
����������������ѡȡ����
������1, 2�������1����ѩ3��������1�������1
(1. �й�ʯ�ʹ�ѧ(����) ������������Ϣ����ѧԺ ������Դ��̽������ص�ʵ���ң�������102249��
2. ������ѧ ��Ϣ��ѧ�뼼��ѧԺ������ ���ݣ�121013��
3. School of Information Technology and Electrical Engineering, the University of Queensland,
Brisbane, 4072, Australia)
ժ Ҫ��
�ռ��еķֲ����������������ռ�Ϊ���һ���߽������Ķ���ӿռ䣻�Ѹ����ӿռ�ֱ�ͶӰ�����������ϣ���ȡ���в�ͬ����ӿռ�Ե�ǰ�ӿռ���������������������ͨ���������������������ʵ����������������������������������Ϊ���ݣ�ѡȡ�����Ӽ���ʵ������ѡȡ��ʵ������������������ѡȡ������Ч�Ժ�Ч�ԡ�
�ؼ��ʣ�
����Լ��������ѡȡ�����������������߱���
��ͼ����ţ�TP18 ���ױ�־�룺A ���±�ţ�1672-7207(2011)S1-0651-05
Method of feature selection for continuous features
WANG Hong-wei1, 2, LI Guo-he1, LI Xue3, WU Wei-jiang1, LI Hong-qi1
(1. State Key Laboratory of Petroleum Resource and Prospecting, College of Geophysics and Information Engineering,
China University of Petroleum, Beijing 102249, China;
2. College of Information Science and Technology, Bohai University, Jinzhou 121013, China;
3. School of Information Technology and Electrical Engineering, the University of Queensland,
Brisbane, 4072, Australia)
Abstract: In terms of the distribution of objects and their classification labels, the continuous feature space was partitioned into a variety of subspaces, each one with clear edge and unique classification label. After the projection of all the subspaces to each feature, the quality of each feature was estimated for a subspace opposite to all the other subspaces with different classification labels by means of statistical significance. Through construction of a matrix by all the estimate qualities of all features of all the subspaces, all the features was ranked from the highest classifying power to the lowset on the matrix for the feature space. According to the ranked-feature set, the feature selection was completed. The experimental results illustrate that the feature selection is efficient and effective.
Key words: data reduction; feature selection; continuous attributes; decision table
����ѡȡ��֪ʶ��ģ���Զ����Ʋ����Ż��ȵõ��㷺Ӧ��[1]��Ŀǰ������ѡȡ��Ҫ��������ɢ�͡��������ԡ��мල��������ϢΪԼ�������ڵȼ۹�ϵ���ۣ�������ѧϰ�㷨�صġ����ˡ�����������������������������ѡȡ������2�ַ�����(1)������������������ɢ�����ٲ���������ɢ������������ѡȡ��������ɢ������������������������ʧ�棬�Ӷ�Ӱ�쵽����������ѡȡ��ȷ�ԣ�(2)ֱ�Ӳ��������������������ġ�����ԡ�������������ѡȡ����Reliefϵ��[2-4]����ѡȡ��Reliefϵ�а���Relief��ReliefF��RReliefF(�ع�)������ָĽ�������ReliefF��Relief�����������չ������࣬����kNN������ϵ�ÿ���������������������ϣ����������������³���ԡ������ø���������m�����������������һ���̶��Ϻ����˶���ķֲ�ȫ���ԡ�������������⣬Liu��[5]����ÿ�����ķֲ�����p���������m��p������ʹ���������������������Ӻ�����Huang��[6]���ݶ���������NN���࣬ȷ��ÿ�������ж���������Ѿ�������Ϊ������m�����m���Զ�ȷ�����⣬����Ծ�������Ϊ��������������������������������Guo��[7]����kNN���о��࣬ʹ��ÿһ�������ͬ���Ķ������࣬�����ɺ���e���������Ķ����Ծ�������Ϊ������������ÿ�������ڲ�ͬ�������Ķ�������������������������⣬�����������������������������������������m���Զ�ȷ�����ҽ�һ�����Ƕ���ֲ���������������������Ӱ�졣��e=0ʱ���÷����ͱ�ΪHuang�ȵķ�������Щ�������˲��ö�����������ͶӰ������Ϊ����������������⣬��Ҫ���ڵ��������£�(1)ֻ���Ƕ�����ֲ��ֲ�����(�ٽ�����)��������ȱ��ȫ���ԣ�(2)ֻǿ������(��)�ľ���Զ�������������������������ã����ڷ��������ϣ�ֻҪ�ܹ����ֶ���IJ�ͬ��𣬾��볤���ǵ�Ч�ġ������Щ���⣬�����������һ�ֻ��ڶ���ֲ�������ѡȡ������
1 ��ػ�������
1.1 ��Ϣϵͳ������ѡȡ
��Ϣϵͳ�����ݼ��ij������[8-11]������K=(U��A��V)��ʾ������U={u1��u2������u|U|}Ϊ����(|U|Ϊ������Ԫ�صĸ���)��A={ai|i=1��2������k}Ϊ�������������V={![]() |i=1��2������k}��
|i=1��2������k}��![]() ��������ai��ֵ��ʾ����u��U��ai�ϵ�ͶӰ����ai��U?
