基于模糊粗糙集和蜂群算法的属性约简
王世强1, 2,张登福1,毕笃彦1,张立东3,王占领1,李洋1,雍霄驹1
(1. 空军工程大学 工程学院,陕西 西安,710038;
2. 解放军93986部队,新疆 和田,848000;
3. 空军装备研究院 雷达与电子对抗研究所,北京,100085)
摘要:为获取连续属性数据集的最小属性子集,提出一种基于模糊粗糙集和人工蜂群算法的约简方法。首先由边缘蕴含算子和t-模给出集合的模糊粗糙近似,以下近似构建模糊粗糙正域,并据此确定决策属性对条件属性集的依赖度,然后通过依赖度和约简率构建能够反映属性集大小和重要性的目标函数,将属性约简问题转化为优化问题,最后以目标函数为迭代准则,利用人工蜂群优化算法完成数据集的属性约简。仿真结果表明:该方法在不降低分类正确率的同时,可以有效降低属性维数。
关键词:属性约简;粗糙集理论;模糊粗糙集;依赖性;人工蜂群算法
中图分类号:TP181 文献标志码:A 文章编号:1672-7207(2013)01-0172-07
Attribute reduction method based on fuzzy rough sets and artificial bee colony algorithm
WANG Shiqiang, ZHANG Dengfu, BI Duyan, ZHANG Lidong, WANG Zhanling, LI Yang, YONG Xiaoju
(1. Institute of Engineering, Air Force Engineering University, Xi’an 710038, China;
2. PLA Unit 93986, Hetian 848000, China;
3. Radar and Electric Countermeasure Research Institute, Air Force Equipment Academy, Beijing 100085, China)
Abstract: To acquire the minimum attribute reduction of the dataset with continual attribute values, a novel method was proposed on the basis of fuzzy rough sets (FRS) and artificial bee colony (ABC) algorithm. Firstly, the fuzzy rough approximation of the sets was given via a border implicator and a t-norm, and the fuzzy rough positive region and dependency of the decision attribute about the condition attribute have generated using this approximation. Then, an objective function indicating the importance and size of attribute sets was constructed based on the concept of dependency and reduction rate. Via this operation, the problem of attribute reduction was converted to that of optimization. Finally, the attribute reduction for datasets was performed using the ABC algorithm under the guidance of the objective function value. Experimental results show that the strategy can reduce the attribute dimensions efficiently without sacrificing the classification accuracy.
