

J. Cent. South Univ. (2020) 27: 3744-3753
DOI: https://doi.org/10.1007/s11771-020-4574-9
Robust multi-layer extreme learning machine using bias-variance tradeoff
YU Tian-jun(�����), YAN Xue-feng(��ѧ��)
Key Laboratory of Advanced Control and Optimization for Chemical Processes of Ministry of Education, East China University of Science and Technology, Shanghai 200237, China
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2020
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2020
Abstract:
As a new neural network model, extreme learning machine (ELM) has a good learning rate and generalization ability. However, ELM with a single hidden layer structure often fails to achieve good results when faced with large-scale multi-featured problems. To resolve this problem, we propose a multi-layer framework for the ELM learning algorithm to improve the model��s generalization ability. Moreover, noises or abnormal points often exist in practical applications, and they result in the inability to obtain clean training data. The generalization ability of the original ELM decreases under such circumstances. To address this issue, we add model bias and variance to the loss function so that the model gains the ability to minimize model bias and model variance, thus reducing the influence of noise signals. A new robust multi-layer algorithm called ML-RELM is proposed to enhance outlier robustness in complex datasets. Simulation results show that the method has high generalization ability and strong robustness to noise.
Key words:
extreme learning machine; deep neural network; robustness; unsupervised feature learning��
Cite this article as:
YU Tian-jun, YAN Xue-feng. Robust multi-layer extreme learning machine using bias-variance tradeoff [J]. Journal of Central South University, 2020, 27(12): 3744-3753.
DOI:https://dx.doi.org/https://doi.org/10.1007/s11771-020-4574-91 Introduction
As an efficient single-layer feed-forward network (SLFN), extreme learning machine (ELM) [1, 2] has elicited much attention over the past few years. Different from traditional SLFNs, such as back propagation (BP), ELM has a high calculation speed and powerful generalization ability; thus, it can obtain good results at a low computational cost. ELM has been used in many applications, such as image identification [3-7], biomedical research [8-10], and troubleshooting [11-13].
However, the original ELM is a learning process based on the principle of empirical risk minimization. Consequently, the trained model is prone to overfitting. Furthermore, the hidden layer outputs of the original ELM may fluctuate considerably when many outliers exist in the datasets used. This situation reduces the generalization ability and robustness of the model. Regularized ELM (RELM) adds regularization or penalty items representing model complexity on the basis of empirical risk [14]. During the minimization of the empirical risk, the simpler the model is, the smaller the empirical risk is and the better the generalization ability of RELM is. ZHANG et al [15] proposed a robust ELM called outlier robust extreme learning machine (ORELM), which adds an L1 regularization item in the loss function to improve the generalization ability of the model. However, ORELM requires a higher computational cost than ordinary ELM. To solve this problem, LU et al [16] developed a new probability ELM. This model adds bias and variance to the loss function to express the error distribution of modeling. If the error distribution of modeling is consistent with that of concomitant noise, this model can obtain good fitting ability and overcome the interference of noise. ZHAO et al [17] proposed a robust ELM called ridge regression extreme learning machine (RRELM) with the same loss function as probability ELM. RRELM adds bias and variance to the loss function to overcome the bias-variance dilemma and improve the generalization ability of the model.
Deep learning has been the most interesting part of machine learning in recent years [18]. Unlike traditional machine learning, deep learning focuses on extracting effective features. Before the introduction of deep learning, feature selection was performed manually. With deep learning, a model can select valid features without supervision. Deep learning uses the multi-layer model to determine complex structures and learn high-level representation through the model. Deep learning algorithms have been proven to be superior to SLFN in many applications. However, despite the advantage of the multi-layer model of deep learning, the model gives rise to the problem of exponential growth of the calculation cost. Nevertheless, the advantages of deep learning under the condition of low calculation cost can be obtained when the algorithm is combined with the characteristics of ELM. KASUN et al [19] proposed a new autoencoder called ELM-based autoencoder (ELM- AE), which is an unsupervised SLFN learning algorithm. When the least-squares method is used to solve the output weight, ELM-AE makes the input data of the network as consistent as possible with the target output. By combining the autoencoder with ELM, KASUN et al [19] proposed a multi-hidden-layer model based on ELM-AE called multi-layer extreme learning machine (ML-ELM). This model consists of two parts. The first section is stacked with multiple ELM-AEs for feature extraction, and the second section uses an ELM model as the classifier. TANG et al [20] developed a multi-layer perceptron stratified learning framework called hierarchical extreme learning machine (H-ELM). In the feature extraction stage, on the basis of ELM-AE, L1 regularization is introduced to establish a sparse ELM-AE for improving generalization ability. However, to improve the robustness of H-ELM, CHEN et al [21] introduced a new full Correntropy-based ML-ELM (FC-MELM) that uses Correntropy-based ELM-AE to perform feature extraction. FC-MELM is robust, but it considerably increases the cost of computing and requires a large computational memory.