��������ai��ֵ��ʾ����u��U��ai�ϵ�ͶӰ����ai��U? ![]() ��ai(u)?Vai��������aiΪʵ��ʱ������aiΪ��������������ֵ��VaiΪ�����������䡣��A=C��D����C�٦�, D�٦���C��D=������KΪ���߱�DT������CΪ������������DΪ������������������������Ӽ�Fs?C����ʹ����в�����C�ķ��������������Fs���̳�Ϊ����ѡȡ�����������������Ϊ�����ͣ���������Ϊ��ɢ�͵�����ѡȡ��
��ai(u)?Vai��������aiΪʵ��ʱ������aiΪ��������������ֵ��VaiΪ�����������䡣��A=C��D����C�٦�, D�٦���C��D=������KΪ���߱�DT������CΪ������������DΪ������������������������Ӽ�Fs?C����ʹ����в�����C�ķ��������������Fs���̳�Ϊ����ѡȡ�����������������Ϊ�����ͣ���������Ϊ��ɢ�͵�����ѡȡ��
1.2 �������ĺͰ뾶
����������A��?A�������⼯��S?U�����������A������ĺͰ뾶�������£�
 (1)
(1)
![]() (2)
(2)
���У�distΪ���뺯��(��ŷ�Ͼ����)��
2 ���ڶ���ֲ�������ѡȡ
Ϊ��ʵ�ֻ��ڶ���ֲ�������ѡȡ(Feature selection for continuous features, FSCF)����������һЩ���
2.1 ͬ���Ӽ������Ż�
�������߱�DT=(U, C![]() D, V)��������������C���е������(Nearest neighbour, NN)���࣬�õ������Clus(U, C)�������㣺(1)����"Si?Clus(U, C)��|Si|��2��"u,v?Si��D(u)=D(v)����(2)���"w?U���뾶Radius(Si
D, V)��������������C���е������(Nearest neighbour, NN)���࣬�õ������Clus(U, C)�������㣺(1)����"Si?Clus(U, C)��|Si|��2��"u,v?Si��D(u)=D(v)����(2)���"w?U���뾶Radius(Si![]() {w}, C)>Radius(Si, C)��������$x, y?U��D(x)��D(y)������Radius(Si, C)Ϊ�뾶�ij�����ΪDT��һ��ͬ���Ӽ�(Same-label subclass set, SLSS)��һ�����߱���������һ��ͬ���Ӽ��ļ���SLSS_Set(DT)��SLSS_Set(DT)�����������ռ����ɲ��֡����ھ��߱�����������ȶ���SLSS_Set(DT)����Ȼ��| SLSS_Set(DT)|��|U|�������ڽ��и�Ч����ѡȡ�����|Si|=1����ô��ΪSiΪ������Ӧ��ɾ����
{w}, C)>Radius(Si, C)��������$x, y?U��D(x)��D(y)������Radius(Si, C)Ϊ�뾶�ij�����ΪDT��һ��ͬ���Ӽ�(Same-label subclass set, SLSS)��һ�����߱���������һ��ͬ���Ӽ��ļ���SLSS_Set(DT)��SLSS_Set(DT)�����������ռ����ɲ��֡����ھ��߱�����������ȶ���SLSS_Set(DT)����Ȼ��| SLSS_Set(DT)|��|U|�������ڽ��и�Ч����ѡȡ�����|Si|=1����ô��ΪSiΪ������Ӧ��ɾ����
2.2 ����������������������������
�ھ��߱�DT�У�ÿ�����������ķ��������Dz�ͬ�ģ�����ͨ��SLSS_Set(DT)�������������ȣ�ȷ��ͬ���Ӽ�"Co?SLSS_Set(DT)������"c?CͶӰ���䣺
![]()
![]() (3)
(3)
���У�Za/2Ϊ�ڸ���a�±���̬�ֲ�˫�ٲ�ֵ������
![]() (4)
(4)
��Za/2?[0, 3.09]����Ӧ����a?[0, 1]��
����ͬ���Ӽ�![]() ��
��![]() ?SLSS_Set(DT)����D(
?SLSS_Set(DT)����D(![]() )��D(
)��D(![]() )��ͬ���Ӽ�
)��ͬ���Ӽ�![]() ��
��![]() ������c��������������£�
������c��������������£�
![]()
![]() (5)
(5)
��Ȼ��DPc(![]() ,
,![]() , a)?[0, 1]���京�壺������c�ϣ�ͬ���Ӽ������Ķ���Խ��Խ���У���ͬ���Ӽ������ԽԶ����ô�ɷ��ͬ���ͬ���Ӽ�������Խǿ��DPc(
, a)?[0, 1]���京�壺������c�ϣ�ͬ���Ӽ������Ķ���Խ��Խ���У���ͬ���Ӽ������ԽԶ����ô�ɷ��ͬ���ͬ���Ӽ�������Խǿ��DPc(![]() ,
,![]() , a)=1ʱ����ʾ��ͳ�Ƹ���a�����ϣ���ͬ����
, a)=1ʱ����ʾ��ͳ�Ƹ���a�����ϣ���ͬ����![]() ,
,![]() ��ȫ����c����ʶ���ڵȼ۹�ϵ�У�ͬ���Ӽ�Ϊ�ȼ���
��ȫ����c����ʶ���ڵȼ۹�ϵ�У�ͬ���Ӽ�Ϊ�ȼ���![]() ��
��
��ʽ(5)�����ϣ���������ͬ���Ӽ�����������������������FIM(Feature importance matrix)��
![]() (6)
(6)
����
![]() (7)
(7)
ʽ�У�����c����ͬ���Ӽ�Co��������ͬ���ͬ���Ӽ�������������������Ȼ��![]() [0, 1]�����Կ�����FIM��ÿһ�ж�Ӧһ��ͬ���Ӽ���ÿһ�ж�Ӧһ������������
[0, 1]�����Կ�����FIM��ÿһ�ж�Ӧһ��ͬ���Ӽ���ÿһ�ж�Ӧһ������������
2.3 ����ȫ������������
Ϊ���ۺ�����ͬ���Ӽ����������������з����������ۺ��������������������������Ӵ�С��Ӧ������������������������������һ��Selected���ԡ���SelectedȡֵΪTrue��Falseʱ����ʾ����(ͬ���Ӽ�)�Ƿ��ٲ�����������������������㷨���£�
FSCF(FIM(DT, a), C) ��������߱�����������������������������
If C�٦�, then
![]()
������������ǿ����(����)
For "r?[1..|SLSS_Set(DT)|]
��ÿһ��(ͬ���Ӽ�)
For "c?C-RankedFeatureSet ��������(����)
If c(r)��cmax(r) then Selected(r)=True
�����±��
If "r?[1..|SLSS_Set(DT)|]
��������(ͬ���Ӽ�)
and Selected(r)=True then Selected(r)=False
���������Ѿ���ǣ���������
RankedFeatureSet={cmax}![]() RankingFeature(FIM(DT, a),C-{cmax}) ���ݹ�������
RankingFeature(FIM(DT, a),C-{cmax}) ���ݹ�������
Else
Return RankedFeatureSet
���Է��������Ӵ�С�õ�����������
Endif
�������㷨���Կ���������ȷ��һ��ͬ���Ӽ����������������������������Ҳ������ͬ���Ӽ���������������������ô��Щͬ���Ӽ����ٲ����������Ӷ��õ����ݷ���������ȫ���Ե���������
2.4 ����ѡȡ
��������������RankedFeatureSet=<>1, f2, ��, fn>������fi��A�����������Ӽ�<>1, f2, ��, fk>(����k��n)��ѡ��һ���������������ݼ�D���з��ྫ�ȵIJ��ԣ�ֱ��k=n�����ѡȡ���ྫ����ߺ�ѡȡʱ����С�������Ӽ�Ϊ����ѡȡ��
3 ʵ����
��ʵ������������E255 ��Windows XP�ϣ� Visual Basic 6.0Ϊ����ƽ̨������Access 2003Ϊ���ݻ�����ʵ��SLSS_Set(DT)��FSCF��
3.1 SLSS_Set(DT)������
SLSS_Set(DT)��һ���������������������obj������������
 (13)
(13)
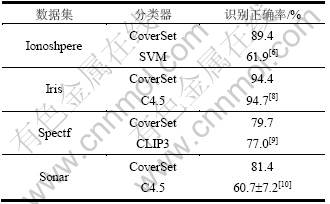
