

J. Cent. South Univ. (2020) 27: 101-113
DOI: https://doi.org/10.1007/s11771-020-4281-6
Interaction behavior recognition from multiple views
XIA Li-min(������), GUO Wei-ting(�����), WANG Hao(����)
School of Automation, Central South University, Changsha 410083, China
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2020
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2020
Abstract:
This paper proposed a novel multi-view interactive behavior recognition method based on local self-similarity descriptors and graph shared multi-task learning. First, we proposed the composite interactive feature representation which encodes both the spatial distribution of local motion of interest points and their contexts. Furthermore, local self-similarity descriptor represented by temporal-pyramid bag of words (BOW) was applied to decreasing the influence of observation angle change on recognition and retaining the temporal information. For the purpose of exploring latent correlation between different interactive behaviors from different views and retaining specific information of each behaviors, graph shared multi-task learning was used to learn the corresponding interactive behavior recognition model. Experiment results showed the effectiveness of the proposed method in comparison with other state-of-the-art methods on the public databases CASIA, i3Dpose dataset and self-built database for interactive behavior recognition.
Key words:
Cite this article as:
XIA Li-min, GUO Wei-ting, WANG Hao. Interaction behavior recognition from multiple views [J]. Journal of Central South University, 2020, 27(1): 101-113.
DOI:https://dx.doi.org/https://doi.org/10.1007/s11771-020-4281-61 Introduction
In recent years, video-based human behavior analysis [1-8] has attracted widespread attention from computer vision researchers, since it has wide application prospects in the visual monitoring system, human-computer interaction, sports analysis and other aspects.
The changes of light and observation angle make the recognition difficulty increase in single-view environment. Moreover, it may not be able to capture the ideal behavior characteristics in the current observation angle. Therefore, many researchers have tried to use multi-view methods to solve such problems. SHEN et al [9] used the three-joint point set to represent the action pose and look for the invariant of the rigid motion consisting of a three-node set between two frames. LI et al [10] proposed a generative Bayesian model not only jointly taking the features and views into account, but also learning a discriminant representation across distinctive categories. LI et al [11] learned a low dimensional manifold and reconstructed the 3D model by modeling the dynamic process. These multi-view algorithms usually need to know the angle between different perspectives in advance, which severely limits their applications. Therefore, researchers pay more attention to view-invariant feature learning. For example, ZHENG et al [12] proposed source domains and target domains dictionaries that are simultaneously learned to constitute a convertible dictionary pair, so that the same action has the same sparse representation at two different perspectives. LIU et al [13] used a bidirectional graph to model visual word bags,which transformed a bag of visual-words (BOVW) action model into a bag of bilingual-words (BOBW) model with significant stability from different perspectives. JUNEJO et al [14] used a self-similarity matrix and a Support Vector Machine (SVM) classifier to assign a separated SVM classifier to each view, and apply a fusion method to achieve the final result. However, the correlation between different views is lacked. GAO et al [15] proposed a multi-view discriminative structured dictionary learning with group sparsity and graph model (GM-GS-DSD L). HSU et al [16] used a temporal-pyramid BOW to represent local spatio- temporal descriptors. HAO et al [17] utilized the sparse coding algorithm to transfer the low-level features of various views into the discriminative and high-level semantics space, and employed the multi-task learning approach for joint action modeling, while the divergence of low-level features in different perspectives will affect the action modeling.
At the same time, there are a lot of research results in the field of single-person behavior recognition, but few studies on interaction behavior recognition. In addition to the difficulties of motion recognition, such as the dithering of image acquisition equipment, the change of illumination intensity in the scene, and the occlusion of secondary object, the main problem in the recognition of two-person interaction behavior is to describe the body posture and complex spatio- temporal relationship. At present, there are two kinds of recognition methods for two-person interaction behavior. One is based on overall interaction recognition, while the other is based on individual segmentation. The former method mainly regards the two parts of the interaction behavior as a whole to describe the characteristics represented by overall spatio-temporal relationship, and recognizes interaction behavior by matching the test sample with the training sample. YU et al [18] used pyramid spatio-temporal relationship matching to check interactive actions. YUAN et al [19] proposed to construct spatio-temporal context kernel functions for interactive video matching and recognition. BURGHOUTS et al [20] improved the accuracy of interactive behavior recognition by introducing spatio-temporal layout to improve the inter-class discrimination ability of spatio-temporal features. LI et al [21] proposed a random forest method based on GA training and an effective spatio-temporal matching method to realize the recognition and understanding of interaction behavior. Overall methods treat the interactive behavior as a single-person action, without the need to separate the individual actions of the feature, and the processing idea is simple. However, the kind of method can not accurately represent the intrinsic attributes of interaction, which may cause limited accuracy. It often needs complex feature representation and matching methods to ensure accuracy. The latter is to understand the interaction behavior as a spatio-temporal combination between individual sub-actions. In the process of recognition, the meaning of a single individual action in the interaction behavior is recognized first, then the final recognition result is obtained by combining the spatio-temporal relationship between two individuals. KONG et al [22] proposed a training SVM based recognition model to identify interactive actions. SLIMANI et al [23] proposed a method based on symbiotic visual dictionary. The method is simple and easy to implement, but the recognition accuracy is limited. In a word, individual segmentation method either needs to track and detect the limbs of the human body, or needs to recognize the atomic movement. In complex interaction scenarios, it is difficult to get part of the human body and identify the atomic movement accurately due to occlusion and other factors.