In this study, we propose a multilayer robust extreme learning machine autoencoder (ML- RELM) to improve the robustness of the model when the data are polluted by noise. The effectiveness of the model is proven through experiments.
2 Background
Regularization ELM, robust regularization ELM (RRELM), and ELM-AE are introduced in this section.
2.1 Regularization ELM
For any unknown nonlinear system, we can describe it as
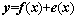 (1)
(1)
where x is the input matrix or vector; y is the output matrix or vector; f(x) is the model for y; e(x) is the error of the model��s fitting of y, which may be the bias and variance of the model itself or noise from the data.
The model of ELM [14] can be described by the above-mentioned system as follows:
 (2)
(2)
where g(��) is the activation function; ai is the input weight matrix (input weight vector); bi is the input bias that connects the input layer with the middle layer; ai and bi are randomly generated; ��i is the weight vector that connects the hidden nodes to the output nodes.
When the model has an input data set 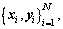 the original ELM applies itself to make the output variable as consistent as possible with the target variable. In other words, it makes the following equation true:
the original ELM applies itself to make the output variable as consistent as possible with the target variable. In other words, it makes the following equation true:
Y=H�� (3)
where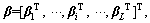
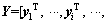
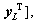 and H is the hidden node output matrix expressed as follows:
and H is the hidden node output matrix expressed as follows:
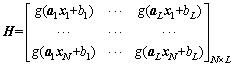 (4)
(4)
The following optimization problem needs to be solved to obtain the key of weight vector �� in Formula (3).
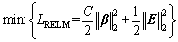
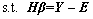 (5)
(5)
where 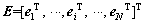 is the error matrix consisting of all the modeling errors;
is the error matrix consisting of all the modeling errors; 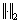 is the L2 norm; C is the regularization parameter for improving the model��s fitting ability. The Lagrangian multiplier method is used to calculate ��, and the result is as follows:
is the L2 norm; C is the regularization parameter for improving the model��s fitting ability. The Lagrangian multiplier method is used to calculate ��, and the result is as follows:
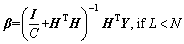 (6)
(6)
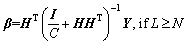 (7)
(7)
where I is the identity matrix. RELM is effective for noiseless conditions, but the generalization ability of RELM decreases when the environment has outliers or noise.
2.2 RRELM
To overcome the bias-variance dilemma that widely exists in ML models, RRELM [17] adds bias and variance to the loss function to reach a state of approximate optimum by equilibrating the bias and variance of the model. The loss function [16] is as follows:
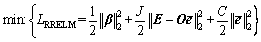
(8)
where O is the matrix with all one elements; 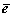 represents the modeling error adjusting factor; C and J are regularization parameters. For the loss function, minimizing the second term can increase the robustness of the model, and minimizing the third term can avoid the decrease in generalization ability caused by the increase in the biases. Noise and outliers usually generate large modeling errors. RRELM considerably reduces the impact of noise on modeling performance, improves the fitting ability of the model, and has stronger robustness than RELM in the optimization process. To sum up, minimizing the loss function (8) can improve the robustness and generalization ability of the model simultaneously.
represents the modeling error adjusting factor; C and J are regularization parameters. For the loss function, minimizing the second term can increase the robustness of the model, and minimizing the third term can avoid the decrease in generalization ability caused by the increase in the biases. Noise and outliers usually generate large modeling errors. RRELM considerably reduces the impact of noise on modeling performance, improves the fitting ability of the model, and has stronger robustness than RELM in the optimization process. To sum up, minimizing the loss function (8) can improve the robustness and generalization ability of the model simultaneously.
The optimization problem has two solutions. Here, the Lagrange multiplier method is used, and in most of the situations, the amount of data (N) is larger than feature dimension number L.
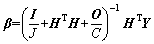 (9)
(9)
On the basis of the loss function (9) and according to the theory put forward by ZHAO et al [17],has a close relationship with E(e):
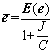 (10)
(10)
When J��0 or C or the number of input samples (N) is large, 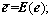 when J����,
when J����, 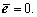 Under this circumstance, RRELM is reduced to RELM.
Under this circumstance, RRELM is reduced to RELM.
