
J. Cent. South Univ. Technol. (2011) 18: 1097-1104
DOI: 10.1007/s11771-011-0809-0![]()
Introducing semantic information into motion graph
LIU Wei-bin(��μ��)1, 2, LIU Xing-qi(������) 1, 2, XING Wei-wei(��ޱޱ)3, YUAN Bao-zong(Ԭ����)1, 2
1. Institute of Information Science, Beijing Jiaotong University, Beijing 100044, China;
2. Beijing Key Laboratory of Advanced Information Science and Network Technology,
Beijing 100044, China;
3. School of Software Engineering, Beijing Jiaotong University, Beijing 100044, China
? Central South University Press and Springer-Verlag Berlin Heidelberg 2011
Abstract:
To improve motion graph based motion synthesis, semantic control was introduced. Hybrid motion features including both numerical and user-defined semantic relational features were extracted to encode the characteristic aspects contained in the character��s poses of the given motion sequences. Motion templates were then automatically derived from the training motions for capturing the spatio-temporal characteristics of an entire given class of semantically related motions. The data streams of motion documents were automatically annotated with semantic motion class labels by matching their respective motion class templates. Finally, the semantic control was introduced into motion graph based human motion synthesis. Experiments of motion synthesis demonstrate the effectiveness of the approach which enables users higher level of semantically intuitive control and high quality in human motion synthesis from motion capture database.
Key words:
1 Introduction
In the past decade, the computer generated virtual humans have become ubiquitous in numerous applications. As an integral key part of these application systems, realistic virtual human motion enables virtual characters to be life-like and helps create a sense of immersion. Synthesizing realistic motions of virtual human that mimic the complicated human motion processes and reproduce life-like actions in virtual environment has been a difficult challenge and under active research in the areas of computer science and technology industry. Over the last decade, many efforts have been made in researches from different disciplines.
To obtain realistic human motion, keyframing is the most traditional approach which gives animator the ultimate control over every detail of the motion. However, it requires special artistic talents and skills to create natural looking motions with keyframing manually based on the observation and knowledge of human motion, and the technique is, of course, very time and effort intensive. Moreover, the animation produced may not follow physical laws.
Physically based motion synthesis methods usually build an internal rigid body model of the synthetic actor combined with control systems under the laws of motion to generate motion trajectories. Controllers have been successfully designed for specific human motions. Most of them generate physically based human animations using proportional-derivative controllers (PD controllers) that were either manually designed and hand tuned or relied on optimization with energy-minimizing objectives. Although physically based synthesis can be applied to simple motion simulation system successfully, it is difficult to be implemented for generating realistic motion of human characters which is a high dimensional and highly nonlinear dynamic system. The key issues with physically based techniques for interactive environments have been of high computational costs and provided the appropriate amount of high-level control. In addition, physical correctness does not guarantee motion naturalness. Though some of those controllers are very robust, they tend to result in stereotyped gaits often looking robotic and lifeless.
In recent years, as a reliable way for digitally acquiring three-dimensional human motion, motion capture is becoming increasingly popular in a wide range of applications. The growing availability and increasing variety of motions recorded with motion capture technology have spurred researches on data-driven approach which focuses on ways to improve the utility of motion capture data and synthesize motion streams based on an existing corpus or database of captured human movements. Inspired by the video textures work of SCH?DL et al [1] of synthesizing seamless video streams from short clips and driving these streams according to high-level user input, motion graphs were developed simultaneously by several research groups [2-4] in 2002. KOVAR et al [2] developed a novel method called ��motion graph��, which is a directed graph where edges represent clips of motion and nodes indicate places where different clips can connect, and new motions can be created simply by traversing the graph. ARIKAN and FORSYTH [3] used a randomized global search over a hierarchy of motion graphs to obtain motions subjected to a variety of user specified constraints. LEE et al [4] also combined motion graphs with clustering and employed a local search algorithm to generate motions at interactive rates which enable real-time control of the avatar. A number of methods to augment motion graphs have been proposed in subsequent years [5-9]. The interpolated motion graph introduced by SAFONOVA and HODGINS [5] was created by combining two identical standard motion graphs, which was explored to blend paths within the graph in order to produce more accurate and natural motions. IKEMOTO et al [6] created quick (1 s long) transitions between all frames in the motion capture database by interpolating existing motion segments. TREUILLE et al [7] introduced reinforcement learning into motion graphs for real-time character animation with multidimensional and interactive control. ZHAO et al [8] used interpolation of motion segments of the same contact to add additional data to the database, which allowed for better connectivity between behaviors. REN et al [9] presented an approach to motion synthesis based on combining continuous constrained optimization useful for generating short motions with graph-based motion synthesis useful for generating long motions. Motion graph is becoming increasing popular because of its simple graph structure, ability to generate long motion, and fully automatic solution to motion synthesis problem. The key to generate long streams of motion is able to locate frames of motion in motion database that should be similar enough to be used as the most natural transition points between different motion clips in motion graph. A suitable similarity measure plays an important role in motion graph based synthesis, which requires not only the identification and extraction numerically similar but also the semantically related motions scattered within the motion database.