In view of the advantages on multi-view recognition and the difficulties on interactive behavior recognition above, we propose a multi-view interactive behavior recognition method. In the process of bottom interactive feature extraction, the individual motion context and the global motion context of each video frame are spliced into composite interactive feature, which possess well discriminative description to represent complex interactive behavior. For solving the influence of observation angle changes on human interactive behavior recognition, self-similarity matrix (SSM) [14] based on composite interactive feature is constructed, since it has affine invariance and projection invariance. However, the absolute value of the self-similarity matrix element is related to the feature of each video frame, and further away from the diagonal elements, the less reliable the value. Therefore, we extract the local features on diagonal of SSM and represent them by temporal pyramid word-bag model to obtain view-invariant interactive features, which reduce the effect of high-speed motion and retain the temporal information. It only is robust to the changing view, but ignores the relevant information between different interactive behaviors and different views. To address this problem, we propose a graph shared multi-task learning function (GSMTL) and classify human interactive behavior by reconstruction of the minimum label information error. Our method is more discriminative for interactive behavior recognition and has well robustness to view changes.
2 Interactive behavior features
In order to describe interactive behavior in video frames, first we need to extract and track interest points from input image sequences. Then, the individual motion context and the global motion context are constructed since they have been proven to be efficient for capture motion relationships at the individual and global levels [24]. Finally, the two motion contexts are connected to composite interactive feature with a highly discriminative description.
2.1 Interest points detection
In the actual operation, the filter is obtained by transforming the scale factor of Gaussian kernel function [25], and then convoluted with the video sequence to get image sequences in different scales.
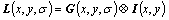 (1)
(1)
where L(x, y, ��) denotes the scale space; I(x, y) denotes the input image; G(x, y, ��) is a Gaussian kernel function with scale factor ��.
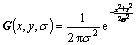 (2)
(2)
where �� is the scale factor and the Harris-Laplace multi-scale detection auto-correlation matrix [25] is:
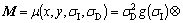
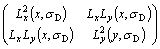 (3)
(3)
where x and y are the pixel coordinates of the image; ��I is the integral scale; ��D is the differential scale. Generally, ��I=s��D and the empirical value s=0.6. Multi-scale Harris detects the response of points on each scale space image.
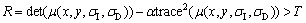 (4)
(4)
where ��=0.04-0.06; T is the threshold value used to control the number of extraction corner points. The larger the R is, the more likely it is the corner point.
2.2 Composite interactive feature extraction
After obtaining interest points and boundaries, we will use them to represent a video frame. Let Qt=(Bt, Pt) be the video frame of time duration t. Here, Bt are the set of boundaries and Pt are the interest points. Thus, Q=[Q1, Q2, ��, QT] denotes a video containing T frames. Now, we begin to construct individual movement context and global movement context.
First, the geometric centers of individual motion and global motion are calculated, as shown below:
 (5)
(5)
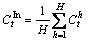 (6)
(6)
where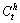 denotes geometric center position for the h-th human boundary and the t-th frame;
denotes geometric center position for the h-th human boundary and the t-th frame; 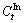 denotes average value of geometric center of the existing human objects for the t-th frame; and H is the number of people in video.
denotes average value of geometric center of the existing human objects for the t-th frame; and H is the number of people in video.
Next, the gradients between interest points and the individual motion center, the global motion center are calculated respectively in each frame (see Eqs. (7) and (8)).
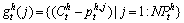 (7)
(7)
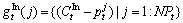 (8)
(8)
where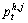 means the j-th interest point for the h-th boundary and the t-th frame;
means the j-th interest point for the h-th boundary and the t-th frame; 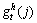 denotes the gradient between the centroid for the h-th boundary and the j-th interest point belonging to the h-th boundary;
denotes the gradient between the centroid for the h-th boundary and the j-th interest point belonging to the h-th boundary; 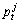 is the j-th interest point for the t-th frame;
is the j-th interest point for the t-th frame;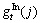 denotes the gradient between the global motion center and the j-th interest point.
denotes the gradient between the global motion center and the j-th interest point.
And 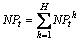 , where
, where 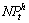 means interest
means interest
points for the h-th boundary and the t-th frame; NPt means all interest points for the t-th frame. Each motion context is a histogram of size NB, where NB indicates the number of sub-regions in the boundary with the geometric center as the reference point. For each frame, the two motion contexts are calculated as follows:
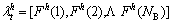 (9)
(9)
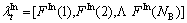 (10)
(10)
where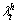 and
and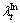 are the individual motion context and global motion context, respectively. Each bin of the histogram is the sum of the magnitude of gradients.
are the individual motion context and global motion context, respectively. Each bin of the histogram is the sum of the magnitude of gradients.
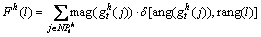 (11)
(11)
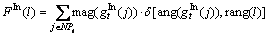 (12)
(12)
where mag(��) and ang(��) denote magnitude and angle of interest point gradient, respectively. 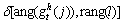 is an indicator function, it equals 1 when
is an indicator function, it equals 1 when 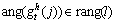 and 1, otherwise, it equals 0. rang(l) is the angle range of the l-th bin in histogram.
and 1, otherwise, it equals 0. rang(l) is the angle range of the l-th bin in histogram.
The final composite interactive feature vector for the t-th frame is represented by the concatenation of these two motion contexts, with a size of NB��(H+1).
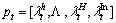 (13)
(13)
3 Self-similarity matrix representation of interaction behavior
The same human action will make different visual effect and lead to the differences of the feature extracted from interaction behavior, due to different taken angles. Self-similarity matrix reflects the relationship between image sequences, which has affine invariance and projection invariance. Feature self-similarity matrix discards the feature of the frame and only preserves the feature difference between frames. The feature difference is represented by the distance between the two feature descriptors and it has little to do with the view position. In the case of similar interactive behaviors at two different moments, it will be a short distance between the two feature descriptors. However, it will be a opposite situation for two different interactive behaviors. We use self- similarity matrix to describe interaction behavior, since it has a good performance on interaction behavior represented between different views.