2.3 ELM-AE
ELM-AE can be used as SLFN, and ELM theory can be used to construct an autoencoder for feature extraction or dimension reduction, which has the advantages of fast calculation speed and high efficiency of ELM. Similar to the traditional ELM neural network, the network structure of ELM-AE includes three layers: input layer, hidden layer and output layer. The only difference is that the target output of ELM-AE and its input are equal. Figure 1 shows the network diagram of ELM-AE. ELM-AE performs feature extraction in a multilayer learning framework and can learn many advanced features of input data x by minimizing the reconstruction error of input data x with the encoded output 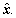 The process of ELM-AE can be divided into two parts, namely, encoding and decoding [19]. In coding, x can be mapped into the coded value y via deterministic mapping as follows: y=g(Wx+b), where g(��) is the activation function and W and b are randomly generated but have the constrained condition WTW=I, bTb=1. This constrained condition can promote the generalization ability of ELM-AE. In decoding, y can be mapped into the decoded value
The process of ELM-AE can be divided into two parts, namely, encoding and decoding [19]. In coding, x can be mapped into the coded value y via deterministic mapping as follows: y=g(Wx+b), where g(��) is the activation function and W and b are randomly generated but have the constrained condition WTW=I, bTb=1. This constrained condition can promote the generalization ability of ELM-AE. In decoding, y can be mapped into the decoded value  via deterministic mapping as follows:
via deterministic mapping as follows: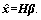 The reconstruction of input data by ELM-AE can also be solved by using the ELM method. Given that the amount of data is often larger than the amount of features, the Lagrangian multiplier method is used to calculate ��, and the following result is achieved.
The reconstruction of input data by ELM-AE can also be solved by using the ELM method. Given that the amount of data is often larger than the amount of features, the Lagrangian multiplier method is used to calculate ��, and the following result is achieved.
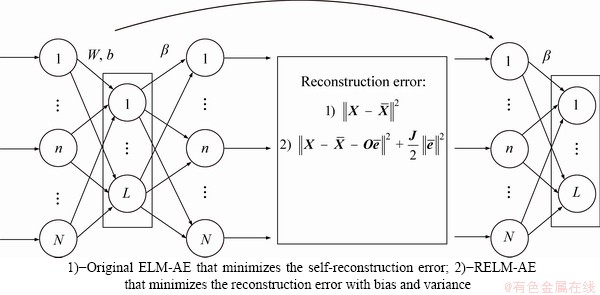
Figure 1 ELM-AE structure chart:
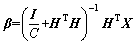 (11)
(11)
The main goal of ELM-AE is to meaningfully re-express input data in three different representation forms:
Compression: The representative features come from a higher-dimensional input data space to a lower-dimensional functional space.
Sparseness: This represents a feature space from a low-dimensional input data space to a higher-dimensional feature space.
Equality: This indicates that the spatial size from the input data is equal and characterized by the spatial size.
3 Proposed learning algorithm
In this section, we present a new ELM-AE for unsupervised feature extraction. We use it under the multi-layer ELM framework to put forward a new multi-layer ELM.
3.1 Robust extreme learning machine autoencoder
A new robust extreme learning machine autoencoder (RELM-AE) is developed. Based on the construction of ELM-AE and the approximation ability of ELM, the bias and variance of the training data are added to the loss function to design the autoencoder effectively. The mathematical model of RELM-AE is given as follows:
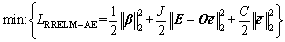
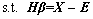 (12)
(12)
The definitions of all the letters in the formula are similar to those in Formula (9).
The Lagrangian equation is established to address the optimization question.
 (13)
(13)
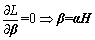 (14)
(14)
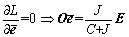 (15)
(15)
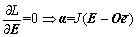 (16)
(16)
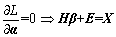 (17)
(17)
Next, Formulas (15), (16), and (17) are summed up.
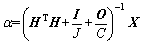 (18)
(18)
The result is
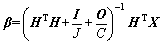 (19)
(19)
When RELM-AE is used as the unsupervised feature extractor, it does not exhibit much difference from ELM-AE structurally; therefore, theoretically, the training time of RELM-AE is consistent with that of ELM-AE. The network diagram of ELM-AE is shown in Figure 1. When the training data are contaminated by noise, the stronger the noise is, the greater the bias and variance of the model are. RELM-AE inputs bias and variance to the model to obtain a model that is free of the bias-variance dilemma. In real situations, very little data are not contaminated by noise. Therefore, incorporating the bias and variance of the model into the loss function is often useful. RELM-AE has better fitting ability and stronger robustness than ELM-AE. Given the better fitting ability of RELM-AE, the autoencoder can better learn deep information. At the same time, the learner can take advantage of learning the deviation and variance of the model in a noisy environment to improve the robustness of the model.