Key words: attribute reduction; rough set theory; fuzzy rough sets; dependency; artificial bee colony algorithm
粗糙集理论是Pawlak[1-2]提出的一种能够处理不精确和不完整信息的数学工具。目前,该理论已被成功的应用机器学习、知识发现、数据挖掘、决策分析等诸多领域。其中,以不降低信息系统中分辨不同对象能力的属性约简问题一直是粗糙集理论研究的核心问题之一[3]。然而,经典粗糙集理论以分明等效关系为基础,要求不同对象的属性值之间具有精确的等效关系才能构成等效类,主要用来处理清晰、有限且离散的属性值,对于现实生活中本身具有模糊性的原始数据却不能直接处理。针对上述问题,研究者联合利用粗糙集和模糊集[4-5]来解决模糊属性信息表中的属性约简问题。基于模糊粗糙集(FRS)的属性约简在近几年里备受关注,并已取得一定的研究成果[3, 6-9]。而且结合优化算法的FRS属性约简方法也逐渐受到重视,如将模糊粗糙依赖度作为子集的性能评价准则,结合蚁群模型实现最优子集选择的方法[10],将FRS的信息熵和蚁群模型相结合的属性约简方法[11],利用遗传算法的全局优化和并行能力等优点,结合FRS的相关概念进行属性约简的方法[12-13]等。然而,这些方法都存在一定的不足,如蚁群算法初始信息素匮乏、容易出现停滞现象,遗传算法存在早熟收敛、参数不易确定、易出现冗余迭代、求解效率低等问题。而人工蜂群(ABC)算法[14]因具有计算简单、需要调整参数少、能够求得全局最优解等优点而成为当前研究热点,在函数优化[15]、组合求解[16]、聚类分析[17]、多目标优化[18]、神经网络训练[19]、工程设计[20-21]、图像处理[22]等方面均已取得一定成果。本文作者结合模糊粗糙集(FRS)和人工蜂群(ABC)算法的优点,提出一种融合FRS和ABC算法的属性约简方法。根据模糊粗糙依赖性和约简率设计一种适合属性约简的适应度函数,在此基础上利用ABC算法对数据集进行约简,最后得到最小约简子集。
1 模糊粗糙集模型
粗糙集理论中的等效关系是研究FRS的前提,也是应用其解决实际问题的基础。将经典粗糙集理论中的近似对象从分明集扩展到模糊集,并用论域上的模糊等效关系代替分明等效关系即可得到FRS。经典粗糙集研究对象是分明等效类,而FRS研究对象是模糊等效类,是将论域上的对象在模糊等效关系下划分成为模糊等效类。
设(U, A Q)为一个信息系统,其中:U表示对象的非空有限集,即论域;A表示条件属性的非空有限集,在不指明的情况下,属性指条件属性;Q表示决策属性的非空有限集,即类别属性集。属性集
Q)为一个信息系统,其中:U表示对象的非空有限集,即论域;A表示条件属性的非空有限集,在不指明的情况下,属性指条件属性;Q表示决策属性的非空有限集,即类别属性集。属性集 对应一个不可分辨的等效关系,在不引起歧义的情况下,将此等效关系简记为P,下文以此信息系统为前提展开研究。
对应一个不可分辨的等效关系,在不引起歧义的情况下,将此等效关系简记为P,下文以此信息系统为前提展开研究。
1.1 模糊粗糙集理论
记论域U上的模糊关系为P,对象x和y之间的相似度为uP(x, y)=uP(y, x),若P满足三角模算子的条件,即:(1)自反性, x∈U,uP(x, x)=1;(2)对称性,x, y∈U,
x∈U,uP(x, x)=1;(2)对称性,x, y∈U, ;(3)传递性,x, y, z∈U,min(uP(x, y), uP(y, z))≤uP(x, z),则称P为模糊等价关系[23]。根据P可定义对象x∈U的模糊等效类[x]P为:
;(3)传递性,x, y, z∈U,min(uP(x, y), uP(y, z))≤uP(x, z),则称P为模糊等价关系[23]。根据P可定义对象x∈U的模糊等效类[x]P为: ,y∈U。上式表示论域U中与对象x邻近的所有对象的聚集,它是论域上的一个模糊集。
,y∈U。上式表示论域U中与对象x邻近的所有对象的聚集,它是论域上的一个模糊集。
定义1 设(U, P)是模糊近似空间,即P是论域U上的模糊等价关系,I表示边缘蕴含算子;T表示t-模;模糊近似空间(U, P)上的(I,T)-模糊粗糙近似表示这样一个映射[24]: ,对
,对 ,
, 。
。
模糊集 ,