3.1 SSM construction of composite interaction features
Given a video image sequence R={r1, r2, ��, rN}, SSM is defined as follows:
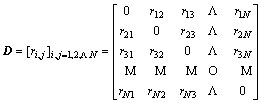 (14)
(14)
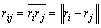 (15)
(15)
where ������ indicates the distance between low-level feature vectors. The elements on the diagonal should be zero, since they represent the distance between the feature vector and themselves. Meanwhile, the distance between ri and rj is equal which the distance between rj and ri. It is clear that D is a symmetric matrix. The mode of self- similarity matrix depends on the features and distance metrics.
In this paper, we define rij as the Euclidean distance between the composite interactive features. Therefore, the self-similarity matrix based on composite interactive feature is defined as follows:
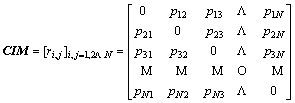 (16)
(16)
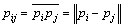 (17)
(17)
3.2 Local feature descriptor
The absolute values of the SSM��s elements are related to the features of each frame, and the further away from the diagonal, the less reliable the pixel. To solve this problem, JUNEJO et al [26] used the local feature descriptor to represent the self-similarity matrix. Each local descriptor is represented by a directional gradient histogram of a semicircle region image. The center of the semicircle region is on the diagonal of the self-similarity matrix (see Figure 1), and the diameter of the semicircle represents the time span. To obtain the vector 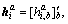 b=1, 2, ��, 8, we can make a calculation for the 8-direction gradient histogram for the i-th time at the region A. The local descriptor at the i-th time is derived from the sequentially connection of 11 region-histograms. If the region overflows the boundary of the self-similarity matrix, the vector of the region is set to a zero vector. In Ref. [26], to reduce the influence of motion speed, the temporal information is discarded and all local descriptors are used to compose bag-of-word to represent the features of the whole human movement. In the BOW method, a large number of local descriptors are randomly selected and a vocabulary containing K visual words is obtained by K-means clustering. In subsequent training and classification, each local descriptor is represented by a word nearest to it. All local descriptors are represented by the frequency of the occurrence of the word, forming a histogram of the frequency of the occurrence of the word. At this point, each video sequence can be represented by a histogram.
b=1, 2, ��, 8, we can make a calculation for the 8-direction gradient histogram for the i-th time at the region A. The local descriptor at the i-th time is derived from the sequentially connection of 11 region-histograms. If the region overflows the boundary of the self-similarity matrix, the vector of the region is set to a zero vector. In Ref. [26], to reduce the influence of motion speed, the temporal information is discarded and all local descriptors are used to compose bag-of-word to represent the features of the whole human movement. In the BOW method, a large number of local descriptors are randomly selected and a vocabulary containing K visual words is obtained by K-means clustering. In subsequent training and classification, each local descriptor is represented by a word nearest to it. All local descriptors are represented by the frequency of the occurrence of the word, forming a histogram of the frequency of the occurrence of the word. At this point, each video sequence can be represented by a histogram.
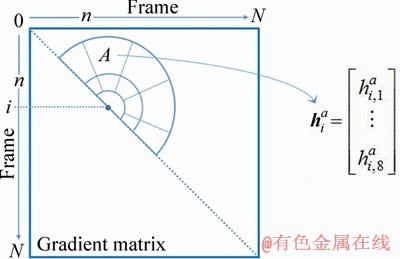
Figure 1 Local descriptor for self-similarity matrix
3.3 Temporal-pyramid BOW
Although the tradition BOW[27] method reduces the influence of motion speed, it ignores the temporal information, which leads to a low ability to recognize interactive behavior in reverse time sequence. In this work, the temporal-pyramid BOW (see Figure 2) is applied to describing the local SSM features, which is a coarse-to-fine representation consisting of the different levels connection of all histograms derived from diverse time slices. Supposing that there are L levels in the pyramid structure, we divide entire interactive behavior features into 2l partial feature slices for level l, where 0��l��L-1. A standardized histogram is calculated from each slice, and the histograms of all segments are joined together to construct temporal- pyramid BOW model. Temporal-pyramid BOW differs from the traditional BOW method in which it retains temporal information of interactive behavior with two or more higher levels because of more time segments, while at level 0, it��s only a traditional BOW providing tolerance of variation of temporal pattern. We can maintain the superiority of different levels by combining with these levels. The final view-invariant interactive behavior feature x is represented by the different levels connection of all histograms derived from diverse time slices with dimension of K��(2L-1). K is size of BOW model codebook.
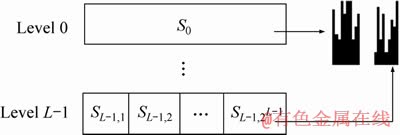
Figure 2 Temporal-pyramid BOW model
4 Interactive behavior recognition based on multi-view and graph shared multi- task learning
The view-invariant interactive feature was obtained in the previous section only by considering the robustness of the same interactive behavior under different views, while ignoring the related information between different interactive behaviors and different views. In this section, we propose a graph shared multi-task learning algorithm, which explores potential relationships from different views by grouping video samples of different views into the graph set [28], and mines the correlation between different interactive behaviors and retain the unique information of each behavior by learning the corresponding interactive behavior recognition model.