ʵ�����ݾ�����UCI���ݼ����������ݼ�����10-Fold Cross Validation����������飬a =78%��b = 100%(��Za/2=1��Zb/2=3.09)��distΪŷ�Ͼ��룬������10��ʵ��(��������100�ε����)������ʶ�ȵ�ƽ��ֵ��������������ʶ�Ⱦ�����������ױ���(����1)�����Կ��������˶�Iris���ݼ���ʶ���������⣬SLSS_Set(DT)���������ݼ�ʶ�ȶ�������ߣ�˵��SLSS_Set(DT)���нϺõķ���ܡ������йط��ྫ�Ⱦ�����SLSS_Set(DT)������������֤��
��1 ������ʶ�ȶԱ�
Table1 Comparison of classification accuracy
3.2 ����������
Parkingson���ݼ���22������������������1����������(��2��)��195����¼��ʵ�����a=78%��b=100%��e=0(��Za/2=1��Zb/2=3.09)��Ϊ��˵��FSCF����Ч�ԣ������ݼ�����10�ε�10-Fold Cross Validationʵ��(��100��)������ѧϰ��ʶ��ʱ�俪����ʶ����Ϊ���ۡ�ʵ������ͼ1��ʾ�����С�����������������������������͡�������������ĺ����Ǹ���ÿһ�����ķ����������Ӵ�С����������������������ȡ�������͡������ѡȡ�����������ɵ������Ӽ�����ͼ1���Կ�����(1)��ͳ�������ϣ����������������ķ���������ǿ���������������������������������������������ķ���������������֮�䣻(2)���������������ӣ�ʶ���������ӣ����Ƕ�γ��־ֲ����ֵ��˵�������Ӽ��������ʶ�ȣ�������ʶ�ȸߵ�λ�ã��������нϵ͵�ʱ�俪����
��������UCI���ݼ�����ʵ�飬�������Ƶ�ʵ��������Щʵ����˵����ͨ��ͬ���Ӽ�ȷ�������ķ�������������������������Ч�ġ�
3.3 ����ѡȡЧ��
��Spectf���ݼ���ʵ���Ǹ���UCI������ѵ�����ݺͲ������ݽ��еģ�������ѵ�����ݼ���������ѡȡ�Ͳ��ԡ������ݼ�����10�ε�10-Fold Cross Validationʵ��(������100�ε����)��ͳ������ȫ��������ѡȡ�������Ӽ���ʶ�Ⱥ�ѧϰ��ʶ��ʱ���ƽ��ֵ��������2���С����ݼ��У�ǰ�����зֱ�Ϊ����ȫ��������ѡȡ��ʵ����������Sonar���ݼ��⣬�������ݼ����������Ӽ���ʶ�����������ȫ����ʶ����Ⱦ��н�������ߣ�ʱ�俪��ȴ�����Լ��١�����Sonar���ݼ���ʶ����߲����ԣ�����������ʱ�俪��ȴ���Լ��١��ر�˵�����ǣ�Iris���ݼ��У�����ѡȡ��õ���ʶ�ȴ��ڲ���C4.5������ȫ����ʶ��(����1)����Щʵ������������Щ�����Ӽ���������ȫ���ķ���������
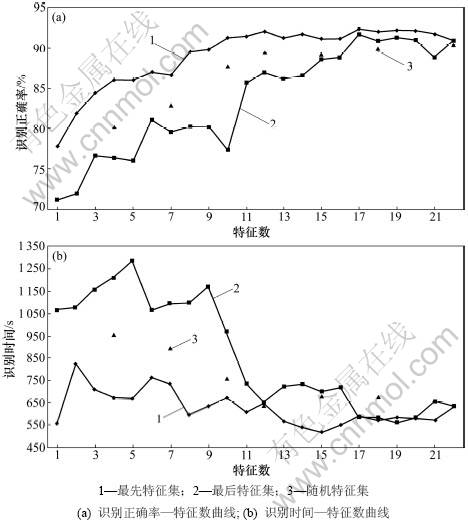
ͼ1 10��ʵ��ƽ��ֵ
Fig.1 Average values of 10 experiments
��2 ʶ�ȵĶԱ�
Table 2 Comparison of classification accuracy with feature subset to original features

4 ������
FSCF���ص����£�(1)��ͬ����ӿռ���ͬһ��������ͶӰ��ֻҪͶӰ���ص������е�ͬ�ķ����������������Ծ�����Ϊ����������������(2)ֻ�����������ͬ�����������������ķ������������ٷ�������������������(3)ͨ������������������ǿ������Ч��������������������ʹ������������ӿۣ�(4)���á���������������Ϊ������Ϣ��ʵ�ַ�������ǿ���������Ƚ�ϣ��õ����ŵ�һ������ѡȡ��
�ο����ף�
[1] Liu H, Motoda H. Feature selection for knowledge discovery & data mining[M]. Boston: Kluwer Academic Publishers, 1998.