3.2 ML-RELM
RELM-AE can be used in unsupervised feature extraction and applied to the framework of deep learning. We propose a new depth framework called ML-RELM. ML-RELM consists of two parts: one is the unsupervised feature extractor superimposed by multiple RELM-AEs, and the other is an ELM as a classifier or used for regression (supervised learning). First, the training data are entered into the RELM-AE of the first layer to obtain further data characteristics. Second, the output of this layer is taken as the input for the next layer. According to this rule, the network can be trained layer by layer until the output of the Kth layer in the final feature is derived. The algorithm is summarized as Algorithm 1. The network diagram of ML-RELM is shown in Figure 2. For the ith layer in the superposition of multiple RELM-AE, the output of each hidden layer can be calculated using the following formula:
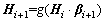 (20)
(20)
Algorithm 1 ML-RELM

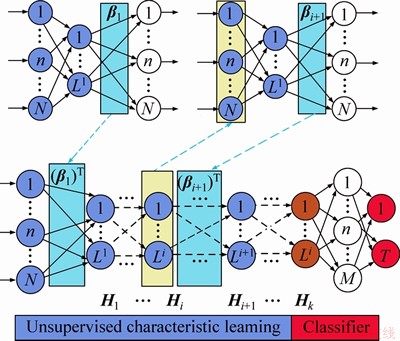
Figure 2 ML-RELM framework
ML-RELM inherits the advantages of other multi-layer ELM-AEs. The idea of ELM is to train each hidden layer without the need for iterative fine-tuning of the parameters of each hidden layer. Hence, the computational cost of ML-RELM is very low. The bias and variance of the model are considered in the process of unsupervised learning for ML-RELM, which can improve the generalization ability and robustness of the model to noise. Therefore, ML-RELM can obtain clear and deep information in the presence of noise in the data environment. We select ELM as the last layer of the neural network for classification or regression.
4 Performance evaluation and analysis
We test the effectiveness of ML-RELM in classification and regression problems by using an artificial dataset and multiple benchmark datasets. Then, we compare it with several effective methods. We added noise signals based on MNIST [22] handwritten data (MNIST) and NYU object recognition benchmark dataset (NORB) [23] to verify the robustness of ML-RELM. All experiments are performed on a personal desktop PC with Intel Xeon Sliver 4110 CPU running at 2.10 GHz, 32 GB of RAM, and Windows 10 operating system in the MATLAB R2018b environment.
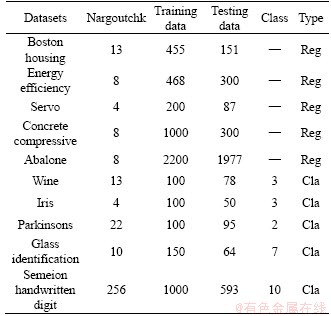
For the calculation accuracy test, the experiment mainly targets regression and classification problems. The test datasets for the regression problems include Boston housing, abalone, servo, energy efficiency, and concrete compressive strength. The test datasets for the classification problem mainly include wine, iris, Parkinson��s, glass identification, and Semeion handwritten digit. The contents of all experimental data for regression and classification problems are from the UCI machine learning knowledge base [24] and shown in Table 1. All network inputs and outputs are randomly shuffled and divided into training and test sets. All data are normalized into the [0,1] range. The activation function is g(x)=1/(1+exp(-x)).
In theory, the hidden layer number K can improve the accuracy of the data if it is large. However, too much hidden layers will also bring bad effects [23]:
1) Too much hidden layer will increase the time of training model and increase computational cost.
2) Too many hidden layers will cause the model to be overfitted, thereby reducing the accuracy of the model.
For experimental data, after many experiments, we finally stipulated that for the artificial dataset, we choose a one-layer network for unsupervised learning; for small data sets shown in Table 1, we choose a two-layer network; and for large data sets, we choose a three-layer network for unsupervised learning.
For the artificial dataset, we create the function y=sinx1+cosx2+sin(Cx3), where x1 is a random number with a mean of 1, x2 is a random number with a mean of 2, and x3 is a random number with a mean of 0.5. We randomly create 1000 sets of data as the training set and 1000 sets of data as the testing set. The same amount of random noise data with the same mean value is added to the training and testing sets. The proportion of noise data in training or testing data is 0, 20%, 40% and 60%. In addition to the proposed ML-RELM, ML-ELM and RELM are also used for comparison. According to the reliable experimental conclusions of Kasun [23], in the unsupervised learning of ELM-AE, the learning ability is not sensitive to the number of hidden neurons L. So, we limit the number of hidden neurons L to 2 times the number of data features for small data sets and the artificial dataset. Root mean square error (RMSE) is adopted as the evaluation standard for regression accuracy to avoid randomness in the experiment. All experiments are repeated 100 times. The results of the artificial dataset experiment are shown in Table 2. ML-RELM presents better robustness than the other algorithms for the artificial datasets polluted by noise.
Table 1 Description of UCI datasets
Aside from the proposed ML-RELM, we also use ML-ELM, RRELM, ELM, and GRELM [7] for comparison. ML-ELM and ML-RELM have two layers of networks for unsupervised feature extraction. According to Formula (10), parameters C and J considerably influence the performance of the model. The model can obtain good fitting ability with appropriate parameters. K-fold cross validation [25] is used to determine parameter C. Parameter J is selected from the set {2-10, 2-9, ��, 29, 210}. The setting result of parameter C of ML- ELM, RRELM, and RELM is similar to that of ML-RELM. The setting result of parameter J of RRELM is similar to that of ML-RELM. Table 3 shows the result of the parameter setting. All experiments are repeated 100 times. Table 4 shows the consequences of the regression experiment.
Table 2 Results of artificial dataset problem solved by ML-RELM with other methods
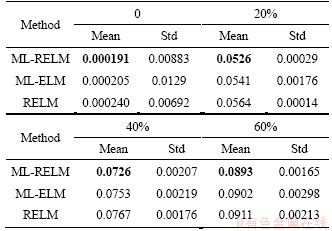
Table 4 reveals that in the five UCI regression datasets, the RMSE of ML-RELM is smaller than that of the other methods, except for the servo data in which it is slightly larger than the RMSE of GRELM. In general, the consequences prove that the algorithm is effective for regression problems.
Table 3 Settings of ML-RELM
For the classification problem, aside from the proposed ML-RELM, we also use ML-ELM, RELM, SVM [26], and GRELM for comparison. Table 3 shows the parameter settings of ML-RELM. The parameter settings of the other methods are similar to those for the regression problem. All experiments are repeated 100 times. Table 5 shows the results of the classification experiment. Table 5 shows that in the five UCI classification datasets, ML-RELM has better classification accuracy than the other methods. This result indicates that ML-RELM has good fitting ability in the classification problem.
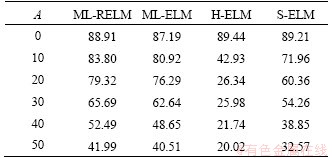
In real environments, data are always contaminated by noise; thus, data modeling is inevitable in the face of noise pollution. The proposed ML-RELM adjusts the size of the bias and variance of the model to eliminate the bias-variance dilemma for the improvement of the robustness of the model with noise data. The proposed ML-RELM also has strong anti-interference ability against noise data. In this section, we use MNIST and NORB datasets contaminated by Gaussian noise to verify ML-RELM��s robustness for the datasets with noise or outliers. The MNIST dataset is a classic dataset in machine learning. It is composed of 60000 training samples and 10000 test samples, each of which is a handwritten digital picture of 28��28 pixels gray scale. NORB is used in experiments to identify 3D objects from their shapes. It contains images of 50 toys that fall into five categories: tetrapods, people, planes, trucks, and cars. The training set consists of a test set of five instances of each category and the remaining five instances. This dataset is composed of 24300 training samples and 24300 test samples. All datasets are standardized into [0, 1]. On this basis, we change the size of noise added to the datasets to determine the robustness of the model against noise with different intensities. There are 11 levels of noise from 0 to 100, which are represented by A in Tables 6 and 7. Several effective ELM-based multi-layer neural networks, namely, ML-ELM, S-ELM [27], and H-ELM, are compared to demonstrate the superiority of the proposed model. For MNIST data set, the network structure of ML-RELM is similar to that of ML-ELM and H-ELM, which is 700-700-12000. For the NORB dataset, the network structure of ML-RELM is similar to that of ML-ELM and H-ELM, which is 3000-3000-15000. The operation is repeated 10 times in each different environment, and the best data are obtained as the result.