4.1 Objective function
In this work, assume that there are J interactive behaviors in V views. For each type of interactive behavior, V video sample can be obtained at the same time, and video interactive feature in each single view is defined as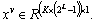 Based on the above ideas, we collectively formulate the multi-task learning model as
Based on the above ideas, we collectively formulate the multi-task learning model as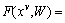
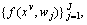 where
where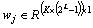 is the model for the j-th task;
is the model for the j-th task;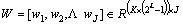 is the model for joint MTL problem;
is the model for joint MTL problem; 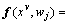
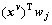 denotes a single-task learning model based on paired features, which can be defined as a linear prediction model;
denotes a single-task learning model based on paired features, which can be defined as a linear prediction model;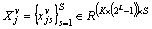 denotes the feature set for the j-th task and the v-th view, where S is the number of samples.
denotes the feature set for the j-th task and the v-th view, where S is the number of samples. 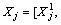
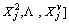 contains the specific partwise features of all training samples in multiple views for the j-th model learning.
contains the specific partwise features of all training samples in multiple views for the j-th model learning.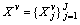 denotes the feature set for entire interactive behavior training set for the v-th view.
denotes the feature set for entire interactive behavior training set for the v-th view.
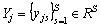 is the corresponding labels of the j-th task and
is the corresponding labels of the j-th task and 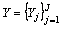 corresponds the labels for all tasks. In this work, the shared information of all tasks and the specific information of each task are studied at the same time, that is wj=u+vJ, where the model parameter wj of each task is composed of the shared information u of all tasks and the specific information vj of each task. In addition, in order to explore the potential relationship between different views, the video samples from different views were built into a graph set, and different coefficients were distributed in each sample. Therefore, we formulate the objective function as:
corresponds the labels for all tasks. In this work, the shared information of all tasks and the specific information of each task are studied at the same time, that is wj=u+vJ, where the model parameter wj of each task is composed of the shared information u of all tasks and the specific information vj of each task. In addition, in order to explore the potential relationship between different views, the video samples from different views were built into a graph set, and different coefficients were distributed in each sample. Therefore, we formulate the objective function as:
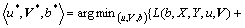
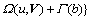 (18)
(18)
where L(b, X, Y, u, V) means the empirical loss function of joint multi-task learning and can be computed by 
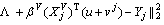 where b=[��1, ��2, ��, ��V] denotes the weight of each view which is automatically learned. Thus, this term enables to be rewritten as
where b=[��1, ��2, ��, ��V] denotes the weight of each view which is automatically learned. Thus, this term enables to be rewritten as 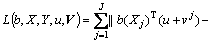
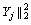 .
.
Besides, objective function has two penalty terms:
1)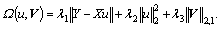 The first term is used to limit the error of the shared part model parameters; the second term is used to control the model complexity of the shared part; and the third term is used to limit the columns of the matrix V. Each column of V can be viewed as a specific feature of each task. If the J tasks are similar, the number and value of non-zero columns in V should be small. When all tasks are equal, the matrix V should approach a zero matrix.
The first term is used to limit the error of the shared part model parameters; the second term is used to control the model complexity of the shared part; and the third term is used to limit the columns of the matrix V. Each column of V can be viewed as a specific feature of each task. If the J tasks are similar, the number and value of non-zero columns in V should be small. When all tasks are equal, the matrix V should approach a zero matrix.
2) Convex hull term (CHT) ��(b). In this section, we constructed a convex hull term for evaluating the interaction behavior correlation from different views. The sum of sub-term is estimated as 1. And in Eq. (18), the model will reconstruct all samples from different views for the j-th task. Meanwhile, all vectors will be adjusted appropriately. Thus, not only the correlation between different views will be mined, but also different samples could be combined together.
Therefore, CHT can be defined as 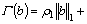
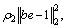 meaning sum of every regular constants
meaning sum of every regular constants
and control weighted coefficient. The first term in ��(b) is used to control sparsity. The corresponding coefficient will be small if the correlation between samples is not strong. Thus, this sample could be considered having low impact. The sum of second terms is used to make sum of all convex coefficients equal to 1.
In summary, the objective function Eq. (18) can be further defined as Eq. (19):
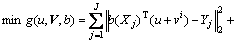
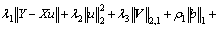
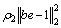 (19)
(19)
4.2 Solution
In order to solve the energy minimization problem of the objective function, the iterative minimization method [29] is used to solve the three parameters, b, u and V in Eq. (18). Specifically, the following two steps are repeated until convergence:
1) fixing b, minimizing 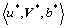 over u and V;2) fixing u and V, minimizing over b.
over u and V;2) fixing u and V, minimizing over b.
When b is fixed, Eq. (19) can be explicitly abbreviated to Eq. (20):
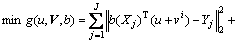
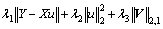 (20)
(20)
The optimization problem in Eq. (20) can be solved by the accelerated proximal method (APM). Because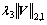 is a non-smooth convex function, Eq. (20) is divided into two parts:
is a non-smooth convex function, Eq. (20) is divided into two parts:
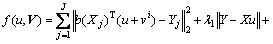
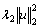 (21)
(21)
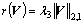 (22)
(22)
Linearizing Eq. (21) obtains:
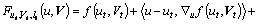
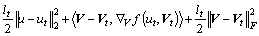 (23)
(23)
where ut and Vt represent the values of u and V at the t-th iteration; lt stands for step size. Thus, it can be obtained:
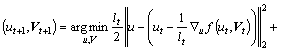
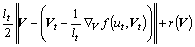 (24)
(24)
Finally, we can get:
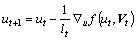 (25)
(25)

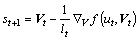 (26)
(26)
Furthermore, when u and V are fixed, we transform the objective function Eq. (18) into the following form:
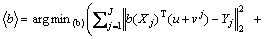
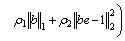 (27)
(27)
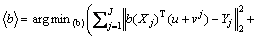
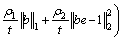 (28)
(28)
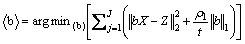 (29)
(29)
where 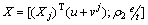 and
and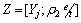 . By some L1-minimization methods including gradient descent algorithm and Least angle regression [30], the problem in Eq. (29) can be easily solved.