However, the notion of ��similarity�� used to compare different motions is ill-defined which depends on the respective application circumstances or on a person��s perception [10-11]. Typically, the similarity measure of motions should be invariant to spatial global transformation or temporal scaling and identify the motions which differ only in certain global transformations, size of skeleton or overall speed of motions. A more complex problem in similarity measure of motions is that semantically similar motions may be numerically dissimilar which have very different skeletal poses and different motion styles due to the performance, the emotional expression or mood, and the complex individual characteristics of motion��s performer. Even worse, numerical similarity does not necessarily imply semantic similarity. In addition, differences between semantic and numerical similarity can also be due to partial similarity where only the movement of certain body parts is concerned in similarity measure. Most existing methods of motion graph based synthesis are based only on numerical similarity measure in motion analysis, which cannot identify the semantically similar motions in the presence of significant spatial and temporal variations for detecting transitions in building motion graph.
In this work, we focus on introducing semantic control into motion graph based synthesis, which enables users higher level of intuitive semantically control to improve the efficiency, flexibility, accuracy and controllability in synthesizing high-quality realistic motions from mocap database. For this end, relational features are implemented for describing and specifying motions at a high semantic level to cope with spatial variations within a class of semantically similar motions. Motion templates are then automatically derived from the training motions for capturing the spatio-temporal characteristics of an entire given class of semantically related motions. Automatic semantic annotation is performed on the unknown motion data document by identifying the presence of certain motion class from matching their respective motion class templates. Finally, the semantic control is introduced into motion graph based human motion synthesis.
2 Hybrid motion features extraction
There are many ways to generate motion capture data or simple mocap data. Motion capture data can be considered as high-dimensional time-series where each time instant holds a pose of the character equivalent to a keyframe of the traditional animation, and each dimension represents different degrees of freedom (DoF) of the character. In the present work, Biovision hierarchical data (BVH) mocap file format is implemented.
2.1 Numerical features
Since BVH files usually only contain the Euler angles, other numerical features may be derived from the basic Euler angles representation. Following that numerical features are implemented, including quaternion rotations, joint spatial coordinates, joint velocity, and joint angular velocity.
2.2 Semantic relational features
In the present work, relational features are implemented as a powerful tool in describing and specifying motions at a high semantic level to cope with spatial variations within a class of semantically similar motions. Based on human cognition of similarity metric in motion category, relational features only focus on certain aspects of a respective pose which retain the important characteristics regarding the given motion type, and discard a lot of other detail variances contained in the raw motion data. Relational features can absorb spatio-temporal variations on the numerical feature level and allow for a more robust and efficient comparison of semantically related motions which are invariant under global orientation and position, size of the skeleton, and local spatial deformations of a pose. Through user-specified combinations of these qualitative relational features, we can get a specific set of semantically rich features for describing meaningfully the overall configurations of poses within a given motion class. Thirty-nine relational features have been defined in Ref.[10], and users may select and combine different features of them according to the characteristics of the motion types.
3 Motion similarity measurement
3.1 Euclidean frame-wise similarity measurement
We represent the similarity metric by a distance function Di, j, where i and j are two frames of poses, and the smaller the value is, the more similar they are. To measure the similarity between two frames of motion, a distance metric is implemented as Eq.(1), which extends the distance metric introduced by LEE et al [4] by taking into account of the semantic relational features when measuring frame-wise similarity:
![]() (1)
(1)
where d(pi, pj) describes the weighted differences of joint orientations, d(vi, vj) represents the weighted differences of joint velocities, and d(ri, rj) describes the weighted differences of generic relational features defined by user selection. Parameters FP, FV, FR weight the different significance of the corresponding features in measuring frame-wise similarity. In the comprehensive measure of similarity between two frames, the velocity term helps preserve the inherent dynamic characteristics of motion and the generic relational features term enables users to intuitively identify the semantically meaningful similarity measurement of motions. For computing d(pi, pj) and d(vi, vj), weights associated with joints are introduced to take into account of the different significances of the influence of each joint rotation on the overall skeletal hierarchy. We set the joint weights following the work of Ref.[12].