Table 4 Results of regression problem solved by ML-RELM with other methods
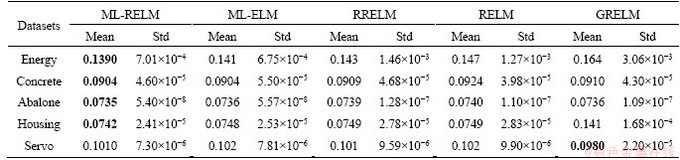
Table 5 Results of classification problem solved by ML-RELM with other methods
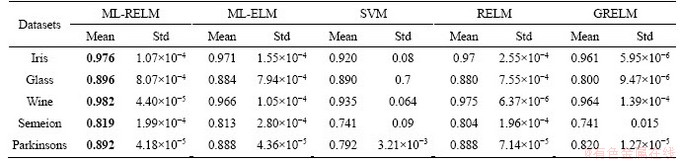
Table 6 shows the recorded test results for the MNIST dataset. When no noise exists in the dataset, the classification accuracy of ML-RELM is slightly lower than that of H-ELM. However, when the noise signal is gradually strengthened, the classification accuracy of all models decreases; the accuracy of ML-RELM decreases the slowest, whereas that of H-ELM decreases the fastest. We graph the data in Table 6 and present the graph in Figure 3. ML-RELM has better robustness than the other methods under the influence of the noise signal.
The test results for the NORB dataset are recorded in Table 7. When no noise exists in the NORB dataset, H-ELM has the best classification accuracy. When the intensity of noise in the dataset gradually increases, all of the algorithms (except for ML-RELM) exhibit a significant decrease, but the results of ML-RELM show a moderate descent. Figure 4 shows the robust performance of ML-RELM.
After combining the experiments on adding noise to the two data sets, we find that the proposed ML-RELM has stronger robustness than the other algorithms.
Table 6 Accuracy (%) for MNIST dataset at different noise levels
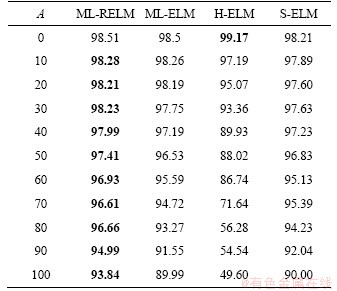
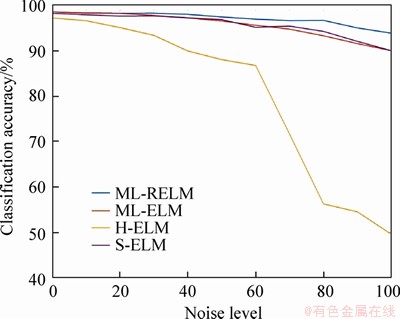
Figure 3 MNIST dataset used to compare classification accuracy of ML-RELM and other methods at different noise levels
Table 7 Accuracy (%) for NORB dataset at different noise levels
5 Conclusions
We proposed a new autoencoder based on ELM for feature extraction called RELM-AE. RELM-AE adds deviation and variance to the loss function and makes a tradeoff between the ability to minimize model deviation and model variance to obtain the best fitting ability. RELM-AE was applied to the deep learning framework, and a multi-layer learning model called ML-RELM was proposed. ML-RELM can learn deep representation and obtain robustness by learning noise pollution in model data. The results of the experiment showed that this model can improve the generalization ability of the model and has strong robustness.
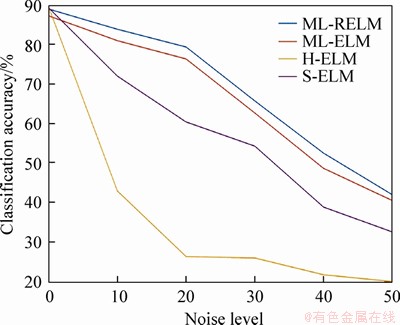
Figure 4 NORB dataset used to compare classification accuracy of ML-RELM and other methods at different noise levels
Contributors
YU Tian-jun provided the concept, conducted the literature review, wrote and edited the draft of the manuscript. YAN Xue-feng edited the draft of the manuscript and provided directional guidance and financial support for the whole study.
Conflict of interest
YU Tian-jun and YAN Xue-feng declare that they have no conflict of interest.
References
[1] HUANG Guang-bin, ZHU Qin-yu, SIEW C K. Extreme learning machine: A new learning scheme of feedforward neural networks [C]// 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No.04CH37541). 2004, 2: 985-990.
[2] HUANG Guang-bin, ZHU Qin-yu, SIEW C K. Extreme learning machine: Theory and applications [J]. Neurocomputing, 2006, 70(1-3): 489-501.
[3] HUANG Zhi-yong, YU Yuan-long, GU J, LIU Hua-ping. An efficient method for traffic sign recognition based on extreme learning machine [J]. IEEE Transactions on Cybernetics, 2017, 47(4): 920-933. DOI: 10.1109/TCYB.2016.2533424.
[4] IOSIFIDIS A, TEFAS A, PITAS I. Approximate kernel extreme learning machine for large scale data classification [J]. Neurocomputing, 2017, 219: 210-220. DOI: 10.1016/ j.neucom.2016.09.023.
[5] YANG Yi-min, WU Q M J. Extreme learning machine with subnetwork hidden nodes for regression and classification [J]. IEEE Transactions on Cybernetics, 2016, 46(12): 2885-2898. DOI: 10.1109/tcyb.2015.2492468.
[6] XU Xin-zheng, SHAN Dong, LI Shan, SUN Tong-feng, XIAO Peng-cheng, FAN Jian-ping. Multi-label learning method based on ML-RBF and laplacian ELM [J]. Neurocomputing, 2019, 331: 213-219. DOI: 10.1016/ j.neucom.2018.11.018.
[7] INABA F K, TEATINI SALLES E O, PERRON S, CAPOROSSI G. DGR-ELM-distributed generalized regularized ELM for classification [J]. Neurocomputing, 2018, 275: 1522-1530. DOI��10.1016/j.neucom.2017.09.090.
[8] ZHANG Yu, WANG Yu, ZHOU Guo-xu, JIN Jing, WANG Bei, WANG Xing-yu, CICHOCKI A. Multi-kernel extreme learning machine for EEG classification in brain-computer interfaces [J]. Expert Systems with Applications, 2018, 96: 302-310. DOI: 10.1016/j.eswa.2017.12.015.
[9] DAI Hao-zhen, CAO Jiu-wen, WANG Tian-lei, DENG Mu-qing, YANG Zhi-xin. Multilayer one-class extreme learning machine [J].Neural Networks,2019, 115: 11-22. DOI: 10.1016/j.neunet.2019.03.004.
[10] CHYZHYK D, SAVIO A, GRANA M. Computer aided diagnosis of schizophrenia on resting state fMRI data by ensembles of ELM [J]. Neural Networks, 2015, 68: 23-33. DOI: 10.1016/j.neunet.2015.04.002.
[11] WONG P K, YANG Zhi-xin, VONG C M, ZHONG Jian-hua. Real-time fault diagnosis for gas turbine generator systems using extreme learning machine [J]. Neurocomputing, 2014, 128: 249-257. DOI:10.1016/j.neucom.2013.03.059.
[12] DU Fang, ZHANG Jiang-she, JI Nan-nan, SHI Guang, ZHANG Chun-xia. An effective hierarchical extreme learning machine based multimodal fusion framework [J]. Neurocomputing, 2018, 322: 141-150. DOI: 10.1016/ j.neucom.2018.09.005.
[13] CHEN Zhi-cong, WU Li-jun, CHENG Shu-ying, LIN Pei-jie, WU Yue, LIN Wen-cheng. Intelligent fault diagnosis of photovoltaic arrays based on optimized kernel extreme learning machine and I-V characteristics [J]. Applied Energy, 2017, 204: 912-931. DOI:10.1016/j.apenergy.2017.05.034.
[14] DENG Wan-yu, ZHENG Qing-hua, CHEN Lin, XU Xue-bin. Research on extreme learning of neural networks [J]. Chinese Journal of Computers, 2010, 33(2): 279-287. DOI��10.3724/SP.J.1016.2010.00279. (in Chinese)
[15] ZHANG Kai, LUO Min-xia. Outlier-robust extreme learning machine for regression problems [J]. Neurocomputing, 2015, 151: 1519-1527. DOI:10.1016/j.neucom.2014.09.022.
[16] LU Xin-jiang, MING Li, LIU Wen-bo, LI Han-xiong. Probabilistic regularized extreme learning machine for robust modeling of noise data [J]. IEEE Transactions on Cybernetics, 2018, 48(8): 2368-2377. DOI: 10.1109/tcyb. 2017.2738060.
[17] ZHAO Yong-ping, HU Qian-kun, XU Jian-guo, LI Bing, HUANG Gong, PAN Ying-ting. A robust extreme learning machine for modeling a small-scale turbojet engine [J]. Applied Energy, 2018, 218: 22-35. DOI: 10.1016/ j.apenergy.2018.02.175.
[18] HINTON G E, OSINDERO S, TEH Y W. A fast learning algorithm for deep belief nets [J]. Neural Comput, 2006, 18(7): 1527-1554. DOI:10.1162/neco.2006.18.7.1527.