. By some L1-minimization methods including gradient descent algorithm and Least angle regression [30], the problem in Eq. (29) can be easily solved.
4.3 Human interactive behavior recognition
The corresponding model wj=u+vJ and b can be established by graph shared multi-task learning function. In the process of prediction and recognition, the J prediction label, which is obtained by multiplying the test sample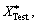 and each task model parameter wj=u+vJ subtract the real labels of test samples and then choose the minimum interactive behavior label as the label of test samples. Finally, to judge whether the predicted labels are consistent with real labels, make use of the final recognition rate which is the result of the figure for correctly predicted samples divided by the total number of predicted samples.
and each task model parameter wj=u+vJ subtract the real labels of test samples and then choose the minimum interactive behavior label as the label of test samples. Finally, to judge whether the predicted labels are consistent with real labels, make use of the final recognition rate which is the result of the figure for correctly predicted samples divided by the total number of predicted samples.
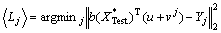 (30)
(30)
5 Experiment
To verify the effectiveness of the proposed method, we conducted experiments on the CASIA dataset and the i3Dpose dataset. Considering the limitation of video quantity in these two datasets, this work adopts leave-one-out cross validation strategy to evaluate the performance.
5.1 CASIA dataset
The CASIA behavior analysis database [31] has a total of 1446 video data, which is captured by cameras in horizontal, angle and top down view in outdoor environment, providing experimental data for behavioral analysis. The data are divided into single-person behaviors and interactive behaviors. Single-person behavior includes walking(1), running(2), bending(3), jumping(4), crouching(5), fainting(6), wandering(7) and punching(8). There are 24 people involved in each type of behavior, about 4 times per person. Interactive behaviors consist of robing(9), fighting(10), following(11), follow and gathering(12), meeting and parting(13), meeting and gathering(14) and overtaking(15). The frame rate is 25fps and the resolution is 320�� 240. The operation example is shown in Figure 3.
5.2 i3Dpose dataset
The i3Dpose dataset [32] contains 12 different behaviors, including 6 single behaviors: walking, running, jumping forward, jumping in place, bending, and one hand waving. Four hybrid activities are sitting down-standing up, walking- siting down, running-falling and running-jumping- walking. Two interactive activities are two persons handshaking and one person pulling another. Camera setups are labeled on Figures 4(a)-(h). Eight amateurs (2 females and 6 males) are participated 13 times for every action. We only test interactive behaviors.
5.3 Self-built dataset
Because there are few data sets for interactive behavior under multiple views, we have built a multi-view database. The self-built data set was shot and established by us on the lawn of Central South University, with a total of 1200 pieces of video data. All video was shot simultaneously from two different angles by two un-calibrated static cameras, with a frame rate of 25fps and a video image resolution of 640��480. The data are divided into single-person behavior and multi-person behavior. Single-person behaviors include walking, running, jumping, squatting, fainting, wandering. For each type of behavior, 10 people are separately photographed, about 4 times per person. Multi- person behaviors include robing, fighting, tailing, many people walking, chatting and playing badminton. Each behavior is filmed 5-6 times. Figure 5 shows some examples of the behavior for a self-built data set.
5.4 Selection of parameters
Firstly, the hierarchical L and the codebook size K of the temporal pyramid bag-of-word are determined by experiments on the i3Dpose dataset. N is the video frames size, and the fixed step size is set to 2 when extracting the local descriptor of self-similarity matrix. Figure 6 shows the testing results on the i3Dpose database. It can be seen from the graph that interactive behavior recognition rate is the highest which ups to 95.12% when L=2 and K=400. In the subsequent experiments, we all set with this parameter.
5.5 Comparison of different interaction features
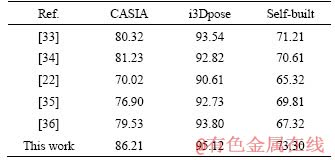
Our method is compared with other advanced interactive feature extraction methods. SAEID et al [33] represented interactions by forming temporal trajectories, coupling together the body motion of each individual and their proximity relationships with others; In Ref. [34], a novel representation based on hierarchical histogram of local feature sequences was proposed for human interaction recognition; KONG et al [22] proposed a discriminative model to encode interactive phrases based on the latent SVM formulation; JI et al [35] proposed a contrastive feature distribution model (CFDM) for interaction recognition. A novel feature descriptor based on spatial relationship and semantic motion trend similarity between body parts was proposed for human-human interaction recognition in Ref. [36]. The comparison results are shown in Table 1. The proposed compositional interactive feature descriptors contain inter-class and intra-class variations, representing motion relationships at the individual and global levels, which are highly discriminatory. Secondly, i3Dpose datasets are collected indoors and CASIA are collected outdoors result in complex background, which increase the difficulty in recognition accuracy. Therefore, the recognition results on i3Dpose datasets are better than those on CASIA datasets.

