DOI: 10.11817/j.issn.1672-7207.2015.12.023
�������ж�����С��Ϣ��ʧ�������ȵ���˽��������
л��1, 2���Ž���2���2���ű�3
(1. �人��֯��ѧ ����ѧԺ������ �人��430200��
2. ���������̴�ѧ �������ѧ�뼼��ѧԺ�������� ��������150001��
3. ������������ѧ ����ѧԺ�������� ��������150080)
ժҪ����Բ�ͬ����ֵ����˽�����̶��������һ�����жȼ��㷽����������ֵ���еȼ����֣��ٶԲ�ͬ�ȼ�������ֵ�趨��ͬ�����жȣ�����һ����˽����ԭ��(��, k)- sensitivity�����Ƶȼ��������жȵķֲ������ʹ�õȼ����и����жȵ�Ԫ�鲻�����������˽й¶�����һ����С��Ϣ��ʧ���������㷨(minimum information loss increment first��MILIF)��ʵ����˽������Ҫ���о����������������ķ����ڽ�������ʱ��ͱ�������Ч�õ�ǰ���£������������ݱ����������Թ�����������
�ؼ��ʣ���˽���������жȣ�������Ϣ��ʧ����
��ͼ����ţ�TP309.2 ���ױ�־�룺A ���±�ţ�1672-7207(2015)12-4548-08
A privacy preserving approach based on minimum information loss increment first for dissimilar sensitivity
XIE Jing1, 2, ZHANG Jianpei2, YANG Jing2, ZHANG Bing3
(1. College of Management, Wuhan Textile University, Wuhan 430200, China;
2. College of Computer Science and Technology, Harbin Engineering University, Harbin 150001, China;
3. School of Software, Harbin University of Science and Technology, Harbin 150080, China)
Abstract: In order to satisfy the different privacy protection requirements for different sensitive values, a method was proposed to calculate the sensitivity of sensitive value, which was divided into several levels with different sensitivities. A (��, k) -sensitivity principle was proposed to control the distributions of sensitivity in equivalence class and the number of the high sensitivity tuples. A minimum information loss increment first algorithm was proposed. The results show that the proposed method can improve the ability of resisting sensitivity attack, on the premise of expending a little time and maintaining a high data utility.
Key words: privacy preserving; sensitivity; neighborhood; information loss increment
����Ϣ��ʱ��������������Ҫ�ռ��ͷ����ĸ����������Ծ��˵��ٶ���������Щԭʼ��ʽ�������ǹ�����Դ���䡢ҽѧ̽��������Ԥ����о��ı�����Դ�����磬ҽԺ���ܷ������˵���ϼ�¼�����ڷ������ּ�����������������ͳ�Ʊ��档Ȼ�����ڽ��������о���ͬʱ����������ɸ���������Ϣй¶����ˣ���Ҫ�����Ч����˽���������Ա�֤���������ڱ�ʹ�õ�ͬʱ��й¶������Ϣ�����ݷ�������˽��������ҪĿ�ľ��ǽ�ԭʼ���ݽ��д�����Ȼ�����µ���ʽ���������Ա�����˽й¶�͵������ֹ���[1]�����ڸ������ݣ���ijЩ����Ψһȷ���������ݵ�����������������֤�ŵȳ�Ϊ���ݱ�ʶ������(identifier)��Ȼ��ͨ����Ͽ���ȷ��ij����������Գ�Ϊ��ʾ������(quasi-identifiers, QI)�������䡢�Ա���ʱ�ȣ���������������Ϣ�����Գ�Ϊ��������(sensitive