
���ڱպ�ģʽ�ĸ�ά��������������
�� �꣬�� �裬�� ���������ǣ�������
(���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ������ ��ɳ��410083)
ժ Ҫ��
ժ Ҫ����Զ����ά����������ص㣬���һ�ֻ��ڱպ�ģʽ�Ķ�������㷨CBCP�������ݴ�ֱ��ʽ�����ݼ�����·��ö�ٵķ����ھ�պ�ģʽ������ؼ���������ģʽ�IJ�����Ȼ�����бպ�ģʽ��������ͨ������ѵ������������������Է�������ʶ����������Ȩ���㷨�����жϣ��˷���ʹ��Default��Ԥ�ⲻ��ȷ�����⡣�о����������CBCP�뾭������㷨��CBA��C4.5��Ⱦ��и��ߵ�Ԥ��ȷ�ʣ������ڻ�����������Ӷ������������������Ծ��н�ǿ���ȶ��ԣ�֤��CBCP�Ŀ���չ��ǿ�������ڸ�ά���ݼ��Ķ������Ԥ�⡣
�ؼ��ʣ�
�����������պ�ģʽ���������Ȩ���㷨��
��ͼ����ţ�TP274 ���ױ�ʶ�룺A ���±�ţ�1672-7207(2008)05-1035-07
Multi-class classification of high-dimension gene expression profile based on closed patterns
LI Hong, LI Xiang, WU Min, CHEN Song-qiao, YI Li-jun
(School of Information Science and Engineering, Central South University, Changsha 410083, China)
Abstract: According to the characteristics of multi-class high-dimension gene expression profile, a new multi-class classification algorithm(CBCP) based on closed pattern was designed. Firstly an approach called path enumeration was proposed to mine closed patterns based on the vertical formatted data-table, which can reduce most redundant patterns. Then closed patterns were sorted and used to cover train dataset for building the classifier. The unrecognized samples were classified by weight algorithm, which can overcome the inaccuracy caused by using Default Class. The results show that the algorithm is proved to be more accurate than classical classification algorithms such as CBA and C4.5. CBCP keeps high accuracy when the number of genes increases substantially with the increase of number of samples fixed, which proves it is suitable for multi-class classification of high dimension datasets, and it is easy to extend.
Key words: association rules; closed pattern; multi-class; weight algorithm
��������ķ����������ھ������һ����Ҫ��ɲ��֣����� Agrawal������������ݿ���֪ʶ����(Knowledge discovery in databases��KDD)����Ҫ�о����⣬�ѹ㷺Ӧ�������ۡ����ա����м�ҽѧ���� ��[1-3]�������Bing��[4-8]�Թ��������ڷ��������е�Ӧ�ý������о���̽�֣�����ľ����㷨��CBA�ȡ���Щ�㷨�Ļ���˼�����������й��������ھ��㷨��������Ƶ����Ŀ��[5]����ʹ����ЩƵ����Ŀ�����������[4, 6]������ͬʱ�����������ԣ��ڵ�ά���ݼ��ϣ���ͬ�����ھ������ķ����㷨��ȣ������Ч�����á����ǣ���Զ����ά��������ķ������⣬����Ĺ�����������㷨��Ȼ����һЩ���㣺
a. �㷨���о��༯���ڶ�����о�[9-11]����������ݹ����������ȡ�ͷ���д���һ���о��� ��չ��
b. �㷨�ھ����Ƶ���������С֧�ֶ����ýϵ�ʱ��Ƶ��������������dz��Ӵ���ˣ�����������������������
c. ��ά���ݼ�����������������������������ص㣬���еľ�������㷨�����������ݼ�ʱ���ײ���Ԥ��ȷ�ʲ��ȶ��������
d. �㷨�����Լ�����ʶ�������ֱ�ӹ�Ϊijһ��Ĭ�����(Default class)��������������ȷ��
����Ƶ���պ�ģʽΩһ����������Ƶ�����ȷ֧�ֶȣ����ҹ�������Ƶ���С����������[4]���ڴˣ������������һ�ֻ��ڱպ�ģʽ�Ķ��������㷨CBCP(Classification based on closed patterns)���Ծ����㷨�ļ�������֮�����иĽ������Ƚ�n�����ݼ������ֳ�n���Ӽ�����Ը��Ӽ��ھ�Ƶ���պ�ģʽ��Ȼ�����еıպ�ģʽ��������������ѵ�������������������պ�ģʽ���ھ���û�����ö��˼���·��ö�ٷ�����ͨ�����м�������FP-tree[12]�ھ�պ�ģʽ��������㷨Ч�ʡ�����Ȩ�غ������Է�������ʶ���������Ȩ��ϵ����������жϣ��Ⱦ����㷨����ͳһĬ�����ķ�ʽ���и��ߵĿɿ��ԡ�CBCP�㷨��һ���µĶ�������ݵķ���������㷨���ڱպ�ģʽ�����Լ���ö�١�FP-tree�������ص�����ƣ�����˷����㷨��Ч�ʣ����н�ǿ�Ŀ���չ�ԡ�
1 ������������ض���
���ڱպ�ģʽ�Ķ�����������Զ���������ھ�պ�ģʽ������������ʵ�ֶ�δ֪��������ķ��������Է�Ϊ3����
a. �ھ�պ�ģʽ��
b. ������������
c. �Բ��Լ�����Ԥ�⡣
������ض������£��������ݼ�D��D�е�������ΪDi��IΪD��������ļ��ϣ�CΪ�������YΪ�����������AΪ��ļ���(�)��GΪ�����飬������֧�ּ�R���еļ��ϣ�����R(A)����D�а���A���м���SΪY��֧������supΪY��֧�ֶȣ�confΪY�����Ŷȡ�
����1��Y����������ʽ��Y: ![]() ��
��
����2��Y��֧����SΪD�а���A�����ΪC������������
����3 Y��֧�ֶȶ���Ϊ��
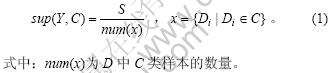
����4 Y�����Ŷȶ���Ϊ��

����5 ������![]() ������������������
������������������
a. ![]() ����ôD�а���Ai���м�
����ôD�а���Ai���м�![]() ��
��
b. ![]() ��������Ai���м�
��������Ai���м�![]() ����
����![]() ������G��
������G��
����6 G���ϱ߽�(upper bound)��G�е�һ�������������![]() ��Yu������������G��
��Yu������������G��![]() ��Ai��Au���Ӽ���
��Ai��Au���Ӽ���
����7 �A�DZպ�ģʽ������A�ij���![]() ��A��֧�������[13]����A��Ƶ���ģ����AΪƵ���պ�ģʽ��Ƶ���պ�ģʽΩһ����������Ƶ�����ȷ֧�ֶȣ����ҳߴ��Ƶ���С����������[3]��
��A��֧�������[13]����A��Ƶ���ģ����AΪƵ���պ�ģʽ��Ƶ���պ�ģʽΩһ����������Ƶ�����ȷ֧�ֶȣ����ҳߴ��Ƶ���С����������[3]��
����1 ����������![]() (AuΪG���ϱ߽�)���������֧�ּ�ΪR����AuΩһ�����ϱ߽���Ωһ�ġ�
(AuΪG���ϱ߽�)���������֧�ּ�ΪR����AuΩһ�����ϱ߽���Ωһ�ġ�
֤���������ϱ߽粻Ωһ���������һ���ϱ߽�![]() ��
��![]() ��A���A����
��A���A����![]() ����
����![]() ����
����![]() ����֪R(A��)=R����
����֪R(A��)=R����![]() ��
��![]() ����ˣ�Au����G���ϱ߽硣�Ӷ��ϱ߽��Ωһ��
����ˣ�Au����G���ϱ߽硣�Ӷ��ϱ߽��Ωһ��
2 CBCP�㷨�����ʵ��
2.1 Ƶ���պ�ģʽ���ھ�
���ô�ͳö�����������бպ�ģʽ���ھ��ǽ��н���ö����ϣ�����������������Ĺ�������÷��������������ݶࡢ�㷨Ч�ʵ͵����⡣���Ļ�����ö��(Row_FP)˼�룬��ϱպ�ģʽ�������ϱ� ��[13]������˸�����FP-tree��rt��������·��ö������·��ö���㷨�ھ�պ�ģʽ���������������ݵIJ����������㷨�Ĵ��������ǣ�
a. ������ֱ��ʽ�����ݼ���ÿ�����Ӧ���а���֧������С�������У�
b. ���ݴ�ֱ���ݼ�������FP-tree��rt����
c. ����rt�����Ե����ϵ�ÿһ�зֱ���·��ö���������ھ���պ�ģʽ��
��1��ʾΪˮƽ��ʽ�����ݼ���
��1 ˮƽ��ʽ�����ݼ�
Table 1 Horizontal formatted dataset

��2��ʾΪ��1�����ݼ��Ĵ�ֱ�ṹ��ʽ[14]�����䰴��FP-tree[1]�Ĺ��췽��ͨ��1��ɨ�轨����FP-tree��rt����������FP-tree���Լ�����Լ���Ӧ��֧��������FP-tree�нڵ㵽���ڵ��·�����ȼ�Ϊ�ýڵ��Ӧ���֧������ͬʱ������1��rt����ָ������FP-tree�а���ij����֧����������С֧���������н�㡣��FP-tree��rt���Ľ��������ͼ1��ʾ��
��2 ��ֱ��ʽ�����ݼ�
Table 2 Vertical formatted dataset

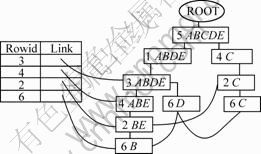
ͼ1 rt������FP-tree(��С֧����Ϊ3)
Fig.1 rt Table and row FP-tree (MinSup is 3)
����2 ��FP-tree�õ�����������걸�ġ�
FP-tree����ˮƽ�ṹ��������ھ���û����©���ھ�������[15]��ͬ������FP-tree��ȡ��ֱ�ṹ���м������ھõ��������Ҳ��û����©�ġ�
����rt���е��У�����ÿ��·������������Ͽɷ�Ϊ2�ࣺ
a. �ɶ���·����ͬ������ɵ�����ϣ�
b. ��������·������������ϡ�
���ڵ�1����ϣ����Ƕ�Ӧ��������а�������ϵ�·����Ӧ��IJ��������֧����Ϊ��ͬ�еĸ��������ڵ�2������ϣ�1��·�������еĴ�����϶�Ӧ��ģʽ��Ϊ��·����Ӧ�����
ͨ����rt�����Ե����ϵ�ÿһ�е�����·����ϸ���·��ö���㷨(Path enumeration algorithm, PEA)����1��·��ö����������rt����ָ�����FP-Tree�ڵ��֧��������������С֧�����Ľڵ�������ˣ����Լ���PEA�㷨������ģʽ�IJ�����·��ö������δ�����ڵ�������Ƶ���պ�ģʽ�������ϱ߽�Ķ��壬���䲢�����յıպ�ģʽ���С�PEA�㷨�������¡�
a. ����·��ö�����Ľڵ�ṹΪ��
![]()
���У�![]() ��ʾ�ڵ�i�����
��ʾ�ڵ�i�����![]() ��ʾ
��ʾ![]() ����FP-tree�еĹ�����·����
����FP-tree�еĹ�����·����
b. ��rt�����к���Ϊ·��ö�����ĸ��ڵ�(��0��)��
c. ��rt�����е�·��ָ��ָ�����FP-tree��n���ڵ�����·����Ϊ·��ö�����ĵ�1��ڵ㡣
d. �����·�������·��ö������w(w��ʼ��Ϊ2)��Ľڵ㣺
n=sum_node(w)�� // nΪw��Ľڵ����
if (n��2)
For i=1 to n-1
For j=i+1 to n
![]() ,
,
![]() ��
��
��Node��Ϊnode(i)���ӽڵ㣻
��֦��
End
End
End
e. w=w+1��ѭ��ִ�в���d����·��ö������
���������У�������3��������м�֦��
a. ��·�����PC1�Ĺ����м�����·�����PC2�Ĺ����м�����ͬ��PC1������·����������PC2������·����������PC2�����Ĺ����м��ϲ����ϱպ�ģʽ�Ķ��壬��PC2ɾ����PC1��PC2ö�ٵĽ����ΪPC1���ӽڵ㡣
b. ��ÿ��·����ϼ��㹫���е���Ŀ������ĿС����С֧���������·����ϱ�ɾ����
c. ��·��ö������·�����PC1�õ���ģʽA��ǰ����ھ����Ѿ����ڣ���ɾ��ģʽA��
ͼ2��ʾΪ��6������֦���·��ö������

ͼ2 ��6��·��ö����(��С֧����Ϊ3)
Fig.2 Path-enum-tree of row 6 (MinSup is 3)
2.2 ����������
�������Ĺ�����ȫ�㷨�Ĺؼ����֣�ѡ��ķ�����������ֱ��Ӱ�쵽�������ķ���Ԥ��ȷ�Ժ��㷨��Ч�ʡ��������������ھ��������Ƶ���պ�ģʽ�Ļ����ϣ����Ҽ����������Ϣ��
�������ݼ�D��T��T �� �ֱ�Ϊˮƽ��ʽ�ʹ�ֱ��ʽ��ѵ���������������Ϊn��������С���Ŷ�MinConf����С֧����MinSup��CBCP�㷨������������ʾ��
a. ��T�����ֽ�ΪT1, T2, ��, Tn�����У�nΪT�е��������
b. For c=1 to n
ɨ��Tc��������FP-tree��rt����
���rt������·��ö�������ھ�պ�ģʽ����Uc��
end
c. ��![]() ��
��
d. ��U���õ�U�䡣
e. ʹ��U���T �� ����Ԥ���Խ�������������U����ȡ��Y������T �� ������Y��������i����i��0����Y���������l�У�����Y��U����������Y�����������T �� ��������U��������Y�����ٸ���T �� �е�����һ������������ʱ��l��Ϊ���յķ�����L��
�㷨�в���a��ѵ�����ֽ�ɻ�����ϵ�n�����֣�����b����ͨ�����еķֲ�ʽ����ھ���ʵ�֣�������㷨������Ч�ʡ�
�㷨�в���d����������������ԭ���������
a. ��U�е�Y����conf�������У�ɾ�����е���MinConf��Y��
b. ��2��Y��conf��ͬ������sup�������У�
c. ��2�������conf��sup����ͬ������֧����![]() �������У�
��������
d. ��2�������conf��sup��![]() ����ͬ�����չ���������Ⱥ�˳�����С�
����ͬ�����չ���������Ⱥ�˳�����С�
e. �������ϲ��������������2����������ȫ��ͬ����ɾ������Ĺ���
ʹ�����շ�����L�Բ��Լ�����Ԥ�⣬����Ԥ�����������Ȩ���㷨(Weight Algorithm, WA)�����жϡ�WA���������£�
a. ��ʼ��Ȩ�ؾ���![]() ��ֵΪ0�����У�nΪ�����������mΪ�����������
��ֵΪ0�����У�nΪ�����������mΪ�����������![]() (i=1, ��, m)��ʾ��i���id��
(i=1, ��, m)��ʾ��i���id��
b. ��T �� �е�i(i=1, ��, m) �������Ϊc(c=1, ��, n)������������Ϊ����c���Ȩ��![]() ���õ�Ȩ�ؾ���
���õ�Ȩ�ؾ���![]() ��
��
c. ����![]() �����¹�ʽ�ֱ�����������s�����Ȩ��SWc��
�����¹�ʽ�ֱ�����������s�����Ȩ��SWc��

H(i)�Ķ������£�
![]() (4)
(4)
d. ѡ������SWC(![]() )���ڵ����c��Ϊs�����
)���ڵ����c��Ϊs�����
��Ϊѵ�����и����������ֵĴ�����һ����ͬ��T �� ��ÿ����������Ȩ��֮�Ͳ�����ȣ����dzʱ�����ϵ����ˣ�����ֱ��ͨ���Ƚϴ������������Ȩ�غʹ�С���ж��������Ȩ��ϵ�������˸���������T �� ����ռ�ı�����
3 ʵ�����������Ƚ�
3.1 ������Դ������Ԥ����
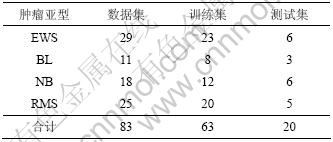
����ʵ��ʹ�õ���СԲ��ϸ��(SRBCT)���� ��[15]�������ݼ�����4�����ͣ�ÿ��������2 308������������ɡ����ݼ��Ļ������3��ʾ��
��3 SRBCT��������
Table 3 Sample partition of SRBCT
���ȣ�ʹ�û���GBָ��(Giniָ��������Bhattacharyya���빹�����ۺ�ָ��)��Euclidean��������ݼ��ػ���������������������Ϣ�����ߵ���Ϣ������Ϊ���ݼ�D��ʹ����Ϣ������й���������ھ����ϻ�����������ݷ�������Ҫ��ͬʱ�������ڽ����������ݶ�CBCP�㷨����ȷ�Եĸ��š�Ϊ֤���㷨���ڸ�ά���ݼ��������ԣ������Զ�δ���������������ݼ����з���Ԥ�⡣
3.2 ʵ���������
��VC++ 6.0��CBCP�㷨���в��ԡ���������Ϊ������ȫT200������������Ϊ����ϵͳΪWindows2000 Server��CPUΪIntel Xeon 2.4GHz���ڴ�Ϊ512MB��
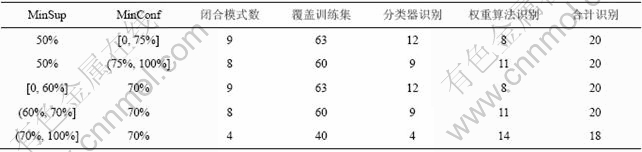
����CBCP�㷨��SRBCT���ݼ�����Ԥ��������62��������������ݼ����Ը����ݿ���з����Ԥ�⣬��������4���ɼ�����MinSup�̶���MinConf����һ����ֵʱ(��62������ʱMinConfΪ75%)�����ߵ�MinConf�̶���MinSup����һ����ֵʱ(��62������ʱMinSupΪ60%)����������Ԥ��ȷ�ʴﵽ��ߡ�����MinSup��MinConf�ļ�С������ıպ�ģʽ���࣬�����շ������еĹ��������䣬����Ӱ���������Ԥ��ȷ�ʡ���MinConf��MinSup������ֵʱ����Ч�Ĺ��������٣���ʶ������������ӣ����·�������Ԥ��ȷ�ʽ��͡���ȻȨ���㷨�ǶԷ���������Ч���䣬������Ԥ���������ʶ��IJ��Լ����������ӷ�������������˵��֧�ֶȺ����Ŷ�Ӧȡ�ܹ��������ѵ��������ʱ�IJ���ֵ��
��4 MinSup�̶�����MinConf�̶������CBCP�㷨��ʵ����(62����)
Table 4 Results of CBCP with fixed MinConf or fixed MinSup (62 gene)
��5��ʾΪ����CBCP�㷨��7��40��62��82����������ݼ������ŷ���Ԥ�������ɼ�����֧�ֶȺ����Ŷ�ȡֵ�ʵ�ʱ������CBCP�㷨������ģ�Ϳ���100%ʶ��ѵ�����Ͳ��Լ�������������˵��CBCP�㷨������ά����Խϵ͵����ݼ���
��5 MinSup��MinConf���������CBCP�㷨��ʵ����( MinSup=60%,MinConf=50%)
Table 5 Results of CBCP with Best MinSup and MinConf when MinSup=60% and MinConf=50%

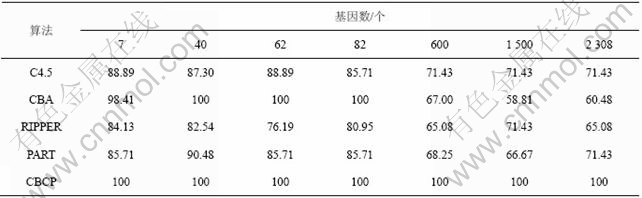
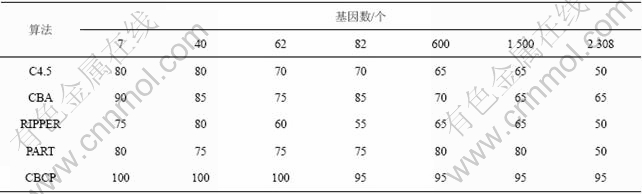
��6�ͱ�7��ʾΪ��Բ�ͬ������ʹ��CBCP�㷨�;�������㷨����Ԥ��Ľ���Ƚϡ��ӱ�6�ɼ�������CBCP�ж��ڱպ�ģʽ��������ǵķ�����������ķ�����ʼ�տ�����ȫ����ѵ�������������ľ�������㷨�ڻ���������1��������ʱ����ѵ�����ĸ���ȷ����һ���̶ȵĽ��͡��ӱ�7�ɼ������ڲ��Լ���Ԥ�⣬���ڻ��������ӣ���������Է����㷨��Ԥ�⾫�Ȳ�����һ���ĸ��ţ�CBCP�㷨Ԥ��ȷ�ʲ���Ϊ100%�����ǣ��Ա������������������㷨�Ľϸ�ȷ�ʣ�˵�����������ͻ����������������£����㷨��Ԥ��ȷ�ʽ��ȶ�������Ȩ���㷨��������Ҫ�����á�ʵ������ֱ�����CBCP�㷨�Ը�ά������������ݼ�����Ԥ��������ԺͿ���չ�Ըߡ�
��6 ��ͬ�㷨��ѵ������Ԥ��ȷ��
Table 6 Accuracy of different algorithms on training datasets %
��7 ��ͬ�㷨�ڲ��Լ���Ԥ��ȷ��
Table 7 Accuracy of different algorithms on test datasets %
4 �� ��
a. ���һ�ֻ��ڱպ�ģʽ�Ķ�������㷨CBCP�����ڽ����ά��������Ķ���������⡣���㷨���������ŵ㣺
1) ʹ��·��ö�ٵķ����ھ�պ�ģʽ�������ھ����������ģʽ��
2) ��Ƶ���պ�ģʽ��Ϊ�������������˷��˾�����������㷨��CBA����Ƶ�����Ϊ�������������ܵ��µĹ������������Ӵ�����⡣
3) �Է�������ʶ�����������Ȩ���㷨�����жϣ����Ƚϸߡ�
b. ͨ����СԲ��ϸ��(SRBCT)���ݼ��ķ���Ԥ�⣬֤����CBCP�㷨������ά���ϵ͵Ķ������ݼ����нϸߵ�Ԥ��ȷ�ʣ����Ҷ��ڻ�������������Ӷ����������ֲ���ĸ�ά���������ݼ���CBCP�㷨�Ծ�������������������㷨��Ԥ��ȷ�ʣ����˵��CBCP�Ը�ά������������������������Ժ��㷨�Ŀ���չ�ԡ�
�ο����ף�
[1] HAN Jia-wei, Kamber M. Data mining: Concepts and techniques[M]. Beijing: Higher Education Press, 2001: 10-20.