, 分别称为X在模糊近似空间(U, P)中的I-下模糊粗糙近似和T-上模糊粗糙近似,其隶属函数分别由式(1)和式(2)确定[9]:
分别称为X在模糊近似空间(U, P)中的I-下模糊粗糙近似和T-上模糊粗糙近似,其隶属函数分别由式(1)和式(2)确定[9]:
 (1)
(1)
 (2)
(2)
其中:F(U)表示U上的模糊子集的全体,对 ,若y∈X,则
,若y∈X,则 为1,否则为0。
为1,否则为0。 表示由模糊关系P确定的对象x和y之间的相似度,蕴含算子和t-模分别为:
表示由模糊关系P确定的对象x和y之间的相似度,蕴含算子和t-模分别为:
I(x,y)=min(1-x+y, 1) (3)
T(x,y)=max(x+y-1, 0) (4)
此时,可由迭代公式(5)确定[24]:
 (5)
(5)
例如,属性集P={a1, a2, a3},则=  ,其中:
,其中:
 (6)
(6)
对于属性a∈P, 可由式(7)表示的模糊相似度确定[9]:
可由式(7)表示的模糊相似度确定[9]:

 (7)
(7)
其中:a(x),a(y)分别表示对象x和y在特征a上的取值; 表示特征a上所有对象取值的标准方差。
表示特征a上所有对象取值的标准方差。
1.2 模糊粗糙依赖性分析
经典粗糙集理论中的正域定义为下近似的并集,将此概念扩展到模糊正域,并结合式(1),得到对象x关于模糊正域的隶属度:
 (8)
(8)
根据隶属度的含义以及模糊正域的定义,可以求出模糊粗糙集条件下决策属性Q对条件属性集P的依赖性[6]:
 (9)
(9)
其中:|U|表示U的势,即U中对象的个数。与经典粗糙集依赖性类似,上式表征仅用属性集P中的信息时可分辨对象在整个数据集中所占比例。式(9)同样表征Q依赖于P的程度,P以比例k决定Q的取值,即决定分类效果,k越大,以属性集P为依据进行分类时所取得效果越好。
下面以一个简单决策信息系统为例对该模糊依赖度的计算进行说明:设原始决策信息系统如表1所示,其中:a1,a2和a3为条件属性;Q为决策属性,先计算集合a1,a2和a3的模糊下近似,然后可计算得到各个属性的依赖度。
表1 具有连续属性值的决策信息系统
Table 1 Decision information system with continuous attribute values

首先,对于所有x, y ,由式(7)计算得到关于属性a1的对象间模糊相似度为:
,由式(7)计算得到关于属性a1的对象间模糊相似度为:

 (10)
(10)
同理得到关于属性a2的模糊相似度 为:
为:

 (11)
(11)
关于属性a3的模糊相似度 为:
为:

 (12)
(12)
决策属性Q决定的U的分明划分为:U/Q= {{1,3,6},{2,4,5}}={X1, X2},显然,若x X1则
X1则 (x)=1,否则(x)=0。从而得到:
(x)=1,否则(x)=0。从而得到:
(x)={1,0,1,0,0,1}
 (x)={0,1,0,1,1,0}
(x)={0,1,0,1,1,0}
此处xU。此时,根据式(1)即可分别得到X1和X2关于属性a1的I-下模糊粗糙近似为:
 (13)
(13)
 (14)
(14)
将式(10)和代入式(13)即可得: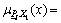 {0,0,0.3006,0,0,0},同理有:
{0,0,0.3006,0,0,0},同理有: {0,0,0,0.3006,0,0}。
{0,0,0,0.3006,0,0}。
然后,求出模糊粗糙近似后即可根据(8)式求得每一对象关于属性P=a1的正域:


最后,由式(9)求得属性P=a1关于决策属性的依赖度: ,其他属性的依赖度同理可求。从而得到各个属性的依赖度,即属性的重要度分别为:
,其他属性的依赖度同理可求。从而得到各个属性的依赖度,即属性的重要度分别为:  =0.3597,
=0.3597, =0.4078,进一步,由式(5)求得多属性模糊相似关系,如
=0.4078,进一步,由式(5)求得多属性模糊相似关系,如 而后类似以上几个步骤求得:
而后类似以上几个步骤求得: =1,
=1, =1,
=1, =0.5501,
=0.5501, =1。
=1。
2 人工蜂群算法