attributes, SA)���缲����н�ʵȡ������������ݷ����е���˽���������ܵ�Խ��Խ��Ĺ�ע�����е��о��ɹ��д���k-����[2-5]����l-������[6-8]ģ�͵���չ������ҪĿ����Ϊ�˿��Ƶȼ�����Ԫ����������ֵ�Ķ����ԡ����⣬t-closenessģ��[9-11]���о�Ҳ��һ���ȵ㷽������Ҫ˼���ǽ����ݱ���ȼ��������ֵ�ķֲ����������һ����ֵ�ڡ������о�ģ�ʹ��û�ж���������ֵ�����г̶Ƚ���Լ��������ʵ�������У���ͬ��������ֵ����˽��������ij̶ȴ��ںܴ�IJ��졣���磬������������ݱ�����������Ϊ���������ڸ�ð��θ�۵ȼ��������߲�������������֪���Լ������༲������ˣ����༲������˽�����̶�Ҫ��ϵͣ������ڷν�ˡ���֢�ȼ��������߲�ϣ������֪���Լ������༲��������������˵����ӣ���������༲������˽�����̶�Ҫ��ϸߡ������ɵȼ���Ĺ����У������������Щ����ֵ���������г̶ȣ����ܻ����ij���ȼ����е�����ֵ��Ϊ�߶�����ֵ���������l-������Ϊ������l=3�����ȼ��������ٰ���3������ֵ����ͬ��Ԫ�顣��һ���ȼ���������ֵ��ȡֵΪ{�ΰ���������θ��}���˵ȼ���������3-�����ԡ�Ȼ�����ΰ���������θ����Ϊ���г̶Ƚϸߵļ�����������ֻҪ֪��ij�������ڸõȼ��࣬��ʹ�����������ø�������ֵ�ľ���ȡֵ��������Ҳ�ܵó��ø��廼�а�֢�Ľ��ۣ�����˸������˽й¶���ɴ˿ɼ������������������ֵ�������������������г̶ȣ����ܻᵼ�¸����жȵ����Եò�����ֱ����������ݷ����е���˽�����о�����Sweeney��[2]���������k-������˽ģ�ͣ�Ҫ��ÿ���ȼ������ٰ���k��Ԫ�飬���Ҹ�k��Ԫ���QIֵ��ȡ�k-����ʹ�ü�ʹ������֪��ij�����QIֵҲ�����Ƶ����ø����������Ϣ(��Ϊ�ø����¼���ڵȼ����е�QIֵ���)��Ȼ������k��QIֵ�������ֵ�Ԫ��ǡ�þ�����ͬ������ֵʱ���õȼ����и��������ֵ�Ѿ�����¶��Ϊ�ˣ��о����������2���Ľ���ģ�͡���(��, k)-����[3]��l-������[6]�����k-�������ڵ����⡣(��, k)-����Ҫ��ÿ���ȼ����в�������k��QIֵ�ϲ������ֵ�Ԫ�飬���ҵȼ�����ÿ������ֵ���ֵ�Ƶ�ʲ�������ֵ����ʹ�õȼ���������ֵ�ֲ����������б��l-������Ҫ��ÿ���ȼ����в�������k-������Ҫ���ҵȼ����в�ͬ����ֵ������������l�����Դ�����֤����ֵ�Ķ����ԡ�����ģ���ж��ǿ�������ֵ������ȡֵ��ͨ�����ֲ�������������ֵ�Ķ����ԣ�û�п�������ֵ�����жȡ�Sun��[7]���һ����չ��(l, ��)-������ģ�ͣ���ģ�Ͷ�����ֵ���еȼ����֣�Ȼ��Բ�ͬ�ȼ�������ֵ����Ȩ�أ���Ҫ��ÿ���ȼ���������ֵ��Ȩ��֮�Ͳ�������ֵ��������[7]�ж�����ֵ����Ȩ����ʵ�������жȵ�һ�����֡�����(l, ��)-������ģ���Դ�����˽й¶�ķ��ա�����[12]Ҳ�������ֵ�����������Խ������о�����������˽����������̶ȣ�������������ֵ����Ϊ�ߡ��С���3���ȼ��࣬ͨ����˽�����Ȳ�����������й¶���գ������(�˦�, k)-�ּ�����ģ�ͣ���ģ��Ҫ��ȼ�����ÿ������ֵ���ֵ�Ƶ�ʲ�������ֵ�˦�����Ȼ��ģ�Ϳ��Կ��Ƶȼ���������ֵ���ֵĸ��ʣ�����Ҳ���ܳ��ֵȼ����е�����ֵ��Ϊ�����жȵ�������������˽й¶������[7��12]����Ԥ����ķ�ʽ�������������Եȼ���������ר�һ�������ӵ������ȷ����������ֵ�����г̶ȣ��˷�����Ȼ���Է�ӳ��һЩʵ�ʵ������Ǵ���һ���������ԡ����������������ֵ�����жȲ�ͬ�����һ�����жȵļ��㷽����������ֵ�����������������Խ��еȼ����֣����������еȼ��趨��ͬ�����жȣ�Ȼ�����һ��(��, k)- sensitivityԭ�������Ƶȼ��������жȵķֲ������������һ����С��Ϣ��ʧ���������㷨��ʵ�������(��, k)- sensitivityԭ��
1 ���жȼ���
���ȸ����������Եȼ����ֵĶ��壬Ȼ�����һ���������Եȼ������㷨����������ֵ�����ݱ��еij���Ƶ�ʶ�����ֵ���л��֣���������жȵļ��㷽�������û������������ݱ�T={QI1������ QIi������QIn��SA}������QIi(1��i��n)Ϊ��ʶ�����ԣ�SAΪ�������ԡ�����T�е���һ��Ԫ��t��t[A]��ʾԪ��t������A��ȡֵ��
����1 �ȼ��ࡣ�������ݱ�T��EΪT��ijЩԪ��ļ��ϣ����E��Ԫ������ʶ�������Ͼ�����ͬ��ȡֵ����ô��EΪ���ݱ�T�ĵȼ��ࡣ
����2 �������Եȼ����֡���R(S)Ϊ���ݱ�T�����������ϵ�ֵ��R(S)����Ϊm�����D(S)={S1��S2������Sm}����D(S)���������Եȼ����֣���D(S)Ӧ��������������
1) 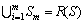 ��
��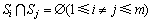 ��
��
2) ��i��j����Si�����жȱ�Sj�����жȸߡ�
����ʵ�����У�ij������ֵ���ֵ�Ƶ��Խ�ͣ�˵�����и�����ֵ�ĸ�����Խ�٣���Щ����������һ������²�Ը������������֪���Լ�������ֵ����Ϊ������ֵ�������˵IJ�ͬ������������ڵĹ�ע�������ӡ���ˣ�����Ƶ�ʵ͵�����ֵ�����ж�Ҫ�ߡ���������ֵ����Ƶ����������ֵ���л��֣��ܹ���ӳ������ֵ�����жȸߵͣ�����һ���ĺ����ԡ���������ֵ�ij���Ƶ����������ֵ�ȼ����л��֣����ַ������㷨1��
�㷨1 �������Եȼ������㷨��
���룺���ݱ�T����ֵm��
������ȼ����ּ���D(S)��
1) �������ݱ�T������ֵ�ij���Ƶ�ʣ�
2) V={������ֵ���������Ƶ�ʽ�������}��
3) while |V|��m do
4) ���㼯��V����������Ԫ�صĺϲ���Χr;//�ϲ���Χ�ļ��㹫ʽ������3
5) �ϲ�rֵ��С��2������Ԫ��vi, vi+1��vnew={vi, vi+1}��
6) 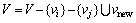 ��
��
7) end while
8) return D(S)=V��
����3 �ϲ���Χ�����ڼ���V�е�����2������Ԫ��vi��vi+1��mini��vi��Ԫ��Ƶ�ʵ���Сֵ��maxi��vi��Ԫ��Ƶ�ʵ����ֵ��vi��vj�ĺϲ���Χ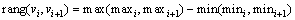 ��
��
���������Խ��еȼ�����֮��ͬ�ȼ�������ֵ�����������еȼ�Ҳ��ͬ����ˣ���Բ�ͬ�ȼ�������ֵ�趨��ͬ�����жȡ�
����4 ���жȼ��㡣��D(S)={S1��S2������Sm}�����ݱ�T���������Եĵȼ����֣�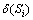 �ǵȼ�Si�����жȣ�
�ǵȼ�Si�����жȣ�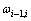 �����ڵȼ�Si-1��Si��Ȩ�أ�������
�����ڵȼ�Si-1��Si��Ȩ�أ�������
�����㣺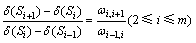 ����
����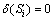 ��
��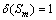 ��
��
������ȡֵ����������2�ֶ���[7]��
1) =1(2��i��m)��
2) 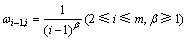 ��
��
ͨ�����Ƶ����Եó�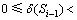
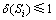 ��2��i��m���ȼ�Si������������ֵ�����жȼ�Ϊ��
��2��i��m���ȼ�Si������������ֵ�����жȼ�Ϊ��
2 (��, k)- sensitivityԭ��
���һ����˽����ԭ��(��, k)- sensitivity���Ƶȼ��������жȵķֲ����������ȼ����е�����ֵ��Ϊ�����жȵ������
����5 ���жȵĦ����������ݱ�T����Ϊ���жȵļ��ϣ������������ж�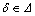 ��
��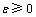 �������жȡ��Ħ�����
�������жȡ��Ħ�����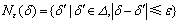 ��
��
����6 Ԫ�����������ȼ���E��t��E������Ԫ�飬Ԫ��t��������ֵ�����ж�Ϊ������Ԫ��t������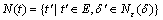 �����У�
�����У�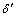 ��t���������ֵ�����жȣ�
��t���������ֵ�����жȣ�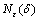 �ǡ��Ħ�����
�ǡ��Ħ�����
����7 (��, k)- sensitivityԭ�������ݱ�T��EΪT��ij���ȼ��࣬��E����(�ţ�k)- sensitivityԭ���ҽ���E��������������
1) �ȼ���E�����ٰ���k��Ԫ�飬k��1��
2) ����E�е�����Ԫ��t��������ֵ�����ж�Ϊ�����ڵȼ���E�У�t�������������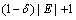 ��Ԫ�顣
��Ԫ�顣
�ɶ���7�е�����2)��֪����Ԫ������жȡ��ϸ�ʱ���ȼ�����Ҫ�������жȵĦ������ڵ�Ԫ��������٣�ʹ�õȼ����в������Ԫ������жȶ��ϸߵ����������ij���ȼ����е�Ԫ������ֵ������ͬ���������ǵ����жȶ��ϸߣ�����ʹ��������������ȷ������ֵ��Ҳ���Եó��ø�����н����е���Ϣ�Ľ��ۡ����ȼ�������(��, k)- sensitivityԭ��������˴�������ķ�����
����1 ���ڰ���k��Ԫ��ĵȼ���E�����������2��Ԫ������������ڽ�������ô�ȼ���E����(��, k)- sensitivityԭ��
֤��������֪�����ɵã��ȼ���E�а���k��Ԫ�飬���㶨��7�е�����1)������ΪE������2��Ԫ������������ڽ�������Ԫ�������ֻ����Ԫ�鱾��������7������2)Ҫ��Ԫ����������Ϊ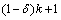 ����Ȼ��
����Ȼ��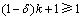 ����ΪE��ÿ��Ԫ�������ֻ����1��Ԫ�飬�ɴ˿ɼ��ȼ���E��������2)��֤�ϡ�
����ΪE��ÿ��Ԫ�������ֻ����1��Ԫ�飬�ɴ˿ɼ��ȼ���E��������2)��֤�ϡ�
����8 �ȼ�������жȡ���EΪ���ݱ�T�ĵȼ��࣬�ȼ���E���������Ե�ֵ��Ϊ{s1��s2������sr}����E�����ж�Ϊ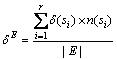 �����У�
�����У�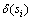 ��ʾ����ֵsi�����жȣ�n(si)��ʾ����ֵsi�ڵȼ����г��ֵĴ�����
��ʾ����ֵsi�����жȣ�n(si)��ʾ����ֵsi�ڵȼ����г��ֵĴ�����
����9 ���ݱ������жȡ��������ݱ�T��G={E1������Eg}ΪT�����еȼ���ļ��ϣ���T�����ж�Ϊ
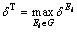
3 �����������жȵ����ݷ�������
3.1 ��Ϣ��ʧ��������
���ݷ��������Ϣ��ʧ�������Ժ������ݵ�Ч�ã�Ҳ��ֱ�ӷ�ӳ����˽ģ�͵����������еĺ���������Ϣ��ʧ�Ķ��������������߶�[13-14]���ֱ��ʶ���[15]�Ͳ�ѯ����[16]�������н�QI���Եij�ʼֵ�������������ֵ֮��ľ�����Ϊ��Ϣ��ʧ����������һ����ʧ����GLM(generalized loss metric)��������Ϣ��ʧ��GLM�Ķ����������¡�
����10 ��ֵ�����Եķ�����Ϣ��ʧ������ʶ������AΪ��ֵ�����ԣ�����Aȡֵ�ķ�Χ����Ϊ[L,U]����v������A��ijһȡֵ��v����Ϊ����[LA,UA]����ôv��������Ϣ��ʧI(v)=(UA��LA)/(U��L)��
����11 ���������Եķ�����Ϣ��ʧ������ʶ������A��Ϊ���������ԣ�HΪ����A��IJ������vΪ����A���ijһȡֵ��v����v�������ȡֵ����ôv����Ϣ��ʧI(v)=(MN-1)/(M-1)(���У�NΪv���ڲ����H�ж�Ӧ�Ľڵ㣻MNΪ��NΪ���ڵ��������Ҷ�ӽڵ�����MΪ�����H��Ҷ�ӽڵ���)��
����12 ���ݱ��ķ�����Ϣ��ʧ������t�����ݱ�T��Ԫ�飬��ôԪ��t���������Ϣ��ʧ
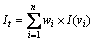 ������
�����У�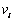 ��ʾԪ��t������QIi�ϵ�ȡֵ��
��ʾԪ��t������QIi�ϵ�ȡֵ��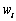 ��ʾ����
��ʾ����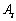 ��Ȩ�ز���
��Ȩ�ز���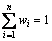 �������ݱ�T����Ϣ��ʧ