Figure 3 Samples on CASIA dataset(robing, punching a car):

Figure 4 Samples on i3Dpose dataset of shaking hands

Figure 5 Samples on self-built dataset of fighting (a, b) and robing (c, d)
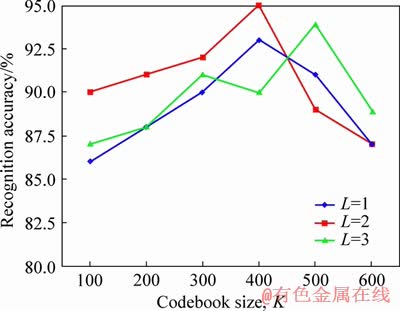
Figure 6 Parameter setting of temporal pyramid bag-of-word model
Table 1 Recognition accuracy of different interaction features (%)
5.6 Influence of different view fusion methods on recognition
We compared the proposed method with some other up-to-date multi-view information fusion methods. FV is combined with sparse coding, and finally SRMTL is used to classify human behavior [17]; GM-GS-DSDL is a multi-view discriminant structured dictionary learning based on group sparse and graph model [15], which is used to fuse different views and recognize human actions human behavior; MDVSD aims to learn a structured dictionary shared by all views and multiple view-specific structured dictionaries with each corresponding to a dictionary [37]. The results are shown in Tables 2-4. The optimal recognition rates are 86.21%, 95.12% and 73.3% respectively. The reason is that the more the views are used as training data, the richer the view information contained in action recognition model is. Our method is superior to FV with sparse coding. Because a specific action was recorded from various camera views, the appearance of the action would be completely different, and finally the completely different FV underlying features will be obtained, which will reduce the human action recognition rate. However, the self-similarity matrix consists of the Euclidean distances between the compositional interactive feature descriptor, which changes less with the variation of the viewing angle. As shown in Tables 2-4, the combination interaction feature self-similar matrix has good robustness to the change of the viewing angle, and performs well on interactive human behavior recognition under multiple views, with the recognition rate as high as 86.21%, 95.12% and 73.3%.
5.7 Comparison of different multi-task functions
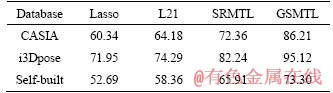
We also used GSMTL, Lasso, L21 and SRMTL to learn the action recognition model to verify the superiority of the GSMTL method. The combination of perspectives with the highest recognition rates in Section 5.6 were viewed as training data. Lasso method was introduced sparsity into the multi-task learning model and aims to reduce the complexity of the model and feature learning. The L21 norm regularization approach captured the common problems of multiple related tasks by limiting all models and shared the same feature set. The SRMTL assumes that all tasks are related and the model of each task is close to the average of all task models. As shown in Table 5, the performance of the GSMTL method is slightly higher than that of other methods because GSMTL considers not only the common information of all tasks, but also the characteristic information of each task, making the model parameters of each task more discriminant.
Table 2 Recognition accuracy of different view fusion methods on CASIA (%)
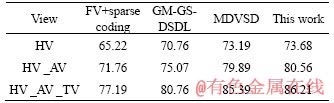
Table 3 Recognition accuracy of different view fusion methods on i3Dpose (%)
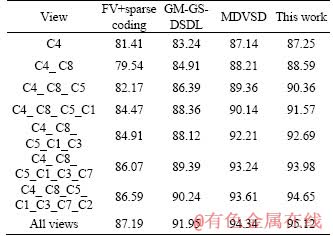
Table 4 Recognition accuracy of different view fusion methods on self-built database

Table 5 Recognition accuracy of different multi-task functions (%)
5.8 Comparison of different methods
Tables 6 and 7 show the confusion matrix on CASIA data set and self-built database, from which we could find the overall accuracy rates were 86.21% and 73.3%.
Table 6 Confusion matrix on CASIA
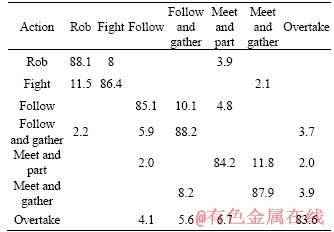
Table 7 Confusion matrix on self-built database
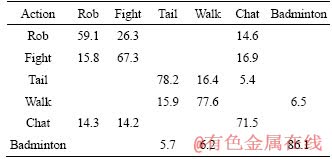
The proposed method had also been compared with other advanced methods. From Tables 6 and 7, we can clearly observe that the overall recognition rate of the proposed method is higher than that of other multi-view methods with an accuracy of 86.21% and 73.3%. Local motion and context information of interest points collected by Harris- Laplace algorithm are encoded at individual and global levels, describing the interaction behavior accurately. Local descriptors abstracted from self-similarity matrix are robust to the changing views. The graph shared multi-task learning explores the potential correlation between different actions and retain specific information of each task, making human behavior recognition more discriminatory. Therefore, our proposed method improves the accuracy of interactive behavior recognition under the change of views.
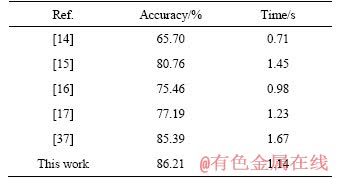
Then, we tested the computational complexity on the CASIA dataset, and calculated the average of the six methods respectively. It can be seen from the Table 8 that the calculation time of method in Ref. [15] is long because the GM-GS-DSDL used the graph algorithm and constructed the discriminative structured dictionary, which consumed a lot of time. In Ref. [17], the computational complexity of fisher vector is relatively large but sacrifices the recognition rate compared with GSMTL, CMTL decreases time. Our method used temporal-pyramid BOW to describe the local feature of self-similarity matrix and utilized the accelerated proximal method to optimize the graph shared multi-task learning function, so the calculation speed is faster.
Table 8 Comparison of different methods
6 Conclusions
This paper suggests a novel multi-view interactive behavior recognition method based on self-similarity matrix and graph shared multi-task learning function. The main work is as follows:
1) The proposed composite interactive feature describes the interaction motion at individual and global levels.
2) The self-similarity matrix represented by local feature descriptors is constructed to reduce the difference of the same interactive behavior caused by the changing view. Compared with other multi-view methods, the proposed method does not need to reconstruct the 3D model and not to calculate the relationship between different views.
