
DOI: 10.11817/j.issn.1672-7207.2020.01.009
基于最大互信息系数属性选择的冷轧产品机械性能预测
颜弋凡,安路达,吕志民
(北京科技大学 钢铁共性技术协同创新中心,北京,100083)
摘要:对于冷轧产品机械性能预测建模时面对的需要对全流程众多影响工艺参数属性选择的问题,提出基于最大互信息系数(MIC)属性选择的机械性能预测建模方法。该方法首先利用MIC算法计算各性能指标和工艺参数之间的相关性度量,然后根据各相关度量选择形成工艺参数属性子集用于性能预测模型建模及预测。研究结果表明:该建模方法构建的冷轧产品性能预测模型的预测精度高于全工艺参数模型、Pearson相关系数选择和经验知识选择,另外该方法也能选择出一些传统方法不能选择出的非线性影响关系的工艺参数。最优特征子集模型预测效果从原始全工艺参数模型的平均相对误差2.90%下降到2.30%。
关键词:最大互信息系数;冷轧;机械性能预测;属性选择
中图分类号:TF089 文献标志码:A 开放科学(资源服务)标识码(OSID)
文章编号:1672-7207(2020)01-0068-08
Prediction of mechanical properties of cold rolled products based on maximal information coefficient attribute selection
YAN Yifan, AN Luda, LU Zhimin
(Collaborative Innovation Center of Steel Technology, University of Science and Technology Beijing, Beijing 100083, China)
Abstract: The selection of process parameters in the throughout manufacturing process influenced the accuracy of prediction model of the mechanical properties of cold rolled products. A mechanical properties prediction modeling method was proposed based on the maximal information coefficient (MIC) attribute selection. Firstly, the MIC algorithm was used to calculate the correlation metric between each mechanical property index and process parameters, and then the relevant metrics ware selected to form a subset of process parameter attributes for mechanical properties prediction modelling. The results show that the prediction accuracy of the cold rolling product properties prediction model constructed by the modeling method is higher than the full process parameter model, Pearson correlation coefficient selection and empirical knowledge selection. In addition, the method can also select some process parameters with nonlinear influence relationships between mechanical property indexes that cannot be selected by the traditional method. The optimal feature subset model prediction effect decreases from the mean relative error of the original full process parameter model by 2.90% to 2.30%.
Key words: maximal information coefficient; cold rolling; mechanical property prediction; feature selection
随着市场对钢铁产品的质量要求不断升级,客户对板形、几何精度、表面质量等产品外观质量以及屈服强度、抗拉强度和伸长率等机械性能指标以及金相组织等质量指标要求越来越趋于定制化。对产品机械性能进行准确预测,减少抽样检测成本成为企业提高产品稳定性的重要手段[1]。冷轧产品作为一类重要的钢材产品,其生产流程长、产品质量好、附加值高,已经成为企业体现企业竞争力的重要产品。钢铁生产全流程中影响产品质量的工艺数据具有多源异构、高维、强相关、工序间遗传等特点[2],预测建模时必须先从众多的属性集中选择出合适的特征子集,才能提高机械性能预测模型的精确度和计算效率[3]。目前已有许多学者针对数据建模过程提出了一些不同的属性选择方法。BERETTA等[4]比较了原始Relief F算法和改进的Relief F算法选择正确属性的能力,并分析了具体原因;针对属性与标签的非线性影响关系,GUYON等[5]采用了核方法对模型的输入变量进行选择;ALIFERIS等[6]讨论了解决多分类问题的属性选择方法。一些研究表明,不同的属性选择方法对特定的分类器获得良好的性能影响不同[7];还有一些研究尝试解决针对样本或属性数量庞大或属性多样本少的高维数据问题[8]。但是目前对于冷轧产品的机械性能预测建模多是基于传统的经验知识确定影响的工艺参数进行建模,常用方法是通过轧钢原理结合物理模型来研究工艺参数与性能指标之间的关系或者将机理模型与智能算法的结合进行改进[9]。由于数据和经验等因素影响,这些机理模型基于简化的抽象和经验,对一些工艺参数关注明显不足。另外,与传统方法相比,一些根据实际生产过程特点采用多输入层遗传神经网络建立机械性能预报模型的研究虽然效果有所改进[10],但多数仍采用传统经验知识进行属性选择所得到的特征子集。针对目前许多企业构建产品质量大数据或全流程质量数据平台情况下,冷轧产品制造全流程中可能影响产品质量的工艺参数可以方便获取的前提,如何利用数据之间关系从更多属性选择更有效的产品质量影响因素,提高预测模型预测精度问题成为可能,本文作者提出采用最大互信息系数(maximal information coefficient,MIC)的方法对某钢铁企业冷轧产品制造全流程中的工艺参数进行选择进行机械性能预测建模的方法。该方法的特点是通过计算每个工艺参数与机械性能之间的MIC,根据MIC选择出最优特征子集后再进行后续的机器学习工作。对比其他方法得到的特征子集的预测结果,验证基于MIC方法的属性选择得到的工艺参数最优特征子集可以明显提高冷轧产品机械性能预测精度。
1 最大互信息系数及其计算方法
1.1 互信息
互信息(mutual information,MI)是衡量2个随机变量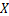 和
和 中一个随机变量由于另一个随机变量发生改变而自身随之改变的程度[11-12],其计算方式为
中一个随机变量由于另一个随机变量发生改变而自身随之改变的程度[11-12],其计算方式为
 (1)
(1)
式中: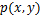 为和的联合概率分布;
为和的联合概率分布; 和
和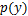 分别为和的边缘概率分布。
分别为和的边缘概率分布。
互信息(MI)可以量化2个随机变量间相关程度,当互信息为0时说明和相互独立;互信息越大,说明和两者之间的相关程度越高[13]。但是互信息并没有上界,所以不能简单地通过互信息来划分特征子集的选择范围,对于属性选择过程则需要将互信息的上限固定才能应用。
1.2 最大互信息系数及其计算方法
RESHEF等[14]提出用最大互信息系数(maximum information coefficient,MIC)来衡量变量之间线性或非线性相关的程度。MIC是互信息的推广,由于MIC的范围为[0,1],因此,它比互信息更具有一般性和公平性。
MIC计算采用非等间隔寻优的方法求出2个变量之间的互信息,然后对求出的值进行归一化处理[15]。对于随机变量和之间MIC的计算方法为:
1) 将随机变量和两者的数据取出来组成数据集 ,并将数据集按一定的顺序进行排序;
,并将数据集按一定的顺序进行排序;
2) 将随机变量等分为 份,将等分为
份,将等分为 份,不同的间隔划分方法可以得到不同数量的网格,网格数量越多互信息也会越大,但总的网格数量
份,不同的间隔划分方法可以得到不同数量的网格,网格数量越多互信息也会越大,但总的网格数量 应满足:
应满足:
 (2)
(2)
为了简化计算过程,先将和初始值分别取为
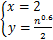 (3)
(3)
3) 在计算完当前的划分方式后将增加1,则:
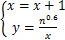 (4)
(4)
当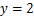 时停止网格的划分。
时停止网格的划分。
4) 在每种划分情况下,通过第 位置格子里面点的数量除以总点数的计算方式求出该格子的概率
位置格子里面点的数量除以总点数的计算方式求出该格子的概率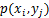 ,该格子所在列的概率
,该格子所在列的概率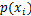 则为落在该列里面的点的数量除以总点数,同理也可以求出所在行的概率
则为落在该列里面的点的数量除以总点数,同理也可以求出所在行的概率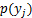 ,当前划分方式下的概率分布则为
,当前划分方式下的概率分布则为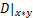 ,通过互信息计算公式求出当前划分的互信息
,通过互信息计算公式求出当前划分的互信息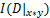 ,找出所有划分情况下互信息的最大值
,找出所有划分情况下互信息的最大值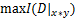 ,令
,令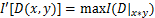 ,对其进行标准化:
,对其进行标准化:
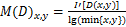 (5)
(5)
之后就可求出随机变量和在不同分割尺度下的最大互信息系数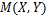 :
:
 (6)
(6)
当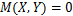 时,说明两者之间不存在任何相关性,其值越接近1则越说明两者之间的相关性越强;当
时,说明两者之间不存在任何相关性,其值越接近1则越说明两者之间的相关性越强;当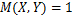 时,说明和之间存在着线性或非线性相关关系。
时,说明和之间存在着线性或非线性相关关系。
2 基于MIC工艺参数选择的冷轧产品机械性能模型
2.1 冷轧产品机械性能预测建模
图1所示为冷轧产品生产全流程是一个典型的多工序顺序加工过程 [16],整个生产过程具有多变量、多种数据来源,在产品生产过程中会涉及到许多个变量,例如冶炼成分、轧制温度、轧制速度以及轧制力等,它们来源多样、数据类型不同、相互之间的耦合关系复杂[17]。而由于制造过程中冶金、物理过程的复杂影响,工艺参数与机械性能之间的关系往往是非线性的,难以用简单的线性模型表征[18],另外,变量之间的相关性也增加了预测建模的复杂性。

图1 冷轧产品制造流程
Fig. 1 Cold rolled product manufacturing process
假设冷轧产品定量质量指标集为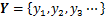 ,可获取产品制造过程{冶炼,连铸,热轧,冷轧}等工序的工艺参数分别表示为
,可获取产品制造过程{冶炼,连铸,热轧,冷轧}等工序的工艺参数分别表示为 ,其中每个阶段又由许多具体工艺参数构成,例如
,其中每个阶段又由许多具体工艺参数构成,例如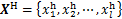 由
由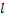 个参数构成。这样全面考虑工艺参数对质量指标的影响的质量建模可抽象为
个参数构成。这样全面考虑工艺参数对质量指标的影响的质量建模可抽象为
 (7)
(7)
在实际应用中,一般产品机械性能多为下屈服强度、抗拉强度和伸长率等。可以针对单一的性能指标分别构建形如式(7)所示的预测模型,但这样的模型虽然有很好的预测精度但不能统一考虑各工艺参数之间对多质量指标的耦合影响。
2.2 基于MIC工艺参数选择的冷轧产品机械性能预测模型及算法
2.2.1 问题定义
设可以获取{冶炼,连铸,热轧,冷轧}各工序的工艺参数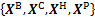 ,每个工序的参数个数分别为
,每个工序的参数个数分别为 ,
, ,和
,和 ,共有
,共有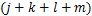 个工艺参数。由于这些工艺参数中有一些并不与质量指标集中的指标相关联,并且相互之间可能因耦合等因素给建模带来非必要的难度,降低了预测模型的准确度。要解决这个问题,可利用某种评价指标从工艺参数集中选择出适合的子集
个工艺参数。由于这些工艺参数中有一些并不与质量指标集中的指标相关联,并且相互之间可能因耦合等因素给建模带来非必要的难度,降低了预测模型的准确度。要解决这个问题,可利用某种评价指标从工艺参数集中选择出适合的子集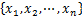 ,
,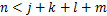 使得利用子属性构建的
使得利用子属性构建的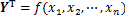 的预测精度更高[19]。
的预测精度更高[19]。
对于线性关联问题,Pearson相关系数、协方差和最小二乘回归误差等方法可以进行比较好的描述[20],但是在冷轧生产实际中许多变量之间是非线性关系,使用线性分析方法会遗失许多重要的非线性关联参数,最大互信息系数则可以有效避免这个问题。
2.2.2 基于MIC参数选择的预测模型和算法
通过MIC方法将整个冷轧过程中涉及的所有工艺参数与机械性能指标之间的关联程度进行量化,根据MIC分辨出关键工艺参数、重要工艺参数、一般工艺参数以及影响因素小或无影响的工艺参数。以不同的MIC阈值筛选出不同的工艺参数特征子集进行冷轧产品的机械性能预测。
在划分阈值范围进行特征子集选择时要考虑到这3个机械性能指标的影响参数之间是部分重叠但不完全相同的,在使用多输出回归模型时就需要将这3个机械性能指标所对应的3个特征子集取并集处理,即特征子集:
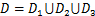 (8)
(8)
本文预测建模中考虑到工艺参数和性能指标之变的非线性影响关系,以及多性能指标之间的影响,采用多输出支持向量回归机(MSVR)作为预测模型,如图2所示。
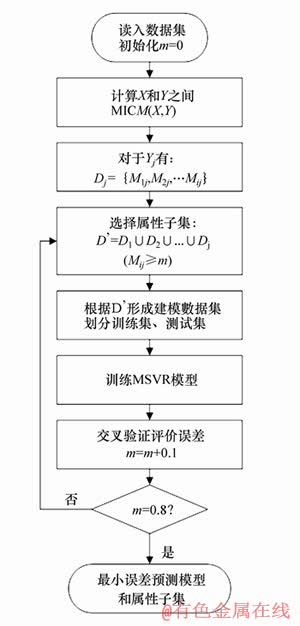
图2 基于MIC参数选择的预测模型流程
Fig. 2 Predictive model flow based on MIC parameter selection
3 实验与结果分析
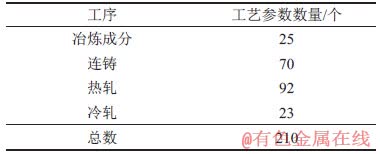
为了验证本文提出模型的有效性,利用某钢厂经过清洗处理后实际生产数据,总计1 607条样本,数据集共含有210个工艺参数和3个机械性能质量指标,其中工艺参数包括:钢卷长度、宽度、厚度和质量、轧机出入口张力、酸洗槽温度、酸质量浓度、冶炼成分、拉速、液位、液位波动量、塞棒位置、上水口氩气流量、内外弧热流、结晶器进水温度等;3个机械性能指标为:下屈服强度、抗拉强度和伸长率。表1所示为各个工序包含的工艺参数数量统计。
在建模中,按照8:2的比例,将1 607条样本数据划分为训练集和测试集,采用随机抽取的方式从样本中选出1 285条数据作为训练样本集,将剩下的322条作为测试集。以模型的平均相对误差作为评价指标:
表1 各工序工艺参数数量
Table 1 Number of process parameters in each process
 (9)
(9)
式中: 为质量指标数量;
为质量指标数量;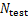 为测试集的样本数量;
为测试集的样本数量; 为样本实际值;
为样本实际值;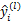 为模型预测值。
为模型预测值。
3.1 不同MIC阈值下模型预测结果
图3所示为利用本文提出方法计算各个工艺参数与质量指标之间的MIC结果的分布情况。从图3可以看出:与机械性能指标之间的MIC在0.2以下的工艺参数数量很大,这种情况下会对机械性能预测模型造成不良影响。
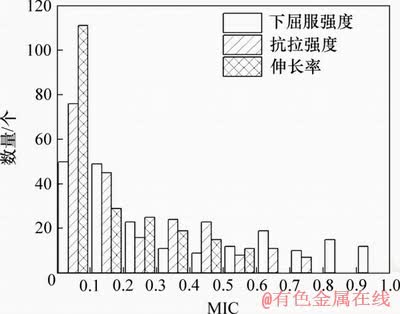
图3 各个变量与机械性能之间的MIC分布
Fig. 3 Distribution of MIC between individual variables and mechanical properties
采用2.2节中提出的预测模型以0.1,0.2,…,0.7为阈值来划分特征子集,表2所示为获得的不同MIC阈值下特征子集所包含的特征数量。
表2 不同MIC阈值下特征子集的特征数量
Table 2 Number of features of feature subsets under different MIC thresholds 个

图4所示为采用MSVR模型在不同MIC阈值下特征子集预测效果的平均相对误差,其中MIC阈值为0的特征子集代表原始特征集。从图4可以看出:当MIC阈值为0.2时,平均相对误差最小。图5所示为针对每项具体的机械性能指标的平均绝对误差。
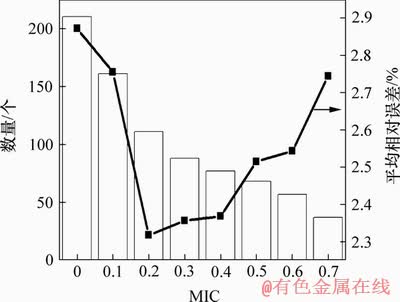
图4 各子集的特征数量和平均相对误差
Fig. 4 Number of features and mean relative error of each subset
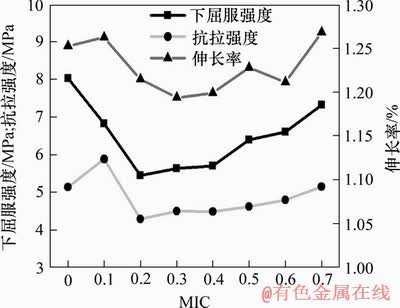
图5 各子集的机械性能平均绝对误差
Fig. 5 Mean absolute error of mechanical properties of each subset
从图4和图5可知:用工艺参数与机械性能指标之间的MIC来判定相关程度进行特征选择,对单个输出维度以及整体的预测效果有明显的影响。将平均相对误差作为模型的评价指标,MIC阈值为0.2时特征子集的下屈服强度、抗拉强度以及整体的平均相对误差最小。
3.2 与其他属性选择方法对比
为了对比最大互信息系数方法选择的最优子集更能合理地用于冷轧产品的机械性能预测模型,选用Pearson相关系数进行选择的特征子集以及基于传统机理和经验所选择的传统子集进行对比试验。
Pearson相关系数是一种比较经典的相关性度量方法。与MIC的特征子集选择过程一样,它通过不同的阈值范围来划分不同的特征子集,表3所示为得到的不同Pearson相关系数阈值下特征子集的构成。
表3 不同Pearson相关系数阈值下特征子集的特征数量
Table 3 Number of features of feature subsets under different Pearson correlation coefficient thresholds 个
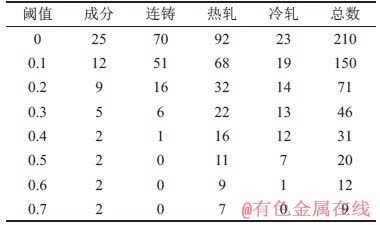
图6所示为利用与2.2节的模型进行预测得出不同阈值下得到的特征子集所得到的平均相对误差。
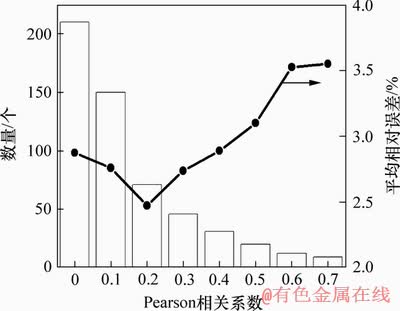
图6 Pearson系数选择子集的特征数量和平均相对误差
Fig. 6 Number of features and MRE error of each subset selected by Pearson coefficient
在模型最优时,通过Pearson相关系数作为相关性度量对冷轧产品的工艺参数进行特征选择,找出了71个与机械性能指标有线性相关的工艺参数。表5所示为以该特征子集建立的回归预测模型精度与最大互信息系数的最优子集以及基于经验知识选择的工艺参数子集的结果对比。
从表5可以看出:与Pearson和经验知识方法相比,MIC方法可以获得更准确的预测结果。
表4 经验知识子集中各工序工艺参数数量
Table 4 Number of process parameters in each process of experience knowledge subset
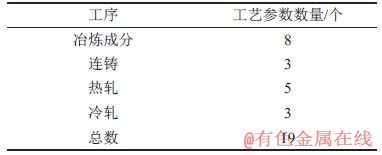
表5 3种方法下模型的预测结果
Table 5 Prediction results of models under three methods %

3.3 基于MIC方法发现的非线性影响关系
Pearson相关系数法对于变量之间的非线性关系不能很好识别,而MIC方法能够找出与机械性能指标之间非线性关联的工艺参数,对比MIC和Pearson方法选择出来的特征子集,可以发现通过MIC方法获得的特征子集中还含有许多非线性关系的变量是Pearson方法不能找出的。例如,原料成分工艺参数中的“Cu”被MIC方法选中而被Pearson方法排除,它与3个机械性能指标之间的关联程度通过MIC方法和Pearson方法的计算值,如图7所示。
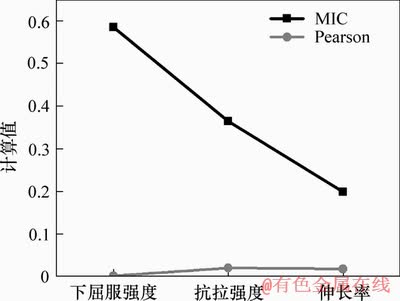
图7 工艺参数Cu的计算结果
Fig.7 Calculation results of process parameter Cu
铜元素能够提高奥氏体稳定性,强化铁素体,对机械性能有影响,但过量的铜元素还会导致钢具有热脆性,通过MIC方法识别出工艺参数“Cu”和机械性能之间的非线性关系使特征子集能更有效提高模型的预测质量。
图8所示为工艺参数酸洗槽酸质量浓度的计算结果。从图8可知: 变量“酸洗槽酸质量浓度”在MIC和Pearson下的计算值差异明显,其与屈服强度、抗拉强度和伸长率的MIC下的计算值分别为0.605,0.369和0.280,其Pearson下的计算值分别为0.149,0.098和0.148。图9所示为酸洗槽酸质量浓度与3个机械性能指标之间的散点图。
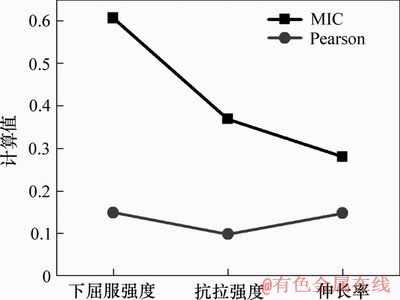
图8 工艺参数酸洗槽酸质量浓度的计算结果
Fig.8 Calculation results of process parameter acid mass concentration of pickling tank
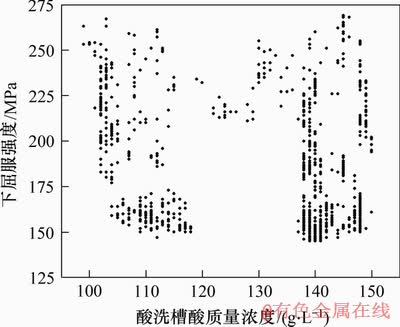
图9 酸洗槽酸质量浓度与机械性能的散点图
Fig.9 Scatter plot of acid mass concentration and mechanical properties in pickling tank
从图9可以看出:酸洗槽酸质量浓度与机械性能指标之间存在着非线性的相关性,这一关系却并没有被Pearson选择出来。将它从MIC方法选择出来的最优特征子集中剔除后,模型的预测精度下降,尤其对于酸洗槽酸质量浓度在区间[118,137] g/L的部分,整体平均相对误差从剔除前的2.31%上升到3.90%。
通过这些基于实际生产数据的实验表明,最大互信息系数能够识别与机械性能相关性较大的线性及非线性相关的工艺参数,通过最大互信息系数选择出的最优特征子集使得预测模型的精度更好。
4 结论
1)提出的基于最大互信息系数选择冷轧产品机械性能预测建模过程中工艺参数特征子集的方法可有效解决面对大量工艺参数特征建模时如何进行属性特征选择的问题。
2)采用最大互信息系数作为相关性度量进行特征选择,能够更有效地辨识冷轧产品的各个生产过程中与其机械性能指标之间存在的线性及非线性相关的工艺参数。
3)最大互信息系数获得的最优特征子集使回归模型具有更高的预测精度:冷轧产品机械性能预测模型的平均相对误差从使用原始数据集作为输入的2.90%下降到了2.30%。
参考文献:
[1] 孙勇, 何飞, 杨德斌. 基于批次回归系数的热轧带钢头部拉窄过程监控与诊断[J]. 中南大学学报(自然科学版), 2018, 49(3): 574-582.
SUN Yong, HE Fei, YANG Debin. Process monitoring and diagnosis of head width narrowing of hot rolled strip based on regression coefficients of different batches[J]. Journal of Central South University (Science and Technology), 2018, 49(3): 574-582.
[2] YU Lei, HUAN Liu. Efficient feature selection via analysis of relevance and redundancy[J]. Journal of Machine Learning Research, 2004, 5(10): 1205-1224.
[3] KASHEF S, NEZAMABADI-POUR H. An advanced ACO algorithm for feature subset selection[J]. Neurocomputing, 2015, 147: 271-279.
[4] BERETTA L, SANTANIELLO A. Implementing Relief F filters to extract meaningful features from genetic lifetime datasets[J]. Journal of Biomedical Informatics, 2011, 44(2): 361-369.
[5] NIKRAVESH M, ZADEH L A, KACPRZYK J. Soft computing for information processing and analysis[M]. Berlin/Heidelberg: Springer-Verlag, 2005: 313-326.
[6] ALIFERIS C F, STATNIKOV A, TSAMARDINOS I, et al. Local causal and markov blanket induction for causal discovery and feature selection for classification part i: algorithms and empirical evaluation[J]. Journal of Machine Learning Research, 2010, 11(1): 171-234.
[7] ZHANG Minling, PENA J M, ROBLES V. Feature selection for multi-label naive Bayes classification[J]. Information Sciences, 2009, 179(19): 3218-3229.
[8] MALDONADO S, WEBER R, FAMILI F. Feature selection for high-dimensional class-imbalanced data sets using Support Vector Machines[J]. Information Sciences, 2014, 286: 228-246.
[9] XIE H B, JIANG Z Y, TIEU A K, et al. Prediction of rolling force using an adaptive neural network model during cold rolling of thin strip[C]//Engineering Plasticity and Its Applications From Nanoscale to Macroscale. Daejeon, Korea: World Scientific, 2009: 351-355.
[10] SUI Xiaoyue . Application of high-dimensional multi-input layers GA neural network in prediction of hot-rolling product's mechanical property[J]. Journal of Information and Computational Science, 2015, 12(3): 1159-1168.
[11] PENG Hanchuan, LONG Fuhui, DING C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and Min-redundancy[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(8): 1226-1238.
[12] VERGARA J R, ESTEVEZ P A. A review of feature selection methods based on mutual information[J]. Neural Computing and Applications, 2014, 24(1): 175-186.
[13] 何飞, 肖会芳. 信息熵特征选择方法定位热轧带钢头部拉窄原因[J]. 工程科学学报, 2015, 37(S1): 45-50.
HE Fei, XIAO Huifang, Cause analysis of head width narrow of hot rolled strip based on feature selection of information entropy[J]. Chinese Journal of Engineering, 2015, 37(S1): 45-50.
[14] RESHEF D N, RESHEF Y A, FINUCANE H K, et al. Detecting novel associations in large data sets[J]. Science, 2011, 334(6062): 1518-1524.
[15] KINNEY J B, ATWAL G S. Equitability, mutual information, and the maximal information coefficient[J]. Proceedings of the National Academy of Sciences, 2014, 111(9): 3354-3359.
[16] LI Xinhang, LU Ningyun, JIANG Bin, et al. A frequent pattern mining based shape defect diagnosis method for cold rolled strip products[C]// 2017 6th International Symposium on Advanced Control of Industrial Processes (AdCONIP). Taipei, China: IEEE, 2017: 90-94.
[17] SUI Xiaoyue, LU Zhimin. Prediction of the mechanical properties of hot rolling products by using attribute reduction ELM[J]. The International Journal of Advanced Manufacturing Technology, 2016, 85(5/6/7/8): 1395-1403.
[18] KANCA E, CAVDAR F, ERSEN M M. Prediction of mechanical properties of cold rolled steel using genetic expression programming[J]. Acta Physica Polonica A, 2016, 130(1): 365-369.
[19] CAI Jie, LUO Jiawei, WANG Shulin, et al. Feature selection in machine learning: a new perspective[J]. Neurocomputing, 2018, 300: 70-79.
[20] CHANDRASHEKAR G, SAHIN F. A survey on feature selection methods[J]. Computers & Electrical Engineering, 2014, 40(1): 16-28.
(编辑 杨幼平)
收稿日期: 2019 -03 -25; 修回日期: 2019 -06 -06
基金项目(Foundation item):中央高校基本科研业务费基金资助项目(FRF-BR-17-030A) (Project(FRF-BR-17-030A) supported by the Fundamental Research Funds for the Central Universities)
通信作者:吕志民,博士,研究员,从事产品质量建模与控制技术、工业大数据分析、计划调度理论与方法等研究;E-mail:lvzhimin@nercar.ustb.edu.cn