�������ݱ�T����Ϣ��ʧ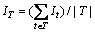 ��|T|��ʾ���ݱ�T��Ԫ������
��|T|��ʾ���ݱ�T��Ԫ������
��l-������[6]�в��÷ֱ��ʶ���DM(discernibility metric)��Ϊ����Ч�õĶ�������DM�Ķ������������ݱ��еȼ����ֵ������ÿһ��������Ԫ��ָ���ͷ�ֵ|E|��|E|��ʾ��Ԫ�����ڵȼ����ֵ����ˣ�
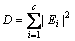
���У�DΪ�ֱ��ʶ�����cΪ�ȼ����������
3.2 ��С��Ϣ��ʧ���������㷨
����13 �ȼ������Ϣ��ʧ�������������ݱ�T��E�����ݱ�T�ĵȼ��࣬E�ķ������Ϊ(g1��g2������gn)������Ԫ��t���뵽�ȼ���E��ʱ���ȼ���E�ķ��������Ϊ(g��1��g��2������g��n)����ȼ���E����Ϣ��ʧ��������Ϊ�� ��
��
�����ɵȼ���Ĺ����У����ÿ��ѡȡ��Ԫ��ʹ�õȼ������Ϣ��ʧ������С������������ݱ�����Ϣ��ʧ�����ֽϸߵ�����Ч�ã���ˣ����һ����С��Ϣ��ʧ���������㷨(minimum information loss increment first��MILIF)�����ȣ���Ԫ�鰴�����жȽ������У�Ȼ������С��Ϣ��ʧ�������ȵIJ��������ɰ���k��Ԫ��ķ��飬���ҷ�����Ԫ����������ཻ���ɶ���1��֪�����ɵķ��鶼����(��, k)-sensitivity����˵���������ֱ��������������Ҫ��ķ��飻�����ʣ��Ԫ����д�����ͬ������С��Ϣ��ʧ�������ȵIJ��Խ�ʣ��Ԫ����뵽����(��, k)-sensitivityԭ��ķ����ڣ���û����Ӧ�ķ��飬��Ԫ�����䡣�����ʵ�ֹ��̼��㷨2��
�㷨2 ��С��Ϣ��ʧ���������㷨��
���룺���ݱ�T����ֵk�ͦţ�
��������ݱ�T�䡣
//�����
�����㷨1�еó������жȵȼ���T��Ϊmά����Q={B1��B2������Bm}��
//ÿ�����ϰ������ж���ͬ��Ԫ�飬����B1��Ԫ������ж���ߣ�Bm��Ԫ������ж���͡�
While 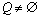 do
do
�����ǿռ���Bi��ѡȡ��һԪ��t��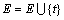 ��
��
for j=i:m
if sensitivity-check(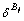 , E) then
, E) then
//�ж�Bj�е�Ԫ�����E��E��Ԫ��������Ƿ��ཻ
t��=choosebest(Bj,E)��//ѡȡʹE��Ϣ��ʧ������С��Ԫ��
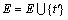 ��
��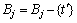 ;
;
else
continue;
end if
end for
if |E|��k then
������E���뼯��R��;
else
������E���뼯��G��;
end if
 ��
��
end while
//����ʣ��Ԫ���
for R�е�ÿһ��Ԫ��t
if (��G�д��ڼ���ʹ������t��������(��, k)- sensitivity) then
��t���뵽��Ϣ��ʧ������С�ļ�����;
else
����Ԫ��t;
end if
end for
������G�����ݱ�T����ʽ������
�㷨3 sensitivity-check(, E)
t�ǵȼ���E������ֵ�����ж���С��Ԫ��;
if |E|=1 then
return true;
else
if  then
then
return false;
else
return true;
end if
end if
�㷨4 choosebest(Bj,E)
I(E)�ǵȼ���E����Ϣ��ʧ��
for ����Bj�е�ÿ��Ԫ��t
����t����E֮��ȼ���E����Ϣ��ʧ����I(E,t);
 ;
;
end for
���ʹ ȡ��Сֵ��Ԫ�顣
ȡ��Сֵ��Ԫ�顣
4 ʵ����������
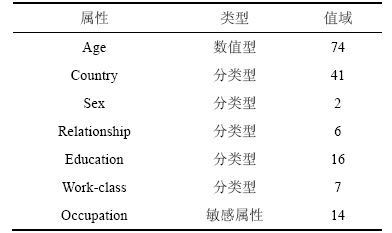
ͨ��ʵ�����(��, k)- sensitivity�����ܣ�������������[3]�����(��, k)-anonymity������[7]�����(l, ��)-diversity���бȽϡ�ʵ�������õ����ݼ�Ϊ��˽�����о��й㷺ʹ�õ�UCI machine learning repository�е�Adult���ݼ��������ݼ��������������˿��ղ����ݣ�������45 222����¼��ɾ������ȱʧֵ�ļ�¼֮��ʣ��30 162����¼��ѡȡ���ݼ��е�7������������ʵ�飬����{Age��Country��Sex��relationship��education��work-class}ΪQI���ԣ�OccupationΪSA���ԣ����ݼ����������1��ʾ��
4.1 ����Ч�÷���
����һ����ʧ����GLM�ͷֱ��ʶ���DM������(��, k)- sensitivity������Ч�á�GLM��DMԽС����˵�����ݵ�Ч��Խ�ߣ���֮������Ч��Խ�͡�
��1 Adult���ݼ�����
Table 1 Description of Adult dataset
4.1.1 һ����ʧ����GLM
ͼ1��ʾΪk��l�ı仯��3���㷨GLM��Ӱ�졣��ͼ1��֪����k��lֵ������ʱ��3���㷨��GLM��������������������k��l�����ӣ��ȼ�����Ԫ�����ؽ����ӣ��ڷ��������д�������Ϣ��ʧҲ�����ӣ���ˣ�GLM������ͼ2��������ʶ������ά��|QI|�仯��3���㷨GLM��Ӱ�졣��ͼ2��֪����|QI|����ʱ��3���㷨��GLM�������ӡ���������|QI|����ʹ���ڷ��������д��������������ӣ������ķ�����Ϣ��ʧҲ�����ӣ���ˣ�GLM������
���⣬��ͼ1��2��֪����ͬ�������£�(��, k)- sensitivity��GLM��(��, k)-anonymity�Ĵ���(l, ��)-diversity��GLM������ƽ����������(��, k)- sensitivity����˽����Ҫ�������2���㷨����˽����Ҫ����ϸ�ʹ������Ϣ��ʧ�ϴ�Ȼ����(��, k)- sensitivity��ѡȡԪ��Ĺ����в�������С��Ϣ��ʧ���Ȳ��ԣ���ˣ���(l, ��)-diversity��GLM������ƽ��
4.1.2 �ֱ��ʶ���DM
ͼ3��ʾΪk��l�ı仯��3���㷨DM��Ӱ�졣��ͼ3��֪����k��l����ʱ��3���㷨��DM��������������������k��l�����ӣ�Ϊ��������˽���������ȼ�����Ԫ���������ӣ�����DM�ļ��㹫ʽ��֪��DM�����ӡ�ͼ4��ʾΪ��ʶ������ά��|QI|�仯��3���㷨DM��Ӱ�졣��ͼ4���Կ�������|QI|����ʱ��3���㷨��DMֻ������ϸ�IJ�������������|QI|�����Ӳ���Ӱ��ȼ����е�Ԫ��������������ϸ������Ԫ��ѡȡ���������ɵģ���ˣ�3���㷨��DM��������
���⣬��ͼ3��ͼ4��֪����ͬ�������£�(��, k)- sensitivity��DM��(��, k)-anonymity��(l, ��)-diversity�Ĵ���������(��, k)- sensitivityҪ��ȼ�����ÿ��Ԫ��t���������������Ԫ��(������7)��Ϊ���ܹ�������˽����������ʹ��(��, k)-sensitivity�еȼ����Ԫ����������2���㷨�е�Ԫ�����࣬��ˣ�DM�ϴ�
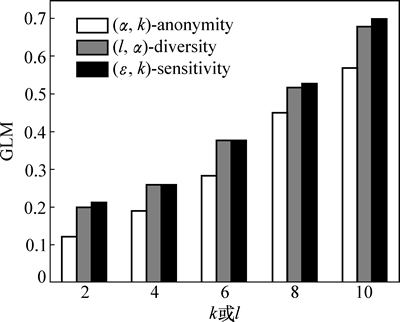
ͼ1 ��ͬk��l��GLM�ıȽ�
Fig. 1 Comparison of GLM at varying k or l
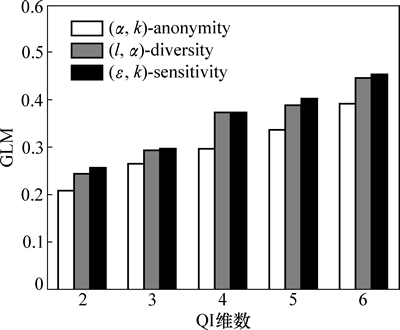
ͼ2 ��ͬQIά����GLM�ıȽ�
Fig. 2 Comparison of GLM at varying |QI|
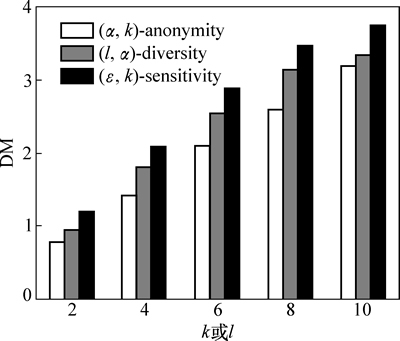
ͼ3 ��ͬk��l��DM�ıȽ�
Fig. 3 Comparison of DM at varying k or l
4.2 ִ��ʱ�����
ͼ5~7��ʾ�ֱ�Ϊk��l����ʶ������ά�������ݼ��仯��3���㷨ִ��ʱ���Ӱ�졣��ͼ5��֪����k��l������ʱ��3���㷨��ִ��ʱ�䶼��С��������������k��l�����ӣ������ɵȼ���Ĺ����л��и���ĺ�ѡԪ�飬����������������˽����ĵȼ��࣬��ˣ�ִ��ʱ�佫���١���ͼ6��֪����|QI|����ʱ��3���㷨��ִ��ʱ�䶼������������������|QI|�����ӣ��ڷ��������д�������ʶ���������ӣ������˸���Ĵ���ʱ�䣬��ˣ�ִ��ʱ�佫���ӡ���ͼ7��֪�������ݼ�����ʱ��3���㷨��ִ��ʱ�䶼�����������������ݼ������Ȼ�ᵼ�´���ʱ�����ӣ���ˣ�ִ��ʱ�䶼�����ӡ�
��ͼ5~7�ɼ�����ͬ�������£�(��, k)-sensitivity��ִ��ʱ���(��, k)-anonymity��(l, ��)-diversity��ִ��ʱ�䳤����������(��, k)-sensitivity��ѡȡԪ��Ĺ�����Ҫ����ȼ������Ϣ��ʧ������Ȼ��ѡȡ��Ϣ��ʧ������С��Ԫ�飬���⣬(��, k)- sensitivity����Ҫ����Ԫ����������ж��Ƿ�������˽����������Щ�����������ʱ���ϵ����ģ���ˣ�(��, k)- sensitivity��ִ��ʱ�������2���㷨��ִ��ʱ�䳤��
ͼ4 ��ͬQIά����DM�ıȽ�
Fig. 4 Comparison of DM at varying |QI|
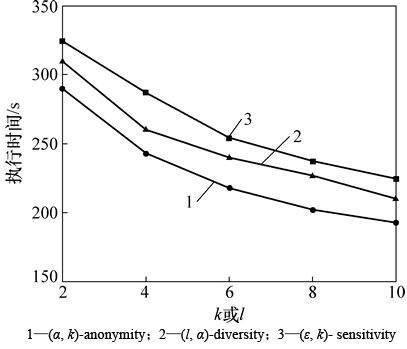
ͼ5 ��ͬk��l��ִ��ʱ��ıȽ�
Fig. 5 Comparison of execution time at varying k or l
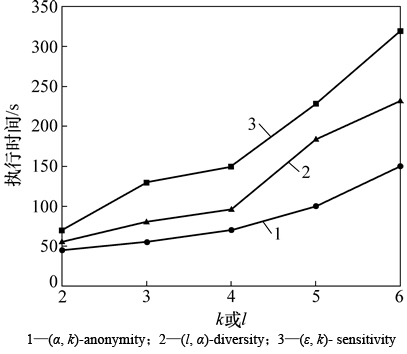
ͼ6 ��ͬQIά����ִ��ʱ��ıȽ�
Fig. 6 Comparison of execution time at varying |QI|
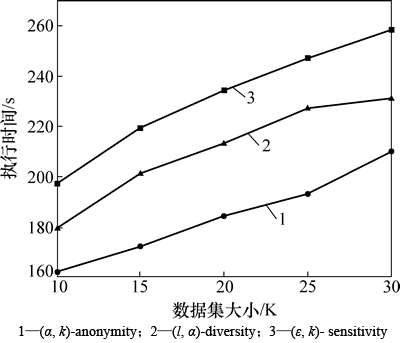
ͼ7 ��ͬ���ݼ���С��ִ��ʱ��ıȽ�
Fig. 7 Comparison of execution time at varying data size
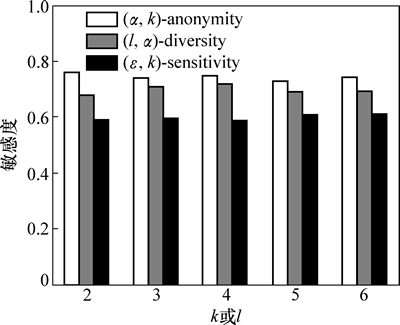
4.3 ���жȷ���
���ö���9�е����ݱ����ж���Ϊ�����������ݱ�T�����ж�Խ����˵��T�еȼ����е�����ֵ��ƽ�����ж�Խ�ߣ�Խ���ױ������߽��������Թ�������ˣ����ж�ԽС������˽�����̶�Խ�ߡ�
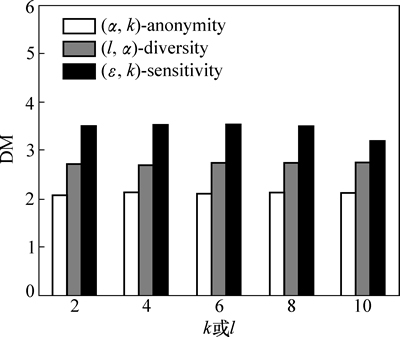
ͼ8��ʾΪk��l�ı仯��3���㷨���жȵ�Ӱ�졣��ͼ8��֪����k��l������ʱ��3���㷨�����ݱ������жȽ���С��������������k��l�����ӣ��ȼ����е�Ԫ�������ӣ�����ֵ������Ҳ�����ӣ���Ϊֻ����������ֵ�����жȽϸߡ���ˣ����ȼ���������ֵ����������ʱ���ȼ����е�ƽ�����жȽ���С��ͼ9��ʾΪ��ʶ������ά��|QI|�ı仯��3���㷨���жȵ�Ӱ�졣��ͼ9��֪����|QI|������ʱ��3���㷨�����ж�ֻ����ϸ�������������ڵȼ�����Ԫ���ѡȡ������ֵ��أ�|QI|�ı仯����Ӱ��ȼ�����Ԫ���ѡȡ��
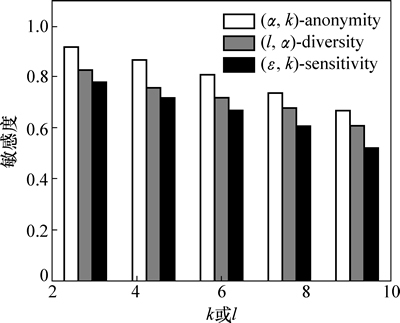
ͼ8 ��ͬk��l�����жȵıȽ�
Fig. 8 Comparison of sensitivity at varying k or l
ͼ9 ��ͬQIά�������жȵıȽ�
Fig. 9 Comparison of sensitivity at varying |QI|
��ͼ8~9�ɼ�����ͬ�������£�(��, k)-sensitivity�����жȱ�(��, k)-anonymity��(l, ��)-diversity��С����������(��, k)- sensitivityҪ��ȼ�����ÿ��Ԫ����������������Ԫ�飬�����˵ȼ��������жȵķֲ���ʹ��Ԫ������ֵ�����ж�Խ�ߣ��������е�Ԫ��Խ�٣������˵ȼ�����ֻ���������ж�Ԫ����������ˣ���ƽ�����жȽϵ͡�
����������(�ţ�k)-sensitivity����Ϣ��ʧ��(��, k)-anonymity�Ĵ���(l, ��)-diversity����Ϣ��ʧ��ƽ��(��, k)- sensitivity��ִ��ʱ���(��, k)-anonymity��(l, ��)-diversity��ִ��ʱ�䳤��Ȼ������ͼ8~9��֪��(��, k)-sensitivity�����ж�Ҫ������2���㷨��С����ˣ���������㷨����������ʱ��ͱ�������Ч�õ�ǰ���£������������ݱ����������Թ��������������������ݵ���˽����й¶��
5 ����
1) ���Ŀǰ����˽����ģ��ֻ��������ֵ�Ķ����ԣ���û�ж�����ֵ�����г̶Ƚ���Լ�������⣬���һ���������ж��»�����С��Ϣ��ʧ�������ȵ���˽�������������ȶ�����ֵ�����жȽ����˶��岢���(��, k)- sensitivity��˽����ԭ��֤�ȼ��������жȵķֲ����������б��Ȼ��ͨ����С��Ϣ��ʧ�������ȵ�˼�������MILIF�㷨�Լ�С��˽��������������Ϣ��ʧ��
2) ������ķ��������˵ȼ���������ֵ��ƽ�����жȣ����Ը���Ч�ص��������Թ�����
��л����л����ʡ�ߵ�ѧУ��������ѧ�ص��о����ء�����ҵ����֧���о����ĵ�֧�֣�
�ο����ף�
[1] XU Yang, MA Tinghuai, TANG Meili, et al. A survey of privacy preserving data publishing using generalization and suppression[J]. Applied Mathematics & Information Sciences, 2014, 8(3): 1103-1116.