3) In order to discover latent correlation among different interactive behaviors and retain specific information of each task, the corresponding interactive behavior recognition model is learned by using the graph shared multi-task learning function, and the minimum reconstruction of tag information error is used to classify human behavior.
4) The proposed method can achieve competing performance against the state-of-the-art methods for interactive behavior recognition on CASIA, i3Dpose and self-built database.
References
[1] FERNANDO I, RICARDO P. Human actions recognition in video scenes from multiple camera viewpoints [J]. Cognitive Systems Research, 2019, 56: 223-232. DOI: 10.1016/ j.cogsys.2019.03.010.
[2] LIN Bo, FANG Bin, YANG Wei-bin. Human action recognition based on spatio-temporal three-dimensional scattering transform descriptor and an improved VLAD feature encoding algorithm [J]. Neurocomputing, 2019, 348: 145-157. DOI: 10.1016/j.neucom.2018.05. 121.
[3] HAN Fei, REILY B, HOFF W, ZHANG Hao. Space-time representation of people based on 3D skeletal data: A review [J]. Computer Vision & Image Understanding, 2017, 158(3): 85-105. DOI: 10.1016/j.cviu.2017.01.011.
[4] LIU J, WANG G. Skeleton based human action recognition with global context-aware attention LSTM networks [J]. IEEE Transactions on Image Processing, 2018, 27(4): 1586-1599.
[5] AMIRA B M, EZZEDDINE Z. Abnormal behavior recognition for intelligent video surveillance systems: A review [J]. Expert Systems with Applications, 2018, 91: 480-491. DOI: 10.1016/j.eswa.2017.09.029.
[6] LUVIZON D C, TABIA H, PICARD D. Learning features combination for human action recognition from skeleton sequences [J]. Pattern Recognition Letters, 2017, 99: 13-20. DOI: 10.1016/j.patrec.2017.02.001.
[7] HUANG Z W, WAN C D. Deep learning on lie groups for skeleton-based action recognition [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA��IEEE, 2017: 1243-1252.
[8] SHAHROUDY A , LIU J. NTU RGB+D: A large scale dataset for 3D human activity analysis [C]// IEEE Conference on Computer Vision and Pattern Recognition. Seattle, WA: IEEE, 2016: 1010-1019.
[9] SHENY P, FOROOSH H. View-invariant action recognition from point triplets[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2009, 31(10): 1898-1905.
[10] LI Jin-xing, ZHANG Bob, ZHANG David. Generative multi-view and multi-feature learning for classification [J]. Information Fusion, 2018, 45: 215-226. DOI: 10.1016/ j.inffus.2018.02.005.
[11] LI R, TIAN T, SCLAROFF S. Simultaneous learning of nonlinear manifold and dynamical models for high-dimensional time series [C]// 11th IEEE International Conference on Computer Vision. Rio de Janeiro, BRAZIL: IEEE, 2007:1687-1694.
[12] ZHENG J J, JIANG Z L, PHILLIPS J. Cross-view action recognition via a transferable dictionary pair [C]// 23rd British Machine Vision Conference. Guildford, England: Springer-Verlag, 2012: 1-10.
[13] LIU J G, SHAH M, KUIPERS B. Cross-view action recognition via view knowledge transfer [C]// 2011 IEEE Conference on Computer Vision and Pattern Recognition. NJ, USA : IEEE, 2011: 3209-3216.
[14] JUNEJO I N, DEXTER E, LAPTEV I. Cross-view action recognition from temporal self-similarities [C]// The European Conference on Computer Vision. Marseille, France: Springer, 2008:293-306.
[15] GAO Zan, ZHANG Hua, XU Guang-ping. Multi-view discriminative and structured dictionary learning with group sparsity for human action recognition [J]. Signal Processing, 2015, 112: 83-97. DOI: 10.1016/j.sigpro. 2014.08.034.
[16] HSU Yen-pin, LIU Cheng-yin, CHEN Tzu-yang. Online view-invariant human action recognition using rgb-d spatio-temporal matrix [J]. Pattern Recognition, 2016, 60: 215-226. DOI: 10.1016/j.patcog.2016.05. 010.
[17] HAO Tong, WU Dan, WANG Qian, SU Jin-sheng. Multi-view representation learning for multi-view action recognition [J]. J Vis Commun Image R, 2017, 48: 453-460. DOI: 10.1016/j. jvcir.2017.01.019.
[18] YU T H, KIM T K, CIPOLLA R. Real-time action recognition by spatiotemporal semantic and structural forests [C]// Proceedings of the 21st British Mac hine Vision Conference. United Kingdom: Springer-Verlag, 2010: 1-12. DOI: 10.5244/C.24.52.
[19] YUAN F, SAHBI H, PRINET V. Spatio-temporal context kernel for activity recognition [C]// Proceedings of the 1st Asian Conference on Pattern Recognition. Beijing, China: IEEE, 2011: 436-440.
[20] BURGHOUTS G J, SCHUTTE K. Spatio- temporal layout of human actions for improved bag-of-words action detection [J]. Pattern Recognition Letters, 2013, 34(15): 1861-1869. DOI: 10.1016/j.patrec.2013.01. 024.
[21] LI N J, CHENG X, GUO H Y, WU Z Y. A hybrid method for human interaction recognition using spatio-temporal interest points [C]// The 22nd International Conference on Pattern Recognition. Stockholm, Sweden: IEEE, 2014: 2513-2518.
[22] KONG Yu, JIA Yun-de, FU Yun. Interactive phrases: semantic descriptions for human interaction recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(9): 1775-1788. DOI: 10.1109/ TPAMI.2014.230 3090.
[23] SLIMANI K, BENEZETH Y, SOUAMI F. Human interaction recognition based on the co-occurrence of visual words [C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition Workshops. Columbus, Ohio, USA: IEEE, 2014: 461-469. DOI: 10.1109/CVPRW. 2014.74.
[24] CHO N G, PARK S H, PARK J S. Compositional interaction descriptor for human interaction recognition [J]. Neurocomputing, 2017, 267: 169-181. DOI: 10.1016/j.neucom.2017.06.009.
[25] HARRIS C, STEPHENS M J. A combined corner and edge detector [C]// Proceedings of Fourth Alvey Vision Conference. Manchester, England: IEEE, 1988: 147-151. DOI: 10.5244/C.2.23.
[26] JUNEJO I, DEXTER E, LAPTEV I. Cross-view action recognition from temporal self-similarities [C]// European Conference on Computer Vision. Berlin: Springer-Verlag, 2008: 293-306. DOI: 10.1007/978-3-540- 88688-4_22.
[27] LAPTEV I, MARSZALEK M, SCHMID C. Learning realistic human actions from movies [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, AK: 2008: 1-8. DOI: 10.1109/ CVPR.2008. 4587756.
[28] HU YQ, AJMAL S, ROBYN O. Sparse approximated nearest points for image set classification [C]// IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, CO: IEEE, 2011: 121-128.
[29] WRIGHT J, YANG A, GANESH A. Robust face recognition via sparse representation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(2): 210-227.
[30] HUANG Zhi-wu, WANG Rui-ping, SHAN Shi-guang. Face recognition on large-scale video in the wild with hybrid Euclidean-and-Riemannian metric learning [J]. Mixture Research Article Pattern Recognition, 2015, 48(10): 3113-3124. DOI: 10.1016/j.patcog.2015.03. 011.
[31] ZHANG Z, HUANG K Q, TAN T N. Multi-thread parsing for recognizing complex events in videos [C]// European Conference on Computer Vision. Marseille, France:Springer,2008: 738-751.
[32] NIKOLAOS G, HANSUNG K, ADRIAN H. The i3DPost multi-view and 3D human action/interaction database [C]// 2009 Conference for Visual Media Production. London, England: IEEE, 2009:159-168.
[33] SAEID M, FARZAD S, RANYA A. Online human interaction detection and recognition with multiple cameras[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 27(3): 649-663.
[34] CAVENT A, IKIZLER N. Histograms of sequences: A novel representation for human interaction recognition [J]. IET Computer Vision, 2018, 12(6): 844-854.
[35] JI Yan-li, CHENG Hong, ZHENG Ya-li, LI Hao-xin. Learning contrastive feature distribution model for interaction recognition [J]. Journal of Visual Communication and Image Representation, 2015, 33: 340-349. DOI: 10.1016/j.jvcir.2015.10.001.
[36] LIU B L, CAI H B, JI X F, LIU H H. Human-human interaction recognition based on spatial and motion trend feature [C]// IEEE International Conference on Image Processing. Beijing, China: IEEE,2017: 4547-4551.
[37] WU Fei, JING Xiao-yuan, YUE Dong. Multi-view discriminant dictionary learning via learning view-specific and shared structured dictionaries for image classification [J]. Neural Process Lett, 2017, 45(2): 649-666. DOI: 10.1007/ s11063-016-9545-7.
(Edited by ZHENG Yu-tong)
���ĵ���
���ӽ��µĽ�����Ϊʶ��
ժҪ�����������һ�ֻ��ھֲ���������������ͼ����������ѧϰ�Ķ��ӽǽ�����Ϊʶ�������ȣ������һ�ָ��Ͻ���������ʾ�������÷�������Ȥ��ֲ��˶��Ŀռ�ֲ����������Ľ��б��롣��Σ�Ϊ�˼�С�۲�Ƕȱ仯��ʶ���Ӱ�첢����ʱ����Ϣ����ʱ��������ʴ�ģ�ͶԾֲ����������������б�ʾ��Ϊ�˴Ӳ�ͬ���ӽ�̽����ͬ������Ϊ֮���DZ�ڹ�����������ÿ�ֽ�����Ϊ���ض���Ϣ������ͼ����������ѧϰѧϰ��Ӧ�Ľ�����Ϊʶ��ģ�͡�����������÷�����CASIA��i3Dpose�������ݼ����Խ�������Ϊʶ�����ݿ��������������ʶ���ʸ��ߡ�
�ؼ��ʣ��ֲ���������������ͼ����������ѧϰ�����Ͻ���������ʱ��������ʴ�ģ��
Foundation item: Project(51678075) supported by the National Natural Science Foundation of China; Project(2017GK2271) supported by Hunan Provincial Science and Technology Department, China
Received date: 2018-11-05; Accepted date: 2019-06-16
Corresponding author: XIA Li-min, PhD, Professor; Tel: +86-13974961656; E-mail: xlm@mail.csu.edu.cn; ORCID: 0000-0002-2249- 449X
Abstract: This paper proposed a novel multi-view interactive behavior recognition method based on local self-similarity descriptors and graph shared multi-task learning. First, we proposed the composite interactive feature representation which encodes both the spatial distribution of local motion of interest points and their contexts. Furthermore, local self-similarity descriptor represented by temporal-pyramid bag of words (BOW) was applied to decreasing the influence of observation angle change on recognition and retaining the temporal information. For the purpose of exploring latent correlation between different interactive behaviors from different views and retaining specific information of each behaviors, graph shared multi-task learning was used to learn the corresponding interactive behavior recognition model. Experiment results showed the effectiveness of the proposed method in comparison with other state-of-the-art methods on the public databases CASIA, i3Dpose dataset and self-built database for interactive behavior recognition.