3.2 Dynamic time warping-based sequence-wise similarity measurement
Although Euclidean distance can be calculated efficiently on multidimensional time-series due to its easiness of implementation and computational efficiency, it usually does not perform well in measuring similarity of motion sequence. The drawback of Euclidean metric is its incapability in coping with time deformations and different speeds associated with time-dependent motion sequence data, for example, two motion sequences could be very similar, but not perfectly synchronized [11].
As opposed to Euclidean distance, dynamic time warping (DTW) [13] constitutes an important tool widely used in the analysis and synthesis of motion data. DTW computes the global distance of similarity between two motion sequences, where the Euclidean frame-wise similarity metric Di,j acts as the local distance measurement. The goal of DTW is to find the path W that minimizes the cumulative sum of local distances along similarity matrix between two motion sequences, which is accomplished by dynamic programming (DP). Several constraints are exercised on searching the optimal path W since the number of possible warping paths grows exponentially with the length of time-series. The number of potential paths can be further reduced by applying the windowing condition [13] on local distance calculations and path searching.
4 Semantic annotation of motions
Motion template (MT) [14] method has been implemented for semantically annotating an unknown motion data document in which the presence of certain motion classes like walking, running, jumping, etc. at certain time is detected and annotated. With automatic annotation, the consecutive, semantically related frames are organized into groups and user-specified semantic motion type description is added into the raw mocap data.
4.1 Motion templates construction
Motion template is a generalized boolean feature matrix derived from a class of training motions, which is an efficient way for capturing the spatio-temporal characteristics of an entire class of semantically related motions into a compact and explicit matrix representation. Motion template semantically captures the consistent as well as the inconsistent aspects of all motions in the class. The consistent aspects of motion template represent the class characteristics that are shared by all motions, whereas the inconsistent aspects represent the class variations due to different realizations. Eight motion classes are defined in the present experiments, including walking, running, jumping, punching, etc., which may be expanded according to the application requirements. Motion template of a motion class is derived based on a self-learning procedure as follows.
Given a set of N example training motions D of a specific motion class, a set of selected relational features is extracted from the data stream of each training motion D : [1, Kj], j![]() [1, N], and forms a binary feature matrix Y
[1, N], and forms a binary feature matrix Y![]() for each motion, where f is the dimension of the selected relational features and Kj is the length of the j-th training motion data. So we get initial motion templates
for each motion, where f is the dimension of the selected relational features and Kj is the length of the j-th training motion data. So we get initial motion templates ![]() for N training motions. Each row of a motion template (MT) corresponds to one relational feature, and each column corresponds to the real time duration of one frame.
for N training motions. Each row of a motion template (MT) corresponds to one relational feature, and each column corresponds to the real time duration of one frame.
By a combination of warping and averaging operation of the MTs of N training motions, the class M is computed as follows for expressing the essence of an entire class of training motions, which is intuitively a semantically meaningful average over the N training motions within the same class.
First, due to the different length and temporal structure of the N training motions, dynamic time warping is applied for temporally aligning the N MTs to agree in length and temporal structure prior to arithmetic averaging operations. Now all the MTs have the same length, and each is associated with a weight vector to keep track of the time-scale contracting and stretching operations during the temporal alignment. Then, compute the weighted average over all the N aligned MTs in a column wise fashion and get the average MT and average the weight vector which constitutes a combined representation of all the N training motions. Finally, unwrap the average MT according to the average weight vector to get the class motion template.
In addition, an iterative averaging procedure is implemented [11,14] for eliminating the bias of class motion template caused by the influence of the selection of reference MT during temporal alignments. Figure 2 shows the final motion class template of training motions in Fig.1.
4.2 Semantically annotating motion documents
Now we get the motion templates of each motion class after the self-learning procedure. To semantically annotate an unknown motion data document, we need to identify the presence of certain motion class at certain time of the motion document by matching the unknown motion data stream with each of the class motion templates. Each local minimum of the matching close to zero or below a suitable threshold, like 0.1, indicates a motion subsegment of the stream that belongs to the corresponding motion class[15].