[2] Sweeney L. k-anonymity: A model for protecting privacy[J]. International Journal of Uncertainty, Fuzziness and Knowledge based Systems, 2002, 10(5): 557-570.
[3] WONG Chiwing, LI Jiuyong, FU Waichee, et al. (��, k)-anonymity: An enhanced k-anonymity model for privacy preserving data publishing[C]//Proceeding of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2006: 754-759.
[4] Tassa T, Mazza A, Gionis A. k-Concealment: An alternative model of k-type anonymity[J]. Transactions on Data Privacy, 2012, 5(1): 189-222.
[5] Sarowar Sattar A H M, LI Jiuyong, DING Xiaofeng, et al. A general framework for privacy preserving data publishing[J]. Knowledge-Based Systems, 2013, 54(4): 276-287.
[6] Machanavajjhala A, Kifer D, Gehrke J. l-diversity: Privacy beyond k-anonymity[J]. ACM Transactions on Knowledge Discovery from Data, 2007, 1(1): 1-52.
[7] SUN Xiaoxun, LI Min, WANG Hua. A family of enhanced (L,��)-diversity models for privacy preserving data publishing[J]. Future Generation Computer Systems, 2011, 27(3): 348-356.
[8] Abdalaal A, Nergiz M E, Saygin Y. Privacy-preserving publishing of opinion polls[J]. Computers & Security, 2013, 37(3): 143-154.
[9] Li H, Li C, Venkata S. t-closeness: privacy beyond k -anonymity and l-diversity[C]//Proceeding of the 23rd International Conference on Data Engineering. Piscataway: IEEE, 2007: 106-115.
[10] Li H, Li C, Venkatasubramanian S. Closeness: A new privacy measure for data publishing[J]. IEEE Transaction on Knowledge and Data Engineering, 2010, 22(7): 943-956.
[11] �Ž���, л��, �, ��. ������������ֵ����Ͱ�����t-closeness ��˽ģ��[J]. ������о��뷢չ, 2014, 51(1): 126-137.
ZHANG Jianpei, XIE Jing, YANG Jing. et al. A t-closeness privacy model based on sensitive attribute values semantics bucketization[J]. Journal of Computer Research and Development, 2014, 51(1): 126-137.
[12] ����, ��С��. ���ھ���ķ�����������[J]. �����Ӧ��, 2013, 33(2): 412-416.
GUI Qiong, CHENG Xiaohui. Clustering-based approach for rnulti-level anonymization[J]. Journal of Computer Application, 2013, 33(2): 412-416.
[13] Lefevre K, Dewitt D J, Ramakrishnan R. Incognito: Efficient full-domain k �Canonymity[C]//Proceeding of the 2005 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2005: 49-60.
[14] Samarati P. Protecting respondents' identities in microdata release[J]. IEEE Transaction on Knowledge and Data Engineering, 2001, 13(6): 1010-1027.
[15] Bayardo R J, Agrawal R. Data privacy through optimal k-anonymization[C]//Proceeding of the 21st International Conference on Data Engineering. Piscataway: IEEE, 2005: 217-228.
[16] XIAO Xiaokui, TAO Yufei. Anatomy: Simple and effective privacy preservation[C]//Proceeding of the 32nd International Conference on Very Large Data Bases. New York: ACM, 2006: 139-150.
(�༭ �Կ�)
�ո����ڣ�2014-12-28�������ڣ�2015-03-28
������Ŀ(Foundation item)��������Ȼ��ѧ����������Ŀ(61370083��61073043��61073041��61402126��71571139��71171153)���ߵ�ѧУ��ʿѧ�Ƶ�ר����л���������Ŀ(20112304110011��20122304110012)(Projects (61370083, 61073043, 61073041, 61402126, 71571139, 71171153) supported by the National Natural Science Foundation of China; Projects (20112304110011, 20122304110012) supported by the National Research Foundation for the Doctoral Program of Higher Education of China)
ͨ�����ߣ��Ž��棬��ʿ�����ڣ�������˽��������������о���E-mail��zhangjianpei@hrbeu.edu.cn