[19] KASUN L L C, ZHOU Hong-ming, HUANG Guang-bin, VONG C. Representational learning with extreme learning machine for big data [J]. IEEE Intelligent System, 2013(4): 1-4.
[20] TANG Jie-xiong, DENG Chen-wei, HUANG Guang-bin. Extreme learning machine for multilayer perceptron [J]. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(4): 809-821. DOI: 10.1109/tnnls. 2015.2424995.
[21] CHEN Liang-jun, HONEINE P, QU Hua, ZHAO Ji-hong, SUN Xia. Correntropy-based robust multilayer extreme learning machines [J]. Pattern Recognition, 2018, 84: 357-370. DOI��10.1016/j.patcog.2018.07.011.
[22] LE CUN Y, HUANG F J, BOTTOU L. Gradient-based learning applied to document recognition [C]// Proceedings of the IEEE. 1998, 86(11): 2278-2324. DOI: 10.1109/5. 726791.
[23] LE CUN Y, HUANG F J, BOTTOU L. Learning methods for generic object recognition with invariance to pose and lighting [C]// Conference on Computer Vision and Pattern Recognition. Washington DC: IEEE Comp Soc, 2004, 2: 97-104.
[24] LICHMAN M. UCI machine learning repository [D]. California, Irvine, CA, USA: School Inf Comput Sci Univ 2013. http://archive.ics.uci.edu/ml.
[25] WIENS T S, DALE B C, BOYCE M S. Three-way k-fold cross-validation of resource selection functions [J]. Ecological Modelling, 2008, 212(3, 4): 244-255. DOI: 10. 1016/j.ecolmodel.2007.10.005.
[26] SUYKENS J A K, VANDEWALLE J. Least squares support vector machine classifiers [J].Neural Process Lett, 1999, 9(3): 293-300. DOI: 10.1023/A:1018628609742.
[27] ZHOU Hong-ming, HUANG Guang-bin, LIN Zhi-ping, WANG Han, SOH Y C. Stacked extreme learning machines [J]. IEEE Transactions on Cybernetics, 2014, 45(9): 2013- 2025. DOI: 10.1109/TCYB.2014.2363492.
(Edited by YANG Hua)
���ĵ���
����ƫ��-����Ȩ��Ķ��³������ѧϰ��ģ��
ժҪ������ѧϰ��(ELM)��Ϊһ�����͵�������ģ�ͣ��������õ�ѧϰ�ٶȺͷ���������Ȼ����������ṹ��ELM�����ٴ��ģ����������ʱ��������ȡ�����õ�Ч����Ϊ�˽��������⣬���һ�����͵Ķ��ELMѧϰ�㷨��������ģ�͵ķ������������⣬��ʵ��Ӧ���У���������Ϊ�����������쳣�������ѵ�����ݱ���Ⱦ����Ա���Ⱦ�����ݣ���ͨ��ELM�ķ����������½���Ϊ�˽��������⣬����ƫ��-����ֽ����ۣ�����ʧ�����м���ģ�͵�ƫ��ͷ��ʹģ�ͻ����С��ģ��ƫ���ģ�ͷ�����������Ӷ����������źŵ�Ӱ�졣�������һ���µ�³������㷨ML-RELM���������ں�����Ⱥ��ĸ������ݼ��е�³���ԡ��������������÷������н�ǿ�ķ��������ͽ�ǿ�Ŀ�����������
�ؼ��ʣ�����ѧϰ������������磻³���ԣ��ලѧϰ
Foundation item: Project(21878081) supported by the National Natural Science Foundation of China; Project(222201917006) supported by the Fundamental Research Funds for the Central Universities, China
Received date: 2020-04-22; Accepted date: 2020-10-10
Corresponding author: YAN Xue-feng, PhD, Professor; Tel: +86-21-64251036; E-mail: xfyan@ecust.edu.cn; ORCID: https://orcid.org/ 0000-0001-5622-8686
Abstract: As a new neural network model, extreme learning machine (ELM) has a good learning rate and generalization ability. However, ELM with a single hidden layer structure often fails to achieve good results when faced with large-scale multi-featured problems. To resolve this problem, we propose a multi-layer framework for the ELM learning algorithm to improve the model��s generalization ability. Moreover, noises or abnormal points often exist in practical applications, and they result in the inability to obtain clean training data. The generalization ability of the original ELM decreases under such circumstances. To address this issue, we add model bias and variance to the loss function so that the model gains the ability to minimize model bias and model variance, thus reducing the influence of noise signals. A new robust multi-layer algorithm called ML-RELM is proposed to enhance outlier robustness in complex datasets. Simulation results show that the method has high generalization ability and strong robustness to noise.