人工蜂群(ABC)算法是由Karaboga[14]于2005年提出的一种实参群集智能优化算法。该算法以蜜蜂群觅食行为为基础,利用蜂群的引领蜂、跟随蜂和侦查蜂通过不同的职能转换完成蜂巢花蜜最大化的原理求解目标函数的最优解。ABC算法中,优化问题中解的位置相当于食物源,其价值由适应度来表示,初始化解与引领蜂或跟随蜂的个数相等,其中引领蜂和跟随蜂各占蜂群的50%,侦查蜂由引领蜂抛弃某食物源后转换职能而来。其主要搜索过程如下所述。
首先,随机产生N个初始化解,每个解xi由d维向量构成,即xi=[xi1, xi2,…, xid]。其中:d表示优化问题中的解所包含参数的个数;i=1, 2, …, N。
其次,设定ABC算法最大循环搜索次数Cmax,设定某位置可行解最大可搜索次数t,即经过t次搜索后该处的更新解依然不能使得适应度值得到提高,则抛弃该处的可行解,令每次循环中引领蜂和跟随蜂数目分别为N,循环次数C=1,按照以下步骤开始循环。
步骤1 令i=1,对引领蜂Ei按照步骤2执行搜索,直到i=N;
步骤2 根据随机更新的解vi对食物源即解xi进行修正,如果vi使得适应度值得到提高,则以vi替换原解,同样记替换后的解为xi,否则,记录解xi在N个初始化解中的位置,并称此位置的解为候选丢弃解。vi由式(15)确定:
 (15)
(15)
其中:xij表示解xi中随机选取的第j个参数,vij表示修正xij产生的候选解vi的参数,xkj表示随机选取的解xk中的第j个参数,k位于i的邻域内,且k≠i, 表示与xij相关的随机数,∈[-1,1]。
表示与xij相关的随机数,∈[-1,1]。
步骤3 计算跟随蜂选择某食物源xi的概率pi,pi值越大,表明通过xi可获得更好适应度,从而被跟随蜂选中的概率越大。pi由下式确定:
 (16)
(16)
其中: 表示与食物源xi花蜜数量即目标函数值成比例的适应度,即第i个解的适应度,N 表示解的个数。
表示与食物源xi花蜜数量即目标函数值成比例的适应度,即第i个解的适应度,N 表示解的个数。
步骤4 令j=1,记跟随蜂Oj选中的食物源为xi,对Oj按照步骤2执行搜索,直到j=N,此处i∈{1, 2, …, N}。
步骤5 侦查蜂比较步骤2中各候选丢弃解的记录次数hi与t的关系,若hi>t,则抛弃该处解,同时令hi=0,并根据式(17)产生新的随机可行解:
 (17)
(17)
其中:rij表示解xi中的第j个替换参数; 和
和 分别表示xi的最大值和最小值;
分别表示xi的最大值和最小值; 表示与rij相关的随机数;∈[0, 1];i∈{1, 2, …, N};j=1, 2, …, N。
表示与rij相关的随机数;∈[0, 1];i∈{1, 2, …, N};j=1, 2, …, N。
步骤6 记录此时的最优解。
步骤7 判断算法是否达到最大循环次数或者满足终止条件,若任一条件成立,则终止算法,否则令C=C+1并从步骤1再次开始循环。
最后,算法终止时得到步骤6中的解即为全局最优解。
3 联合模糊粗糙依赖度和人工蜂群算法的属性约简
3.1 适应度函数设计
适应度函数是ABC算法中最重要的元素,一个食物源即解的适应度可以理解为解接近目标函数的程度。对于函数最优化问题,适应度函数即为目标函数,例如文献[15]对50个函数进行最优化求解,均利用目标函数值充当迭代的准则。对于属性约简问题,没有现成的目标函数可用,因此,需要设计一种适合属性约简问题的适应度函数。
考虑到属性约简的目的在于:找到与原始条件属性集合依赖性相当的最小条件属性子集,即要求最大的依赖性和最小的属性数目。因此,适应度函数中依赖性增加或属性数减少都要有利于总的适应度增加。为使属性集的依赖度与解中属性数目对适应度函数的贡献相当,需要将两者对适应度的贡献约束至同一数量级。基于以上考虑,设计属性约简问题中的适应度函数如下:
 (18)
(18)
其中:
 (19)
(19)
其中:表示由引领蜂Ei确定的属性子集Pi的适应度值;fi表示由子集Pi确定的目标值,由 可知,0<fi<1;
可知,0<fi<1; 表示约简率;
表示约简率; 表示决策属性Q对子集Pi的归一化依赖度;
表示决策属性Q对子集Pi的归一化依赖度; 表示权重因子,用来调节适应度函数的弹性。
表示权重因子,用来调节适应度函数的弹性。
由式(19)表明:约简率和归一化依赖度都与fi成正相关的关系,即fi随约简率和归一化依赖度的提高而增大,然而约简率和归一化依赖度之间并非正相关,因此,如何在最大化目标值前提下求得最大的依赖性和最小的属性数目,正是本文所要解决的问题。
3.2 约简方法
综合以上分析,利用ABC算法来完成数据集的属性约简。以蜂群随机选择属性子集为基础,通过模糊粗糙集计算其适应度函数,在迭代过程中找到最佳的子集,称其为模糊粗糙人工蜂群(FRABC)算法,该算法具体步骤如下。
步骤1 雇佣蜂随机产生属性子集。设属性集P包含d个属性值{a1, a2, …, ad},雇佣蜂数目为N,随机产生的食物源即初始化解数目取N,每个解xi由d维向量构成,即xi=[xi1, xi2,…, xid]。其中:d表示属性集P所包含属性的个数,i=1, 2, …, N。
步骤2 对产生的解进行取整与合并相同项操作。例如,设d=8,则随机产生的解为{5.75, 6.30, 6.20, 3.75, 5.59, 2.20, 5.94, 1.22},取整并将相同项合并后为{6, 4, 2, 1},代表属性集P中的第6、第4、第2和第1个属性被选中用以组成属性子集。
步骤3 根据(9)式计算产生的N个属性子集关于决策属性的依赖度,即属性子集重要性,从而求得ABC算法的适应度函数。
步骤4 根据适应度函数和N个属性子集运行ABC算法。
最后得到的全局最优解即为所求数据集的约简 子集。
4 仿真分析
为考察融合模糊粗糙集和蜂群算法的属性约简方法的有效性,在UCI机器学习数据库[12]上取7个连续值属性数据集进行实验。数据集的基本情况如表2所示。鉴于评估属性约简算法性能的指标主要体现在属性子集的大小和分类准确率上,文中采用Weka平台[25]分别对选取的数据集进行属性约简,并使用10-折交叉验证法得到JRip[26]和C4.5决策树[27]的分类准确率。同时选取Relief-F(Re)[6],Information Gain (IG)[6],Fast Correlation-based Filter (FCBF)[28],OneR (OR)[6]和Fuzzy Discernibility Matrix-based (FDM)[9] 5种不同的属性约简算法与本文方法进行对比分析,详细结果如表3~5所示,其中:Origin对应未经约简的属性数目,NA表示条件属性数目,r表示分类正确率;引领蜂,跟随蜂和食物源数目与特征数相同,设置 ,Cmax=1 000,认为平均约简率为约简前后属性数目的差与约简前属性数目的比值。
,Cmax=1 000,认为平均约简率为约简前后属性数目的差与约简前属性数目的比值。
表2 试验UCI数据集基本信息
Table 2 Information of data sets from UCI

表3中给出应用不同算法对数据集进行约简得到的属性子集,数字元代表属性子集中与UCI数据集相对应属性的标号。表4和表5给出不同约简算法下得到属性子集大小和不同分类算法下分类精度的比较 情况。
未经约简的属性集理论上分类能力较强,准确率也高,以下仅比较几种约简算法的性能。对照表3~5可得:
(1) Re,IG,FCBF,OR和FDM算法均对特征数量进行较大幅度的约简,与这5种算法相比,FRABC算法产生的约简结果平均属性子集最小;
(2) 若采用JRip分类器,则FRABC算法产生的属性子集平均分类准确率比Re和OR算法的略低,但此时属性个数明显较少,平均约简率约为93.79%,与IG,FCBF和FDM算法相比较,FRABC算法用较少的平均属性获得了较高的分类准确率;
(3) 采用C4.5决策树时,其他算法产生的属性子集分类准确率都比FRABC算法的低。
上述实验表明:FRABC算法在得到最小属性约简子集的同时,分类性能并没有明显降低,相反,多数情况下较其他算法的分类正确率略提高,说明基于FRABC算法的属性约简算法不仅降低了属性维数,而且一定程度上保证了分类器的正确率,验证了融合模糊粗糙集和人工蜂群属性约简方法的有效性。与其他算法相比较,该方法计算效率有待进一步提高。
表3 不同约简算法下数据集属性子集的比较
Table 3 Comparison of reduction subsets under different reduction methods

表4 JRip条件下分类精度比较
Table 4 Comparison of classification accuracy under JRip classifier

表5 决策树C4.5条件下分类精度比较