[2] Kira K, Rendell L A. A practical approach to feature selection[C]//Sleeman D, Edwards P. Proc Intern Conf on Machine Learning. Aberdeen: Morgan Kaufman, 1992: 249-256.
[3] Kira K, Rendell L A. The feature selection problem: Traditional methods and a new algorithm[C]//Proceedings of the Tenth National Conference on Artificial Intelligence. Menlo Park: AAAI Press/The MIT Press, 1992: 129-134.
[4] Robnik-Sikonja M, Kononenko I. Theoretical and empirical analysis of relief and relief[J]. Machine Learning Journal, 2003, 53: 23-69.
[5] Huang Y, McCullagh P J, Black N D. Feature selection via supervised model construction[C]//Proc of the Fourth IEEE International Conference on Data Mining, 2004: 411-414.
[6] Liu H, Yu L, Dash M, et al. Active feature selection using classes[C]//Proc of PAKDD, 2003: 474-485.
[7] GUO Gong-de, Neagu D, Mark T D. Cronin: Using kNN model for automatic feature selection[J]. Pattern Recognition and Data Mining, 2005, 3686: 410-419.
[8] LIU Huan, Rudy S. Feature selection via discretization[J]. IEEE Transaction on Knowledge and Data Engineering, 1997, 9(4): 642-645.
[9] Blake C L, Merz C J. http://www.ics.uci.edu/~mlearn/ MLRepository.html. 1998
[10] Richeldi M, Lanzi P L. ADHOC: A tool for performing feature selection[C]//Proceedings of 8th International Conference on Tools with Artificial Intelligence, 1996: 102-105.
[11] �����. ���������ž������Ϣϵͳ����ѡȡ[J]. ��������̣�2006, 32(17): 52-54.
LI Guo-he. Feature subset selection of information system based on similar extension matrix[J]. Computer Engineering, 2006, 32(17): 52-54.
(�༭ ������)
�ո����ڣ�2011-04-15�������ڣ�2011-06-15
������Ŀ�����Ҹ��¼����о���չ�ƻ�������Ŀ(2009AA062802)��������Ȼ��ѧ����������Ŀ(60473125); �й�ʯ�ͿƼ������괴�»���������Ŀ(05E7013); �����ش�ר���ӿ���������Ŀ(G5800-08-ZS-WX)
ͨ�����ߣ�������(1980-)���У����������ˣ���ʿ�о�������ʦ�������˹����ܣ�֪ʶ���ֵ��о����绰��15501083193��E-mail: bhu_whw@163.com
ժҪ�����ݶ����������ռ��еķֲ����������������ռ�Ϊ���һ���߽������Ķ���ӿռ䣻�Ѹ����ӿռ�ֱ�ͶӰ�����������ϣ���ȡ���в�ͬ����ӿռ�Ե�ǰ�ӿռ���������������������ͨ���������������������ʵ����������������������������������Ϊ���ݣ�ѡȡ�����Ӽ���ʵ������ѡȡ��ʵ������������������ѡȡ������Ч�Ժ�Ч�ԡ�
