection probability of error with [0.7, 2.6] compared to the support vector machine based algorithm.