[2] Doug B, Johannece G, Manuel M. MAFIA: A maximal frequent itemset algorithm for transactional databases[C]//Proceedings of the 17th International Conference on Data Engineering. German: Heidelbergt, 2001: 443-452.
[3] Bastide Y, Pasquier N, Taouil R. Discovering frequent closed itemsets for association rules[C]//Proceedings. of the 7th International Conferenece on Database Theory. Jerusalem: Springer-Verlag, 1999: 398-416.
[4] Bing L, Wayne S, Yiming M. Integrating classification and association rule mining[C]//Proceedings of the 4th International Conference on Knowledge Discovery and Data Mining. New York: AAAI Press, 1998: 80-86.
[5] LI Wen-min, HAN Jia-wei, PEI Jian. CMAR: Accurate and efficient classification based on multiple class association rules[C]// Proceedings of IEEE International Conference on Data Mining. San Jose: CA, 2001: 369-376.
[6] �� ��, �Ž���, ������. �ֲ�ʽ���ݿ�Լ���Թ��������ھ�[J]. ���ϴ�ѧѧ��: ��Ȼ��ѧ��, 2004, 35(6): 998-1003.
LI Hong, DU Jian-feng, CHEN Song-qiao. Mining association rules with item constraints in distributed database[J]. Journal of Central South University: Science and Technology, 2004, 35(6): 998-1003.
[7] ������, ½����, ������. ����ģ�������������ķ���ϵͳ[J]. ������о��뷢չ, 2003, 40(5): 651-656.
ZOU Xiao-feng, LU Jian-jiang, SONG Zi-lin. A classification system based on fuzzy class association rules[J]. Journal of Computer Research and Development, 2003, 40(5): 651-656.
[8] Thabtah H, Cowling P, Yonghong P. MMAC: A new multi-class, multi-label associative classification approach//Proceedings of IEEE International Conference on Data Mining. Brighton, 2004: 217-224.
[9] Lim T, Weiyin L. A comparison of prediction accuracy, complexity and training time of thirty-three old and new classification algorithms[J]. Machine Learning, 2000, 40: 203-228.
[10] Quinlan J. C4.5: Programs for machine learning[M]. San Francisco: Morgan Kaufmann, 1993: 56-89.
[11] YIN Xiao-xin, HAN Jia-wei. CPAR: Classification based on predictive association rule[C]// SDM 2003. San Francisco: CA, 2003.
[12] MAO Run-ying, HAN Jia-wei, PIE Jian. CLOSET: An efficient algorithm for mining frequent closed itemsets[C]//Workshop on Data Mining and Knowledge Discovery. Dallas: ACM Press, 2000: 21-30.
[13] Zaki M J. CARPENTER: Finding closed patterns in long biological datasets[C]//Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Washington, 2003: 413-419.
[14] Zaki M, Hsiao C. CHARM: An efficient algorithm for closed itemset mining[C]//Proceedings of the 2nd SIAM International Conference on Data Mining. Arlington: SIAM, 2002: 12-28.
[15] Khan J, Wei J. Ringner M. Classification and diagnostic prediction of cancers using gene expression profiling and artificial neural networks[J]. Nat Med, 2001, 7(6): 673-679.
�ո����ڣ�2007-11-25�������ڣ�2008-01-20
������Ŀ�����ҽܳ������ѧ����������Ŀ(60425310)�����ϴ�ѧ��ʿ�����������Ŀ(2008)
ͨ�����ߣ��� ��(1966-)���У����ϳ�ɳ�ˣ����ڣ���ʿ���������ھ�ģʽʶ����źŴ����������绰��13575892566��E-mail: lihongcsu@mail.csu.edu.cn
