
DOI: 10.11817/j.issn.1672-7207.2015.05.017
���ٹ�Ӧ���з�ȷ����RFID���ݴ�������
л��1, 2��Ф��3�������4����ͮ1
(1. �������ĿƼ�ѧԺ �������ѧ����ϵ������ ¦�ף�417000��
2. ���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ, ���� ��ɳ��410083��
3. ���ϵ�һʦ�� ��Ϣ����ϵ������ ��ɳ��410205��
4. ¦��ְҵ����ѧԺ ������Ϣ����ϵ, ���� ¦�ף�417000)
ժ Ҫ��
��Ӧ��ϵͳ�д�����ȷ����RFID���ݲ��ܱ���Ч���������⣬ͨ������RFIDӦ�õĹؼ����������ݷ�ȷ�������ݵı����������������ڣ����ò�ͬ���Դ�����ͬ���͵ķ�ȷ�������ݣ�����ɴ����������ͷ�ȷ�������ݵ���ϴ���������ݶ����ڹ�Ӧ���г��ֵ�λ�ü��������������ֶ����©���Ͳ��������ݣ����ڶ����������ڵ����ƶ�·����Ӧ������ͼ��һ���������Ӧ�������Ͷ����ƶ��Ĵ����㷨���о��������������ķ����������õ���ϴЧ�����洢Ч���Լ���ѯ���ܣ��ڲ�ͬ��������������Ч��֧�ֶ���·����ѯ��
�ؼ��ʣ�
��Ӧ����������Ƶʶ������ȷ����������
��ͼ����ţ�TP311 ���ױ�־�룺A ���±�ţ�1672-7207(2015)05-1688-11
Methods for processing uncertain RFID data in traceability supply chains
XIE Dong1, 2, XIAO Jie3, GUO Guangjun4, JIANG Tong1
(1. Department of Computer Science and Technology, Hunan University of Humanities, Science and Technology,
Loudi 417000, China;
2. School of Information Science and Engineering, Central South University, Changsha 410083, China;
3. Information Technology Department, Hunan First Normal College, Changsha 410205, China;
4. Department of Electronics and Information Engineering, Loudi Vocational and Technical College,
Loudi 417000, China)
Abstract: Considering that massive uncertain radio frequency identification (RFID) data cannot be efficiently processed in application systems of traceability supply chains, key features of RFID applications were analyzed, and different smoothing windows were adjusted according to different rates of uncertain data. Different types of uncertain readings were obtained by employing different strategies, and the methods for efficiently and effectively processing various types of uncertain data were put forward. The methods distinguish between ghost, missing and incomplete data according to their appearing positions and their continuities in supply chains. The processing algorithms that are suitable to group and independent moving of objects were proposed based on the directed graph, which corresponds to moving paths of objects in logistics nodes. The results show that the proposed methods provide good cleaning effects, storage efficiencies, and query performances, and also efficiently support path-oriented queries of objects under different parameters.
Key words: supply chain management; radio frequency identification (RFID); uncertain data