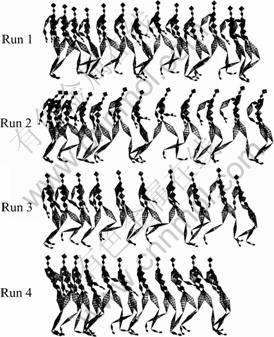
Fig.1 Training motions for generating motion templates

Fig.2 Motion class template of training motions in Fig.1
First, for template matching, a quantized class motion template Mq is defined by replacing each entry of the class motion template below a suitable preset threshold by zero, each entry above ��![]() [0, 0.5] by one, and all remaining entries by 0.5, as shown in Fig.3.
[0, 0.5] by one, and all remaining entries by 0.5, as shown in Fig.3.
Then, a local cost measure between the feature matrixes of the unknown motion stream and a given class motion template is defined which only accounts for the consistent entries of quantized motion template with value of zero or one, and leaves other inconsistent entries unconsidered. The distance function of class matching motion template to motion stream can be computed by the subsequence DTW. We assume that the unknown subsequence to be identified can be three-times longer or half-times shorter than the respective class motion template to cope with the speed variance within a motion class.
Finally, every local minimum of the distance function close to zero or below a suitable threshold indicates a subsegment of unknown motion document that belongs to the respective motion class. If the distance functions of multiple motion classes are below the threshold for a subsegment, the class with the minimum distance function value is selected and labeled. The related subsegments are semantically labeled through the identification of the corresponding motion class, as illustrated in Fig.4.
5 Introducing semantic control into motion graph based synthesis
5.1 Building motion graph
Motion graphs provide a framework for motion
synthesis of motion capture data, which have the potential to make use of the existing motion sequence to synthesize a wide variety of new motions in response to user control. A standard motion graph is a directed graph formed from a set of motion clips in the database of motion capture data by adding the additional transitions between frames of motion capture data. Once the motion graph is constructed, users can generate the desired motion by randomly searching the graph for an optimal path that is an ordered sequence of motion frames connected by the motion transitions meeting the constraints of user��s control. One common criterion for selection of transitions is that the similarity measurement between two candidate frames of motion sequence is below a certain threshold.
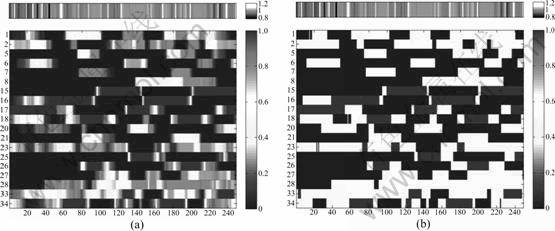
Fig.3 Quantized class motion template (��=0.1): (a) Class motion template; (b) Quantized class motion template
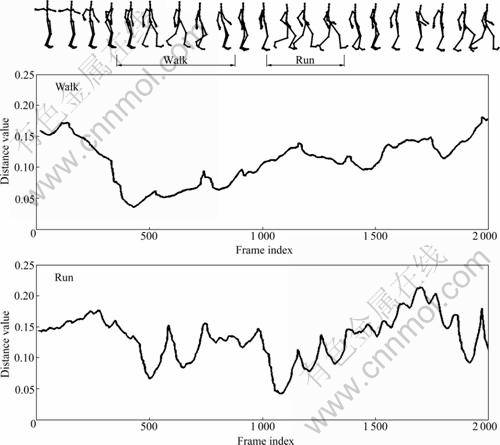
Fig.4 Automatic annotation of mocap document
5.2 Hybrid motion graph based synthesis with semantic control
Both semantic motion class annotation of motion data document and semantic relational features extracted from motion stream may be implemented for user��s semantic control in motion graph based synthesis. The weight of semantic control in motion synthesis relative to the numerical feature determination may be set by the user according to his task needs. If the user wants the precise vocabulary definition in synthesis that requires completely controlling the motion class types and transition path of the intermediate motion segments, he may set a much higher weight for semantic control part; if the user primarily concerns the smoothness quality and minimum numerical frame-wise difference of transition and no clear-cut motion class prerequisite for synthesis, he may set a much lower weight for semantic control part while a higher weight for numerical feature determination. In addition, motion annotation could be a meaningful reference in synthesis for avoiding the transitions happening between motions of two completely unrelated motion classes. Let Xsemantic be the semantic metric and Xnumerical be the numerical metric of similarity measurement in motion synthesis, we set the total similarity measure Xtotal as
Xtotal=wXsemantic+(1-w)Xnumerical (2)
where w![]() [0, 1] denotes the weight of semantic control in synthesis relative to numerical feature determination.
[0, 1] denotes the weight of semantic control in synthesis relative to numerical feature determination.
5.3 Generating motion transitions
Motion transitions in motion graph based synthesis are generated as follows [16].
First, the transition point between two connected sequences is determined. Let P and Q be the sequences to be synthesized, we construct a probability matrix M(P, Q), where the (i, j)-th element, M(Pi, Qj), is the probability of motion transitioning from frame i to frame j. The Euclidean frame-wise similarity metric Di,j in Eq.(1) is implemented as the distance metric for computing transition probability from frame i to frame j.
Then, the blend length of transition between two connected sequences is computed by using the geodesic distance method [16] based on the assumption that a transition will be smooth if two windows of the motion sequence to be blended have strong correspondence. We calculate the cost for blending within a feasible range of blend length, like 1-60 frame, and pick up the best blend length with minimum cost.
With the obtained best transition point and blend length, we can generate the transition between two motions using linear blending. Figure 5 shows an example of motion transitions.
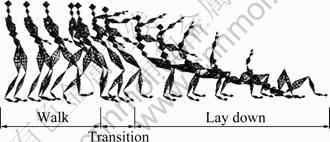
Fig.5 Example of motion transitions
6 Results and discussion
A prototype system of motion graph based human motion synthesis has been developed in the present work, which mainly integrates functions of motion editing, motion class template training, motion annotation, motion graph building, interactive motion synthesis, and so on. Figure 6 shows the interface of the prototype system.
Figures 7 and 8 shows two comparative experiments of motion graph based motion synthesis. The above example of Fig.7 shows the motion synthesized from motion graph without semantic control, which mainly considers the similarity of numerical features like pose and velocity in generating motion transition. Between the two user-selected walk motion clips for synthesis, a run motion is embedded as transition motion, as shown in Fig.7(a). The below example shows the motion synthesized from motion graph with semantic control, which considers both the similarity of numerical features and semantic descriptions in motion clips. A direct transition between two walk motion clips is produced by user��s semantic restriction of walk motion type in synthesis, as shown in Fig.7(b). The above example of Fig.8 does not employ the semantic control. Between the two user-selected punch and walk clips for synthesis, a run motion is embedded as transition motion, as shown in Fig.8(a). The below example shows the synthesis result with semantic control of user��s limitation on motion types. A direct transition between two selected motion clips is produced by user��s semantic restriction in synthesis, as shown in Fig.8(b). Experimental results of motion synthesis show that introducing user��s higher level of semantically intuitive control into motion graph based synthesis may effectively improve the control flexibility, accuracy, quality, and computation efficiency of synthesis.
Fig.6 Prototype motion synthesis system
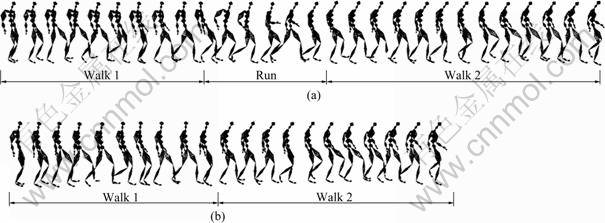
Fig.7 Motion synthesis experiment of comparison 1: (a) Synthesis experiment without semantic control; (b) Synthesis experiment with semantic control
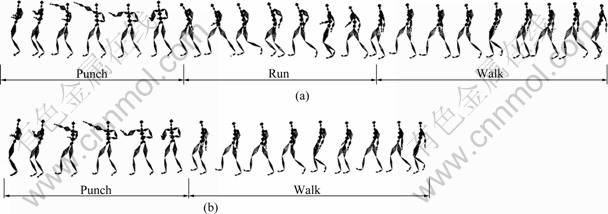
Fig.8 Motion synthesis experiment of comparison 2: (a) Synthesis experiment without semantic control; (b) Synthesis experiment with semantic control
7 Conclusions
1) Hybrid motion features including both numerical and user-defined semantic descriptions are extracted for encoding characteristic aspects contained in the character��s poses of the given motion sequence in mocap database. Motion templates are then automatically derived from the training motions for capturing the spatio-temporal characteristics of an entire given motion class of semantically related motions.
2) The motion data streams are automatically annotated by certain motion classes as semantic labels through identification with their respective class motion templates.
3) Motion graph is built on the semantically labeled motion sequence, which enables users the semantic control of motion synthesis. Experiments of motion synthesis demonstrate the effectiveness and controllability of the approach proposed in synthesizing high-quality realistic motions from mocap database.
References
[1] SCH?DL A, SZELISKI R, SALESIN D H, ESSA I. Video textures [C]// ACM SIGGRAPH 2000. New Orleans: ACM Press, 2000: 489- 498.
[2] KOVAR L, GLEICHER M, PIGHIN F. Motion graphs [C]// ACM SIGGRAPH 2002. San Antonio: ACM Press, 2002: 473-482.
[3] ARIKAN O, FORSYTH D A. Interactive motion generation from examples [C]// ACM SIGGRAPH 2002. San Antonio: ACM Press, 2002: 483-490.
[4] LEE J, CHAI J, REITSMA P S A, HODGINS J K, POLLARD N S. Interactive control of avatars animated with human motion data [C]// ACM SIGGRAPH 2002. San Antonio: ACM Press, 2002: 491-500.
[5] SAFONOVA A, HODGINS J K. Construction and optimal search of interpolated motion graphs [C]// ACM SIGGRAPH 2007. San Diego: ACM Press, 2007: 106.
[6] IKEMOTO L, ARIKAN O, FORSYTH D. Quick transitions with cached multi-way blends [C]// ACM Symposium on Interactive 3D Graphics 2007. Seattle: ACM Press, 2007: 145-151.
[7] TREUILLE A, LEE Y, POPOVIC Z. Near-optimal character animation with continuous control [C]// ACM SIGGRAPH 2007. San Diego: ACM Press, 2007: 7.
[8] ZHAO L, NORMOYLE A, KHANNA S, SAFONOVA A. Automatic construction of a minimum size motion graph [C]// ACM SIGGRAPH/Eurographics Symposium on Computer Animation. New Orleans: ACM Press, 2009: 27-35.
[9] REN C, ZHAO L, SAFONOVA A. Human motion synthesis with optimization-based graphs [J]. Computer Graphics Forum (Eurographics 2010), 2010, 29(2): 545-554.
[10] M?LLER M, R?DER T, CLAUSEN M. Efficient content-based retrieval of motion capture data [C]// ACM SIGGRAPH 2005. Los Angeles: ACM Press, 2005: 677-685.
[11] M?LLER M. Information retrieval for music and motion [M]. Secaucus: Springer-Verlag New York, Inc., 2007: 184-296.
[12] WANG J, BODENHEIMER B. An evaluation of a cost metric for selecting transitions between motion segments [C]// ACM SIGGRAPH/Eurographics Symposium on Computer Animation. San Diego: ACM Press, 2003: 232-238.
[13] CARDLE M. Automated motion editing [R/OL]. Cambridge, UK: Computer Laboratory, University of Cambridge, (2004-5)/[2007-1]. http://www.cardle.info/lab/Cardle-Mocap-Matching-techreport-2004. pdf
[14] M?LLER M, R?DER T. Motion templates for automatic classification and retrieval of motion capture data [C]// ACM SIGGRAPH/Eurographics Symposium on Computer Animation. Vienna: ACM Press, 2006: 137-146.
[15] M?LLER M, BAAK A, SEIDEL H P. Efficient and robust annotation of motion capture data [C]// ACM SIGGRAPH/ Eurographics Symposium on Computer Animation. New Orleans: ACM Press, 2009: 17-26.
[16] WANG J, BODENHEIMER B. Computing the duration of motion transitions: An empirical approach [C]// ACM SIGGRAPH/ Eurographics Symposium on Computer Animation. Grenoble: ACM Press, 2004: 335-344.
(Edited by HE Yun-bin)
Foundation item: Project(60801053) supported by the National Natural Science Foundation of China; Project(4082025) supported by the Beijing Natural Science Foundation, China; Project(20070004037) supported by the Doctoral Foundation of China; Project(2009JBM135, 2011JBM023) supported by the Fundamental Research Funds for the Central Universities of China; Project(151139522) supported by the Hongguoyuan Innovative Talent Program of Beijing Jiaotong University, China; Project(YB20081000401) supported by the Beijing Excellent Doctoral Thesis Program, China; Project (2006CB303105) supported by the National Basic Research Program of China
Received date: 2011-01-14; Accepted date: 2011-04-12
Corresponding author: LIU Wei-bin, Associate Professor, PhD; Tel: +86-10-51685723; E-mail: wbliu@bjtu.edu.cn