Table 5 Comparison of classification accuracy under C4.5 decision tree

5 结论
(1) 属性约简是模糊粗糙集理论的核心内容之一。针对利用传统方法进行约简时仍存在冗余的问题,提出一种基于模糊粗糙人工蜂群(FRABC)算法的约简方法。
(2) 该方法从模糊粗糙集依赖度入手,构建了反映属性子集重要性和约简率的适应度函数,并以此函数为准则利用人工蜂群算法对数据集进行属性约简。
(3) 在选取的UCI数据集上进行试验,结果表明该方法在不降低分类精度的同时,克服了传统方法的约简结果中含有冗余属性的问题,能够得到数据集的最小属性约简,平均约简率达93.79%。
参考文献:
[1] Pawlak Z. Rough set[J]. International Journal of Computer and Information Sciences, 1982, 11(5): 341-356.
[2] Pawlak Z, Skowron A. Rudiments of rough sets[J]. Information Sciences, 2007, 177(1): 3-27.
[3] Cornelis C, Jensen R, Hurtado G, et al. Attribute selection with fuzzy decision reducts[J]. Information Sciences, 2010, 180(2): 209-224.
[4] Banerjee M, Pal S K. Roughness of a fuzzy set[J]. Information and Computer Science, 1996, 93(3): 235-245.
[5] Dubois D, Prade H. Rough fuzzy sets and fuzzy rough sets[J]. Information and Computer Science, 1990, 17(2): 191-209.
[6] Jensen R, Shen Q. Fuzzy-rough sets assisted attribute selection[J]. IEEE Trans on Fuzzy Systems, 2007, 15(1): 73-89.
[7] Shang C J, Barnes D, Shen Q. Facilitating efficient mars terrain image classification with fuzzy-rough feature selection[J]. International journal of hybrid intelligent systems, 2011, 8(1): 3-13.
[8] Tsang E C C, Chen D G, Yeung D S, et al. Attributes reduction using fuzzy rough sets[J]. IEEE Trans on Fuzzy Systems, 2008, 16(5): 1130-1141.
[9] Jensen R, Shen Q. New approaches to fuzzy-rough feature selection[J]. IEEE Trans on Fuzzy Systems, 2009,17(4):824-838.
[10] Jensen R, Shen Q. Fuzzy-rough data reduction with ant colony optimization[J]. Fuzzy Sets and Systems, 2005, 149 (1): 5-20.
[11] 赵军阳, 张志利.基于模糊粗糙集信息熵的蚁群特征选择方法[J]. 计算机应用, 2009, 29(1): 109-111.
ZHAO Junyang, ZHANG Zhili. Ant colony feature selection based on fuzzy rough set information entropy[J]. Journal of Computer Applications, 2009, 29(1): 109-111.
[12] 聂作先, 刘建成. 一种面向连续属性空间的模糊粗糙约简[J]. 计算机工程, 2005, 31(6): 163-165.
NIE Zuoxian, LIU Jiancheng. An attribute-reducing algorithm based on GA and fuzzy rough set theory[J]. Computer Engineering, 2005, 31(6): 163-165.
[13] 朱江华, 李海波, 潘丰. 基于遗传算法和模糊粗糙集的知识约简[J]. 计算机仿真, 2007, 24(1): 86-89.
ZHU Jianghua, LI Haibo, Pan Feng. Knowledge-reduction based on GA and fuzzy-rough set[J]. Computer Emulation, 2007, 24(1): 86-89.
[14] Karaboga D. An idea based on honey bee swarm for numerical optimization, Technical Report-TR06[R]. Erciyes University, Engineering Faculty, Computer Engineering Department, 2005.
[15] Karaboga D, Akay B. A comparative study of artificial bee colony algorithm[J]. Applied Mathematics and Computation, 2009, 214(1): 108-132.
[16] Pan Q-K, Tasgetiren M F, Suganthan P N, et al. A discrete artificial bee colony algorithm for the lot-streaming flow shop scheduling problem[J]. Information Sciences, 2011, 181(12): 2455-2468.
[17] Karaboga D, Ozturk C. A novel clustering approach: artificial bee colony (ABC) algorithm[J]. Applied Soft Computing, 2011, 11(1): 652-657.
[18] Omkar S N, Senthilnath J, Khandelwal R, et al. Artificial bee colony (ABC) for multi-objective design optimization of composite structures[J]. Applied Soft Computing, 2011, 11(1): 489-499.
[19] Karaboga D, Ozturk C. Neural networks training by artificial bee colony algorithm on pattern classification[J]. Neural Network World, 2009, 19(3): 279-292.
[20] Singh A. An artificial bee colony algorithm for the leaf-constrained minimum spanning tree problem[J]. Applied Soft Computing, 2009, 9(2): 625-631.
[21] Karaboga N. A new design method based on artificial bee colony algorithm for digital IIR filters[J]. Journal of Franklin Institute, 2009, 346 (4): 328-348.
[22] Xu C, Duan H. Artificial bee colony (ABC) optimized edge potential function (EPF) approach to target recognition for low-altitude aircraft[J]. Pattern Recognition Letters, 2010, 31(13): 1759-1772.
[23] Hu Q H, An S, Yu D R. Soft fuzzy rough sets for robust feature evaluation and selection[J]. Information Sciences, 2010, 180(22): 4384-4400.
[24] Radzikowska A M, Kerre E E. A comparative study of fuzzy rough sets[J]. Fuzzy Sets and Systems, 2002, 126(2): 137-155.
[25] Hall M, Frank E, Holmes G, et al. The weak data mining software: An update[J]. SIGKDD Explorations, 2009, 11(1): 10-18.
[26] Cohen W W. Fast Effective Rule Induction[C]//12th International Conference on Machine Learning. Tahoe City, CA: Morgan Kaufmann, 1995: 115-123.
[27] Quinlan J R. C4.5: programs for machine learning[M]. San Francisco: Morgan Kaufmann Publishers, 1993: 81-91.
[28] Yu L, Liu H. Efficient feature selection via analysis of relevance and redundancy[J]. Journal of Machine Learning Research, 2004, 5(10): 1205-1224.
(编辑 邓履翔)
收稿日期:2011-12-26;修回日期:2012-02-17
基金项目:国家自然科学基金资助项目(61175029);国防科技重点实验室基金资助项目(9140C610301080C6106,9140C6001070801);航空科学基金资助项目(20095596014,20101996009);陕西省自然科学基金资助项目(2009JM8001-4)
通信作者:王世强(1982-),男,陕西西安人,博士研究生,从事智能信息处理、模式识别等研究;电话:15829462239;E-mail: wunsicon@163.com