������Ƶʶ��(RFID)����[1]�Ƕ��������Ͼ���Ψһ��ʾ���ĵ��Ӳ�Ʒ��ǩ(electronic product code��EPC)���ٽ�������ʶ��ķ��������Զ���RFID�Ķ���ʶ�����ɴ������ݣ����㷺Ӧ���ڹ�Ӧ������(supply chain management, SCM)��[1]��RFIDӦ�ÿ�Խ�����ҵ����ȡRFID��������Ժ�λ�����ݣ����ݶ����ڲ�ͬʱ�ڵ�λ����Ϣ(����Ѫͳ)��������ʷ�켣��λ�á����ܴ����RFID�����Ǿ�ȷ�ģ�������RFID�Ķ���λ��֪�����С����š��Ķ��������Ϻ�һЩ�������أ�RFIDԭʼ���������Dz�����������ȷ�����Ǵ���ġ���ȷ����RFID��������һ�������1) �����Ķ��Ƕȡ��źű������ź�ä�������أ����Ի�ȡ����ȷ��λ�õ���©�����ݣ�2) ���ڲ�ͬ��RFID�Ķ������ܴ��ڽ�����Ķ�����ͬһ��RFID������ܱ���ͬ��RFID�Ķ�����ȡ���Ӷ����в�ͬλ�õķ�һ�������ݣ�3) �Ķ������Ķ�������ܻ�ȡ�����ڵ��źţ������źű�ʶ��Ϊ�������ڵ�RFID�����¶�����ݣ�4) ��Դ��RFID�Ķ��������ڲ�ͬʱ������Ƶ���ض�ȡû���ƶ���RFID���Ӷ��������в�ͬʱ�����������ͬλ����Ϣ���������ݣ�5) ���������ݱ���ΪRFID��������û�г����ڹ�Ӧ���е�ijЩλ�ã���Ҫԭ��Ϊ�ٻ���ij����Ӧ���ڵ���빩Ӧ����RFID����͵��������Щ������û���ѯ����ֱ���ڷ�ȷ����RFID�����Ͻ��в��������ڴ�ͳ��ERģ�����Ա���RFID���ݵ�ʱ���ԣ�Wang��[2]�����DRERģ�ͣ���RFID���ݷ�Ϊ�����¼��ͻ���״̬2�����ͣ�����һ���������ƶ��Ķ�����ϸ����Ӧ�ó�������ģ[3]��Ȼ������Щ�����漰������λ�õ�·����ѯ����Ҫ�Դ洢���ݽ��ж�������ӣ�����Ч�ʽϵͣ���û�п��Ƿ�ȷ�������ݡ�����ʱ��ƽ���IJ���[4]ͨ����̬�������©�����ݣ������������ݵ�ʵʱ����ȥ���������ڴ�С��Jeffery��[5]�����һ������Ӧʱ��ƽ�������������Ч���ϲ������[6]ͨ�������������С��Ķ�̬������ʵ��������ϴ������Ҫ�Ƚ���������ϴ���ܱ�RFIDӦ��ʹ�á������˲�[7]����ֱ�ӹ۲������״̬(��RFID�Ķ�����λ��)�Ʋⲻ��ֱ�ӹ۲������״̬(����������λ��)�����ز����λ���ʧ��������Ч�ԺͶ����ԣ����¶�λ��������[8]��[9]�ֱ���ø�˹��Ϸֲ���ʱ���ͼģ������ȡ���ݵķ�ȷ���ԣ������ƶ��ֳֻ������£���Ȼ��λ��������������ֻ���©����δ���Dz�һ�����ݡ����ڿ�����������ķ�ȷ�������ݹ���[10]��PCQA����[11]������һ��������[12]�����п���������������п���һ���Ե��Ӽ������ٶ������Ƕ����ġ�л��[14]�ڿ���������������Ϸ�չ��һ�ֿ���չ�ķ�ȷ�������ݴ���ƽ̨���ڸ߲�Ӧ������ֱ�ӶԷ�ȷ�������ݽ��д���������Щ������û�п���©�����ݡ����Ϲ�����û�п����������͵ķ�ȷ�������ݣ�����Щ�����γɵĺ�����������ʵ����������Ч�ؽ����漰������λ�õ�·���١��������߿����������͵ķ�ȷ�������ݣ��ڻ���һ�����ķ�һ�������ݴ�������[15]�ͷ�ȷ����RFID����ģ��[16]�ȹ��������ϣ�ͨ������RFID����Ĺؼ����������һ�ַ�ȷ�������ݴ�������������©������������ͷ�һ�������ݵı����������������ڣ����ò�ͬ���Դ���©������������ࡢ��һ���Ժͷ�������(�ٻ������͵)���ݣ������ݶ����ڹ�Ӧ���г���λ�ü�����������ʶ������©���ͷ��������ݣ�ͨ�������������·��������ͼ����һ���������Ӧ�������Ͷ����ƶ��Ĵ����㷨��������������ڲ�ͬ��������������Ч��֧�ְ������١��١��ۼ���ѭ���ͳ�·���ȶ���·����ѯ��
1 ��ȷ����RFID���ݵĴ�������
1.1 ����RFID�Ĺ�Ӧ��
����RFID�Ĺ�Ӧ��������ͼ1��ʾ�����У�F������һ��������ݣ����������ڣ�D���ظ���ȡ����û�иı�λ�õ�����½������������ݣ�B��©������Ҫ���������Ϣ���ƶ�����λ�ã�C��2���Ķ���ͬʱ��ȡ������2����ͬ��λ�ã��ٻ�G�ڹ�Ӧ�����μ��룻D�ڲֿⱻ͵���ر�أ�������ٻ������͵���ƣ����������ڹ�Ӧ����ijЩλ�á�
RFIDӦ�������Ƶģ����з�ȷ���ԡ���ͬλ�õ�ʱ������ԡ���ͬλ�õĶ�������Ժʹ����ȡ�������Щ�ص㣬���ĸ��������¶��塣
����1 RFID�Ķ���RFID�Ķ���һ������ΨһEPC��RFID����tagIDi��timestampiʱ��㱻readerID�Ķ�����ȡ����ʾΪrdi=(tagIDi, timestampi,readerIDi)��
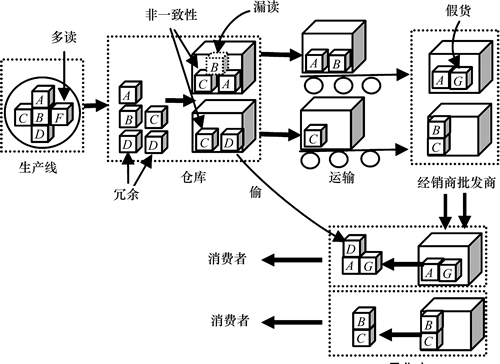
ͼ1 ����RFID�Ĺ�Ӧ��
Fig. 1 A RFID-based supply chain
����2 RFID��������RFID�������Ƕ������ΨһEPC��RFID����tagIDi��timestampiʱ��㱻readerIDi�Ķ�����ȡ����ʾΪRD=(rd1, rd2, ��, rdk)������rdi=(tagIDi, timestampi, readerIDi)��
�����ܽ��˼������ʵ�壺����ΨһEPC��RFID�����Ķ�����λ�á���Щʵ����������ݷ�Ϊ�������ݡ��Ķ����ݺ������ݡ�����������RFIDӦ�ò���ʱ�ͱ���ȡ����Щ��������ȶ���ȷ������λ�ú��Ķ������ݵȣ��Ķ�����ΪRFID�Ķ�����ȡ�����ݣ���������Ϊͨ�������Ķ����ݺ����ɵ������û���ѯ�����ݡ�
1.2 �������
ͼ2��ʾΪ��ȷ����RFID���ݵĴ�����ܡ�RFID�Ķ����Ӷ����������ȡEPC���ݣ������Ѵ����Ķ����ݵķ�ȷ���Ա�����ָ��һ���������ڣ�Ȼ��������е��Ķ������ƶ϶�ȡ�������Ƿ����©�����ݣ��洢RFID�����EPC��λ�ú�ʱ�����RFID���ݿ���(���У���һ���ԡ��������������Ҳ��Ҫ���洢��RFID���ݿ���)������һ���ķ�һ�������ݣ���ϴ������������ݡ�
��������������Ӱ�����ࡢ��һ���ԡ������©�����ݵı�������ѡ���Ĵ��ڣ����ܻ�ȡRFID����������Ϣ���������¸�������ࡢ��һ���ԺͶ�����ݲ�������ѡ��С�Ĵ��ڣ�����Լ������ࡢ��һ���ԺͶ�����ݵIJ����������ײ��������©�����ݡ�SMURF[5]������Ч��ȷ��һ������Ӧ�Ĵ��ڣ��������1���������ڲ���ȥ�������ࡢ��һ���ԡ������©�����ݵı�����
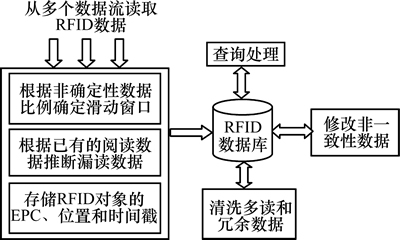
ͼ2 ��ȷ����RFID���ݴ������
Fig. 2 A framework for processing uncertain RFID data
��ͬ�����µĻ���������ͼ3��ʾ����©��Ƶ������ʱ(��p1��p2)��Stream A��������1������Ĵ��ڣ��������ࡢ��һ���ԺͶ������Ƶ������ʱ(��p2��p3)��Stream C��������1����С�Ĵ��ڣ�Stream B��������еģ�������ƽ��2���Ķ�������©��������С������Ҫ�ʵ��Ŵ������ࡢ��һ���ԺͶ������������Ҫ�ʵ���С���������¹�ʽ�����������ڣ�
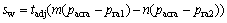 (1)
(1)
���У�swΪ�������ڳߴ磻pacraΪ�û��ɽ��ܵķ�ȷ�������ݵı�����pra1Ϊ��������ࡢ��һ���ԺͶ��������pra2Ϊ�����©��������tadjΪ�ɵ�����ʱ������m��nΪpra1��pra2�ĵ���������
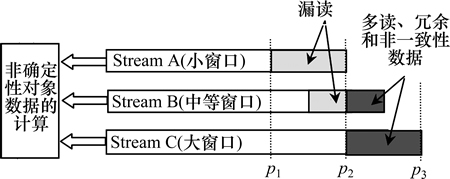
ͼ3 ��ͬ�����µĻ�������
Fig. 3 Smooth windows under different rates
1.3 �����ƶ�
�Ķ�����(EPC, position, timestamp) һ������ɷ�ӳRFID����״̬�Ĵ洢��ʽ(EPC, position, tin, tout)������[tin, tout]��ʾEPC��λ��position��ͣ��ʱ�䡣��ͬ��ȷ�������ݴ������ƶϹ������£�
����3 �ƶϹ���(INFERRING RULE)������ģʽ(PATTERN)-����(CONDITION)-����(ACTION)��ʽ��
INFERRING RULE < rule-id >
PATTERN< pattern > CONDITION< condition >
ACTION< action >
���У�patternΪ��ȷ�����������ͣ�conditionΪ���������ں��־��������actionΪִ�е��ƶϲ�����
�ƶϲ�ͬ���͵ķ�ȷ����������ͼ4��ʾ��

ͼ4 �ƶϲ�ͬ���͵ķ�ȷ��������
Fig. 4 Inferring different types of uncertain data
1) ©�����ݡ�����o1ͨ��λ��p 1��p2��p3������λ��p2ʱδ�������Ը���RFID������ƶ���ʷ��λ�ù�ϵ���ƶϣ��������o1һ�������RFID�����λ��p1��p3����ͨ��λ��p2��������ƶ϶���o1Ҳͨ����λ��p2���������λ��p2��ͣ��ʱ�估���ʣ���(o1, p2, t2, t3, prob)��
2) ��һ�������ݡ�����o1��p1��p3�����ܱ�2����ͬ���Ķ�����ȡ���Ӷ��γɾ���2����ͬλ��p2��p��2�ķ�һ�������ݡ����Բ���2�ַ����ƶϣ�һ����������©�����ݵ��ƶϣ�����RFID������ƶ���ʷ��λ�ù�ϵ���ƶϣ���(o1, p2, t2, t3, prob)����һ���Ǹ���RFIDӦ�õĴ������ص㣬�Ѱ���2����ͬλ��p2��p2������һ��λ��pa���浱ǰ��һ����λ�ã��� (o1, pa, t2, t3)��
3) ������ݡ������ڵĶ���o1��λ��p2����ȡ����o1Ҳ����������λ�ó��֣����Ա�ʾΪX->X->X�������һ��RFID�������뿪�����ߺ����ϱ�͵�����ڱ�͵RFID����Ҳ��������һ����ֻ����1�Σ���ô���ܱ�����Ϊ�Ƕ�����ݣ���ˣ���Ҫ��һ�����֡����������Ҫ��������ϴ��
4) �������ݡ�λ��û�иı��RFID�����ڲ�ͬ��ʱ�����ڱ���ȡ�������o1��ʱ���t2��t��2�ϱ���ȡ2�Ρ�����o1��������һ��λ�ñ�©�����ƶ���©��λ����Ҫ�����λ����Ϣ����ˣ���Ҫ���������λ����Ϣ��ֱ������o1�����µ�λ��Ϊֹ��
5) ������������(�ٻ�)���ٻ��ڹ�Ӧ�������λ��������IJ�Ʒ�У����ٻ�����������������ϡ���ٻ�o1������λ��p2��p3����o1û����λ��p1���֣���ʾΪX->p2->p3���ڹ�Ӧ����ֻ����1�εļٻ�û�����壬�ٻ��������������ξͱ��뱻��ȡ2�Σ���ֱ�ӽ�������������Ҫ��EPC�����ڼٻ�ʵ�ʴ��ڣ�����2�����ϼٻ����ݲ��ᱻ��ϴ�����⣬��¡�ٻ���EPC���ܳ������������ϣ���ˣ���¡�ٻ�����Ʒ����ͬʱ�����ڹ�Ӧ���л��߲�ͬʱ���֣���EPC�����γ�2����ʷ�켣����¡�ٻ��γɵ���ʷ�켣��λ����������������
6) ������������(����͵)��ͼ4(f)��ʾRFID������ijһλ�ñ�͵����͵����������½���ù�Ӧ����Ҳ������Զ��ʧ�������o1������λ��p1��������o1��λ��p2��͵����ˣ�����o1��λ��p2û�б���ȡ��o1�Ĺ켣���Ա�ʾΪp1->X->X(��Զ��ʧ)������������λ��p3���룬��ʾΪp1->X->p3��
1.4 �����©���ͷ����������ݵ�����
���ڶ����©���ͷ����������ݶ����ڹ�Ӧ����ijЩ�ڵ�ȱ��λ����Ϣ�������ǵĴ���������ͬ����ˣ���Ҫ������Щ���ݡ���Щ�����������Ķ�����ȡʱ���������֡����磬����o1������λ��p1������o1�����Ƕ�����ٻ���
ͼ5��ʾΪ�����©���ͷ������������ڹ�Ӧ���п��ܳ��ֵ�λ�á�©�����ݿ��ܳ����ڳ������ߵ��κ�λ�ã��ٻ�ֻ�����˹�Ӧ���������Σ������ܽ��������ߣ��ٻ�Ҳ����ֱ�ӽ��������̣�����ٻ���������EPC����ֱ�����۸������ߣ�RFID���������������ϱ�͵������͵��һ�������ڱ���ǩ֮ǰ������͵���ܷ����ڳ��������ϵ�����λ�ã�Ҳ���ܱ�͵�����½��빩Ӧ����������ݿ��ܷ����ڹ�Ӧ��������λ�ã����������ϵķ�ȷ��������ֻ���ܴ��ڶ�����ݡ�
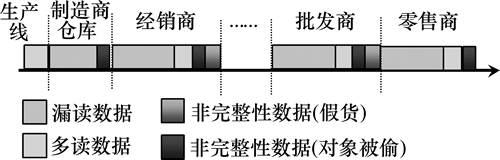
ͼ5 �����©���ͷ������������ڹ�Ӧ���г��ֵ�λ��
Fig. 5 Positions for ghost, missing and incomplete data in supply chains
ͼ6��ʾΪ�����©���ͷ����������ݵ�3�������
1) ���A��ʾ1���Ķ�����ֻ�����������ϣ�������Ƕ�����߶������뿪�����ߺ����ϱ�͵������RFID������������д���Ʒ��������ˣ������ƶ϶������û����ز���������͵��������ز�����
2) ���B��ʾ��ͨ�ٻ���EPC����������û����Ϣ������¡�ٻ������������������Ϣ����ȱ������λ����Ϣ��������ΪRFID�����ڹ�Ӧ�����ƶ��������ģ��������ڵ�����λ����Ϣ������¡�ٻ���ͻȻ�����ڹ�Ӧ���У����ȱ�����ڵ�����λ����Ϣ��
3) ���C��ʾRFID������ֳ���1�Σ���û�г�����ijЩλ�á����������ΪRFID������ijЩλ�ñ�©�����߱�͵��RFID�������½��빩Ӧ����©����RFID����һ����ʧ����ɢ��λ�ã�����͵��RFID����һ����ʧ��������λ�ã��ұ�͵��RFID��������ԭ���ķ��顣��ˣ�����ͨ��λ�õ������Ժͷ��������������2�������
1.5 ����ģ��
���IJ������µ�ģ�ʹ洢��ȷ��������(ͼ7)���ڲ��������У�READER(reader_id, name, owner_id)�� ���Ķ�����EPC�����ֺ������ߣ�OBJECT(EPC, description)�洢RFID�����EPC�����ͣ�POSITION (postion_id, name, parent_id)�洢λ��ID�����֡���һ��λ��ID��BUSINESS(id, name)�洢ҵ�����͡����Ķ������У�READING(reader_id, EPC, timestamp, prob)ͨ��OBJECT��READER���ɣ��洢RFID�����ԭʼ���ݣ�Ϊ�����ַ�ȷ�������ݣ��ǿ�¡�ٻ�����¡�ٻ�����͵���������������probֵ�ֱ�Ϊ2, 1, 0��NULL���ڸ�Ҫ�����У�REA_BUS(reader_id, tin, tout, business, position)�洢�Ķ�����һ��ʱ�����ڵ�ҵ����PATH(path_id, parent, weight)�洢·�����У�SEQ(sqid, postion_id, tin, tout)�洢��һ��ʱ�����ڵ�λ�ã�STAY(EPC, sqid)�洢�����·�����С�
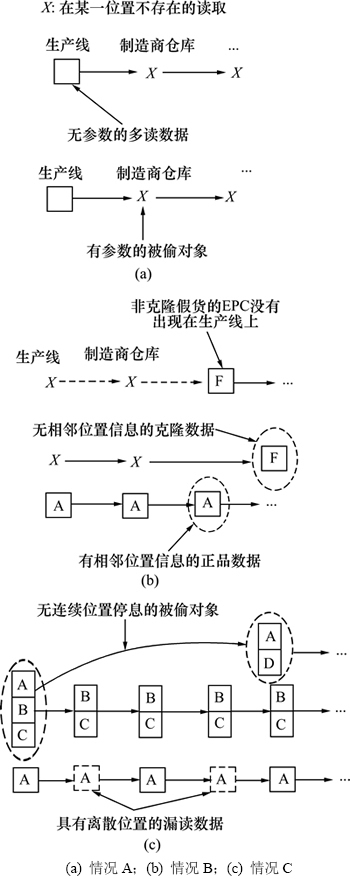
ͼ6 �����©���ͷ����������ݵ�3�����
Fig. 6 Three situations for ghost, missing and incomplete data
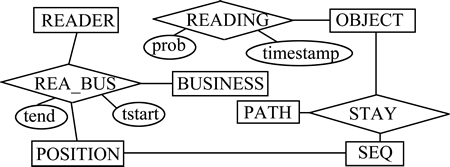
ͼ7 ����ģ��
Fig. 7 Data model
1.6 �㷨
��������Ŀ�ܺ���������˻�������ͼ(����1)�ķ�ȷ�������ݴ����㷨��
����4 һ�������ε����εĹ�Ӧ��SC�ɱ�ʾΪ����ͼ
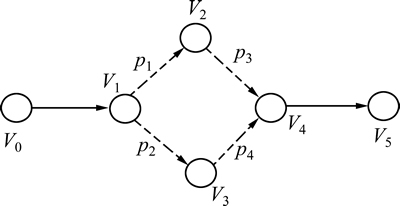
ͼ8 ��ʾ�����ƶ�������ͼ
Fig. 8 A directed graph for expressing object moving
ͼ8�е�����ͼ��ʾ��<>1, V2>��<>1, V3>��Ȩ�طֱ�Ϊp1��p2����ʾ��V1��V2�ʹ�V1��V3�ĸ���(������©���ͷ�һ�������ݵĿ�����)������Ϊǰ���ڵ��������������ߵ���ʷ�ƶ��������ǰ���ڵ����������ʷ�ƶ�����ı�����
����ͼ4(a)��4(f)���㷨1������������ࡢ�������ԡ�©���ͷ�һ�������ݣ������㷨2 Builddirectedgraph����������ͼ��·������SEQ���㷨1�ٸ����Ķ������ֵ�λ�ã���READING��ϴ������������ݣ�����Ǽٻ��ͱ�͵��������ݣ���������ͼ�дӸ��ڵ㵽�ӽڵ��·��Ȩ�أ��ڸ�����ֵ�����±�Ǻʹ���©���ͷ�һ�������ݣ�����©�����ݵ�STAY����ͨ���ۼ����߲�ε�ʱ����AT��λ��AP�ķ�һ�������ݣ�����㻬�����ڳߴ硣
�㷨1���ȵ����㷨2������ STAY�е�Ԫ��������READING�е�Ԫ�������㷨2�ڵ�1����ʼ��ѭ������Ϊt����ˣ��㷨2��ʱ�临�Ӷ�ΪO(t)���ڵ�3����ʼ����ѭ������Ϊt���ڵ�17��24����ʼ����ѭ��������Ϊ·������l(3~22)��������ѭ��EPC������ͬʱ�����17��24����ʼ��2����������ˣ���3����ʼ��ѭ����ʱ�临�Ӷ�ΪO(lt)�����õ��㷨��ʱ�临�Ӷ�ΪO(t(l+1))��
�㷨1 main
Input: READING����ֵTV ���û��ɽ��ܵķ�ȷ�������ݵı���acra���ɵ�����ʱ����adj����ȷ�������ݱ����ĵ�������m��n
Output: ��ϴ������������ݣ���Ƿ����������ݣ���©���ͷ�һ�������ݣ��������ڳߴ�sw
Begin
1. Builddirectedgraph (EPC);
2. ra �� 0��t �� READINGԪ������
3. For RADING��EPC do
4. If EPC �ڽڵ���ֻ����һ��
5. ɾ��������ݣ�
6. Else if EPC��ͬһ�ڵ����2������
7. ɾ������ʱ����������������ݣ�
8. Else if EPCû�г����ڸ��ڵ�
9. ����EPCΪ�ǿ�¡�ٻ���
10. Else if EPC�����ڸ��ڵ���������·������·�������ڽڵ㲻����
11. ����EPCΪ�ǿ�¡�ٻ���
12. Else if EPC�����ڸ��ڵ㵫û�г����ں����ڵ�
13. ����EPCΪ��͵����
14. Else if EPC û�г�����ijһ�ڵ�
15. ra ++��
16. ����EPCΪ©�����ݣ�
17. For i =1 to ·������l do
18. {W �� ��i��©���ڵ�·����Ȩ�أ�
19. If W �� TV
20. STAY �� EPC��©���ڵ�;
21. Else ͨ���ۼ��ϼ�AT��AP��EPC��STAY��ģ��·���ڵ�λ��}
22. Else if EPC��ͬһʱ�������2��λ��
23. ����EPCΪ��һ�������ݣ�
24. For i �� 1 to ·������l do
25. {W �� ��i����һ���Խڵ�·����Ȩ�أ�
26. If W �� TV
27. ��EPC�ķ�һ���Խڵ㵽STAY��
28. Elseͨ���ۼ��ϼ�AT��AP��EPC��STAY�ķ�һ����·���ڵ�λ��}
29. }
30. ra2 �� ra/t��
31. ra1 �� 1 �C ����ϴ��READINGԪ����/t - ra2 ��
32. sw �� adj*(m*(acra�Cra1)�Cn*(acra�Cra2)) ��
End
�㷨2 Builddirectedgraph
Input: EPC
Output: ����ͼ��SEQ
Begin
For i �� 1 to STAY�е�Ԫ����do
{parent �� EPC�ĸ��ڵ㣻
node = EPC��parent���ӽڵ㣻
If node is NULL then
{node �� new node��
node.loc �� EPC.loc��
node.tin �� EPC.tin��
node.tout �� EPC.tout��
parent���ӽڵ� �� node��
}
����node.path��PATH��
W �� parent��node�ߵ�Ȩ�أ�
W �� PATH��
}
End
2 ʵ������
2.1 ʵ�黷��
���Ŀ������������͵ķ�ȷ�������ݣ�������������ʵ�����ݲ�����һ�£���ˣ��������ķ����������������бȽϡ�
ʵ�����ۻ����в���CPUΪCore i2 2.00 GHz���ڴ�Ϊ2 Gb RAM�Ļ���������ϵͳΪWindows 7�����ݿ�ΪMYSQL5.6������ȱ��ͨ�õ�RFID�������ݣ����ĸ���1��ʳƷ����ģ��[17]�������ݣ���������Ӧ�IJ�ѯ���в��ԡ�
���������ڽ����г���ũ��Ʒ��Ӧ�̵ȸ��ڵ㣬��ͨ����������������ʽ�ƶ�����һ��λ�á���������ͼ�����Ƿ�������ȥ���ɶ������ݣ������������ضԲ�ѯ���ܵ�Ӱ�졣����ͼ��ÿ���ڵ��ʾijһλ�õ�һ����߱�ʾ������λ��֮����ƶ���һ��أ��������ڵ�Ķ����ƶ������Ǹ�����飬����Ҷ�ӵĶ����ƶ������Ǹ�С���顣����ijߴ��ʾΪG����ʾΪһ���ƶ��Ķ������������ĸ�������ͼ�и�����G������������ݣ�SEQ��Ӧ����ͼ�еıߣ���ʾ�����ƶ���
���ڷ�ȷ�������ݴ���©�����ݣ���������Ӱ�����أ�©��������Ͷ�����ݱ������û�ָ����λ�ú�ʱ�������(������2����ε�·�����н��Զ��ۼ�)����ͬ���ݹ�ģ��ʵ���������1��
��1 ʵ�����
Table 1 Experimental parameters
2.2 ���ݴ���
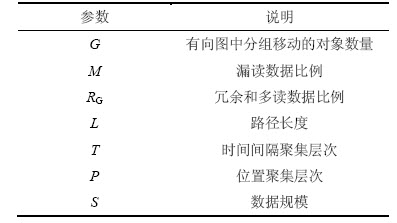
���ݲ�ͬ�����Ƚ���ϴ��Ĵ洢��ģ������©�����ݱ���M=(0.500, 0.250, 0.100, 0.500, 0.025)������Ͷ�����ݱ����ֱ�ΪRG=(0, 0.333, 0.500, 0.666, 0.750)�����������ֱ�Ϊ1 000��2 500��5 000��7 500��10 000�����ݹ�ģΪS=(3 800, 31 700, 135 000, 427 500, 975 000)��������READING������ϴ����Ͷ�����ݣ�����©�������Ҵ���ñ���Ҳ��ע�ٻ��ͱ�͵����ȷ����������ݣ����ķ�һ�������ݡ�
����©�����ݱ���������Ͷ�����ݱ����Ƕ����ģ���ˣ�����5�����ݱ�������ʾ����1Ϊ(M=0.5, RG=0)����2Ϊ(M=0.25, RG=0.333)����3Ϊ(M=0.1, RG=0.5)����4Ϊ(M=0.05, RG=0.666)����5Ϊ(M=0.025, RG=0.75)��©�����ݱ�����0.500 �½�Ϊ0.025������Ͷ�����ݱ�����0 ���Ϊ0.75����ͼ9��֪��û����ϴ���������ڲ�ͬM��RG�³���������������©�����ݱ��ƶϼ�������READING��������Ͷ��������READING����ϴ������ϴ�����ݹ�ģ�ڲ�ͬM��RG������ͬ�ġ����ߵ�RG��������������READING�ߴ硣����С��RG���ܵ��¸����©������Ӱ��©���ƶ�ȷ�ʡ���ˣ����ݻ������ڵ���RGΪ��Сֵ���ҵ���MΪ���ʵ�ֵ��

ͼ9 ��ͬ��M��RG�����ݹ�ģ(S=10 000, P=3~22, T=3 600, PA=3)
Fig. 9 Size of different rates of missing, redundant, and ghost data (S=10 000, P=3-22, T=3 600, PA=3)
ͼ10��ʾΪ��ͬS�����ݹ�ģ������ΪM=0.1��RG=0.5�����ݶ�������(1 000��2 500��5 000��7 500��10 000)�ֱ��������ݽ����READING����Ӧ��·�����ȷֱ�Ϊ(3-4)��(3-7)��(3-9)��(3-17)��(3-22) (ÿ500����������ͬ��·������)������RG=0.5�ͳ�·�����ܵ��¸�����������ݣ�û����ϴ�������ݹ�ģ���Եش��ڱ���ϴ�������ݹ�ģ�����ɵ����ݽ������SEQ��STAY��PATH�����ڱ�STAYֻ�洢��һ�����ӦԪ���һϵ������·������(һһ��ӦOBJECT�еĶ���)����SEQֻ�洢��2���ɵ�����ʱ������λ�ã���PATHֻ�洢��������ͼ������·������ˣ��û�����ͨ����ѯ��С�ߴ�ı�����Ч�ػ�ȡ���������·����
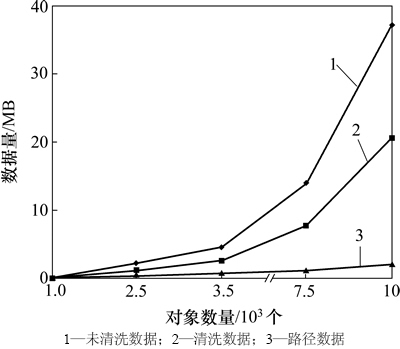
ͼ10 ��ͬS�����ݹ�ģ(P=3~22, T=3 600, PA=3, M=0.1, RG=0.5)
Fig. 10 Size of different data sizes (P=3-22, T=3 600, PA=3, M=0.1, RG=0.5)
����[17]��������С·��Ϊ3�����·��Ϊ9������ѭ���ͳ�·�����⣬�ӳ������·�����ȵ�17��22��һ��أ������·������Ϊ3~9���ر���3~6����������5��ϵ�е�·�����ȣ�3~4(ÿ5 000����������ͬ·������)��3~7(ÿ2 000����������ͬ·������)��3~9(ÿ1 500����������ͬ·�����ȣ���9��Ϊ1 000����������ͬ·������)��3~17(�ӵ�3�㵽��9��ÿ1 300����������ͬ·�����ȣ��ӵ�10�㵽��17��ÿ90����������ͬ·������)��3~22(�ӵ�3�㵽��9��ÿ1 300����������ͬ·�����ȣ��ӵ�10�㵽��22��ÿ90����������ͬ·������)����ͬ��P���ݹ�ģ(S=10 000, T=3 600, PA=3, M=0.1, RG=0.5)��ͼ11��ʾ����ͼ11��֪��û����ϴ�ĺ���ϴ�������ݹ�ģ��·����������ʱ�������ӣ���·�����ݹ�ģ��·����������������������������·����������Ӱ�����ݹ�ģ������·�����ݹ�ģӰ�첻��

ͼ11 ��ͬ��P���ݹ�ģ(S=10 000, T=3 600, PA=3, M=0.1, RG=0.5)
Fig. 11 Size of different path lengths (S=10 000, T=3 600, PA=3, M=0.1, RG=0.5)
���ǵ������ں̵ܶ�ʱ���ڲ����ܴ�һ��λ���ƶ�����һ����Զ��λ�ã���ˣ�ÿһ��λ�ý���Ӧһ�����ʵ�ʱ��������ʱ����T=60��Ӧ��λ�ü��PA=2����ͬ��T��P�����ݹ�ģ(S=10 000, P=3-22, M=0.1, RG=0.5)��ͼ12��ʾ����ͼ12��֪��·�����ݹ�ģ��T��PA�����Ӷ�����(����ϴ���ݵĹ�ģ����T��PA�ĸı���ı�)��·�����ݹ�ģ�ļ��ٶԽ���·����ѯ�ĸ����Ƿdz���Ч�ġ�
2.3 ��ѯ
����û����ϴ�������ݲ��ʺ��ڽ��в�ѯ���ۣ����IJ����㷨��ϴ���ݺ;ۼ�����������ѯ���бȽϡ�Q1Ϊ���ٲ�ѯ��Q2��Q3��Q6��Q7Ϊ�ٲ�ѯ������Q4��Q5Ϊ�ۼ���ѯ��Q6Ϊ�����������ݲ�ѯ��Q7Ϊѭ���ͳ�·����ѯ��
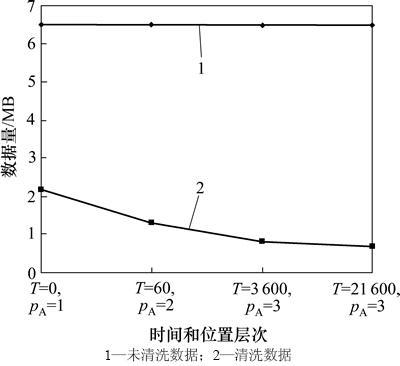
ͼ12 ��ͬ��T��P�����ݹ�ģ(S=10 000, P=3~22, M=0.1, RG=0.5)
Fig.12 Size of different aggregate levels of positions and time intervals (S=10 000, P=3-22, M=0.1, RG=0.5)
��2 ���Բ�ѯ
Table 2 Test queries

�ڱ�STAY�д洢����EPC����·�����У�Q1��Q2����Ҫ���Ӷ����ȥ��ȡ·����Ϣ������Q3��Ҫ����2����ȥ��ȡ·����Ϣ�����洢ʱ������λ����Ϣ�ı�SEQ�Ѿ���������ѹ�����ۼ���ѯQ4��Q5��Ҫ����2���������൱�����������Ҳͨ���ۼ�ѹ����Ҳ�������ظ��Ʋ�ѯ���ܡ����ڲ�ѯ�ٻ��漰����STAY, SEQ��PATH��Q6������3�������ַǿ�¡�ٻ��Ϳ�¡�ٻ���ѭ���ͳ�·����ѯҲ�漰��STAY��SEQ��PATH��Q7��Ҫ������3������ȡϸ�ڵ�·����Ϣ��
��ͬ����G��ִ�������ͼ13��ʾ������ΪS= 10 000��P=3-22��T=3 600��PA=3����ͼ13��֪������path(sequence)��Q3~Q7��ִ��ʱ�����ŷ���G�����Ӷ����١�������ΪQ1��Q2ֻ��Ҫ��ѯSTAY����ȡ·����Ϣ�����Q1��Q2��ִ��ʱ��û�иı䡣Q3��ִ��ʱ����G�����Ӷ����٣�������Ϊ����ķ������������ѹ��SEQ�Ի�ȡ·����Ϣ������Q4��Q5��Ҫ����2�������оۼ�������G�����ӣ��ڲ���T=3 600��PA=3�����µ�ѹ����Ҳ���������ӡ����Ƶأ�Q6��Q7��Ҫ����3����(SEQ, STAY��PATH)ȥ�ټٻ��;���ѭ���ͳ�·���Ķ���ѹ��������G�����Ӷ����ӡ�
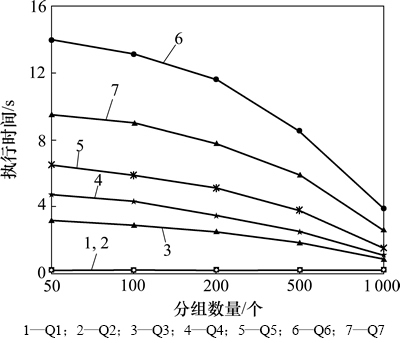
ͼ13 ��ͬ��G�����ִ�����(S=10 000, P=3~22, T=3 600, PA=3)
Fig. 13 Execution time with different number of groupings (S=10 000, P=3-22, T=3 600, PA=3)
Q1~Q7�ڲ�ͬ���ݹ�ģSʱ��������ͼ14��ʾ�����Բ���G=200��P=3~22��T=3 600��PA=3�����ݹ�ģ������Ӱ��Q3~Q7��ִ��ʱ�䡣����Q3~Q7��Ҫ���Ӷ��������ִ��ʱ����S�����Ӷ��������ӡ���Q1��Q2ֻ��ѯ��STAY�����ݹ�ģ�ı仯����ִ��ʱ��Ӱ���С��
����RFID�Ķ�������������ʱ����ڶ�������ͬ��ʱ�����ȡ�����ǩ��path(sequence)�ۼ�ʱ������λ�ã������˾����ʱ�����λ�ã����������ظ��ƴ洢�Ͳ�ѯ����Ч�ԡ�ͼ15��ʾΪ�ڲ�ͬ�ۼ�����µIJ�ѯִ��ʱ�䡣��������4�鲻ͬ�ľۼ���Σ�����(T=0, PA=1)������(T=60, PA=2)������(T=3 600, PA=3)������(T=21 600, PA=4)������4��ۼ�������۲�ѯQ1~Q7�����У�����(T=0, PA=1)��û�оۼ��ģ������Q3~Q7����Ч�ġ����žۼ�ʱ������λ�ü�����ӳ���Q3~Q7��ִ��ʱ���������١�
һ���·������Ϊ3-9[17]����ˣ����Ǵֶ����·������Ϊ3-9��������4�鲻ͬ��·������P1=3~5��P2=3~9��P3=3~17��P4=3~22������Q1~Q7����·�����ȳ���9����ʵ������10%�Ķ����·������Ϊ10~22 (ÿ�����ȵĶ����������ƽ��)������90%�Ķ����·������Ϊ3~9(ÿ�����ȵĶ����������ƽ��)��ͼ16��ʾΪ Q3~Q7�ڲ�ͬ·�����ȵ�ִ��ʱ�䡣��ͼ16�ɼ���Q3~Q7��ִ��ʱ������·�����ȵ����Ӷ��������ӡ�������Ϊ��·�������������Ա�ѹ������ͬ·����Ϣ������·��������������ѹ���IJ�ͬ·����Ϣ�����ھ���·������10~22�Ķ�����٣�ִ��ʱ�������������
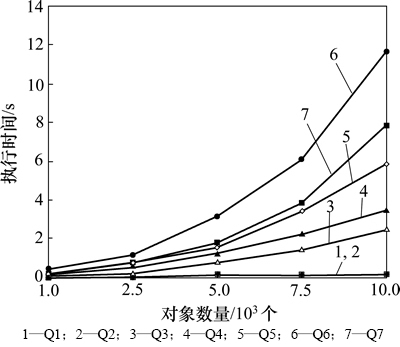
ͼ14 ��ͬ��ģS��ִ�����(G=200, P=3~22, T=3 600, PA=3)
Fig. 14 Execution time with different data sizes (G=200, P=3-22, T=3 600, PA=3)
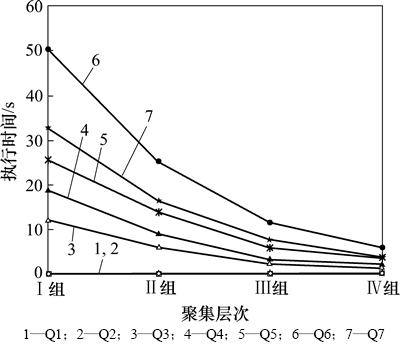
ͼ15 ��ͬ��T��PA��ִ�����(S=10 000, G=200, P=3~22)
Fig. 15 Execution time with different aggregate levels of positions and time intervals(S=10 000, G=200, P=3-22)
������ʵ���У�Q6��Q7��ִ��ʱ��ϳ�����������2���ѯ��Խ��٣���ˣ���ѯ����Ҳ�ǿ��Խ��ܵġ�
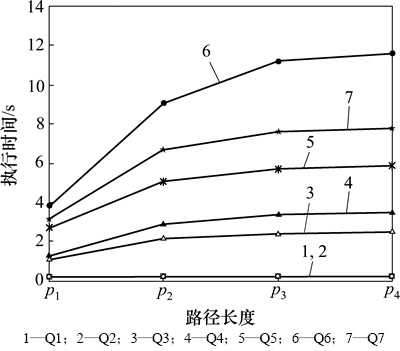
ͼ16 ��ͬ��P��ִ�����(G=200, S=10 000, T=3 600, PA=3)
Fig. 16 Execution time with different path lengths(G=200, S=10 000, T=3 600, PA=3)
3 ����
1) �������������͵ķ�ȷ�������ݣ�ͨ������RFID����Ĺؼ�����������©������������ͷ�һ�������ݵı����������������ڣ������һ�ַ�ȷ�������ݴ������������ò�ͬ���Դ���©������������ࡢ��һ���Ժͷ�������(�ٻ������͵)���ݣ������ݶ����ڹ�Ӧ���г���λ�ü�����������ʶ������©���ͷ��������ݡ�
2) ������������ڲ�ͬ���������¾������õ���ϴЧ�����洢Ч���Լ���ѯ���ܣ�����Ч��֧�ֶ���·����ѯ��
3) ��һ���Ĺ��������������ƶ�����·������·������һ��ѹ����������ߴ洢�Ͳ�ѯ���ܡ�
�ο����ף�
[1] Ilic A, Andersen T, Michahelles F. Increasing supply-chain visibility with rule-based RFID data analysis[J]. IEEE Internet Computing, 2009, 13(1): 31-38.
[2] WANG Fusheng, LIU Shaorong. Temporal management of RFID data[C]// Proceedings of the International Conference on Very Large Data Bases. New York: Association for Computing Machinery, 2005: 1128-1139.
[3] WANG Fusheng, LIU Shaorong, LIU Peiya. A temporal RFID data model for querying physical objects[J]. Pervasive and Mobile Computing, 2010, 6(3): 382-397.
[4] Rizvi S, Jeffery S R, Krishnamurthy S, et al. Events on the edge[C]// Proceedings of the International Conference on Management of Data. New York: Association for Computing Machinery, 2005: 885-887.
[5] Jeffery S R, Garofalakis M, Franklin M J. Adaptive cleaning for RFID data streams[C]// Proceedings of the International Conference on Very Large Databases. New York: Association for Computing Machinery, 2006: 163-174.
[6] ����, �ڸ�, ��С��, ��. ���ڼ�ض���̬�۴صĸ�ЧRFID������ϴģ��[J]. ����ѧ��, 2010, 21(4): 632-643.
GU Yu, YU Ge, HU Xiaolong, et al. Efficient RFID data cleaning model based on dynamic clusters of monitored objects[J]. Journal of Software, 2010, 21(4): 632-643.
[7] ������, Ǯ����, ������, ��. AMUR: һ��RFID���ݲ�ȷ���Ե�����Ӧ�����㷨[J]. ����ѧ��, 2011, 39(3): 579-584.
WANG Yongli, QIAN Jiangbo, SUN Shurong, et al. AMUR: An adaptive measuring algorithm of underlying uncertainty for RFID data [J]. Acta Electronica Sinica, 2011, 39(3): 579-584.
[8] Tran T T L, Peng L P, DIAO Yalei, et al. CLARO: Modeling and processing uncertain data streams[J]. The VLDB Journal, 2012, 21 (5):651-676.
[9] NIE Yanming, Cocci R, ZHAO Cao, et al. SPIRE: Efficient data inference and compression over RFID streams[J]. IEEE Transactions on Knowledge and Data Engineering, 2012, 24(1): 141-155.
[10] ZHOU Aoying, JIN Cheqing, WANG Guoren, et al. A survey on the management of uncertain data[J]. Chinese Journal of Computers, 2009, 32(1): 1-16.
[11] LIAN Xiang, CHEN Lei, SONG Shaoxu. Consistent query answers in inconsistent probabilistic databases[C]// Proceedings of the International Conference on Management of Data. New York: Association for Computing Machinery, 2010: 303-314.
[12] Arenas M, Bertossi L, Chomicki J. Consistent query answers in inconsistent databases[C]// Proceedings of the Symposium on Principles of Database Systems, 1999: 68-79.
[13] Chen L, Tseng M, Lian X. Development of foundation models for internet of things[J]. Frontiers of Computer Science in China, 2010, 4(3): 376-385.
[14] л��. ��ȷ���Թ�ϵ���ݴ����о�[R]. ��ɳ: ���ϴ�ѧ��Ϣ��ѧ�빤��ѧԺ, 2010: 30-55.
XIE Dong. Research on uncertain relational data processing[R]. Changsha: Central South University. School of Information Science and Engineering, 2010: 30-55.
[15] XIE Dong, CHEN Xinbo, ZHU Yan. Tackling polytype queries in inconsistent databases: theory and algorithm[J]. Journal of Software, 2012, 7(8): 1861-1866.
[16] XIE Dong, Sheng Q Z, MA Jian-gang. A temporal-based model of uncertain RFID data[C]// Proceedings of the International Conference on Computer Science & Education. New York: Association for Computing Machinery, 2012: 847-850.
[17] Bowersox D J, Closs D J. Logistical management[M]. New York: McGraw-Hill, 1996: 55-80.
(�༭ �Կ�)
�ո����ڣ�2014-05-14�������ڣ�2014-07-20
������Ŀ(Foundation item)������ʡ��Ȼ��ѧ����������Ŀ(12JJ3057)������ʡ�ص㽨��ѧ��(�����Ӧ�ü���)������Ŀ(2011-2015)������ʡ�Ƽ��ƻ���Ŀ(2013NK3090)������ʡ���������л���������Ŀ(13A046) (Project(12JJ3057) supported by the Hunan Provincial Natural Science Foundation; Project(2011-2015) supported by the Construct Program of the Key Discipline ��Computer Application Technology�� in Hunan Province; Project(2013NK3090) supported by the Hunan Provincial Science and Technology Plan; Project(13A046) supported by the Research Foundation of Education Committee of Hunan Province)
ͨ�����ߣ�л������ʿ�������ڣ����������������ݹ����о���E-mail: dong.xie@hotmail.com
ժҪ����Կ��ٹ�Ӧ��Ӧ��ϵͳ�д�����ȷ����RFID���ݲ��ܱ���Ч���������⣬ͨ������RFIDӦ�õĹؼ����������ݷ�ȷ�������ݵı����������������ڣ����ò�ͬ���Դ�����ͬ���͵ķ�ȷ�������ݣ�����ɴ����������ͷ�ȷ�������ݵ���ϴ���������ݶ����ڹ�Ӧ���г��ֵ�λ�ü��������������ֶ����©���Ͳ��������ݣ����ڶ����������ڵ����ƶ�·����Ӧ������ͼ��һ���������Ӧ�������Ͷ����ƶ��Ĵ����㷨���о��������������ķ����������õ���ϴЧ�����洢Ч���Լ���ѯ���ܣ��ڲ�ͬ��������������Ч��֧�ֶ���·����ѯ��
